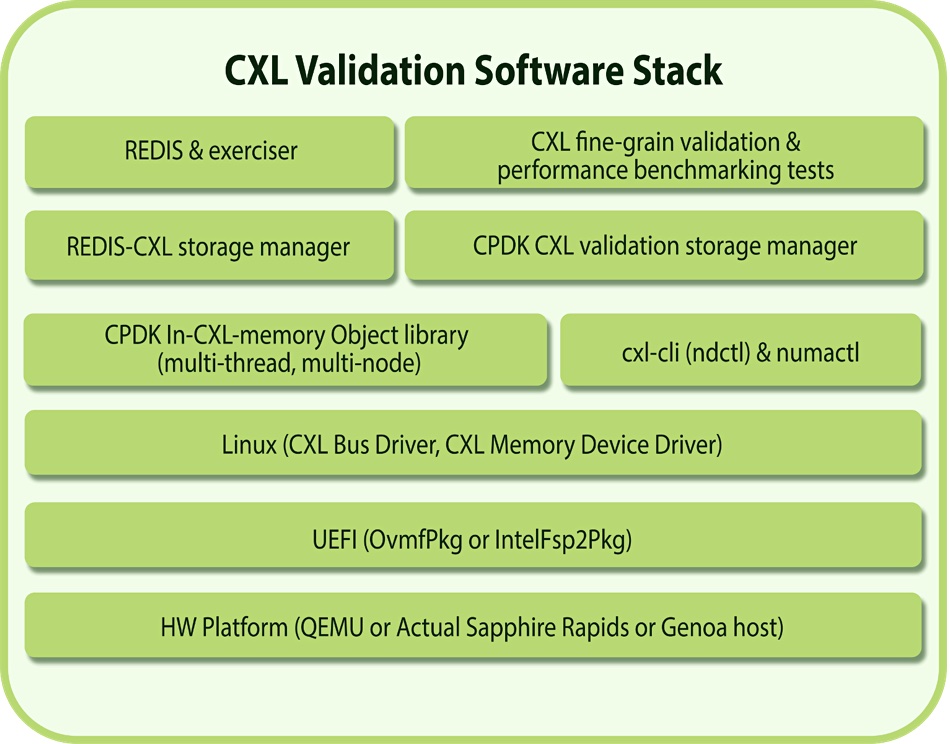
Avery Design Systems has announced a validation suite supporting the Compute Express Link (CXL) industry-standard interconnect. It enables rapid and thorough system interoperability, validation and performance benchmarking of systems targeting the full range of versions of the CXL standard, including 1.1, 2.0 and 3.0. The suite covers both pre-silicon virtual and post-silicon system platforms.
…
Data lake supplier Dremio has rolled out new features in Dremio Cloud and Software. Expanded functionality with Apache Iceberg includes copying data into Apache Iceberg tables, optimizing Apache Iceberg tables and table roll back for Apache Iceberg. Customers can create data lakehouses by performantly loading data into Apache Iceberg tables, and query and federate across more data sources with Dremio Sonar. It is also accelerating its data as code management capabilities with Dremio Arctic – a data lakehouse management service that features a lakehouse catalog and automatic data optimization features to make it easy to manage large volumes of structured and unstructured data on Amazon S3.
…

Hitachi Vantara has appointed Sheila Rohra as its Chief Business Strategy Officer, reporting to CEO Gajen Kandiah and sitting on the company’s exec committee. CBSO is a novel title. Kandiah said: “Sheila has repeatedly demonstrated her ability to identify what’s next and create and execute a transformative strategy with great success. With her industry expertise and technical understanding of the many elements of our business – from infrastructure to cloud, everything as a service (XaaS), and differentiated services offerings – I believe Sheila can help us design a unified corporate strategy that will address emerging customer needs and deliver high-impact outcomes in the future.” Rohra comes from being SVP and GM for HPE’s data infrastructure business focused on providing primary storage with cloud-native data infrastructure and hyperconverged infrastructure to Fortune 500 companies.
…
Huawei has launched several storage products and capabilities at MWC Barcelona. They include a Blu-ray system for low-cost archiving; OceanDisk, “the industry’s first professional storage for diskless architecture with decoupled storage and compute and data reduction coding technologies, reducing space and energy consumption by 40 percent”; Foiur-layer data protection policies with ransomware detection, data anti-tamper, air-gap isolation zone through the air-gap technology, and end-to-end data breach prevention; and a multi-cloud storage solution, which supports intelligent cross-cloud data tiering and a unified cross-cloud data view. OceanDisk refers to two OceanStor Micro 1300 and 1500 2RU chassis holding 25 or 36 NVMe SSDs respectively, with NVMeoF access. We’ve asked for more information about the other items.
…
Data migrator Interlock says it is able to migrate data from any storage (file/block) to any storage, any destination and for any reason. Unlike competitors, Interlock can migrate data from disparate vendors as well as across protocols (NAS to S3). It is able to perform data transformation necessary to translate data formats and structures of one vendor/protocol to another. Interlock says it can extract data from an application if given access to storage. This allows Interlock to migrate data at the storage layer, which is faster than through the application.
Interlock migrates compliance data with auditability and can “migrate” retention from before. Typically, when migrating data across different storage systems, built-in data protections like snapshots are lost. But with Interlock, snapshots, labels, as examples, may be migrated with data. Migrations are complicated by lack of resources such as bandwidth and CPU/memory bottlenecks in the system. Interlock is able to track utilization (when the system is busy etc.) and adjust number of threads accordingly. This also helps reduce required cutover time.
…
Nyriad, which supplies disk drive-based UltraIO storage arrays with GPU controllers, is partnering SI DigitalGlue with its creative.space platform making enterprise storage simple to use and manage. Sean Busby, DigitalGlue’s President, said: “DigitalGlue’s creative.space software coupled with Nyriad’s UltraIO storage system offers high performance, unbeatable data protection, and unmatched value at scale.” Derek Dicker, CEO, Nyriad, said: “Performance rivals flash-based systems, the efficiency and resiliency are equal to or better than the top-tier storage platforms on the market – and the ease with which users can manage multiple petabytes of data is extraordinary.” The UltraIO system can reportedly withstand up to 20 drives failing simultaneously with no data loss while maintaining 95 percent of its maximum throughput.
…
Veeam SI Mirazon has selected ObjectFirst and its Ootbi object storage-based backup device as the only solution that met all its needs. Ootbi was racked, stacked, and powered in 15 minutes, built on immutable object storage tech. Mirazon says that, with Object First, it can shield its customers’ data against ransomware attacks and malicious encryption while eliminating the unpredictable and variable costs of the cloud.
…
Data integrator and manager Talend has updated its Talend Data Fabric, adding more AI-powered automation to its Smart Services to simplify task scheduling and orchestration of cloud jobs. The new release brings certified connectors for SAP S/4HANA, and SAP Business Warehouse on HANA, enabling organizations to shift critical workloads to these modern SAP data platforms. The release supports ad platforms such as TikTok, Snapchat, and Twitter, and modern cloud databases, including Amazon Keyspaces (for Apache Cassandra), Azure SQL Database, Google Bigtable, and Neo4j Aura Cloud. The addition of data observability enables data professionals to automatically and proactively monitor the quality of their data over time and provide trusted data for self-service data access. More info here.
…
Veeam has launched an updated SaaS offering – Veeam Backup for Microsoft 365 v7 – enabling immutability, delivering advanced monitoring and analytics across the backup infrastructure environment, along with increased control for BaaS (backup as a service) through a deeper integration with Veeam Service Provider Console. It covers Exchange Online, SharePoint Online, OneDrive for Business and Microsoft Teams. Immutable copies can be stored on any object storage repository, including Microsoft Azure Blob/Archive, Amazon S3/Glacier and S3-compatible storage with support for S3 Object Lock. Tenants have more self-service backup, monitoring and restore options to address more day-to-day requirements. Veeam Backup for Microsoft 365 v7 is available now and may be added to the new Veeam Data Platform Advanced or Premium Editions as a platform extension or operate as a standalone offering.
…
AIOps supplier Virtana has announced a Capacity Planning offering as part of the infrastructure performance management (IPM) capabilities of the Virtana Platform. Companies get access to real-time data for highly accurate and reliable forecasts. Jon Cyr, VP of product at Virtana, said: “You’ll never be surprised by on-prem or cloud costs again.”
…
A Wasabi Vanson Bourne survey found 87 percent of EMEA respondents migrated storage from on-premises to public cloud in 2022, and 83 percent expect the amount of data they store in the cloud to increase in 2023. Some 52 percent of EMEA organizations surveyed reported going over budget on public cloud storage spending over the last year. Top reasons for EMEA orgs exceeding budget included: storage usage was higher than anticipated (39%); data operations fees were higher than forecast (37%); additional applications were migrated to the cloud (37%); storage list prices increased (37%); higher data retrieval (35%); API calls (31%); egress fees (26%) and more data deletion (26%) fees than expected. Overall, EMEA respondents indicate that 48 percent of their cloud storage bill is allocated to fees, and 51 percent allocated to storage capacity, on average.