Pure Storage has chopped up to 275 employees globally, marking another round of layoffs.
Update: Zeoli attribution of VAST having a 6 percent share of the data center all-flash array market removed. 10 February 2024.
We’re told the all-flash array supplier’s data protection, AI & analytics, database, alliances, and unstructured data areas are affected, and the reductions amount to some 4 percent of Pure’s workforce.
A spokesperson at Pure told Blocks and Files: “As Pure continues to scale and maintain a record of high growth and innovation, we recently completed a workforce rebalancing initiative to align our employees with company priorities and areas that are strategic to the business. The employees affected by this initiative were eligible to apply to open roles and also offered outplacement services to assist with their job search outside of Pure.”
This latest round of layoffs follows job cuts made by Pure in January and April last year
Nasdaq-listed Pure announced a healthy set of results for its Q3 of fiscal 2024, ended November 5, with revenues up 13 percent year-on-year to $762.8 million, and a profit of $70.4 million recorded compared to a minor loss in the same period of the prior year. The Q4 outlook was more downbeat, with revenues of $782 million forecast, equating to a decline of 3.5 percent year-on-year.
A move toward more subscription-based business is affecting income on the one hand and delayed shipment of a $41 million 5G telco customer is another headwind.
We have heard from industry sources that Hammerspace is making inroads at Meta, a big FlashBlade customer, in the large language model training arena, using all-flash storage servers orchestrated by Hammerspace’s software. Meta, like other large web-scale customers, needs a POSIX-compliant file system and not an HTTP/RSST object system, according to a source familiar with the situation.
AI training cluster diagram
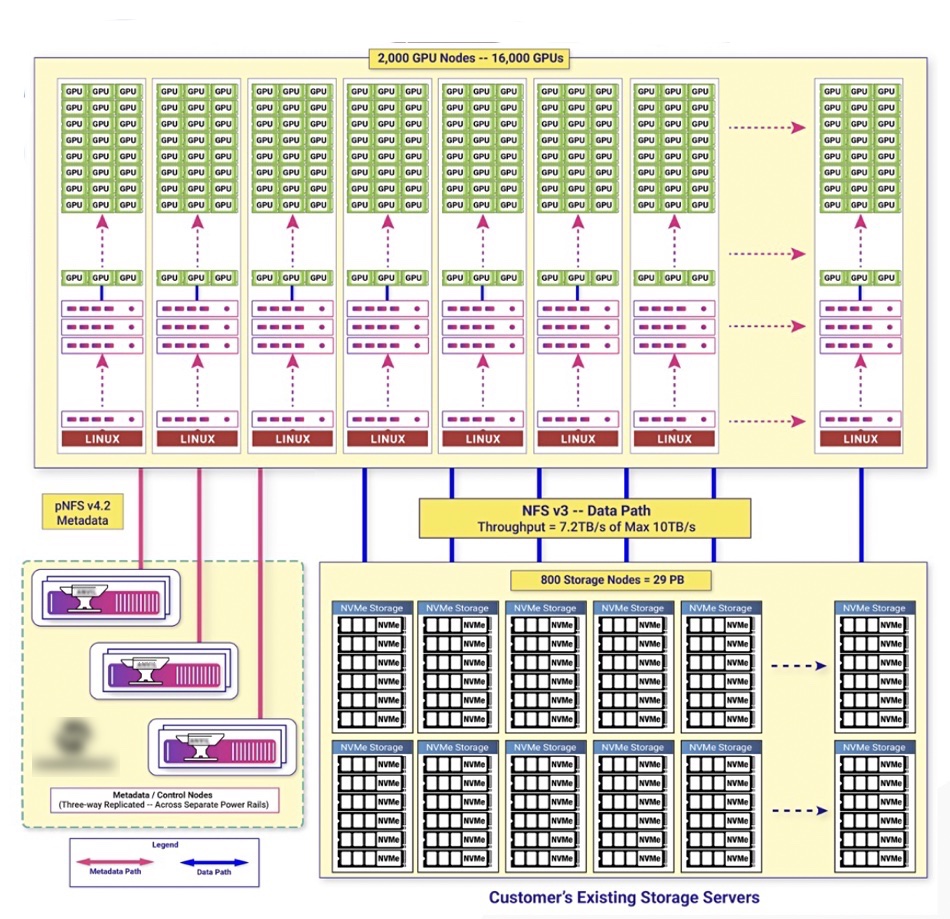
Meta is building 1,000 node clusters with 100 Tbps bandwidth and doesn’t have an RDMA-capable network, we’re told. It uses layer 3 switching and cannot use NVMeoF. Meta started with Pure Storage’s FlashBlade as the array, we’re told, but came to view it as limited. It’s also not a commercial-off-the-shelf (COTS) system.
At this scale you need to save pennies on the dollar, and it was felt that Hammerspace’s relatively cheap Linux storage boxes could fit the bill. We’re also told VAST Data, which uses COTS kit with an internal NVMe-oF fabric, was expensive and wouldn’t scale past 30 nodes without performance falling off. Vast disputes this.
Veritas, which private equity house Carlyle bought from Symantec for $7.4 billion in 2015, supplies data protection and management products. It is regarded as a legacy data protection vendor, which has moved into cloud with Alta. The CEO is Greg Hughes. Cohesity, led by CEO Sanjay Poonen, was founded by Mohit Aron in 2013 and has raised $660 million in total funding. The company supplies data protection and cyber resilience software, provided as cloud services. It also has a CS5000 HCI data protection appliance product line.
Sanjay Poonen
“This deal will combine Cohesity’s speed and innovation with Veritas’ global presence and installed base,” said Poonen in a statement. “This combination will be a win-win for our collective 10,000 customers and 3,000 partners, and I can’t wait to work with the Veritas team to bring our vision to life.”
“We will lead the next era of AI-powered data security and management by bringing together the best of both product portfolios – Cohesity’s scale-out architecture ideally suited for modern workloads and strong Generative AI and security capabilities and Veritas’ broad workload support and significant global footprint, particularly in the Global 500 and large public sector agencies.”
Cohesity’s Turing initiative involves a generative AI partnership with Google Cloud and Vertex AI platform for building and scaling machine learning models. Cohesity is extending this initiative by working with AWS Bedrock to have business context-aware answers generated in response to user requests and questions.
Veritas’ data protection operation is understood to have a value of more than $3 billion, including debt. To pay for this, Cohesity has raised some $1 billion in equity and $2 billion in debt from an investment group including Haveli Investments, Premji Invest, and Madrona. The combined Cohesity-Veritas data protection business has a reported $7 billion valuation.
The new entity will have a $1.6 billion annual revenue run rate, the companies said.
The deal should close by the end of 2024, and Carlyle will roll over or retain its holding in the Veritas data protection business and join Cohesity’s board, along with Veritas CEO Hughes.
The remainder of Veritas’ business, said to include data compliance and backup services, will be placed in a new company by Carlyle. It will be called DataCo and will include Veritas’ InfoScale, Data Compliance, and Backup Exec businesses. It is interesting that Backup Exec is not included in the Cohesity-Veritas transaction, perhaps because it is regarded as an SME data protection product. A Cohesity spokesperson said: “I’ll just say that Cohesity is focused on the enterprise, and the businesses from Veritas that we are combining with keep us focused on the enterprise.” Lawrence Wong, presently SVP of Strategy and Products at Veritas, will head DataCo.
Commvault’s chief customer officer, Sarv Saravanan, said: “This deal between Cohesity and Veritas could create complete chaos for customers. Platform integration challenges and redundant product portfolios could take years to address. With cyberattacks increasing in severity and frequency, there’s no time for that. Customers need to know if they’re hit, they can recover fast. In today’s world, cyber resilience equals business resilience.”
The combined Cohesity-Veritas business has c10,000 customers and c3,000 partners with hundreds of exabytes of data under management.
DCIG proprietor Jerome Wendt opines: “This acquisition gives both companies what they want and enterprises what they need. Veritas NetBackup gets the next-generation technologies in the form of AI, hyperconvergence, and a cloud platform that it needs to stay relevant. Cohesity gains immediate access to enterprise accounts and the ability to set NetBackup’s future technology direction by owning NetBackup. Finally, enterprises obtain a technical path forward that does not require them to abandon their investment in NetBackup.”
Comment
This deal is a major reshaping of the data protection and cyber resiliency landscape. Poonen became Cohesity CEO in August 2022 and he’s putting his own stamp on the company with this merger for Cohesity, which is still technically a startup.
The data protection and cyber resiliency market is fragmented with roughly three groups of suppliers:
Fast-growing new arrivals: Cohesity, Druva, HYCU, Rubrik, and more
Mature players: Arcserve, Asigra, NAKIVO, HPE’s Zerto, and many others
Rubrik, a strong rival to Cohesity, is reportedly gunning for an IPO, and Veeam surely has an IPO in its future. Cohesity filed for an IPO in December 2021 but it did not come to fruition. Now it could position itself for one in the 2025/2026 time frame once the Veritas acquisition has been digested and the business has a healthy bottom line. It is probable that a combined Cohesity-Veritas data protection and cyber resilience business will become one of the largest players in the data protection marketplace. William Blair’s Jason Ader thinks it will be the leading company, larger than Veeam. It’s good news for IBM as its Storage Defender offering includes Cohesity’s data protection as an integral part of the product.
There will be a lot of business and technology integration and consolidation inside the new business. We have heard, for example, that Cohesity’s hyperconverged offering – the Cohesity Data Cloud and the Helios interface – will get Veritas software IP and be offered as an upgrade to the Veritas customer base. Obviously there will need to be a single management facility and perhaps a combined data protection map and weakness identification facility.
This is the first major consolidation move in the fragmented backup industry. It may prompt more jostling for position as other legacy incumbents look to join with aggressive and faster growing new players to secure their position in an evolving market.
Interview: Compared to file, object has simply become a protocol absorbed into an analysis solution, and proprietary GPUDirect will be followed by more generic multi-GPU-vendor technology. These are points made by Qumulo CTO Kiran Bhageshpur when asked about the relative status of object and file storage on the one hand and the role of GPUDirect and object storage on the other. Qumulo supplies scalable and parallel access file system software and services for datacenters, edge sites, and the cloud with a scale anywhere philosophy. It supports the S3 protocol with Qumulo Shift, but not GPUDirect.
Kiran Bhageshpur
The surge of interest in AI means Qumulo is placed at the intersection of large unstructured data sets, GPU processing, and LLM training and inference. Nvidia’s GPUs dominate the LLM training market and there are two distinct populations of unstructured data – files and objects – on which these GPUs can feed. How does Bhageshpur view their relative status?
He said: “My firmly held opinion is that object in the cloud is an absolute first-class citizen … It is a fundamental primitive; S3 and EC2 and EBS were the first three services as a part of AWS back in 2006. And it is insanely durable. It is ridiculously available. It is got fantastic throughput characteristics, not latency, but throughput. So therefore, it is impossible to overwhelm object in the cloud. It’s got a huge scale. They talk about zone-redundant storage, they talk about locally redundant storage. You could do replication as a part of the setup to a different region. It’s fantastic.”
But “object on-premises is a cruel joke.”
Qumulo supports the S3 protocol “simply because we support a protocol.”
On-premises object storage is a pale imitation of in-cloud object storage, he says. “Nobody has the capability to actually deliver that level of redundancy that exists in the cloud on-premises. And even if they do, it is tiny in terms of the number of people who can operationalize it. Think about zone redundant storage which is an S3 basic characteristics, which means they have three datacenters, all of them with separate power cooling, networking, and yet only one millisecond to one and a half millisecond latency between these datacenters. And they are essentially doing erasure encoding of the object across these things. How many people on earth do you think outside the magnificent seven, and maybe another 10 to 12, can actually do this?”
The magnificent seven refers to Amazon Web Services (AWS), Microsoft Azure, Google Cloud Platform (GCP), Alibaba Cloud, IBM Cloud, Oracle Cloud, and Salesforce.
General enterprise datacenters may have “three datacenters in three different states. Now your latencies are 30, 40, 50, 60, 70 milliseconds; the experience is crappy. And now you get the sort of opinion that it is slow.”
But “then you will have people like Pure and VAST come along and say, hey, it’s fast object. But, if you look at the use cases, it’s not quite there. Now, let me flip that around to something else and talk about file.”
“Enterprise file, whether it is Dell EMC Isilon, or Qumulo or NetApp, is world class. It is fantastic. It is scalable, it’s reliable, it is affordable. It’s great. I’ll even throw in VAST and give them credit; it’s really good service on premises.”
However, he says, “file in the cloud … is a bit of a cruel joke, until we came along with Azure Native Qumulo.”
“Think about it. EFS is just NFS highly scalable, good shared storage. But it’s got none of the features, it’s got no … quotas and replication and snapshots … Azure NetApp Files is actually hardware in the cloud datacenter … If you look at all of these, they are 10 to 20 times more expensive than what is available on-premises.”
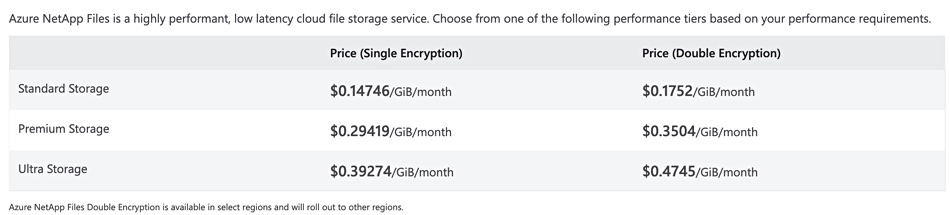
“Look at the price point on, I just pick on Azure NetApp. The premium tier, the ultra premium fast thing on Azure NetApp Files, is over $300 per terabyte per month. This is publicly available.”
Azure NetApp Files pricing for West US 2 region. It’s $392.74/TiB/month for single encryption, which equates to $357.19/TB/month
Bhageshpur asserts: “It still is a robust business … And that’s because it is speaking to a palpable need for file. So the whole thought process that file is going to die because of object was nonsensical, and everybody is recognizing that including the cloud guys.”
“That’s why people like Microsoft have partnered very closely with us with Azure Native Qumulo as a service out there. And if you think about it, it’s going to have all the performance of file on premises, it’s got all the elasticity of the cloud in every possible way, when you’re paying for only consumed services, whether it is performance or capacity. So you’ve got the best of both worlds.”
“One of my one of my colleagues, who spent a lot of time at Dell, and AWS, and now is with us running our file business, Brandon Whitelaw, loves to say that, if you take any of the file services in the cloud, wrap, you know, sheet metal around that and try to sell it to an on-premises buyer, they will laugh at that, because it’s so not better from the features, functionality, cost point of view.”
In his view: “When we bring in a unified service, which has got the best of both worlds, all the power and POSIX compliance of file with the cost elasticity of object, that’s where it changes the game. That’s my take on that one.”
“There are niche use cases for object on-premises, such as being an S3 backup target for Veeam or Rubrik, running a Kafka workflow or a … Spark workflow on-premises in conjunction with the cloud offering.”
But object on-premises has not had a great run. “Nobody has had a big outcome … There’s no big standalone object company. Is it Scality? Is it Cloudian? MinIO has come along with an open source plane, that’s kind of clever … In fact, object has simply become a protocol absorbed into an analysis solution … We have object, Pure supports object, VAST supports object. It is just a protocol that we think about. It’s a standard version of an HTTP protocol. That’s all, OK?”
In summary, object on-premises is a cruel joke and basically just protocol support. File in the cloud is a cruel joke, apart from Azure Native Qumulo.
GPUs and GPUDirect
We discussed sending unstructured data to GPU servers, specifically Nvidia GPUs. Unstructured data lives basically in file or object repositories. Nvidia has its proprietary GPUDirect protocol for getting NVMe SSD-held file information to its servers direct from storage with no time-consuming host server CPU intervention. Can we envisage a GPUDirect-type arrangement for objects? Bhageshpur argues that we should not consider developing such a protocol.
“Let me articulate what I think is happening, right? Nvidia is the sexiest company on the face of this planet. Today, it’s joined Amazon and Apple and Microsoft, in being one.”
“GPUDirect is not a technically complicated thing. Especially for a product like Qumulo, which is a user space protocol running on the richness of file. Supporting RDMA is trivial to go do, right? But also, the thing that you gotta go ask yourself, and we ask ourselves this very, very seriously all the time, is: what is the problem? And for which customers?”
“GPUDirect is an Nvidia thing. Does that work with Intel’s Gaudi 2 architecture? No. Does that work with the Microsoft Maia chipset coming out? What happens when there is the next-generation silicon in AWS?”
In other words, he appears to be saying, GPUDirect and Mellanox Ethernet NICs are proprietary lock-in technologies.
Bhageshpur asks: “What’s the generic solution? To get data, independent of file, object or whatever else out there? And what that is is the generic problem to solve.”
He admits: “There are a modest number of players on-premises inside the Nvidia GPU infrastructure, which have just built out massive amounts of Nvidia GPU farms and they probably have GPUDirect storage, whether it is NetApp, or Pure, or our Dell or Vast behind that … And there are small numbers of very large customers.”
But this is not general across the market, although big numbers are involved. ” The reality for AI in general is I’ve talked to a lot of folks [and] by and large, broadly, it’s very much in the experimental stage. I mean, ChatGPT gets our attention, Google Bard gets our attention … ServiceNow announced that it’s had a billion dollars in additional revenue in the last one year because of their AI integration.”
The use case is almost trivial in one way. “If you look at what they have done, it’s pretty straightforward. It is a modern version of a better chatbot in front of it, right? … You’re going to do the things in your workflow engine that you would otherwise have very complex commands and connect things up [to do]. But that’s powerful. That’s really useful.”
However: “It’s in a highly experimental stage. We find a lot of the experimentation is going on either at small scale at a desktop level … or it’s happening in the cloud, not counting the small number of people who do have large farms out there.”
Bhageshpur notes: “It’s not very obvious what the thing is, and whether there is actually going to be everybody doing the training. Is training going to be something that; pick a generic Fortune 1000 company does, or do they consume the output of that as a package service? I think the jury’s still out.”
While the jury is still out, “our focus is really about data and scaling anywhere. Do we have the solution for our customers on premises on any of their infrastructure? Do they get the exact same file and data services in the cloud, any of the clouds that they may choose to go?What about out at the edge [where] they have completely different requirements? Can they exist and operate a single data plane across this, both from a control as well as data visibility and data access point of view?”
Focusing on this, he says: “From a data point of view, getting that to be a really robust solution across, is going to allow us as a company to intersect what the AI trend lines do, no matter which way it goes.”
This is because “inference at the HQ, you have a solution out there. Training in the datacenter, you got a solution out there. You’re gonna go training and inference in the cloud, you got a solution for data out there. How do you connect the GPUs to the data no matter where it is, is the problem we want to solve rather than a point solution.”
He wants us to realize, though, that GPUDirect (NFS over RDMA) has validity. “Don’t get me wrong. That’s not hard to do. And it’s not unreasonable for us to do it. But it’s also, I know, there’s so much talk about it that everybody thinks that’s the cat’s meow and that’s the thing which is most magically required. And it’s an important, but not indispensable, part of what strategy you should be [looking at] going forward.”
Our sense is that Qumulo would like there to be fast file data access technology covering GPUs in general – Nvidia, Intel, AMD, Microsoft, Amazon, and Google ones. And it thinks supplying file data fast for LLM training and inference in the public cloud, at edge sites and in datacenters is also going to be needed.
We think that, until the GPU hardware players come up with a standard interface, a kind of multi-vendor GPUDirect that can be used to put data in any GPU’s memory, then supporting very large GPU players with supplier technology-specific software will be largely inevitable. It is not in Nvidia’s interest to enable GPUDirect-type support for Intel’s Gaudi 2, AMD Radeon or Microsoft’s Maia chips.
GPUDirect and S3
But could we have a GPUDirect for S3? Bhageshpur thinks not. “There is no such thing as S3 over RDMA, because, essentially, GPUDirect is NFS over RDMA.”
Also, the big CSPs face another problem here. He says: “Let me talk about one more reason why RDMA is over bought. You need network card support to make that happen, right? It’s not generic on anything. You need a the network interface to be able to support RDMA to be able to go make it work.” He rhetorically asks: “Guess which is the most prominent networking card which supports RDMA? Do you want to take a guess on which one it is?”
I said Ethernet ones and he almost pounced on this answer: “Who makes them? Mellanox. And who owns Mellanox? Nvidia.”
“If you look at the clouds, various clouds in various regions have pockets where they have Mellanox interfaces on their CPU side that you can go leverage. But it’s various pockets, and it’s kind of scattered; it’s not standard. You’re not going to see Mellanox type RDMA-enabled Ethernet cards ubiquitously available in the cloud for a long time … We know that getting into every other place means that these guys have to go through a sort of hardware refresh cycle, which takes years, you know, to have ubiquitous availability.”
“There are going to emerge different technologies other than GPUDirect, especially in the cloud, to bring data faster from where it lives closer to the GPU.” He wouldn’t be drawn on any details about this.
Bhageshpur thinks that the compound effect of individual productivity enhancements from AI could be huge.
“The real thing to think about is how many people are going to train foundational models? I would argue it is extremely small. How many people are going to update foundational models with specific data? I would think that is also small. It’s not going to be hundreds of thousands. And then how many people are going to consume that? It’s a lot, right?”
“One analogy I’ll make is, how many people build their own distributed file system? If you’re a company, not too many. You look to somebody else to solve that infrastructure problem, because it’s hard. It’s kind of the same thing with foundational models. Training foundational models is difficult … How is the generic enterprise going to go update that?”
He doesn’t think it will, and the main use for AI LLMs is “all about individual productivity, which is why, if you look at the focus, the big part of Azure is a Copilot for everything, which is: let us use our technology to make an individual inside a corporation more productive.”
He says: “That’s exactly what ServiceNow has also done. And by the way, to some extent, maybe it’s correlation and not causation, but it shows up in terms of the US, which is the dominant adopter of all of these things, having had this huge productivity spike in the last 18 to 24 months.”
The answer to the GenAI and ChatGPT question “isn’t going to be as simple and as reductionist as, oh my God, AIG and Terminator, and Skynet … That’s a joke, it doesn’t work. It’s going to be really compelling in mundane ways. It is going to make everybody a little bit more productive.”
“If you’re seeing 5, 10, 20 percent improvement in productivity among your workforce, that’s huge. And people are willing to pay for that.”
And Qumulo’s function? “All the focus in our tiny, teeny little role here is: how do we help our customers who have all of that data stored on us to go take advantage of the [AI] services, build the appropriate connection such that the jobs are done much easier.”
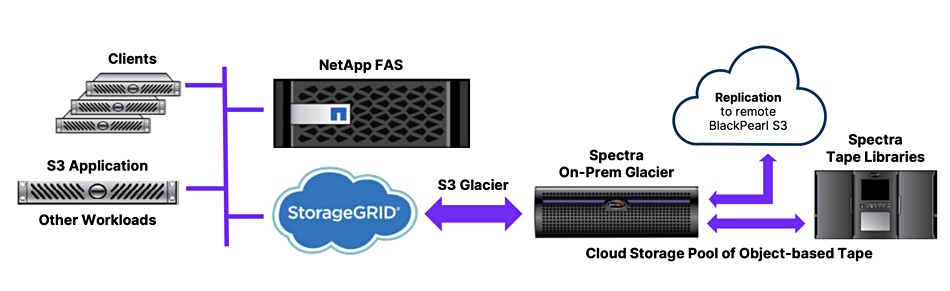
SpectraLogic is providing validated on-premises object archival storage on tape for NetApp StorageGRID systems as an affordable alternative to S3-based public cloud long-term retention.
StorageGRID is NetApp’s S3-based object storage product with its software running in a virtual machine, bare metal server or NetApp appliance, and using SSD or disk-based storage. It can store billions of objects in a single namespace and scale up to 16 datacenters worldwide. Spectra’s on-prem archive pairs a tape library system and its BlackPearl object interface and storage device to provide an S3-to-tape front end to Spectra tape library systems. The key point here is that an On-Prem Glacier archive can provide both faster access and lower costs than an AWS S3 archive store.
Vishnu Vardhan, Director of Product Management for Object Storage at NetApp, said: “The Spectra On-Prem Glacier solution provides NetApp StorageGRID customers with the ability to add a Glacier tier configured with object-based tape to extend the capacity and reduce the costs of their long-term on-prem object storage.
Spectra diagram
“The validated integration gives organizations more flexibility in how they store their data, especially archives and back-up that are not in active use. By combining both technologies, our customers can get both the agility of flash and the longevity of tape to help ensure their data is always ready when they need it.”
Spectra and NetApp say that on-prem object stores can fill up with old and cold data. If that is tiered or mirrored to a backend long-term retention store based on tape, it can offer faster retrieval than Amazon’s public cloud S3 Standard and Amazon S3 Glacier protocols, and up to two thirds lower cost because there are no egress fees. Of course you’ll need a relatively large amount of data to go into on-prem Glacier to make the cost-savings appear as the necessary hardware and software must be purchased and maintained.
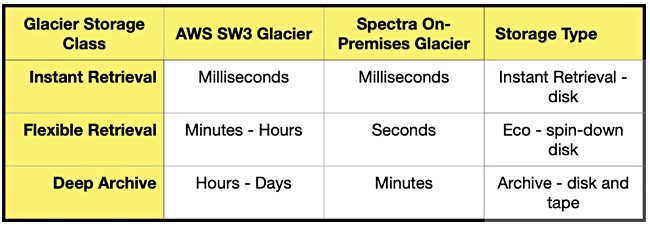
There are three tiers of Spectra’s On-Prem Glacier with varying retrieval speeds – Instant Retrieval, Eco, and Archive – as a table indicates:
The On-Prem Glacier provides air-gapped tape and object lock to secure the data and provides an on-premises hybrid cloud. It can be used as a replication endpoint for the StorageGRID CloudMirror service create a protected copy of the objects.
Chris Bukowski, Senior Manager, Product Marketing, Spectra Logic, said: “We’re excited that NetApp has validated Spectra On-Prem Glacier for use by StorageGRID customers … We recognize the significance of the increasing costs of storing data in the cloud. This integration provides a valuable new option for reducing cloud data retrieval and accompanying egress fees, while scaling to near-limitless capacity with less complexity.”
Access a NetApp solution brief document here. A short NetApp blog provides that company’s perspective on the partnership.
Comment
Object storage tends to grow and grow. Moving stale objects to background storage as a way of saving space and cost on the primary object can make sense once the cost savings are greater than the cost of the backend storage itself and the value of having faster data access is factored in to the equation.
Bootnote
Spectra tells us: “The BlackPearl appliance comes in two physically separate versions, BlackPearl NAS and BlackPearl S3. Only the BlackPearl S3 includes S3 Glacier and an object-based interface to tape.”
Startup QiStor has scored pre-seed funding to develop hardware acceleration for key-value data store access.
Generalized server CPUs have been augmented by specialized hardware accelerators for some time now, ranging from RAID controllers, through SmartNICs (Bluefield), DPUs, SQL Accelerators (Pliops), to separate GPUs. The idea is to invent focused hardware to run a particular kind of processing faster than an x86 CPU and so enable it to run more app code. Key-value stores hold variable length data addressed by a data string or key and represent low-level storage engines such as RocksDB, used by Redis for Flash and MongoDB.
Silicon Valley-based QiStor’s founders have set out to run key-value store (KVS) data access operations faster and in a Platform-as-a-Service (PaaS) business model.
Founding CEO Andy Tomlin stated: “Our revolutionary service reduces [compute] power by 10x, enabling us to offer our customers high-performance solutions more economically and with reduced environmental impact … Just as the GPU is essential for AI, our technology will play a similar role for key-value.”
Tomlin was a fellow at Kioxia from 2020 to 2022, a CTO at devicepros LLC, and VP Engineering at Samsung’s closed-down startup subsidiary Stellus, which launched a key-value store-based all-flash array with NVMe-oF access in May 2020.
QiStor’s other founders are architect Justin Jones and design lead Chris Brewer. Its board includes John Scaramuzzo. Jones, who has authored about 30 storage patents, has been a principal engineer at Stellus and Samsung Electronics America before that. Brewer was an ASIC architect engineer at Toshiba America and principal engineer for ASIC design at SandForce, LSI, and Seagate prior to that.
Scaramuzzo has 30-plus years’ storage industry experience, holding CRO and CEO advisor roles at troubled Nyriad, and executive positions with Western Digital, SanDisk, Seagate, and Maxtor. He founded, led, and sold SMART Storage Systems to SanDisk for $307 million.
The funding round was led by datacenter expert Samir Raizada, who joins QiStor’s board. He said: “Our experience in the datacenter shows that QiStor is addressing an important customer need in a fast-growing market, especially with increasing AI demand. The QiStor team experience and technology really impressed the investors.”
Now that it has scored initial funding, QiStor plans to develop its technology further and expand its reach. We asked how its hardware acceleration unit would connect to a host server. Andy Tomlin told us: “QiStor’s algorithms run on FPGAs which connect via PCI and are directly provisioned in existing cloud platforms. No ASICs or custom add-in cards are needed.”
The company says key-value data stores enables every modern app in social media, mobile, web, AI, and gaming spaces to store data at scale. Tomlin thinks that a value proposition of QiStor is hardware acceleration in a Platform-as-a-Service (PaaS) operation versus needing to develop and sell an expensive ASIC and card. This will be “much easier and cost efficient for a customer to deploy.”
This positions QiStor against Pliops, which has developed its XDP add-in card to provide a key-value store interface and functionality to an NVMe SSD to speed up applications such as relational and NoSQL databases, and stores such as MySQL, MongoDB, and Ceph.
Komprise has pushed out elastic replication that it says provides more affordable disaster recovery for non-mission-critical file data at sub-volume level.
Komprise’s Intelligent Data Management product can tier data between costly and fast storage and less expensive but slower access storage on-premises or in the public cloud. It says that disaster recovery of mission-critical file data is traditionally provided by mirroring NAS systems to a remote site and this synchronously replicates data at the volume level to an identical target NAS system using the same infrastructure. If the source NAS is affected by ransomware, that gets replicated as well.
Kumar Goswami
Komprise CEO Kumar Goswami states: “Our customers are uneasy about not having disaster recovery plans for all unstructured data, but as unstructured data volumes continue to balloon, the one-size-fits-all mirroring approach is too expensive for most.”
The underlying assumption is that customers also wish to secure their non-mission-critical data against disasters, but find it prohibitively expensive. It’s important to note that unstructured (file) data varies in criticality, ranging from “must not lose” to “doesn’t really matter.”
Komprise is providing so-called elastic replication at the sub-volume level so that shares or directories can be asynchronously replicated to a target file or object store that could be in the public cloud. It implies that this provides time for ransomware affecting such files to be detected and cleaned before the replication, and hence is safer than sync replication, which is nearly instantaneous. The replication can be to an immutable, object-locked target to provide resistance to ransomware attacks against the target systems.
Its replication is based on snapshots and the file metadata, including versioning, is retained if the files are sent to object targets, meaning that files can be restored from them with no loss of fidelity. The replication schedule can be based on user-set policies.
Komprise also claims that it can cut the cost of disaster recovery by 70 percent or more from the synchronous NAS-to-NAS schemes, with the source for this claim described in a blog going live later today.
Goswami said: ”We are excited to help organizations customize disaster recovery so they can afford the protection they need for all of their data, within tight budgets.”
Peer Software also provides asynchronous replication for Windows Server, as does Dell with its PowerFlex and StorONE for itsS1 systems. However, these solutions are system-specific, whereas Komprise is not.
Elastic replication is provided in a winter release of the Intelligent Data Management software. This allows users to save custom report configurations and maintain multiple versions of any type of report. It also supports tiering from Pure Storage FlashBlade//S to an on-premises FlashBlade//E target. As we wrote in March, the FlashBlade//E evolved from the FlashBlade//S and adds storage-only blades to the existing compute+storage blades to increase capacity and lower cost. Moving rarely accessed files and objects from the //S to the //E makes space on the //S for more more important data. Pure resells Komprise software.
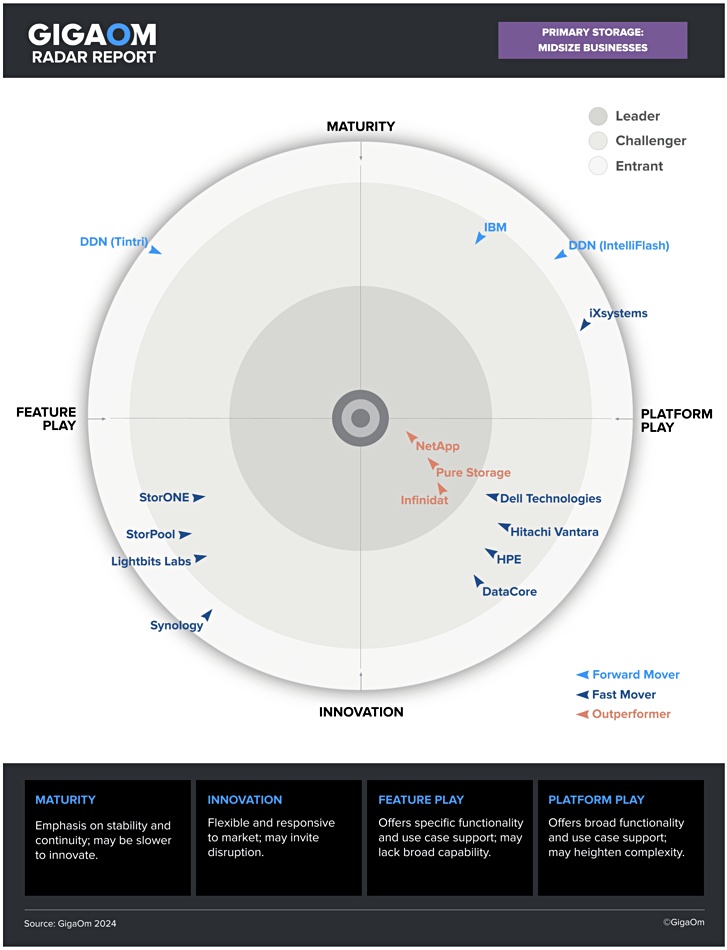
As in the enterprise storage Radar NetApp, Pure and Infinidat are the clear and only leaders and outperformers in GigaOm’s mid-size enterprise storage Radar report and chart.
The Radar report looks at suppliers’ products for a market sector based on key and emerging functional features beyond table stakes and business criteria, such as upgrability and efficiency, from a value point of view. The Radar diagram features a series of concentric rings, with those set closer to the center judged to be of higher overall value. The chart characterizes each vendor on two axes – balancing Maturity versus Innovation and Feature Play versus Platform Play – with a prediction of the supplier’s development speed over the coming 12 to 18 months, from Forward Mover, through Fast Mover to Outperformer.
A companion Key Criteria report looks at functional items in more detail. This Radar report also includes consideration of departmental needs in large enterprises. This year’s edition of the primary storage for mid-size enterprises Radar examines 14 vendors and 15 products – both IntelliFlash and Tintri arrays from DDN are evaluated. Last year’s edition looked at 13 vendors.
Overall, the analysts, Max Mortillaro and Arjan Timmerman, note that AI-based analytics, helping to defend against ransomware attacks, and STaaS are development areas in this mature mid-size enterprise primary storage market. Electricity price increases have caused a renewed emphasis on energy efficiency and carbon footprints.
Compared to last year’s report, Synology has entered the arena, and Dell, Hitachi Vantara, and IBM have all been demoted from the Leaders circle to the Challenger ring. The bulk of the suppliers – 11 of the 13 – are in the bottom half circle in three quite tight groups. The other three are classed as more nature and spread around the outer entrants’ ring or very close to it.
StorOne, StorPool and Lightbits Labs (NVMe/TCP-based storage) are classed as Challengers in the innovation-feature play quadrant, with Synology rated as a new entrant. Dell (PowerStore), Hitachi Vantara (VSP E-Series), HPE (Alletra 5000 and 6000) and DataCore (SANsymphony) are Challengers in the Innovative-Platform Play quadrant. All eight are fast movers – not developing as fast as the three Leaders. The report authors call out Lightbits’s blisteringly fast technology.
DDN (IntelliFlash), IBM (Spectrum Virtualize, FlashSystem 7300), and iXSystems (TrueNAS) are placed in the Maturity-Platform Play quadrant and judge to be forward movers. DDN (Tintri) is an outlier, a forward mover, all on its own in the Maturity-Feature Play quadrant.
The report authors point out that DDN’s NexentaStor, evaluated in the 2023 edition, is no longer actively developed – existing customers get only maintenance releases. DDN’s Tintri is now very mature and stable and there has been little development from its core design center of presenting VMware-specific storage features with no file or block abstractions. The authors observe that it was architected to solve a niche use case and has little potential for evolution.
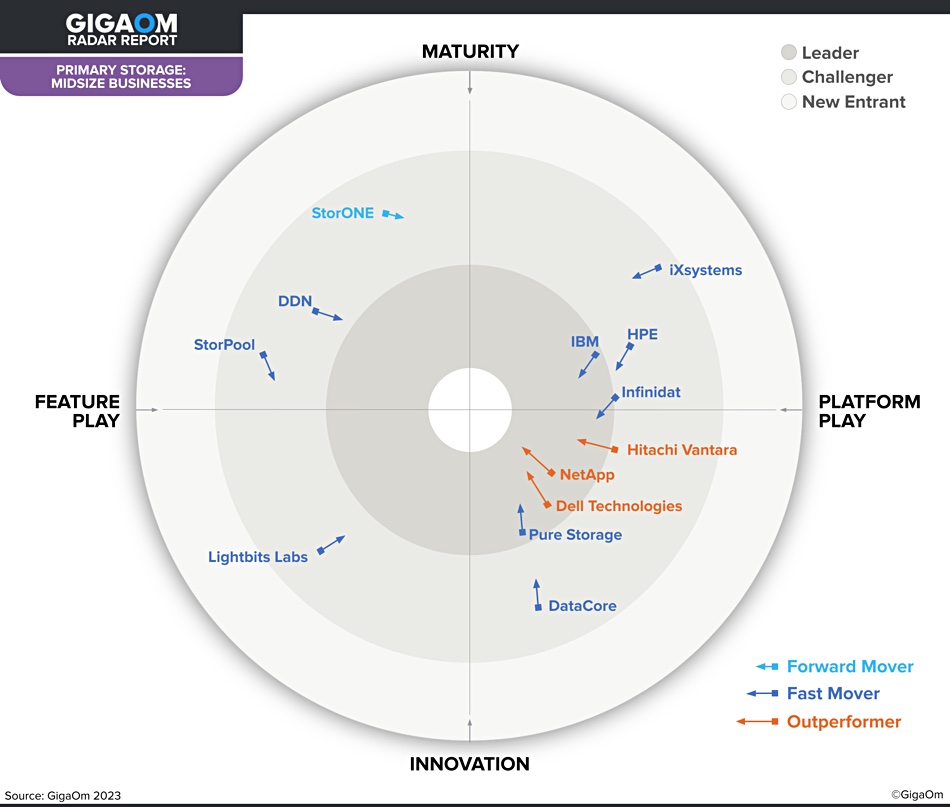
A glance at the 2023 edition’s Radar chart shows a more evenly distributed set of suppliers in the Challengers ring.There has been a substantial rise in innovation since then causing the clumping into two supplier groups in the bottom half of the 2024 chart.
We are left with the impression that this mature market has seen renewed development because of ransomware encouraging AI analytics, and a cost efficiency focus helping STaaS offers proliferate. That has also meant green agenda items – such as energy efficiency and a lower carbon footprint – gain a stronger emphasis.
It may be that DDN’s Tintri and IntelliFlash products will enjoy renewed development this year, as might IBM’s FlashSystem/Spectrum Virtualize product, and not be outliers in the 2025 edition of this report. GigaOm subscribers receive a copy of the report. If you are not a subscriber then its detailed contents are not available.
NetApp has partnered with the Aston Martin Aramco Racing team and VAST Data is linking up with the Williams Racing team as the two file storage suppliers duke it out in Formula One.
Formula 1 sponsorships are big business in the world of motor sports. Businesses that sponsor F1 teams include financial, telecom, tech, and consumer brands wanting exposure to F1’s global audience. Examples include Petronas (Mercedes), Aramco (Aston Martin), and Oracle (Red Bull). Many sponsorship contracts are valued in the tens of millions on an annual basis. Title and principal sponsorships can be $50 million-plus per year with top teams. NetApp and the Aston Martin Aramco team have renewed a three-year agreement where NetApp is the team’s Global Data Infrastructure Partner.
Clare Lansley and George Kurian, NetApp CEO
Clare Lansley, Aston Martin Aramco CIO, said: “NetApp has been with us all the way on this journey together and are fundamental to our trackside operations and at our Headquarters at the AMRTC in Silverstone. We use data to improve our performance and go faster and NetApp’s work with the team is vital to this success.”
We’re told that the Aston Martin Aramco team collects data from hundreds of sensors, including real-time performance statistics such as track temperature, tire degradation, and aerodynamics. Instant access to that data enables the team to adapt its race strategy in real time. Sharing data between the track and team headquarters is a mission-critical function.
Aston Martin Aramco reached the podium eight times, scored 280 points, and finished fifth in the Constructors’ Championship in the 2023 Formula One season, partly by using the data NetApp stores and manages. NetApp provides its FlexPod, Cloud Volumes ONTAP, Cloud Insights, and Storage Workload Security products and services to the Aston Martin team.
We’re told the sheer speed at which Aston Martin Aramco can harness its stored data gives it a competitive advantage. NetApp CMO Gabie Boko said: “When Aston Martin returned to the Formula One circuit after more than 60 years away, they needed a technology partner to help them rise to every moment, both on and off the track. NetApp provides Aston Martin Aramco with an intelligent data infrastructure that runs at the speed of Formula One.”
VAST and Williams
VAST Data has joined Williams as an Official Partner and technology vendor for the 2024 season and beyond. The logo will be plastered on on driver overalls and the FW46 cars driven by Alex Albon and Logan Sargeant in the upcoming Formula One season.
The yet-to-be revealed FW46 car for the 2024 season
In a typical race weekend, the hundreds of sensors on a Williams F1 car will generate 1 TB of data, and there are two cars per race. Williams said designing and simulation testing the car generates hundreds more terabytes. Understanding the in-race and design-and-test data is critical to on-track success, and VAST Data’s skills in managing and processing large datasets can help optimize the team’s performance, we’re told.
Peter Gadd, VP International at VAST Data, said in a statement: “VAST Data is thrilled to be an Official Partner of Williams Racing. This partnership symbolises our commitment to pushing the boundaries of technology and performance. Williams Racing’s legacy of innovation and excellence in Formula 1 aligns perfectly with our vision of revolutionising data-driven insights in high-stakes environments.
“By bringing our advanced data management capabilities to the forefront of motor racing, we are not just sponsoring a team; we are driving a new era of technological synergy between data science and the pinnacle of motorsport.”
Pat Fry, Williams Racing CTO, said in his statement: “F1 teams generate enormous amounts of data every day, so we’re privileged to partner with Vast Data whose expertise in managing and processing large datasets will play a crucial role in optimizing our performance. The collaboration will allow us to harness the full potential of our data and help move us up the grid.”
The Williams team has faded since the glory days of the ’90s when its drivers won world championships and Williams itself won Constructors’ championships. The team was bought by private equity business Dorilton Ventures for around $200 million in 2021 and aims to revive its racing fortunes.
Not every sponsorship is a direct cash payment. Some sponsorships involve companies providing technical support, R&D partnerships, or supplying components to the team. Exact details of the sponsorship arrangements for VAST Data and NetApp are confidential.
The two storage suppliers are fighting a marketing war using Formula One racing team proxies.
Rubrik is planning an IPO in April when a fraud investigation in the US should be finished, according to a Reuters report.
Bipul Sinha.
The firm began its startup life as a data protector with backup and restore software, and has since moved into cyber security and resilience. It was founded in 2014 by ex-venture capitalist and CEO Bipul Sinha, CTO Arvind ‘Nytro’ Nithrakashyap, VP engineering Arvind Jain and Soham Mazumdar. It has raised in excess of $550 million with an E-round for $260 million in 2019 followed by a Microsoft equity investment in 2021, at a valuation of around $4 billion. The business has grown quickly, having gained >5,000 customers and $600 million annual recurring revenue. It hired bankers – Goldman Sachs, Barclays and Citigroup – to work on an IPO in June last year according to an earlier Reuters report and has filed IPO papers with the SEC.
Bloomberg suggested in September last year that it could IPO by the end of 2023 and Pitchbook notes Rubrik has raised about $1 billion in funding.
Sinha has fought hard to keep Rubrik on top of emerging trends in the market. It announced a Ruby Gen AI copilot in November last year, adopted zero trust principles in its product, provided a ransomware guarantee, moved into SaaS app data protection, set up an MSP business, and acquired Laminar for its data security posture management software.
Rubrik competes with legacy data protection vendors, such as Commvault, Dell and Veritas, relative monster newcomer Veeam, Druva, fellow startup Cohesity – which has evolved into a data management company as well as espousing cyber resilience – and a mass of smaller suppliers such as HYCU and Asigra. Cohesity made an IPO filing at the end of 2021 but no IPO has yet taken place.
Reuters based its report on people familiar with the matter, and said the US Department of Justice is investigating a former sales division employee and the diversion of an undisclosed amount of funds from 110 US government contracts, worth $46 million, into a separate business vehicle. If the investigation finishes in March then Rubrik, which is co-operating with the Justice Department, could run its IPO in April.
Neither Rubrik, Microsoft nor the US Department of Justice commented on the Reuters story. When we asked Rubrik a spokesperson replied: “We decline to comment.”
Established optical disc-based archiver Rimage is pivoting to data management with an AI-powered digital asset metadata extraction and search product announced, and advanced optical storage in its roadmap.
Rimage describes itself as a global leader in on-demand enterprise and consumer digital publishing to CD, DVD, and Blu-ray discs and USB sticks with 194 channel partners and over 20,000 systems installed by more than 3,000 customers in law enforcement, government, manufacturing health and finance. It has just launched its SOPHIE digital lifecycle management system and has an Electronic Laser Storage (ELS) initiative underway focussed on emerging optical disk technology. Rimage presented its SOPHIA product and ELS plans to an IT Press Tour in Silicon Valley in January. Before we examine these it is instructive to understand Rimage’s history and grasp a key takeaway.
Rimage history
It was founded in 1987 as IXI inc. in Minnesota, with its founders having bought floppy disk manufacturing assets from the previous owner. This evolved into CD-ROM printing, with colored cartridge labels and also direct thermal printing in the disks, and CD-R and DVD-R duplication equipment. Rimage went public in 1992. The diskette business became loss-making after 1995 and it put its main focus on the duplication systems, and full-color images on CDs. DVDs came along in 2000 and Rimage produced DVD burners and photo-quality printing systems for opticaldisk labels. High-definition Blu-ray disk support was added in 2007. It acquired Qumu in 2011 for $57 million to enter the enterprise video content industry. Rimage changed its name to Qumu in 2013 but then ran into problems with its declining disk publishing business while the video content business had healthy prospects.
Rick Bunce.
Qumu Corp sold its Rimage assets to private equity business Equus Holdings in 2014 for $23 million, with Equus ressurrecting the Rimage name. It did not prosper as well as hoped and Christopher Rence was appointed Rimage CEO in 2020 to continue an ongoing transformation. The pivot to digital data asset management is taking place as part of Rence’s strategy and product line restructuring. COO and CRO Rick Bunce told the Press Tour audience that, like Smith Corona with its typewriters, Rimage had to change. It has been retreating from some verticals – eg finance – as its product offer stagnated, and needs new products.
The takeaway to bear in mind is this: Rimage has always been about the production of disks – from floppy disks through CDs and DVD to Blu-ray disks. Although it uses optical disks for archiving data it has not been involved with archiving per se, specifically with archiving software and archiving data to tape. Its DNA is centered on disks and not ribbons – of digital tape. SOPHIA could change that.
The pivot
Bunce told the Press Tour that AI is a new trend, some of which is LLM (Large Language Model)-based and other purpose-built AI. He identified AI that is used for storage, and storage that is used for AI, and asserted that purpose-built AI is what’s going to matter and machine learning is key.
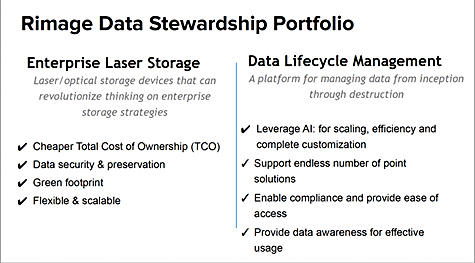
Rimage’s broader strategy has hardware (Enterprise LaserStorage) and software (Data Lifecycle Management) elements that help customers to manage data from birth to destruction. Rimage now sees itself as a digital steward and thinks the data lifecycle management (DLM)/document asset management (DAM) market is fragmented with many suppliers and no one dominant vendor. That means a new entrant can prosper.
it has two product categories in its data stewardship portfolio: DLM and ELS. SOPHIE is the first product in the DLM area and is AI-powered.
SOPHIA
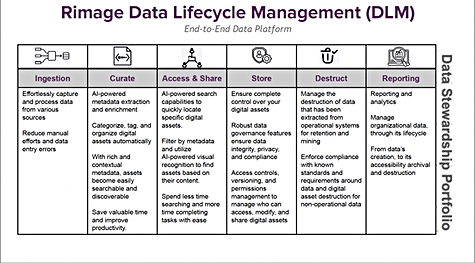
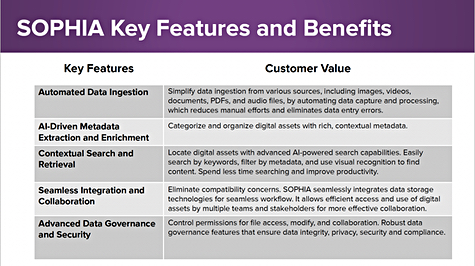
SOPHIA is from the Greek for knowledge and wisdom. Rimage’s product is the first of a set of modules, software abstractions above storage hardware, and is concerned with Digital Asset Management (DAM).
Rimage claims it seamlessly automates data ingestion from any source and builds a global repository to organize and optimize digital assets in a streamlined and secure way. The product uses AI to help it extract and generate contextual metadata from ingested digital assets and users can also customize filter fields, upload requirements and workflow controls to make its operation more efficient. Search is AI-powered with metadata filtering capabilities. There are permissions controls to help with security and governance features to aid compliance.
SOPHIA has file syncronization features to make files available to any location, whatever the network connection, syncs all changes back to the SOPHIA library. It works with any native Windows or OSX (macOS) application, eliminating any need for plug-ins or third-party applications. Linux support is coming.
SOPHIA integrates into all of the Rimage family of products and supports Al–driven data management.
The software is not entirely home-grown. Bunce explained: “We use a number of partners bringing infrastructural software into Sophia. We buy or license it and build on top of that. … We will slot the new software into our existing management layer.” One its partners is Germany-based PoINT Software which produces archive software, including software moving archive data to object storage on tape.
SOPHIA covers part of the DLM feature set. Rosen said Destruct (data destruction) is coming soon and Rimage is working hard on developing deeper analytics.
The product uses Google Vision AI and Rimage has written some of its own AI software.
SOPHIA is data agnostic, supporting file, block, object, structured and unstructured data. It has customizable AI features,an API, and flexible deployment, either on-premises, as SaaS or in hybrid form. SaaS SOPHIA can use Azure or AWS or horizontal/vertical MSPs.
ELS
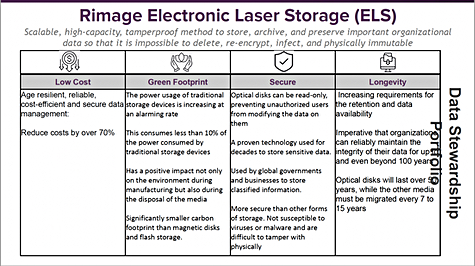
The term ELS, Electronic Laser Storage, refers back to Rimage’s CD/DVD/Blu-ray heritage as all these optical disk drives use lasers for reading and writing. Their use in archiving is falling away because of capacity limitations. Enterprise sales director Jeff Rosen noted: “Blu-ray has a maximum of 200GB/disk. It needs increasing and the density will scale.”
Optical disks can last for 50 years and complement LTO tape by having better (faster) random data access. Tape is not actually physically immutable, Rosen explained, being subject to EMPs (Electro-Magnetic Pulses). Optical disk is a safer medium in this regard. He also observed: “China has a mandate that all of its archive data will be optical disk in five years and not tape [and] China will effectively restart an optical disk industry. A Chinese company is building what we’re doing.”
Also Rosen and Bunce revealed multi-layered optical disk density improvements are coming from suppliers such as Sony, Folio Photonics, and Pioneer. In other words, optical disk is going to make a comeback. But these products don’t exist yet.
He dismissed Microsoft’s Project Silica though, saying: “Microsoft has abandoned glass – it’s buried maybe in R&D.”
Comment
The ELS product, when it arrives, being optical disk-based will provide an upgrade path for Rimage’s installed base of >3,000 customers with 20,000 or so optical disk printing and publishing machines.
The general theme of DLM and archiving software is that it is media-agnostic. Digital archives can live in tape libraries, on optical disk, even on spun-down disk, or on whatever devices are used by the public clouds underneath their S3 or Blob storage abstractions – be they disk or tape.
Based on this thought, Rimage could embrace LTO tape technology, also object-to-tape technology, and set up alliances with tape library system vendors such as Quantum and SpectraLogic. It should perhaps join the Active Archive Alliance and learn what the archive software players are doing.
Yes, the data lifecycle management market is fragmented, with players including Komprise, Datadobi, Data Dynamics, SpectraLogic, Arcitecta, Quantum, and StorMagic. But it is also quite mature in a software sense. We can expect all the existing archive software system players to add AI features to their products, with AI becoming table stakes. It is already happening in the data protection market. On the hardware side, new glass-based media technologies will likely come along, but the archive storage software layer will adapt to them and not be revolutionized or replaced.
If Rimage now sees itself as a data lifecycle management steward then turning its face away from the tape archive system market may seem like it is deliberately missing an opportunity.
Bootnote
Rimage has a range of additional products, which include:
Rimage Protection Shield for cyber security;
Rimage Data Solutions to gather and ingest digital assets from various devices onto multiple storage platforms;
Data protector Acronis has become a member of the Microsoft Intelligent Security Association (MISA), an ecosystem of independent software vendors (ISV) and managed security service providers (MSSP). MISA members have integrated their products with Microsoft security technology to build a better defense against increasing cybersecurity threats.
…
Dell’Oro Group predicts that the SmartNIC market will exceed $5 billion by 2028. Accelerated computing will continue to push the boundaries in server connectivity, demanding port speeds of 400 Gbps and higher speeds.
The total Ethernet Controller and Adapter market, excluding the AI backend network market, is forecast to exceed $8 billion by 2028.
The majority of accelerated servers will have server access speeds of 400 Gbps and higher by 2028.
SmartNICs are expected to cannibalize standard NICs during the forecast period.
Jim O’Dorisio
…
HPE has hired Jim O’Dorisio as its SVP and GM for storage, replacing the promoted Tom Black. O’Dorisio comes from being SVP and GM at Iron Mountain. He was VP and COO of business and technology at EMC before that, in the period before Dell bought EMC, spending 14 years at EMC altogether. He’ll report to Fidelma Russo, EVP of Hybrid Cloud at HPE, as does Black. O’Dorisio and Russo overlapped at Iron Mountain and EMC.
…
Storage industry analyst firm DCIG has named Infinidat‘s InfiniBox and InfiniGuard solutions as among the top five cyber secure backup targets. DCIG reviewed 27 different 2 PB+ cyber secure backup targets as part of its independent research in the enterprise market where ransomware and malware are first attacking backup targets to hinder an enterprise from recovering from a cyberattack. DCIG opted to solely focus its report on cyber secure backup targets that supported NAS interfaces. The top five suppliers/products were ExaGrid EX189, Huawei OceanProtect X9000, Infinidat InfiniBox/InfiniGuard, Nexsan Unity NV10000, and VAST Data’s Data Platform. The “2024-25 DCIG TOP 5 2PB+ Cyber Secure Backup Targets Global Edition” report is now available here.
…
Neurelo emerged from stealth, introducing a comprehensive and extensible data access platform that enhances developer productivity by simplifying and accelerating the way they build and run applications with databases. The Neurelo Cloud Data API Platform is generally available as of today, providing auto-generated, purpose-built REST and GraphQL APIs, AI-generated custom-query endpoints, deep query observability, and Schema as Code. The company has secured $5 million in seed funding led by Foundation Capital with participation from Cortical Ventures, Secure Octane Investments, and Aviso Ventures.
Torsten Volk, managing research director, Enterprise Management Associates (EMA), said: “Neurelo turns data sources into centrally controlled and governed APIs that developers can simply consume instead of having to worry about the intricacies of the specific type of database. The ability for DBAs, cloud admins, IAM admins, and other relevant roles to ensure consistency and compliance of individual databases organization-wide instead of chasing after each data source separately is a significant upside of the Neurelo platform.”
…
Belgian company MT-C S.A., which produces the Nodeum HPC data mover product, is renaming itself Nodeum.
…
Own Company, a SaaS data protection supplier, launched a global Channel Partner Program so resellers and system integrators can prevent their customers from losing mission-critical data and metadata. With automated backups and rapid recovery, Own partners will be equipped with the resources, skills, and support necessary to generate new lines of business and increase profit margins.
…
Scale-out filer Qumulo announced the availability of Superna Data Security Edition for Qumulo and its Ransomware Defender, which automates real-time detection of malicious behaviors, false positives, and other events consistent with ransomware access patterns for both SMB and NFS files. Superna Data Security Edition for Qumulo detects malicious behavior at the onset (often referred to as the “burrowing event”) and also automates access lockout. Superna’s native integrations with SIEM, SOAR, and ticketing platforms automatically alerts administrators and other users involved in incident response, providing them with the information required to accurately prioritize the incident. Get more information here.
…
Wells Fargo analyst Aaron Rakers met Seagate CFO Gianluca Romano and told subscribers: “Seagate is not focused on, nor does it expect, its leadership position in HAMR-based HDDs to drive nearline market share expansion.” No need for Western Digital and Toshiba to worry then.
…
The Financial Times reports that SK hynix will build a plant in Indiana to stack DRAM chips into HBM units for packaging with Nvidia GPUs in other, possibly TSMC, plants in the USA.
…
The SNIA’sStorage Management Initiative (SMI) announced that the Swordfish v1.2.6 bundle is now available for public review. Swordfish provides a standardized approach to manage storage and servers in hyperscale and cloud infrastructure environments. Swordfish v1.2.6 key features include:
New “NVMe-oF and Swordfish” white paper, which discusses how NVMe over Fabrics (NVMe-oF) configurations are represented in Swordfish Application Programming Interface (API).
New metrics for FileSystem, StoragePool, StorageService, and enhancements to VolumeMetrics.
New mapping and masking models using Connections in the Fabric model and deprecates StorageGroups.
Support for new volume properties: ProvidingStoragePool, ChangeStripSize, Asymmetric Logical Unit Access (ALUA) to manage reservations
Enhancements to NVMe Domain Management, including ALUA support.
Updates to NVMe namespaces, such as simplified Logical Block Address (LBA) Format representation and multiple namespace management.
…
Startup Zilliz, which supplies the open source Milvus vector database, has a forthcoming Zilliz Cloud service update, with RAG/GenAI, recommendation systems, and cybersecurity/fraud detection capability. RAG/GenAI will empower autonomous agents replacing human support agents. Recommendation systems will be powering ads, product, and news recommendations based on user preferences and actions taken. The cybersecurity features will be applied in banking transactions and antivirus systems to quickly identify anomalies in new data by finding similarities within a short time frame.
UK-based NexGen Cloud has signed up Weka to provide parallel access filesystem software for its GPU-as-a-Service customers, becoming Weka’s third GPU cloud farm customer.
GPU-as-a-Service (GPUaaS) operations are spinning up in response to the generative AI training and inferencing boom. They buy thousands of Nvidia GPUs and rent them out on a pay-per-use basis. Enterprises buying smaller numbers of GPUs or GPU servers are finding that the supply is constrained because Nvidia can’t get enough of them built to meet the demand. NexGen Cloud, started up in 2020, has one of the largest GPU fleets in Europe – including H100 GPUs – and it’s powered by renewable energy sources. Nexgen says its services are up to 75 percent more cost-effective than legacy cloud providers. Weka’s Data Platform is a fast scale-out and parallel filesystem with integrated data services.
Weka president Jonathan Martin explained in a statement: “GPU cloud providers like NexGen Cloud will play a critical role in accelerating the next wave of AI innovation. The Weka Data Platform helps GPUs to run at peak performance and efficiency, reducing energy consumption and giving customers a much more sustainable way to run enterprise AI workloads – even at extreme scale.”
NexGen has an existing HyperStack offering and is developing an AI Supercloud. Both use Weka’s filesystem to provide file storage for customer data. NexGen plans to invest $1 billion to build its AI Supercloud in Europe, with $576 million already committed in hardware orders with suppliers. Deployment in European datacenters began late last year.
Chris Starkey, cofounder and CEO at NexGen Cloud, recalled: “When we started building our AI Supercloud solution, we looked at several data platforms and parallel filesystem solutions. The environment’s extreme scale and performance demands quickly removed other vendors from consideration.”
Weka being software-defined and hardware-agnostic was a characteristic that resonated with Starkey. “The Weka Data Platform immediately stood out, not only for its exceptional performance and low latency but also for its ability to maximize the efficiency of our GPU cloud with a hardware-agnostic, innovative software solution. It enabled us to leverage existing hardware investments and power all of our cloud services as efficiently and sustainably as possible, which is core to our mission.”
Weka competitor VAST Data has benefited from GPU cloud farm adoption, counting CoreWeave, Lambda Labs and Genesis Cloud as customers. Its pitch is that standard NFS is easier to use than parallel filesystems, like Weka’s Data Platform. Weka’s pitch is that its software provides very high performance, is hardware-agnostic, and has lots of data services.
Weka has existing filesystem supply deals with two North American GPUaaS providers: Applied Digital (under Sai Computing) and Iris Energy – a Canadian bitcoin miner and GPUaaS operator with datacenters in Canada, the US and Australia. Incidentally, Iris Energy also uses renewable energy sources.
Find out more about NexGen Cloud’s GPU cloud offerings powered by Weka here.