


Analysis NetApp is one of the first of the major incumbent storage vendors to respond to VAST Data’s parallel NFS-based data access for AI work, with its internal ONTAP Data Platform for AI development, after HPE rolled out its AI-focused Nvidia partnership in March.
VAST Data has penetrated the enterprise data storage market with its DASE (Disaggregated Shared Everything) architecture, which provides a single tier of storage with stateless controllers driving low-latency, high-bandwidth, all-flash storage across an internal RDMA-type fabric with metadata stored in storage-class memory type drives. The company pitches its AI-focused software stack built on this base as providing costs that are close to that of disk, parallel access, and a single namespace used by a data catalog and unstructured data store plus a structured database, IO-event triggered data engine, and now an InsightEngine using Nvidia GPUs as compute node units and embedded NIM microservices.
VAST’s platform and products are being presented at its Cosmos marketing event. Until now, none of the enterprise storage incumbents – with the exception of HPE, which announced the AI-focused Nvidia partnership earlier this year – has responded to the tech other than to adopt lower-cost QLC (4 bits/cell) flash technology. HPE developed its Alletra MP hardware architecture and runs VAST’s file software on that with its own block storage offering separately available. Quantum’s Myriad OS development shares many of these concepts as well.
Now NetApp has just announced its own disaggregated compute/storage architecture development at its Insight event and a white paper, ONTAP – pioneering data management in the era of Deep Learning, fleshes out some details of this ONTAP Data Platform for AI project.
Currently, NetApp has three ONTAP storage hardware/software architectures:
- FAS – clustered, dual-controller base Fabric-Attached Storage for unified files and blocks on hybrid disk and SSD drives
- AFF – all-flash FAS with SSD drives only
- ASA – all-flash SAN Array, AFF with block storage optimizations
Now a fourth ONTAP Data Platform for AI architecture is being developed, with NetApp saying it’s “a new design center in NetApp ONTAP built on the tenets of disaggregation and composable architecture.”
It’s a ground-up concept, starting with separate compute controllers, running ONTAP instances, “embellished with additional metadata and data services,” and storage nodes filled with NVMe SSDs, forming a single storage pool, accessed across a high-speed, low-latency, Ethernet-based RDMA fabric. Both compute units and storage nodes can be scaled out with dynamic workload balancing.
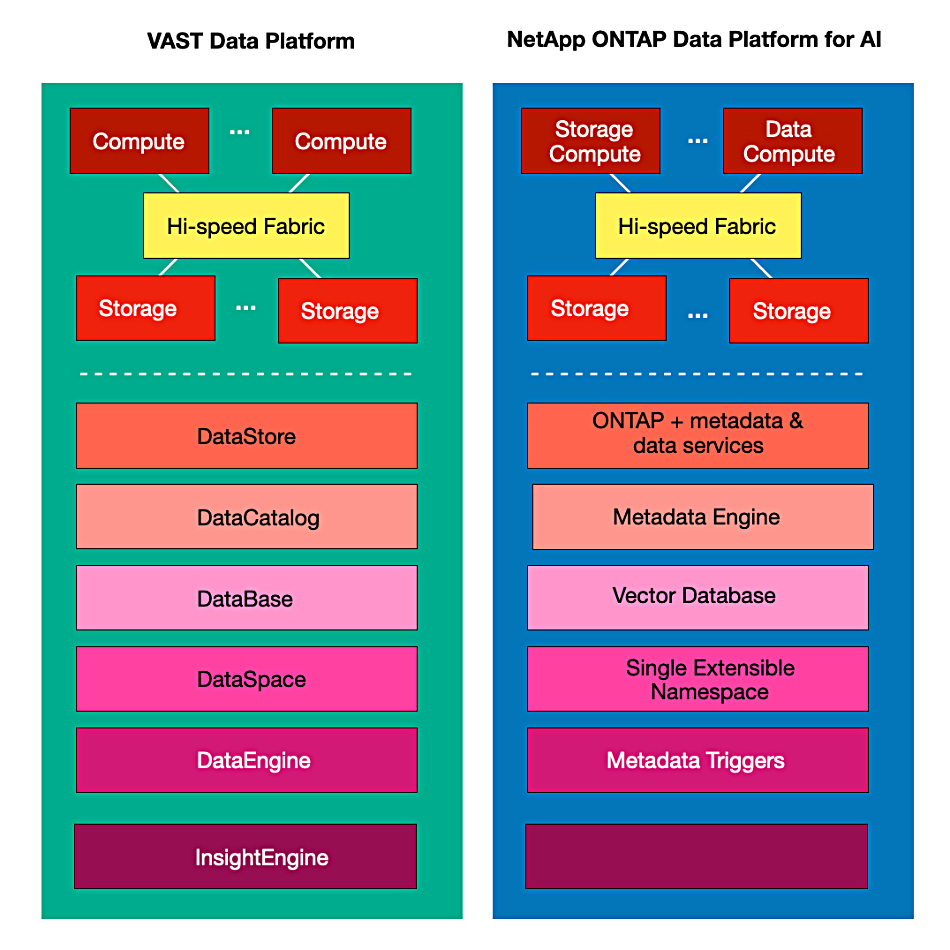
The system supports file, block, and object storage with underlying Write Anywhere File Layout (WAFL) storage and a single namespace. “Physical block space is now distributed across multiple [drive] enclosures, thus creating a single extensible namespace” and “each compute unit or node running the ONTAP OS has full view of and can directly communicate with the storage units providing the capacity.”
The ONTAP instances provide data protection (snaps, clones, replication, anti-ransomware), storage management (speeds, feeds, protocols, resiliency, scale), and intelligent data functions (exploration, insights, getting data AI-ready).
File locking can disrupt parallel access. NetApp is developing “the concept of independently consistent micro file system instances. Each micro file system instance operates as a fully functional file system and provides consistency across data and metadata operations … Since each micro file system instance has exclusive ownership of its resources at a given point in time, they can operate safely on file system internal data structures in parallel to other instances.”
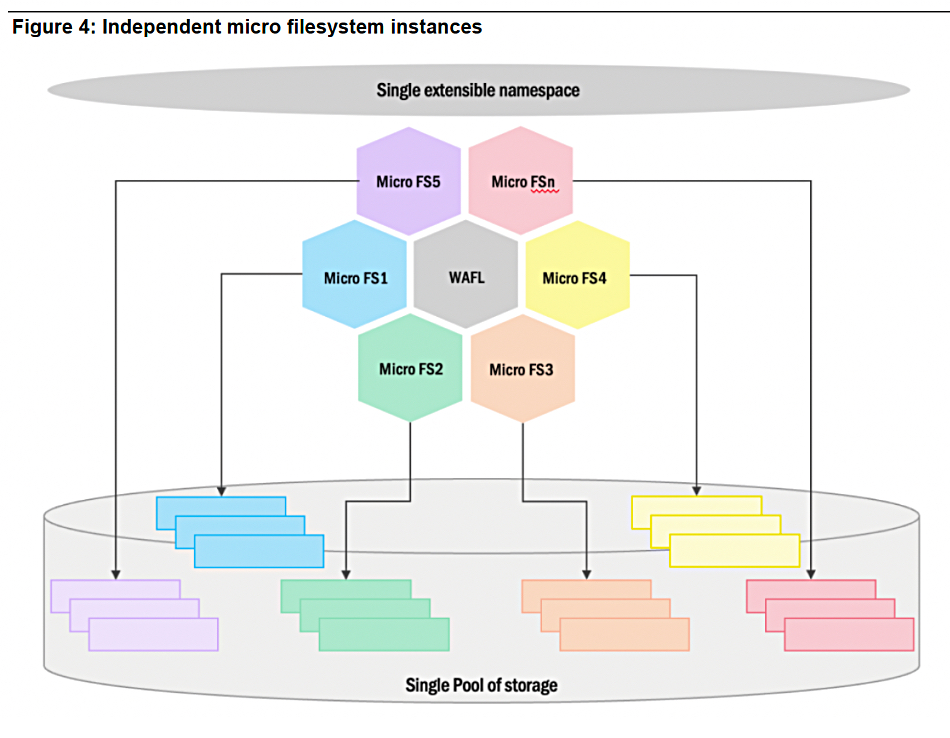
NetApp says “these micro file system instances are decoupled from the front end or application facing constructs. As an example, a file system client mounting file shares and performing data and metadata operations has no visibility to which micro file system instance is processing the request. The client will communicate with the file server as per semantics prescribed during mount.”
The design achieves parallelism at three levels:
- Client and server-side protocol stack
- File system namespace and object management subsystem
- File system block layer managing on-disk layout
The white paper says the “WAFL on-disk layout will ensure that each individual file or a collection of files within a file share will have their data blocks distributed across multiple disk enclosures to drive massive parallelism and concurrency of access. Each instance of the ONTAP OS will have high bandwidth connectivity across the backend disk enclosures and can leverage RDMA constructs to maximize performance as well as ensure quality of service end to end.”
Metadata engine
A structured metadata engine “extracts the data attributes (or metadata) inline. Once the attributes are extracted, the metadata engine indexes and stores this metadata to enable fast lookups. A query interface allows applications to query for this metadata. The query interface is extensible to enable semantic searches on the data if exact key words are not known.”
It provides “a fast index and search capability through the metadata set. AI software ecosystems deployed for data labeling, classification, feature extraction or even a RAG framework deployed for generative AI inferencing use cases can significantly speed up time-to-value of their data by leveraging the structured view of unstructured data presented by the metadata engine.”
The data in the system is made ready for AI as ”NetApp’s powerful SnapDiff API will track incremental changes to data in the most efficient manner. The metadata engine in ONTAP will record these changes and leverage its trigger functionality to initiate downstream operations for data classification, chunking and embedding creation. Specialized algorithms within ONTAP will generate highly compressible vector embeddings that significantly reduces both the on-disk and in-memory footprint of the vector database (significantly shrinking infrastructure cost). A novel in-memory re-ranking algorithm during retrieval ensures high precision semantic searches.”
The generated embeddings are stored in an integrated vector database backed by ONTAP volumes.
Looking ahead
NetApp’s ONTAP Data Platform for AI project validates VAST’s architectural approach and raises a question for the other enterprise storage incumbent suppliers. If NetApp sees a need to spend deeply on a new ONTAP data architecture, what does that mean for Dell, Hitachi Vantara, IBM, and Pure Storage? Do they have their product design engineers poring over VAST and working out how they could develop competing technology on PowerStore or Power Scale, VSP One, FlashSystem, and FlashArray/FlashBlade base architecture systems?
Secondly, with VAST, HPE, and NetApp providing, or soon to provide, parallel NFS-based data access for AI work, where does that leave previously HPC-focused parallel file system suppliers looking to sell their storage into enterprises for AI workloads? We’re thinking DDN (Lustre), IBM (StorageScale), Quobyte, and VDURA (PanFS). Is there some kind of middle ground where a parallel file system meets disaggregated architecture?
Answers to these questions will likely emerge in 2025, when we might also expect a VAST IPO.





