


Analysis: LucidLink announced its Filespaces cloud file service product provides on-premises applications with instant access to large data sets over long distances, without consuming local storage.
That got Blocks & Files attention; instant access to TBs and PBs of data over long distances? No local storage? How?
The announcement release said Filespaces works with any OS, and any cloud or on-premises object storage. Its cloud-native product sits on top of S3 object storage and reduces the traffic between applications and its remote storage.
George Dochev, LuciudLink co-founder and CTO, said: “By seamlessly transforming any S3 storage into just another tier of local storage, LucidLink allows organisations to leverage the cloud economics for high-capacity data workloads.”
LucidLink says there is no need to download all the data and synchronise it as file sync-and-sharing applications do. Because it streams data on demand to a requesting site applications can read or write portions of large files without the need to download or upload them in their entirety.
LucidLink claim concerns
On-premises applications mount the remote storage as if it were a local disk and only the portion of the data currently being used is streamed across the network. Filespaces “mitigates the effects of latency when using cloud storage as primary storage.”
Mitigating the effect of latency could mean something different from “instant access.”
The point about not “consuming local storage” is not quite true as Filespaces utilises the local storage on each device to cache the most frequently accessed data. Why bother doing this unless there is a time penalty when accessing remote data in the cloud?
Blocks & Files checked out how this technology works.
LucidLink Technology
There are three Filespaces technology components;
- Client SW,
- Metadata service, known as the hub,
- Object store.
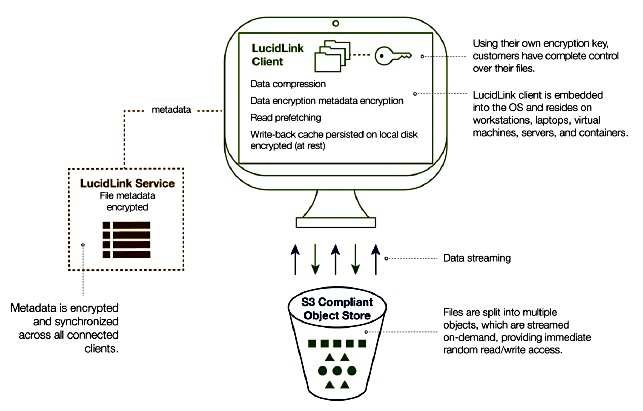
SW on each client device is integrated with the local OS to present a file system mount point that seems to be a local device. This software talks to the metadata service and the object store back-end via a LucidLink protocol. It does not use the standard NFS or SMB protocols.
The metadata service is replicated across all nodes so that access is local and not remote. LucidLink says: “overall system responsiveness increases significantly when all metadata related operations are serviced locally.“
This means that Filespaces accelerates access to metadata to achieve the same end as InfinteIO; save the network links for data traffic and don’t fill them up with chatty metadata traffic.
The metadata service is a distributed key:value store, stored separately from the object store, and delivers file system metadata – (file system hierarchy, file, and folder names, attributes, permissions etc.,) to all client nodes. Metadata is continuously synced between client devices.
The object store contains file data which is compressed and encrypted on client devices before being uplinked to the object repository. This inline compression reduces the amount of data sent up the links to the object store. There is no deduplication.
As a file is written to the object store it is split up into equal-size pieces which are each written as separate objects and manipulated as atomic entities. The segment size is a configurable parameter at file system initialisation time.
When a client device requests file access, data is streamed down to it, first being decrypted and verified.
LucidLink says performance is enhanced through the metadata synchronisation, local on-disk caching, intelligent pre-fetching and multiple, parallel IO streams.
Multiple parallel streaming
Dochev told us: “When the user reads from a file, for instance, we prefetch simultaneously multiple parts of the file by performing GETs on multiple segments using the already opened connections. When writing, we again upload multiple objects simultaneously across these multiple connections.”
This is reminiscent of Bridgeworks’ parallel TCP streaming technology.
“Multiple parallel IO streams mean that we open multiple HTTPs connections (64 by default) to the object store and then perform GET/PUT requests in parallel across these multiple connections. Conceptually we talk about one object store, but in reality, these multiple connections likely end up connecting to different servers/load balancers comprising the cloud provider infrastructure. In the case of a local on-premise object store, they might be different nodes forming a cluster.”
Prefetching
Prefetching involves fetching more blocks than requested by the application so that future reads can hopefully be satisfied immediately from the cache without waiting for data to come from the remote object store.
LucidLink’s software checks for two types of IO; reads within the same file and within the same directory. It identifies and analyses multiple streams to improve the prefetch accuracy. When an application issues multiple streams of sequential or semi-sequential reads within the same file or multiple files in the same directory, each stream will trigger prefetching.
The aim is to eliminates cache misses, and LucidLink will incorporate machine learning in the future to improve prefetching accuracy.
Write-back caching
Filespaces also uses persistent write-back caching as well as prefetching, to improve write performance.
Application write requests are acknowledged as soon as the data is written to the local disk cache. These cached writes are pushed asynchronously and in parallel to the object store. As each block is uploaded, the metadata is updated so all other Filespaces clients can see the file store state as soon as the data is available to them.
Multiple writes to the same file might be cached before being uploaded, reducing network traffic.
Cache size can vary from a few GBs on smaller devices like laptops all the way to multiple TBs on servers. It expands on demand up to a predefined and configurable limit. Once the cache fills up with data to be written, the system can slow down, as all new writes get processed at the speed at which old ones are flushed to the cloud.
On top of this
Filespaces is based on a log-structured design. A filespace can be snapshotted and preserved at any point in time. Using the snapshot, individual files or the entire file space can be recovered to an earlier point in time. A snapshot copies incremental changes since a previous snapshot was taken and not the full data set.
Admin staff can control which parts of a filespace are accessible by individual users and the design supports global file locking and zero-copy file clones.
Future advancements will deliver multi-cloud capabilities in the form of striping, tiering, and replication across multiple S3 buckets. Replication to multiple regions or providers offers a higher degree of durability, and reduces the distance (time) to data by allowing each node to access its closest location.
Net:net
Can LucdLink’s Filespaces product deliver cloud economics, object store scalability and local file store performance?
The proof of its usability will be defend upon the caching size, the prefetch ability, the multiple parallel IO streaming, the write back caching flush speed, and the metadata synchronisation. As a Filespaces systems grows in size all these things will be tested.
The basic design looks comprehensive and a proof of concept would seem to be a good idea for interested potential customers.





