


The OMI serial bus gets more memory near to the CPU than either parallel DDR memory channels or High-Bandwidth Memory (HBM) at HBM speed levels, faster than DDR channels.
That’s the position espoused by a white paper: The Future of Low-Latency Memory, co-authored by Objective Analysis (Jim Handy) and Coughlan Associates (Tom Coughlan) for the OpenCAPI consortium.
The OpenCAPI (Open Coherent Accelerator Processor Interface) was established in 2016 by AMD, Google, IBM, Mellanox and Micron to develop a better way than the DDR channel to connect memory to CPUs. There are several other members, such as Xilinx and Samsung. Intel, notably, is still not a member.
OpenCAPI has developed its OMI subset standard to focus on near memory, that memory which is connected directly by pins to CPUs.
Other CPU-memory interconnect technology developers such as CXL and Gen-Z are banding together around the CXL serial bus, which connects so-called far memory to CPUs, GPU and other accelerators.
That paper’s authors say the OMI alternatives are DDR4, DDR5, and HBM in its current HBM2E guise.
The white paper puts forward the view that the Open Memory Interface (OMI) is superior to DDR4, DDR5 and High-Bandwidth Memory (HBM). Its reasoning is it doesn’t suffer from their limitations, basically lack of bandwidth and capacity with DDR4 and 5, and lack of capacity by HBM. It plots the four technologies in a 2D space defined by bandwidth and capacity, both set in log scales:
The authors say HBM is faster than DDR memory because it has 1,000 to 2,000 parallel paths to the host CPU. But HBM is more expensive than commodity DRAM. It also has a limit of stacks of 12 chips, restricting the capacity it supports. HBM is also, unlike DDR4 and DDR5 DRAM, not field-upgradable.
OMI connects standard DDR DRAMs to a host CPU using high-speed serial signalling and “provides near-HBM bandwidth at larger capacities than are supported by DDR.”
The authors compare and contrast three different CPU-memory interfaces in terms of the die area they consume and bandwidth they deliver, looking at AMD’s EPYC processor with DDR4 DRAM, Nvidia’s Ampere GPU with HBM2E, and IBM POWER10 with OMI. They tabulate their findings and conclude OMI offers the most bandwidth per square millimetre of die area and the highest capacity per channel:
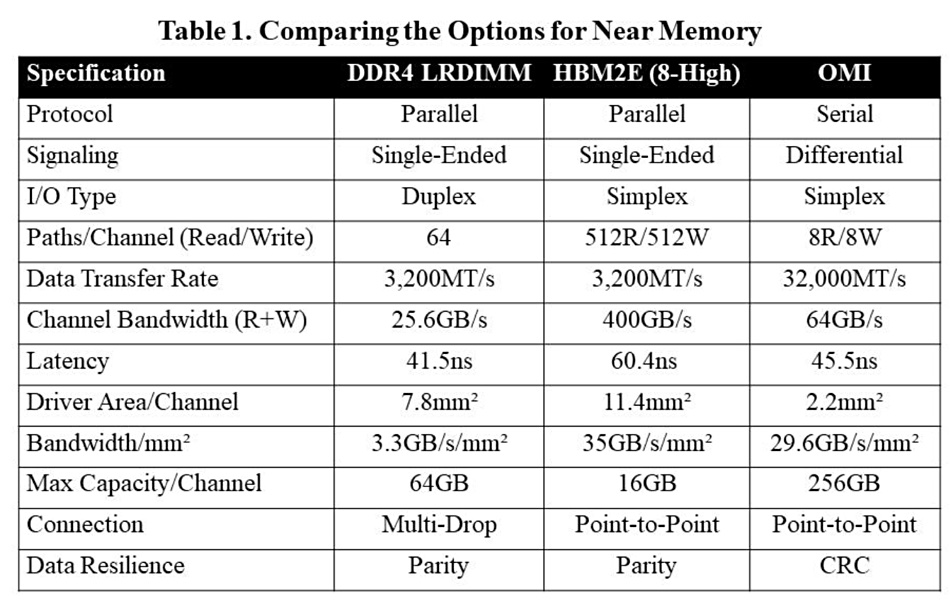
They write: “Each HBM2E channel can support only a single stack of up to 12 chips, or 24GB of capacity using today’s highest-density DRAMs, while each DDR4 bus can go up to 64GB and an OMI channel can support 256GB, over 10 times as much as HBM.”
You can fit “a very large number of OMI ports to a processor chip at a small expense in processor die area.” they write. They add: “OMI does requires a DRAM die to have a transceiver, such as a Microchip Smart Memory Controller, but this is small (30 square millimetres) and doesn’t add much cost to the DRAM.”
They conclude that “OMI stands a good chance of finding adoption in those systems that require high bandwidth, low latencies and large capacity memories. “
However, “DDR should remain in good favour for widespread use at computing’s low end where only one or two DDR memory channels are required. HBM will see growing adoption, but will continue to remain an expensive niche technology for high-end computing.”




