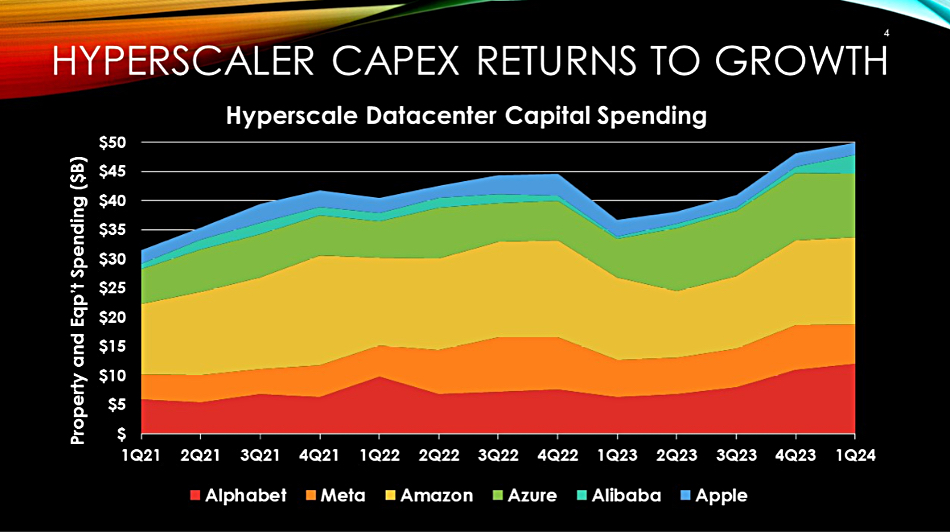
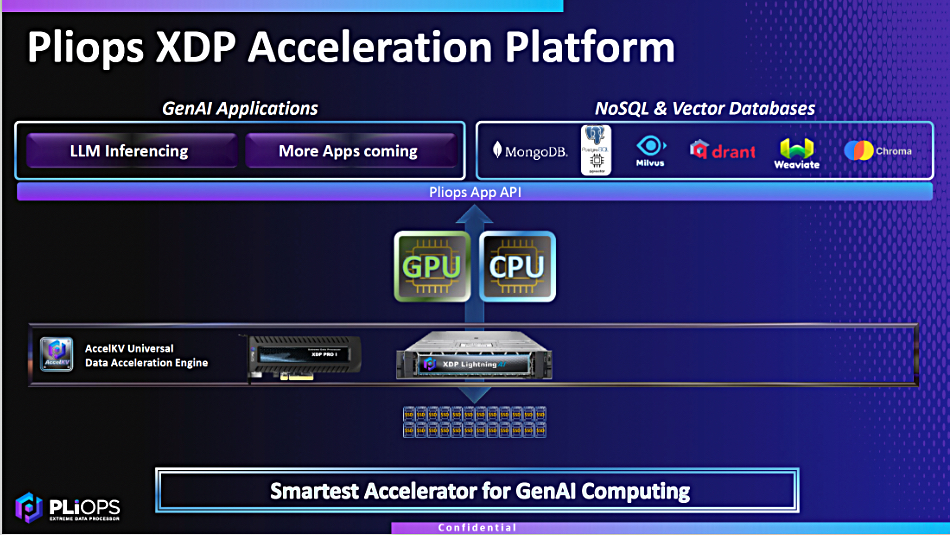
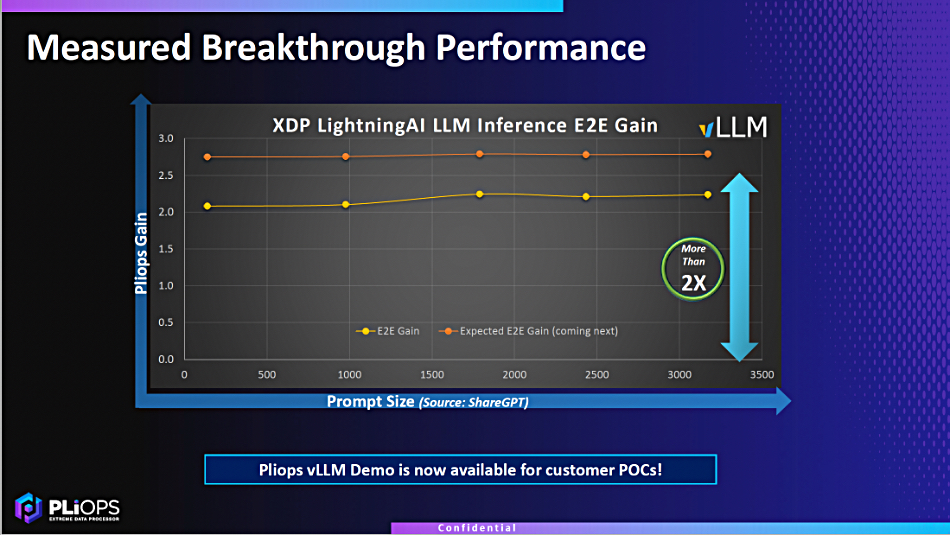
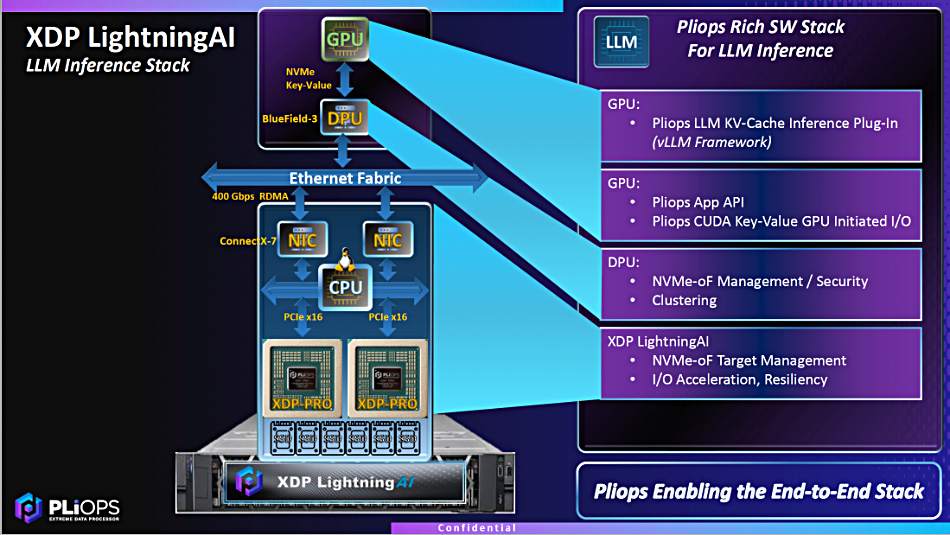
SPONSORED FEATURE: It’s the job of a storage array to be a data service, to store and serve data to its users. If that data is corrupted or stolen then the array is not doing its job.
Storage array suppliers have increasingly emphasized cyber-resilience measures to safeguard the data they hold. An example of this Pure Storage adding a generative AI Copilot to help storage admin teams with security issues as well as performance investigations and fleet management.
Now the epidemic of malware assailing virtually every organization getting worse with AI-assisted malware being more and more effective at opening and passing through doorways into IT systems and setting them up for data extraction and encryption. Emotet and TrickBot are examples of AI-assisted malware.
This form of malware will be more effective at gaining entry to target systems. Organizations can themselves take advantage of AI to strengthen their attack response posture. Andy Stone, CTO for the Americas at Pure Storage, has written a 3-part blog looking at the before-, during -, and after-attack phases and how organizations can organize themselves to resist, respond and recover.
Malware businesses are businesses; not short-sighted groups of disaffected hackers; teenagers in a basement. They can be strong, efficient, well-organized and determined. Pure VP R&D Customer Engineering, Shawn Rosemarin, commented on “the level of corporate maturity in some of these companies, like they are run by CEOs and CFOs they have fundamental formal support plans. You can even purchase extensive support contracts allowing you to call and get support with their tools if you’re having trouble getting them to do what you need them to do. In fact, some of them even offer “as-a-service” campaigns where they’ll take a piece of what it is that you are able to get access to, or even charge you on the amount of positive responses, or essentially the amount of breach that you’re able to cause.”
All of this suggests that target organizations, meaning any organization, need to have the same kind of approach to incoming malware. That means a well thought through and informed stance.
This starts with being prepared for an attack by maintaining a high standard of data hygiene, looking for active threats and having a rehearsed attack response plan. In a pre-attack or reconnaissance phase, attackers reconnoiter systems, initiate an attack plan, and try to gain entry through social engineering phishing techniques. It is during this pre-attack phase that AI-assisted malware can be most effective, crafting more sophisticated phishing approaches, extensive port log scanning, and also polymorphic signatures.
With port scanning, Rosemarin said: “If I can get into a port and I can start to sniff that port and look at what’s happening, the ability for AI to actually filter and analyze what is potentially millions or hundreds of millions of logs makes it significantly easier. Finding vulnerabilities within those logs becomes easier with AI, because AI is very good at looking at massive amounts of information, finding something that’s interesting.”
AI can also help improve social engineering phishing: If the attacker can find out even a little bit about an employee or officer of an organization and the way they behave, their access patterns they can more effectively pretend to be that officer or employee, and that person.
Once an employee has been duped and malware code installed then, in Rosemarin’s view: “AI is changing the way these threats behave. You can call this concept ‘shape-shifting’, which you know is really probably a comic book or animation cartoon concept until now. What AI is allowing these threats to do is shape-shift and change their activity, on-the-fly. So if I see it in one place, it looks like this, but by the time I go to get rid of it, it’s changed its signature. it’s changed its behavior, which makes it significantly harder to identify and deal with.” Such polymorphic viruses are harder to detect and remediate.
It is quite possible that, right now, there is malware lurking in your IT system, being used to scan and map out your system’s overall architecture so that vulnerabilities and targets can be identified.
Rosemarin said: ”Ultimately the attacks will come in, and they’ll come in from an application or user device, and they’ll find a way to move through your environment, either north, south or east, west, depending on how they can and where they’ll find the most valuable or the biggest payload is, ‘honey pot’ as it’s called in the industry. And they’ll dwell undetected until the timing is right to attack that particular honey pot.”
Once malware code is dwelling in a system it can watch what staff do in a typical day. It can watch for 45 days, 60 days, or even longer and detect that, say, every Tuesday at 8pm the employee does some sort of download. Rosemarin suggested: “That would be the time for me to move my malware to these particular systems, because that would not be considered out of the ordinary.”
He said: “I can arm the malware to attack against the latest CVEs (Common Vulnerabilities and Exposures), what are often zero day attacks. Because, in a large environment, it currently can take a few weeks, days or weeks to get CVEs actioned due to change control and outage windows. CVEs provide excellent entry points allowing malware to assess your data estate, and assess the appropriate payload to release.”
Where Pure Storage can help
What can Pure Storage do to better detect these attacks? Rosemarin told us: “The opportunity for us that’s unique is that, unlike our competitors, we have visibility into the life of an IO all the way from the storage controller through to the flash media. Specifically, we are able to follow the particular command set that’s coming from the app through the storage controller down to the flash, allowing us to see exactly what’s happening to that IO at every element of the storage stack. We leverage this full telemetry, as well as the metadata management associated with it, to make it easier for us to spot potential anomalies.”
“This is already in use today within Pure1’s ransomware detection mechanisms learning what’s normal in the life of an IO all the way down to the flash level.” He says no other storage array supplier can do this due to their reliance on third party SSDs and the disparate firmware therein.
Pure also has ransomware detection built in now to Pure1. Customers can go in and turn on the feature to look through recorded logs and alert them within the Pure1 console.
At a higher level, Pure works with security companies like Palo Alto Networks allowing them to use this information: ”There’s a standard called Open Telemetry, which is essentially taking my metrics and converting them to a format that is easily integrated into third party systems,” says Rosemarin. “Today, we use telemetry from infrastructure in the open telemetry standard, and then we put this data directly into SecOps workflows so that customers can gain visibility all the way down to their storage level.”
That means it can be correlated with what’s happening at the user authentication schema level; for example who’s logged into which systems, and play a role at the SIEM, SOAR, and security operations center level.
But there’s more: “As we find these particular signatures or patterns within the telemetry, we take automated action to protect the data that’s within it.”
Pure’s malware security infrastructure also features automated action scripts. Rosemarin said these “integrate with SIEM, SOAR and XDR (Extended Detection and Response) so that if we natively find a threat, or if the SecOps workflow finds a threat, we engage certain capabilities like SafeMode snaps that would protect that particular volume in the case of an anomaly detection without human intervention.”
This automated execution is a major advantage, as opposed to an alert says Rosemarin. When someone gets an email or a page or a text alert, they then have to go in and do something, which takes time. As Pure’s system has complete storage telemetry visibility and automated script actions, it has the capabilities to lock down that storage instantly. That can be a huge benefit in damage limitation to its customers.
Safemode for resilience and space efficiency
In addition, a feature of Pure’s volume snapshotting is its “SafeMode” immutability, notable not only for its resilience but also its space-efficiency. Rosemarin says: “The easiest way to restore a data set is a snap,” and Pure has: “the most space-efficient snapshot technology in the industry.” With other suppliers: “snapshot technology can consume a significant amount of space. Cyber criminals know that the average organization only does snaps for 60 days, say, because they don’t want to consume a ton of expensive space, and so they’ll let the malware dwell for 65 days, knowing that now it’s taken you to the point where your only restoration mechanism is from backups.”
“And not only is that slower and more kludgy, it also represents all sorts of additional risks, I have to restore the applications, then I have to replay logs, because transactions have occurred since the last full backup. And if I’m in banking or in insurance or any kind of institution, I could potentially lose valuable transactions. People made deposits, they took withdrawals. Equipment moved. Customers placed orders.” It all adds up and can make restoring from backup painful and risky.
The benefit, he explains, is that “with Pure I can get more space-efficient snapshots, which allows me to have more days of protection for the same amount of potential use of the storage capacity. And those snapshots will be immutable to the point where, even if the credentials are phished to Pure1, the attackers will not be able to go in and encrypt my snaps. SafeMode immutability is protected beyond access credentials with named users and secondary passcodes. Snapshot strategy is so important, because, in the event of an attack, I’m just going to use my snaps to instantly restore myself to a period pre-breach.”
Once an attack is detected the affected systems have to be identified, locked down, disconnected from the network and quarantined. Rosemarin said: “The array is put into solitary confinement.”
Attack detection should trigger a SecOps response plan: ”This is no different than any element of your DR plan. Ultimately it should not be that the phone rings at 2am or someone gets paged, and now everybody’s got to come in and figure out what they’re going to do.”
“This is part of the SecOps playbook, part of the SecOps mandate. Most organizations now have a SecOps organization, and it’s not necessarily a full-time job function. It’s individuals from specific groups that have been pulled into SecOps to not only build but practice and execute this plan in the event of an attack.
“But it’s also not just the company itself. It includes their cyber-insurers, potentially law enforcement, and even government organizations like the CIA and FBI who get engaged in these pursuits. There is an established process, an ’In case of emergency, break glass’ type of book that spells out the process and the people involved.”
“This is a formal team, a little bit like what we had back with Y2K. This team has to practice. It has to know what processes they’re going to follow. If you just leave this to your network and system administrators it’s usually ineffective. It requires business leadership, critical partners. It might involve your legal teams, external law enforcement as well as your cyber insurance providers.”
Time for data restoration and recovery
Once the attack is halted, and in the initial post-attack stage, this is where data restoration and recovery take place. The affected data must be identified and restored to fresh and clean systems. This requires replacement clean hardware as the attacked system hardware is now corrupt and quarantined. It may be required for forensic analysis use which can take appreciable time; days and weeks.
Rosemarin again: “You’ll have a recovery environment, whether off-site, on-site, rented, leased or as-a-service. And that’ll give you line of sight to new hardware. In many cases we deal with this at Pure through Evergreen/One. We actually offer a ransomware recovery SLA and we take care of it. We guarantee the shipment of equipment, we guarantee the migration of the data and the restoration of the systems, and we actually ensure that the systems are up and running.”
The attack recovery process is complex. Rosemarin told us: “You want to update your credentials and passwords. You want to make sure that you know if any information was posted on your site by the attackers. You remove it. You contact the search engines to clear the cache, so that any kind of breach fallout is minimized. Then you have to mobilize your emergency response team, which gets us back to SecOps.
Rosemarin thinks attacked organizations should share their attack data. They “should consider publicizing these attacks and the activity to help their peers deal with similar attacks. They can do that either anonymously through case studies or cybersecurity forums. Some of the biggest are the Information Sharing and Analysis Center (ISACs) in financial services and healthcare.
“Some of these are protected in that you need to be a member of a given organization and you need to be vetted. But there’s also less formal clearinghouse called the Information Sharing and Analysis Organizations (ISOs). They’re similar, but they’re more flexible in terms of membership. What this does is give companies the ability to have collective defense community support, the concept of ‘you give to get.’”
Rosemarin thinks that: “As humans, we are the largest weakness in the security chain. And the good news is, when I look at AI, the ability for AI to augment our systems to protect us against these threats is the way forward. That augmentation is going to come on the back of clear and present visibility, and I think that organizations who have the ability to most effectively gather that telemetry and connect it, will be in the best position to deal with attacks.”
Sponsored by Pure Storage.