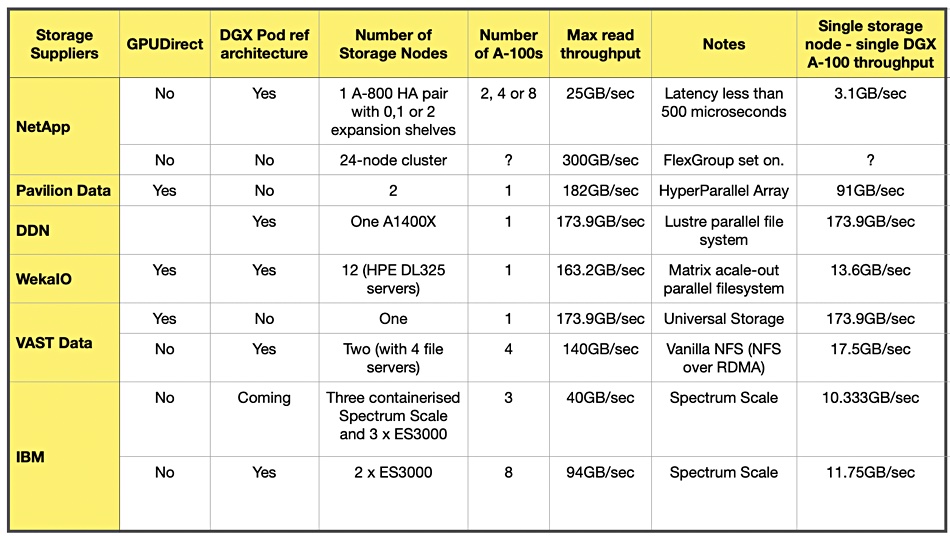
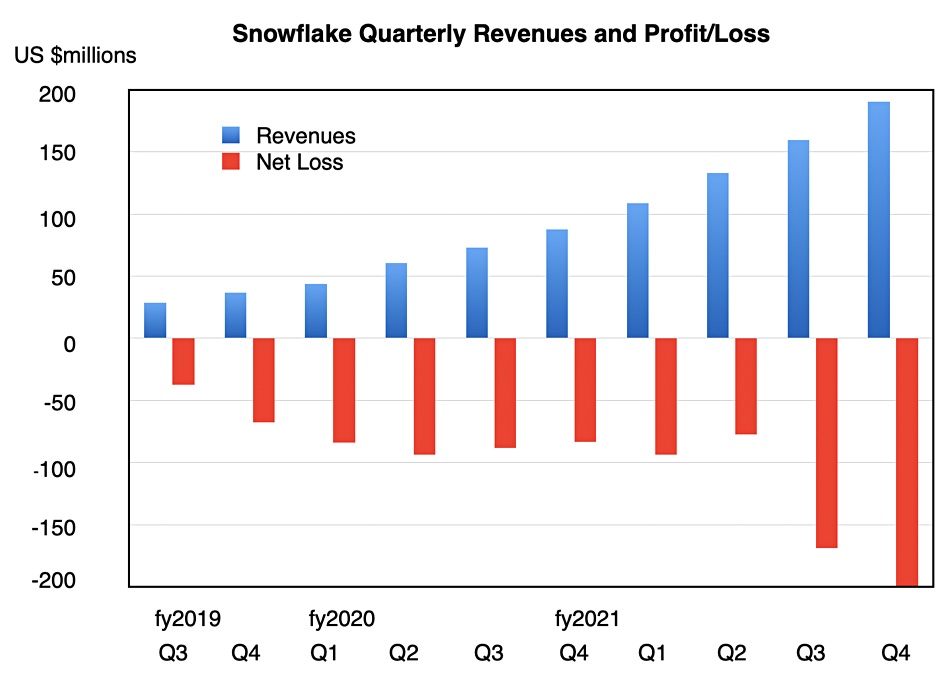
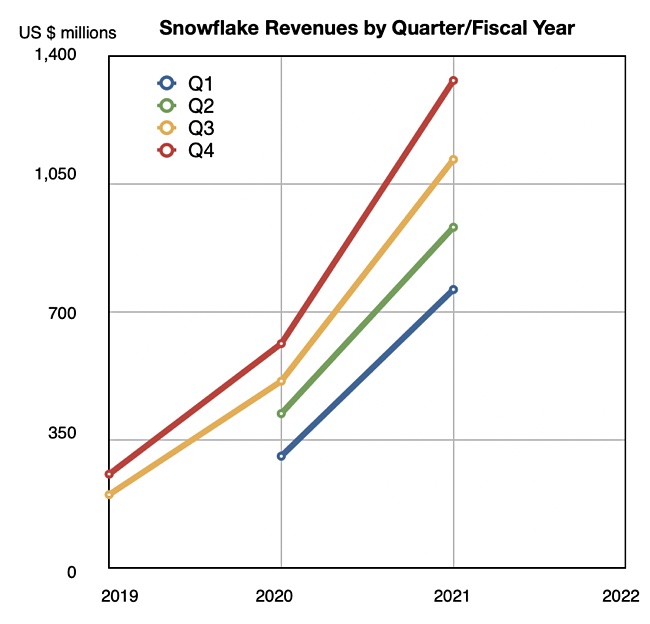
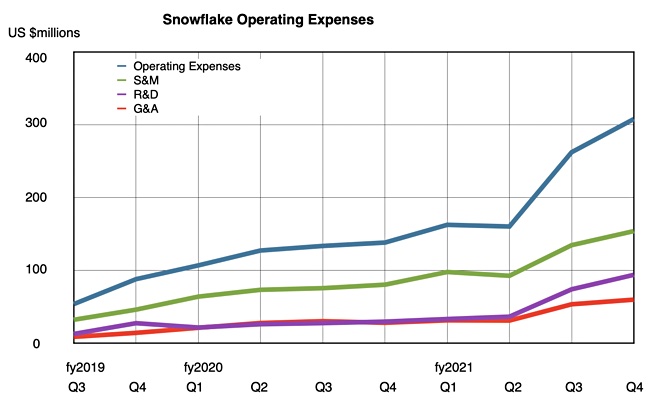
Sponsored Artificial Intelligence techniques have been finding their way into business applications for some time now. From chatbots forming the first line of engagement in customer services, to image recognition systems that can identify defects in products before they reach the end of the production line in a factory.
But many organisations are still stuck at where to start in building machine-learning and deep-learning models and taking them all the way from development through to deployment. Another complication is how to deploy a model onto a different system than the one that was used to train it. Especially for situations such as edge deployments, where less compute power is available than in a datacentre.
One solution to these problems is to employ OpenVINO™ (Open Visual Inference & Neural Network Optimization), a toolkit developed by Intel to speed the development of applications involving high-performance computer vision and deep-learning inferencing, among other use cases.
OpenVINO takes a trained model, and optimises it to operate on a variety of Intel hardware, including CPUs, GPUs, Intel® Movidius™ Vision Processing Unit (VPU), FPGAs, or the Intel® Gaussian & Neural Accelerator (Intel® GNA).
This means that it acts like an abstraction layer between the application code and the hardware. It can also fine tune the model for the platform the customer wants to use, claims Zoë Cayetano, Product Manager for Artificial Intelligence & Deep Learning at Intel.
“That’s really useful when you’re taking an AI application into production. There’s a variety of different niche challenges in inferencing that we’ve tackled with OpenVINO, that are different from when models and applications are in the training phase,” she says.
For example, Intel has found there is often a sharp decline in accuracy and performance when models that were trained in the cloud or in a datacentre are deployed into a production environment, especially in an edge scenario. This is because the trained models are shoe-horned into a deployment without considering the system they are running on.
In addition, the model may have been trained in ideal circumstances that differ from the actual deployment environment. As an example, Cayetano cites a defect detection scenario in which a camera view close to the production line may have been assumed during training. The camera may be positioned further away so the images may have to be adjusted – which OpenVINO can do.
Interoperability is another issue, according to Cayetano, “We were seeing this trend of a lot of businesses adopting AI and wanting to take AI into production. But there was a gap in developer efficiency where developers had to use a variety of different tools and ensure they were interoperable and could operate with each other in the same way,” she says. “So they needed a toolkit that would have everything that you want from a computer vision library that allows you to resize that image, or that allows you to quantize your model into a different data type like INT8 for better performance.”
And although OpenVINO started off with a focus on computer vision, the feedback Intel got from developers was that they wanted a more general-purpose solution for AI, whether that was for applications involving image processing, audio processing or speech and even recommendation systems.
“So, the shift we did last year was to make OpenVINO more accessible and for developers to be able to focus solely on the problem that they’re trying to solve and not be encumbered by having to pick different toolkits for different workloads,” Cayetano says.
Plug-in architecture
The two main components of OpenVINO are its Model Optimizer and the Inference Engine. The Model Optimizer converts a trained neural network from a source framework to an open-source, nGraph-compatible intermediate representation ready for use in inference operations.
In addition to the toolkit, there is the Open Model Zoo repository on GitHub, which comprises a set of pre-trained deep learning models that organisations can use freely, plus a set of demos to help with development of new ones.
OpenVINO supports trained models from a wide range of common software frameworks like TensorFlow, MXNet and Caffe. The optimisation process removes layers in the model that were only required during training and can also recognise when a group of layers could be unified into a single layer, which decreases the inference time.
The Inference Engine actually runs the inference operations on input data and outputs the results, as well as managing the loading and compiling of the model, and is able to support execution across different hardware types through the use of a software plug-in architecture.
An FPGA plug-in allows execution targeting Intel® Arria® devices, for example, while another supports CPUs such as the Intel® Core™ or Xeon® families. An OpenCL plug-in supports Intel® Processor Graphics (GPU) execution. A Movidius™ API supports VPUs, and there is an API for the low-power GNA coprocessor built into some Intel processors that allows continuous inference workloads such as speech recognition to be offloaded from the CPU itself.
“So, what OpenVINO does is it actually abstracts the developer away from having to code for each type of silicon processor. We have this write-once deploy-anywhere approach where you can take the same code, and then deploy that application into a Core or a Xeon processor, without having to rewrite your code. So, there’s a lot of efficiency to be had there,” Cayetano says.
This radically reduces time to market for projects and means that businesses are not encumbered by having to select the right hardware first or shoehorn their application into a system that does not fit their ultimate needs.
OpenVINO even allows simultaneous inference of the same network on several Intel hardware devices, or automatic splitting of the inference processing between multiple Intel devices (if, for example, one device does not support certain operations).
Real-life scalability
This flexibility means that OpenVINO has now been deployed by many Intel customers, including Philips and GE Healthcare, which use the toolkit for medical imaging purposes.
“Being able to analyse X-ray images or CT scans and be able to more accurately detect tumours, for example, is one use case. The neural network here is essentially similar to the example of the defect detection, it’s detecting if there’s a tumour or not in the X-ray image/datasets and is using OpenVINO to infer that,” Cayetano says.
With GE Healthcare, the firm used the capabilities of OpenVINO to scale their application for several different end customers, from private clinics to public hospitals.
“For one customer, they needed a Xeon processor, because they were optimising for accuracy and performance, whereas another customer was optimising for cost and size, because it was a smaller deployment site,” Cayetano explains. “So not only was GE Healthcare able to take advantage of the optimisation that OpenVINO can do, but also the scalability of being able to write once, deploy anywhere.”
This shows that OpenVINO provides organisations with the ability to take a trained neural network model and build a practical application around it, which might otherwise have taken a lot more effort to build and may not have delivered satisfactory results.
“Now you’re able to have faster, more accurate results in the real world when you actually go into deployments because we have optimisations built into OpenVINO that allow you to do really cool math stuff that only data scientists used to use, like layer fusion for your neural network, for example,” Cayetano says.
“We’ve put a lot of those advanced state of the art optimisations into OpenVINO for the masses to use, not just the top-notch data scientists. And then it’s all interoperable in the one toolkit. So, you can now use the same computer vision libraries with our model optimisation techniques, and quantisation, all these other tools that really streamline your development experience.”
This article is sponsored by Intel®.