


All-flash storage array supplier VAST Data has ported its storage controller software into Nvidia’s BlueField-3 DPUs to get its stored data into the heart of Nvidia GPU servers, transforming them, VAST says, into AI data engines.
Update: Supermicro and EBox section updated 13 March 2024.
The BlueField-3 is a networking platform with integrated software-defined hardware accelerators for networking, storage, and security. Nvidia’s BlueField-3 portfolio includes DPUs and SuperNICs, providing RDMA over ROCE, with both operating at up to 400Gbps and a PCIe gen 5 interface. VAST Data supplies a disaggregated single QLC flash tier, parallel, scale-out, file-based storage system and has built up layers of software sitting on top of this: data catalog, global namespace, database, and coming data engine, all with an AI focus.
Jeff Denworth, co-founder at VAST Data, talked about the news in AI factory architecture terms, saying in a statement: “This new architecture is the perfect showcase to express the parallelism of the VAST Data Platform. With NVIDIA BlueField-3 DPUs, we can now realize the full potential of our vision for disaggregated data centers that we’ve been working toward since the company was founded.”
The existing VAST storage controller nodes (C-nodes) are x86 servers. The controller software has been ported to the 16 Armv8.2+ A78 Hercules cores on the BlueField-3 card, and this new VAST architecture is being tested and deployed first at CoreWeave, the GPU-as-a-service cloud farm supplier.
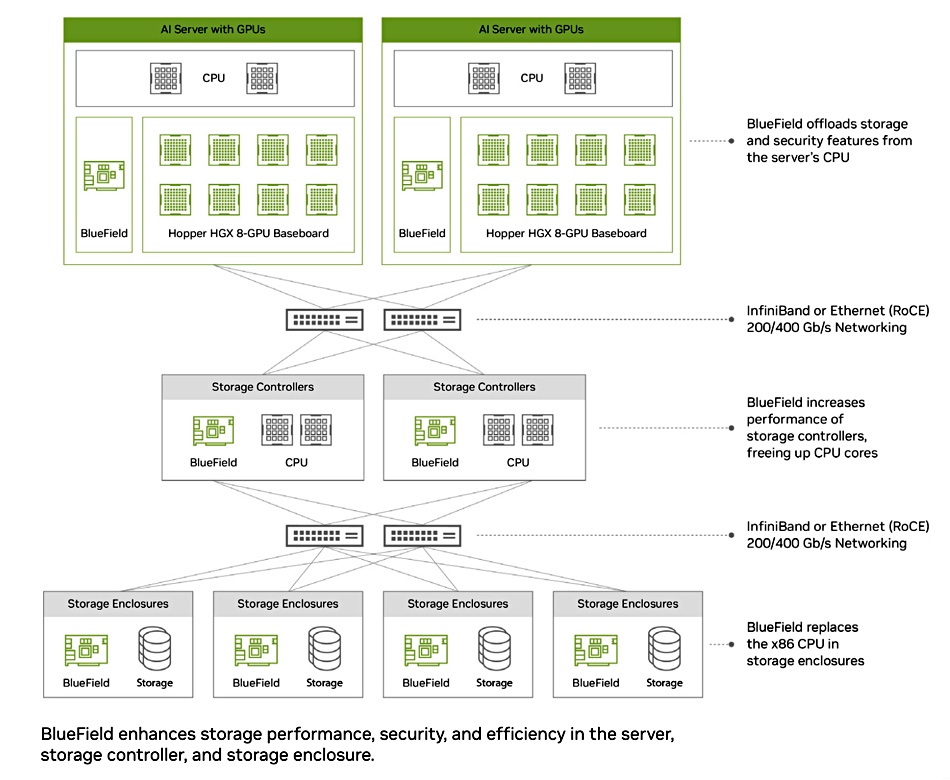
VAST highlights four aspects of its BlueField-3 (BF3) controller adoption:
- Fewer independent compute and networking resources, reducing the power usage and data center footprint for VAST infrastructure by 70 percent and a net energy consumption saving of over 5 percent compared to deploying NVIDIA-powered supercomputers (GPU servers) with the previous VAST distributed data services infrastructure.
- Eliminating contention for data services infrastructure by giving each GPU server a dedicated and parallel storage and database container. Each BlueField-3 can read and write into the shared namespaces of the VAST Data system without coordinating IO across containers.
- Enhanced security as data and data management remain protected and isolated from host operating systems.
- Providing block storage services natively to host operating systems – combining with VAST’s file, object, and database services.
This fourth point is a BlueField-3 SNAP feature, providing elastic block storage via NVMe and VirtIO-blk. Neeloy Bhattacharyya, Director, AI/HPC Solutions Engineering at VAST Data, told us this is not a VAST-only feature: ” It is on any GPU server with BF3 in it, with no OS limitation or limitation of the platform that the BF3 is connected to. The block device is presented from the BF3, so it can be used to make the GPU server stateless.”
We asked is VAST now delivering block storage services generally to host systems? Bhattacharyya replied: ”Not yet, that will be available later this year.”
VAST has Ceres storage nodes (D-nodes) with BF1 and we asked if the block protocol will include them: “Yes, the block device is presented on the BF3, so the hardware the CNode function is talking to on the backend does not matter.”
We also asked if this is effectively an update on the original Ceres-BlueField 1 announcement in March 2022. He said: “No, this announcement is the logic function (aka CNode) running on a BF3 hosted in a GPU-based server. This means VAST now has an end-to-end BlueField solution (between the BF3 in the GPU server and currently BF1 in the DBox). By hosting the CNode on the BF3, each GPU server has dedicated resources to access storage which provides security, removes contention between GPU servers and simplifies scaling.”
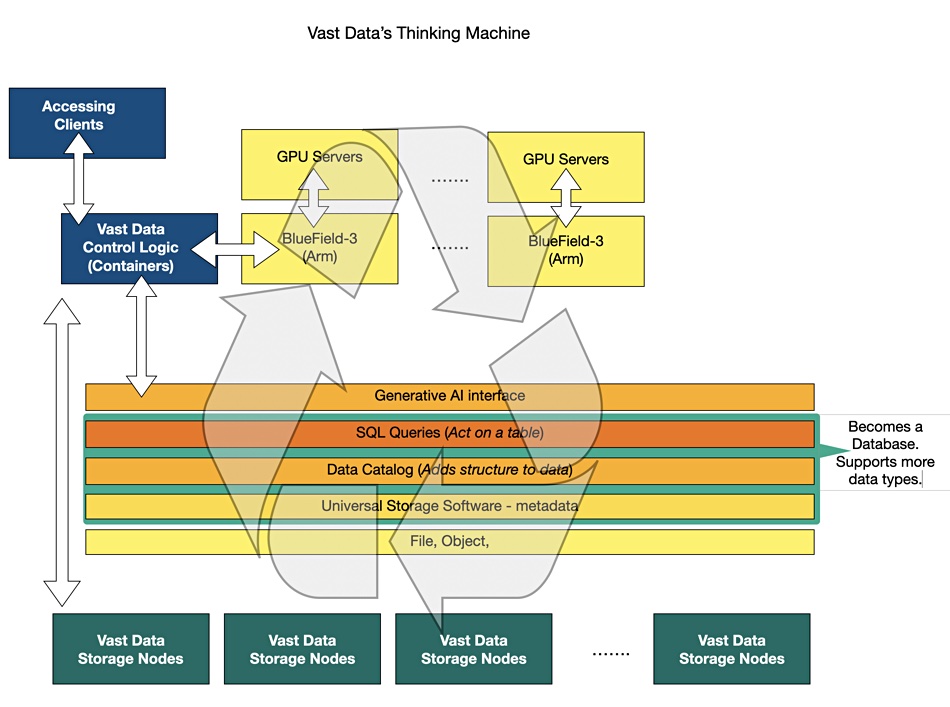
Back in May last year we interpreted VAST’s Thinking Machine’s vision in a diagram (see above), and Bhattacharyya told us us: “this is the realization of that vision.”
Peter Salanki, VP of Engineering at CoreWeave, said: “VAST’s revolutionary architecture is a game-changer for CoreWeave, enabling us to fully disaggregate our data centers. We’re seamlessly integrating VAST’s advanced software directly into our GPU clusters.”
The performance angle is interesting. As no x86 servers are involved in the data path on the VAST side there is no need for the x86 server host CPU-bypassing GPUDirect. Denworth told B&F: “Performance-wise, the introduction of VAST’s SW on BlueField processors does not change our DBox numbers, these are orthogonal. We currently get 6.5 GBps of bandwidth from a BlueField-3 running in a host. The aggregate is what matters… some hosts have one BF-3, others have 2 for this purpose – which results in up to 13 GBps per host. Large clusters have 1,000 of machines with GPUs in them. So, we’re essentially talking about being able to deliver up to 13 TBps per every 1,000 clients.”
Supermicro and EBox
VAST Data is also partnering Supermicro to deliver a full-stack, hyperscale, end-to-end AI system, certified by Nvidia, for service providers, hyperscale tech companies and large, data-centric enterprises. Customers can now buy a fully-optimized VAST Data Platform AI system stack built on industry-standard servers directly from Supermicro or select distribution channels.
There is a second VAST-Supermicro offering which is an alternative to the BlueField-3 configuration and aimed at exabyte scale deployments. A LinkedIn post by VAST staffer John Mao, VP Global Business Development, said the company has developed an ” ‘EBox’, whereby a single standard (non-HA) server node is qualified to run both VAST “CNode” software containers and VAST “DNode” containers as microservices installed on the same machine.”
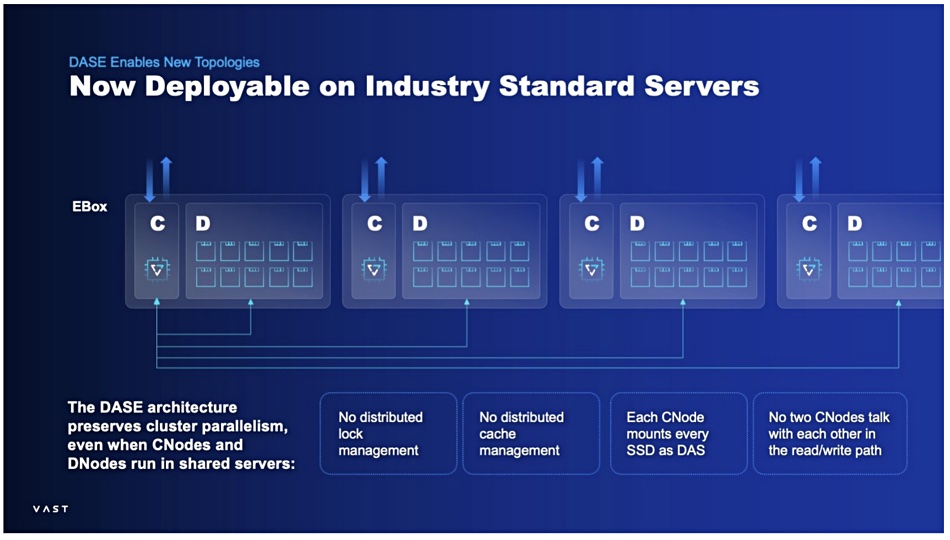
“While from a physical appearance this offering may look like many other software-defined storage solutions in the market, it’s critically important to understand that the DASE software architecture remains 100 percent intact, to preserve true cluster wide data and performance parallelism (ie. no distributed lock or cache management required, every CNode container still mounts every SSD to appear as local disks, and CNode containers never communicate with each other in the read/write data path.)”
The term EBox refers to an exabyte-scale system. Mao says that, at this scale, “failure domains shift from server-level to rack-level, homogeneity of systems become critical in order to optimize their hardware supply chain, and better overall utilization of data center rack space and power.”
Write speed increase
Denworth has written a blog, “We’ve Got The Write Stuff… Baby”, about VAST increasing its system’s write speed as the increasing scale of AI training processing means a greater need for checkpointing at intervals during a job. The idea is it would safeguard against re-running the whole job if an infrastructure component fails. We saw a copy of the blog before it went live, and Denworth says: “Large AI supercomputers are starting to shift the balance of read/write I/O and we at VAST want to evolve with these evolutions. Today, we’re announcing two new software advancements that will serve to make every VAST cluster even faster for write-intensive operations.”
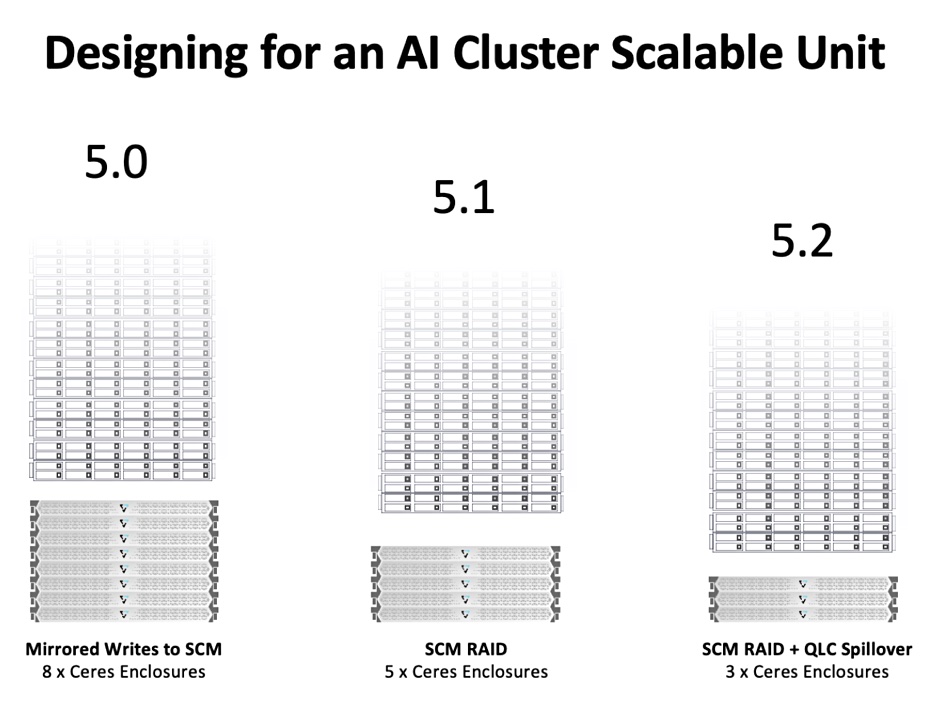
They are SCM RAID and Spillover. Regarding Storage-Class Memory (SCM) RAID, Denworth writes: “To date, all writes into a VAST system have been mirrored into storage class memory devices (SCM). Mirroring data is not as performance-efficient as using erasure codes. … Starting in 5.1 (available in April, 2024), we’re proud to announce that the write path will now be accelerated by RAIDing data as it flows into the system’s write buffer. This simple software update will introduce a performance increase of 50 performance.”
Currently write buffers in a VAST system are the SCM drives with their fixed capacity, which can be less than the capacity needed for a checkpointed AI job. So: “Later this summer (2024), version 5.2 of VAST OS will support a new mode where large checkpoint writes will spillover to also write directly into QLC flash. This method intelligently detects when the system is frequently being written to and allows large, transient writes to spillover into QLC flash.”
All-in-all these two changes will help reduce the VAST hardware needed for AI training: “When considering how we configure these systems for large AI computers, write-intensive configurations will see a 62 percent reduction in required hardware within 6 months time. … If we take our performance sizing for NVIDIA DGX SuperPOD as a benchmark, our write flow optimizations dramatically reduce the amount of hardware needed for a single Scalable Unit (SU).”
VAST Data will be exhibiting at NVIDIA GTC at Booth #1424.





