


DapuStor has accelerated Gen AI model training with data on its PCIe gen 4 and 5 SSDs accessed and moved to GPU memory faster than GPUDirect by using Nvidia’s BaM framework.

Shenzhen-based DapuStor supplies SSDs such as its PCIe gen 4 R5101 and PCIe gen 5 Haishen H5100. It claims it has in excess of 500 customers and was China’s 4th largest enterprise SSD supplier in 2023. GPUDirect is a latency-reducing way for GPU servers to read and write data from a storage system’s NVMe-connected SSDs to/from GPU memory without having the storage system’s CPU and DRAM involved. BaM (Block-accessed Memory) goes beyond this by optimizing storage drive block data arrival and placement in GPU memory to keep GPU threads busier than GPUDirect.
Dapustor Solutions Architect Grant Li stated: “As AI models scale rapidly, ensuring efficient utilisation of GPU resources has become a critical challenge. With the BaM framework and DapuStor’s high-performance NVMe SSDs, AI model training times can be drastically reduced, leading to cost savings and more efficient use of infrastructure.”
He reckons: “DapuStor’s R5101 and H5100 SSDs demonstrate the potential for tens of times faster model training.”
The company said Graph Neural Network (GNN) training was evaluated using heterogeneous large datasets. A test system processed 1100 iterations, with DapuStor’s R5101 and H5100 SSDs showing a “remarkable 25X” performance increase over traditional methods, significantly reducing end-to-end execution time.
The training’s feature aggregation phase saw “substantial improvements” with BaM. The end-to-end execution time dropped from 250s to less than 10s, and BaM reduced the time spent on feature aggregation from 99 percent in baseline tests to 77 percent. Adding additional SSDs further enhanced the system’s ability to handle data in parallel, reducing feature aggregation times by an additional 40 percent.
What is BaM
BaM was developed by a collaboration of industry engineers and academic researchers at NVIDIA, IBM, the University of Illinois Urbana-Champaign, and the University at Buffalo. The approach maximizes the parallelism of GPU threads and uses a user-space NVMe driver, helping to ensure that data is delivered to GPUs on demand with minimal latency.
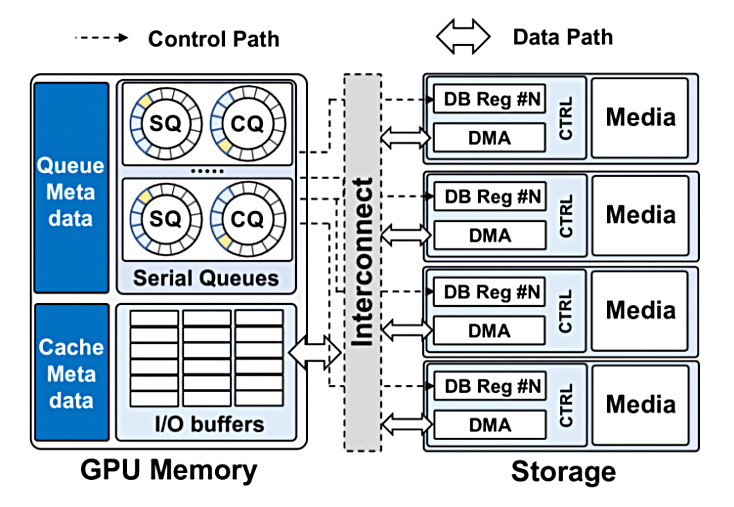
A research paper, GPU-Initiated On-Demand High-Throughput Storage Access in the BaM System Architecture, says BaM stands for Big accelerator Memory, and it “features a fine-grained software cache to coalesce data storage requests while minimizing I/O amplification effects. This software cache communicates with the storage system through high-throughput queues that enable the massive number of concurrent threads in modern GPUs to generate I/O requests at a high-enough rate to fully utilize the storage devices, and the system interconnect.”
It goes on to say: ”The GPUDirect Async family of technologies accelerate the control path when moving data directly into GPU memory from memory or storage. Each transaction involves initiation, where structures like work queues are created and entries within those structures are readied, and triggering, where transmissions are signaled to begin. To our knowledge, BaM is the first accelerator-centric approach where GPUs can create on-demand accesses to data where it is stored, be it memory or storage, without relying on the CPU to initiate or trigger the accesses. Thus, BaM marks the beginning of a new variant of this family that is GPU kernel initiated (KI): GPUDirect Async KI Storage.”
And: “The goal of BaM’s design is to provide high-level abstractions for accelerators to make on-demand, fine-grained, high-throughput access to storage while enhancing the storage access performance. To this end, BaM provisions storage I/O queues and buffers in the GPU memory.”
There is a BaM software cache in the GPU’s memory. The research paper discusses GPU thread data access to it, and says: “If an access hits in the cache, the thread can directly access the data in GPU memory. If the access misses, the thread needs to fetch data from the backing memory [NVMe SSDs]. The BaM software cache is designed to optimize the bandwidth utilization to the backing memory in two ways: (1) by eliminating redundant requests to the backing memory and (2) by allowing users to configure the cache for their application’s needs.”
To fetch data from the NVMe SSDs: “The GPU thread enters the BaM I/O stack to prepare a storage I/O request , enqueues it to a submission queue , and then waits for the storage controller to post the corresponding completion entry. The BaM I/O stack aims to amortize the software overhead associated with the storage submission/completion protocol by leveraging the GPU’s immense thread-level parallelism, and enabling low-latency batching of multiple submission/completion (SQ/CQ) queue entries to minimize the cost of expensive doorbell register updates and reducing the size of critical sections in the storage protocol.”
A doorbell register is a signaling method to alert a storage drive that new work is ready to be processed.
It says BaM is implemented completely in open source, and both hardware and software requirements are publicly accessible.

As we understand it, and compared to GPUDirect, BaM streamlines data access paths and reduces the need for high queue depths to provide better memory throughput and utilization, particularly for large-scale models or datasets. It enables GPU threads to directly access storage enabling compute and I/O overlap at fine-grain granularity. Memory access overhead is reduced and data is loaded in larger, more manageable blocks, so improving GPU utilization efficiency.
The research paper authors conclude: “As BaM supports the storage access control plane functionalities including caching, translation, and protocol queues on the GPU, it avoids the costly CPU-GPU synchronization, OS kernel crossing, and software bottlenecks that have limited the achievable storage access throughput.”
Comment
We can expect the GPUDirect-supporting storage system suppliers to rapidly enhance their NVIDIA GPU-server credentials by supporting BaM as well, and producing BaM performance stats. We can also expect other GPU suppliers, such as AMD and Intel to develop BaM-like protocols so as not to get left behind in the AI model training stakes.
Check out the BaM research paper here.





