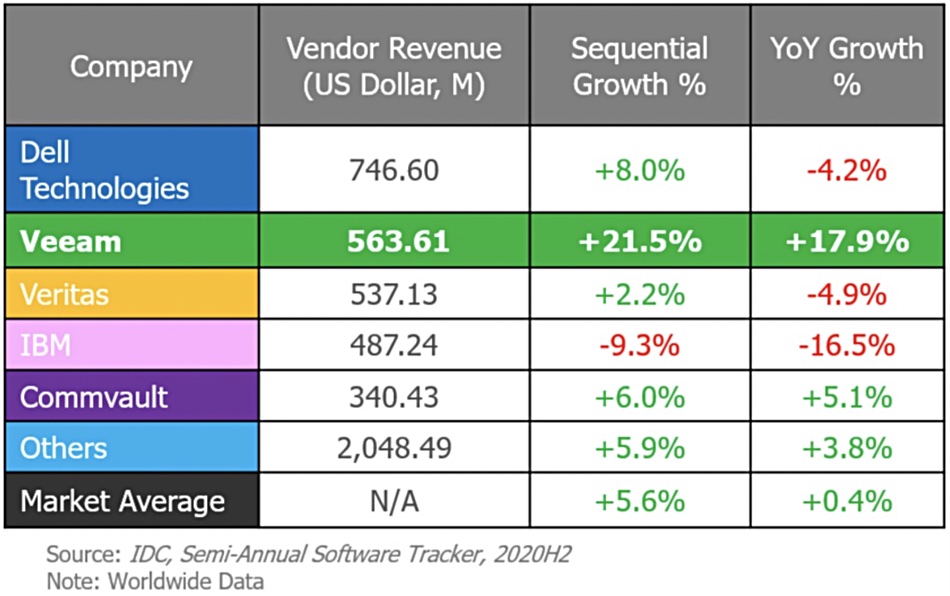
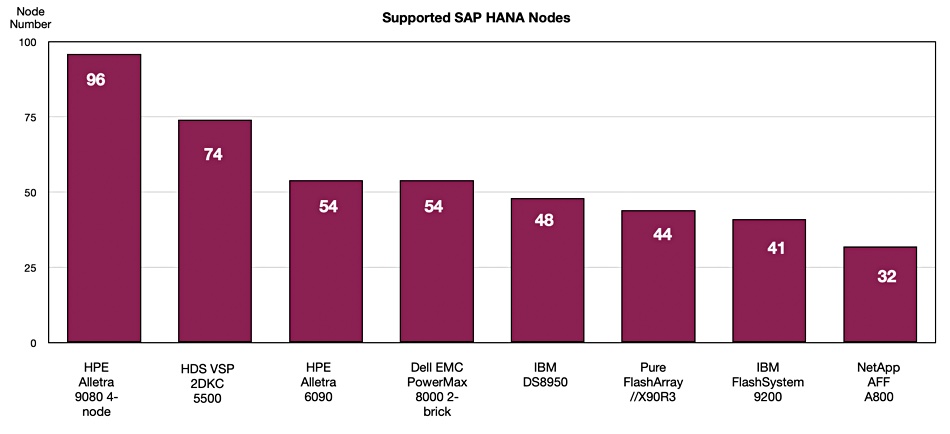
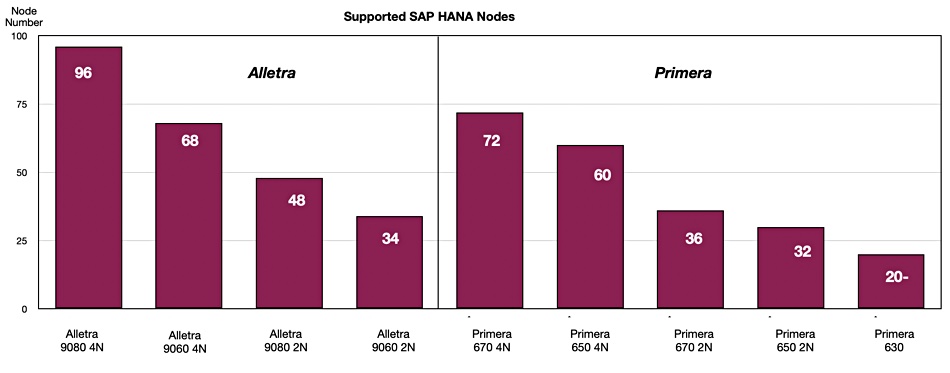
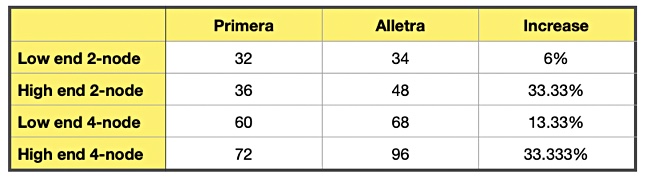
Disk drive and SSD supplier Western Digital has spoken about computational storage use cases using SSDs and the need for a standard drive-host interface for computational storage drives (CSDs), indicating it wasn’t a question of if but when they become mainstream.
Computational storage aims to overcome the time issue created when data is moved to computation by moving a slice of compute to the data instead. One example of such a time issue would be when reading data from storage into a host server’s memory. There are two main ways to move compute to the data: at the array level and at the drive level.
Array level
It has been tried at the array level with Coho Data, and that attempt failed as there simply weren’t enough use cases to justify the product’s use back in 2017.
Dell EMC’s PowerStore has an AppsOn feature to enable virtual machines to run in the array’s controllers. In theory it can be used to run any workload on the array. We don’t yet know how popular this idea is.
One issue with array-level computation is that the data still has to be read into main memory, controller main memory in this case. There is no need for a network hop to a host server, but data movement distance has only been shortened, not abolished.
Drive level
Drive-level or in-situ computational storage carries out the processing inside a drive’s chassis, with an embedded processor operator almost directly on the data. There are five startups active in this area: Eideticom, NGD, Nyriad, and ScaleFlux. Seagate may also be active.

Typically that adds an Arm processor, memory and IO to a card inside the drive enclosure. Seagate is basing its efforts on the open source RISC-V processor, as is Western Digital. But WD has also invested in NGD, having two CPU irons in the computational storage fire so to speak.

Although WD would not be drawn on any moves on its own part to manufacture CSDs, the potential extent of Western Digital’s computational storage ambitions became evident in a briefing with Richard New. New is VP of Research at the company, and the person who runs WD Labs.
Use cases
New described the features of computational storage use cases using SSDs:
- The application is IO-bound and that needs alleviating.
- No need for significant computation, only a fairly simply compute problem that needs to be done quickly, encryption for example.
- Data needs filtering with a search algorithm. The IOs sent to the host after filtering represent a fraction of the overall data set.
- A streaming data application that needs to touch every byte that is written to the storage device, like encryption and compression.
Other potential applications include image manipulation and database acceleration. New suggested video transcoding is a less obvious application.
In this use case, unless this in-situ processing is transparent to the host server, it needs to know when drive-level processing starts and stops. We need a host-CSD interface.

Host-drive interface
New said there needs to a standard drive-host interface. The NVMe standards organisation is working on such a standard. In fact the NVMe standard is properly known as the Non-Volatile Memory Host Controller Interface Specification (NVMHCIS).
There is an NVMe Computational Storage Task Group, with three group chairpersons: Eideticom’s Stephen Bates, Intel’s Kim Malone, and Samsung’s Bill Martin. The task group’s scope of work encompasses discovery, configuration and use of computational storage features inside a vendor-neutral NVM Express framework. The membership count is greater than 75, with over 25 of these suppliers.
The point of having a standard would be to enable a host server to interact with a CSD. The host system would then know about the status of a CSD and the work it could do. New suggested a general purpose script file could be used. He said: “We need such a standard” to bring about broad adoption of CSDs.
There is also an SNIA workgroup looking into computational storage.
Risc-V
The CSD processor has to be purpose-built and New said: “RISC-V gives Western Digital more flexibility in doing this. You can target specific computational problem types.”
For example you might combine RISC-V cores with ASICs and develop orchestrating software. In New’s view: “You need to optimise for a particular use case.”
We note that Arm processors have to use IP licensed from Arm, whereas RISC-V is open source and free of such restrictions.
Challenges
New mentioned four challenges he thinks stand in the way of broader CSD adoption:
- How do you pass context to the device?
- A file system: how is implemented on the device?
- How can a key be passed to the device to enable it to decrypt already-encrypted data?
- How can it cope with data striped across multiple drives?
We would add the challenge of programming the device. Does it run firmware? Does it have an OS? How is application code developed, compiled or assembled, and loaded onto the device?
New is confident CSD will be adopted: “We believe it will happen but it will take some time for the use cases to be narrowed down and standards to be set.”

Comment
It seems to us at Blocks & Files that a use case justifying CSD development and deployment will have to involve tens of thousands of drives, if not more. Without that, CSDs will never progress beyond being highly customised products sold in low numbers into small application niches.
This use case will involve, say, hundreds of thousands of files or records needing to be processed in pretty much the same way. Instead of a host CPU processing one million records read in from storage, which takes 2 minutes, you would have 1,000 CSDs each processing 1,000 records. The latter would complete in 20 seconds – because there is no data movement. Each CSD tells the host server that it has completed its work and then the host CPU can kick off the next stage of the workflow. It’s this kind of calculation that could drive CSD adoption – if such use cases exist in the real world. Perhaps the Internet of Things sector will help generate them.
If they did, Western Digital could sell tens of thousands of computational storage SSDs. We think it would want to sell hundreds of thousands. B&F does not think that WD will build its own RISC-V-powered CSDs and hope the customers will come. It will surely want to see solid signs of sustained customer adoption of CSDs and an ecosystem of CSD developers before it will start building its own branded CSDs for sale through such an ecosystem.
We are all, like WD, watching the CSD startups to see if they gain traction. They can take most of the “build it and they will come” approach and pain, with WD and pals stepping in after that traction has been demonstrated.