

VAST Data wants to direct an extinction event for hard drives.
This is a bold ambition but VAST Data is a remarkable startup, certainly in the scope of its claims and use of new technology. Without QLC flash, 3D XPoint, NVMe over fabrics, data reduction, metadata management, its product simply would not exist.
The company has accumulated $80m in funding through two VC rounds and officially launches its technology today. But it is already shipping product on the quiet and says customers are cutting multi-million dollar checks for petabytes of storage. Existing customers include Ginkgo Bioworks, General Dynamics Information Technology and Zebra Medical Vision.
It also claims it has earned more revenue in first 90 days of general availability than any company in IT infrastructure history, including Cohesity, Data Domain, and Rubrik combined.
So what is the fuss all about?
VAST opportunities
This may sound unreal: VAST Data has found a way to collapse all storage tiers onto one with decoupled compute nodes using NVMe-oF to access 2U databoxes filled with QLC flash data drives and Optane XPoint metadata and write-staging drives, with up to 2PB or more of capacity after data reduction.
How do VAST’s claims stack up? They seem plausible but it is, of course, early days. Our subsidiary articles look at the various elements of VAST Data’s story: click on the links below.
- VAST data reduction
- VAST decoupling compute and storage
- VAST striping and data protection
- VAST universal file system
- VAST Data’s business structure and situation
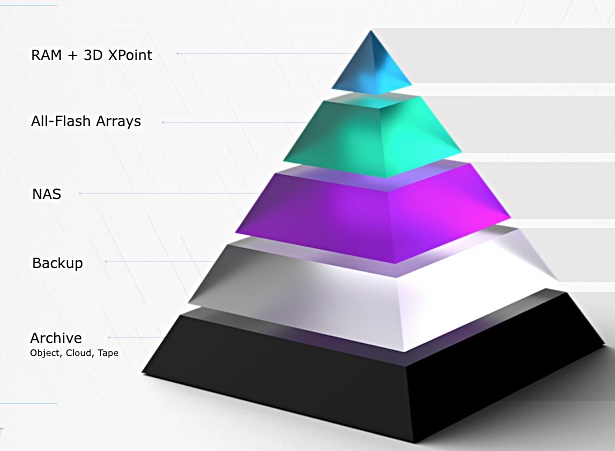
Let’s try it from another angle. VAST Data has created an exabyte-capable, single tier, flash-based capacity store that can cover performance to archive-level data storage needs at a cost similar to or lower than hard disk drives. This equates to about $0.03/GB instead of a dual-port NVMe enterprise SSDs at $0.60/GB.
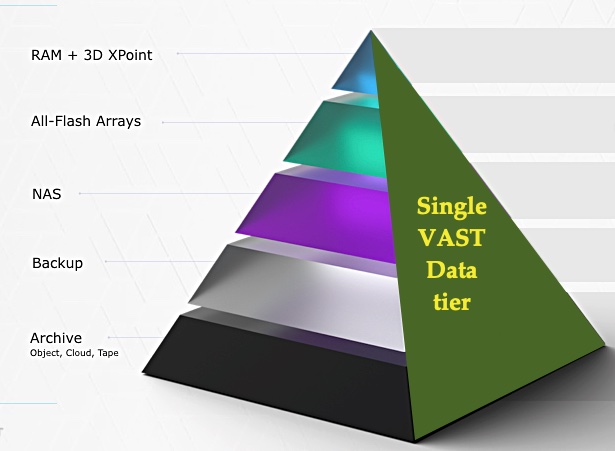
At its heart the technology depends upon a new form of data reduction to turn 600TB of raw flash and 18TB of Optane SSD into up to 2PB or more of effective capacity. Without this reduction technology the exabyte scaling doesn’t happen
In addition, extremely wide data stripes provide for global erasure coding and fast drive recovery.
There is a shared-everything architecture embodied in separate and independently scalable compute nodes in a loosely-coupled cluster running Universal Filesystem logic. These link across an NVMe link to databoxes (DBOX3 storage nodes) which are dumb boxes filled with flash drives for data and Optane XPoint for metadata.

The flash drives have extraordinary endurance – 10 years – because of VAST’s ability to reduce the number of writes; the opposite of write amplification.
The pitch is that VAST’s data reduction and minimised write amplification enables effective flash pricing at capacity disk drive levels with performance at NVMe SSD levels for all your data; performance, nearline, analytics, AI machine learning, and archive.
Benefits
- With a flat, single-tier, self-protecting data stricture there s no need for separate data protection measures.
- There is no need for data management services for secondary, unstructured data.
- There is no need for a separate archival disk storage infrastructure.
- There is no no need to tier data between fast and small device and slow, cheap and deep devices.
- There is no need to buy, operate, power, cool, manage, support and house such devices.
- With a single huge data store with NVMe access and, effectively, parallel access to the data, then analytics can be run without any need for a separate distributed Hadoop server infrastructure.





