


Moving 100TB per car of data a day from test cars to GPU-driven automated driver assistance (ADAS) AI modelling systems needs a multi-stage data pipeline. Seagate, IBM and Nvidia have created one based on using disk drives in the cars, object storage, parallel file system software and GPUs.
Each test vehicle is, in effect, a mobile edge IT site generating around 100TB a day of data from the multiple sensors in the car — such as radar, LiDAR, engine management system, cameras and so forth. This data has to be somehow fed into a data lake, from which it can be extracted and used for AI and machine learning modelling and training. The end result is AI/ML model code which can be used in real life to assist drivers by having vehicles increasingly taking on more of the driving responsibilities.
The problem is that there can be 10, 20 or more test vehicles, each needing to store logged data from multiple devices. Each device can store its own data (a distributed concept) or they can all use a central storage system.
Each method costs money. Seagate calculates that just putting in-vehicle data storage in place can cost up to an eye-watering $200,000 per vehicle. That means a 50-vehicle fleet needs an up to $10 million capital expenditure before you even start thinking about how to move the data.
Centralising the data can be done two ways: move the data across a network or move the data storage drives. Once in the same data centre as the AI training systems the data has to be made available at high speed to keep the GPUs busy.
Networking the data is costly and, unless the automobile manufacturer spends a great deal of money, slow. Consider that a fleet of 20 vehicles could each arrive at the edge depot on a daily basis with 100TB of data. That’s 2PB/day to upload. It’s cheaper and maybe faster to just move the drives containing the data than send the bytes across a network link.
Data pipeline
In summary we have five problem areas in this data pipeline:
- In-vehicle storage;
- Data movement from vehicle to data centre;
- Data centre storage;
- Feeding data fast to GPUs;
- AI training.
Seagate takes care of the first three stages. IBM looks after the fourth stage, and Nvidia is responsible for stage number five.
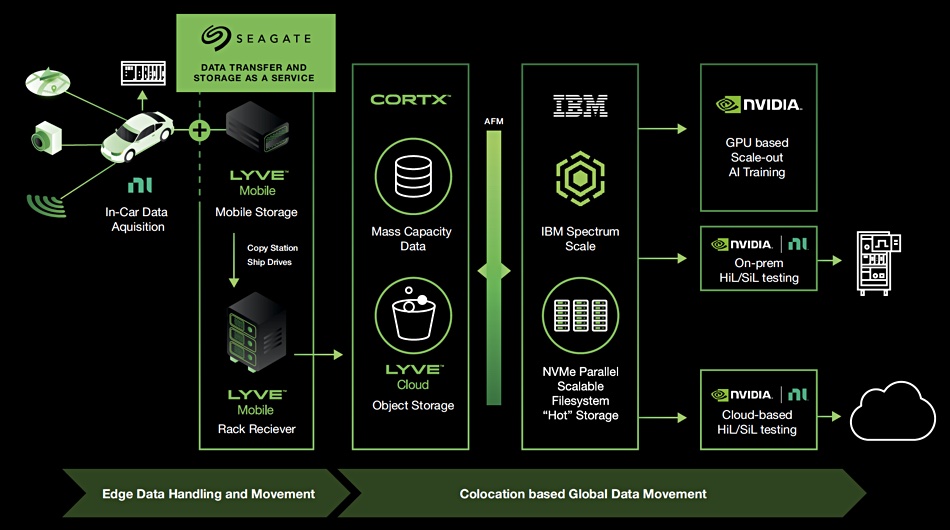
Each test vehicle has a disk drive array in its trunk: a Seagate Lyve Mobile array. These take data streamed from sensors to National Instruments (NI) data loggers and store it centrally. When a test car returns to its depot, drives inside data cartridges can be removed and physically transported to Lyve Mobile Rack Receivers in the AI/ML training data centre.
The Lyve Mobile system can be used on a subscription basis to avoid capital expenditure.
Once arrived at the data centre the data can be stored in Seagate’s CORTX object storage system and also in Seagate’s Lyve Cloud object storage for longer-term retention. At this point IBM steps onto the stage.
Its AFM (Active File Management) software feeds the data from CORTX, a capacity tier, into the Spectrum Scale parallel file system and NVMe flash storage. It’s then in a performance tier of storage, and Spectrum Scale can send data at high speed and with low latency, using RDMA — think GPUDirect, to Nvidia GPUs for the model training.
This Seagate-IBM-Nvidia partnership enables fleets of cars at the mobile edge to generate hundreds of terabytes of test data on a daily basis and have it transported to and stored within a data centre, and then transferred at high speed to GPUs for model training. We have a workable data pipeline for ADAS data generation and model creation.





