


The MLPerf Storage benchmark combines three workloads and two types of GPU to present a six-way view of storage systems’ ability to keep GPUs busy with machine learning work.
This benchmark is a production of MLCommons – a non-profit AI engineering consortium of more than 125 collaborating vendors and organizations. It produces seven MLPerf benchmarks, one of which is focused on storage and “measures how fast storage systems can supply training data when a model is being trained.”
MLCommons states: “High-performance AI training now requires storage systems that are both large-scale and high-speed, lest access to stored data becomes the bottleneck in the entire system. With the v1.0 release of MLPerf Storage benchmark results, it is clear that storage system providers are innovating to meet that challenge.”
Oana Balmau, MLPerf Storage working group co-chair, stated: “The MLPerf Storage v1.0 results demonstrate a renewal in storage technology design. At the moment, there doesn’t appear to be a consensus ‘best of breed’ technical architecture for storage in ML systems: the submissions we received for the v1.0 benchmark took a wide range of unique and creative approaches to providing high-speed, high-scale storage.”
The MLPerf Storage v1.0 Benchmark results provide, in theory, a way of comparing different vendors’ ability to feed machine learning data to GPUs and keep them over 90 percent busy.
However, the results are presented in a single spreadsheet file with two table sets. This makes comparisons between vendors – and also between different results within a vendor’s test group – quite difficult. To begin with, there are three separately tested workloads – 3D Unet, Cosmoflow, and ResNet50 – each with MiB/sec scores, meaning that effectively there are three benchmarks, not one.
The 3D UNet test looks at medical image segmentation using “synthetically generated populations of files where the distribution of the size of the files matches the distribution in the real dataset.” Cosmoflow is a scientific AI dataset using synthetic cosmology data, while ResNet50 is an image classification workload using synthetic data from ImageNet. All three workloads are intended to “maximize MBit/sec and number of accelerators with >90 percent accelerator utilization.”
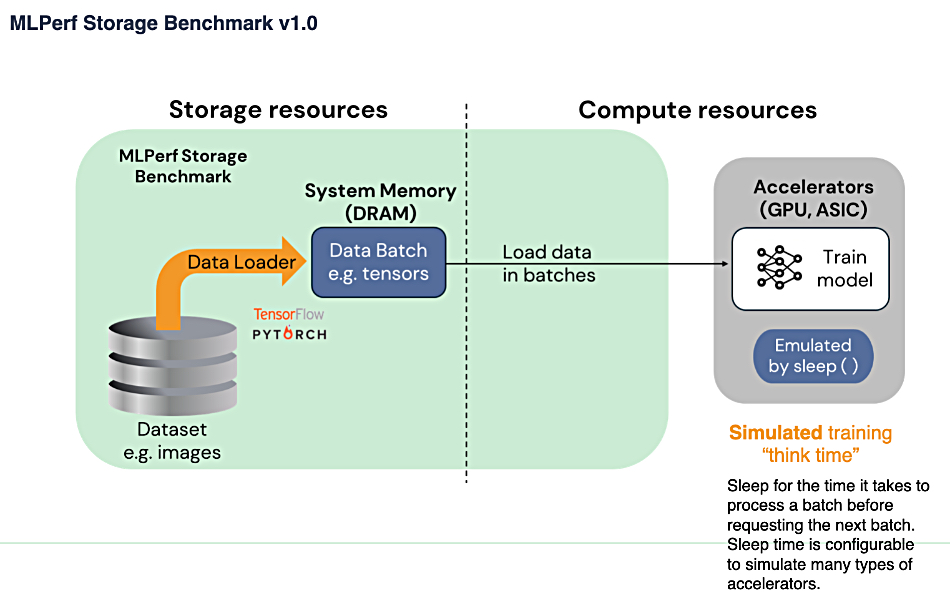
These three workloads offer a variety of sample sizes, ranging from hundreds of megabytes to hundreds of kilobytes, as well as wide-ranging simulated “think times” – from a few milliseconds to a few hundred milliseconds. They can be run with emulated Nvidia A100 or H100 accelerators (GPUs), meaning there are actually six separate benchmarks.
We asked MLPerf about this and a spokesperson explained: “For a given workload, an emulated accelerator will place a specific demand on the storage that is a complex, non-linear function of the computational and memory characteristics of the accelerator. In the case here, an emulated H100 will place a greater demand on the storage than an emulated A100.”
There are two types of benchmark run division: Closed, which enables cross-vendor and cross system comparisons; and Open, which allows for interesting results intended to foster innovation. Open allows more flexibility to tune and change both the benchmark and the storage system configuration to show off new approaches or new features that will benefit the AI/ML community. But Open explicitly forfeits comparability to allow showcasing innovation. Some people might think having two divisions is distracting rather than helpful.
Overall there are seven individual benchmarks within the MLPerf Storage benchmark category, all present in a complicated spreadsheet that is quite hard to interpret. There are 13 submitting organizations: DDN, Hammerspace, HPE, Huawei, IEIT SYSTEMS, Juicedata, Lightbits Labs, MangoBoost, Nutanix, Simplyblock, Volumez, WEKA, and YanRong Tech, with over 100 results across the three workloads.
David Kanter, head of MLPerf at MLCommons, said: “We’re excited to see so many storage providers, both large and small, participate in the first-of-its-kind v1.0 Storage benchmark. It shows both that the industry is recognizing the need to keep innovating in storage technologies to keep pace with the rest of the AI technology stack, and also that the ability to measure the performance of those technologies is critical to the successful deployment of ML training systems.”
We note that Dell, IBM, NetApp, Pure Storage and VAST Data – all of whom have variously been certified by Nvidia for BasePOD or SuperPOD use – are not included in this list. Both Dell and IBM are MLCommons members. Benchmark run submissions from all these companies would be most interesting to see.
Hammerspace noted: “It is notable that no scale-out NAS vendor submitted results as part of the MLPerf Storage Benchmark. Well-known NAS vendors like Dell, NetApp, Qumulo, and VAST Data are absent. Why wouldn’t these companies submit results? Most likely it is because there are too many performance bottlenecks in the I/O paths of scale-out NAS architectures to perform well in these benchmarks.”
Comparing vendors
In order to compare storage vendors on the benchmarks, we need to separate out their individual MLPerf v1.0 benchmark workload type results using the same GPU on the closed run type – such as 3D Unet-H100-Closed. When we did this for each of the three workloads and two GPU types, we get wildly different results, even within a single vendor’s scores, making us concerned that we are not really comparing like with like.
For example, we separated out and charted a 3D Unet-H100-Closed result set to get this graph:

Huawei scores 695,480 MiB/sec while Juicedata scores 5,536 MiB/sec, HPE 5,549 MiB/sec, and Hammerspace 5,789 MiB/sec. Clearly, we need to somehow separate the Huawei and similar results from the others, or else normalize them in some way.
Huawei’s system is feeding data to 255 H100 GPUs while the other three are working with just two H100s – obviously a completely different scenario. The Huawei system has 51 host compute nodes and the other three have none specified (Juicedata) and one apiece for HPE and Hammerspace.
We asked MLPerf if we should normalize for host nodes in order to compare vendors such as Huawei, Juicedata, HPE, and Hammerspace. The spokesperson told us: “The number of host nodes is not particularly useful for normalization – our apologies for the confusion. The scale of a given submission is indicated by the number and type of emulated accelerators – ie ten emulated H100s is 10x the work of one emulated H100 from a storage standpoint. While MLCommons does not endorse a particular normalization scheme, normalizing by accelerators may be useful to the broader community.”
We did that, dividing the overall MiB/sec number by the number of GPU accelerators, and produced this chart:
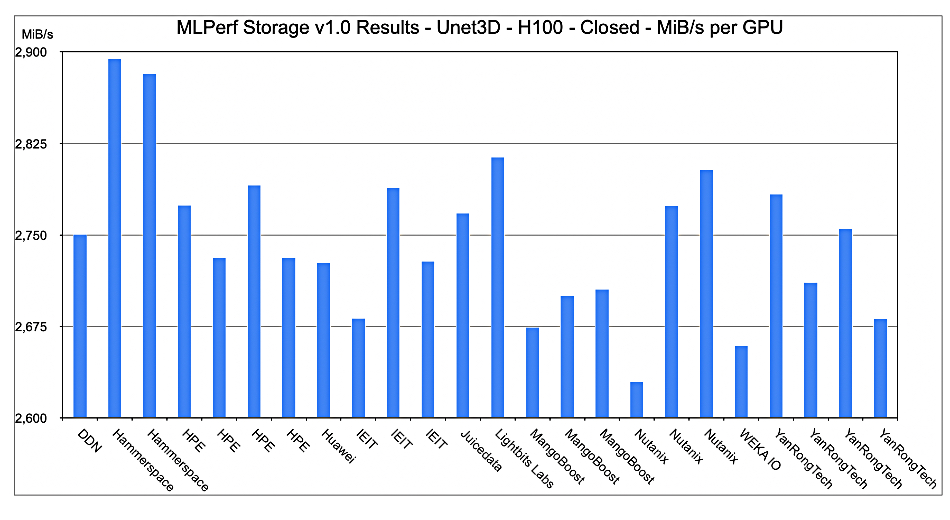
We immediately see that Hammerspace is most performant – 2,895 MiB/sec (six storage servers) and 2,883 MiB/sec (22 storage servers) – on this MiB/sec per GPU rating in the 3D Unet workload closed division with H100 GPUs. Lightbits Labs is next with 2,814 MiB/sec, with Nutanix next at 2,774 MiB/sec (four nodes) and 2,803 MiB/sec (seven nodes). Nutanix also scores the lowest result – 2,630 MiB/sec (32 nodes) – suggesting its effectiveness decreases as the node count increases.
Hammerspace claimed it was the only vendor to achieve HPC-level performance using standard enterprise storage networking and interfaces. [Download Hammerspace’s MLPerf benchmark test spec here.]
Huawei’s total capacity is given as 457,764TB (362,723TB usable) with Juicedata having unlimited capacity (unlimited usable!), HPE 171,549.62TB (112,596.9TB usable), and Hammerspace 38,654TB (37,339TB usable). There seems to be no valid relationship between total or usable capacity and the benchmark score.
We asked MLPerf about this and were told: “The relationship between total or usable capacity and the benchmark score is somewhat submission-specific. Some submitters may have ways to independently scale capacity and the storage throughput, while others may not.”
Volumez
The Volumez Open division test used the 3D Unet workload with 411 x H100 GPUs, scoring 1,079,091 MiB/sec; the highest score of all on this 3D Unet H100 benchmark, beating Huawei’s 695,480 MiB/sec.
John Blumenthal, Volumez chief product officer, told us: “Our Open submission is essentially identical to the Closed submission, with two key differences. First, instead of using compressed NPZ files, we used NPY files. This approach reduces the use of the host memory bus, allowing us to run more GPUs per host, which helps lower costs. Second, the data loaded bypasses the Linux page cache, as it wasn’t designed for high-bandwidth storage workloads.”
Volumez submitted a second result, scoring 1,140,744 MiB/sec, with Blumenthal explaining: “In the second submission, we modified the use of barriers in the benchmark. We wanted to show that performing a barrier at the end of each epoch during large-scale training can prevent accurate measurement of storage system performance in such environments.”
YanRong Tech
YanRong Tech is a new vendor to us. A spokesperson, Qianru Yang, told us: “YanRong Tech is a China-based company focused on high-performance distributed file storage. Currently, we serve many leading AI model customers in China. Looking globally, we hope to connect with international peers and promote the advancement of high-performance storage technologies.”
We understand that the firm’s YRCloudFile is a high-performance, datacenter-level, distributed shared file system product built for software-defined environments, providing customers with a fast, highly scalable and resilient file system for their AI and high-performance workloads.





