


GPU cloud service provider Lambda Labs is using VAST Data to store customers’ AI training data across its 60,000+ Nvidia GPU server cloud and co-location datacenters.
This deal closely follows a similar one between VAST and CoreWeave last month. Like CoreWeave, Lambda is seeing a sustained rise in demand for its GPU services as customers use them for large language model training. It offers a hyperscale GPU cloud, co-location-housed, GPU-focused datacenters, and customer-housed Echelon hardware systems, with an open source Lambda software stack covering all three.
Mitesh Agrawal, head of cloud and COO at Lambda, said: “The VAST Data Platform enables Lambda customers with private cloud deployments to burst swiftly into Lambda’s public cloud as workloads demand. Going forward, we plan to integrate all of the features of VAST’s Data Platform to help our customers get the most value from their GPU cloud investments and from their data.”
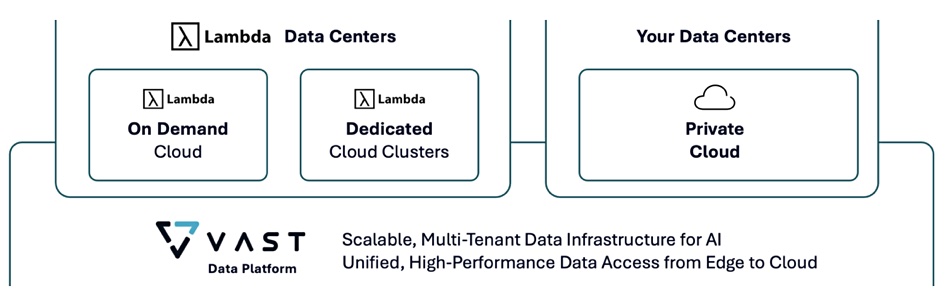
The deal takes advantage of VAST Data’s Nvidia SuperPod certification and also its DataBase and DataSpace, a global file and object namespace across private and public cloud VAST deployments. Customers can store, retrieve, and process data consistently within this namespace.
Renen Hallak, VAST Data founder and CEO, said: “We could not be happier to partner with a company like Lambda, who are at the forefront of AI public and private cloud architecture. Together, we look forward to providing organizations with cloud solutions and services that are engineered for AI workloads, offering faster LLM training, more efficient data management and enabling global collaboration.”
VAST’s DataSpace means that customer data is accessible across the three Lambda environments. In a blog we saw before publication, VAST co-founder Jeff Denworth says: “We’re already working with several large Lambda customers who want to realize this vision of hybrid cloud AI data management.”
Bootnote
Lambda Labs provides access to Nvidia H100 GPUs and 3,200 Gbps InfiniBand from $1.89/hour, the claimed lowest public price in the world.
It says it’s a deep learning infrastructure company building a huge GPU cloud for AI training. It was founded in 2012 by Michael Balaban and CEO Stephen Balaban. They developed a facial recognition API for Google Glass, based on machine learning, a wearable camera, AI Echelon and Tensor hardware, and an internal GPU cloud. This became the Lambda GPU cloud in 2018. People could use its Nvidia GPU compute resources in Amazon compute instance style. It also offers co-location space in San Francisco and Allen, Texas.
Lambda has had several funding rounds totaling $112 million, including a $15 million round in July 2021 and a $44 million B-round in March this year. As the GenAI surge accelerates, a follow-on $300 million round is being teed up, according to outlets such as The Information, so it can buy more GPU server systems.
It expects 2023 revenues in the $250 million area and $600 million for 2024.
Download a Lambda Stack PDF doc here.




