Distributed cloud storage firm Storj has a new CEO. Colby Winegar has been promoted to the role after previously serving as chief revenue officer.
Colby Winegar
Prior to Storj, Winegar co-founded and led CrowdStorage, another distributed cloud storage player. He was also previously at Vivint Smart Home.
Ben Golub, outgoing Storj CEO and current executive board chairman, said: “Colby has been instrumental to Storj’s most significant developments, including the acquisitions of Valdi and PetaGene this year, cultivating outstanding customers, and building an award-winning partner ecosystem.”
Golub has served as CEO and executive chair for over six years. The process of shifting responsibilities to Winegar is said to have begun six months ago. Golub will continue as executive chair.
Storj reckons its distributed solutions yield “up to” 90 percent lower costs and 83 percent less carbon emissions for customers. Winegar said: “With AI adoption accelerating across industries, enterprises need new solutions to manage skyrocketing amounts of data, while innovating more rapidly, affordably, and sustainably.
“As CEO, I will continue leading the company’s direction together with technical alliance partners, customers, and resellers, which increasingly recognize the transformative capabilities Storj delivers.”
Storj’s S3-compatible storage architecture uses unused capacity distributed across drives and datacenters in more than 100 countries and over 20,000 points of presence. It also provides GPUs on-demand via its distributed global network, and offers a client mount, so customers can treat file storage the same as object storage and vice versa.
Winegar was Storj senior vice president, business development, from June 2022 to April 2023. He then took the chief business development job up to January 2024, before being appointed CRO.
To fill the CRO role, Storj recently hired a leader for the direct sales organization and promoted an internal person to run the channel sales team; both report directly to Winegar.
In August, Storj said it had “made access to AI compute a bit easier” by working with CUDOS. CUDOS is a DePIN (decentralized physical infrastructure network) for AI and Web3 applications and workloads. It has access to hard-to-get H100 chips, we’re told, and the latest liquid-cooled H200 chips from Nvidia, which support AI workloads.
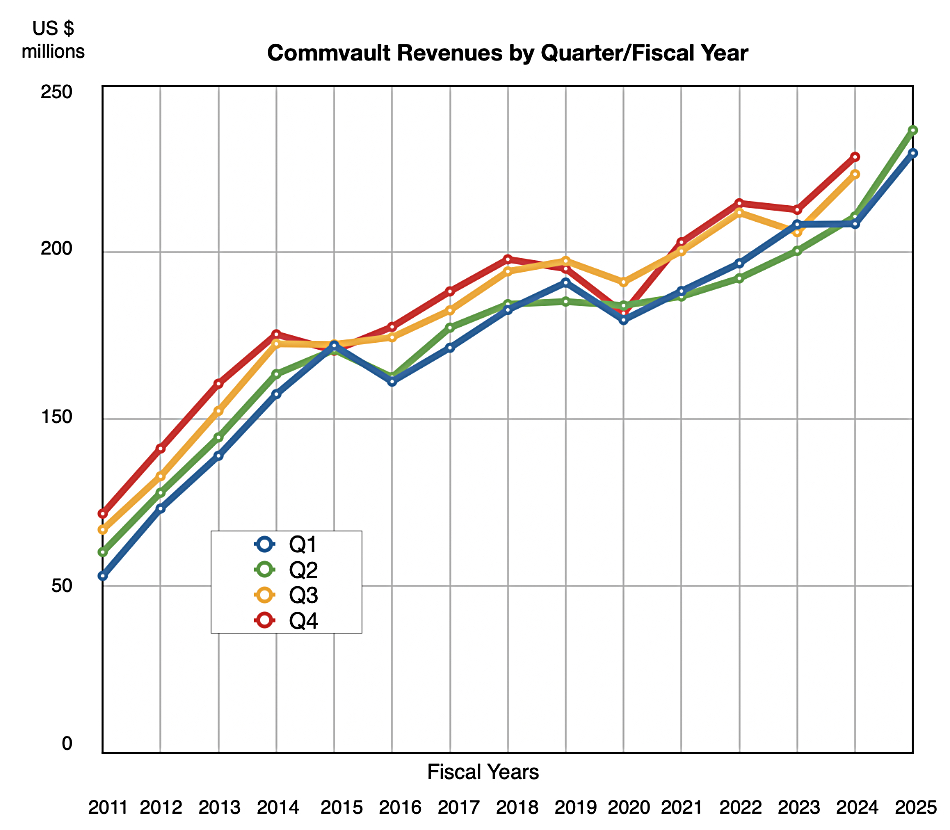
Commvault beat last quarter’s revenue outlook as its data security, subscription-focused business grew faster than anticipated.
Revenues in its second quarter of fiscal 2025 – ended September 30 – were $233.3 million, 16 percent higher than a year ago and beating its $222 million high-end guidance. This was its fourth consecutive quarter of double-digit growth.
Jen DiRico
It reported a $15.6 million net income, up 19.8 percent. Annual recurring revenue (ARR) rose 20 percent to $853.3 million with subscription ARR going up 30 percent to $687 million and SaaS ARR jumping 64 percent to $215 million, a record. The subscription revenue for the quarter was $134 million, up 37 percent year-on-year.
CFO Jen DiRico said in the earnings call: “We’re really proud of the execution that we saw in the first half of the year. It really does a testament to not only what we’re seeing from a product perspective, but overall execution by the sales team.”
Commvault now has 10,500 large subscription customers, up from 8,300 a year ago and 9,900 last quarter.
President and CEO SAnjay Mirchandani opened the earnings call by saying: ”Q2 was an exceptional quarter with momentum once again accelerating across all our primary KPIs,” meaning key performance indicators: ARR, subscription ARR, total revenue, subscription revenue, non-GAAP EBIT margin and free cash flow.
Commvault’s fifth recent growth quarter has the steepest rise
Financial summary
Gross margin: 82.2 percent, up 20 basis points annually
Operating cash flow: $55.6 million
Free cash flow: $53.7 million
Cash and cash equivalents: $303.1 million
Stock repurchases in quarter: $51,600,000, equalling 97 percent of free cash flow
Commvault is now a data security company, with data protection being a major part of that. Mirchandani said: “In an age of nonstop threats and cyber-attacks, organizations need to be ready. And once that moment comes, they need to be able to quickly recover without missing a heartbeat.”
“This is even more important in the cloud-first world that we live in today. … IDC reported that 73 percent of all new data that will be stored in the cloud and that spending on public cloud services is expected to double in the next four years.”
Hence Commvault’s emphasis on its Metallic – now Commvault Cloud – SaaS protection in the cloud business and its recent acquisitions of Clumio and Appranix. He said: “We expect to release an enhanced Active Directory offering shortly” and: “We’re bringing the breadth of the Commvault Cloud Cyber Resilience platform to AWS customers.”
Sanjay Mirchandani
He emphasized: ”We’re serious when we say no workload, no cloud and no application left behind.”
As well as onboarding 600 new customers in the quarter, DiRico said: ”Existing customer expansion remained healthy with a Q2 SaaS net dollar retention rate of 127 percent, driven by both upsell and cross-sell.” That’s: “one third cross-sell and two-thirds upsell.”
Hinting at acquisitions, DiRico said: “We remain opportunistic around technologies that further the depth and breadth of our platform.”
Analyst Aaron Rakers asked about the status of the Commvault-Dell Data Domain partnership, and Mirchandani said: “When we announced it, Aaron, I was very clear that this is not a short-term thing. Taking out entrenched sort of incumbents needs an overall strategy, needs Cyber Resilience end-to-end, and that’s exactly the kind of wins we’re having. This is work in progress. We’re working together. It’s moving along well. We’ve got lots and lots of good stuff happening, but I’m not putting out a number in any way around that specifically.”
Mirchandani was asked about consolidation in the backup supplier business and said: ”I’ve been saying this for a while that there is a platform consolidation required in the industry. Just over the years, there have been too many big part programs. There have been too many best-of-breed ‘capabilities’ that have been inserted into enterprises, which – and I think I’ve said – I said last quarter, I’d say again, in this case, more is not necessarily better.”
And: “having an end-to-end capability that really allows you to see every single workload every application and every cloud and one pane of glass is the right approach. Now – it’s a journey. This is not easy.”
Commvault is: “going to go the entire distance and [our] one platform allows customers to do any workload, any cloud, any application, whether it starts on-premise, on the edge or in the cloud and wants to move between them. So, that’s been our stated direction. And we are putting every ounce of engineering energy we’ve got into that.”
He went on to claim the company was taking market share from some of the other incumbents.
Next quarter’s revenues are being guided to be $245 million +/- $2 million, up 13 percent annually at the mid-point. The company is lifting its full year revenue guidance to $954.5 million +/- $2.5 million, 13.7 percent higher than last year at the mid-point. It was projecting $920 million +/- $5 million. The full year guidance rise is quite large, reflecting the third quarter’s outlook. Commvault still expects to have more than $1 billion in ARR in its fy2026 (>15 percent CAGR) and more than $330 million in SaaS ARR (>40 percent CAGR).
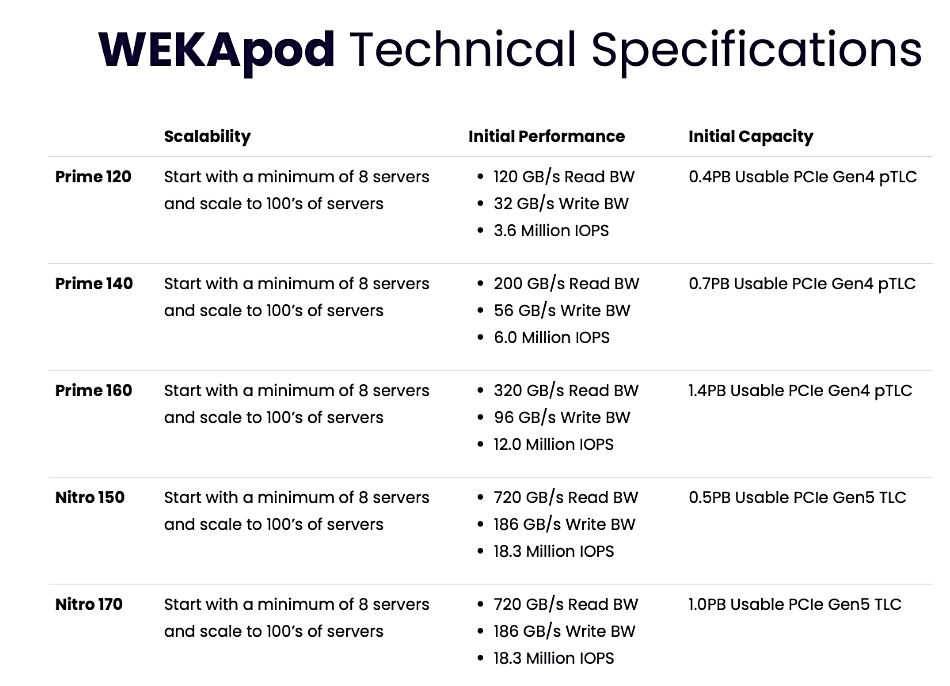
Fast filer software shipper WEKA has designed two versions of its WEKApod storage appliance for AI training and inference.
The WEKApod appliance is a storage server appliance able to store and push data out to GPU servers such as Nvidia’s SuperPOD. Each appliance consists of pre-configured hardware + WEKA Data Platform SW storage nodes built for simplified and faster deployment. A 1 PB WEKApod configuration starts with eight storage nodes and can scale out to hundreds.
Nilesh Patel
WEKApod Nitro configurations use the PCIe gen 5 bus and are slated for large scale enterprise AI deployments. WEKApod Prime configurations use the slower PCIe gen 4 bus and are for smaller scale AI deployments.
Nilesh Patel, WEKA’s chief product officer, claimed in a statement: “Accelerated adoption of generative AI applications and multi-modal retrieval-augmented generation has permeated the enterprise faster than anyone could have predicted, driving the need for affordable, highly-performant and flexible data infrastructure [systems] that deliver extremely low latency, drastically reduce the cost per tokens generated and can scale … WEKApod Nitro and WEKApod Prime offer unparalleled flexibility and choice while delivering exceptional performance, energy efficiency, and value.”
WEKA says its Data Platform software delivers scalable AI-native data infrastructure purpose-built for the most demanding AI workloads, accelerating GPU utilization and retrieval-augmented generation (RAG) data pipelines efficiently and sustainably and providing efficient write performance for AI model checkpointing.
WEKApod Nitro scales to deliver more than 18 million IOPS in a cluster and is SuperPOD-certified. WEKApod Prime can scale up to 320 GBps read bandwidth, 96 GBps write bandwidth, and up to 12 million IOPS for customers with less extreme performance data processing requirements.
Open-source object storage supplier MinIO has tweaked its code so AI, ML, and other data-intensive apps running on Arm chipsets go faster.
Manjusha Gangadharan
Arm servers are making inroads against Intel and AMD in the datacenter. In MinIO’s view, object storage has become foundational to AI infrastructure with all the big LLMs (Large Language Models) being built on object storage. The company released its DataPOD reference architecture in August, to help customers build exascale MinIO stores for data needing to be pumped out to AI workload GPUs. MinIO is also working with Intel and providing the core object store within its end-to-end Tiber AI Cloud development platform.
Manjusha Gangadharan, head of Sales and Partnerships at MinIO, stated: “As the technology world re-architects itself around GPUs and DPUs, the importance of computationally dense, yet energy efficient compute cannot be overstated. Our benchmarks and optimizations show that Arm is not just ready but excels in high-performance data workloads.”
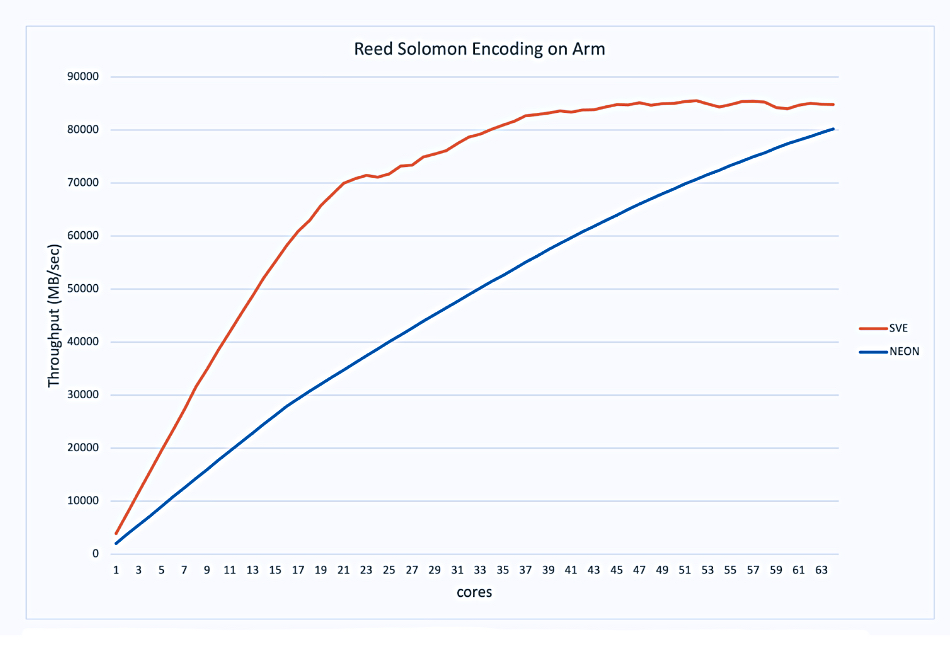
MinIO said it made use of Arm’s Scalable Vector Extension Version (SVE) enhancements – SVE improving vector operation performance and efficiency – to improve its Reed Solomon erasure coding library implementation. The result was 2x faster throughput compared to its previous NEON instruction set implementation, it claimed:
The new code uses a quarter of the available cores (16) to consume half the memory bandwidth used by NEON.
SVE offers support for lane masking via predicated execution, allowing more efficient use of the vector units. Support for scatter and gather instructions makes it possible to efficiently access memory more flexibly.
MinIO also boosted performance for the Highway Hash algorithm it uses for bit-rot detection, using SVE support for the core hashing update function. The algorithm is frequently run during both GET (read) as well as PUT (write) operations.
NVIDIA’s BlueField-3 smartNIC/DPU (Data Processing Unit), which can effectively front-end storage drives, has an on-board 16-core Arm CPU and MinIO’s software can run on that. MinIO says that, with 400Gbps, Ethernet, BlueField-3 DPUs offload, accelerate and isolate software-defined networking, storage, security and management functions. “Given the criticality of disaggregating storage and compute in modern AI architectures, the pairing is remarkably powerful.”
Eddie Ramirez, VP of marketing and ecosystem development, Infrastructure Line of Business, Arm, played the power efficiency card, saying: “Delivering performance gains while improving power efficiency is critical to building a sustainable infrastructure for the modern, intensive data processing workloads demanded by AI. Performance efficiency is a key factor in why Arm has become pervasive across the datacenter and in the cloud, powering server SoCs and DPUs.”
We think that MinIO and Arm could play a role in AI inferencing workloads as edge IT locations. Their presence in the datacenter relies on DC operators adopting Arm servers over x86 boxes and that could happen as Arm server performance and power efficiency match power-restrained data center needs.
Scality’s all-flash RING XP provides GPUDirect class object storage for AI workloads, enabling it to compete with file systems in pumping data to GPU servers.
The RING is Scality’s core object storage software and it has been loaded with optimizations to provide object storage with, we’re told, microsecond response-time latencies for small object data, making it ideal for AI model training and fine-tuning. Scality claims it is 10–20X faster than Amazon S3 Express One Zone and 50–100X faster than Amazon S3 in terms of latency, meaning microsecond speed instead of milliseconds. GPUDirect is an Nvidia file storage access protocol enabling direct GPU server-to-NVME-storage-drive-access to lower access latency.
Giorgio Regni
Giorgio Regni, CTO and co-founder of Scality, said in a statement: “Object storage is a natural foundational repository for exabytes of data across the AI pipeline. With RING XP, we’ve not only optimized object storage for extreme performance but also reduced data silos — offering one seamless flexible technology for both long term data retention and ultra-high performance AI workloads.”
S3 Express One Zone’s latency to the first byte is in the single-digit milliseconds compared to S3 standard with double-digit millisecond latency, claims Scality. It says RING XP (eXtreme Performance) has:
AI-optimized object storage connectors to provide scale-out, fast access to storage from applications
Performance-tuned software that accelerates storage I/O throughout the storage stack
AMD EPYC-based all-flash NVMe storage servers from Lenovo, Supermicro, Dell and HPE with support for PCIe and NVMe, and the highest number of cores in single-socket CPUs to deliver optimal latencies
Scality claims the XP version of RING provides microsecond-level write (PUT) and read (GET) latency for 4KB objects. It can also provide storage for all AI pipeline stages, from ingesting massive datasets to model training and inference. RING XP has integrated lifecycle management covering these pipeline stages and a common framework of management and monitoring tools.
It also has integrated Scality CORE5 capabilities to boost security and data privacy.
We wanted to dive deeper into RING XP and here is how Regni and Scality CEO and founder Jérôme Lecat answered our questions:
Blocks & Files: How does RING XP achieve its higher level of performance?
Scality: RING XP achieves this new level of object storage performance for AI in a few key ways.
[We’re] streamlining the object API: the right tradeoff for AI applications is to eliminate unnecessary API features and heaviness in exchange for low latency and high throughput – as Amazon has shown the market with S3 Express One Zone.
With that said, we believe that Amazon left its users with a weak tradeoff in S3 Express One Zone that doesn’t provide sufficient performance gains. With RING XP we’re going even further by simplifying the object stack and removing features that are commonly performed at a higher level in the stack.
For example, every data lake management system (or data lake house) maintains an indexed view of all data across the entire dataset. That’s why we made the decision to remove object listing from RING XP since it would be an unnecessary duplication of functionality and effort.
RING XP software implements several optimizations in our software that led us to power the largest email service provider platforms in the world, for processing 100K small object transactions per second.
Blocks & Files: Have you managed to get GPUDirect-like capabilities into Ring? Is there some way Ring XP sets up a direct GPU memory-to-SSD (holding the object data) connection?
Scality: RING XP currently achieves microsecond latencies even without Nvidia GPUDirect, as current libraries don’t yet support object storage directly. However, we have active R&D underway for GPUDirect compatibility with object storage, which we see as a major opportunity to further reduce RING XP’s latency.
GPUDirect for filesystems uses FIEMAP (the ioctl_fiemap() command), which retrieves the physical location of file data on storage by mapping file extents. This is valuable for direct-access applications like GPUDirect Storage, as it enables the GPU to access data blocks directly on disk or over the network during training or inference.
To achieve similar functionality, we’re developing an extension for the S3 protocol in RING and RING XP called ObjectMap. ObjectMap will provide the same extent-level data mapping as FIEMAP, but it will be native to our object storage system.
Our goal is to publicly document ObjectMap to enable other object storage systems to adopt it, aiming to make it an industry standard and position object storage as the optimal solution for AI deployments.
It’s also worth noting that Nvidia’s MAGNUM-IO toolchain currently relies heavily on filesystem-based data, such as local storage or NFS. Moving forward, we anticipate the need for that toolchain to evolve and become more storage-agnostic.
Blocks & Files: Out of curiosity, does the Nvidia BaM concept have any relevance here?
Scality: Yes, Nvidia’s BaM concept is highly relevant. By enabling GPUs to directly access SSDs, BaM could allow object storage to effectively expand GPU memory, letting GPUs access object data directly. With a mapping layer similar to FIEMAP, BaM could make object storage a practical, high-speed extension for GPU memory, benefiting AI and analytics workloads that require rapid data retrieval.
Blocks & Files: Is RING XP protected by patents? And I expect there is a RAG angle here as well. Perhaps the Ring can store vectors as objects?
Scality: Yes, RING XP is indeed protected by our core patent. Key elements include:
Low-latency DHT: the architecture builds a distributed hash table over the storage nodes, ensuring guaranteed, bounded access times without needing a central database. This eliminates bottlenecks typical in centralized architectures.
O(1) Access: In normal operations (no disruptions), access nodes cache the entire topology, enabling O(1) access to any object in the system, contributing to our low-latency performance.
Late Materialization: this technique enables network operations to first hit memory or fast metadata flash for a high percentage of IO requests. This optimizes performance (latency) by shielding the disk drives used to store data for all non-data operations. With NVMe flash at the storage layer, RING XP maintains microsecond response times through the full IO stack.
We’re excited to push object storage into new territory with RING XP, and we have patents pending to protect this innovation further, around optimizing on drive data layout for GPUs and vector data co-location.
On storing vectors, absolutely – RING is designed to handle vector data as objects, making it ideal for RAG (Retrieval-Augmented Generation) applications and AI workloads requiring rapid access to complex datasets.
As an object store, RING already provides a comprehensive capability for storing user-/application-extended metadata along with the object data, and this will be an ideal mechanism for storing vectors.
Object storage is ill-suited to supporting AI, ML, and HPC workloads because it can’t pump data fast enough to the many processors involved. File systems can do that but cloud file storage is expensive – compared to S3 object storage.
Gary Planthaber
Paradigm4’s CTO Gary Planthaber has been deeply involved in bridging this divide by creating the flexFS file system to turbocharge object storage with a POSIX-compliant, fast throughput file access front end. He joined Paradigm4, a provider of large scale data set management software for life sciences customers, in 2018. That software, which includes the SciDB database, has distributed computing and parallel processing capabilities.
Planthaber has written a Medium article about the how-and-why of flexFS’s foundation, and explains that Paradigm4 wanted to help pharma companies develop drugs by looking into massive datasets of genomic, medical history, and diagnostic scan data for 500,000 or more patients, and population-scale biobanks. It wanted to trace genetic element links to ill health using phenotypes (observable traits of an individual determined by their genotype and the environment) and genotypes (genetic makeup).
This analytical processing work involves “large clusters comprising hundreds of powerful servers working together to provide researchers with answers within a reasonable period of time.” Typically this work is done in the public cloud so that the necessary servers can be spun up when needed and then shut down when the job is done. This saves server provisioning and operating cost.
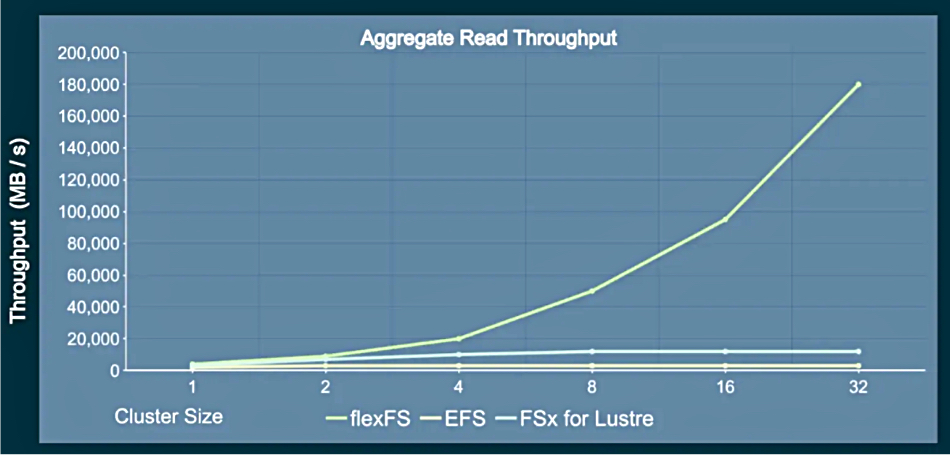
But there is so much data that each computational node only has access to parts of it, which are streamed from the data storage source – hundreds or thousands of GB in size – and not stored on direct-attached storage drives. Planthaber explained the core requirement was “to maximize cluster-wide throughput” with latency being a secondary concern as so much data is being read. He needed a rate of around 1GB/sec per cluster server node – 500GB/sec for a 500 server cluster.
Amazon’s EBS was not suitable as: “It turns out that the sustained throughput of EBS for large files is actually not very high.” Amazon EFS also did not match the need as “the EFS limited pool of throughput gets exhausted easily when concurrently transferring gigabytes of data to hundreds of consumers.” EFS provisioned throughput is expensive and “when hundreds of servers are performing sustained reads of several gigabytes of data concurrently, we witnessed a complete meltdown. Unfortunately, that happened to be our primary use-case, so we ultimately had to abandon EFS.”
Amazon FZSx for Lustre was prohibitively expensive as: “we would have to provision far more storage capacity than we needed in order to get enough aggregate throughput to service a cluster of hundreds of servers with anywhere near 1GB/sec throughput each.”
Amazon S3 could meet Paradigm4’s cost and throughput goals, but is not a file system and “the tools that we need to run on our analysis servers expect to see files as inputs.”
Planthaber said he realized that: “What we really wanted was a proper POSIX network file system with the pricing, durability, and aggregate throughput of S3” with file data stored in physical blocks to mitigate S3 API charges and latency. There were several open-source S3-backed file systems, such as s3backer, but they were all unsuitable. For example, “we couldn’t use s3backer to read data and also write results at the same time on multiple servers.”
Throughput performance of flexFS vs EFS and FSX for Lustre
So “we decided to build our own commercial S3-backed file system” using Paradigm4’s own software engineers – the result is flexFS.
Planthaber has written an Introduction to flexFS article in which he notes it features POSIX-compliance and Linux advisory file locking. He mentions that: “We also went to great lengths to ensure that XATTRs and extended ACLs are fully supported by flexFS.”
To counter S3’s high latency, he writes: “We decided to separate file system metadata handling into a lightweight, purpose-built metadata service with low latency and ACID compliance. This adds a small amount of infrastructure cost but pays dividends through much faster metadata performance and safety.”
Also, “By assigning persistent IDs to every file inode in flexFS and only building S3 keys using these inode IDs rather than dentries, we can perform file system path operations (mv, cp, ln, etc.) entirely within our low-latency metadata service without touching S3 at all.”
File data partitioning is dealt with like this: “The address space of all file data is partitioned into fixed-sized blocks (i.e., the file system block size), which map to deterministic indices. … Having file data partitioned into fixed-sized address blocks allows flexFS to support highly parallel operations on file data and contributes to its high-throughput characteristics. It also allows flexFS to store extremely large files that go well beyond the 5TB size limit S3 imposes on objects.”
Cost of flexFS vs EFS and FSx for Lustre
Compression is also used to cut down storage space and network time. “By default, flexFS compresses all file data blocks using low-latency LZ4 compression. Though this feature can be disabled, it nearly always yields performance and storage cost benefits.
“We have, in practice, seen dramatic reductions in the storage space needed by S3 file data objects, even when source files had already been compressed. For example, we can see a real-world HDF5 file with 1.6TB of data has been reduced to 672GB of data stored in S3.”
Both file system data and metadata are encrypted.
All-in-all, “We built flexFS to be a high-throughput, cloud-native network file system that excels at concurrently streaming large files to large clusters of servers.” The software was launched in 2023.
It works and is successful, Planthaber observed. ““”flexFS is being used in production by multiple top-tier biotech and pharmaceutical organizations to analyze large volumes of mission-critical data.” Other customers operate in the climate science and insurance risk modeling areas.
As it has a pluggable backend architecture, flexFS can also be used in the Azure and Google public clouds and others as well.
Tesla is reportedly talking to SK hynix about a potential ₩1 trillion ($725 million) order for the high-capacity SSDs it will need to store data for its AI training supercomputers.
This is according to a report by the Korea Economic Daily, whose chip industry sources reckon the storage product in question is SK-hynix-owned Solidigm’s 61.44 TB D5-P5336 SSD made with QLC (4bits/cell) flash. It is a PCIe gen 4 drive and a single unit price is around $7,300. A $725 million order value would imply 99,315 drives at full price, and around 200,000 at a 50 percent volume discount, providing 12.3 EB of capacity.
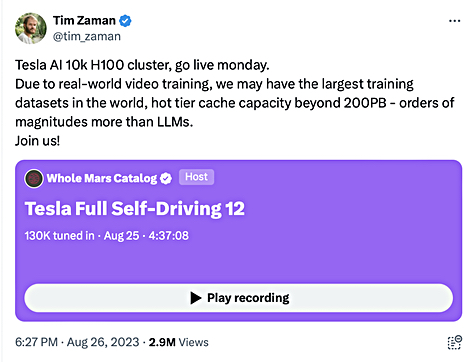
Neither SK hynix nor Tesla have responded to a request for comment about the claimed deal, but whether or not such talks are taking place, Tesla’s need for SSDs to feed AI training data to its GPUs is very real – and huge. Its Dojo supercomputing infrastructure, spread across three sites is being used to develop Tesla’s Autopilot and Full Self-Driving (FSD) mode software for its electrically powered cars and trucks. One Dojo supercomputer employs 10,000 NVIDIA H100 GPUs in a gigantic cluster, according to a tweet from Tim Zaman – formerly of Tesla and currently working for Google’s Deepmind AI team – last August.
Zaman tweet. SSDs could provide the 200PB+ of hot-tier cache storage.
Zaman was then an AI Infra & AI Platform Engineering Manager at Tesla. He’s now a software engineer at Deep Mind.
Another and more recent report suggests Dojo will use 50,000 H100s plus Tesla’s own 20,000 wafer-scale AI processors using internally developed D1 chips set out in a 5×5 matrix of 25 x D1s per wafer. Tesla is building a second Dojo supercomputer at Austin, Texas, and the Dojo systems will also be used to develop AI software for FSD and to operate the Optimus robot.
Elon Musk’s xAI business is building a separate Colossus supercluster in Memphis, Tennessee, with >100,000 H100 GPUs on a single RDMA fabric, and exabytes of storage. Supermicro built the servers using its liquid-cooled racks, each with 8 x 4RU Universal GPU system servers, fitted with 8 x NVIDIA H100s, meaning 64 GPUs per rack. The racks are grouped in mini-clusters of 8, meaning 512 GPUs, plus networking. That implies, with c100,000 GPUs in total, there are some 200 mini-clusters, and these are deployed in 4 x 25,000 GPU data halls.
Much of the storage hardware is based on Supermicro Storage Servers, such as the 1RU NVMe storage node with 8 x 2.5-inch all-flash storage bays. The storage software comes from several sources including, we understand VAST Data.
Nvidia said on Oct 28: “Colossus, the world’s largest AI supercomputer, is being used to train xAI’s Grok family of large language models, with chatbots offered as a feature for X Premium subscribers. xAI is in the process of doubling the size of Colossus to a combined total of 200,000 NVIDIA Hopper GPUs.”
Tesla CEO Elon Musk has tweeted about Tesla’s Cortex AI training supercomputer cluster being built at its Gigafactory in Austin, Texas. You can check out a short video of Cortex here. We understand that this is a renamed Dojo system.
We view Tesla as having a Dojo infrastructure for FSD and Optimus bot training, with the original Dojo system based in California using sites in San Jose (ex-Twitter) and Sacramento. Dojo 2 is what is being called Cortex, based at the Gigafactory site in Austin, Texas. Dojo 3 will be the Buffalo, New York, installation.
Together, the three Dojo sites plus the xAI Colossus system in Memphis, Tennessee – four AI supercomputer clusters in all – means that Tesla has an almost insatiable need for AI training compute power and, hence, also for fast access to AI training data. And that means SSDs.
QLC SSDs provide an excellent mix of capacity and access speed for AI model training and can keep GPUs active better than disk drives with their long access time. Having a reliable, long-term supply deal for the tens of thousands of SSDs needed would make sense.
Solidigm was an early entrant into the QLC SSD market and is now developing a 122TB follow-on. Competitors like Samsung are also building 61.44TB SSDs, its BM1743, and developing 128TB ones. Western Digital also has its own 61.44 TB SN655 drive.
SK hynix supplies high-bandwidth memory (HBM) chips used by NVIDIA to build its GPU servers, and Tesla represents a huge end-user customer for SK hynix and its DRAM and SSD products – possibly its single largest customer.
Nvidia’s Enterprise Reference Architectures (ERAs) are blueprints for building AI workload-focused datacenters to, as Nvidia says, manufacture intelligence. ERAs help Nvidia systems partners and joint customers build their own AI factories. An ERA provides full stack hardware and software recommendations, with the hardware side overseeing servers, clusters, and networking.
Bob Pette
An Nvidia blog by Bob Pette, VP and GM for enterprise platforms, claims that each ERA covers:
Nvidia-certified server configuration, featuring its GPUs, CPUs and networking technologies to deliver performance at scale.
AI-optimized networking with Nvidia’s Spectrum-X AI Ethernet network and BlueField-3 DPUs to address varying workload and scale requirements.
NvidiaA AI Enterprise software base for production AI, which includes AI application NeMo and NIM microservices, and Base Command Manager Essentials for infrastructure provisioning, workload management and resource monitoring.
ERA systems are available from Nvidia partners including Cisco, Dell, HPE, Lenovo and Supermicro, with 23 certifed datacenter partners, and 577 systems listed in an Nvidia catalog.
The certified servers come in compute, general purpose and high-density VDI categories, with the compute ones appropriate for ERA as they cover AI training and inferencing, data analytics, and HPC.
There is no focus on storage at this ERA level, although it’s needed to keep Nvidia’s GPUs busy, as Nvidia does not supply storage. Instead storage hardware and software is left to Nvidia’s certified server partners, and they use storage that has Nvidia GPU integration, typically including GPUDirect support with its direct GPU server to storage drive RDMA data transfers.
For example, HPE Private Cloud AI’s AI infrastructure stack includes GreenLake for File Storage, based on Alletra MP all-flash storage compute nodes running VAST Data software. This software has Nvidia SuperPOD certification. HPE’s Private Cloud AI itself has has Nvidia BasePOD certification and OVX storage validation.
The new Enterprise Reference Architectures are different from the existing Nvidia AI Enterprise: Reference Architectures (note the colon, which specifies deployments of Nvidia’s AI Enterprise software suite with VMware vSphere).
COMMISSIONED: As enterprises increasingly adopt GenAI-powered AI agents, making high-quality data available for these software assistants will come into sharper focus.
This is why it’s more important than ever for IT leaders to get their data house in order. Unfortunately, most IT shops’ data houses may be messier than they should be, as poor data quality remains one of the biggest challenges confronting organizations’ generative AI strategies.
In fact, 55 percent of organizations avoid certain GenAI use cases due to data-related issues, according to Deloitte research. The consultancy also found that 75 percent of organizations have increased their tech investments around data lifecycle management due to GenAI.
“I think we’re probably spending as much time on data strategy and management as on pure GenAI questions, because data is the foundation for GenAI work,” the chief technology officer at a manufacturing company told Deloitte.
As IT leaders, you know that high-quality data is critical for organizations seeking value from their GenAI use cases – and this is especially true for agentic architectures.
Agents are capable of “thinking,” essentially reasoning, planning, making decisions and learning from feedback. Memory systems help make this possible, ensuring that agents can retrieve information, including relevant context, procedural knowledge of how to execute processes and details about past events.
Enthusiasm for these tools is robust, with 82 percent of organizations saying they expect to adopt AI agents in one to three years, Capgemini says. Eventually, experts say, multi-agent systems – an entire host of agents communicating with each other and other applications as they execute tasks without human intervention – will automate entire workflows and business processes.
That is the dream, anyway. What is real today is that poor data hygiene – data rife with errors or duplications – can break an agentic AI system.
The data preparation playbook
Agents require the right information – high-quality data – in their moment of need to complete their tasks. This user guide can help:
Define requirements: What do you wish to accomplish with GenAI? Do you want to create basic digital assistants, autonomous agents or something else? Will a small language model do, or do you require a LLM? Be sure to account for specific features and attributes you want your applications to execute. Identify and collect: You’ll want to figure out the data you need to achieve your goals. Instruct your data architects and engineers to collect the data necessary to train your systems.
Clean: “Cleaning” data means handling missing values, correcting errors, removing duplicates and addressing outliers. Use undersampling to remove data points from majority groups and oversampling to duplicate data points from minority groups.
Preprocess: You’ll preprocess the data, which may include tokenizing texts, resizing images or extracting audio features. This will make it suitable for training.
Label: You’ll manually assign labels to each data point, underscoring what the data represents. Although time consuming, labeling is essential for training a high-quality model.
Organize: Organize the data for training your model, which includes splitting the data into training, validation and test sets. This is no trivial task, as many organizations struggle with organizing their data.
Model training: With high-quality and well-organized data, you can begin training. This is where the model learns to generate new data consistent with the patterns present in the training data.
Model evaluation: After training, you should evaluate the generative model’s performance using the validation and test datasets. Assess text, images or other outputs to ensure they meet your desired criteria.
Monitor: Regularly monitor the model for errors, inconsistencies and data outliers. Monitoring your data quality helps ensure that your GenAI models are always using the best possible data – and should help you avoid bias creep. Consider bias detection tools to examine your data as you work.
The takeaway
As an IT leader, you can help shape the outcomes of your agents – and any GenAI application or service – by following best practices. This will require embracing data management solutions.
From vector databases that help manage the copious amounts of data LLMs generate to data lakehouses that help consolidate data siloes, there are several emerging tools at your disposal.
Fortunately, trusted advisors can help you navigate this new AI landscape. Dell Technologies offers accelerator workshops, or half-day events in which Dell consultants work with your business and technology stakeholders to brainstorm ideas for AI use cases that can augment your business.
Chinese server and storage supplier YanRong Technologies suddenly showed up on many radars when it appeared in the MLPerf v1 storage benchmark results with a high score a few weeks ago, and that warrants a closer look.
Haitao Wang
YanRong was founded in 2016 by CEO Haitao Wang, an ex-IBMer. It is a Beijing-based business which raised a seed round in 2018, a CN¥50 million ($4.2 million) A-round in 2019, and a CN¥200M ($28 million) B-round this year. It produces products such as the F9000X all-flash array and YRCloudFile software. The biz saw 80 percent year-on-year growth in the first 2024 quarter according to an IDC CHina SDS market report. The report adds it’s at the top six position in the global IO500 Storage List for high-performance computing.
An F9000X datasheet says it is a scale-out server equipped with 5th gen Xeon CPUs, and a PCIe 5 bus hooking that up to U.2 format NVMe SSDs and Nvidia ConnectX-7 host channel adapters. The DRAM capacity range is not specified though.
It supports 400Gbit/sec InfiniBand and 400GbE RoCE networking, and Nvidia’s GPUDirect protocol for direct GPU server memory to storage drive data access.
YanRong F9000X
The networking side can operate TCP and RDMA access at the same time. It supports bandwidth performance aggregation across multiple networks through multi-channel functionality. The system supports POSIX, NFS, SMB and CSI with Linux/Windows POSIX clients.
The F9000X can have up to 22 NVMe SSDs used for data storage, with 7.68TB, 15.36TB, 30.72TB, etc. capacities. Each node has 2x 1.6TB NVMe SSDs used as metadata disks and also 2x 480GB SATA SSDs for the operating system software. Both data nodes and metadata nodes can be expanded as needed.
It achieves up to 260GB/sec in a three-node cluster and 7.6 million IOPS.
The OS provides two replicas and uses erasure coding for data protection. There is no snapshot functionality – a point which is remarked upon in Gartner Peer Insights about the system.
Other suppliers can ship storage servers with similar hardware capabilities, such as Supermicro. YanRong squeezes a lot of performance from the hardware with its YRCloudFile software.
This software provides a parallel filesystem with a global namespace and has optimizations for better RDMA performance in data/task affinity, cache alignment, request encapsulation, and page locking. The system can support data accesses by thousands of clients simultaneously. YanRong says that, as the number of nodes increases, both storage capacity and performance grow linearly.
We’re told that the YRCloudFile Windows client can achieve three times the I/O performance of SMB (compared to industry-standard SMB protocols) under the same configuration and network conditions.
The data and metadata nodes can be scaled independently to suit different workloads. A node’s storage media and networking can be configured to suit particular workloads as well.
The YRCloudFile software is decoupled from any particular hardware. It can run on the F90000X, any standard x86 server or on a public cloud server instance, and it’s available in the AWS marketplace.
The software can automatically and transparently move cold data to object storage and supports loading data from its own drives and cloud object storage for applications. The mapping between bucket and directory integrates “seamlessly with object and file storage for efficient data transfer.”
YRCloudFile should be compared to DDN’s Lustre, IBM’s Storage Scale, Vdura’s PanFS and WEKA’s parallel filesystem software offerings. There is a YRCloudFile Distributed File System brochure available but it requires a registration process with YanRong sending download details to you via email.
Bootnote
The F9000X’s dimensions, without a security panel, are 87.5mm high x 445.4mm wide x 780mm deep. The depth is 808mm with the security panel.
Airbyte announced a new connector to Databricks’ Delta Lake that replicates data from any source. Airbyte says it enables organizations to replicate data into the Databricks Data Intelligence Platform in minutes, with post-load transformation capabilities. To learn more, visit Airbyte’s Delta Lake connector page.
…
CHOROLOGY.ai said its Automated Compliance Engine (ACE) is built on AI-based Knowledge Encoding, a powerful new Domain Language Model (DLM) Paradigm, and AI Planning Automation. These patented technologies coalesce, providing the claimed first and only mandate-agnostic solution to deliver a complete view of all sensitive enterprise data (known and unknown) throughout structured and unstructured environments. A deeper look will follow.
…
Informatica announced the availability of Generative AI (GenAI) Blueprints which make it faster and easier for customers to build enterprise-grade GenAI applications on six technology platforms. The blueprints – for AWS, Databricks, Google Cloud, Microsoft Azure, Oracle Cloud and Snowflake – include standard reference architectures, prebuilt, ecosystem-specific “recipes” and GenAI Model-as-a-Service and vector database connectors to minimize GenAI development complexity and accelerate implementation. The blueprints comprise architectural guidelines and pre-defined configurations for use with Informatica’s Intelligent Data Management Cloud (IDMC) platform and leading cloud data platforms. Professional services firms such as Deloitte and Capgemini, are building their GenAI platforms on top of Informatica blueprints.
The blueprints are available at no cost in Informatica’s Architecture Center. Recipes for AWS, Google Cloud, Microsoft Azure and Oracle are available now, with Snowflake and Databricks recipes due next year.
…
Marvell demonstrated PCIe 7 connectivity, using its PAM4 technology, at the OCP Global Summit, October 15–17, at the San Jose Convention Center. It says PCIe 7, operating at 128 GT/sec, will enable larger volumes of data to be across the bus to reduce AI training and inference time, cost and energy usage. The Marvell PCIe 7 SerDes is designed using 3nm fabrication technology enabling lower power consumption.
…
Pete Hannah.
Veeam backup object appliance target company Object First has promoted Pete Hannah to vice president of sales, Western Europe. He will focus on channel development, recruitment of partners, and hiring to grow the sales team. Object First achieved a 300 percent year-over-year increase in transacting partners in Q2 2024.
…
Trino lakehouse supplier Starburst announced 100GB/sec streaming ingest from Apache Kafka to Apache Iceberg tables at half the cost of alternative solutions. Configuration is completed in minutes and simply entails selecting the Kafka topic, the auto-generated table schema, and the location of the resulting Iceberg table.
Starburst Galaxy’s streaming ingestion is serverless, automatically ingests incoming messages from Kafka topics into managed Iceberg tables in S3, compacts and transforms the data, applies the necessary governance, and makes it available to query within about one minute. Starburst’s streaming ingestion can connect to Kafka-compliant systems, which includes Confluent Cloud, Amazon Managed Streaming for Apache Kafka (MSK), and Apache Kafka.
Starburst guarantees exactly once delivery, ensuring no duplicate messages are read, and no messages are missed to ensure accuracy. It is built for a massive scale.
Supermicro launched an optimized storage system for high performance AI training, inference and HPC workloads. This JBOF (Just a Bunch of Flash) system utilizes up to four Nvidia BlueField-3 data processing units (DPUs) in a 2U form factor to run software-defined storage workloads. Each BlueField-3 DPUs features 400Gb Ethernet or InfiniBand networking and hardware acceleration for high computation storage and networking workloads such as encryption, compression and erasure coding, as well as AI storage expansion. The state-of-the-art, dual port JBOF architecture enables active-active clustering ensuring high availability for scale up mission-critical storage applications as well as scale-out storage such as object storage and parallel file systems.
The Supermicro JBOF with Nvidia BlueField-3 solution replaces the traditional storage CPU and memory subsystem with the BlueField-3 DPU and runs the storage application on the DPU’s 16 Arm cores. In addition to storage acceleration such as erasure coding and decompression algorithms, the BlueField-3 also accelerates networking through hardware support for RoCE (RDMA over Converged Ethernet), GPU Direct Storage and GPU Initiated Storage. More information on the Supermicro’s storage solutions for AI can be found here.
…
Shawn Kinnear.
Lisbon-based distributed storage supplier Vawlt named Shawn Kinnear as its chief sales officer. He comes from being VP worldwide sales at Avesha and will be based in the US. Kinnear has roles at Diamanti (VP worldwide sales) and Micron (senior director enterprise sales North America) in his CV.
…
Virtualized datacenter supplier VergeIO announced ioOptimize, an integrated VergeOS service featuring machine learning (ML) and narrow artificial intelligence (AI). It enables servers to provide dependable service long beyond their expected lifespan by employing VergeOS to support multiple generations of CPUs, various storage media, and diverse network hardware simultaneously. Customers can utilize VergeOS without being tied to specific hardware, mixing new and older nodes from different vendors. By automatically migrating virtual machines (VMs) from aging or failed servers to more capable nodes, ioOptimize ensures smooth, uninterrupted operation. With the release of VergeOS 4.13, ioOptimize introduces an “automated scale-down” feature. As VergeIO’s unique licensing is per server rather than per CPU or core, this feature enables customers to reduce server count while increasing capacity.
…
SQL supplier Yellowbrick Data announced an expanded collaboration with data management and analytics vendor Coginiti. The combined offering enables organizations to transform raw data to create structured, queryable formats, providing insights to drive analytics, business intelligence and AI workloads in hybrid and multi-cloud environments. “Yellowbrick’s powerful data platform running real-time analytics and fraud use cases enables secure and efficient access to data on-premises and in the cloud. With Coginiti’s collaborative data tools, we’ve built a unique environment that simplifies and boosts data workflows,” said Allen Holmes, vice president of marketing and global alliances at Yellowbrick. “Our combined data operations platform not only scales with customers’ needs but provides them with streamlined workflows and actionable insights.” The software is available now.
Organizations are increasingly adopting Gen AI in business functions, according to research – with its use in operations, purchasing and procurement doubling since 2023.
This is shown by the “Growing Up: Navigating Gen AI’s Early Years” study by The Wharton School of the University of Pennsylvania, which surveyed more than 800 enterprise decision-makers across the US.
Stefano Puntoni.
Stefano Puntoni, Sebastian S Kresge Professor of Marketing and Co-Director of AI at the Wharton School, said in a statement: “Generative AI has rapidly evolved from a tool of experimentation to a core driver of business transformation.”
“Companies are no longer just exploring AI’s potential – they are embedding it into their strategies to scale growth, streamline operations, and enhance decision-making. The novelty phase is over. We’re now starting to see the integration of AI into various business processes, as companies look to unlock its long term value across the enterprise.”
The study, which was carried out in collaboration with GBK Collective, found that:
Nearly 3 in 4 Leaders (72 percent) report using Gen AI at least once a week, up from 37 percent in 2023.
AI adoption in Marketing and Sales tripled, from 20 percent in 2023 to 62 percent in 2024, with AI usage in Operations, HR, Purchasing, and Procurement doubling.
Spending on AI has increased by 130 percent, with 72 percent of companies planning further investment in 2025.
90 percent of leaders agree that AI enhances employee skills, up from 80 percent in 2023, while concerns about job replacement have eased, dropping from 75 percent to 72 percent.
The surveyed businesses are now actively using Gen AI across multiple functions, such as coding, data analysis, idea generation, brainstorming, content creation, and legal contract generation. Nearly half of organizations are hiring Chief AI Officers (CAIOs) to lead strategic initiatives. Such CAIOs are now in 46 percent of companies. Challenges around accuracy, privacy, team integration, and ethics persist, though these concerns have slightly eased compared to last year.
Extract from report PDF.
90 percent of leaders in 2024 agreed that AI enhances employee skills, up from 80 percent in 2023. Concerns about AI replacing human skills have slightly decreased.
A banking leader told the study surveyors: “The biggest impact of Gen AI will be to augment my capabilities. [It will] automate routine tasks and provide 24/7 support to our customers, freeing me up to focus on [customer] empathy and more complex problem-solving.”
Puntoni said: “There’s a clear shift in mindset. Leaders are increasingly viewing AI as a tool to augment employee capabilities rather than replace them, with a focus on enhancing productivity and improving work quality.” The small percentage changes here, even though 10 percent is statistically significant, may not actually be viewed as “a clear shift in mindset” by some folks though.
Extract from report
Mary Purk, executive director, AI at Wharton, said: “Businesses must refine their AI strategies, not only to integrate AI across functions but also to demonstrate its value. The real competitive edge will come from those who can scale AI effectively and confidently.”
Puntoni talked of a “pivotal moment,” saying: “Companies are now leveraging AI for tangible business outcomes, but they’re also facing new challenges in governance and integration as they scale AI solutions across the enterprise.”
GBK Collective partner Jeremy Korst said: “Governance, security, ethics, and training around new LLM (Large Language Model) applications and use cases are critical. We’re only now at the start of this journey and the companies that get this right will lead the next wave of AI innovation and transformation.”
What this Wharton study predicts for IT compute, storage and networking infrastructure suppliers is that the Gen AI market for their products, particularly the inference market, is becoming stronger and will be sustained. The study found that Gen AI budgets will rise across all functional areas over the next 2 to 5 years.
As we understand it, the key need, will be an ability to show tangible value from products used in Gen AI applications, such as x percent lower cost in Gen AI-assisted purchasing compared to traditional purchasing.
Today, Gen AI receives the highest performance scores for data analysis/analytics, idea generation/brainstorming, legal contract generation, fraud detection and email generation. The study reckons that it’s in these areas where Gen AI product proliferation will most likely occur.
The study says the predicted leading AI vendors in three to five years from now will be Microsoft/Azure and Google GCP in equal first place (47 percent), with AWS third (33 percent), followed by Open AI, Apple, IBM and Meta.