Comment Against reports of a nearing merger of Western Digital and Kioxia, B&F is reviewing the implications and some of the difficulties that could lie ahead in such a deal.
The Bloomberg report claims the two are working towards a combined business based on Kioxia’s operation and a spun-off Western Digital SSD business. It would own the fab plants operated by the existing Kioxia-Western Digital joint venture, and build and sell SSDs using the fabs’ NAND chips. The new business would have a US stock market listing and also one in Japan, thus placating Japanese national interest in having a national NAND semiconductor business.
Western Digital (WD) management would run the cobined business, according to Bloomberg’s report. In our estimations, a WD exec could be the CEO with a Kioxia chairman or perhaps a couple of co-CEOs. There would have to be, B&F thinks, visible involvement with real operational influence to gain Kioxia exec buy-in.
WD is in an interesting position as it is involved in a strategic review of its business with its two SSD and hard disk drive units. This is as a result of involvement from activist investor Elliott Management. As we understand it, Elliott believes the WD stock price, which is roughly equivalent to that of its disk drive competitor Seagate, effectively undervalues its SSD business. By separating the HDD and SSD business units, each could have its own stock market listing and the sum of the two business’s share prices would exceed WD’s current capitalization, giving investors a good return on their WD shares.
If a split happens then the two business unit execs, Robert Soderbery and Ashley Gorakhpurwalla, would not necessarily be the CEOs of the resulting Kioxia+WD SSD business and the WD HDD operation. WD’s current CEO, David Goeckeler, and Kioxia CEO Nobuo Hayasaka would both need status-worthy roles after their businesses were combined.
Long-term, the SSD business probably has a higher growth prospect than HDDs so Goeckeler might prefer being involved with that. There will surely be a lot of senior exec brain time dedicated to this topic at WD and Kioxia, and what it means for career paths.
Apart from populating the exec offices, a combined business would surely require regulatory approval as it would decrease competition. And that brings up the issue of China’s regulatory authority, which might, in the circumstances of current US-China relations, not play nice. One possibility, maybe distant, is that the new Kioxia/WD business simply ignores the Chinese regulator but that would mean no sales into China.
The merged WD and Koixia entities will be viewed by management as having potential for cost savings, with duplicated business functions likely scrapped. Wells Fargo analyst Aaron Rakers lists significant combined synergies – end market/product roadmap, overlapping R&D (controller/system development), separate assembly and test operations, operating committee/decision, go-to-market/sales consolidation etc.
Outside the 50:50 split of their JV NAND foundry chip, Kioxia actually has its own additional NAND supply from a fab, amounting to 20 percent of its JV output share, and a combined company would inherit this.
Valuation
Kioxia has a complicated ownership structure, with a Bain Capital consortium owning 56.2 percent, Toshiba Corporation having 40.3 percent, and Hoya Corporation 3.1 percent. Any acceptable Kioxia-WD combination would have to deliver perceived value to these three parties. The Bain consortium was composed of Bain, SK Hynix, Apple, Dell Technologies, Seagate Technology and Kingston Technology. It paid $18 billion for its share of the Toshiba Memory business in June 2018, which became Kioxia.
Kioxia tried to run an IPO in 2020-2021 with a valuation of $20.1 billion. The IPO attempt failed in 2022.
A driver for the IPO was that Toshiba needed to raise cash because it had its own financial problems, originally due to issues with its Westinghouse Electric nuclear power station business in 2017. These led to a potential bankruptcy and the selling off of Toshiba Memory in the first place.
Toshiba was even considering selling itself in April last year as a way of paying off debts and liabilities and becoming a freshly capitalized business. The net:net here is that it really does need the cash from a Kioxia-WD merger and as much cash as it can get.
Market share
The new SSD business will start life with an enviable third of the SSD market, roughly equal give or take a few points to Samsung’s market share. TrendForce revenue market share numbers for the third 2022 quarter were:
Samsung: 33 percent
Kioxia: 20.6 percent
SK hynix + Solidigm: 18.5 percent
Western Digital: 12.6 percent
Micron: 12.3 percent
Others: 4.6 percent
Kioxia + WD would equal 33.2 percent. Rakers estimates market section capacity shipment shares for the merged entity as:
Enterprise SSDs: ~15 percent versus Samsung (~50 percent), Hynix (~25 percent), and Micron (~8 percent).
Client SSDs: WD + Kioxia at ~29 percent vs Samsung (~28 percent), Hynix (~16 percent), and MU (~11 percent).
There is obvious scope to grow in the enterprise SSD market. Unlike the Sk hynix-Solidigm business, a combined Kioxia-WD NAND business will use a single technology stack and doesn’t have to worry about somehow integrating two stacks or otherwise moving to a single stack.
Merger finance
Who would finance such a merger? A combined company would involve WD splitting itself in two, meaning two stock market listings, unless the new Kioxia-WD was privately owned. We doubt that Elliott Management would agree to that deal unless it could see a way to unload the shares it would have in a reasonable time.
Also the share structure for current WD owners would need convoluted calculations. For example, if an investor owned one WD share now, how many shares would they get in the two resulting businesses? They could get one share in the WD HDD business and, say, only half a share in the WD/Kioxia combined business because WD currently has a 50:50 cut of the JV Fab’s output.
But Kioxia has additional NAND output from outside the JV’s Fabs so the value of that has to be taken into account, lessening the WD investor’s share in the new business, but increasing that of the Bain consortium and Toshiba itself.
For the investment experts involved in this deal, it will be a complicated process to emerge with an outcome that satisfies all the parties involved. In its favor are Toshiba’s need for cash and WD’s need to get Elliott off its back via realizing value from its Kioxia JV stake.
The NAND market is in a downturn, but that may only last for another two quarters or so, after which the underlying constant data storage increase should return it to growth. That would be a better backdrop for a public offering by a Kioxia-WD combination, with an interim private ownership deal led by, of course, Bain Capital.
This is just speculation, but discussions with a source close to Bain Capital showed that these they are realistic. They reminded me that there are several potential routes to liquidity for owners of stock in a merged business, if indeed a merger takes place at all.
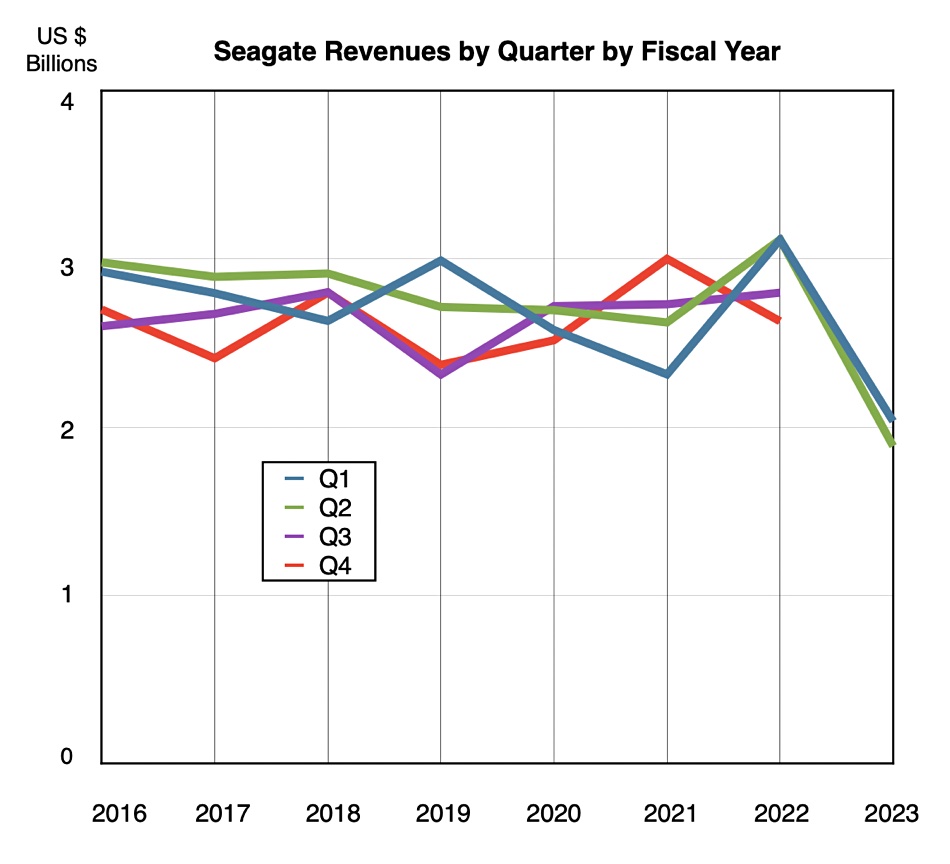
HDD vendor Seagate recorded a 39 percent drop in revenues for its second fiscal 2023 quarter, chalking it up to an adverse economic environment.
For the quarter ended December 30, the storage company generated revenues of $1.89 billion compared to $3.12 billion a year ago. There was a loss of $33 million – the first loss in many years – down from a profit of $501 million. This follows a dire first quarter of fiscal 2023 when revenue plunged 35 percent and profit dived 94 percent. Some 3,000 layoffs were announced.
On the latest earnings call, CEO Dave Mosley said: “Seagate delivered on what we set out to do in the December quarter, and I’m proud of our team’s accomplishments amid this tough business environment.”
Seagate’s revenue was slightly above its guidance midpoint and Mosley said this “extended a decade-long trend of generating positive free cash flow.”
Mosley listed the main factors that pulled revenues down, weighing heavily on the mass capacity markets: “The COVID-related economic slowdown in China, the work down of nearline HDD inventories among US cloud and global enterprise customers under a more cautious demand environment, and macro-related disruptions primarily impacting our consumer-facing markets.”
A chart of revenues by quarter by fiscal year shows the dramatic revenue fall in the past two quarters:
Financial summary
The main disk drive business pulled in $1.66 billion, down 41 percent; while enterprise, flash systems and other products generated $224 million – a 24 percent fall. Seagate shipped 113EB of disk drive capacity, down 31 percent, and the average capacity per drive was 7.3TB, lower than the previous quarter’s 7.5TB.
Seagate reduced its total debt in the quarter by $220 million and reduced its capital expenditures by more than 40 percent sequentially. It recognized charges related to last quarter’s layoffs, the October 2022 Restructuring Plan, plus various gains and charges associated with other cost-saving measures.
Despite these charges and the lower revenues, investors still made out: it nonetheless declared a dividend of $0.70 per share, which will be payable on April 6, 2023.
Seagate said there was ongoing adoption of its 20+TB platform, representing nearly 60 percent of nearline EB shipped in Q2 FY23. It shipped 79.7 nearline exabytes; about 35 percent of which as shingled magnetic media (SMR) drives in the quarter.
High customer inventory levels affected nearline drive demand, but Seagate thinks customers are getting inventory levels down. The VIA (Video and Image Apps) market was depressed by the prolonged economic slowdown in China, following recent China government policy changes to reverse Covid lockdowns. Seagate anticipates demand will improve as the year progresses.
Demand for other drives, its legacy group, were seasonally up 8 percent due to a consumer demand rise compared to the prior quarter.
Seagate has lowered production output to help progress customer inventory correction and support supply discipline as demand recovers. It is already seeing encouraging signs in China, and Mosley expects “nearline sales will improve slightly in the current quarter, particularly for our high-capacity drives.” Overall there are signs that conditions will generally improve as the calendar year progresses.
Seagate will add another 10 percent to SMR drive capacity and launch 25TB plus drives this quarter. It says it will be launching its 30+TB HAMR-based product family in the June quarter, Q4 FY23, slightly ahead of schedule. This will be preceded by it shipping pre-qualification units to key cloud customers in the coming weeks.
Mosley believes Seagate has a HAMR technology advantage that is measured in years, with “strong and consistent cost reductions at the highest drive capacities and enable future cost-efficient refreshes of our midrange capacity drives.” That means they’ll need fewer platters and heads and cost less to produce because they change from 2 or 2.2TB/platter to 3+TB/platter.
The outlook for the next quarter is for revenues of $2 billion, plus or minus $150 million. This compares to the year-ago $2.8 billion, a 26.8 percent fall. Look out to the quarter after that for signs of an upturn in Seagate’s revenues.
NetApp has discontinued the Astra Data Store product, which provided Kubernetes persistent storage for the NetApp Blue XP data management layer, leaving ONTAP as sole provider.
Astra Data Store, launched in preview mode in May 2022, is cloud-native software providing shared NFS file and block storage to containers and virtual machines. It was one way of provisioning persistent storage to Kubernetes-orchestrated apps in the Astra Control Center with the alternative being Cloud Volumes ONTAP.
Astra Control Center v21.12, released 2021, and the later v22.04.0 released in 2022, could both deploy and manage the Astra Data Store.
Eric Han LinkedIn post from June 2022
Everything changed when Blue XP, a software control plane to manage a customer’s data estate in a hybrid on-premises and multi-cloud environment, was announced in November 2022. The aim was to provide a single control plane, unifying separate NetApp offerings and covering non-NetApp tech. It included the various Astra products inside its umbrella, and provided on-premises data storage (ONTAP, StorageGRID, E-Series) and cloud data storage (Cloud Volumes, ANF/FSx/CVS) but not the Astra Data Store.
Cloud Volumes ONTAP supports Kubernetes dynamic provisioning with its Astra Trident CSI driver. Astra Trident is an open source storage orchestrator for containers and Kubernetes distributions, including Red Hat OpenShift. It works with the entire NetApp storage portfolio, including the NetApp ONTAP and Element storage systems, and also supports NFS and iSCSI connections. CSI, the container storage interface, is a standardized API for container orchestrators to manage storage plugins.
Sources have claimed NetApp closed down the Astra Data Store product, in what looks like a storage responsibility takeover by NetApp’s ONTAP mothership. NetApp was contacted about this closure and a spokesperson told us: “Participating in the Kubernetes ecosystem is strategically important to NetApp and the company continues to invest in building Astra, including Astra Control and Astra Trident. Astra’s mission was always to make stateful workloads simpler to adopt on Kubernetes and to solve the challenges customers face in production – and based on this objective, NetApp is continuing the Astra Control product and pausing the Astra Data Store project.”
“The Astra Data Store (ADS) Beta program revealed that customers were requesting an integrated experience for Kubernetes data management and cloud mobility. NetApp takes customer feedback seriously, and these insights informed the pivot in resources to focus on the customer need – taking advantage of containerized workloads running in native Kubernetes clusters in the public clouds.“
“Astra Control provides Kubernetes data management for Azure NetApp Files, and just recently announced support for both Cloud Volume ONTAP and Amazon FSx for NetApp ONTAP. Astra Control already supported customers who want to self-manage their Kubernetes data, including on-prem customers who have NetApp ONTAP as their storage provider. Astra and ONTAP now provide full data protection for containerized applications that were tested with Astra Data Store.”
Pure Storage reckons that its sales org should sell the entire product portfolio in its fiscal 2024 and thereby increase their reach.
Update: Email author corrected to Dan FitzSimons, Chief Revenue Officer, 26 Jan 2023.
Pure is currently in the final quarter of its FY2023, and preparing for FY2024. We have seen an internal email from Pure Storage sent by Dan “Fitz” FitzSimons, Chief Revenue Officer, presenting the new go-to-market organization within sales and its supporting technologies.
Dan FitzSimons.
It starts out by declaring: :This past year Pure once again took more of the overall storage market than any of our competitors.”
Hmm. We have a bit of a problem with this as Pure’s expected full FY2023 revenues are ~$2.75 billion, whereas Dell storage has been pulling in $4.2 billion a quarter for its past three quarters.
Then Fitz talks about a $5 billion bookings goal for the year and declares: “Our strategy is simple: to expand our footprint and wallet-share with existing customers building on core strengths and winning new use cases, and to do the same to land new customers in every segment.”
“The single biggest factor in your and Pure’s success is tied to our ability to integrate the breadth of the portfolio – FlashArray, FlashBlade, Evergreen//One, Portworx – into your selling motions.”
He says “FlashBlade is a clear example of a successful Pure growth engine … delivering more than $1.5 billion in total FB bookings, extending Pure into new fast file and object use cases.”
FlashBlade has reached mature levels of scale. Nevertheless, its sales team is being amalgamated with the core FlashArray team because the integrated portfolio is the big selling strength Pure sees itself as possessing. So Pure is “Unifying our FlashArray sales team (known as the ‘core’ team) and our UDS/FlashBlade specialist team into a single, unified Portfolio Sales Team. This combined team will immediately increase the reach of our portfolio-focused account executives around the world.”
Pure is also unifying its Data Architect and Field Solution Architect teams: “creating a consistent engagement model for customers that covers the portfolio across all technical use cases – Database, Modern Data Protection, Virtualization/Cloud, Modern Data Analytics.” The Principal Technologists (PT) team will be expanded “with a dedicated PT in each major sales region.”
Fitz argues: “The tighter alignment will create velocity, reduce customer friction, and help us lead with the use cases that our solutions have been built to address.”
And it’s not just sales leading with this effort. “This is a company effort. It will require everyone who ‘wears the orange’ to shift our mindsets in how we train, engage with, and represent the portfolio in our marketplace.”
Finally, a note of caution: “In the unlikely event that you are contacted by a financial/industry analyst or a journalist, do not offer a statement, and contact the communications team.”
A separate source in Pure said this is just the annual culling of underperforming sales reps, and there haven’t been any layoffs in other parts of the org. Pure has been contacted for a comment, and told us: “Just to reiterate what we shared, the unification of our global go-to-market organization is a very positive outcome for not only our customers, but our internal team. It enables our customers to leverage the full portfolio and our unified sales team to put forward the best possible solutions (across every workload) to our customers. “
“Additionally, very few employees were impacted by the change.”
We had the opportunity to run an email interview with Mark Greenlaw, VP of market strategy at Cirrus Data and asked him questions to find out more about where block-based migration fits in the market.
Mark Greenlaw
Blocks & Files: How would you advise customers to decide between block-based and file-based data migration? What are the considerations when choosing which to use?
Mark Greenlaw: Good question! We often get questions about the differences between block and file data and how to think about it. Ultimately, the migration methodology is determined by the type of data you’re migrating. Typically, you use block migration tools for block data and file migration tools for file data. That said, there are exceptions to this rule depending on the desired outcome.
One example is when you want to migrate your data from an Oracle environment to a Microsoft SQL environment. In this situation, you need to not only migrate the data but also transform it. You would use a file migration solution to extract, transform, and load the block data, getting a representation of the data in a file format that can now be read into a SQL environment.
There are also situations in file migrations where block migration solutions work better. This scenario happens when you want to move a large amount of file data from cloud vendor A to cloud vendor B and you plan to keep it all on the same file server. The right block migration solution can make a bitmap copy of the drive which allows you to do only the change data, not file by file, but by the whole volume. A block migration in this situation performs the file migration quicker and without disruption.
Here are the important considerations for choosing the right migration solution. If you’re using a block tool and haven’t synchronized your applications, you can end up with a less-than-perfect copy. It is important when moving data from source to destination that the migration solution has automation that enables you to track changes and then synchronize the source and destination to make sure they are exact replicas.
In a file migration, you must keep file attributes like modification time, creation date, etc. If you don’t, you are likely to end up with file administrative nightmares. Imagine you had a shared drive with a rule that said, “Archive any files that are in the drive for more than two years.” If I’m not careful to keep the creation date and I change my modification time, I could end up with too much data in the shared drive. Then I must expand it, which can be expensive and lead to operational interrupts that are difficult to manage.
Blocks & Files: What are the considerations involved in object data migration?
Mark Greenlaw: Objects, in general, are there because they’re hashed data. I create an address for the data that I’m trying to access, and I have a hash that says, “I know the address of this data,” and then I can store it in object. That process gives me object attributes instead of file attributes. As long as I have the hash, I can move where the data is and not worry about updating it.
Let’s say I’m taking a portion of the object data. It’s possible to take archived data out to an object pool, such as an S3 bucket. Now I can archive to that object pool—but I need to ensure when somebody accesses that file, they can read it. The challenge is I have to encapsulate essentially a block of data or a group of data bytes that I want to archive and create that hash. I can move the object data to an S3 bucket, but if it moves back to an on-premises bucket, I need to copy that hash with all the data there. If your hash gets corrupted, you lose all the attributes of your data.
The big cloud vendors offer these object-based repositories that are not very performant, but they are scalable. The advantage of such an object store is that it’s essentially limitless. As long as I have a hash key, I can continue writing—enabling me to have a moderately slow but scalable archive. There I can archive chunks of data, which allows me to keep the file attributes onsite or keep the database instance onsite while a portion of my data is now on a lower cost, lower performance environment. This is fine if I’m not accessing the data very frequently, and I want to keep it out of my core data. If you have a high level of recall, object buckets tend not to be very performant, which slows things down.
Blocks & Files: Can Cirrus Data help with data repatriation from the cloud? Is this file or block-based and how do egress fees affect things?
Mark Greenlaw: Cirrus Data’s data migration solutions are source and destination agnostic. We regularly help organizations migrate data from their on-premises environment to the cloud. There are also situations when we need to migrate data from the cloud back to an on-premises environment.
Why would someone do that? Essentially, buyer’s remorse. Maybe you moved your data to the cloud, but it was more expensive than you expected. It could also be that it didn’t deliver the performance you wanted, or perhaps you changed your business priorities. Now you’ve decided that your data needs to be back on-premises.
There are a few considerations in bringing your data back from the cloud. There are lots of free vendor tools that get you up to the cloud, but cloud vendors don’t have any incentive to provide you assistance in leaving. They also charge you an egress fee. It is essentially The Hotel California: You can check in anytime you like, but you can never leave. Egress fees are usually a month’s rent. Your fee is typically determined by the number of terabytes per month, and you receive another bill for egress charges per terabyte.
When Cirrus is repatriating data for customers, our solution does a data reduction before it hits the meter. If you’re moving a terabyte and it’s only half full, a typical migration tool will copy the full terabyte, zeros, and all. We run a process called de-zeroing, which removes all the empty space and compresses the rest. This can be a significant saving if you are, for example, only 50% full. We use industry-standard tools to examine the data in its environment and often get an overall reduction of 8 to 1, which means my egress fee is one-eighth what it would’ve been if you didn’t use a solution like Cirrus Data.
Blocks & Files:Can Cirrus move block data between public clouds? Has this ever happened?
Mark Greenlaw: Yes, we have absolutely moved block data between public clouds. As hybrid IT continues its hunger for optimization, we expect such cloud-to-cloud migrations to increase. Here’s how this usually happens:
A customer has an environment with some data on-premises, different data on AWS, and then another group of data with Azure. Imagine AWS announcing, “Storage now costs 25 percent less.” The customer will obviously want to move their data from Azure to AWS to take advantage of that lower-cost environment.
We are completely source and destination agnostic. In this scenario, because Cirrus Data is cloud agnostic, we have no problems helping the customer take advantage of the best storage environment for their data. The customer could run into the same issue with the egress fees we mentioned earlier. To minimize those egress charges, we would run our data reduction, de-zeroing, and compression software to make sure the volume of data being moved is only what is required. The customer then can take advantage of lower storage costs with the right SLA. Cirrus Data is renowned for the speed of its data migrations, so all this can happen at lightning speed.
Speed is the other aspect of data reduction that’s critically important. When I’m moving on-premises data to the cloud, or from the cloud back to an on-premises environment, that data reduction also results in work getting done significantly faster. One independent study reported a four to sixfold improvement in time over using a tool that doesn’t have that data reduction.
Blocks & Files: How can deduplication and/or compression work with block-based migration?
Mark Greenlaw: Block storage is usuallymission-critical applications and databases. Those who manage databases and applications are typically not IT infrastructure people. More likely, they are focused on the applications and making sure that those applications stay up 24/7. Applications and databases generally require a full backup and are managed carefully, so that if something goes bump in the night they can recover quickly.
So if you’re an administrator of applications and databases, you want to ensure you can take on an influx of new data at any given time. Let’s say you’re running a website, and somebody puts a promotion out there. Suddenly, you get a flurry of new activity and, with it, lots of new information being written into your database. If you were running at 80% or 90% full, you could get dangerously close to a full database. A full database means it is unable to take any new information and your application fails. It is not an acceptable outcome.
It’s important to consider this scenario because it leads database administrators (DBAs) and application managers to say, “I’m not going to let my database be more than 40 to 60% full. When I reach that threshold, I’ll expand my storage bucket, so I don’t ever run out of space.” The problem is if your maximum threshold is only 60%, you are not very efficient. And keep in mind that application owners are not evaluated on IT infrastructure costs—they’re evaluated on application uptime because the cost of the application or database being down is catastrophic.
The flip side to this reality is that when you are migrating those applications or databases, you need to get rid of the empty space. We quickly remove all those zeros and move just the necessary data. It is a great result for the DBAs and application managers who want to reduce the time it takes to get to the next level. It takes less time to move one-eighth of the data than it takes to move the entire volume. IT is happy because we were able to optimize the costs and the application teams are happy because the block data moved quickly and without disruption.
Blocks & Files: Are there any benchmark tests or other performance measures customers could use to decide which data mover to select: Cirrus Data, DataDobi, WANdisco, etc.? Eg. $/TB moved, total migration time per 10PB?
Mark Greenlaw: We benchmark ourselves against cloud vendors’ free data migration tools like AWS CloudEndure and Microsoft Azure Migrate. The reason for that is our customers are tempted by free migration tools. Testing ourselves with encryption and data reduction in flight; we are about 4 to 6 times faster than those free tools.
More importantly, we can keep these speed advantages at scale for customers moving big data volumes. If you’re moving 100TB, free vendor tools could take nine months or longer, which is an excessively long period to manage risk and manage disruption. Cirrus Data has successfully moved 100TB in one month. This is a huge business advantage for the organization trying to bring its new storage environment online. Reduced risk, minimal downtime during cutover, and an accelerated digital transformation—in short, a game changer for large organizations.
Blocks & Files: Why are transportable disk-based migration methods, such as Seagate’s Lyve Mobile and Amazon Snowball still in use? Don’t they point to the view that network-based data migration fails above a certain level of TB-to-be-moved-in a-certain-time?
Mark Greenlaw: Let’s examine how these technologies work. They mail you a set of disk drives. You connect that to your infrastructure, copy the data, and mail it back to the cloud vendor. Then they put it into the cloud.
If that’s the fastest way you can migrate onto your new storage environment, you must be okay with significant disruptions. By the time you disconnect that container and ship it up to the cloud vendor and restore it in the cloud, there’s a long gap in connectivity. Customers end up with these options because they don’t have data reduction in flight.
If they accelerate the process four to sixfold, they might not need to take advantage of these disk-mailing tools. The other challenge is these cloud vendors (like all storage vendors) want to make it difficult to move. Hotel California is really the theme song. The organization has the ability to connect and move the repository to the cloud, but if you are dissatisfied with that move, these tools do not have a reverse button. You are stuck in this environment because you can’t get your data out.
That’s why it’s important you have a multidirectional solution with data reduction. We also have a capability called Intelligent Quality of Service (iQoS). This patented technology can look at the data and determine what is in use and what is inactive. We measure and automatically yield. If that data’s active, we just pause, and then we resume when the data becomes inactive. All data has a variable access environment, so we can ensure we are doing good, high-speed migrations without impacting production and do it in a way that doesn’t overwhelm a customer’s TCP/IP connections.
These physical disk services are a stop gap created because SMB organizations don’t have the networks of big enterprises. Since these SMBs are going to the cloud, they might try to delay a network upgrade. It wouldn’t make sense to complete an upgrade only to move to the cloud. Once the data is there they won’t need the increased bandwidth. We enable SMBs to get to the cloud they want without using these disk-based tools at a reasonable time and without application impact.
Blocks & Files: Do fast file metadata accessors with caching, such as Hammerspace, make networked data migration redundant? What are the considerations involved in a decision between actual data migration and metadata-access-led remote data access such as Hammerspace‘s Global Data Environment and technology from cloud file services suppliers such as Panzura and Nasuni?
Mark Greenlaw: Fast metadata accessors make recently and often-used file data feel like it’s being accessed locally when it’s stored in the cloud. These tools are ideal when groups of users need fast access to data from any location, such as a temporary office or small branch. They’re also useful for global collaboration.
Maybe my company has a global development program. Some people are based in low-cost geographies, and I have others working from the home office in a major metropolitan center. I want everybody to have the same performance with a shared file. This works by having metadata describe the file data—telling me where that data lives, then taking and caching that information in a local repository. Now I don’t have to worry about the distance between my users.
As useful as fast metadata accessors are, I don’t believe they make networked data migration redundant. While these tools are great for short-term offices that need high performance, their cost means they don’t scale well for larger offices or individual users. You wouldn’t put a Hammerspace application on everybody’s laptop. What’s more, because these tools can’t cache everything, they must focus on data in high demand—they won’t help if users need access to more obscure files.
File data management startup Komprise has raised $37 million in its first fund raiser since 2019.
Komprise’s Intelligent Data Management (IDM) product manages and monitors unstructured data estates for customers across their on-premises and public cloud environments and stores the data to the most cost-effective storage tier. The software also finds out which users access which data and in what location.
Kumar Goswami.
CEO Kumar Goswami put out a statement: “We’re thrilled that our investment partners see the opportunity we’re creating by developing a comprehensive platform for customers to modernize unstructured data management practices.”
“Komprise delivers immediate data storage cost savings and long-term business value with a foundation for unstructured data analytics and machine learning innovations.”
The cash will be uses to “to scale operations and extend market leadership” – though how it’s going to do that isn’t specified. Presumably it’s product development.
The cash raise is being presented as a growth capital round and came from Canaan Partners, Celesta Capital, Multiplier Capital and Top Tier Ventures. Kevin Sheehan, founder and managing general partner, Multiplier Capital, said: “We invested in Komprise because of their impressive growth and path to profitability combined with the massive opportunity in edge data management and unstructured data for AI/ML in the cloud. We believe in the company’s market, vision, team and execution.”
Komprise says it experienced record-setting growth and customer expansions in 2022. It grew revenues 306 percent from 2018 to 2021, with new customers in 2022 accounting for 30 percent of the total. That’s very encouraging considering the Ukraine war, supply chain issues and inflation headwinds affecting everyone. Its Net Dollar Retention is 120 percent, meaning customers tend not to leave once recruited and spend more money with Komprise.
Clearly it is not yet self-funding but the investors see a route to profitability. The increasing emphasis being paid to storage cost-efficiency and reducing power consumption plays into Komprise’s marketing tailwinds.
Komprise was started up in 2014 and has taken in a relatively small $85 million in funding, with the last round taking place in 2019 and raising $24 million. The three founders are Goswami, president and COO Krishna Subramanian, and CTO Michael Peercy.
OneFS 9.5, the latest PowerScale OS version, provides a claimed 55 percent in streaming data access speed plus cyber resiliency improvements.
PowerScale and the prior Isilon scale-out filers are powered by OneFS and come in all-flash and hybrid flash-disk formats.
Chris Mount.
Dell’s director of product management Chris Mount told us: “There is a 55 percent increase in streaming read performance on F600 and F900 platforms. That means our our F601 all-flash node can get to line rate on 100 Gig networking at the front end.” That’s from a 1RU box and it’s entirely from software changes and comparing OneFS 9.4 to the latest version using NVMe SSDs.
It’s been achieved by rebuilding the caching process for NVMe drives with lots of optimizations, such as side-stepping the L2 cache. Mount said there is more performance to come. That means PowerScale will have a stronger enterprise HPC story.
He said that the PowerScale team is convinced that hybrid flash-disk systems are worthwhile in terms of affordable and storage performance and capacity and: “More seamless tiering is coming” and “We think the hard disk drive is here to stay for quite a while.”
There are a mass of other improvements. For example a Dell blog says: “Enhancements to SmartPools in OneFS 9.5 introduce configurable transfer limits. These limits include maximum capacity thresholds, expressed as a percentage, above which SmartPools will not attempt to move files to a particular tier, boosting both reliability and tiering performance.”
“Granular cluster performance control is enabled with the debut of PowerScale SmartQoS, which allows admins to configure limits on the maximum number of protocol operations that NFS, S3, SMB, or mixed protocol workloads can consume.”
The PowerScalers are also working to improve the system’s performance per watt efficiency – dramatically – and capacity per rack unit. They think that performance and capacity efficiency are both going to be important customer concerns.
Cyber resiliency is another major concern and Dell has added a software firewall inside a PowerScale OneFS cluster. It’s a zero trust thing, with the assumption that malware actors could break through a datacenter’s firewall infrastructure and then have access to the PowerScale array. So they have a separate firewall inside the firewall area to cope with – a Russian Doll-like security concept.
This is based on a partnership with Superna and API-level access to put immutable snapshots behind a so-called smart air-gap. If cluster telemetry shows bad actors are trying to access the cluster then network access to the air-gapped snapshots is closed down.
OneFS now supports self-encrypting 15TB and 30TB SSDs as well.
The roadmap for OneFS includes a stronger public cloud presence. Mount said Project Alpine for PowerScale is coming soon. That means OneFS being ported to the three main public clouds – AWS, Azure and GCP – though not necessarily all at once. Think about the idea of a OneFS data fabric proving a single environment covering the on-premises and multi-public cloud worlds.
Dell is also building partnerships between data virtualizers such as Dremio and Databricks so that they can use PowerScale storage as a platform for the data they are holding. It thinks that the unstructured data market is becoming heavily verticalized and partnerships open access into different vertical markets.
We should expect to hear more about this and the OneFS Alpine project progress later this year. We hear initial customers testing this are super-excited. The takeaway is that the PowerScale system story is getting stronger and there’s more to come. And that includes the portable PowerScale controller upgrades to Sapphire Rapids processors.
The new OneFS 9.5 code is available on the Dell Technologies Support site, as both an upgrade and reimage file, allowing both installation and upgrade of this new release.
Pure Storage has confirmed to B&F that it has broken up its specialist regional FlashBlade sales teams amid the creation of a single global go-to-market organization.
FlashBlade is Pure’s scale-out all-flash file and object storage array used as a backup target and fast restore system, as well as for fast file and object storage. It complements Pure’s main FlashArray line of all-flash block storage arrays. Increasingly the two product lines have been using common components. For example, the FlashBlade//S uses the same Direct Flash Modules, Pure’s proprietary flash drives, as the FlashArray//C.
A Pure spokesperson told us: “Pure continues to grow and innovate at a rapid pace, releasing a record number of new products and services in 2022. As a result, we have unified our global go-to-market organization to enable our customers to leverage the full portfolio of products, solutions and services.”
Sources told us the separate FlashBlade sales teams had been shuttered, with their salespeople informed that they can apply to be a rep selling FlashArray (core systems) or look for employment outside the company. Low-end FlashBlade customers are being presented with alternative FlashArray//X or //C systems. The background is that FlashBlade no longer needs specialized sales teams as it has become a mainstream product.
This information came from Pure people looking for job posts in competing suppliers.
FlashBlade//S front view
The latest FlashBlade//S is sold into markets such as AI/ ML, high-volume analytics, rapid restore for backups and ransomware recovery, manufacturing, high-performance simulation and EDA, medical and enterprise imaging, and genomics. Pure claims it has unmatched storage efficiency compared to any other scale-out storage system on the market. That means customers can save on their power spending by using FlashBlade//S.
The spokesperson said: “FlashBlade is a great example of a successful growth engine for Pure, surpassing $1 billion in lifetime sales all while being recognized as an industry leader by Gartner for Distributed File Systems and Object Storage.”
Both FlashBlade and FlashArray use the Purity operating system.
Storage software supplier DataCore is buying media and entertainment object storage supplier Object Matrix.
DataCore supplies block (SANsymphony), file (vFILO), object storage (Swarm), and Kubernetes storage (Bolt). It entered the object storage market by buying Caringo in 2021. Swarm Object Storage is used by hundreds of customers in over 25 countries, growing in excess of 35 percent in 2022.
DataCore can provide increased sales coverage to Object Matrix, as its CEO, Jonathan Morgan, acknowledged: “By leveraging DataCore’s experienced leadership team, worldwide distribution – consisting of over 400 channel partners and more than 10,000 global customers – combined with world-class engineering, sales, and marketing, we are in an excellent position.”
The media archives here are disk-based and online, not based on tape or optical disks. The need is to store vast amounts of media content affordably online so that it is immediately available. There is no waiting for a slow tape library to find it, mount a cartridge, and stream the data out to the waiting video effects artist.
Object Matrix was founded in Wales in 2003 with the idea of storing video workflow data on disk in object storage form rather than on LTO tape. The company developed its MatrixStore software product to be a pre-production archive, storing production content data and making it available on-demand. Broadcast, production, VFX, post-production and creative agency types have been customers since 2006.
It now supplies on-premises appliances, hybrid systems, and cloud storage with which broadcasters and service providers can securely manage content at all stages of the media life cycle. Object Matrix customers include NBC Universal, Warner Bros. Discovery, MSG-N, ATP Media, BT, and the BBC.
In September 2022, DataCore did a deal with shared storage supplier Symply to release DataCore Perifery, a media archiving appliance using Swarm as its objects storage base. The product supports edge devices and integrates with workflows used in media production, post-production, studios, sports, and in-house creative teams.
Object Matrix’s appliances and cloud services will be added to DataCore’s Perifery portfolio. This, it says, will reinforce the Perifery line of edge devices and systems, and add talent and expertise to its Perifery team.
Abhijit Dey, general manager of DataCore’s Perifery business, said: “Gartner predicts that more than 50 percent of enterprise-managed data will be created and processed at the edge by 2025. We’re excited to expand our Perifery portfolio with innovative solutions that will enable us to lead in edge markets.”
There is now the possibility of Object Matrix transitioning to Swarm technology as its object storage, thus reducing DataCore’s object code base count and engineering costs.
The cost of the acquisition was not revealed. CB Insights classed privately owned DataCore as a unicorn, worth over $1 billion, earlier this month. The company has been vigorously expanding since CEO Dave Zabrowski came on board in 2018.
Object Matrix co-founder Nick Pearce has written an entertaining blog about the acquisition.
MLOps supplier Iguazio has been bought by McKinsey and Company to form the hub of its QuantumBlack AI practice in Israel.
Machine Learning DevOps (MLOps) refers to operationalizing ML processes in a cloud-native application world. This is a vastly complicated process because every customer’s combination of sensor feeds, log information, databases, AI pipelines and stages and component processes is different – effectively making every implementation a custom one and delaying if not even defeating business AI projects. Iguazio’s software technology makes the process faster and more dependable. That AI project completion reliability and speed is what McKinsey is buying.
McKinsey senior partner and QuantumBlack global leader of alliances and acquisitions Ben Ellencweig issued a statement: “After analyzing more than 1000 AI companies worldwide, Iguazio was identified as the best fit to help us significantly accelerate our AI offering – from the initial concept to production – in a simplified, scalable and automated manner.”
By working with Iguazio McKinsey says its QuantumBlack unit will be able to provide clients with industry-specific AI solutions that are five times more productive, eight times faster from proof-of-concept to production, and twice as reliable.
Four of Iguazio’s founders. From the left: CTO Yaron Haviv, Chief Product Officer Yaron Segev, VP Architecture Orit Nissan-Messing, and CEO Asaf Somekh.
Asaf Somekh, co-founder and CEO of Iguazio, also put out a statement: “McKinsey’s experience and QuantumBlack’s technology stack and expertise, now coupled with Iguazio, is the ultimate solution for enterprises looking to scale AI initiatives in a way that directly impacts their bottom line. We’re thrilled to join the McKinsey family and embark on this next chapter for Iguazio.”
Iguazio’s 70+ staff will join QuantumBlack. No one is saying how much McKinsey – which has acquired more than 20 other businesses in the past few years – is paying for Iguazio. That biz has publicly raised $72 million in venture capital funding across, A, B and extended B-rounds. The last round took place in January 2020 and raised $24 million.
Has Iguazio been trading profitably since this funding round?
Somekh told us “Iguazio had considerable market traction, with key clients in the manufacturing, technology, transportation, financial services and other industries. No doubt, there have been challenges – with a global pandemic and then economic recession which happened in the last few years – but we were seeing great success with clients, were positioned well in the industry (in industry reports by Gartner, Forrester, GigaOm etc.), had strong partnerships with all the leading technology providers and a growing community.”
Who approached who first; McKinsey or Iguazio?
Ellencweig replied: “The relationship between Iguazio and McKinsey started over a year ago. … The natural synergy and great alignment was realized over time, both on the technology side and the talent / people. It was a natural progression of our relationship.”
How much is McKinsey paying for Iguazio?
Alexander Sukharevsky, senior partner and global co-leader of QuantumBlack, answered this question: “McKinsey is a private company and we are not able to discuss financials unfortunately. What we can say is that the entire Iguazio team will be joining QuantumBlack, McKinsey’s AI arm, and the technology will augment our offering to scale AI for enterprises globally.”
Israel’s Calcalist media site estimated the price to be $50 million, somewhat less than the total $72 million amount of Iguazio’s funding.
Sukharevsky added: “One of the main reasons behind the acquisition is the world class talent we saw at Iguazio. The entire Iguazio team will be staying on. Moreover, Iguazio will form the foundation for the fifth Global R&D Lab for QuantumBlack, right here in Tel Aviv – with other locations in London, New York, Gurgaon and São Paulo. We are excited to expand and establish this location with access to some of the world’s best tech talent.”
The extended B-round funding was led by INCapital Ventures, with participation from existing and new investors, including Samsung SDS, Kensington Capital Partners, Plaza Ventures and Silverton Capital Ventures. Dell Capital is another investor in Iguazio.
Are the Iguazio investors happy at this outcome?
Back to Somekh: “I cannot comment on behalf of our investors. You will be seeing their public statements in few hours to address this question. I do want to take the opportunity to thank them for their ongoing support and friendship.”
McKinsey is one of the top three global business consultancies – a somewhat discreet and secretive one, with more than 30,000 employees working in 60-plus countries. QuantumBlack is its data and analytics operation and nothing to do with quantum computing, a field in which other parts of McKinsey are active.
Iguazio was started up in 2014 by several co-founders: CEO Asaf Somekh, CTO Yaron Haviv, chief product officer VP architecture Aaron Segev, and VP architecture Orit Nissan-Messing. Eran Duchan lists himself on LinkedIn as a prolific code monkey and co-founder and says he is involved in R&D. Download a copy of Iguazio’s Enterprise Data Platform datasheeet here.
A big battle is brewing. There are two opposing groups of suppliers in conflict. One grouping is formed from the on-premises filers who are adding multi-cloud support to their file system products such as Dell’s OneFS and NetApp’s ONTAP, also Qumulo, but not the HPC-focussed file services suppliers such as Panasas, IBM’s Spectrum Scale and WEKA. The mainstream on-premises filers provide client access for the gamut of everyday file-based workloads in offices everywhere.
The second grouping is a collection of cloud-based file service upstart suppliers who have developed their offerings from the early cloud storage gate, file sync’n’share days, into more capable file services gateways. Our term, using front-end high-speed local caches, optimized WAN links and back-end capacity-based storage, often object-based with sophisticated central software in the cloud capable of handling hundreds of tenant customers and thousands, tens of thousands of users, keeping everything synchronised and working properly.
There are six suppliers we can identify in this group, with a well-established central trio – CTERA, Nasuni and Panzura – the restricted enterprise-focussed Egnyte, technologically unique Hammerspace plus newcomer LucidLink.
Some, like Nasuni, openly wish to replace on-premises filers – particularly from NetApp – while others, such as CTERA and Panzura, dismiss such aggressive marketing aims. Major incumbent filers do not publicly admit to any competitive impact from the upstarts. Dell and NetApp, for example, point to their revenue growth and IDC market share numbers, or make fastest-growing product in their history statements (such as PowerScale) to show that they are growing their file-based businesses.
Yet we doubt that there are many, if any at all, greenfield cloud field services customers. Their customers will generally have had existing file-based workloads and any sale they make is a sale lost to the incumbents. But the overall unstructured data market is growing so fast that the incumbents and the upstarts have been able to grow.
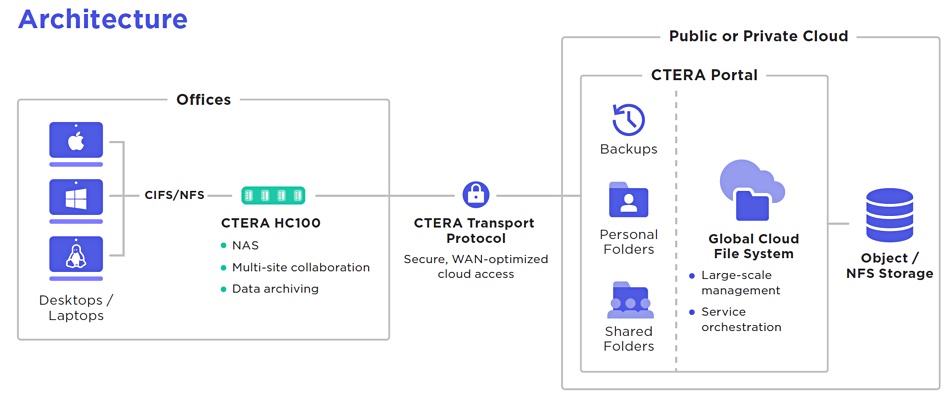
CTERA architecture diagram.
These cloud file service upstart suppliers have made progress selling to customers who have complex file-based workloads involving multiple stages and remote and skilled workers. They need to have files updated by one set of remote technicians and quickly available to others who need to process the output of the first group.
EDA (Electronic Design Automation) is one such area and others are distributed architectural practices and also distributed entertainment and media outfits needing to handle special video effects.
Lacking a central public cloud facility, the on-premises filers have to have site-to-site networking in place for their networked file systems when coping with customers who have distributed office sites and a need to share complex and large file data sets. The cloud file services upstarts squirt updated metadata and files to their central public cloud facility and then their software technology uses the metadata to update all the necessary remote sites and sends the data out as it is needed. Their centralized software technology is a strength, a moat, and represents years of development and battle-hardening by customer use.
They have a base from which they can scale and are operationally competent when handling tens of thousands of users in different organizations. The on-premises filers now extending into the cloud have to decide whether to develop their own version of this technology or to continue with their … what we might call ‘repeated point-to-point connectivity’ for customers. It is our belief that they will have to develop multi-tenant centralized technology if they want to scale.
We think that they might decide to buy the technology, meaning that Dell and NetApp could cast acquisitive eyes at CTERA, Nasuni and Panzura – much as Microsoft bought Avere and its cloud storage gateway tech back in 2018. We don’t see IBM getting acquisitive here as its main file interest – parallel access Spectrum Scale – is more of an HPC offering.
HPE does not have its own file services product in the OneFS, ONTAP sense. It could buy one of these upstarts in order to get an owned cloud file services offering into GreenLake.
The public cloud players could also decide to get involved, moving up the stack from simply providing a central high capacity storage vault and compute instances for the upstarts’ application software. An AWS, Azure or GCP could also acquire one of the upstarts.
Arcserve launched Unified Data Protection (UDP) 9.0 – a single platform, centrally managed backup and disaster recovery product for every type of workload. It combines data protection, Sophos cyber security protection, immutable storage, tape backup, and scalable onsite or offsite business continuity. UDP v9 includes data protection for Oracle Database, restore options for Microsoft SQL Server Deployments, enhanced availability, durability & scalability with Cloud Object Storage, and a choice of cloud-based or on-premises Private Management Console.
…
Real-time data platform supplier Aerospike announced Aerospike Connect for Elasticsearch, which enables developers and data architects to use Elasticsearch to perform fast full-text-based searches on real-time data stored in Aerospike Database 6. It complements the recently announced Aerospike SQL powered by Starburst product, which allows users to perform large-scale SQL analytics queries on data stored in Aerospike Database 6. The Aerospike Connect product line also includes connectors for Kafka, Pulsar, Spark, and Presto-Trino.
…
Cloud database supplier Couchbase announced its Capella Database-as-a-Service on Azure, claiming it offers best-in-class price-performance compared to other DBaaS offerings. Capella is a fully managed JSON document and key-value DBaaS with SQL access and built-in full-text search, eventing and analytics. It offloads database management, lowers total cost of ownership, delivers database flexibility for developers and enables performance at scale to build modern applications. It has mobile and IoT app synchronization, high-availability and automated scaling. Capella’s real-time, memory-first architecture ensures millisecond responses for highly interactive applications and the price-performance keeps improving as users scale.
…
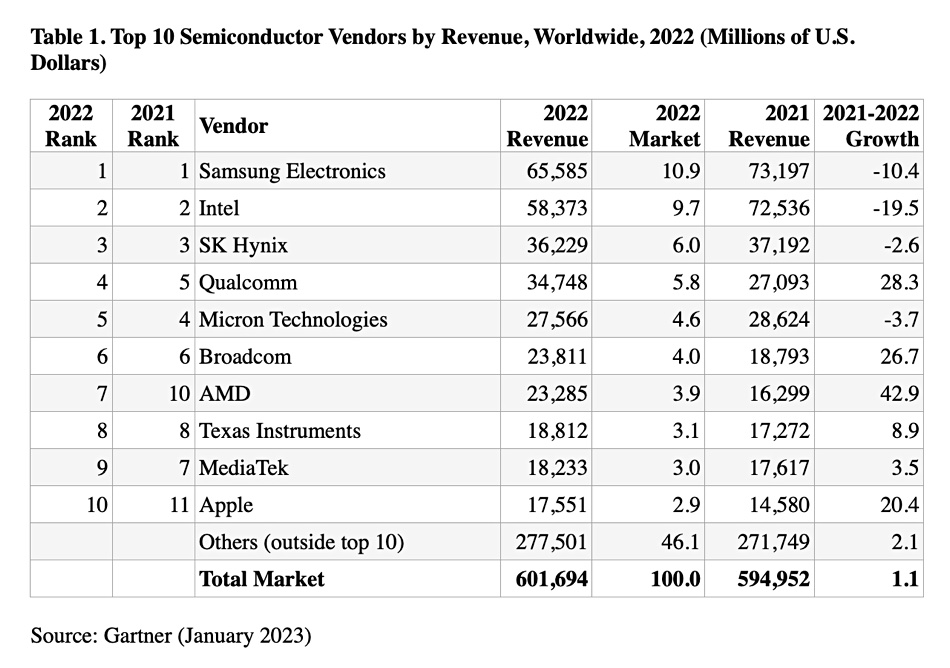
Gartner released its report into the semiconductor market in 2022 with the top 10 suppliers’ revenues listed in a table:
Worldwide semiconductor revenue increased 1.1 percent in 2022 to total $601.7 billion – up from $595 billion in 2021, according to preliminary results by Gartner. The year started with shortages driving up prices and OEM inventories. Andrew Norwood, VP analyst at Gartner, said: “However, by the second half of 2022, the global economy began to slow under the strain of high inflation, rising interest rates, higher energy costs and continued COVID-19 lockdowns in China, which impacted many global supply chains. Consumers also began to reduce spending.” So enterprises lowered spending which slowed overall semiconductor growth.
Memory, which accounted for around 25 percent of semiconductor sales in 2022, was the worst-performing device category, experiencing a 10 percent revenue decrease. OEMs started to deplete memory inventory they had been holding in anticipation of stronger demand. Conditions have now worsened to the point where most memory providers have announced capital expenditure (capex) reductions for 2023, and some have cut wafer production to reduce inventory levels and try to bring the markets back into balance.
Overall non-memory revenue grew 5.3 percent in 2022, but the performance varied wildly across the different device categories. Samsung Electronics maintained the top spot although revenue declined 10.4 percent in 2022, primarily due to declines in memory and NAND flash sales (see table above). Gartner clients can read more in “Market Share Analysis: Semiconductors, Worldwide, Preliminary 2022.“
…
Security supplier Immuta announced Immuta Detect with continuous security and compliance monitoring capabilities. It alerts users to risky data access behavior, enabling quicker and more accurate risk remediation and improved data security posture management. Detect consolidates data access logs for monitoring and analysis, and provides a deep dive analysis of individual user and data activity. It Detect automatically scores data based on how sensitive it is and how it is protected (such as data masking or a stated purpose for accessing it) so that data and security teams can prioritize risks and get real-time alerts about potential security incidents.
…
ioSafe 1522+
IoSafe introduced the ioSafe 1522+, a five-bay network attached storage (NAS) device for businesses of all sizes, protected against fire and flood. The fireproof and waterproof 1522+ has dual-core AMD processor and comes standard with 8GB of configurable RAM upgradeable to 32GB. Four 1GbitE LAN ports enable link aggregation for high throughput and failover support, with an optional 10GbitE network port. It comes with Synology DiskStation Manager (DSM), which includes on-site or cloud-integrated backup, data encryption, data sharing, synchronization, and surveillance. It is available immediately, beginning at $2399. The devices include a two-year hardware warranty and for devices with factory-installed and validated drives, two years of Data Recovery Service.
Jeffrey Wang.
…
Big memory supplier MemVerge has appointed Jeffrey Wang as its VP of engineering. He comes from being Area VPE, cyber security division at Arista Networks. Before that he was VP engineering at Awake Security, which was acquired by Arista Networks.
…
NAND and SSD supplier Solidigm, an SK hynix subsidiary, is spending $25 million improving its three new Rancho Cordoba offices. Solidigm pulled about 800 employees out of Intel, many of them from its Folsom campus. The Solidigm employees are working in temporary space or remotely. There are about 1,000 Solidigm employees now tied to the Rancho Cordova office, and the company anticipates growing the operation to 1,900 employees locally by 2027. It’s good to hear about tech industry recruitment in these days of layoffs at Google, Microsoft and others. The Rancho Cordova offices will include engineers and scientists, and teams in sales, marketing, communications, human resources, operations and finance. The first Solidigm building there to open, expected next month, will be general office space. A research and development lab office will open later this year.
…
Quest Software announced GA of SharePlex 11, enabling active-active database replication across PostgreSQL and Snowflake environments. It has conflict resolution to ensure high availability, disaster recovery and horizontal scaling. SharePex supports active-active replication between Oracle and PostgreSQL, also with conflict resolution. The replication to Snowflake enables the creation of data pipelines into the Snowflake Data Cloud. There is also the ability to move data from PostgreSQL to targets like Kafka and SQL Server for real-time analytics and integration.
…
Snowflake announced an agreement with Mobilize Net to acquire SnowConvert, a suite of tools to help enterprises migrate their databases to the Snowflake data cloud. Financial terms were not disclosed. A legacy database can have millions of lines of DDL, BTEQ and thousands of objects. To ensure a successful migration, this code needs to be rebuilt and made equally functional on the other side. SnowConvert uses sophisticated automation techniques with built-analysis and matching to recreate functionally equivalent code for tables, views, stored procedures, macros and BTEQ files in Snowflake. It can migrate databases from any source data platform (such as Oracle, Teradata or Spark) and cut down the time and effort spent on manual coding. According to Snowflake, the toolkit has already been used to convert more than 1.5 billion lines of code.
…
TNAS Mobile 3 smartphone screenshot
TerraMaster announced the TNAS Mobile 3 – a dedicated mobile client app developed for remote storage management for TNAS devices running on the TOS 5 operating system. The app comes with two-factor authentication and functions including phone backup, photo management, personal folder, team folder, file sharing, personal storage, coffer, remote administrator, and more. TNAS Mobile 3 is available on both Android and iOS.