


Fast filer software shipper WEKA has designed two versions of its WEKApod storage appliance for AI training and inference.
The WEKApod appliance is a storage server appliance able to store and push data out to GPU servers such as Nvidia’s SuperPOD. Each appliance consists of pre-configured hardware + WEKA Data Platform SW storage nodes built for simplified and faster deployment. A 1 PB WEKApod configuration starts with eight storage nodes and can scale out to hundreds.

WEKApod Nitro configurations use the PCIe gen 5 bus and are slated for large scale enterprise AI deployments. WEKApod Prime configurations use the slower PCIe gen 4 bus and are for smaller scale AI deployments.
Nilesh Patel, WEKA’s chief product officer, claimed in a statement: “Accelerated adoption of generative AI applications and multi-modal retrieval-augmented generation has permeated the enterprise faster than anyone could have predicted, driving the need for affordable, highly-performant and flexible data infrastructure [systems] that deliver extremely low latency, drastically reduce the cost per tokens generated and can scale … WEKApod Nitro and WEKApod Prime offer unparalleled flexibility and choice while delivering exceptional performance, energy efficiency, and value.”
WEKA says its Data Platform software delivers scalable AI-native data infrastructure purpose-built for the most demanding AI workloads, accelerating GPU utilization and retrieval-augmented generation (RAG) data pipelines efficiently and sustainably and providing efficient write performance for AI model checkpointing.
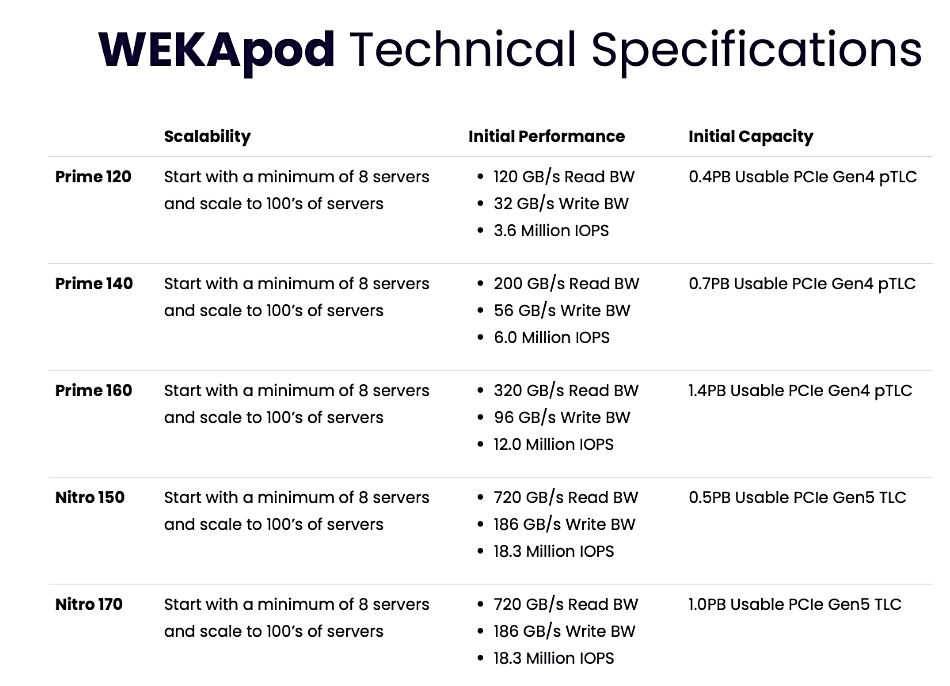
WEKApod Nitro scales to deliver more than 18 million IOPS in a cluster and is SuperPOD-certified. WEKApod Prime can scale up to 320 GBps read bandwidth, 96 GBps write bandwidth, and up to 12 million IOPS for customers with less extreme performance data processing requirements.
Find out more about WEKApod appliances here.





