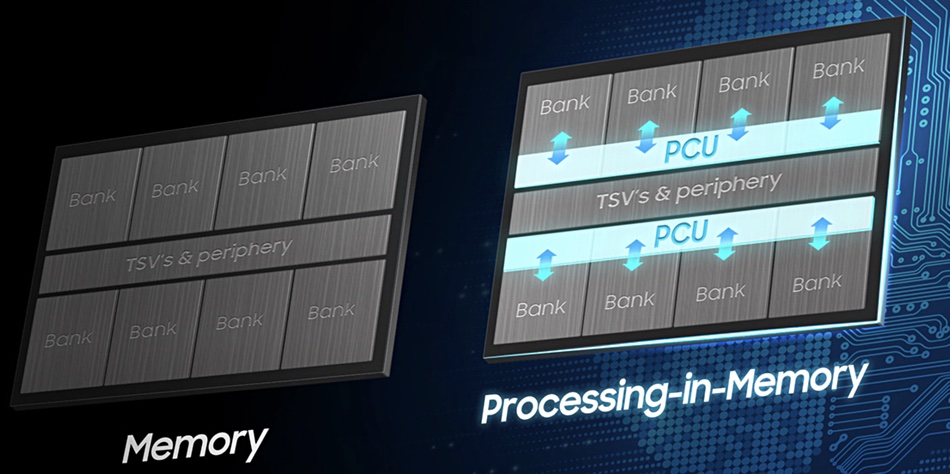
Samsung has announced a high bandwidth memory (HBM) chip with embedded AI that is designed to accelerate compute performance for high performance computing and large data centres.
The AI technology is called PIM – short for ‘processing-in-memory’. Samsung’s HBM-PIM design delivers faster AI data processing, as data does not have to move to the main CPU for processing. According to the company, no general system hardware or software changes are required to use the technology.
Samsung Electronics SVP Kwangil Park said in a statement: “Our… HBM-PIM is the industry’s first programmable PIM solution tailored for diverse AI-driven workloads such as HPC, training and inference. We plan to build upon this breakthrough by further collaborating with AI solution providers for even more advanced PIM-powered applications.”
A number of AI system partners such as Argonne National Laboratory are testing Samsung’s HBM-PIM inside AI accelerators, and validations are expected to complete by July.
Rick Stevens, Argonne Associate Laboratory Director, said in prepared remarks: “HBM-PIM design has demonstrated impressive performance and power gains on important classes of AI applications, so we look forward to working [with Samsung] to evaluate its performance on additional problems of interest to Argonne National Laboratory.”
Samsung HBVM-PIM graphic.
High Bandwidth Memory
Generally, today’s servers have DDR4 memory channels that connect memory DIMMs to a processor. This connection may be a bottleneck in memory-intensive processing. High bandwidth memory is designed to avoid that bottleneck.
High Bandwidth Memory involves layering memory dies in a stack above a logic die, and connecting the stack+die to a CPU or GPU through an ‘interposer’. This is different from a classic von Neumann architecture setup, which separates memory and the CPU. So how does this difference translate into performance?
Let’s compare DDR4 DIMM with Samsung’s Aquabolt 8GB HBM2, launched in 2018, which incorporates eight stacked 8Gbit HBM2 dies. DDR4 DIMM capacity is 256GB and the data rate is up to 50GB/sec. The Aquabolt 8GB HBM provides 307.2GB/sec bandwidth – six times faster than DDR4 – and 2.4Gbit/s pin speed.
Samsung’s new HBM-PIM is faster again. This design embeds a programmable computing unit (PCU) inside each memory bank. This is a “DRAM-optimised AI engine that forms a storage sub-unit, enabling parallel processing and minimising data movement”. The engine performs half-precision binary floating point computations and the memory die loses some capacity due to each bank having an embedded PCU. This takes up space on the die.
An Aquabolt design incorporating HBM-PIM tech delivers more than twice HBM2 performance for image classification, translation and speech recognition, while reducing energy consumption by more than 70 per cent. (There are several HBM technology generations: HBM1, HBM2, which comes in versions 1 and 2, and also HBM2 Extended (HBM2E.)
A Samsung paper on the chip, “A 20nm 6GB Function-In-Memory DRAM, Based on HBM2 with a 1.2TFLOPS Programmable Computing Unit Using Bank-Level Parallelism, for Machine Learning Applications,” will be presented at the February 13-22 virtual International Solid-State Circuits Conference.
VAST Data was cash flow-positive “going out of 2020” and finished the fourth quarter on a $150m run rate. The high-end all-flash array startup’s revenues in FY2021 ended Jan 31 were 3.5 times higher than FY 2020 and it has not spent any of the $100m raised in its April 2020 funding round.
Startups use ‘momentum releases’ as a PR tool to encourage new customers to jump aboard a bandwagon without actually revealing the bandwagon size. Blocks & Files pores over these momentum announcements in an attempt to understand the size of the iceberg below the surface but typically they are bereft of useful information. However, VAST has been a bit more forthcoming than most.
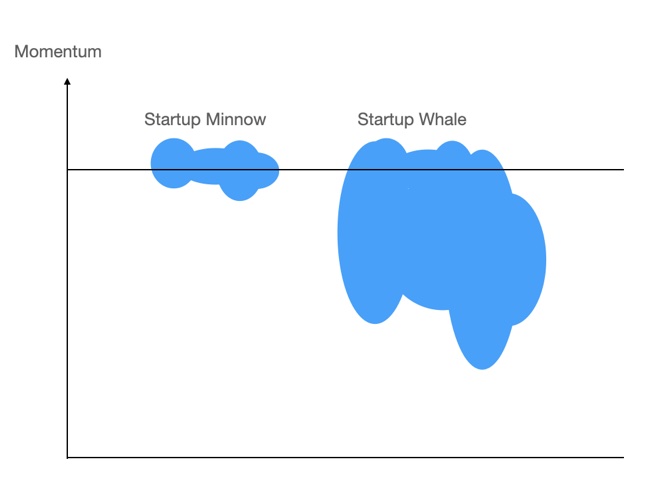
Is VAST a minnow or a whale?
In its press briefing, VAST teased some clues about the size of its business underneath the surface. One concerned the size of customer orders.
Denworth said VAST has just achieved its third $10m-spend account – a customer in the defence sector. He said the company has dozens of $1m customers and is “getting first orders of $5m from customers.”
VAST won its first $10m deal from a hedge fund in December 2019. The customer now has 30PB of VAST storage. The second $10m customer is a large US government agency in the bioinformatics and health sector.
A second clue relates to VAST’s headcount. At the end of fy2021 it was 186. VAST said it is averaging a nearly $1m run rate per employee, which is a tad over-enthusiastic with a $150m run rate. The company wants to hire 200 people in 2021, with Peter Gadd, VP International, aiming to hire 30 to 50 outside North America. He is focusing on Europe and Asia.
A third clue is that VAST compares itself to Pure Storage, saying it has fewer employees than Pure and is growing faster. Denworth characterises Pure as selling medium and small enterprise deals that are susceptible to migration to the public cloud. VAST’s on-premises business deals are more sustainable as they involve larger volumes of data that are difficult to move to the cloud, he claimed.
VAST background and direction
VAST markets its Universal Storage Array as a consolidator of all enterprise storage tiers onto its single scale-out, QLC flash-based platform.The system relies on its software, NVMe-over-Fabrics, Optane SSDs, metadata management and data reduction features to provide high-speed and enterprise disk drive array affordability.
Denworth revealed VAST plans a gen 3 hardware refresh later in the year. He said the company has a single data centre product – we press briefing participants detected hints of smaller VAST arrays coming, cross-data centre metro/geo technology, and some kind of future compute/application processing in the arrays.
VAST Data marketing VP Daniel Bounds said on the press call that VAST ”is building the next great independent storage company.” In other words, its ambition is to dress itself for IPO as opposed to a trade sale.
Pure Storage is to resell Komprise software technology to replicate files from one FlashArray to another, so providing a level of disaster recovery.
Shawn Hansen, FlashArray GM at Pure Storage, said in a statement today: “Together with Komprise, innovating in robust file replication will extend our market leadership in unified enterprise storage.”
Komprise CEO Kumar Goswami chipped in: “By expanding our strategic partnership with Pure Storage we are now able offer an integrated data replication solution that leverages the performance and efficiency of Pure along with the intelligent data management simplicity and scale of Komprise.”
Komprise’s Intelligent Data Management (IDM) software assesss file-level activity and moves less-accessed files to slower and cheaper storage tiers, including the public cloud. Users retain access from the previous file address. The Pure Storage FlashArray is an all-flash block access array product line. It gained file support in the Purity v6.0 software release in June. At that time it said that near-synchronous replication was coming.
The Komprise IDM suite includes asynchronous replication and this is the basis for the Komprise Asynchronous Replication for FlashArray Files. Capabilities include:
Granular Data Replication at whole file share or directory level and at schedulable times
Multiple FlashArray replications, managed through a single console
API for automating replication.
The destination Flash Array holds a consistent replicated file data copy that is available if disaster strikes the source FlashArray. Komprise Asynchronous Replication is available now.
FlashArray vs FlashBlade replication
Pure’s unified file and object FlashBlade array has its own asynchronous replication software, which arrived with the PurityFB// v3.0 release in May 2020. It is based on snapshot technology, which is also used by Komprise with its FlashArray file replication. The FlashBlade system is positioned as a higher performance and more scalable file system offering than FlashArray Files.
Krishna Subramanian.
Komprise co-founder and COO Krishna Subramanian told us: “Komprise takes snapshots on the Pure FlashArray File, and replicates incrementally after the first copy so only changes are copied on subsequent iterations. The difference is that this is for FlashArray whereas what Pure currently has is for FlashBlade – they are two different architectures.
“Also, the Komprise replication for FlashArray is fully integrated with the Purity OS and supports managed directories and is optimised for Pure’s architecture to maximise parallelism and performance.”
Pure Storage has added disaster recovery and ransomware protection via Purity OS upgrades for the company’s FlashArray systems. Pure has also launched the C40, a new entry-level FlashArray. And it has added SMB support for the FlashBlade line.
Let’s start with Purity 6.1 for FlashArray. New features include SafeMode ransomware protection and immutable snapshots for the block and file access FlashArray line, which comprises //X high-performance tier 1 systems and //C tier 2 arrays.
SafeMode makes the retention periods for snapshots of volumes, Pods, Protection Groups and files are tunable from 24 hours to 30 days. Within that period a snapshot cannot be deleted and its contents are available in seconds to recover data attacked by ransomware.
Ajay Singh
Ajay Singh, Pure’s Chief Product Officer, provided an announcement statement: “We are chipping away at the complexity baked into legacy storage that is simply not designed for the digital age. … [We are] providing a dynamic, cloud-based storage experience that is flexible, on-demand, and delivered as code.”
The Cloud Block Store product (Purity running in AWS) and FlashBlade systems also receive the Safe Mode and immutable snapshot upgrade.
Purity 6.1 for FlashArray
Purity//FA 6.1 adds grouping of FlashArrays using ActiveCluster over Fibre Channel to provide stretched clustering between data centres. This disaster recovery feature is integrated with the Pure1 Cloud Mediator, which removes the need for a third-site witness. It also enables a third recovery site to be added anywhere in the world.
Alex McMullan.
Purity//FA 6.1 introduces host access with NVMe-over-Fabrics using 32Gbit/s Fibre Channel, in addition to the existing NVMe-oF across Ethernet. This can reduce data access latency by up to 50 per cent.
Pure’s International CTO Alex McMullan told Blocks & Files in a briefing that Pure will add gen 7 Fibre Channel -meaning 64Gbit/s speed – when there is customer demand.
The new, lower-cost entry-level FlashArray//C40 incorporates Purity//FA 6.1. The array has a QLC flash capacity range of 247TB to 494TB, positioning it as a more affordable system than the existing //C60, with its 366TB to 1.8PB capacity range. McMullan mentioned a $0.50/GB cost before data reduction.
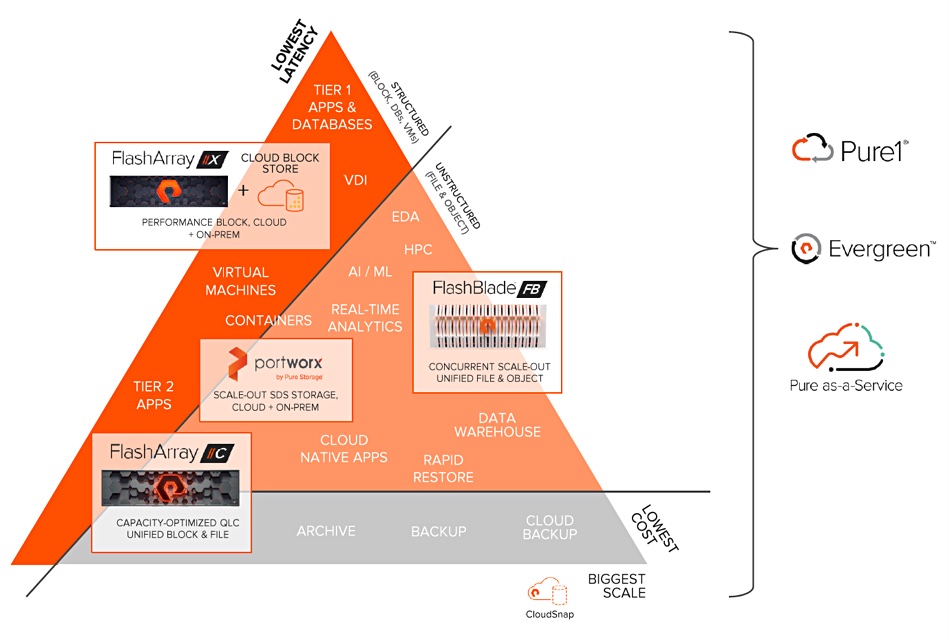
Pure product positioning diagram.
Pure said it has has improved FlashArray//C data reduction efficiency .
FlashBlade functionality improvements
FlashBlade also gets a software upgrade.The file and object all-flash storage combo receives Purity//FB 3.2, added SMB support to the existing NFS. It scales out to all blades in a cluster and accelerates disk array-based Windows applications.
Pure has validated FlashBlade SMB configurations with various healthcare Picture Archiving and Communications Systems. These PACS applications run faster on FlashBlade than on unidentified competing systems. Pure claims SQL Server Backup can run at speeds higher than 1TB/min and 43.78TB/hour on FlashBlade for SQL farms that need fast backup and recovery. That means just over 1PB in 24 hours.
There is access control list interoperability between NFS and SMB users for consistency. Pure has also added:
Cross-protocol file access,
S3 user policies for create/delete/read/write control at the user level,
Monitoring of real-time user activity to prevent runaway jobs,
Sparse files support; files with zeros removed to save space.
Sparse file support reduces licensing cost for third-party data moving applications. It also means VMware virtual disks can be thin-provisioned and Commvault dedupe made more efficient via ‘micro-pruning’.
All these new FlashArray and FlashBlade features, including ActiveCluster, require no additional licenses or support costs, and are included with Pure’s Evergreen subscription. The new features in Purity for FlashArray are available immediately and in Q1 for Purity for FlashBlade.
Pure also announced file replication capabilities on FlashArray with Komprise.
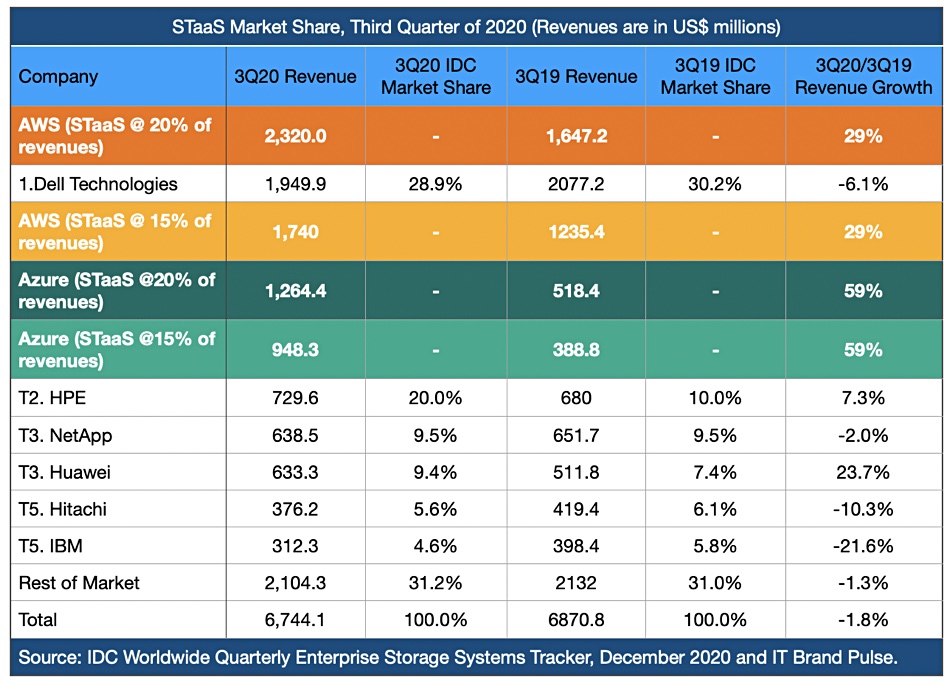
Amazon Web Services is the world’s biggest enterprise storage supplier. Or maybe second biggest, behind Dell. Either way, Microsoft ranks third by revenue share, ahead of NetApp and Huawei.
These are the findings of IT Brand Pulse. To arrive at its conclusions, the tech analyst firm looked first to AWS and Microsoft’s IaaS (infrastructure-as-a-service) revenues – which both companies publish. Then it tested two assumptions – first, that storage revenues comprised 15 per cent of overall IaaS revenues and and second, that they accounted for 20 per cent of the IaaS pot.
IT Brand Pulse dropped those estimates into the mix with IDC’s Worldwide Enterprise Storage Systems Tracker numbers for the third 2020 quarter. You can see in the table below how the inclusion of AWS and Azure changes the revenue standings.
IT Brand Pulse’s storage leaderboard table with AWS and Azure numbers added to IDC Worldwide Quarterly Enterprise Storage Tracker table, December 2020. There are no market share percentages for AWS and Azure as they were not included in the original IDC table.
Based on IT Brand Pulse’s 20 per cent IaaS share assumption, AWS was top of the storage tree in Q3 with $2.32bn in storage revenues in the third calendar quarter of 2020, ahead of Dell on $1.95bn. Tweak the storage percentage of IaaS revenues to 15 per cent, and Amazon eases into second place, on $1.74bn.
Using the 20 per cent of IaaS assumption, Azure was in third place with $1.26bn revs, ahead of NetApp in fourth place on $638m. Microsoft may soon run in to the law of large numbers, but if it maintains its current 59 per cent growth rate, it could overtake Dell’s storage revenues by the end of 2021. That is a big if. However, only Huawei has a storage revenue growth rate that is close to AWS’s 29 per cent, and it is less than half the Azure STaaS growth rate.
If IT Brand Pulse’s working assumption – that storage comprises 20 per cent of IaaS revenues is correct – the combined AWS+Azure storage revenues of $4bn translates into overall market share of 37.6 per cent in Q3 2020. We also note that cloud giants Google, Alibaba and Tencent deliver enterprise storage services – albeit they are a long way behind AWS and Azure.
The trend lines are clear. On-premises storage vendors today represent not much more than half of the overall enterprise storage services, by revenue share, This share will likely shrink further.
Interview: Delphix, the data virtualization, vendor now describes itself as the industry leader in “programmable data infrastructure”. So we asked Jedidiah Yueh, founder and CEO, what that term actually means. Here is his reply.
Blocks & Files: What is the overall definition of a programmable data infrastructure?
Jedidiah Yueh
Jedidiah Yueh: Today, it’s easy to get an automated build of an application environment with code, compute, storage, etc. But how do you get the right data into the environment?
Code, servers, storage, compute, and networks have all been automated and can be managed via APIs. Data is the last automation frontier.
Programmable data infrastructure (PDI) enables data to be automated and managed via APIs.
PDI sources data from all apps across the multi-cloud, including SaaS, private, and public clouds. It ensures data compliance with regulations like GDPR and CCPA by masking personally identifiable or sensitive information.
PDI enables mission critical application use cases, including cloud adoption, CI/CD, and AI/ML model training and deployment.
Blocks & Files: What is the purpose of a data infrastructure?
Jedidiah Yueh: Tech giants are masters of data management and infrastructure. Today, data is a strategic battleground for all businesses.
Data is critical for digital transformation – cloud adoption, accelerating application releases, and training AI/ML models.
Data infrastructure is what enables these objectives, accelerating digital transformation and increasing the ability to compete in the modern world.
With the Delphix API-first data platform, enterprises can adopt cloud 30% faster, release software 50% faster, and access 90% more data for AI/ML, while protecting data privacy and maintaining compliance with GDPR, CCPA, HIPAA, etc.
Blocks & Files: What is the difference between a programmable data infrastructure and data management?
Jedidiah Yueh: You can manage data manually without automated data infrastructure. But it takes a really long time, and the data is often filled with compliance and security risk.
Digital transformation programs are starved for data and environments. When you delay the data you need in application environments, you hemorrhage developer productivity and overrun project timelines and budgets.
Programmable data infrastructure ends the wait for data and ensures data security and compliance.
Blocks & Files: A data infrastructure would seem to consist of (a) data and of elements that (b) store it, (c) move it, (d) deliver it to applications in the right format, and (e) manage the data and this infrastructure. What are a, b, c, d, and e for Delphix? I’m looking for named product entities that customers can buy or subscribe to.
Jedidiah Yueh: A, b, c, d, and e are all part of the Delphix Data Platform, which is software that we sell on a subscription basis.
In addition, we sell Compliance Engines, which operate as part of the platform to profile, mask, de-identify, and tokenize data to comply with regulations including GDPR, CCPA, HIPAA, PCI, etc. You can also buy these separately from the platform, but then you lack the version control and delivery capabilities.
Finally, we sell Data Control Tower (DCT), which provides centralized API access and management for data stored across the multi-cloud (SaaS, on prem, or public cloud).
Blocks & Files: A programmable infrastructure must be programmable. How are the elements of such an infrastructure programmable? Would you argue that setting policies amounts to programming? Are API calls used? API calls by what? API calls to what?
Jedidiah Yueh: Setting policies does not amount to programming. You need to be able to make API calls as part of automated workflows, such as a CI/CD pipeline.
In CI/CD, you might have an automated build process that stands up compute, storage, network, and the latest code, but then you need the data.
For programmable data infrastructure, you would make API calls to a Delphix Data Platform Engine or Data Control Tower.
Those calls need to cover a comprehensive set of requirements to be part of a CI/CD build pipeline, including:
Provisioning data to a target application environment (build)
Configuring and starting the database or data store
Profiling data for compliance or security risk
Masking data for compliance
Selecting the specific version of data or time of data (e.g. most recent data)
Rollback, reset, or cleanup of data or the environment (e.g. after test or batch run)
Bookmarking for later retrieval and version control.
API calls can be made by automation servers, including Jenkins, to enable CI/CD pipelines.
Blocks & Files: If a data management product, such as Cohesity or the Google-acquired Actifio, have API interfaces then do they offer a programmable infrastructure? How is Delphix’ offering positioned against data management products (or services) offering API access and hence programmability?
Jedidiah Yueh: No, some backup products may have APIs, but they do not meet several requirements for PDI.
They do not enforce data compliance and masking, which is a foundational requirement in a world of increasing data privacy regulations and security risks.
They do not have comprehensive APIs to enable the application development lifecycle or a CI/CD pipeline (see a subset of our APIs shared above).
They do not meet performance or duty load requirements. For instance, we have customers running millions of CI/CD pipeline runs per month with Delphix. You simply cannot restore data fast enough from backup solutions to satisfy that demand, even via APIs.
Blocks & Files: Does Komprise offer a programmable data infrastructure? If not – why not?
Jedidiah Yueh: Komprise is a tool focused on data tiering and mobility (modern HSM).
It does not meet the data compliance requirement and lacks a comprehensive set of APIs necessary to enable application workflows such as CI/CD, SRE, and AI/ML.
We prefer to leave it to Komprise to determine if they are or are not offering programmable data infrastructure.
Blocks & Files: Does Hammerspace offer a programmable data infrastructure? If not – why not?
Jedidiah Yueh: Hammerspace is a Kubernetes solution focused on data tiering and mobility (Kubernetes HSM and portability).
It lacks support for the world of apps outside of Kubernetes, the compliance requirement, and a comprehensive set of APIs necessary to enable application workflows such as CI/CD, SRE, and AI/ML.
Delphix supports Kubernetes, but also everything from mainframe to cloud-native PaaS apps.
We prefer to leave it to Hammerspace to comment on whether they are or are not offering programmable data infrastructure.
Datera CEO and exec chairman Guy Churchward has resigned, citing health reasons. His colleague chief Product Officer Narasimha Valiveti – known as ‘VNR’ – has left the company to join Oracle.
Guy Churchward
Churchward told us: “I watched how the pandemic has really impacting our industry (not the marketing fluff) and felt it was a natural time to move on for my own personal health and well being.”
He suffered two heart attacks in May 2019 during surgery to insert three stents into his arteries. He is looking at a few opportunities but is taking time out, for now.
Valiveti has joined Oracle as its VP Storage at the Oracle Cloud Infrastructure business unit. Churchward said: “He got pursued for a cracking opportunity and I am totally thrilled for him as it’s well deserved and Oracle have done well there.”
Churchward revealed: “VNR and I had a spit handshake agreement to see our tour of duty through the 2020 fiscal.” Datera has been enjoying continued growth; “Key metrics for success were again all up and to the right so I feel good about that.”
Datera’s President and Chief Revenue Officer Flavio Santoni tells us: “Guy had a prior agreement with the board to step back at the end of 2020. Our lead investor stepped in as interim CEO to work through the next few moves.” Santoni did not say who that was.
The lead investor is Khosla Ventures and Brian Byun, a venture partner at Khosla, may be the interim CEO. He has been identified as a Datera board member by Crunchbase and ZoomInfo.
Datera provides high-end scale-out virtual SAN storage software which tiers data across a range of media from Optane to disk drives. It supports physical, virtual and containerised hosts and is supplied to customers through deals with semi-OEM HPE and OEM Fujitsu and other channel partners. Datera’s Data Services Platform software also supports the S3 object access protocol.
Datera was founded in 2013 and the company has taken in $63.9m in funding, including a $26m C-round in September 2018. Board member Guy Churchward was appointed CEO in December 2018, replacing co-founder Marc Fleishmann who is now the CTO in VMware’s Cloud Platform business unit.
Interview File system software suppliers such as Nasuni and WekaIO have built-in backup facilities. They say their customers do not need a separate backup product or service and therefore can save money.
We asked W. Curtis Preston, Chief Technical Evangelist at Druva and a published backup expert, what he thinks about this approach.
Blocks & Files: Nasuni and WekaIO say their filesystem software includes built-in back up and therefore customers do not need a separate backup product or service. Is this a valid position to take or does it create just another backup silo?
W.Curtis Preston
W. Curtis Preston: For what it’s worth, I actually cover this topic in my upcoming book, Modern Data Protection, which should be published this summer by O’Reilly & Associates. The question for me is whether or not they comply w/the “3-2-1” rule of at least three versions on two media, one of which is somewhere else. They can easily comply with the “3” and the “1” of the 3-2-1 rule; I wonder about the “2.” While they can make sure multiple versions are stored in multiple places, all versions are controlled by the same codebase. The concern is that a rolling disaster or creeping bug damages all copies of the data. This can happen and has happened throughout computing history; this is why we back up.
Another thought is to entrust data protection to a company who does it 24×7 and has it as a core competency, versus a company that does it as a side job. It’s unclear, for example, whether or not they have put all the same protections in place that someone specializing in data protection would do. There is precedent of vendors who didn’t fully understand basic backup and recovery concepts building such features with glaring feature omissions.
Blocks & Files: In that sense they are self-protecting filesystems. Is this a sensible approach?
W. Curtis Preston: The term “self-protecting” has always concerned me. While I applaud native data protection features that make the backup and DR systems a truly last resort, I get concerned when a vendor says their product is so good it doesn’t need backup of any kind.
Blocks & Files: Is this a new idea? Has it been tried before and, if so, how did it turn out?
W. Curtis Preston: I have heard the “we don’t need backup” mantra many times: RAID, NAS, object, SaaS. Every other time, the claim turned out to be false for some customers. Something went wrong with the setup or the software, and the next thing you know, all your data is gone and there is no backup. A perfect example is the deletion of the private Microsoft Teams messages of 146,000 employees of KPMG in a single mouse-click. Microsoft 365 is another vendor whose proponents often tout their native data protection features.
Blocks & Files: Is NetApp’s ONTAP a self-protecting filesystem with its various snapshot-based features? Ditto Qumulo Core and Isilon’s OneFS?
W. Curtis Preston: In one word, yes. They are the previous iteration of the same concept.
Blocks & Files: Aren’t customers moving to backup systems that provide multi-application backup to a single backup repository? Won’t a self-protecting filesystem work against this idea? For example, a customer with WekaIO and a bunch of applications and systems protected by Druva will find the WekaIO backup is not integrated with the Druva backup (Or Cohesity or Rubrik or Veeam or whatever?)
W. Curtis Preston: Customers have always sought a centralised backup system; that’s nothing new. And yes, this would be a separate protection system not managed by said centralised backup system. These vendors would probably argue that is a good thing, as it probably reduces your TCO and operational complexity.
Data protection has always been about reducing risks. Some would argue that the risk reduction you get from decreasing operational complexity outweighs the risks of having a single codebase controlling all your storage. I’d say if your backup system is that complex, perhaps you should consider replacing it with a less complex system, rather than throwing out the baby with the bathwater.
Blocks & Files: Customers are also moving to Data Protection as a service (DPaaS). How would this work with a self-protecting filesystem product/service?
W. Curtis Preston: Any backup system (either traditional or DPaaS) needs an authoritative source to backup. In the case of these latest vendors, backup vendors would either be integrated with a data protection API provided by the vendor, or use a NAS proxy to monitor and back up any files placed on the local filesystem cache before it is synced to any other places.
Blocks & Files: Would the self-protecting file system vendors work better with the data protection industry if they partnered with suppliers?
W. Curtis Preston: I think so, and you saw that eventually happen in the NAS world. First they created NDMP, which gave an official industry-standard API to backup products to back them up. Then individual vendors (e.g. NetApp) also provided specific APIs that now directly integrate with data protection vendors to make it easier to back up data stored on their filers. It’s important to note that this took 10+ years to start happening.
A zettabyte of disk capacity shipped in 2020. A 2U Dell server can have over a petabyte of Nimbus Data flash. And GigaSpaces in-memory apps can use less space and yet go faster. Read on.
A zettabyte of HDD capacity shipped in 2020
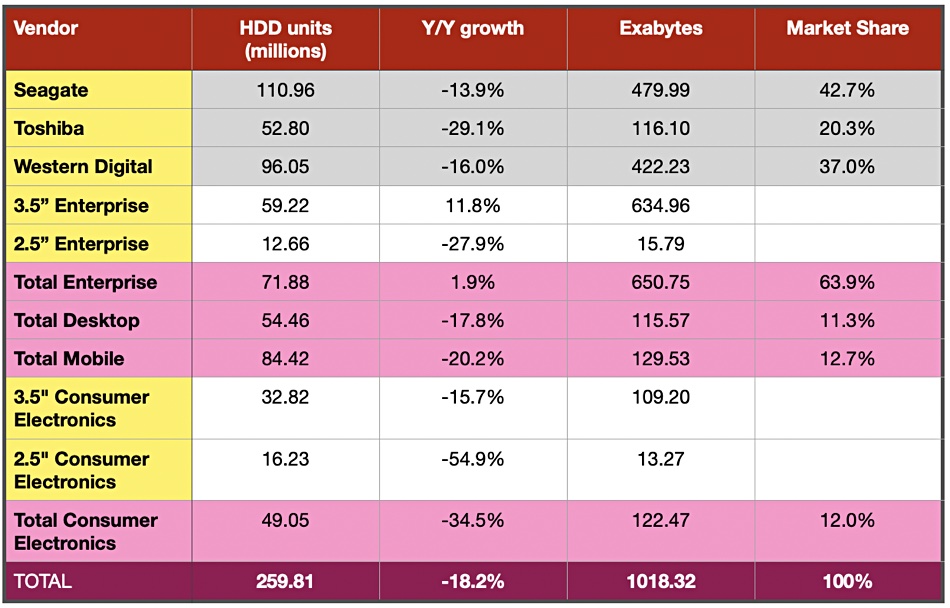
TrendForce research showed demand for storage has fuelled HDD exabytes shipped growth, and a record zettabyte of HDD capacity was shipped in 2020. A zettabyte is 2 to the 70th and equal to 1,000 exabytes, a million petabytes, and a billion terabytes.
TrendForce HDD unit and exabyte ship numbers for 2020
Toshiba America Electronic Components, Inc. was quick off the mark and boasted that it led Seagate and Western Digital in year-on-year nearline HDD average capacity growth in 2020. It followed its 55 per cent year-on-year growth in 2019 with 35 per cent growth in 2020 according to the TrendFocus data.
TrendFocus VP John Chen was quoted in a Toshiba statement: ”Toshiba’s 9-disk helium-sealed HDD platform has enabled the company to achieve the highest five-year compound annual growth fates for nearline HDD Units, Exabytes, and average capacity shipped through 2020.”
GigaSpaces in-memory software gets smaller and faster
GigaSpaces has made in-memory applications faster and more affordable with v15.8 of its InsightEdge Portfolio. This release reduces hardware costs and provides up to 10X faster response time on queries.
It features memory space reduction as the GigaSpaces Ops Manager can automatically reduce an object’s RAM storage footprint by up to 70 per cent.
Yuval Dror, GigaSpaces’ VP for R&D, said in a statement; “The release of InsightEdge Portfolio version 15.8 delivers our best performance results to date for operational and analytical workloads, and higher elasticity to handle expected and unexpected peaks; all while reducing infrastructure and cloud costs.”
Up to 10x faster response time is achieved for SQL queries, reporting and BI by automatically replicating selected small tables of data to the nodes in the cluster to accelerate server-side JOIN performance. A new Broadcast Objects feature replicates smaller static tables that are used frequently when combining rows from two or more tables, for example daily exchange rates.
GigaSpaces Kubernetes Operator supports Kubernetes Helm for day-1 deployment in a cluster and subsequent operations of managing application workloads and auto scaling up or out to support unexpected workloads.
Dell servers get up to 1.2PB of flash in 2RU
Nimbus Data’s ExaDrive SSDs have been certified with Dell EMC PowerEdge servers, enabling up to 1.2PB (petabytes) of flash storage in one 2 rack unit (2U) server.
The ExaDrive range includes the 100TB capable ExaDrive DC series and QLC flash-based ExaDrive NL series.
“The combination of Dell EMC PowerEdge servers and Nimbus Data ExaDrive SSDs enables 5x greater storage capacity per server than nearline enterprise HDDs and 6x greater flash capacity than the closest competing SSDs,” stated Thomas Isakovich, CEO of Nimbus Data.
ExaDrive SSDs have been certified in the following Dell EMC servers and the following maximum capacities may be achieved.
Dell PowerEdge R240: Up to 400 TB of TLC flash or 256 TB of QLC flash
Dell PowerEdge R440: Up to 400 TB of TLC flash or 256 TB of QLC flash
Dell PowerEdge R540: Up to 1,200 TB of TLC flash or 768 TB of QLC flash
Dell PowerEdge R740: Up to 1,200 TB of TLC flash or 768 TB of QLC flash
Dell PowerEdge R7525: Up to 1,200 TB of TLC flash or 768 TB of QLC flash
Shorts
Cloud data repository platform provider RSTOR has teamed up with Arcserve to provide data and ransomware protection. In the near future, RSTOR and Arcserve plan to release cloud-based services to ensure business continuity of applications and data. RSTOR does not charge egress and data access fees.
Commvault has signed up with Skytap, a cloud service provider, to expand data protection and migration for IBM i workloads hosted in Skytap on Microsoft Azure.
Stargate support for DataStax Enterprise (DSE) is now available, enabling users to use REST, GraphQL, and schema-less Document APIs in addition to CQL when building applications on top of DSE.
Kubesafe, a cloud-native data protection company, has announced the general availability of its app-centric Kubernetes backup and business continuity software support for NetApp ONTAP storage systems. This is for applications using ONTAP storage running on Kubernetes, Amazon EKS, and Red Hat OpenShift platform without any changes to their existing infrastructure.
Cloud filesystem supplier Nasuni recorded a record $24.6m in annual contract value bookings in the fourth quarter of 2020 and software subscription revenue for 2020 grew 36 per cent Y/Y. Data under management increased 70 per cent across AWS, Azure and other cloud object storage.
Pavilion Data said it working on a 250PB opportunity with Seagate. It tells us it can be an important part of the overall Federal solution for Seagate, even more so as it GAs its Global File System which will be able to support tiering.
Rewind has acquired BackHub, and its Backup-as-a-Service (BaaS) software for GitHub repositories. BackHub currently protects data for over 1000 customers.
StorCentric last week said it closed 2020 with record growth and ” greater than 35 per cent CAGR achieved over the past several years”. The company claims it has more than 7,000 enterprise customers.
Opus Interactive, a cloud, colocation and IT services company, is using Scality RING and Zenko to deliver services, including data management across multi-cloud infrastructure, backup-as-a-service and more. Most Opus customers are in highly regulated industries with strict data compliance requirements. Scality RING meets this need and gives Opus Interactive the scale and flexibility of S3 object storage and NFS and SMB file access.
Amy Madeiros
Amy Medeiros has been named SVP Corporate Marketing and Inside Sales for DDN and Tintri brands. She will be responsible for strategic and creative marketing and sales initiatives, with a focus on increasing the profitability of channel partners.
The Evaluator Group has hired Dave Raffo as Senior Analyst, HCI and Container Storage. He most recently worked for 13 years at TechTarget as Editorial Director and Executive News Editor for storage, data protection and converged infrastructure.
Analysis: For 17 years, a small California firm called IC Manage quietly toiled away as it built up a business catering to the specialist requirements of integrated circuit (IC) and electronic design automation (EDA) design vendors. For one of its co-founders, Dean Drako, IC Manage was, for many years, just a side gig while he concentrated on running and exiting from another company he founded – Barracuda Networks.
Today, the company thinks that Holodeck, the hybrid cloud data management software it has developed for EDA companies, is equally applicable to other industries where tens of millions of files are involved.
Holodeck provides public cloud P2P file caching of an on-premises NFS filer – and IC Manage says that any on-premises file-based workloads that need to burst to the public cloud can use it. To this end it is working with several businesses, including a major Hollywood film studio, on potential film production, special FX, and post-processing applications.
Let’s take a look at IC Manage Holodeck and see why it might be extensible from semiconductor design companies to the general enterprise market.
For EDA firms, tens of millions of files may be involved in IC circuit simulations run on their on-premises compute server farm. The NFS filer – NetApp or Isilon, for example – could be a bottleneck, slowing down file access at the million-plus file level. IC Manage EVP Shiv Sikand told us he has little respect for NFS file stores: “NFS has terrible latency; it doesn’t scale… I never met a filer I liked.”
Holodeck accelerates file access workloads by caching file data in a peer-to-peer network. The cache uses NVMe SSDs in on-premises data centres. It also builds a similar cache in the public cloud so that on-premises workflows bursts to the cloud. In this scenario, the Holodeck in-cloud cache acts an NFS filer.
The company
IC Manage was founded in 2003 by CEO Dean Drako and Shiv Sikand. The company says it is largely self-funded. Drako founded and ran Barracuda Networks from 2003 to 2012, with an IPO in 2013, and he lists himself as an investor. He has invested in the file metadata acceleration startup InfiniteIO.
Drako also runs Eagle Eye Networks which acts as a video surveillance management facility in the public cloud. Together with Sikand he co-founded Drako Motors which is building the limited edition 4-seat Drako GTE electric supercar. Just 25 will be built and sold for $1.25m apiece.
That means neither Drako nor Sikand are full-time on IC Manage; this is not a classic Silicon Valley startup with hungry young entrepreneurs struggling in a garage. But Sikand shrugs thus off: “Is Elon Musk part-time on Tesla?”
Holodeck on-premises
Shiv Sikand
In a DeepChip forum post in 2018, Sikand said IC Manage’s customers “have 10’s to 100’s of millions of dollars and man-hours invested in on-premise workflows and EDA tools and scripts and methodologies and compute farms” that they know work. They don’t want to interfere with or upset this structure.
The “big chip design workflows,” he wrote, are “typically mega-connected NFS environments, comprised of 10’s of millions of files, easily spanning 100 terabytes.” These can include:
EDA vendor tool binaries – with years of installed trees
100s of foundry PDKs, 3rd party IP, and legacy reference data
Massive chip design databases containing timing, extracted parasitics, fill, etc.
A sea of set-up and run scripts to tie all the data together
A nest of configuration files to define the correct environment for each project.
Sikand told us: “These are 10’s of millions of horrifically intertwined on-premise files.”
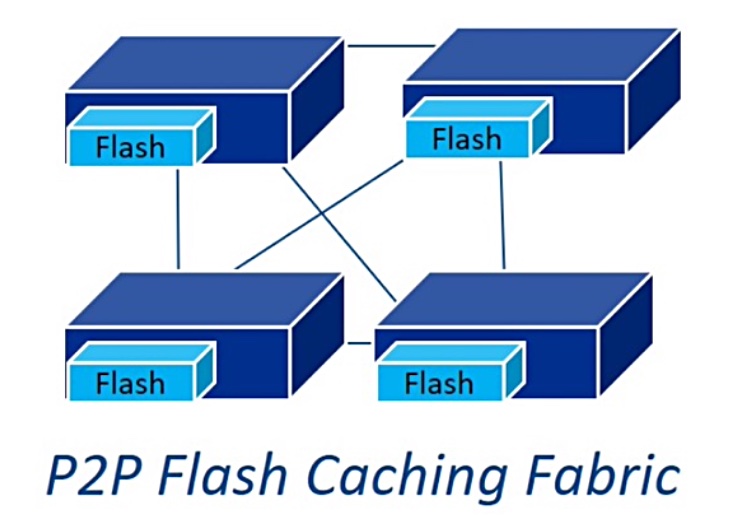
Holodeck speeds file data access partly because it “separates out data from whole files and only transfers extents (sections),” Sikand wrote in his forum post. Holodeck accelerates workloads by building a scale-out peer-to-peer cache using 50GB to 2TB NVMe SSDs per server node. These sit in front of the bottlenecked NFS filer and enable parallel access to file data in the cache. All nodes in the compute grid share the local data – both bare metal and virtual machines. More NVMe flash nodes can be added to scale out performance.
Holodeck peer-to-peer caching fabric
According to IC Manage, this ensures consistent low latency and high bandwidth parallel performance, and it can expand to thousands of nodes.
The P2 cache can be set up on a remote site – and it can also be set up in the public cloud, using a Holodeck gateway to support compute workload bursting.
Sikand told us people criticise the P2P approach on the grounds that “no-one else is doing this. You must be wrong.” His response to the critics – who “not the sharpest knives in the box” – is that this works for semiconductor design and manufacturing shops.
Holodeck in the public cloud
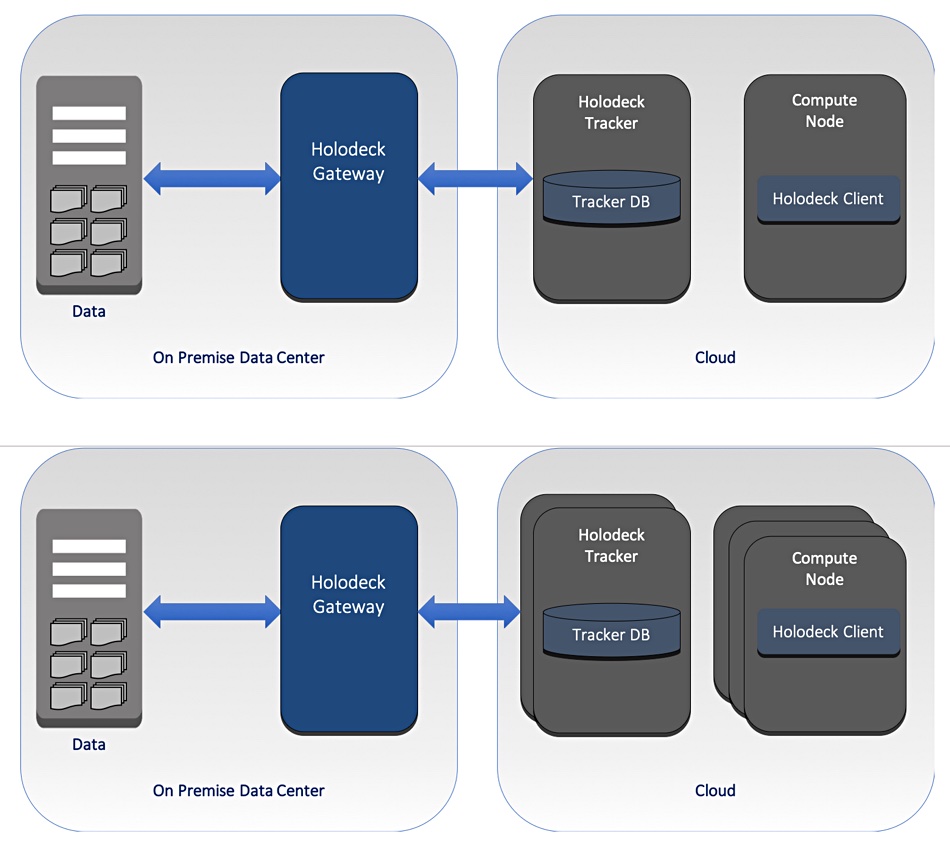
The P2P cache approach is used in the public cloud but Holodeck is using it on-premises. The Holodeck software sets up a cloud Gateway system to take NFS filer information and send it to a database system, called ‘Tracker’. Public cloud peer nodes in the P2P facility use Tracker, and compute instances – called Holodeck clients – access these peer nodes. The compute instances and the peer nodes both scale out.
Holodeck and the hybrid cloud
The Tracker database can be provisioned on block storage; the peer nodes use only small amounts of temporary storage using high performance NVMe devices, such as AWS i3 instances.
The Holodeck Client compute nodes access the P2P cache as if it were an NFS filer and job workflows execute in the cloud exactly as they do on premises. Holodeck’s peer-to-peer sharing model allows any node to read or write data generated on any other node. This sharing model has the same semantics as NFS, and so ensures full compatibility with all the on-premises workflows.
The good thing here is the on-premises file data is never stored outside the caches in the public cloud. There is no second copy of all the on-premises files in the clouds, which reduces costs. Any Tracker database changes made as a result of the cloud compute jobs are tracked by Holodeck and only these changes are sent back on-premises, meaning that cloud egress charges are low.
Holodeck supports selective writeback control to prevent users from inadvertently pushing unnecessary public cloud data back across the wires to the on-premises base.
Data coherency between the peer nodes is maintained using the RAFT distributed consensus protocol, which can withstand node failures. Basically, if a majority of the peer nodes do the same thing such as update a file metadata value, then that is the single version of the truth and a failed node can be worked around.
Competition
Panzura’s Freedom Cloud NAS offering runs on-premises and in the public clouds. This enables file transfer between distributed EDA systems to accomplish remote site access to another site’s files. It uses compression and deduplication to reduce file transfer data amounts.
Nasuni also provides a NAS in the cloud with on-premises access.
As soon as an EDA customer has a scale-out file system which supports flash drives, such as one from Qumulo or WekaIO, the need for Holodeck on-premises is reduced. If that file system runs in the public cloud the need for Holodeck hybrid cloud reduces further.
However, Holodeck’s return of only updated data from the cloud (delta changes) minimises cloud egress charges, and that could be valuable. Sikand has this to say about WekaIO: “WekaIO is blindingly fast but it makes your nose bleed when you pay the bill.”
Data protector Veeam said yesterday annual recurring revenues grew 22 per cent in 2020 and it has more than 400,000 customers under its belt, including 82 per cent of the Fortune 500 and 69 per cent of the Global 2000. The company said 2020 was the second consecutive year that annual bookings surpassed $1bn.
Veeam reported 250 per cent growth in large-deal transactions, with the large deal threshold being $1m.
The company reported 73 per cent growth for Veeam Backup for Microsoft Office 365, its fastest growing product for the past two years in terms of product growth/adoption.
It also noted Veeam Backup & Replication 10 has been downloaded more than more than 650,000 times since its release in February 2020.
Veeam said its technology alliance resell agreements with HPE, Cisco, NetApp, and Lenovo grew 16 per cent Y/Y.
All-in-all, the Veeam revenue growth machine continues racing along, which must be cheery news for Insight Venture Partners. It bought Veeam for $5bn a year ago.
IBM executive Arvind Krishna. 5/30/19 Photo by John O’Boyle
LucidLink is to offer a bundled version of Filespaces based on IBM Cloud Object Store.
LucidLink says the bundle can cost less than standard prices from AWS, Azure and other S3-compatible object stores. Peter Thompson, LucidLink CEO, said in a statement: “Now, with IBM Cloud, we will be able to further offer egress fees 60 per cent lower than our previous offering to a wider audience and pass those saving directly along to our customers.”
Adam Kocoloski, IBM Fellow, VP and CTO, Cloud Data Services, said: “As companies adjust to a new way of working, the ability to securely share and access large amounts of data remotely while taking advantage of object storage in a cloud environment has become indispensable.“
The IBM COS LucidLink bundle is designed for applications that require fast file-protocol access to massive datasets. These are stored most cost-effectively as object repositories rather than in more expensive NAS filer systems. However object stores are slower to access than filers – unless they are front-ended with LucidLink’s Filespaces or an equivalent software.
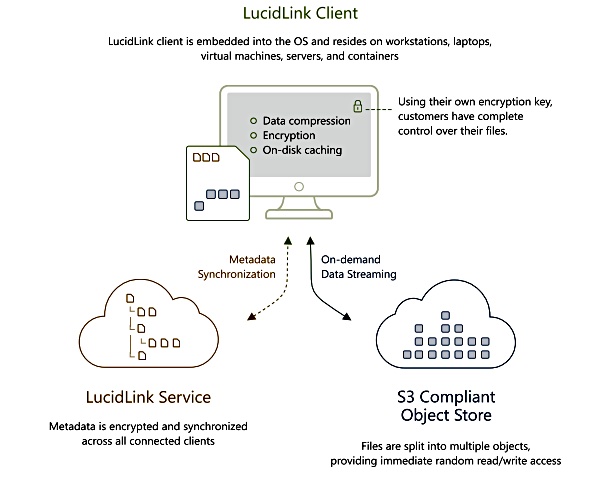
LucidLink schematic diagram.
Filespaces runs directly on each endpoint, caching the working data set for each user. The LucidLink client provides file system access while natively using S3 object protocols. All the file metadata is held in the local node so file:folder lookups do not incur network hop latencies.
User file sharing is supported. Julie O’Grady, LucidLink’s marketing director, told us. “Filespaces … enables teams to collaborate on the same file, no matter where they are located.”
All access to the object store is carried out using parallel links to speed file reads and writes. All file reads result in partial file transmission with pre-fetching of data that is likely to be needed next. File writes are packaged by the Filespaces cache node, and then compressed, encrypted and multiplexed across parallel links to the back-end object store. The net effect of the caching, local metadata look-up and pre-fetching is that remote object access can be as fast as local filer access.
In May 2019 IBM had a partnership with file collaborator Panzura to provide a Freedom Cloud file access front-end to its object store. The focus was on file sharing. Today’s LucidLink-IBM partnership has a focus on file access speed.
IBM is supporting access to all its US data centres together with its UK and Australian data centres. The bundle does not support on-premises IBM COS deployments.
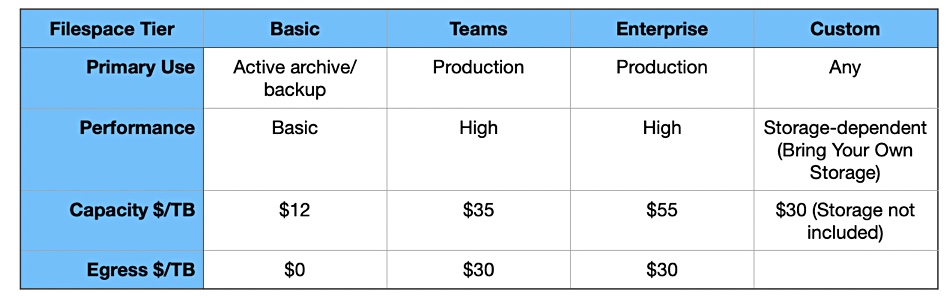
LucidLink Filespaces pricing. IBM COS is the storage for the Teams and Enterprise categories.
The IBM COS/Filespaces bundle is available now from LucidLink. Users are charged per account at $10.00/user month, starting at 6 users. It will provide users access to all IBM’s worldwide regions