The El Capitan exascale supercomputer will use HPE-designed ‘Rabbit’ near node local storage to get data faster to its many processing cores from a backend SAN.
The $600m 2 exaFLOPs El Capitan will be housed at the US Lawrence Livermore National Laboratories and is slated for delivery by HPE and its Cray unit by early 2023.
The number of compute nodes in El Capitan has not been revealed. However, in a prior 1.5 exaflops El Capitan iteration, the compute blades would form a line 10,800 feet long if laid end-to-end. If each blade is three-feet long that adds up to 3,600 blades.
Hence El Capitan will have several thousand compute blades and it would be impractical to have all of these connect directly to the SAN. Instead the Rabbit nodes function as SAN gateways or access concentrators. Without the Rabbit nodes the SAN would be overwhelmed.
The supercomputer incorporates AMD Epyc CPUs and Radeon GPUs linked across AMD’s Infinity interconnect fabric with CPU boards, chassis, storage, Slingshot networks and software organised under Cray’s EX architecture.

Bronis de Supinksi, Lawrence Livermore Computing CTO, revealed in a presentation at the Riken-CCS International Symposium last week (reported by HPCWire), that the Rabbit storage boxes are 4U in size and house SSDs controlled by software using an Epyc storage CPU.
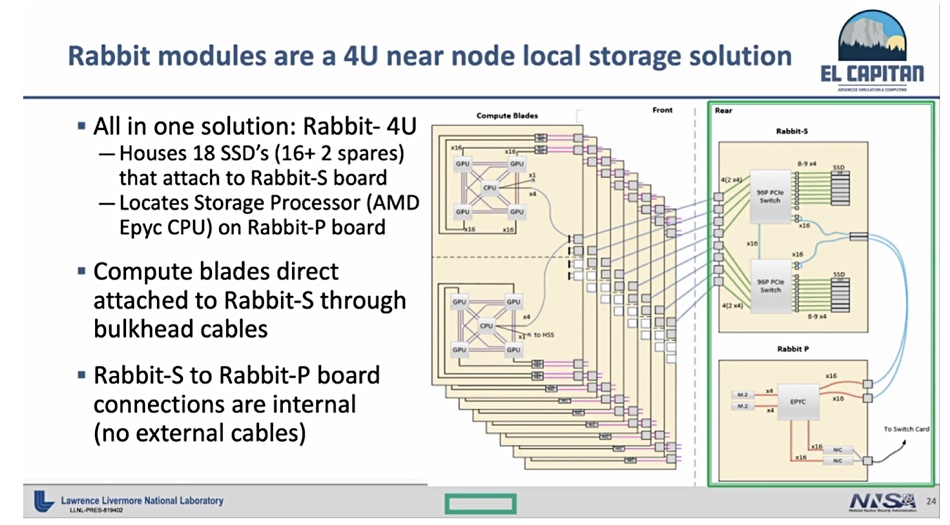
The enclosure has two boards, a Rabbit-S storage board with 16 SSDs plus 2 spares plugged into it. It hooks up to a Rabbit-P processor board which carries the Epyc CPU. The Rabbit-S SSDs connect to eight El Capitan compute blades across PCIe. Each compute blade has two sets of resources, each comprising a Zen 4-based Genoa Epyc CPU and four GPUs, interconnected by AMD’s Infinity Fabric technology, according to a diagram from the Supinski presentation. Thee GPUS and the CPU will share a unified memory structure.
A diagram shows the Rabbit-P processor hooking up to the nearby compute blades and the SAN. It is unclear from the diagram if it connects to other El Capitan components. That means the Rabbit flash can be accessed as direct-attached storage by the PCIe-connected El Capitan compute blades and also as network-attached storage by other parts of the system.
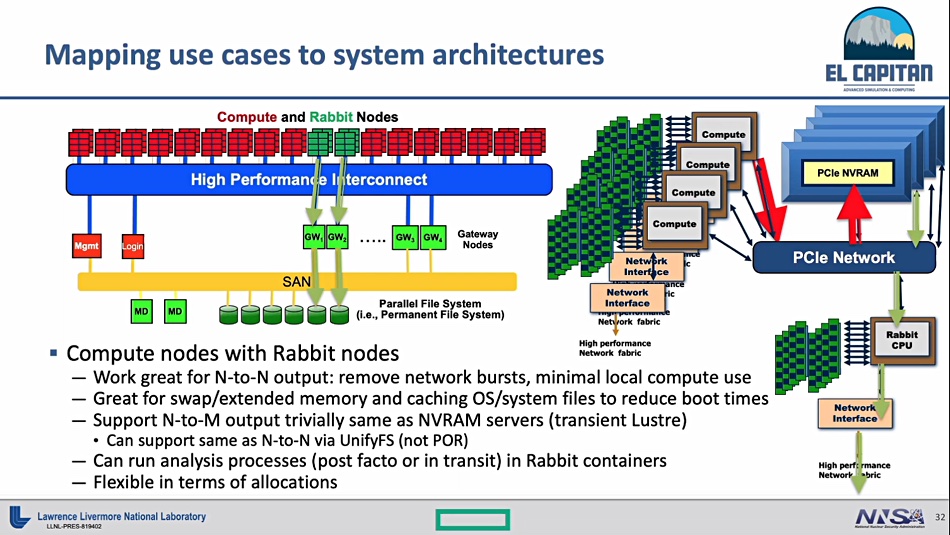
The Rabbit P processor runs containerised software and this can operate on (analyse) the data in the Rabbit-S SSDs. These SSDs cache operating system files and hold extended memory and swap files for the attached compute blades.
The Rabbit flash enclosure plugs into Cray XE racks housing El Capitan switch modules. They connect to an El Capitan SAN via the XE rack switches and gateway nodes. The SAN will be built from Cray ClusterStor E1000Lustre parallel storage systems which combines NVMe-accessed SSDs and disk drives with PCIe Gen 4 access. The E1000 runs up to 1.6 terabytes per second and delivers 50 million IOPS per rack.
Thus we have flash storage locally adjacent to a bunch of El Capitan compute blades, and acting as an all-flash front end to a flash+disk SAN. The SAN does not connect direct to the compute blades. Instead it acts as a backing store.
We might enquire if future exabyte-scale storage repositories will also need gateway/concentrator storage nodes to provide access from thousands of CPU cores. HPE’s Rabbit could be a forerunner of things to come.