


MinIO has devized an exascale DataPOD reference architecture for storing data needed by GPUs doing AI work.
The open source object storage software supplier is positioning its scalable 100PiB (112.6PB) unit as an object alternative to parallel file storage systems using GPUDirect to feed data fast to Nvidia’s hungry GPUs – with a nod to Nvidia’s SuperPOD concept. MinIO says it covers all stages of the AI data pipeline: data collection and ingestion, pre-processing, vectorization, model training and checkpointing, model evaluation and testing, and model deployment and monitoring.
It says: “Networking infrastructure has standardized on 100 gigabits per second (Gbit/sec) bandwidth links for AI workload deployments. Modern day NVMe drives provide 7GBit/sec throughput on average, making the network bandwidth between the storage servers and the GPU compute servers the bottleneck for AI pipeline execution performance.’
That’s why GPUDirect was invented by Nvidia.
MiniO says don’t bother with complex InfiniBand: “We recommend that enterprises leverage existing, industry-standard Ethernet-based solutions (eg HTTP over TCP) that work out of the box to deliver data at high throughput for GPUs.” These have: “High interconnect speeds (800GbE and beyond) with RDMA over Ethernet support (ie RoCEv2).”
According to MinIO: “Object stores excel at handling various data formats and large volumes of unstructured data and can effortlessly scale to accommodate growing data without compromising performance.” Also MinIO’s viewpoint is that its object storage can easily scale to the exabyte levels that could be needed for AI pipeline storage and that it can perform fast enough. One aspect of this is that MinIO has: “Distributed in-memory caching that is ideal for AI model checkpointing use cases.” However, no performance numbers are supplied.
A separate “High-Performance Object Storage for AI Data Infrastructure” white paper states: “MinIO’s performance characteristics mean that you can run multiple Apache Spark, Presto/Trino and Apache Hive queries, or quickly test, train and deploy AI algorithms, without suffering a storage bottleneck.”
It claims: “During model training, MinIO’s distributed setup allows for parallel data access and I/O operations, reducing latency and accelerating training times. For model serving, MinIO’s high-throughput data access ensures swift retrieval and deployment of AI models, and enables predictions with minimal latency. More importantly MinIO’s performance scales linearly from 100s of TBs to 100s of PBs and beyond.”
It quotes performance benchmarks with a distributed MinIO setup delivering 46.54G/sec average read throughput (GET) and 34.4GB/sec write throughput (PUT) with an 8-node cluster. A 32-node cluster delivered 349GB/sec read and 177.6GB/sec write throughput.
MinIO says it has customer deployments of 300 servers that are reading at 2.75TB/sec. We can take it as read that a MinIO setup can attain overall GPUDirect-like speeds but there are no comparisons we can find between such a MinIO system and a GPUDirect-supporting parallel file system delivering the same overall bandwidth. We can’t therefore directly compare the number and cost of the server, storage and network components in a MinIO and, for example, VAST Data system, with each providing 349GB/sec read and 177.6GB/sec write throughput.
DataPOD repeatable units
The DataPOD white paper says: “Enterprise customers using MinIO for AI initiatives build exabyte scale data infrastructure as repeatable units of 100PiB.” These consists of 30 racks, each containing 11x 2RU storage servers, 2 Layer 2 top-of-rack leaf switches, a management switch, and with 10x 64-port network spine switches.
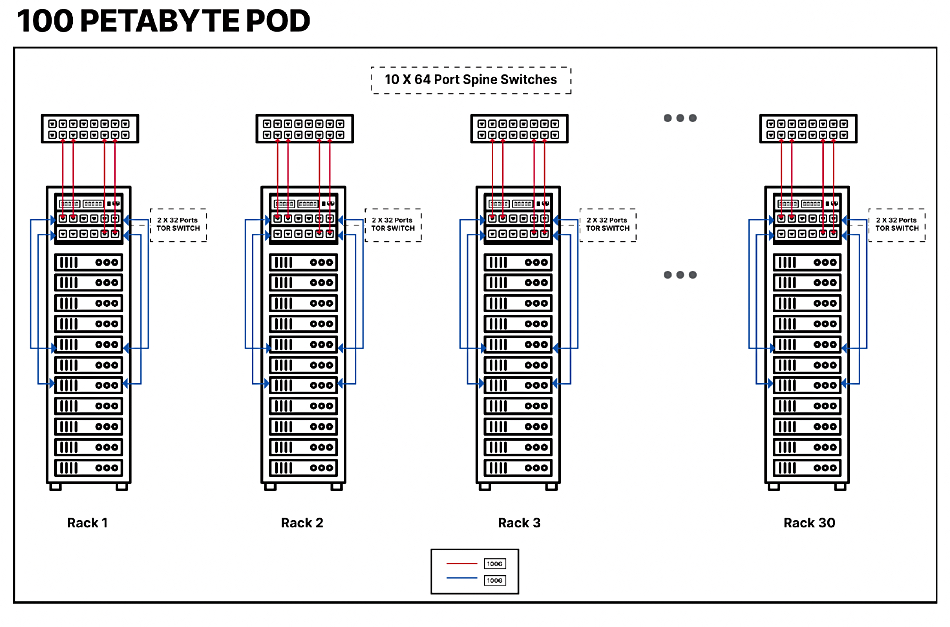
The storage server is a 2RU, single socket 64-core CPU-powered system with 128 PCIe 4 lanes, 256GB of memory, dual-port, 200GbE NIC, 24x U.2 drive bays, each holding a 30TB NVMe SSD, making a total of 720TB raw capacity. The reference architecture doc identifies Supermicro A+ 2114SWN24RT, a Dell PowerEdge R761 rack server and HPE ProLiant DL345 Gen 11 as valid servers.
It reckons such a setup would cost $1.5 per TB/month for the hardware and $3.54 per TB/month for the MiniIO software – $1,500/month for the hardware, $3,540/month for the software and $5,040/month all-in.
MinIO asserts that “Vendor-specific turnkey hardware appliances for AI will result in high TCO and is not scalable from a unit economics standpoint for large data AI initiatives at exabyte scale.”
It argues “AI data infrastructure in public clouds are all built on top of object stores. This is a function of the fact that the public cloud providers did not want to carry forward the chattiness and complexity associated with POSIX. The same architecture should be no different when it comes to private/hybrid cloud deployments.”
MinIO goes on to assert: “As high-speed GPUs evolve and network bandwidth standardizes on 200/400/800Gbit/sec and beyond, purpose-built object storage will be the only solution that would meet the performance SLAs and scale of AI workloads.”
DDN (Lustre), IBM (StorageScale), NetApp, PEAK:AIO, Pure Storage, Weka, and VAST Data – the GPUDirect-supporting parallel filestore suppliers – will all disagree with that point.





