On-prem VMware users with external block storage can face problems moving to the Azure cloud, and Pure Storage is hoping to attract customers who have those issues with its AVS (Azure VMware Solution) product.
The problems faced by orgs center on providing the same on-prem external block storage facilities in the Azure cloud that a customer has on-premises. For example they may be using vSphere Storage APIs for Array Integration (VAAI) and vSphere Virtual Volumes (vVols) in their VMware environment and support for them is lacking in Azure, according to Pure. They may also find it difficult to separate compute and storage instances in Azure for their vSphere environment and pay for for storage or compute by using combined instances. Pure can fix these refactoring issues with its AVS fully managed block Storage-as-a-Service (STaaS).
Shawn Hansen
Pure’s Shawn Hansen, GM for its Core Platform, stated: ”Enterprises have struggled for years with the inefficiencies and high costs tied to migrating VMware workloads to the cloud. [AVS] eliminates these obstacles by providing seamless, scalable storage as-a-service that scales efficiently and independently with business needs.”
Scott Hunter, VP Microsoft Developer Division, said: “Through this collaboration, Pure and Microsoft can better serve customer needs by enabling them to provision, use and manage Pure Storage on Azure just like other Azure services.”
AVS decouples Pure’s block storage, Azure Cloud Block Store, and compute in the Azure Cloud. It provides an external storage option for organizations needing to migrate storage volumes and VMs to Azure, providing the same on-prem block storage experience for VMs running in the Azure cloud. VAAI and vVols are supported.
AVS optimizes Azure storage instances, with Pure claiming customers can save up to 40 percent on their Azure VMware Solution costs when using it. It says data protection is built in with Pure’s SafeMode Snapshots, enabling systems to be back up-and-running in minutes when data is needing to be restored.
Because the storage environment, as seen from VMware, is the same on-premises and in Azure, a single hybrid data plane is in operation. Pure says, IT teams can centrally manage their storage and monitor usage without having two separate silos to look after.
AVS, a development of Pure’s Azure Native Integrations service, is being announced before it enters its preview development stage, which it will soon, says Pure.
The Lightbits cloud virtual SAN software has been ported to Oracle Cloud Infrastructure (OCI), where it delivers fast, low-latency block storage.
Lightbits block storage software has, until now, run in the AWS and Azure clouds, using ephemeral storage instances for faster than standard cloud block storage that also cost less. It creates a linearly scalable virtual SAN by clustering virtual machines via NVMe over TCP, and can deliver up to 1 million IOPS per volume with consistent latency down to 190 microseconds.
Lightbits, with certification on OCI, claims it enables organizations to run their most demanding, latency-sensitive workloads with sub-millisecond tail latencies, perfect for AI/ML, latency-sensitive databases, and real-time analytics workloads.
Kam Eshgi
Kam Eshghi, co-founder and chief strategy officer of Lightbits, stated: “Certification on OCI marks a major step forward for Lightbits. We’re delivering a breakthrough in block storage performance, giving organizations the tools they need to migrate their most demanding applications to OCI and achieve faster, more reliable, and more efficient cloud services.”
OCI FIO benchmark runs, conducted with BM.DenseIO.E5.128 bare-metal OCI Compute shapes, supported by two BM.Standard.E5.192 shapes as clients, running Lightbits software on Oracle Linux 9.4, revealed:
3 million 4K random read IOPS and 830K 4K random write IOPS per client with a replication factor of three, saturating the 100GbE network card configuration on BM.Standard.E5.192 servers.
Sub-300 microsecond latencies for both 4K random read and write operations, and 1ms latency when fully utilizing the clients for both random reads and writes – delivering fast performance even under heavy loads.
In a mixed workload scenario (70 percent random reads, 30 percent random writes), each client achieved a combined 1.8 million IOPS, “setting a new benchmark for efficiency at scale.”
The Lightbits software on OCI can scale dynamically without downtime and has “seamless integration” with Kubernetes, OpenStack, and VMware environments. There is built-in high resiliency and availability, with snapshots, clones, and distributed management to prevent single points of failure.
Cameron Bahar
Cameron Bahar, OCI SVP for Storage and Data Management, said: “Our collaboration with Lightbits and its certification on OCI delivers a modern approach to cloud storage with the performance and efficiency that enables our customers to bring their latency demanding enterprise workloads to OCI.”
Coincidentally, Lightbits competitor Volumez is also available in OCI, having been present in the Oracle Cloud Marketplace since September, claiming it provides 2.83 million IOPS, 135 microseconds ultra-low latency, and 16 GBps throughput per volume. It says users can harness Volumez’s SaaS services to create direct Linux-based data paths using a simple interface for Oracle Cloud Infrastructure (OCI) Compute VMs.
Find out more about Lightbits on OCI here and about OCI itself here.
Seagate is developing an SSD that can operate in the vacuum of space aboard low Earth orbit satellites, providing mass storage for satellite applications.
It is testing this concept by having its Seagate Federal unit ship an SSD up to the International Space Station (ISS) as part of a BAE Systems Space & Mission Systems payload. This environmental monitoring payload was ferried to the ISS by NASA, where astronauts installed it.
The payload included a processor and real-time Linux plus containerized applications, and Microsoft Azure Space was involved in this aspect of the mission. Microsoft is developing an Orbital Space SDK and views satellites as a remote sensing and satellite communications edge computing location. Naturally, such a system needs mass storage.
The mission is scheduled to last for one year. At that point, the payload will be uninstalled and returned to Earth. BAE Systems engineers and scientists will analyze it to assess its impact from the space environment. Seagate’s engineers will check the SSD and its telemetry to see how well it withstood the rigors of space.
Unlike the space environment outside the ISS, the interior has atmospheric pressure, temperature control, and insulation from solar radiation. The SSD must operate while withstanding stronger solar radiation, extreme cold, and the vacuum of space.
Last year, HPE servers equipped with Kioxia SSDs were used on the ISS as part of NASA and HPE’s Spaceborne Computer-2 (SBC-2) program. We asked if this BAE program is doing pretty much the same thing as far as the storage drive is concerned.
Seagate said: “The main difference here is that we are being used outside the ISS, rather than inside it. The interior of the ISS is scientifically engineered to be a pristine environment, as it needs to protect its human inhabitants. It has a lot of shielding and air conditioning, which actually makes it a more desirable location than most places on Earth. We’re working to design technology that can survive without these advantages and function under higher levels of radiation, where there is no monitored climate or temperature, and in the vacuum of space – outside, in low Earth orbit (LEO).”
Seagate told us this task was undertaken to determine if technology could enhance LEO data storage capabilities. If successful, it could aid in extending content delivery networks (CDNs) for new AI-powered workflows. Satellites already provide the last mile connection to areas without fiber and cell connectivity, and with storage as part of the equation, AI inferencing could then occur in more places.
The SSD’s design “was based around Seagate SSD technology … however, our design is a 3U-VPX form factor, completely different than typical SSDs.” The form factor comes from the avionics world and has a size of 100 x 160 mm. VPX is used to specify how computer components connect across a VME bus and has been defined by the VMEbus International Trade Association (VITA) working group.
A 4 TB SSD is being used. We’re told: “For most of the mission the drive is being used as a general-purpose storage device to store mission data. Seagate SSD drives support FIPS140-2 data encryption, but that was not used in this mission. In addition to general-purpose storage, we ran special stress tests on the drive during parts of the mission and collected telemetry. Those tests revealed that many SSDs are susceptible to certain levels of radiation, and many are corrupted at the same exposure level. So, we did a lot of ‘failure testing’ to reverse engineer ways to make them more resistant and robust. On top of radiation soft errors under stress, we were also interested in measuring temperature and current.”
We wondered what this could mean for consumers and enterprises in the future. A Seagate spokesperson said: ”We intend to make this storage device available for purchase to both commercial and military aerospace customers. Right now, the market consists of off-the-shelf drives as a low-cost option, which, as you would expect, have a handful of faults for these applications. However, the opposite end is expensive military-grade hardware. We’re aiming to bridge the gap between the two and make the technology more accessible to consumers and enterprises. We are also looking whether this sort of ruggedized solution might be useful for terrestrial applications.”
Profile. Qumulo brought in Doug Gourlay in July, appointing him as president and chief executive. Gourlay also joined Qumulo’s board of directors. The business has an on-premises scale-out file system and cloud-native product that can be used in the general file-focused unstructured primary data market.
Qumulo has more than 1,000 customers in 56 countries, with several adjacent and overlapping markets. Segments it serves include cloud file services; public cloud unstructured data; high-performance computing (HPC); file lifecycle management and orchestration; and GenAI training and inferencing, for example. Gourlay’s stated mission is to accelerate the business’s growth but says there is a constant tension as Qumulo and its leadership considers its markets. Which are worth adopting and which are niche – for now, the mid-term, or long term?
Gourlay tells Blocks & Files he has to consider things including the company’s product set, the core culture of the company, and market developments before he can steer Qumulo in the right direction.
Doug Gourlay
He says: “There was an obvious gap that the company did have, and that gap was it didn’t have a good story, it didn’t have a good talk track of where it was and where it was going. And a lot of our customer base wanted to know that the boat had a rudder and which way it was pointing.”
There are advantages in being a niche file-type product: “It’s not a niche product, it’s a enterprise-wide primary storage offering. And the downside of that is the niche offerings command significant price premiums because they do something in that niche that somebody thinks is valuable. Their go-to-market organization knows exactly what to call on, and they talk to this person, that person goes, wow, that’s amazing. That solves so much for me that I’m willing to pay you a metric ton of cash for.”
The more general-purpose products have lower prices. Should Qumulo move to these higher-priced niches? Gourlay says: “If I turned to just doing a specialty offering, we would lose the top-line revenue that the company depends on. If I just rotate it tomorrow to only do cloud, even though the unit economics are better, the margins are better, the deal velocity is better, I kill the company.”
Cloud and hybrid cloud
Blocks & Files sees Qumulo as a hybrid – on-premises and public cloud – company. Gourlay responds: ”Our customers are hybrid. And our cloud story is very simple. I can state in less than 30 seconds and probably one sentence: our job is to align our technologies with our customers’ priorities. Our job in cloud, therefore, is to give our customers the ability to make a business or economic decision about where their data and workloads reside and to eliminate all the technology barriers to that decision.”
He doesn’t buy into simple cloud repatriation stats, saying the situation is much more nuanced than we might think: “Michael Dell … posted to LinkedIn … four months or four weeks ago, which was 85 percent of the customers we polled are repatriating from the cloud. They’re going back on-prem.”
“OK, I have a book called How to Lie with Statistics. All right, if I tell you that data, it might be 100 percent accurate, but I’m not telling you how many workloads are moving. Somebody moving one workload? Check! You’re repatriating from the cloud.”
But it’s only a single workload, out of tens or hundreds. “There’s workloads that make sense in the cloud, and there’s workloads that don’t. Now, if I’m a cloud-only company, I’m going to tell you a completely different story. If the whole world is going cloud then, if you’re not going cloud, you’re a Luddite. If the answer isn’t cloud, the question is wrong. It’s cloud-first. It’s cloud-only.”
For now, Gourlay says: “Cloud, this quarter, is probably a fifth of our revenue contribution. It’s about 20 to 28 percent.”
It’s likely growing and the need for a hybrid data fabric with good on-prem-to-cloud data movement (and no doubt the other way) is too. He asks rhetorically: ”Can we invest in advanced technologies that allow rapid data replication between the cloud and the on-prem that accelerated and overcome some of the bandwidth delay product issues? So we’re testing those right now, with tremendous early results and further layering on capability that differentiates and maps these use cases.”
He sees similar one-dimensional – and wrong – thinking elsewhere: “If I’m Jensen (Huang), it’s all about the AI center, the datacenter is the AI center, the future is all GPUs and all our type of computing.”
This is half-blind thinking, he says: “These are wonderful stories from myopic points of view. Our customer base has a mosaic point of view, not a myopic one. And they want a system that works for their AI workloads, for their own workloads and their cloud workloads. And they want one that is consistent in operation and capability and capacity, regardless of which modality they’re executing against. That’s our job. That’s our job more than anything.”
He wants Qumulo and its people to have “organizational alignment around a common vision and strategy. A common technology evolution that addresses key priorities within our customers, whether those are AI, whether those are cloud adoption, whether those are a shift to different virtual machine types inside their datacenter, whether these are this ever expanding data set that our customers are getting weighed under.”
“Historically, they were deploying different file systems and different storage systems for each application. One of the great things about what we do is we can consolidate those. One of the great things about the way that we move the data inside of the system is we can start collapsing tiers very cost effectively.”
Having a global namespace (GNS) as an integral part of the product is a vital facility for Gourlay. He is not a believer in adding an external GNS, which is one way he views Hammerspace: “The unfortunate problem of an overlay GNS on third-party systems is no system has the verbs in place to give them an assurance that the data has been durably written to multiple targets before they acknowledge the data. And in that scenario, you end up with a tremendous risk of data loss, which our customers have experienced, multi petabyte data losses.”
“It’s funny that I looked throughout all of our marketing material, and that never came out to me. I see customers drawing up a four tier storage system. I’m like, but guys, I could put a lot of QLCs in here and a caching layer, and I could do hybrid over there. But if I just increase the cache sizes and the SSDs, [then] haven’t I really collapsed two or three of those tiers together, at a similar price point, with a larger storage cluster?”
Gourlay discusses a customer example: “I have a customer who does rocket launches. We store the telemetry for it. They may have had data loss because of organizations that didn’t have the ability to guarantee writes rights – so strict consistency matters when the data matters. Our customer base has data that matters.”
AI training and inference
What about AI where Qumulo, unlike NetApp, Pure Storage, and other competitors, does not support Nvidia’s GPUDirect protocol for feeding data to GPUs for AI work? He makes a distinction between AI model training, which does need GPUDirect, and AI model inference, which does not.
The Qumulo CEO thinks that AI training is a highly niche market. The 15th largest GPU cluster in the world has, he says, just 256 GPUs. “Numbers one through 14 are larger and number 16 onward are smaller. Why do I want to chase such a small market?”
He’s emphatic about this point: “Why do you want me to sit there and compete with four other companies, all chasing 14 companies that are spending enough to be worth calling them? Do you realize that the largest financial institution in the US has eight DGXs and doesn’t know what to do with them. Number one, the largest bank in America, has eight DGXs. Why should I bother with a tiny market?”
There are two successful storage suppliers to his knowledge, but hyperscaler customers are ruthless: “There’s two storage suppliers [that] are being pretty successful, right? One of them is getting kicked out of the largest cluster because they’re building their own. Now, that’s the other problem. These are hyperscalers. Yes, the largest AI cluster in the world is moving from an open storage environment, consuming a commercial product, to them building their own.”
This is a risky sales approach: “If I’m a company that has a 50 percent revenue concentration in one customer, that’s huge risk. I have 1,000 customers. I have over five exabytes to date under storage. I don’t have a single customer worth more than 2 percent revenue to me. I don’t have risk. They do. They have a customer concentration risk with customers who actively want them out of their system.”
”Hyperscalers either want to ram your margin down or get you out and replace you with something they can build themselves. I want customers who love me, who want to keep us in because they love what we do, and who aren’t capable of investing hundreds of engineers of effort in getting us out of their networks and systems.”
This is the situation now. It could change: “My statement wasn’t never. My statement was, I’m not going to chase it now.”
“I need to do this for a different reason. I need to do this because I have a substantial number of the largest ADAS (Automated Driver Assistance Systems) clusters in the world. I’m in seven of the eight largest autonomous driving clusters in the world, two largest research grant recipients in North America. We’re in the largest pediatric critical care facilities … we have customer demand now to start building it for things that are being delivered in the next two to four years, [the] cycle of our customers adopting next generation technologies. So it’s not a never, it’s at a right time.”
“I want to be right-timed. I want to hit a market inflection. I want to hit it when it scales out. To go for the broad customer adoption, for the base we have. I don’t want to build customer concentration risk in a market that wants to evict me. I want it with ones that embrace me. So I’m not saying never, definitely not saying never.”
If not never, when? “I think if you and I are sitting here next year having this conversation, I will happily have product to market that addresses some, if not all of what you and I are discussing.”
A last question from us: “NetApp is building a third ONTAP infrastructure to cope with supplying systems for AI, a disaggregated infrastructure. Dell is aiming to stick a parallel interface on top of PowerScale. Is Qumulo thinking about being able to respond already to these moves; developing something like a parallel architecture for itself?”
Gourlay exudes positivity about this: “I think if you take a look at the architecture that we’re using in our cloud-native offering, one that runs as a series of EC2 instances, backed with EBS and local NVMe, but then using parallel access to object storage in the back end, called S3 in the cloud. I think you see the exact architecture you’re describing in production today.”
****
A CEO like Gourlay can encapsulate key aspects of a company’s offerings and approach, then express them compellingly, not shying away from debate with opposing views, and winning doubters over with strongly argued and logical views. It’s a formidable talent and, when coupled with a clear view of a market and its realities, should enable a business to do very well indeed.
Qumulo is being re-energized and carving out its own messaging under Gourlay. Its competitors are going to face a tougher fight when meeting it in customer bids, and he’ll relish that.
Panzura has released version 8.4 of its CloudFS core technology, claiming the latest update increases access security and lowers cloud storage costs.
CloudFS, billed by Panzura as being built on the world’s fastest global file system, has a global namespace and distributed file locking supported by a global metadata store. It is the underlying technology used by Panzura Data Services, which provide cloud file services, analytics, and governance, and also support the new Symphony feature for on-premises, private, public, and hybrid cloud object storage workloads managed through a single pane of glass.
Sunar Kanthadai
Panzura CTO Sundar Kanthadai blogs that CloudFS v8.4 “introduces important enhancements for cloud and on-premises storage. CloudFS 8.4 makes it easier to get into the cloud, reduce total cost of ownership (TCO), and improve user command and control over the unstructured data.”
Kanthadai claims the software provides “finely tuned, granular Role-Based Access Control (RBAC). This allows for precise user permissions within the CloudFS WebUI, ensuring compliance with internal and external controls.” It integrates with Active Directory (Entra) with “tailored access for various roles and enables even more compliance options.“
Competitors CTERA and Nasuni have RBAC support and Panzura has now caught up with them in this regard.
CloudFS v8.4 supports more S3 tiers through S3 Intelligent Tiering and also Glacier Instant Retrieval:
Frequent access for freshly uploaded data,
Infrequent access for data with no accesses in 30 days,
Archive Instant Access for data with no accesses within 90 days,
Glacier Instant Retrieval with millisecond access, faster than Glacier Standard or Deep Archive with their retrieval times in minutes or hours
Kanthadai writes: “CloudFS caches frequently used data at the edge, enabling local-feeling performance and virtually eliminating the need to egress data from the cloud to support active file operations. As such, Glacier Instant Retrieval may be used with CloudFS to offer performant retrieval on the occasions it is required, while offering substantial overall storage savings” of up to 68 percent.
Panzura admins can now directly assign “objects to their desired storage class upon upload, eliminating the need for separate lifecycle policies and reducing application programming interface (API) calls.”
CloudFS already supports VMware and Hyper-V on-premises edge nodes and now adds Red Hat Enterprise Linux (v9.4) KVM support.
V8.4 has existing support for cloud mirroring with identical copies of data in two separate object stores, and “now accelerates synchronization of data changes made any time the primary object store was unavailable” up to 10x faster. Also “the synchronization itself serves to dramatically reduce egress charges.”
More speed improvements come from “file operations for extremely large files and folders [being] faster with this release, which improves file and folder renaming as well as changes to file and folder permissions, and some file write operations.”
SK hynix has added another four layers to its 12-Hi HBM3e memory chips to increase capacity from 36 GB to 48 GB and is set to sample this 16-Hi product in 2025.
Up until now, all HBM3e chips have had a maximum of 12 layers, with 16-layer HBM understood to be arriving with the HBM4 standard in the next year or two. The 16-Hi technology was revealed by SK hynix CEO Kwak Noh-Jung during a keynote speech at the SK AI Summit in Seoul.
SK hynix CEO Kwak Noh-Jung presenting the 16-Hi HBM3e technology at the SK AI Summit in Seoul
High Bandwidth Memory (HBM) stacks memory dice and connects them to a processor via an interposer unit rather than via a socket system as a way of increasing memory to processor bandwidth. The latest generation of this standard is extended HBM3 (HBM3e).
The coming HBM4 standard differs from HBM3e by having an expected 10-plus Gbps per pin versus HBM3e’s max of 9.2 Gbps per pin. This would mean a stack bandwidth of around 1.5 TBps compared to HBM3e’s 1.2-plus TBps. HBM4 will likely support higher capacities than HBM3e, possibly up to to 64 GB, and also have a lower latency. A report says Nvidia’s Jensen Huang has requested SK hynix to deliver HBM4 chips 6 months earlier than planned. SK Group Chairman Chey Tae-won said the chips would be delivered in the second half of 2025.
The 16-Hi HBM3e chips have generated performance improvements of 18 percent in GenAI training and 32 percent in inference against 12-Hi products, according to SK hynix’s in-house testing.
SK hynix’s 16-Hi product is fabricated using a MR-MUF (mass reflow-molded underfill) technology. This combines a reflow and molding process, attaching semiconductor chips to circuits by melting the bumps between chips, and filling the space between chips and the bump gap with a material called liquid epoxy molding compound (EMC). This increases stack durability and heat dissipation.
The SK hynix CEO spoke of more memory developments by the company:
LPCAMM2 module for PCs
1c nm-based LPDDR5 and LPDDR6 memory
PCIe gen 6 SSD
High-capacity QLC enterprise SSD
UFS 5.0 memory
HBM4 chips with logic process on the base die
CXL fabrics for external memory
Processing near Memory (PNM), Processing in Memory (PIM), and Computational Storage product technologies
All of these are being developed by SK hynix in the face of what it sees as a serious and sustained increase in memory demand from AI workloads. We can expect its competitors, Samsung and Micron, to develop similar capacity HBM3e technology.
Cloud storage player Backblaze is spreading the reach of managed hybrid cloud solutions firm Opti9 through a new partnership. As part of the alliance, Backblaze will open a new datacenter region in Canada, and Opti9 will be the exclusive Canadian channel for Backblaze B2 Reserve and the Powered by Backblaze program.
Opti9 delivers managed cloud services, application development and modernization, backup and disaster recovery, security, and compliance solutions to businesses around the world. B2 Cloud Storage promises secure, compliance-ready, “always-hot” object storage that is “one-fifth the price” of traditional cloud storage providers. B2 can be used in any of the solutions Opti9 provides.
Gleb Budman
Increasingly, say the new partners, companies seeking managed services support are demanding solutions made up of “best-of-breed providers”. While traditional cloud platforms “work against this principle,” Backblaze and Opti9 are committed to delivering cloud solutions without the “limitations, complexity, and high pricing” that are “holding customers back.”
The new Canadian data region gives businesses the freedom to access Backblaze’s offering, while still allowing them to benefit from local storage and compliance. Located in Toronto, Ontario, the datacenter complies with SOC 1 Type 2, SOC 2 Type 2, ISO 27001, PCI DSS, and HIPAA. The region will be available to customers in the first quarter of 2025.
Jim Stechyson
“Being able to integrate the high performance and low total cost of ownership of Backblaze’s object storage into our set of solutions will greatly enhance our ability to drive success for our customers,” said Jim Stechyson, president of Opti9.
“Businesses want modern storage solutions that serve their needs without worrying about out-of-control fees, complexity, or other limits,” added Gleb Budman, CEO of Backblaze. “Coming together means we can unlock growth for even more businesses around the world.”
Opti9 has multiple offices in North America and has datacenter space in the US, Europe, and the APAC region. It is an AWS Advanced Consulting Partner, Platinum Veeam Cloud & Service Provider, and Zerto Alliance Partner.
Earlier this year, Backblaze took the wraps off Backblaze B2 Live Read, giving customers the ability to access, edit, and transform content while it’s still being uploaded into B2 Cloud Storage.
The Ultra Accelerator Link (UALink) Consortium, led by data processing and connectivity industry heavyweights, is now inviting new members to join.
The UALink effort was initiated in May 2024, and seeks to define a high-speed, low-latency interconnect for scale-up communications between accelerators and switches in AI pods and clusters. The effort aims to create an open ecosystem and provide an alternative to Nvidia’s proprietary NVLink technology.
In addition, work is already under way by the Consortium to develop additional usage models for datacenter AI connectivity.
Existing Consortium board members include AMD, Amazon Web Services, Astera Labs, Cisco, Google, Hewlett Packard Enterprise, Intel, Meta, and Microsoft. They have now announced the incorporation of the Consortium, and are extending an invitation for membership to the wider industry to become “contributor members” who will help shape future UALink specifications.
The UALink 1.0 specification will enable up to 200 Gbps per lane scale-up connections for up to 1,024 accelerators within an AI pod. The specification will be available to contributor members this year, and will be available for general industry review in the first quarter of 2025, said the Consortium.
Kurtis Bowman
“The UALink standard defines high-speed and low-latency communication for scale-up AI systems in datacenters,” said Willie Nelson, president of the UALink Consortium. “Interested companies are encouraged to join as contributor members to support our mission, which is establishing an open and high-performance accelerator interconnect for AI workloads.”
Kurtis Bowman, chairman of the UALink Consortium, added: “The wider release of the UALink 1.0 specification in Q1 2025 represents an important milestone, as it will establish an open industry standard, enabling AI accelerators and switches to communicate more effectively, expand memory access to meet large AI model requirements, and demonstrate the benefits of industry collaboration.”
NVLink is Nvidia’s proprietary interconnect technology, which is being challenged by UALink and Ultra Ethernet.
Profile. Blocks & Files spoke to Syniti CEO Kevin Campbell about his time with the company, how it has developed, and where it might be headed.
Massachusetts-based Syniti was founded as BackOffice Associates in 1996 by CTO Tom Kennedy to help businesses with data quality, data governance, and data migration issues for enterprise resource planning (ERP) systems like SAP and Oracle. It became involved in system upgrades and mergers, and developed a widely used Data Stewardship Platform (DSP). This provided tools for data governance, quality management, and compliance. The company raised $30 million from Goldman Sachs in a venture round in 2008 and acquired a few other businesses as it grew: HiT Software in 2010, ENTOTA in 2013, CompriseIT in 2016. Kennedy left the company and its board at the end of 2012, subsequently founding a couple of other businesses.
Private equity house Bridge Growth Partners (BGP) bought BackOffice Associates from its owners and Goldman Sachs in 2017. At that time, Syniti’s CEO was ex-HPE exec David Booth and the company had around 800 employees and more than 500 customers worldwide. BGP brought in Kevin Campbell to be CEO two years later, in February 2019. He did not have a typical background for such a role, joining BackOffice Associates after being a volunteer working at food banks and so forth for three years, a COO at Oscar Health for a year before that, and co-COO at Bridgewater Associates the prior year. But his main CV event equipping him for the CEO role was being Group Chief Executive of Technology at Accenture for six years from February 2006, and Group Chief Exec for Outsourcing for a year before that.
At BackOffice Associates, he instituted a strategic shift from a focus on data management as a back-office function to a more strategic emphasis on intelligent data management, analytics, and cloud migration as part of end-to-end data transformation for enterprises. The company was rebranded to Syniti, being a blend of “synergy” and “infinity.”
Kevin Campbell
In the five years since Campbell became CEO, he has helped enable BGP’s profitable exit, with Syniti being sold to Capgemini in August.
Campbell talked about how the Syniti name came about, saying: “I became CEO six years ago, and we changed name in my first board meeting. One of my longtime clients who happened to be on the board, said to me, ‘You guys all hate the name … BackOffice Associates. Why don’t you change the name?’ And I said, ‘We can’t do that, because we’ve got this big event with SAP coming up in 12 weeks.’ And they said, ‘You can do it. We’ve seen you work before. You can do it’. So anyway, we went from BackOffice Associates to Syniti. You can’t use any word that’s already out there. So you have to make one up, right? So that’s how we got it.”
A large focus inside Syniti is on moving customer data to the public cloud, with Campbell saying: ”We’re almost always moving from one set of source systems to a new set of source systems, and you’re mapping them and transforming it. And our point is, if you just take the old data and put it in the cloud, then you got bad data in the cloud, right? Which I always say is like putting old gas in your brand-new Ferrari. It doesn’t work very well.”
This data transformation can also happen because businesses buy other businesses in mergers and acquisitions (M&A). Campbell told us: “A big part of what we do is all related to M&A, because people are always buying something or selling something. So what do they need to do? Split the data often with somebody, or integrate it. So we’re working at businesses like Bosch right now. There are 100 systems there that are all unintegrated acquisitions they made over the years.”
Now Bosch wants to integrate them and have a single version of data truth, so to speak. It wants a single consistent name for any Bosch customer and a single set of records pertaining to that customer, collected from across the multiple systems with multiple versions of the customer name or identifying number, and consistent record formats for things like invoices and purchase orders. This kind of data management is a long, long way from file life cycle management.
We suggested to Campbell that Syniti is “more towards the consultancy end of the supplier spectrum, the Arthur Andersen, the Price Waterhouses and so on. And going a little bit further than that, you represent a specialized niche in that market where you’ve got expertise that they probably rely on.”
He said: “Our point is, data should be its own unique impact, right, and its own specialty. So we’re a specialist provider. Now, sometimes we would do it in place of them. Sometimes you can do it side by side with them. Sometimes they use our software and do it themselves. All of those ways work.”
We suggested that because Syniti is highly focused on a particular area of enterprise data management, it’s probably limited in its go-to-market capabilities, and Capgemini will enable the company to broaden its sales funnel and reach.
Campbell said: “We’re roughly a $250 million company … 1,500 people [and] we have to make choices about what we could do, when we’re private equity backed … Our private equity owners, at some point, have to move us on. And so we were looking for the next chapter in our history [and] Capgemini will give us a lot more reach.”
We asked him to describe the current state of the data management market.
He said he considers that “the struggle in the data management market today is making it high enough priority. When I go around and talk to people all the time, everybody agrees that data quality is important. Without good data, I don’t have good AI. You know, it’s all about the business benefits. The difference between 85 percent accuracy and 99.9 percent accuracy is all the business benefits. And every problem in a company is ultimately a data problem. Everybody gets that and reiterates it, but causing action and causing people to do something about it is hard. I’m hopeful, and I always tell my team: ‘We’re never wrong. We’re just often not convincing enough.’
“The challenge in the data management market is getting people to put money to fix those problems. I’m hopeful, it’s not unrealistic, that AI will be defined to be something that helps elevate that, because what’s happening today … there’s a ton of proof of concepts out there. Everybody’s taking the great technology of AI, but they learn quickly that if the data is bad, it just gives me garbage on the other side.”
B&F tried to flesh this out a little, talking about “the magic phrase, retrieval-augmented generation. You could say to a potential customer, that because of GenAI projects you need to rely on highly accurate responses to inquiries into your proprietary data. We don’t want hallucinations in what your execs are finding out from your data. So that means your data absolutely has to be top notch quality. You cannot afford not to ensure that.”
Campbell replied that such errors could be caused by mistakes in a company’s own documentation. He said AI could be used to improve data quality. “You need data quality for AI, but you can also use AI to improve your data quality. And that’s the combination. We’re using AI to build data quality rules to interrogate all the data that you have out there about problems, so that you can then build faster rules, that you can run against the data to make sure you’re trying to prevent the data errors.”
Syniti, it seems to B&F, is not going to move into the file life cycle part of the general data management market. It’s going to stick to its enterprise data management knitting and go deeper into more and more customers.
He agreed: “I don’t think all of the Fortune 2000 are clients. So until you run out of the Fortune 2000, keep going back.” Syniti could start on a customer’s customer service department, or HR, and then build its presence out within that customer, staying with some for 15, 20 years or more.
What’s the product roadmap like, looking ahead to the next few months?
“We’ve got some AI stuff in the product, and then have some proof of concept we’re doing with the customers. And what we’re going to start in the fourth quarter is incorporating the answers from some of the concepts into the product.” The GenAI space is developing fast with new models and techniques and they may well find their way into the product.
“I think the other major thing for us is our governance product. Today it’s still a product that is cloud-like but not cloud-native, and the rest of the product is cloud-native. So we’re continuing to upgrade the interfaces and things like that in the governance product.”
We didn’t ask if or for how long Campbell would stay at the Syniti operation’s helm inside Capgemini. Given the pattern of events in his CV, he may well decide to take another volunteering break once the integration into Capgemini is complete. On the other hand, with his Accenture history, he could equally find himself doing more inside Capgemini. We’ll watch and wait with interest.
Analysis. Cisco has announced an Nvidia-based GPU server for AI workloads plus plug-and-play AI PODs that have “optional” storage, though Cisco is not included in Nvidia’s Enterprise Reference Architecture list of partners.
Cisco M8 C885A GPU server
Switchzilla introduced an AI server family purpose-built for GPU-intensive AI workloads with Nvidia accelerated computing, and AI PODs to simplify and de-risk AI infrastructure investment. The server part of this is the UCS C885A M8 rack server with Nvidia H100 and H200 Tensor Core GPUs and BlueField-3 DPUs to accelerate GPU access to data. The AI PODs for Inferencing are full-stack converged infrastructure designs including servers, networking, and Nvidia’s AI for Enterprise software portfolio (NVAIE), but they don’t actually specify the storage for that data.
A Cisco webpage says that the AI PODs “are CVD-based solutions for Edge Inference, RAG, and Large-Scale Inferencing,” meaning not AI training. CVD stands for Cisco Validated Designs, “comprehensive, rigorously tested guidelines that help customers deploy and manage IT infrastructure effectively.”
The webpage has an AI POD for Inferencing diagram showing the components, which include an Accelerated Compute (server) element:
We’re told that Cisco AI Infrastructure PODs for Inferencing have independent scalability at each layer of infrastructure and are perfect for DC or Edge AI deployments. There are four configurations that vary the amount of CPU and GPUs in the POD. Regardless of the configuration, they all contain:
Cisco UCS X-Series Modular System
Cisco UCS X9508 Chassis
Cisco UCS-X-Series M7 Compute Nodes
Note the M7 Compute Nodes, which means Cisco’s seventh UCS generation. The new M8 generation GPU server is not included and thus is not part of this AI POD. Neither are Nvidia’s BlueField-3 SuperNICs/DPUs included.
Because of this, we think that Cisco’s AI POD for Inferencing does not meet Nvidia’s Enterprise Reference Architecture (RA) needs, which is why Cisco was not listed as a partner by Nvidia. The Enterprise RA announcement said: “Solutions based upon Nvidia Enterprise RAs are available from Nvidia’s global partners, including Dell Technologies, Hewlett Packard Enterprise, Lenovo and Supermicro.”
We have asked both Cisco and Nvidia about Cisco being an Enterprise RA partner and the AI PODs being Enterprise RA-validated systems. A Cisco spokesperson answered our questions.
Blocks & Files: Are Cisco AI PODs part of the NVIDIA RA program, and if not, why?
Cisco: Nvidia has previously introduced reference architectures for cloud providers and hyperscalers, and their recent announcement extends those RAs to enterprise deployments. Their RA program isn’t dissimilar to Cisco’s Validated Designs. A key component of the Nvidia’s RAs is their SpectrumX Ethernet networking, which is not offered as part of Cisco’s AI PODs. Additionally the AI PODs will, over time, offer choice in GPU provider. Regardless of PODS vs. RAs, Cisco and Nvidia are in agreement that our customers need us to help them along on this journey by simplifying our offers and providing tried and tested solutions that help them move faster.
Blocks & Files: Do the AI PODs include the latest UCS C885A M8 servers?
Cisco: The UCS C885A M8 is not part of an AI POD today, but it is planned for future PODs. The UCS C885A M8 was just announced at Cisco Partner Summit and will start shipping in December. At that time, Cisco will develop Validated Designs, which will be used as the basis for creating AI PODs for training and large-scale inferencing. All to say – more to come.
****
There is no storage component identified in the AI POD diagram above, despite AI PODs being described as “pre-sized and configured bundles of infrastructure [which] eliminate the guesswork from deploying AI inference solutions.”
Instead, either Pure Storage or NetApp are diagrammed as providing a converged infrastructure (CI) component. The webpage says: “Optional storage is also available from NetApp (FlexPod) and Pure Storage (FlashStack).”
We find this odd on two counts. We would think AI inferencing is obviously critically dependent on potentially large amounts of data that must be stored. Yet the storage part of an AI POD is “optional” and hardly helps “eliminate the guesswork from deploying AI inference solutions.”
Blocks & Files: Why is storage optional in the AI PODs?
Cisco: The AI PODs that were introduced at Partner Summit are for inferencing and RAG use cases. Inferencing doesn’t necessarily require a large amount of storage. In order to align with customers’ needs, we wanted to make the storage component optional for this use case. Customers using the AI PODs for RAG can add NetApp or Pure as part of Converged Infrastructure stack (FlexPod, FlashStack), which is delivered through a meet-in-the-channel model. For future PODs, in which the use case requires greater storage needs, we will work with our storage partners to fully integrate.
****
Also, a FlexPod is an entire CI system in its own right, including Cisco servers (UCS), Cisco networking (Nexus and/or MDS), and NetApp storage, with more than 170 specific configurations. The storage can be ONTAP all-flash or hybrid arrays or StorageGRID object systems.
Cisco’s AI POD design, purporting to be an entire CI stack for AI inferencing, needs to include specific NetApp storage and not a NetApp entity (FlexPod) that is itself a CI stack.
Pure’s FlashStack is, like FlexPod, a full CI stack with “more than 25 pre-validated solutions to rapidly deploy and support any application or workload.” It has “integrated storage, compute, and network layers.”
Again, Cisco’s AI POD design needs to specify which Pure Storage products, FlashArray or FlashBlade, and allowable configurations, are valid components for the AI POD, not just refer to Pure’s full CI FlashStack.
It could make more sense if there were specific FlexPod for AI Inferencing or FlashStack for AI Inferencing designs. At least then customers could get converged AI infrastructure from one supplier or its partners, instead of having to go to Cisco and then, separately, to NetApp or Pure. The AI POD for Inferencing CI concept could be confusing when it refers to FlexPod and FlashStack CI systems.
Cohesity has hired Vasu Murthy as SVP and chief product officer. He comes from Rubrik, where he was VP of products – responsible for the core product, platform, and technology partnerships. He helped grow Rubrik’s ARR tenfold over six years to IPO while navigating transformation across three fronts: software to subscription, on-prem to cloud, and backup to data security. Prior to Rubrik, Murthy was VP of products for the Analytics Platform at Oracle, launching several $100M+ products.
…
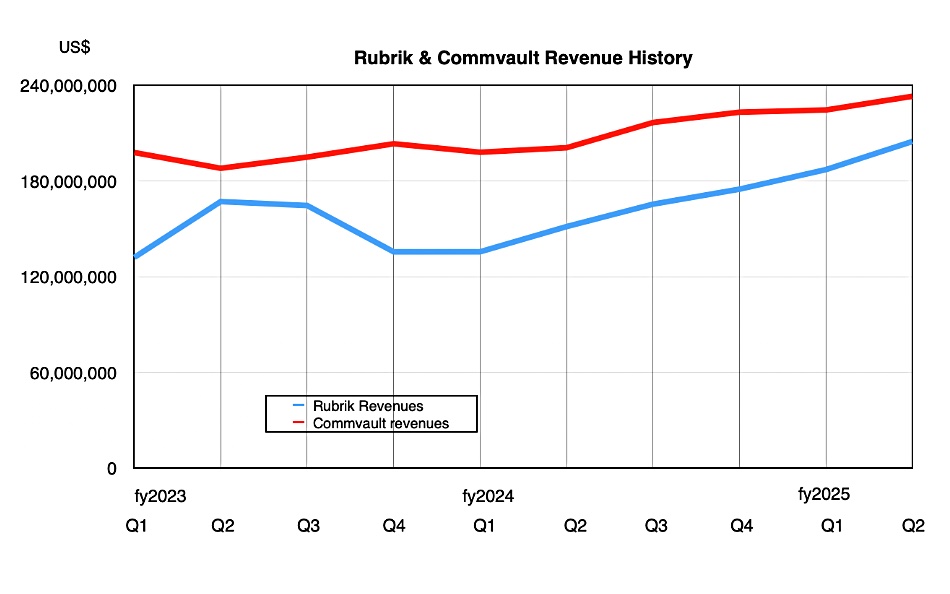
We compared the revenue histories of Commvault and Rubrik:
Rubrik is growing revenues faster than Commvault, but not by that much. If Commvault can accelerate its growth then it can stay ahead.
…
AstraDB supplier DataStax announced the enhancement of its GitHub Copilot extension with its AI Platform-as-a-Service (AI PaaS) offering. This will make it easier for developers to interact directly with DataStax Langflow and their Astra DB databases’ vector, tabular, and streaming data right from their IDE through the DataStax GitHub Copilot Extension.
Jyothi Swaroop.
…
DDN hired Jyothi Swaroop earlier this year in March as its chief marketing officer. VP marketing Kurt Kuckein resigned from DDN in August after nine years. Swaroop had been on a career break after being CMO at Nylas, a developer supplying APIs for embedding email and calendar functionality directly into apps. He had been global marketing VP at Veritas before that.
…
DDN is supplying storage for Denmark’s Gefion AI supercomputer. It is being supplied by France’s Eviden and is based on an Nvidia DGX SuperPOD with 1,528 NH100 Tensor Core GPUs, Nvidia Quantum-2 InfiniBand networking with DDN storage, understood to be Lustre-based ExaScaler systems. It also uses Nvidia BioNeMo and CUDA-Q software. The new AI supercomputer was symbolically turned on by King Frederik X of Denmark, Nvidia’s Jensen Huang and Nadia Carlsten, CEO of DCAI, at an event in Copenhagen this month. Huang said: “Gefion is going to be a factory of intelligence. This is a new industry that never existed before. It sits on top of the IT industry. We’re inventing something fundamentally new.”
Gefion is being prepared for users, and a pilot phase will begin to bring in projects that seek to use AI to accelerate progress, including in such areas as quantum computing, drug discovery and energy efficiency.
…
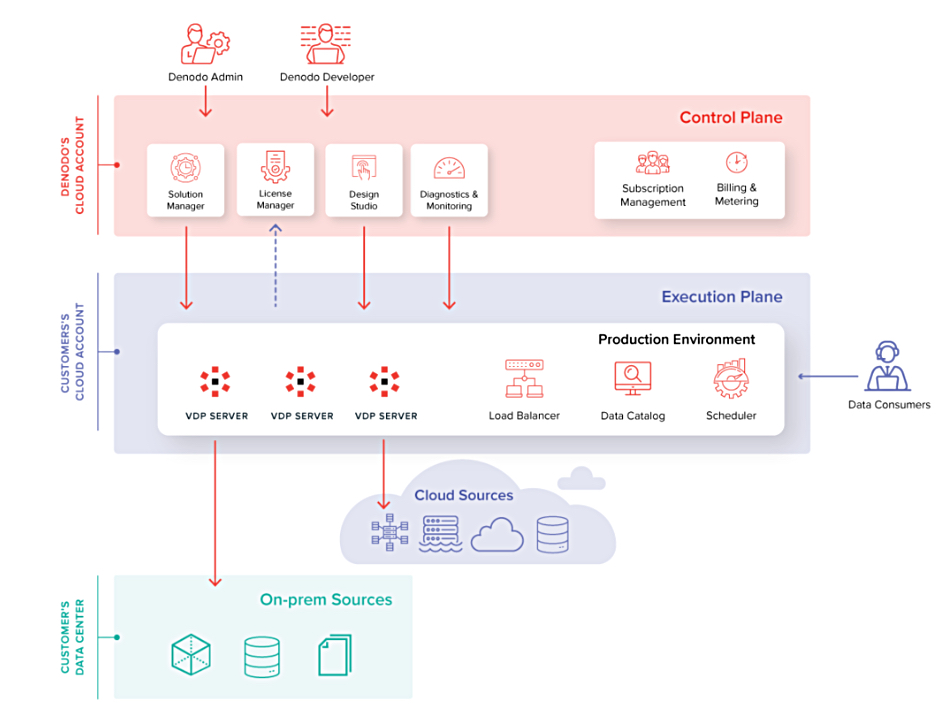
Data management supplier Denodo announced Agora, fully-managed cloud-based software which it claims will eliminate the need for IT teams to manage infrastructure. Agora has a control plane, providing the capabilities found in Solution Manager, License Manager, Design Studio, and the Monitor in a customer’s own cloud environment. This ensures that data remains under their control, adhering to security policies and compliance requirements. In this plane, the Virtual DataPort (VDP), Scheduler, and Data Catalog servers work to process and catalog customer data.
Denodo Agora diagram.
…
Lakehouse supplier Dremio announced its Data Catalog for Apache Iceberg. Built on the open source Project Nessie, it supports all deployment options – on-prem, cloud, and hybrid – making Dremio the only lakehouse provider to deliver full architecture flexibility. Additionally, Dremio is announcing integrations with Snowflake’s managed service of Apache Polaris (incubating) and Databricks’ Unity Catalog managed service. This allows customers to choose the best catalog for their needs, while using Dremio to deliver seamless analytics across all data.
…
Sathya Sankaran.
SaaS backupper HYCU has hired Sathya Sankaran as head of cloud products. He was at Catalogic and slated to run the to-be-spun-off CloudCasa Kubernetes app SaaS backup service. The spin-off was put off, so Sankaran spun himself off to HYCU. A main attraction was HYCU’s R-Cloud, which “offers a unique solution to the growing challenges of protecting data in cloud and SaaS environments without forgetting where much of that data currently resides.” Read more here.
…
HYCU announced the GA of GitHub and GitLab, adding to existing support for Bitbucket, Terraform, AWS CloudFormation, CircleCI, and Jira in the HYCU R-Cloud Marketplace. This provides developers with the broadest data protection capabilities to protect and recover IP, source code, and configurations across an enterprise. With the highest change rate across a company’s tech stack, GitHub is a platform where developers constantly update repositories and increase the risk of data loss due to human error from multiple contributors, command-based activities, and heavy CI/CD automations.
…
Denmark-based SaaS data backup target supplier Keepit won in four categories at the Top Infosec Innovator 2024 awards. Keepit was named the winner in the following categories: Cutting Edge Cloud Backup; Most Innovative Cyber Resilience; Hot Company Data Security Platform; and Hot Company Ransomware Protection of SaaS Data.
…
Kioxia has begun mass production of the industry’s first QLC UFS v4.0 embedded flash memory devices. Its new 512 gigabyte QLC UFS achieves sequential read speeds of up to 4,200 megabytes per second and sequential write speeds of up to 3,200MB/sec. UFS is well suited for smartphones and tablets, as well as other applications where higher storage capacity and performance are key – including PCs, networking, AR/VR, and AI. UFS 4.0 incorporates MIPI M-PHY 5.0 and UniPro 2.0 and supports theoretical interface speeds of up to 23.2 gigabits per second per lane or 46.4Gbit/sec per device, and is backward compatible with UFS 3.1.
…
NetApp has appointed Pamela Hennard as its new chief diversity and inclusion officer after being global head of talent acquisition from August 2022 onwards. She came from the same position at troubled Boeing. Hennard will lead NetApp’s efforts to foster diversity, equity, and inclusion across the organization and within the talent acquisition process and throughout the full employee journey. She has more than 27 years of HR experience. Comment: the ever-increasing number of chief something-or-other officers in business exec ranks is becoming comical. This comment is being written, of course, by Blocks & Files’ chief comment officer.
…
Oxla came out of stealth with its next-gen OLAP Oxla database dubbed the world’s fastest distributed database. It’s a high-performance distributed analytical database designed from the ground up for large-scale data processing. With ten times faster analytical query execution speeds and up to 85 percent lower costs compared to data warehouses from Snowflake, Databricks, or ClickHouse, Oxla is suited for data-intensive workloads across IoT, industrial applications, e-commerce, and cyber security. Led by Google alumnus and three-time CTO Adam Szymański, Oxla’s expert team of database scientists has secured three patents related to an innovative system for controlling data flow in query engines and the dynamic execution of those queries, with three more patents pending.
Oxla’s fully managed cloud offering is currently available on Amazon Web Services, with deployment options for Microsoft Azure and Google Cloud Platform in the final stages of development. The company intends to scale the product’s performance further, aiming to handle tens of petabytes of data and process hundreds of thousands of queries per second – capabilities it claims remain beyond the reach of competitor offerings.
…
Revefi announced a Fortune 500 company reduced its Snowflake spend by $200K within a few days of installing Raden, Revefi’s AI data engineer that augments data teams with expertise in data architecture, system performance and cost management. Acting as a co-pilot or autopilot, the Raden AI data engineer automates functions such as data quality and data observability, as well as spend, performance and usage management, enabling data teams to, for example, connect performance to spend usage. Sanjay Agrawal, CEO and co-founder of Revefi, explained “We’ve seen a 300 percent increase in demand from enterprise data teams in the Americas and Europe, signalling a massive shift toward AI-centric solutions for data observability, data quality and spend optimization.” Raden’s zero-touch, no data-access approach allows for quick implementation and significant cost reductions.
Tony Craythorne.
…
Block storage supplier StorPool Storage has appointed Tony Craythorne as its new CRO. Previous positions include CRO of Linarc Inc. where he launched a new product resulting in multiple new large ARR customer wins. Also CRO at Index Engines and Zadara, CEO of Bamboo Systems, senior vice president of worldwide sales at Komprise, and executive leadership positions at Brocade, Hitachi Data Systems, Nexsan and others.
…
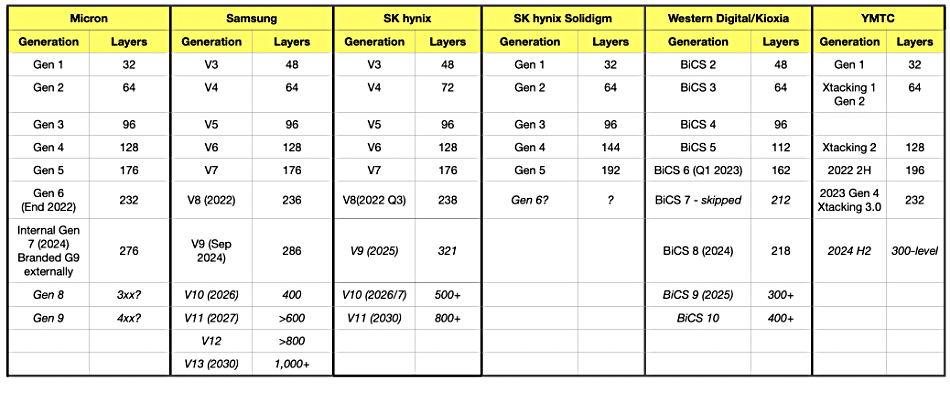
The Korea Economic Daily reports Samsung is developing 400-layer 3D NAND for 2026 availability based on an acquired Samsung roadmap document. This would be version 10 of its V-NAND technology. Its current v9 has 286 layers. The logic die would be manufactured separately from the NAND die, with the two bonded together after being cut out of their wafers. A v11 NAND would follow in 2027 and we think that will have 500 to 600+ layers. Samsung is clearly not thinking that the 3D NAND layer race is over, as WD reckons.
…
Supermicro, which makes x86, Nvidia GPU and storage servers, has been set back by the resignation of its auditors, Ernst & Young, citing governance and transparency issues. Basically, E&Y is telling Supermicro it doesn’t trust what it’s been told by the firm’s financial reports and the biz can’t give it reliable information for the audit. That will delay Supermicro’s next annual report to the SEC and has spooked investors – Supermicro stock dropped more than 15 percent.
In its resignation letter, E&Y stated, in part: “We are resigning due to information that has recently come to our attention which has led us to no longer be able to rely on management’s and the Audit Committee’s representations and to be unwilling to be associated with the financial statements prepared by management, and after concluding we can no longer provide the Audit Services in accordance with applicable law or professional obligations.”
Supermicro will provide a first quarter fiscal 2025 business update on Tuesday, November 5.
….
Data migrator to the cloud Vawlt announced Vawlt 3.1 to add:
Bandwidth Throttling – Set a maximum limit on the bandwidth Vawlt can use for uploads and downloads.
New Cloud Providers – Added support for Tencent Cloud and IDrive.
Automated Air-Gapping Rules – Schedule specific periods for data volumes to be automatically air-gapped, enhancing security.
Enhanced Volume Access Permissions – Assign read-only or read/write access per user to specific prefixes within the same Vawlt data volume.
2FA Protection for Key Operations – Enable two-factor authentication for critical operations, such as updating immutability properties.
Support S3 Object Sources in our Synchronization Tool – Automatically sync data from any S3-compatible storage sources with Vawlt data volumes.
Seamless Proxy Support – Easily configure a proxy through which Vawlt communicates with the internet.
Jon Howes.
…
Cloud object storage supplier Wasabi has appointed Jon Howes as SVP of global sales, promoting him from VP and GM of EMEA, which he became in January 2023. He drove 77 percent year over year growth in ARR and played a pivotal role in building key partnerships for Wasabi with some of EMEA’s largest companies including Retelit, Bechtle, Exclusive Networks, TD Synnex, and more.
Chorology has released a patented AI-driven compliance engine to auto-identify, contextualize and classify sensitive data at scale.
The San Jose-headquartered compliance and security posture management firm has unveiled its Automated Compliance Engine (ACE) – equipped with AI-based knowledge encoding, a new domain language model, and AI planning automation. The startup came out of stealth mode earlier this year.
“These patented technologies coalesce, providing the first and only mandate-agnostic solution to deliver a complete view of all sensitive enterprise data – known and unknown – throughout structured and unstructured environments,” claimed Chorology.
Several compliance and security challenges continue to pose major risks to organizations, making technology that accurately identifies, contextualizes and classifies data essential, says the provider.
Chorology ACE graphic
Efficiently responding to consumers’ data subject access requests (DSARs) is one use case that has to be addressed. Under legislation such as the General Data Protection Regulation, failure to respond to consumer DSARs in time can leave organizations open to administrative fines and financial risk.
With the ACE platform, organizations can frame enterprise data under management as knowledge objects. With this AI framing, very large repositories of sensitive data can be discovered, identified and classified at “ultra-high speed” and scale, we are told. Large numbers of DSARs can be automatically processed too, delivering time savings and helping to avoid penalties.
Tarique Mustafa
And by encoding knowledge objects for each data type, ACE can accurately recognize any data type, for any mandate, in any industry, without any costly machine learning training, and through using a single compliance platform.
“ACE now makes it possible to automatically discover all known and unknown sensitive data throughout the enterprise’s data universe, where compliance policies can then be automatically applied,” said Tarique Mustafa, CEO, CTO and founder of Chorology.ai. “Our mandate-adaptive technology uniquely applies knowledge representation and inference encoding disciplines into the artificial intelligence and language understanding, to very accurately discover, identify, classify and map data at scale, which has not been possible previously.”
Mustafa previously founded cyber security platform GhangorCloud, and he has held senior positions at the likes of Symantec, Nevis Networks, Andes Networks, Nextier Networks, and MCI WorldCom. Chorology’s founding team includes executives that have experience at firms including McAfee, TrendMicro, Cisco, and Array Networks.