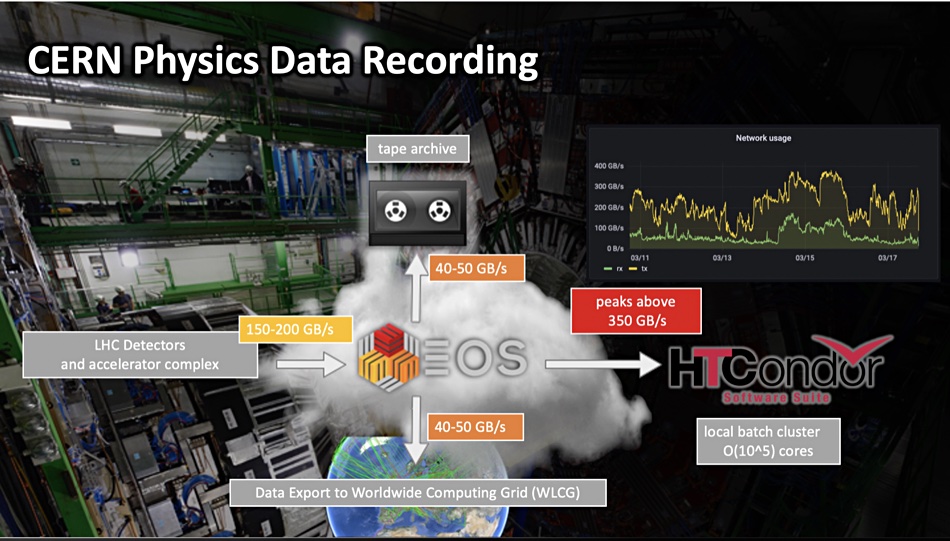
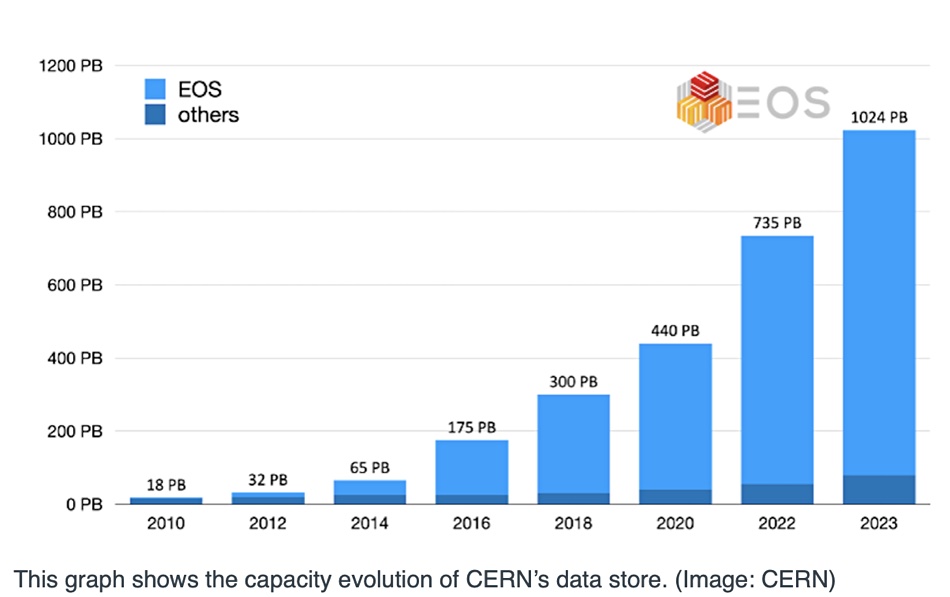
The reason that CERN, Europe’s atom-smashing institution, can store more than an exabyte of online data comes down to its in-house EOS filesystem.
EOS was created by CERN staff in 2010 as an open source, disk-only, Large Hadron Collider data storage system. Its capacity was 18PB in its first iteration – a lot at the time. When atoms are smashed into one another they generate lots of sub-atomic particles and the experiment recording instruments generate lots of data for subsequent analysis of particles and their tracks.
The meaning of the EOS acronym has been lost in time; one CERN definition is that it stands for EOS Open Storage, which is a tad recursive. EOS is a multi-protocol system based on JBODs and not storage arrays, with separate metadata storage to help with scaling. CERN used to have a hierarchical storage management (HSM) system, but that was replaced by EOS – which is complemented with a separate tape-based cold data storage system.
There were two originial EOS data centers: one at CERN in Meyrin, Switzerland, and the other in the WIGNER center in Budapest, Hungary. They were separated by 22ms network latency in 2015. CERN explains that EOS is now deployed “in dozens of other installations in the Worldwide LHC Computing GRID community (WLCG), at the Joint Research Centre of the European Commission and the Australian Academic and Research Network.”
EOS places a replica of each file in each datacenter. CERN users (clients) can be located anywhere, and when they access a file the datacenter closest to them serves the data.
EOS is split into independent failure domains for groups of LHC experiments, such as the four largest particle detectors: LHCb, CMS, ATLAS, and ALICE.
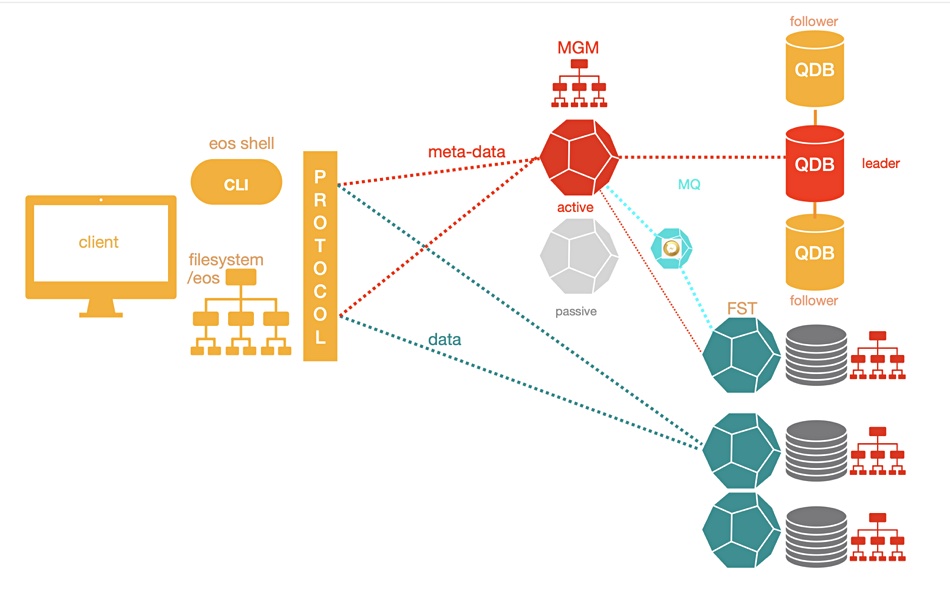
As shown in the diagram below, the EOS access path has one route for metadata using an MGM (metadata generation mechanism) service and another route for data using FST. The metadata is held in memory on metadata service nodes to help lower file access latency. These server nodes are active-passive pairs with real-time failover capability. The metadata is persisted to QuarkDB – a high-availability key:value store using write-ahead logs.
Files are stored on servers with locally-attached drives, the JBODs, distributed in the EOS datacenters.
Each of the several hundred data-holding server nodes has between 24 and 72 disks, as of 2020. Files are replicated across JBOD disks, and EOS supports erasure coding. Cluster state and configuration changes are exchanged between metadata servers and storage with an MQ message queue service.
The MGM, FST and MQ services were built using an XRootD client-server setup, which provides a remote access protocol. EOS code is predominantly written in C and C++ with a few Python modules. Files can be accessed with a Posix-like FUSE (Filesystem in Userspace) SFTP client, HTTPS/WebDav or the Xroot protocol – also CIFS (Samba), S3 (MinIO), and GRPC.
The namespace (metadata service) of EOS5 (v5.x) runs on a single MGM node, as above, and is not horizontally scalable. There could be standby nodes to take over the MGM service if the active node becomes unavailable. A CERN EOS architecture document notes: “The namespace is implemented as an LRU driven in-memory cache with a write-back queue and QuarkDB as external KV store for persistency. QuarkDB is a high-available transactional KV store using the RAFT consensus algorithm implementing a subset of the REDIS protocol. A default QuarkDB setup consists of three nodes, which elect a leader to serve/store data. KV data is stored in RocksDB databases on each node.”
Client users are authenticated, with a virtual ID concept, by KRB5 r X509, OIDC, shared secret, JWT and proprietary token authorization.
EOS provides sync and share capability through a CERNbox front-end service with each user having a terabyte or more of disk space. There are sync clients for most common systems.
The tape archive is handled by CERN Tape Archive (CA) software, and it uses EOS as the user-facing, disk-based front end. Its capacity was set to exceed 1EB this year as well.
Capacity growth seems to be accelerating.
Exabyte-level EOS can now store a million terabytes of data on its 111,000 drives – mostly disks with a few SSDs – and an overall 1TB/sec read bandwidth. Back in June last year it stored more than 7 billion files in 780PB of disk capacity using more than 60,000 disk drives. The user base then totalled 12,000-plus scientists from institutes in 70-plus countries. Fifteen months later the numbers are even larger, and set to go higher. The EOS acronym could reasonably stand for Exabyte Open Storage.
Decentralized storage provider Storj has announced a new integration with Adobe Premiere Pro, and says its revenues are growing 226 percent year on year.
Premiere Pro is professional video editing software used by artists and editors worldwide. They need to collectively work on media projects, such as special effects and video sequencing, and share project work with other team members. In other words, media files need storing and moving between the teams. Storj supplies a worldwide cloud storage facility based on spare datacenter capacity organized into a single virtual data store with massive file and object sharding across multiple datacenters, providing error-coded protection and parallel access for file and object read requests. Adobe has selected Storj as its globally distributed cloud storage for Premiere Pro.
Storj’s 226 percent growth has brought it customers and partners such as Toysmith, Acronis, Ad Signal, Valdi, Cribl, Livepeer, Bytenite, Cloudvice, Amove, and Kubecost. The growth has been helped by a University of Edinburgh report showing a a 2-4x factor improvement in Storj’s transfer performance over the prior year. It found speeds of up to 800 Mbps when retrieving large quantum physics data sets from Storj’s network.
The university’s Professor Antonin Portelli stated: “You can really reach very fast transfer rates thanks to parallelism. And this is something which is built-in natively in the Storj network, which is really nice because the data from many nodes are scattered all over the world. So you can really expect a good buildup of performances.”
Storj says it reduces cloud costs by up to 90 percent compared to traditional cloud providers, and also cuts carbon emissions by using existing, unused hard drive capacity. However, these hard drives have embodied carbon costs, so-called Scope 3 emissions accumulated during their manufacture, which will be shared between the drive owner and the drive renter (Storj).
It also cites a Forrester Object Storage Landscape report which suggests “decentralization of data storage will disrupt centralized object storage providers as computing shifts to the edge.” Storj is listed as one of 26 object storage vendors covered by the report, which costs $3,000 to access.
Bootnote
Scope 1, 2, and 3 emissions were first defined in the Green House Gas Protocol of 2001.
Scope 1 emissions come directly from an organization’s own operations – burning fuel in generators or vehicles.
Scope 2 emissions come indirectly from the energy that an organization buys, such as electricity, the generation of which causes greenhouse gas emissions.
Scope 3 emissions are those an organization is indirectly responsible for when it buys, uses, and disposes of products from suppliers. These include all sources not within the Scope 1 and 2 boundaries.
Commissioned: Generative AI runs on data, and many organizations have found GenAI is most valuable when they combine it with their unique and proprietary data. But therein lies a conundrum. How can an organization tap into their data treasure trove without putting their business at undue risk? Many organizations have addressed these concerns with specific guidance on when and how to use generative AI with their own proprietary data. Other organizations have outright banned its use over concerns of IP leakage or exposing sensitive data.
But what if I told you there was an easy way forward already sitting behind your firewall either in your datacenter or on a workstation? And the great news is it doesn’t require months-long procurement cycles or a substantial deployment for a minimum viable product. Not convinced? Let me show you how.
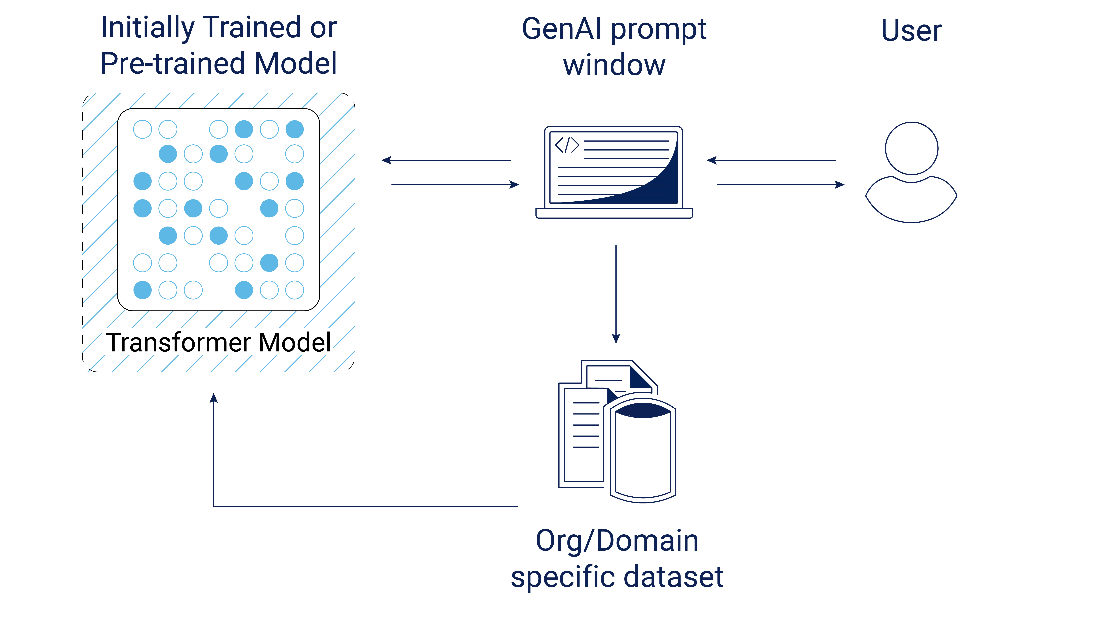
Step 1: Repurpose existing hardware for trial Depending on what you’re doing with generative AI, workloads can be run on all manner of hardware in a pilot phase. How? There are effectively four stages of data science with these models. The first and second, inferencing and Retrieval-Augmented-Generation (RAG), can be done on relatively modest hardware configurations, while the last two, fine-tuning/retraining and new model creation, require extensive infrastructure to see results. Furthermore, models can be of various sizes and not everything has to be a “large language model”. Consequently, we’re seeing a lot of organizations finding success with domain-specific and enterprise-specific “small language models” that are targeted at very narrow use cases. This means you can go repurpose a server, find a workstation a model can be deployed on, or if you’re very adventurous, you could even download LLaMA 2 onto your laptop and play around with it. It’s really not that difficult to support this level of experimentation.
Step 2: Hit open source Perhaps nowhere is the open-source community more at the bleeding edge of what is possible than in GenAI. We’re seeing relatively small models rivaling some of the biggest commercial deployments on earth in their aptitude and applicability. The only thing stopping you from getting started is the download speed. There are a whole host of open-source projects at your disposal, so pick a distro and get going. Once downloaded and installed, you’ve effectively activated the first phase of GenAI: inferencing. Theoretically your experimentation could stop here, but what if with just a little more work you could unlock some real magic?
Step 3: Identify your use cases You might be tempted to skip this step, but I don’t recommend it. Identify a pocket of use cases you want to solve for. The next step is data collection and you need to ensure you’re grabbing the right data to deliver the right results via the open source pre-trained LLM you’re augmenting with your data. Figure out who your pilot users will be and ask them what’s important to them – for example, a current project they would like assistance with and what existing data they have that would be helpful to pilot with.
Step 4: Activate Retrieval-Augmented-Generation (RAG) You might think adding data to a model sounds extremely hard – it’s the sort of thing we usually think requires data scientists. But guess what: any organization with a developer can activate retrieval-augmented generation (RAG). In fact, for many use cases this may be all you will ever need to do to add data to a generative AI model. How does it work? Effectively RAG takes unstructured data like your documents, images, and videos and helps encode them and index them for use. We piloted this ourselves using open-source technologies like LangChain to create vector databases which enable the GenAI model to analyze data in less than an hour. The result was a fully functioning chatbot, which proved out this concept in record time.
Source: Dell Technologies
In Closing
The unique needs and capabilities of GenAI make for a unique PoC experience, and one that can be rapidly piloted to deliver immediate value and prove its worth to the organization. Piloting this in your own environment offers many advantages in terms of security and cost efficiencies you cannot replicate in the public cloud.
Public cloud is great for many things, but you’re going to pay by the drip for a PoC, it’s very easy to burn through a budget with users who are inexperienced at prompt engineering. Public cloud also doesn’t offer the same safeguards for sensitive and proprietary data. This can actually result in internal users moving slower as they think through every time they use a generative AI tool whether the data they’re inputting is “safe” data that can be used with that particular system.
Counterintuitively, this is one of the few times the datacenter offers unusually high agility and a lower up front cost than its public cloud counterpart.
So go forth, take an afternoon and get your own PoC under way, and once you’re ready for the next phase we’re more than happy to help.
Veeam can now back up Microsoft 365 and Azure with its Cirrus by Veeam service.
Backup delivered as a Software-as-a-service (SaaS) has been the focus of suppliers such as Asigra, Clumio, Cohesity, Commvault with its Metallic offering, Druva, HYCU, and OwnBackup, which believe SaaS is the new backup frontier. Up until now, Veeam has been largely absent from this market, apart from a February 2023 partnership deal with Australian business CT4. This has now blossomed into buying CT4’s Cirrus cloud-native software, which provides the BaaS layer on top of Veeam’s backup and restore software.
Danny Allan
CTO Danny Allan said the company is “the #1 global provider of data protection and ransomware recovery. We’re now giving customers those trusted capabilities – for Microsoft 365 and for Microsoft Azure – delivered as a service.”
Cirrus for Microsoft 365 builds on Veeam Backup for Microsoft 365 and delivers it as a service. Cirrus Cloud Protect for Microsoft Azure is a fully hosted and pre-configured backup and recovery offering.
Veeam says its customers now have three options for protecting Microsoft 365 and Azure data:
Cirrus by Veeam: a SaaS experience, without having to manage the infrastructure or storage.
Veeam Backup for Microsoft 365 and Veeam Backup for Microsoft Azure: Deploy Veeam’s existing software solutions for Microsoft 365 and Azure data protection and manage the infrastructure.
A backup service from a Veeam service provider partner: Built on top of the Veeam platform, with value-added services unique to the provider’s area of expertise.
Veeam has invested in Alcion, a SaaS backup startup founded by Niraj Tolia and Vaibhav Kamra. The two founded container app backup outfit Kasten, which was bought by Veeam for $150 million in 2020. The company now has two BaaS bets, with Cirrus looking much stronger than Alcion. The company and its partners can now sell the Cirrus Microsoft 365 and Azure BaaS offerings into Veeam’s 450,000 customer base and hint at roadmap items extending coverage to other major SaaS app players.
It has to extend its BaaS coverage to other major SaaS apps such as Salesforce and ServiceNow, and on to second tier SaaS apps as well, if it is going to catch up with the existing SaaS backup suppliers. That means it has to decide how to solve the connector-build problem to extend its coverage to the tens of thousands of SaaS apps in existence. Our thinking is that it will rely on its existing market dominance and attractiveness as a backup supplier, and provide an SDK for SaaS app developers to use.
Dan Pearson
When the BaaS partnership was announced, Dan Pearson, CT4’s founder, CEO and CTO, said: “We recognize that technologies are continually evolving, along with the ever-changing needs of our clients, so we’re developing new Veeam-powered offerings like Cirrus for Cloud Protect Azure, Cirrus for Cloud Protect AWS, and Cirrus for Salesforce. Our vision is for Cirrus to be considered the only data protection solution for SaaS products globally. This is the cornerstone of our business and go-to market strategy, and Veeam is supporting us every step of the way.”
Not so much now. CT4 is still a partner, but Cirrus development is in Veeam’s hands alone. We think it will throw development resources at it to become a major force in the market with common management and security across its on-premises VM, container, and SaaS backup offerings.
Cirrus by Veeam is available now via here, on the Azure Marketplace, and all existing Cirrus channels, and will soon be expanded to Veeam’s additional routes to market. Veeam will launch a new, enhanced, and fully integrated version of the BaaS offering in Q1 2024, available through Veeam service providers, the Microsoft Azure marketplace, and Veeam’s online store.
Nutanix says it updated its Data Lens SaaS software to detect a threat within 20 minutes, help prevent further damage, and start a single-click recovery process.
Nutanix SVP Lee Caswell told B&F last year that Data Lens, a cloud-based data governance service, helps customers proactively assess and mitigate security risks. Data Lens applies real-time analytics and anomaly detection algorithms to unstructured data stored on Nutanix Unified Storage platform. The latest version adds the 20-minute attack detection timing and Nutanix Object support to the existing Nutanix Files support.
Thomas Cornely, SVP, Product Management at Nutanix, said: “With these new ransomware detection and recovery features, the Nutanix Cloud Platform provides built-in ransomware protection, data visibility and automated data governance for Nutanix Files and Objects across clouds to simplify data protection and strengthen an organization’s cyber resilience posture.”
Data Lens screenshot
Data Lens detects known ransomware variants through signature recognition. Unknown variants are detected by behavioral monitoring using audit trail data to find access pattern anomalies. Admin and other nominated staff receive real-time ransomware attack alerts. They can stop the attack, find out which files have been affected and recover them manually or automatically from the latest clean snapshots.
Robert Pohjanen, IT Architect at Nutanix customer LKAB, added: “Tools like Data Lens give us the insights we need to understand who is accessing our data, if it’s appropriate access, or if there is an attempt to misuse or attack our data. The forensics and the new permissions and access risk views are important tools to keep our data safe from malicious users, or from threats such as ransomware.”
The 20-minute detection window suggests that snapshots, at least of critical files and objects, need to be taken with no more than 20 minute intervals, and preferably even shorter time gaps.
Scott Sinclair, practice director with the Enterprise Strategy Group, commented: “Rapid detection and rapid recovery are two of the most critical elements in successful ransomware planning, yet remain a challenge for many organizations especially as they manage data across multiple clouds.” Nutanix now has “cyber resilience integrated at the unstructured data layer to simplify cyber resilience while accelerating both detection and recovery.”
Check out more Data Lens information, including a video, here.
Nasuni has hired a CMO to to push its cloud file services offering deeper into the market.
The company hired Pete Agresta from Pure to be CRO in January and Jim Liddle, the ex-CEO of acquired Storage Made Easy, and data intelligence technology promotor, was appointed to the Chief Innovation Officer role in August. Now Asim Zaheer is the new CMO, a role previously held by Nasuni president David Grant from June 2019 to April 2021.
Asim Zaheer
Zaheer was CMO of Glassbox before coming to Nasuni, and has a 10-plus year stint as CMO of storage system supplier Hitachi Vantara prior to that. Two other execs have been appointed at the same time as Zaheer; Matthew Grantham is head of Worldwide Partners and Curt Douglas becomes VP Sales Western Region, coming from Nutanix, and periods at NetApp, IBM and EMC.
Grant said in a statement: “Asim’s wealth of experience and the expertise Matthew and Curt bring to their roles will help propel Nasuni forward as we bring much-needed disruption to traditional file infrastructure and strategically grow our market share in the US and Europe.”
In his view: “Legacy file systems simply aren’t enough for the demands of today’s enterprises, which require cloud migration, advanced ransomware protection, and hybrid workforce support.”
A Zaheer quote said: “In my conversations with customers it is clear that enterprises need to replace traditional hardware-based file storage and data protection systems with a scalable cloud-native solution.” They are both expressing the traditional Nasuni view that on-premises filers, exemplified by NetApp, need replacing by its cloud-based file data services product.
Matthew Grantham previously served as Global VP for channel sales for Hyperscience and had exec channel leadership roles at TenFold, Fuze, and others before that.
Nasuni is growing fast, with more than 800 customers in 70+ countries. It went past the $100 million annual recurring revenue mark last year, raising $60 million in an I-round funding exercise that year too. It may be a coincidence but NetApp product sales have been declining. They were $730 million in its first fiscal 2022 quarter, rising to $894 million in the fourth fiscal 2022 quarter, but were reported to be $590 million in NetApp’s first fiscal 2024 quarter in August.
Perhaps the efforts of Nasuni and its relative peers CTERA, Egnyte and Panzura, are having an effect.
With Liddle having an AI aspect to his position we can expect Nasuni to be making generative AI enhancements to its File Data Platform offering shortly. The $60 million funding round means Nasuni can afford to spend money on engineering, and no supplier of storage and data products and services can afford to be left behind in the current wave of AI hype. Egnyte’s AI activities will encourage Nasuni to move faster.
Sandra L. Rivera is executive vice president and chief people officer at Intel Corporation. (Credit: Intel Corporation)
Intel is moving its Altera FPGA-based Programmable Solutions Group (PSG), which are used in its Infrastructure Processing Units (IPU) and other products, into a separate business unit with an IPO planned for 2026/2027.
Update. Intel’s IPUs are the responsibility of its Network and Edge Group (NEX), not PSG. Hence OSG issues re IPUs have been transferred to NEX. 10 Oct 2023.
The main news is covered in this Register report but we’re going to look into the IPU angle here. The Mount Evans IPU, now called the IPU E2000, sits between an x86 processor and its network connections and offloads low-level network, security, and storage processing, so-called infrastructure processing, from the host CPU.
Other vendors such as startups Fungible and Pensando called their similar products Data Processing Units (DPUs) but IPU seems a more accurate term, especially as an x86 CPU processes application and infrastructure data as well as code.
IPUs are said to enable host server CPUs to do more application work and free it up from doing internal device-to-device, east-west type processing in a datacenter. The more servers you have, the more benefits you get from offloading them. That meant hyperscalers were the initial market with enterprises reluctant to buy due to cost, lack of standards and server OEM support. Nvidia’s BlueField smart NIC has IPU-type functionality and muddied the marketing waters.
AWS has developed its own DPU technology with its Nitro ASIC card, reducing the prospective market for the startups. Pensando and its Arm-based IPU product was bought by AMD in April last year for $1.9 billion and AMD is now selling its Pensando DSC2-200 product to cloud providers such as Azure and other hyperscaler customers.
Fungible was bought by Microsoft for $190 million at the end of 2022 for its datacenter infrastructure engineering team’s use. That means Azure and that in turn threatens the AMD Pensando business.
Intel has three IPU technologies: Big Springs Canyon, Oak Springs Canyon, and Mount Evans, based on FPGA or ASIC technology. Both Mount Evans and Oak Springs Canyon are classed as 200GB products.
Big Springs Canyon is built around a system-on-chip (SoC) Xeon-D CPU with Ethernet connectivity. Oak Springs Canyon was its first gen 2 product and uses Agilex-brand FPGA technology with the Xeon-D SoC. It supports PCIe gen 4 as well as 2 x 100Gbit Ethernet. Intel is shipping Oak Springs Canyon to Google and other service providers.
The second gen 2 Intel IPU is called Mount Evans and uses an ASIC instead of an FPGA, featuring 16 Arm Neoverse N1 cores. ASICs are custom-designed for a workload whereas FPGAs are more general in nature, hence ASICs can be faster. Mount Evans was designed in conjunction with Google Cloud and includes a hardware-accelerated NVM storage interface scaled up from Intel Optane technology to emulate NVMe devices. It is shipping to Google and other service providers.
Intel’s NEX business unit, led by Sachin Katti whom was appointed SVP and GM for NEX in February, has these three IPUs in its product portfolio plus an IPU development roadmap. This mentions the 400GB Mount Morgan and Hot Springs Canyon gen 3 products, and a subsequent unnamed 800GB IPU product, presumably gen 4. Mount Morgan is ASIC-based, following on from Mount Evans, while Hot Springs Canyon is FPGA-based, succeeding the Oak Springs Canyon product. Both are scheduled to ship in the 2023/2024 period. The 800GB product is slated to ship in 2025/2026.
Sandra Rivera
PSG standalone operations will start on January 1 with CEO Sandra Rivera in charge, currently the EVP and GM in charge of Intel’s Datacenter and AI unit, and possible private investors putting money in before the IPO.
AWS and Azure have in-house IPU technologies and don’t appear to be potential Intel IPU customers. Nvidia looks set to take a large share of the enterprise SmartNIC/DPU market, potentially limiting Intel’s ability to expand IPU sales into general large server farm enterprises.
Google can develop its own semiconductor products like its AI-accelerating Tensor Processing Unit. That is a potential threat to Intel, which gets enormous market credibility as an IPU supplier with this Google deal. Katie’s NEX needs to ensure the Google co-development continues.
Four block storage suppliers use public cloud ephemeral storage drive instances. So can they be persistent despite being ephemeral?
Yes and no. Let’s take the three public clouds one by one and look at their ephemeral storage, and then take a gander at each four suppliers that provide storage software in the cloud based on this ephemeral storage.
Amazon
The Elastic Compute Cloud (Amazon EC2) service provides on-demand, scalable computing capacity in the AWS cloud. An Amazon user guide says EC2 instance store provides temporary block-level storage for instances. This storage is located on disks that are physically attached to the host computer. Specifically the virtual devices for instance store volumes are ephemeral[0-23] where [0-23] is the number of ephemeral volumes. The data on an instance store volume persists only during the life of the associated instance – if you stop, hibernate, or terminate an instance, any data on instance store volumes is lost. That’s why it’s called ephemeral.
The EC2 instance is backed by an Amazon Elastic Block Store (EBS) volume which provides durable, block-level storage volumes that you can attach to a running instance. The volume persists independently from the running life of an instance.
Azure
Azure’s ephemeral OS disks, actually SSDs, are different from its persistent disks. They are locally attached storage components of a virtual machine instance – either in VM Cache or VM Temp disk – and their contents, which are stored in SSDs, are not available after the instance terminates.
Azure documentation explains: “Data Persistence: OS disk data written to OS disk are stored in Azure Storage” whereas with ephemeral OS disk: “Data written to OS disk is stored on local VM storage and isn’t persisted to Azure Storage.”
When a VM instance restarts, the contents of its persistent storage are still available. Not so with ephemeral OS disks, where the SSDs used can have fresh contents written to them by another public cloud user after the instance terminates.
The Azure documentation makes it clear: “Ephemeral OS disks are created on the local virtual machine (VM) storage and not saved to the remote Azure Storage. … With Ephemeral OS disk, you get lower read/write latency to the OS disk and faster VM reimage.”
Also: “Ephemeral OS disks are free, you incur no storage cost for OS disks.” That is important for our four suppliers below, as we shall see.
Google
Google also makes a distinction between local ephemeral SSDs and persistent storage drives. A web document reads: “Local solid-state drives (SSDs) are fixed-size SSD drives, which can be mounted to a single Compute Engine VM. You can use local SSDs on GKE to get highly performant storage that is not persistent (ephemeral) that is attached to every node in your cluster. Local SSDs also provide higher throughput and lower latency than standard disks.”
It explains: “Data written to a local SSD does not persist when the node is deleted, repaired, upgraded or experiences an unrecoverable error. If you need persistent storage, we recommend you use a durable storage option (such as persistent disks or Cloud Storage). You can also use regional replicas to minimize the risk of data loss during cluster lifecycle or application lifecycle operations.”
Google Kubernetes engine documentation reads: “You can use local SSDs for ephemeral storage that is attached to every node in your cluster.” Such raw block SSDs have an NVMe interface. “Local SSDs can be specified as PersistentVolumes. You can create PersistentVolumes from local SSDs by manually creating a PersistentVolume, or by running the local volume static provisioner.”
Such “PersistentVolume resources are used to manage durable storage in a cluster. In GKE, a PersistentVolume is typically backed by a persistent disk. You can also use other storage solutions like NFS. … the disk and data represented by a PersistentVolume continue to exist as the cluster changes and as Pods are deleted and recreated.”
Our takeaway
In summary we could say the ephemeral storage supplied by AWS, Azure, and Google for VMs and containers is unprotected media attached to a compute instance. This storage is typically higher speed than persistent storage, much lower cost, and has no storage services, such as snapshotting, compression, deduplication, or replication.
Further, suppliers such as Silk, Lightbits, Volumez or Dell’s APEX Block Storage provide public cloud offerings that enhance the capabilities of either the native ephemeral media or persistent block storage, adding increased resiliency, faster performance, and the necessary data services organizations require.
Let’s have a look at each of the four.
Dell APEX Block Storage
Alone of the mainstream incumbent vendors, Dell offers an ephemeral block storage offering called Dell APEX Block Storage. AWS says Dell APEX Block Storage for AWS is the PowerFlex software deployed in its public cloud: “With APEX Block Storage, customers can move data efficiently from ground to cloud or across regions in the cloud. Additionally, it offers enterprise-class features such as thin provisioning, snapshots, QoS and volume migration across storage pools.”
There is a separate Dell APEX Data Storage Services Block which is not a public cloud offering using AWS, Azure or Google infrastructure. Instead customers utilize the capacity and maintain complete operational control of their workloads and applications, while Dell owns and maintains the PowerFlex-based infrastructure, located on-premises or in a Dell-managed interconnected colocation facility. There is a customer-managed option as well.
A Dell spokesperson tells us that, in terms of differentiation, Dell APEX Block Storage offers two deployment options to customers: A performance optimized configuration that uses EC2 instance store with ephemeral storage attached to it; and a balanced configuration that uses EC2 instances with EBS volumes (persistent storage) attached to it.
Dell says APEX Block Storage offers customers superior performance by delivering millions of IOPS by linearly scaling up to 512 storage instances and/or 2048 compute instances in the cloud. It offers unique Multi-AZ durability by stretching data across three or more availability zones without having to replicate the data.
Lightbits
Lightbits documentation states: “Persistent storage is necessary to be able to keep all our files and data for later use. For instance, a hard disk drive is a perfect example of persistent storage, as it allows us to permanently store a variety of data. … Persistent storage helps in resolving the issue of retaining the more ephemeral storage volumes (that generally live and die with the stateless apps).”
We must note that a key differentiation point to make regarding ephemeral (local) storage, is that it requires running the compute and the storage in the same VM or instance – the user cannot scale them independently.
It says its storage software creates “Lightbits persistent volumes [that] perform like local NVMe flash. … Lightbits persistent volumes may even outperform a single local NVMe drive.” By using Lightbits persistent volumes in a Kubernetes environment, applications can get local NVMe flash performance and maintain the portability associated with Kubernetes pods and containers.
Abel Gordon, chief system architect at Lightbits, told us: “While the use of local NVMe devices on the public cloud provides excellent performance, users should be cognizant of the tradeoffs, such as data protection – because the storage is ephemeral – scaling, and lack of data services. Lightbits offers an NVMe/TCP clustered architecture with performance that is comparable to the instances with local NVMe devices. With Lightbits there is no limitation with regard to the IOPS per gigabyte; IOPS can be in a single volume or split across hundreds of volumes. The cost is fixed and predictable – the customer pays for the instances that are running Lightbits and the software licenses … For Lightbits there is no additional cost for IOPS, throughput, or essential data services.”
Silk
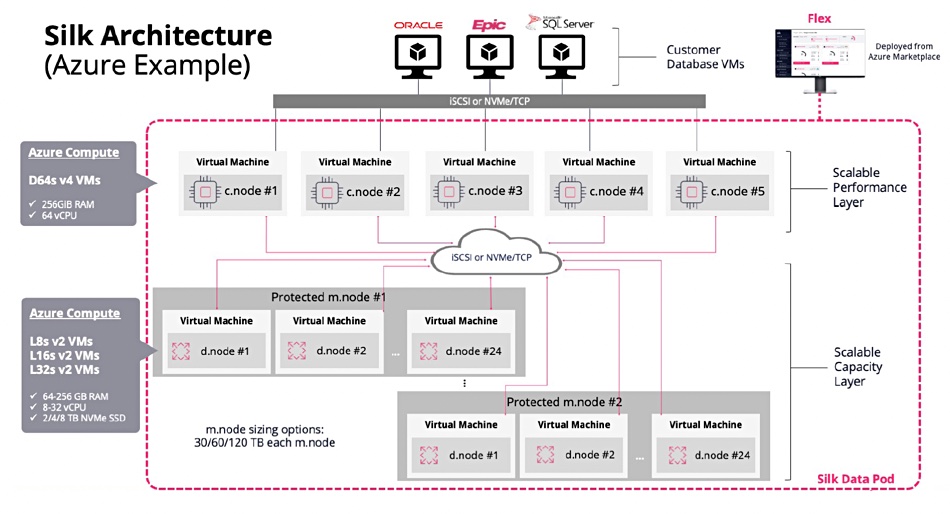
Silk, which supplies ephemeral disk storage for AWS, Azure and the Google Cloud, has two sets of Azure Compute instances running in the customer’s own subscription. The first layer (called c.nodes – compute nodes) provide the block data services to the customer’s database systems, while the second layer (the d.nodes – data nodes) persists the data.
Tom O’Neil, Silk’s VP products, told B&F: “Silk optimizes performance and minimizes cost for business-critical applications running in the cloud built upon Microsoft SQL Server and Oracle and deployed on IaaS. Other solutions are focused more on containerized workloads or hybrid cloud use cases.”
Volumez
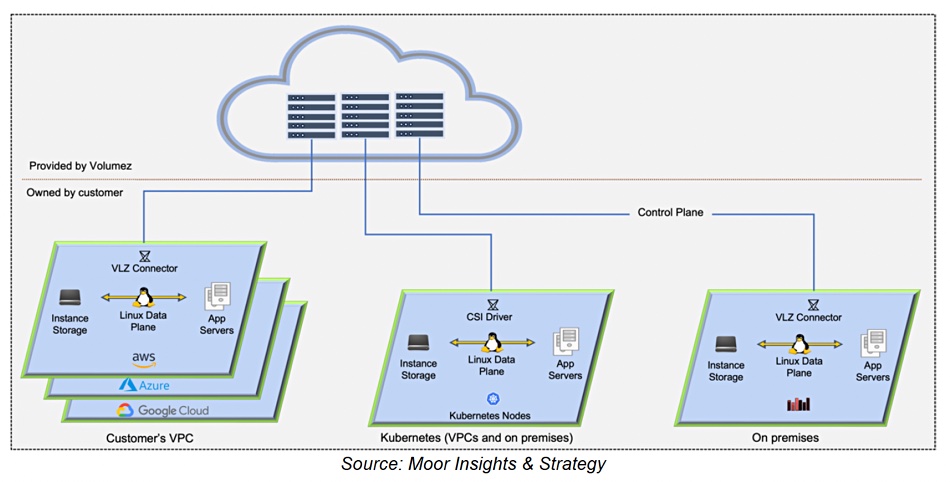
Volumez is composable infrastructure software for block and file storage in the cloud (AWS, Azure) and used by developers to request storage resources, similar to the way they request CPU and memory resources in Kubernetes. It separates the Volumez cloud-hosted storage control plane, data plane, which runs in customer virtual private clouds and datacenters. The Volumez control plane connects NVMe instance storage to compute instances over the network, and composes a dedicated, pure Linux storage stack for data services on each compute instance. The Volumez data path is direct from raw NVMe media to compute servers, eliminating the need for storage controllers and software-defined storage services.
Volumez architecture diagram from Moor Insights and Strategy.
The vendor says it “profiles the performance and capabilities of each infrastructure component and uses this information to compose direct Linux data paths between media and applications. Once the composing work is done, there is no need for the control plane to be in the way between applications and their data. This enables applications to get enterprise-grade logical volumes, with extreme guaranteed performance, and enterprise-grade services that are built on top of Linux – such as snapshots, thin provisioning, erasure coding, and more.”
It claims it provides unparalleled low latency, high bandwidth, and unlimited scalability. You can download a Volumez white paper here to find out more.
Dell has updated its PowerFlex block storage offering and introduced APEX Block Storage for Azure, so providing three APEX block storage environments: on-premises, in AWS, and now in Microsoft’s cloud.
Dell says PowerFlex, the code base for APEX Block Storage, has broad support for hyperscaler and container orchestration platforms for block and file, across bare metal and hypervisors. It’s predominantly a block-based storage system but, with PowerFlex file services, its capability to address file use cases has been expanded.
Shannon Champion.
Dell product marketeer Shannon Champion blogs: “The meteoric rise of data, propelled by advancements in artificial intelligence and the spread of connected devices, offers both unprecedented growth potential and significant challenges. While AI-driven insights herald new avenues for business differentiation, the infrastructure underpinning this growth often feels the strain.”
She wants us to understand that the infrastructure burden can be lightened by using APEX block storage technology.
PowerFlex version 4.5
The v4.5 PowerFlex release includes a single global namespace for enhanced capacity and unified storage pool management, plus file scalability improvements like 400 percent increase in NAS Servers and 22x more file snapshots.
It has already received an AWS Outposts Ready designation. We’re told the combination of AWS Outposts and Dell PowerFlex can deliver 12 times more IOPS compared to a native Outposts deployment and the performance can linearly scale with additional compute. It’s able to scale up to 512 storage instances (or nodes) in a single PowerFlex deployment, providing tens of millions of IOPS. These systems can support over 2000 compute instances (nodes) that consume volumes up to a petabyte in usable capacity.
There is more CloudIQ integration with CloudIQ suite capabilities enhancing system visibility, monitoring and real-time license management and covering both PowerFlex and APEX Block Storage for Public Cloud.
This follows Dell’s introduction of APEX Block Storage for AWS earlier this year and provides block storage for applications running Azure. It can be deployed on managed disks for most workloads or on instances with native attached NVMe SSDs for performance-optimized workloads. In the latter case it delivers, Dell says, extreme performance, low latency, unmatched scalability, flexible deployment options, and enterprise-grade resiliency as well as automated deployment.
The scalability extends to independently scaling compute up to 2048 instances or storage up to 512 instances within a single cluster. This, Dell claims, surpasses the limits of native cloud-based storage volumes. It claims the resiliency includes a unique ability to spread data across multiple availability zones, ensuring data access without requiring extra copies of data or replication across zones.
There are thin provisioning, volume migration, asynchronous replication, snapshots and backup/restore data services, with backup copies available for disaster recovery. From the security angle it has role-based access control, single sign on, encryption and federated identity
Suggested workloads that could use his block storage include mission-critical ones like databases, and analytics, dev/test, virtualization and containers. Deployment automation includes intelligence that optimizes the instance types needed to support the capacity and performance requirements of workloads.
Apex Block Storage for Azure features data mobility and interoperability across multi-cloud environments as well as multiple availability zones. A Solution Brief document has more information.
Competitive comparison
With APEX Block Storage (PowerFlex) on-premises, APEX Block Storage for Azure and also for AWS, and AWS Outposts, Dell now has a hybrid-multi-cloud block storage offering.
A comparison with Pure’s Cloud Block Store – its Purity OS ported to the cloud – shows it running in AWS and Azure and so providing a single hybrid multi-cloud environment between Pure on-premises and in AWS and Azure. This is similar to Dell’s APEX Block Store.
Dell has other block storage offerings, including PowerMax and PowerStore. Our understanding is that the PowerStore OS is headed for AWS and Azure and also towards GCP, which is an APEX Block Store (PowerFlex) roadmap item as well.
NetApp’s ONTAP-based Cloud Volumes is available as a first-party service in in AWS, Azure and GCP, having a wider and deeper cloud coverage than APEX Block Storage and Pure’s Cloud Block Store, and provides file, block and object data access.
Our understanding is that HPE will also eventually have a block storage service available on-premises and in the public cloud.
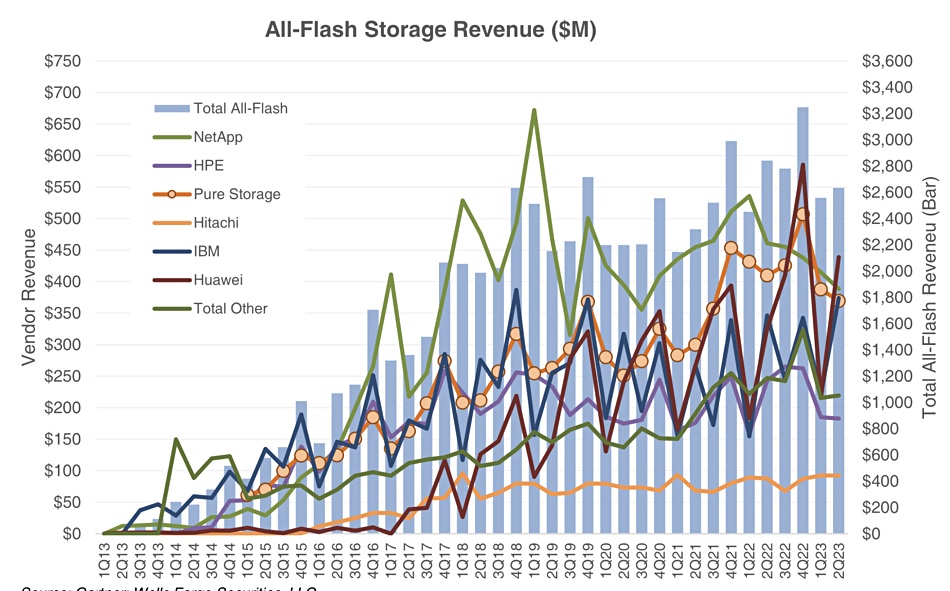
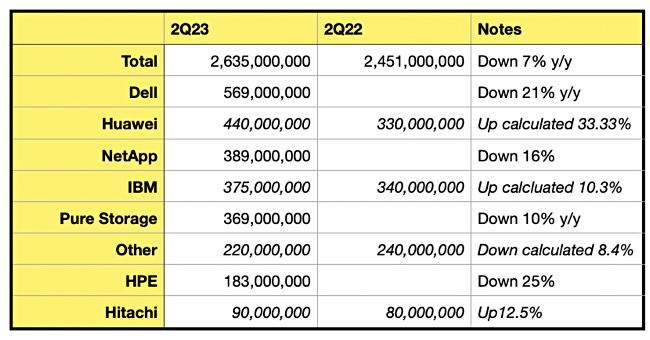
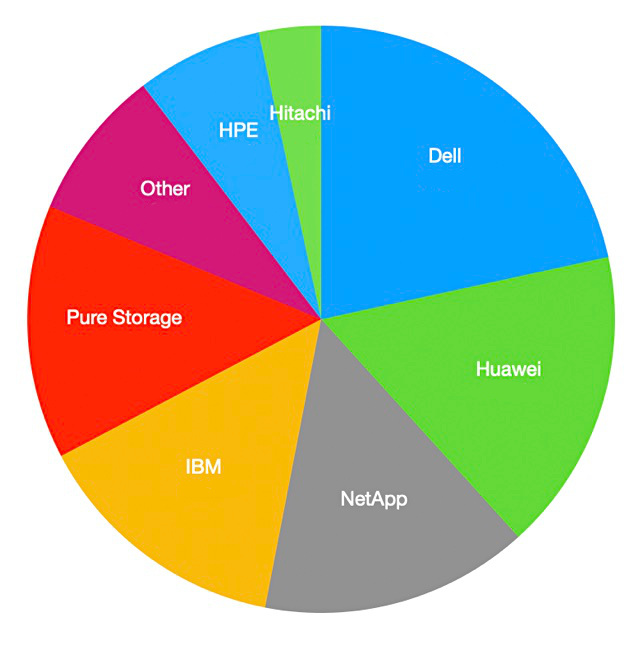
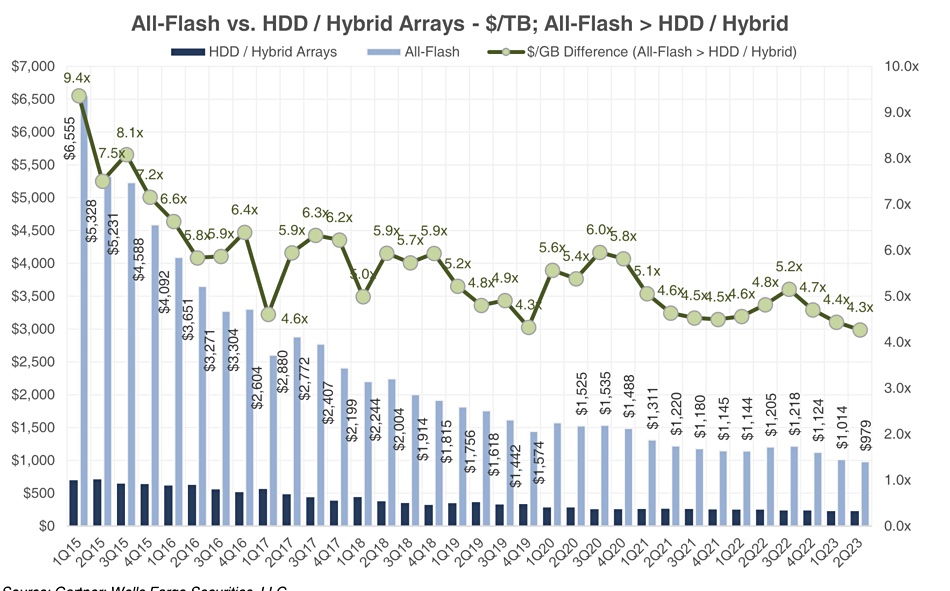
Gartner’s latest external storage market numbers show the total all-flash array market is down 7 percent annually to $2.635 billion, with Huawei up 33 percent – placing it second behind leader Dell, whose share reduced by 21 percent.
Gartner’s analysis of the second 2023 quarter – a summary of which we have seen thanks to Wells Fargo analyst Aaron Rakers – suggests total external storage revenue dropped 14 percent annually to $5.029 billion. Primary storage sank 15 percent, secondary storage decreased 7 percent, and backup and recovery slid 20 percent.
HDD and hybrid revenues were down 21 percent and accounted for 47.6 percent of the market – flash arrays have taken over from disk. Rakers selectively summarizes Gartner’s numbers. We haven’t seen the table of suppliers’ revenues and market shares, but we have made an attempt to fill in the missing numbers by referring to a Gartner/Wells Fargo chart:
This chart shows the dramatic rises in Huawei and IBM’s all-flash array revenues with Huawei eclipsing NetApp and Pure. Dell is not shown on the chart but Gartner says it’s the market leader with $569 million in revenue, 21 percent down on the year. Our table has italicized entries for calculated and estimated numbers:
And we’ve created a pie chart from it to show the rough estimates of supplier shares based on the analysts’ charts:
Rakers writes: “Pure’s revenue share of the all-flash market fell to 14 percent, down from 15.2 percent in the prior quarter and 14.4 percent in the year-ago period.” It is the second quarter in succession that Pure has had a lower share than NetApp and Pure now has lower revenues than in 2021’s fourth quarter.
Rakers estimates Pure’s FlashArray revenues to be $283 million, down 15 percent annually, with FlashBlade bringing in $86 million, up 13 percent year-on-year.
NetApp’s AFA revenue went down more than the market average, at 16 percent annually. Its hybrid/HDD array revenue did worse, falling 47 percent. Its share of the overall storage market, Rakers claims, “fell to a… low of 9.7 percent versus 11.1 percent in the year-ago quarter – the lowest level since 2009.”
HPE’s AFA revenues fell 25 percent annually to $183 million, while Hitachi AFA revenues were, we calculate, $90 million, up 12.5 percent.
Gartner believes AFA array storage costs 4.3 times more on an ASP basis than hybrid/HDD storage down from 4.8x a year ago, and the same as it was at the end of 2019.
Cohesity is expanding its Data Security Alliance ecosystem with six Data Security Posture Management (DSPM) vendors: longstanding partner BigID, Cyera, Dig Security, Normalyze, Sentra, and Securiti.
The Data Security Alliance was set up in November, housing nine members. At the time CEO Sanjay Poonen said: “We are partnering with these industry heavyweights so they can leverage our platform, the Cohesity Data Cloud, to help customers easily integrate data security and resilience into their overall security strategy.”
It is part of Cohesity’s DSPM approach that focuses on data to protect it, with technologies and processes used to identify sensitive data, classify and monitor it, and reduce the risk of unauthorized access to critical data.
We understand that, as the DSPM market is still in its early stages, Cohesity has looked at the plethora of players in the space and rather than picking a single vendor, partnered with the largest share of the market and let its customers decide what’s right for them to best protect against today’s cyber threats.
Cohesity says DSPM is a three-phase process:
Discover and classify data automatically – it continuously finds and labels sensitive, proprietary, or regulated data across all environments, whether on-prem, hybrid, or multicloud.
Detect which data is at risk and prioritize fixing the problem area – by automatically and continuously monitoring for any violations of an organization’s security policies.
Fix data risks and prevent them from reoccurring – any DSPM-discovered data access problem is fixed and the organization’s security posture and policies adjusted to stop a repeat event.
Last month Tata consultancy Services joined Cohesity’s Data Security Alliance, bringing its TCS Cyber Defense Suite portfolio into play. At that point the Data Security Alliance contained 15 members: BigID, Cisco, CyberArk, Mandiant, Netskope, Okta, Palo Alto Networks, PwC UK, Qualys, Securonix, ServiceNow, Splunk, TCS, and Zscaler. BigID is not a new member this month so there are five new members, taking the total to 20 (19 when Cisco buys Splunk).
Cohesity claims that its new DSA group represents the majority of the DSPM market, which means it has 20 partners helping to push its security messaging and services. It is particularly concerned about data in the public cloud, saying 82 percent of breaches involve data stored there. Cloud adoption continues to increase, and copies of data are often shared between clouds without oversight by IT or security, resulting in the growth of shadow data, which is untracked.
Availability
The integration with Normalyze, Cohesity’s initial design partner, is expected to be available within 30 days. The company’s partnership with BigID on enterprise-grade, AI-powered data classification grows through this new integration with SmallID (BigID’s DSPM product) and is expected to be available in 60 days. Additional DSPM partner integrations will be available in the coming months.
CTERA cloud file system users now have access to both file and object data through a single Fusion interface.
The company provides a global file system which can be hosted on a public cloud or on-premises object store, and accessed from a datacenter or remote site using an edge caching device to speed data access. Files are synced and shared between users for collaboration. Now CTERA is providing simultaneous SMB, NFS, and S3 access to the same data set. Cloud applications can connect directly to enterprise file repositories, with no need for an intervening data copy to separate S3 buckets.
Oded Nagel
CTERA CEO Oded Nagel said in a statement: “Fusion extends our vision for the enterprise DataOps platform, enabling organizations not only to store their unstructured data efficiently and securely, but also to unlock its greater potential. By offering easy programmatic access to data, CTERA Fusion allows organizations to implement their own custom data pipelines that operate across multiple access protocols, cloud environments, and remote locations.”
The Fusion software includes:
Single Namespace Across File and Object – interact with data generated at the edge using standard object storage S3 protocols, or access cloud-generated data from the edge using NAS protocols.
Data transfer capabilities like multipart uploads and pre-signed URLs, making ingestion and sharing of large files more efficient.
High availability and scalability.
All data is secured in transit via TLS and encrypted at rest, providing an added layer of protection.
Compatibility with all features of the CTERA Enterprise File Services Platform, including AI-based ransomware protection (CTERA Ransom Protect), WORM compliance (CTERA Vault), and global file collaboration.
Nasuni’s analytics connector creates a read-only temporary copy of file data in S3 so that cloud analytics services can be run against it, but does not natively expose an S3 protocol. Also, based on the information available on Egnyte’s and Panzura’s websites, it appears they do not expose an S3 protocol endpoint. Egnyte, for example, has a virtualized application that can be placed in AWS and will synchronize content stored in Egnyte back to AWS. Also Egnyte provides a way to archive completed projects into lower-cost AWS S3 storage. The file and object domains are kept at relative arms length.
A Panzura spokesperson told us: “Panzura provides SMB and NFS access to the same dataset today. The company refers to that as ‘mixed mode.’ It is in progress on S3 access, and it’s on their roadmap for 2024.”










")