Heat-assisted magnetic recording (HAMR) needs new recording media on disk platter surfaces. One solution is in the works from Seagate, which has partnered with platter and media supplier Showa Denko to develop it.
Of the three disk drive makers, Seagate is the only one which has committed to move to HAMR technology directly from current PMR (perpendicular magnetic recording) technology without using MAMR (microwave-assisted magnetic recording) as a multi-year intermediate step. HAMR media has to withstand repeated high-intensity bit area heating and cooling without degradation.
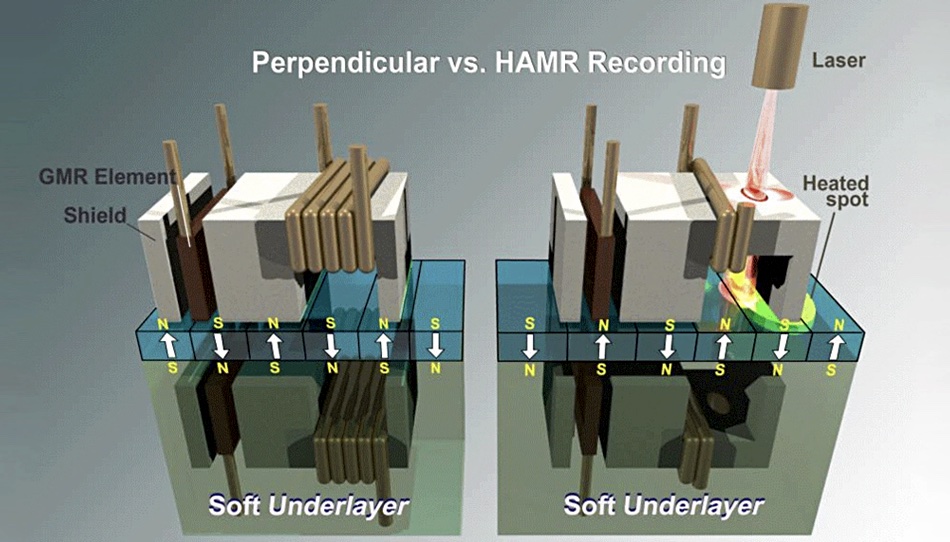
HAMR recording vs PMR
The bit area heating is needed to overcome the resistance or coercivity of the material needed to store magnetic charges in very small bit areas stably over time, at areal densities in the 2TB-plus area per disk platter. PMR media cannot operate reliably at such areal densities.
Showa Denko recently developed a FePt (iron platinum) magnetic material that could provide the ultra-high ordering temperature needed by HAMR. This would be difficult to achieve on the surface of HD media coated with conventional magnetic material. Seagate will evaluate this FePt-based magnetic material, as well as new material to be jointly developed in the future. The two expect their alliance will accelerate the development speed of HAMR-related technologies for both companies.
Up until now Seagate has been relying on HAMR technology created in-house to take its disk drive capacities past PMR’s 16TB–18TB limit, and onwards to 40TB and beyond. It is shipping some 20TB HAMR disks for customer testing, but has not fully committed yet to HAMR technology.
Neither company provided an executive-level statement about their partnership.
Toshiba is sourcing MAMR disk drive platters from Showa Denko, which makes the Japanese firm an important player in the HDD supply chain.
High-end array supplier Infinidat has announced its first all flash array as a higher-performance extension to its existing disk-based InfiniBox line, using the same DRAM-cached architecture and software.
Infinidat has three InfiniBox systems, all rack-based: the entry-level F2300, the F4300 and the high-end F6300. The mid-range F4300 has four 60-drive storage enclosures and triple-active redundant nodes with SSDs used for level 2 caching.
The new InfiniBox SSA (Solid State Array) , the F4304S, is the F4300 modified to have up to 60 SAS SSDs, using TLC NAND, per storage enclosure instead of disk drives.
Phil Bullinger
Infinidat CEO Phil Bullinger said of the established InfiniBox system that it “disrupts conventional all-flash arrays, delivering a unique and very compelling combination of performance, scale, availability and cost for the vast majority of enterprise workloads.” He added: “The InfiniBox SSA now extends our capabilities to meet the most intensive enterprise storage requirements.”
He told Blocks & Files the SSA was not a standard all-flash array (AFA). The Infinidat architecture uses DRAM as a cache to hold data stored in a bulk capacity tier (nearline disk up until now) fetched by its Neural Cache technology. Some 90 per cent of reads, or even more, are served from the DRAM cache, providing better than AFA performance.
With the InfiniBox SSA, the DRAM cache is loaded with data even faster and hence the array is faster still. The disk-based F4300 delivers up to 1.4 million IOPS with 20GB/sec bandwidth while the new F4304S outputs 1.5 million IOPS at sub-millisecond latency with 26.8GB/sec (25GiB/sec on the data sheet) bandwidth.
Infinibox rack.
It supports up to 546TB of usable capacity (1,092TB after data reduction), 2,304GB of DRAM and has 24 x 32Gbits/sec Fibre Channel ports that are NVMe-ready. That suggests a future product development distraction – NVMe drives and NVMe over Fabrics data access.
Bullinger said Infinidat was positioning the F4304S as a higher-performance system for its customers who have stringent low-latency requirements or who may have a blanket AFA requirement. It has been testing the F4304S with customers for six months, he added.
Matt Bieri, Chief Information Officer at Infinidat customer Tyler Technologies, said: “Our most demanding applications, representing about 5 per cent of our workload, require sustained sub-millisecond latency. We’re excited to bring in the InfiniBox SSA, which leverages the same InfiniBox architecture, Neural Cache and feature-set, for these ultra-high performance workloads.”
We were told one Fortune 500 US customer hired a third-party vendor which captured the current customer performance from the current SSA arrays and executed the same profile against multiple storage vendors as well as 3X the profile (for future growth). The customer claimed: “We put the InfiniBox SSA through rigorous testing and compared it head-to-head with the major all-flash array solutions. The InfiniBox SSA surprised us by outperforming every AFA product, achieving 3x the original captured performance with 40 per cent lower latency, even during multiple failure scenarios.”
The InfiniBox SSA is generally available today and you can download a product datasheet.
Cloud-native storage startup Robin.io has gained $38m in VC funding to continue its push into enterprise storage and 5G edge setup automation.
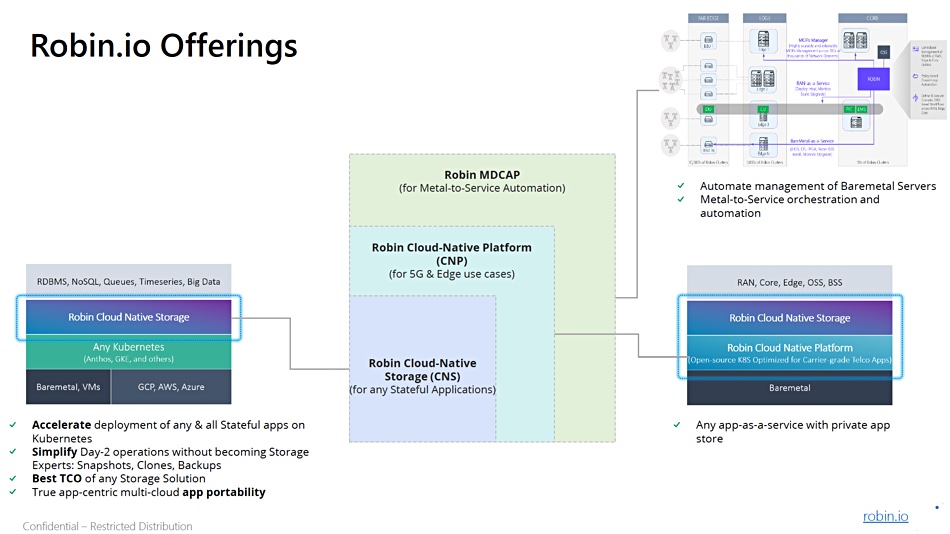
Robin.io is different from other players punting storage software for Kubernetes-orchestrated containers, as it provides its app-aware Cloud-Native Storage (CNS) packaged up a Cloud-Native Platform (CNP) and integrated with networking functionality for telcos. It has also added bare metal server management and edge network setup orchestration (MDCAP) for 5G radio area network (RAN) operators.
Partha Seetala, founder and CEO at Robin.io, provided an announcement quote: “The accelerating adoption of Kubernetes and cloud-native technologies, as well as the accelerating pace of global 5G and edge rollouts, has provided the backdrop for Robin’s competitive success in the past year. … Robin.io … will continue to invest in product leadership and hire talent across sales, engineering and tech support functions. This Series C round is perfectly timed to support these goals.”
This C-round was led by Rakuten Capital, joined by Clear Ventures, Emory University, Raine Next-Gen Communications and current investors. It brings the total capital raised by Robin.io to $86m. Rakuten is heavily involved in 5G activities. It has a cloud-native 4G/5G network and is co-developing a 5G core system with NEC.
Robin.io product positioning diagram
Bookings growth at Robin has surged 681 per cent in its current quarter from a year ago, and it has signed 32 new partnerships during the past year. One of those partnerships is with Quanta Cloud Technology (QCT), a global data centre solution provider, through which the companies will jointly offer solutions to reduce costs, complexities and deployment times for mobile network operators (MNOs) and communication service providers (CSPs) rolling out 5G networks and services.
Robin’s headcount has risen by 57 per cent during the year, across four countries. The new cash will help with product development and business infrastructure expansion — even more partnerships possibly.
Comment
A ReTHINK RAN research document, Patterns of migration to the 5G core, states: “The 5G core will enable capabilities such as ultra-low latency and will be implemented as microservices, which allow network resources to be scaled up and down on-demand to suit the needs of individual services or users, and enables the operator to create virtual ‘slices’ of the network, optimised for the needs of a particular sector, enterprise or use case.“
In other words, the 5G network software will be based on containerisation technology.
Robin says MDCAP automates healing and scaling in 5G deployments and enables RAN-as-a-Service, Core-as-a-Service, BareMetal-as-a-Service and a MOPs Manager that automates thousands of tasks with one API call.
We think Robin.io has built a massive telco 5G wireless area network set-up automation infrastructure (MDCAP) from its base of cloud-native storage, giving it a near-impregnable moat against competitors providing Kubernetes storage to 5G-adopting telcos.
It’s this position and momentum that’s exciting Rakuten Capital and the other VCs.
Veritas has upgraded its NetBackup product to v9.1, adding anti-ransomware protection for containerised environments, S3 immutability, and anomaly detection, plus adding a Flex 5350 appliance with data immutability and faster performance.
It says it is folding Artificial Intelligence and Machine Learning-driven anomaly detection into NetBackup as an inclusive feature to alert backup admins of potential issues and ensure data is always recoverable.
Doug Matthews, Veritas’ VP of Product Management, said in a prepared quote: “Our newest NetBackup release further [protects] customers against increasingly prevalent ransomware attacks, irrespective of where their data resides: cloud, containers or on-premises.”
Veritas claims its Flex 5350 appliance has 300 per cent improved backup performance, delivers 40 per cent lower total cost of ownership, twice the performance and twice the capacity of its closest competitor, which is Dell EMC’s DD9000.
Veritas video – product management VP Doug Matthews talks about the new release.
The details
NetBackup now offers:
Continuous Data Protection and Instant Rollback capabilities, enabling VMware users to recover from ransomware and other events in minutes instead of hours;
Multiple service level objectives — starting with VMware but eventually expanding to any application, organisations can define and automatically execute multiple service level objectives, including the recovery technique (eg, recover from backup, recovery from replication, etc.) and data, for each application;
Extended Write Once Read Many (WORM) storage to AWS S3 cloud environments, using ObjectLock;
Native protection across multiple Kubernetes distributions and layers including clusters, namespaces, custom resources and persistent volumes;
Support for Red Hat OpenShift, VMware Tanzu and Google Kubernetes Engine, with support for additional Kubernetes platform distributions to follow;
Cost-effective ransomware resilience in the cloud by automatically provisioning/de-provisioning cloud resources as needed, ensuring backups do not fail due to insufficient resources, while managing costs;
Policies to automatically protect new workloads as they come online — avoiding data protection gaps;
NetBackup transport security layer improvement, making data movement to the cloud 20 per cent faster;
New cryptographic encryption across all data transports including replication, backup and recovery and deduplication.
Dell EMC has introduced cybersecurity features into CloudIQ, its AIOps application for Dell EMC IT infrastructure products.
CloudIQ supports PowerMAX, PowerStore, PowerScale, PowerProtect, VxBLock, VxRail, as well as older arrays and filers such as Isilon, PowerVault, Unity, SC, VMAX, and XtremIO, plus APEX storage and Connectrix switches. The latest iteration adds CloudIQ cybersecurity using machine learning, and assesses security status as well as an array’s performance, capacity and general health.
We saw a pre-publication blog by Greg Findlen, VP Product Development, Engineering, for Dell Technologies, which reads: “We’ve implemented cybersecurity with the kind of proactive monitoring, notification, and recommendation capabilities that CloudIQ provides to system administrators for addressing infrastructure health, performance, and capacity issues.”
CloudIQ cyber security checks if an IT infrastructure is appropriately hardened — ie, that security configurations adhere to an IT team’s set policy, notifies IT/security specialists of misconfigurations, and recommends actions to make data storage safer.
CloudIQ UI on notebook computer.
FIndlen writes that Infrastructure policies regarding role-based access control, default administrative passwords, data at rest encryption enabling, and NFS security levels are foundational to what he terms infrastructure hardening. Misconfiguring an infrastructure can leave gaping holes for attackers.
Layered security elements on this foundation may include network micro-segmentation, firewalling, incident detection and protection. He suggests using VMware NSX for the network aspect and Carbon Black for incident detection/protection.
He blogs: “Our security engineering team has programmed CloudIQ to continuously evaluate infrastructure security misconfigurations and provide recommendations for remediation.
“You initiate CloudIQ to collect and store your systems’ cybersecurity data via a secure Dell Technologies network; you choose the security configurations to define your policy, and CloudIQ evaluates the data, notifies you of misconfigurations and what to do about them.”
CloudIQ initially supports cybersecurity for PowerStore and PowerMax storage systems, and it’s planned to expand its cybersecurity coverage across Dell’s infrastructure systems portfolio.
We understand CloudIQ is restricted to evaluating Dell Technologies’ products — fine in a homogenous Dell Technologies environment, but no help outside it.
Comment
Adding security policy adherence to a storage array/HCI performance, capacity and status checking service is a simple enough idea. It requires additional telemetry from the monitored systems and provides a so-called closed loop system. It can’t check if attackers using stolen credentials are accessing the monitored systems, but it can check if the security basics are in place — like making sure the office door is locked when you are away.
Over time the capabilities can be extended to more systems and integrated with upstream security systems through supplier partnerships — Virtana for example, or Cisco Intersight and AppDynamics. Dell says CloudIQ is an AIOPs product, and AI-based Security Ops (AISOps?), looking beyond Dell kit confines, would seem a logical and useful extension — particularly in this ransomware pandemic period.
It’s a good market to be in. IDC has increased its disk drive and SSD revenue and capacity forecasts for the 2020–2025 period, citing increased demand pretty much across the board.
The pandemic’s easing is freeing pent-up demand but, basically, the world is creating more data and wants to store it (disk drives) and access it faster (SSDs).
Jeff Janukowicz, Research VP for Solid State Drives and Enabling Technologies at IDC, said “Worldwide SSD units and capacity shipped are higher than the prior forecast thanks to increasing demand from client devices, enterprise storage customers, and cloud service providers.”
His IDC colleague Edward Burns, Research Director, Hard Disk Drive and Storage Technologies, said “While the client HDD market continues a long-term secular decline due to rising SSD attach rates, the COVID-19 pandemic has over the near term increased the demand for certain types of HDDs, particularly mobile HDDs as well as capacity-optimised HDDs. And the demand for storage capacity continues to grow at a steady pace as the world creates and stores more and more data.”
Worldwide SSD unit shipments will increase at a 2020–2025 compound annual growth rate (CAGR) of 7.8 per cent and revenue will grow at a CAGR of 9.2 per cent over the same period, reaching $51.5 billion in revenue by 2025. SSD capacity shipments are expected to grow at a 2020–2025 CAGR of 33.0 per cent as IDC expects ongoing price erosion in the long-term SSD pricing outlook.
Worldwide HDD industry petabyte shipments are expected to see a CAGR of 18.5 per cent over the 2020–2025 forecast period, and average capacity per drive is forecast to increase at a five-year CAGR of 25.5 per cent.
SSD details
The Worldwide Solid State Storage Forecast, 2021–2025 IDC report says that, over the forecast period:
SSD pricing remains volatile and elevated in the near term. Technology advancements in NAND flash (more layers) will lower costs helping to send demand higher.
Client SSD demand is significantly higher than previously forecast as work- and school-from-home trends have strengthened portable PC demand.
Near-term demand for enterprise SSDs remains strong in both cloud and on-premises market.
Lower prices will drive demand elasticity, and system optimisation around flash, coupled with digital infrastructure modernisation, and expanding cloud-centric architectures, will continue to provide ongoing secular demand for SSDs.
HDD details
According to The IDC report, Worldwide Hard Disk Drive Forecast, 2021–2025:
Petabyte demand from OEM storage customers will be higher for 2021 due to an on-premises data centre budget increase and business reopening trends.
Demand from cloud service providers and hyperscale customers will be strong, with petabytes growing at a CAGR of 31 per cent through 2025.
It’s pretty much all good news for disk drive and SSD suppliers — customers want more of their products between now and 2025. What’s not to like?
Disk drive and SSD maker Western Digital is entering the server business with two specialised transportable systems for edge deployments.
It’s made embedded server storage systems already, in the form of home NAS boxes, but these new Ultrastar Edge servers are business products placed at the edge of the incumbent server vendors’ turf — meaning Dell, HPE, Lenovo, et al.
Kurt Chan, Western Digital’s VP for Data Centre Platforms, said in a statement: “The growth in data creation at the edge, the opportunities to extract value from that data, and the total available markets and customers innovating and doing work at the edge, gives us a great opportunity for our new Ultrastar Edge server family.”
WD is building two server systems:
Ultrastar Edge — transportable 2U rack-mountable server with a portable case for colos and edge data centres;
Ultrastar Edge-MR — an extremely rugged, stackable and transportable server for military and specialised field teams working in harsh remote environments.
WD organised a supporting quote from Manoj Sukumaran, Senior Analyst, Data Center Compute, at Omdia: “We expect server deployments at edge locations to double through 2024, totalling an estimated five million units, as they are an essential component in enabling new innovations and products, cloud services, remote campuses, CDNs, and virtually any vertical industry that relies on IoT, sensor or remote data.”
Ultrastar Edge server.
The base Ultrastar Edge product has 2x Xeon Gold 6230T CPUs, 2.1GHz, each with 20 cores, an Nvidia Tesla T4 GPU, and 8x 7.68TB Ultrastar DC SN640 NVMe SSDs providing up to 61TB of storage. It has two 50Gbit/s or one 100Gbit/s Ethernet connection, so it can be hooked up to a data centre or public cloud when connected. These features make the product basically fast and capable of use for real-time analytics, AI, deep learning, ML training and inference, and video transcoding at the edge of an IT network.
Ultrastar Edge MR.
The Ultrastar Edge-MR is the Edge packaged as a rugged, stackable device, designed and tested in accordance with MIL-STD-810G-CHG-1 standards for limits of shock and vibration, and to the MIL-STD-461G standard for electromagnetic interference. It has the same pair of 2x gen-2 Xeon SP CPUs with up to 40 cores, a T4 GPU, 512GB of DRAM, and dual 10GBase-T RJ-45 ports plus a Mellanox ConnectX-5 100GbE QSFP28 port. These come inside a hardened box which is rated IP32 for protection against incoming water and debris.
All in it weighs 71.1lbs (32.25kg) — a heavy thing to lug about. WD is envisaging it being used for analysing data during oil and gas explorations, doing research in the Amazon, or in military operations far away from any server closet.
Both Ultrastar Edge products feature the Trusted Platform Module 2.0, a tamper-evident enclosure, and are built to meet the FIPS 140-2 Level 2 security standard.
Asked why WD was getting into server market, a spokesperson said “Western Digital provides JBODs and JBOFs to xSPS, OEM and channel customers. As the centralised cloud has evolved to the edge, our xSP customers have looked to us to provide specialised servers for data transport and edge capture and compute that leverage our vertical integration capabilities and meet unique requirements that traditional, whitebox servers don’t satisfy.”
Will Western Digital use RISC-V processors in its servers? “The current Ultrastar Edge family is Intel-based. We are exploring other alternatives including AMD as well as RISC-V, especially for custom designs, and we’ll continue to use Arm when that makes the most sense.”
You can read an ‘Edgy’ blog and get an Edge datasheet here and an Edge MR datasheet here.
Both Ultrastar Edge servers are sampling now and orderable, with general availability beginning c.Q4 2021.
Big beast Intel has come crashing out of the semiconductor jungle into the Data Processing Unit gang’s watering hole, saying it’s the biggest DPU shipper of all and it got there first anyway.
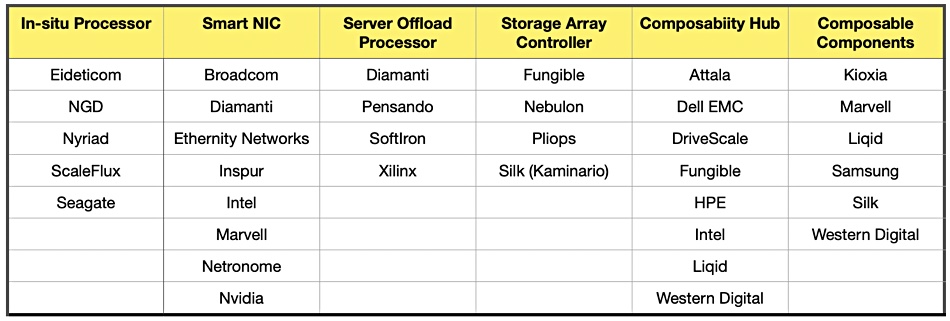
Data Processing Units (DPUs) are programmable processing units dedicated to running data centre infrastructure-specific operations such as security, storage and networking — offloading them from existing servers so they can run more applications. DPUs are built from specific CPU chips, FPGAs and/or ASICs by suppliers such as Fungible, Nvidia, Pensando, and Nebulon. It’s a fast-developing field and device types include in-situ processors, SmartNICs, server offload cards, storage processors, composability hubs and components.
B&F DPU suppliers’ category table.
Navin Shenoy, Intel EVP and GM of its Data Platforms Group, said at the Six Five Summit that Intel has already developed and sold what it called Infrastructure Processing Units (IPUs) — what everyone else calls DPUs. Intel designed them to enable hyperscale customers to reduce server CPU overhead and free up cycles for applications to run faster.
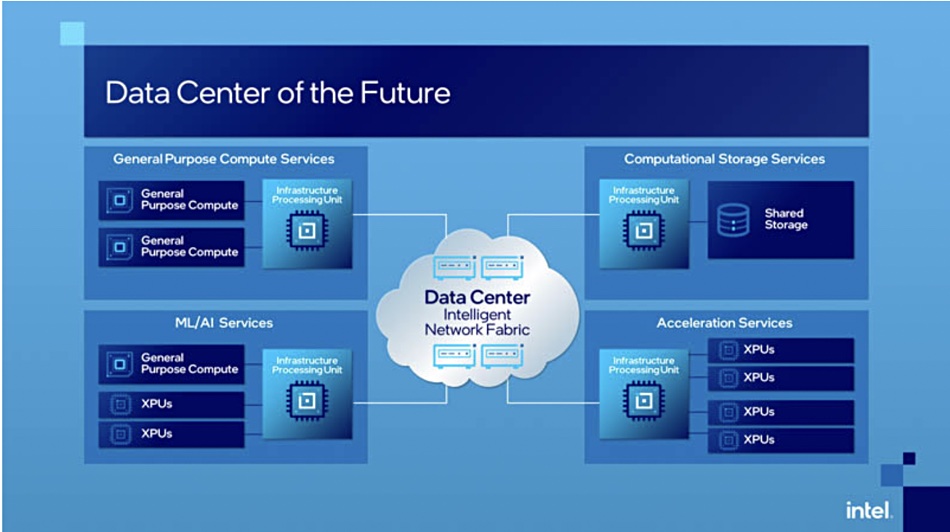
Guido Appenzeller, Data Platforms Group CTO at Intel, said in a statement: “The IPU is a new category of technologies and is one of the strategic pillars of our cloud strategy. It expands upon our SmartNIC capabilities and is designed to address the complexity and inefficiencies in the modern data centre.”
Intel slide.
An IPU, he said, enables customers to balance processing and storage, and Intel’s system has dedicated functionality to accelerate applications built using a microservice-based architecture. That’s because Intel says inter-microservice communications can take up from 22 to 80 per cent of a host server CPU’s cycles.
Intel’s IPU can:
Accelerate infrastructure functions, including storage virtualisation, network virtualisation and security with dedicated protocol accelerators;
Free up CPU cores by shifting storage and network virtualisation functions that were previously done in software on the CPU to the IPU;
Improve data centre utilisation by allowing for flexible workload placement (run code on the IPU);
Enable cloud service providers to customise infrastructure function deployments at the speed of software (composability).
Patty Kummrow, Intel’s VP in the Data Platforms Group and GM of the Ethernet Products Group, offered this thought: “As a result of Intel’s collaboration with a majority of hyperscalers, Intel is already the volume leader in the IPU market with our Xeon-D, FPGA and Ethernet components. The first of Intel’s FPGA-based IPU platforms are deployed at multiple cloud service providers and our first ASIC IPU is under test.”
The Xeon-D is a system-on-chip (SoC) microserver Xeon CPU, not a full-scale server Xeon CPU. Fungible and Pensando have developed specific DPU processor designs instead of relying on FPGAs or ASICs.
There are no DPU benchmarks, so comparing performance between different suppliers will be difficult.
Intel says it will produce additional FPGA-based IPU platforms and dedicated ASICs in the future. They will be accompanied by a software foundation to help customers develop cloud orchestration software.
Flux control MAMR gives Toshiba two more real density increase generations from current disk drive recording technology without having to develop a new recording medium.
Toshiba found that fully reversing the direction of a spin torque oscillator, intended for use with MAMR technology, actually made conventional recording more efficient — providing a 20 per cent areal density gain.
Toshiba Electronics Europe senior manager Rainer Kaese briefed Blocks & Files on its Flux Control – Microwave Assisted Magnetic Recording (FC-MAMR) technology, adding clarity and numbers to the picture we had worked out from reading a Toshiba research paper.
He said FC-MAMR “was an easier leap; an intermediate step,” to full MAMR.
Current perpendicular magnetic recording technology (PMR) was, Toshiba thought, going to run out of areal density increase possibilities after it achieved a 16TB nine-platter MG08 drive. The bits in the recording medium would have too weak a magnetic signal if they became smaller to increase the platter capacity. This signal would be hard to read (poor signal to noise ratio) and be unstable.
This was the reason Toshiba, like Western Digital, planned to move to Microwave Assisted Magnetic Recording (MAMR) technology which has two technology thrusts: first, a more stable magnetic recording medium would be developed that could sustain smaller bit areas; and second, because it was then harder to write bits, microwaves would be fired at the bit area to overcome the higher-than-PMR write resistance (coercivity).
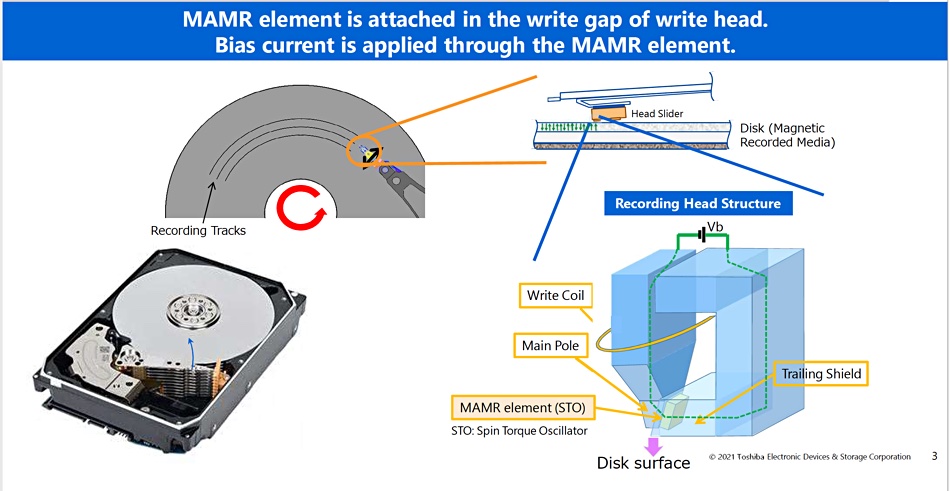
This requires a microwave-generating spin torque oscillator (STO) device, activated by a bias current, to be added to the drive’s read/write heads to enable the smaller bits to be written. However, there was an unanticipated effect and benefit.
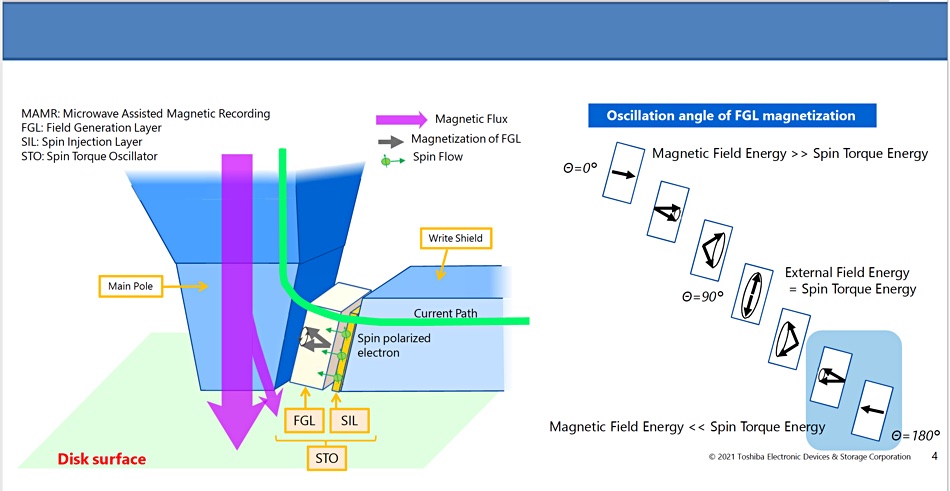
MAMR head in nearline hard disk drive.
A MAMR-equipped write head has a main writing pole which projects magnetic energy or flux (purple arrowed line on diagram above) at the platter recording medium when it needs to write a bit. There is a space between the main pole and a trailing shield. The tiny STO is inserted into this space. The STO has two components: a microwave Field Generation Layer (FGL) and a Spin Injection Layer (SIL), which are shown in another Toshiba diagram (see below).
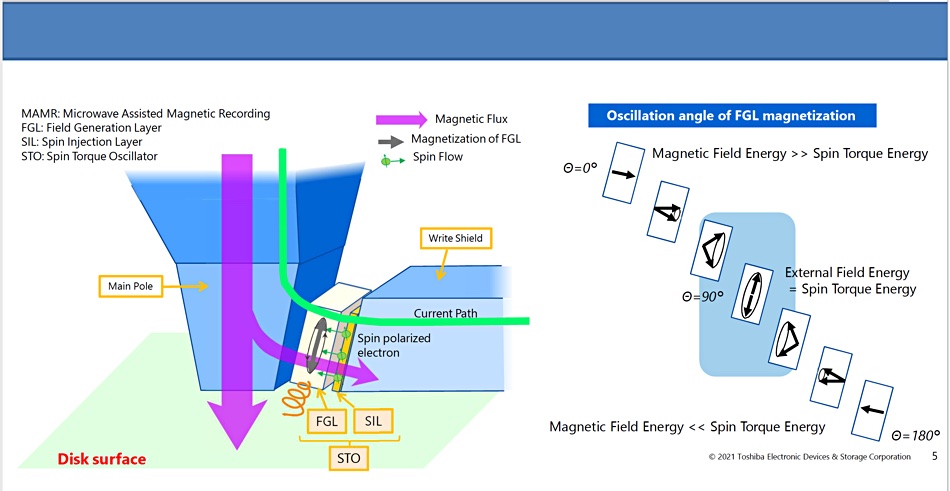
The FGL produces magnetisation using spin torque energy — incoming spin-polarised electrons from the SIL. The resulting magnetic field energy has an oscillation angle (characterising its flux) which varies from zero to 180° and onwards. At 0° (no oscillation) the energy flows in a straight line. At 45° it oscillates around a central point in a circle but points in the same general direction. At 90° it oscillates up and down a central point with a 90° separation between the 0° line and new line. This is the desired MMR state as the diagram illustrates below, and causes the STO to fire microwaves (orange spiral line) at the target bit area.
How Microwave Assisted Magnetic Recording (MAMR) works.
This diagram shows magnetic flux (purple line) plunging down into the platter recording medium from the write head, with a side flow through the microwave-producing STO into the Write Shield.
But, at a 180° oscillation angle the STO’s magnetic field energy flows in a straight line again and in a reverse direction to the 0° line. This is the key effect that the Toshiba research engineers detected and it, crucially, causes the strength of the write head’s magnetic flux to be increased (shown as an allied purple line in the diagram below).
How Flux Control (FC) MAMR works.
The STO produces no microwaves in this case, but they are not needed as this flux control effect can produce a 20 per cent increase in areal density beyond the 16TB, nine-platter reference level with existing PMR recording. Bits are written more strongly with FC-MAMR and can be made smaller without overwhelming the bit signal with surrounding noise.
Toshiba has used this FC-MAMR technology to produce its18TB, nine-platter MG09 disk drive and Kaese implied a 20TB follow-on product successor is coming; possibly to be called, we think, an MG10.
To go beyond the 20TB areal density level, Kaese said, full MAMR will be needed, with a new recording medium having to be developed.
He said full MAMR has the potential to have a more then 200 per cent areal density uplift on the 16TB, nine-platter reference level disk; a 3X or so increase to 48TB–50TB disk drives. Kaese pointed out: “We do not see any obstacle to this.”
Comment
Western Digital has also produced a part-MAMR drive — the 18TB UltraStar HC550 — saying it uses ePMR technology. The technology, a Western Digital document states, “applies an electrical current to the main pole of the write head throughout the write operation. This current generates an additional magnetic field.” WD uses the unit to reduce write signal jitter and so produce a better written bit. That sounds pretty similar to the outcome of Toshiba’s bias current/STO technology.
Seagate, with its Heat-Assisted Magnetic Recording (HAMR) technology, has no similar intermediate step from current PMR to HAMR, and thus is denied the production cost comfort of having lower-cost intermediate staging steps before going into full energy assistance.
New things are the theme of this week’s roundup, with DNA storage prospects explained in a white paper, and IDC setting up a software-defined infrastructure tracking report. These are accompanied by the usual backdrop of data protection, storage array, go-to-market, product and customer developments.
DNA storage white paper
DNA storage developers want us to know that the technology is really, really, no, really, really, really good, and that it is possible, too. DNA storage is no over-hyped Magic Leap type of technology, no sir … although it is, of course, ahem, a magic leap.
The DNA Data Storage Alliance has published a white paper entitled “Preserving our Digital Legacy: An Introduction to DNA Data Storage.”
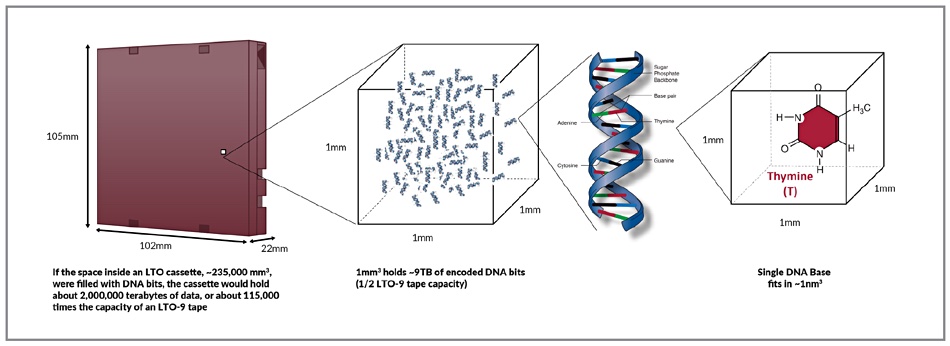
DNA storage diagram.
The gee-whiz capacity density of DNA storage is illustrated by taking the space taken up by an 18TB raw capacity LTO-9 tape cartridge and imagining it full of DNA storage. It would hold about two million TB, which the DNA buffs say is about 115,000 times the capacity of the LTO-9 tape. This DNA storage would be stable, they say, for thousands of years.
The founding DNA Storage alliance members are Twist Bioscience Corp., Illumina, Inc., and Western Digital with Microsoft Research. They say DNA’s structure means that any generation of DNA readers and writers will be able to read and write DNA as long as the bit encoding formats are saved.
Steffen Hellmold, WD’s Corporate Strategic Initiatives VP, said “The density and stability of DNA storage will help the industry cost-effectively cope with the expected future growth of archival data for many decades to come.”
That’s certainly possible, but current DNA Storage write to read latency — under 2bits/hour in a Microsoft and University of Washington demo system (five bits in 21 hours) — needs to be accelerated by many orders of magnitude. Writing DNA Storage bits is a complex bio-chemical process and commercialisation is years away.
We should be optimistic. The white paper declares: “DNA will enable storage capacity on a scale never imagined, let alone considered economically viable, compared to today’s storage technologies.”
It’s a fascinating read. Download the white paper here; no registration required.
IDC software-defined infrastructure
IDC has defined a new software tracking category — software-defined infrastructure — and set up a semi-annual tracker report. It includes three elements in its SFDI revenue numbers:
Software-defined compute software (53 per cent of market value);
Software-defined storage controller software (36 per cent of market value);
Software-defined networking software (11 per cent of market value).
Software-defined compute means virtualised compute nodes and includes virtual machine software (i.e., hypervisor software), container infrastructure software, and cloud system software. Software-defined networking means network virtualisation overlays and SDN controllers used in data centre networks.
Software-defined storage covers a storage software stack delivering a full suite of storage services in conjunction with COTS hardware to create a complete storage system.
IDC Research VP Eric Sheppard issued a statement, saying “Software-defined infrastructure is rapidly becoming the platform of choice for data center modernisation and transformation undertakings all around the world.”
The company publicly revealed only the briefest of summary data, saying the worldwide SDI software market reached $12.17B in calendar 2020, an increase of five per cent year on year.
We query the utility of a single report covering software-defined compute, storage and networking that probably basically says VMware rules the software-defined world — but IDC must have tested the concept and believes it has customers willing to pay for this new tracker.
Shorts
Data protector Acronis released an email protection pack for Acronis Cyber Protect Cloud that uses Perception Point. It’s for MSPs and is claimed to detect and stop all email-borne cyberthreats before they can reach their clients’ Microsoft 365, Google Workspace, or Open-Xchange mailboxes. It scales to cover 100 per cent of the email traffic and shortens the scanning time to a maximum of 30 seconds.
Cobalt Iron’s SaaS-based Compass backup and anti-ransomware offering has entered IBM’s Passport Advantage program. IBM sellers, partners, and distributors around the world can sell Compass under IBM part numbers. Compass integrates with, automates, and optimises IBM Spectrum Protect, FlashSystem, IBM Cloud, and IBM Cloud Object Storage.
Commvault has announced enhanced Managed Service Provider (MSP) and Aggregator Partner Advantage Programmes. There are two MSP tiers with identified tier promotional requirements and incentives, rewarding partners for driving consumption. Commvault plans to add Metallic for MSPs to its Partner Advantage Programme later this year.
FileCloud has announced v21.1 of its FileCloud cloud-agnostic enterprise file sync, sharing and data governance software product. It is 66 per cent faster than before and Microsoft Office sensitivity labels are automatically extracted into FileCloud. There is a new interface and log-in wizard for FileCloud, along with complete keyboard shortcuts.
One reason HPE’s Alletra 6000 is so much faster than the Nimble array it was based on is because it uses AMD Epyc 7252, 7302, 7502 or 7742 series processors with 8 to 64 cores. This is twice as many cores per socket as the existing Nimble arrays. Combine that with 128 lanes of PCIe 4 and Alletra customers get faster storage performance.
Semiconductor supplier Marvell reported Q1fy2022 (ended May 1, 2021) results with revenues up 20 per cent year on year to $832M and a loss of $88.2M. Matt Murphy, Marvell’s President and CEO, said “Marvell’s outlook for strong revenue growth in the second quarter highlights robust demand across all our key end markets. I have never felt stronger about our prospects and believe that we are at the beginning of a multi-year growth cycle.”
HCI vendor Scale Computing has signed up KSG to distribute its all NVMe-flash and Intel NUC-based HE150 edge computing appliance in Japan. The HE150 takes up the same physical space as three smartphones and doesn’t need a rack infrastructure or server closet.
Promise Technology has announced a four rack unit, 60-bay VTrak J5960JBOD (Just a Bunch Of Drives) with up to 8PB of raw capacity in eight enclosures with 18TB HDDs, claiming this to be a new JBOD unit expansion record. It’s said to be eco-friendly and designed for high-performance data center and enterprise applications. A single unit can deliver 16GB/sec from 60 HDDs and 23 GB/sec from 60 SSDs.
Scality’s cloud-native ARTESCA object storage software product is available on the VMware Marketplace.
SMART Modular Technologies has announced T5PFLC FIPS 140-2 SSDs which provide certified authentication, sophisticated encryption, and are available in capacities from 120GB to 2TB. FIPS 140-2 is a National Institute of Standards and Technology (NIST) standard that outlines a set of security criteria to enable the safe handling of sensitive information, and is a requirement for all US Federal government applications as well as most other high-security applications.
Virtual SAN provider StorMagic has a Container Storage Interface (CSI) environment for SvSAN, to provide persistent storage for Kubernetes-orchestrated containers. The CSI driver allows remote sites to deploy containers at the edge with affordable, persistent storage, combined with SvSAN’s no single point of failure architecture.
It claims customers can deploy a two-node, centrally-managed cluster that supports both virtual machines (VMs) and containers specifically designed for edge environments, at the market’s lowest cost.
Research house TrendForce predicts DRAM prices will rise further by three to eight per cent quarter on quarter for 3Q21. It has also increased the magnitude of the predicted quarter on quarter increase in NAND Flash prices for 3Q21 to three to ten per cent (compared with the previous projection of three to eight per cent). This is due to the growing demand for enterprise SSDs and NAND Flash wafers
Long-distance data access accelerator Vcinity has appointed Craig Graulich as SVP of Worldwide Sales, reporting to CEO Harry Carr. Graulich was previously at Hitachi Vantara Federal. It also appointed Andrew Parsons as its Chief Strategy Officer, also reporting to Carr. Parsons was previously at HPE and led service provider/telecommunication strategy and go-to-market for North America.
Customers
The University of Minnesota’s Supercomputing Institute (MSI) has bought 10PB of Panasas ActiveStor Ultra parallel-access storage for its high-performance computing (HPC) system. It’s been a Panasas customer for 13 years. MSI is also buying 5PB of HPE-built capacity for its Ceph-based tier-2 storage.
Lee University has implemented Tintri VMstore for its Virtual Desktop Infrastructure (VDI) and virtual server environments, backup and replication-based disaster recovery. Lee University is a private university in south-eastern USA and maintains sixteen computer labs that use VDI, providing software services to thousands of students and faculty.
Quantum has taken the ActiveScale object storage business it bought from Western Digital and given it a significant upgrade with new hardware and software.
Via the acquisition it obtained entry-level modular P100 and X100 rack-scale cabinets full of 14TB drives, and ActiveScale v5.5 software with NFS file and S3 object performance balancing using an Amplidata software base. The X100 supported 8.2PB per rack and could scale to 45 billion objects.
The intent is to develop an everlasting archive system with massive capacity. Quantum execs told an IT Press Tour virtual briefing that it was already shipping its new ActiveScale X200 platform with v6 ActiveScale software. It claims the X200 has 78 per cent more capacity, 7x performance, and a 6x object count increase per rack – a total of 270 billion – compared to the X100.
Architecturally, ActiveScale 5 and the X100 had separate access nodes and data storage chassis, allowing for separate scaling but entailing configuration complexity. Now the two software control planes run on the same server/storage system base.
X200 hardware
A datasheet says the X200 comes in a 12 rack system with up to 4.86PB base capacity, and a box shot on Quantum’s website shows a 3-unit enclosure labelled “X200 4U90 Twin Server.” In other words the 12U chassis is composed of a 3 x 90-bay 4U sub-chassis. A quick bit of math shows that 270 x 18TB disk drives are being used to reach the 4.86PB base raw capacity.
Three of these 12U boxes can fit into a standard rack, implying a per-rack capacity of 14.6PB, exactly 78 per cent more than the X100 as Quantum says.
We asked if shingled media was being used, and Bruno Hald, Quantum’s Secondary Storage GM, said it was not.
Note that Supermicro’s 90-bay top-loading storage server looks exactly the same as a 4U X100 component chassis from the front, minus its Supermicro logo, of course.
Supermicro 90-bay top loading storage server.
We surmise Quantum is using these Supermicro components in the X200. They support 90 SAS or SATA drives with up to six slots for NVMe SSDs, and up to two third-gen Intel Xeon Scalable Processors for controllers.
Quantum doesn’t provide numbers for the maximum scaled-out X200 capacity nor the total number of objects supported; both are said to be effectively unlimited.
We asked if Quantum was looking to use SSDs as a fast access capacity object storage medium. Hald said: “We are looking at SSD object storage as a possibility [but] we are not being pushed in that direction by our customers.”
ActiveScale currently uses flash storage for its access layer data (metadata) and disk storage as the data layer repository.
ActiveScale 6 software
The v6.0 software has up to 19 nines of data durability. Quantum is positioning ActiveScale as an everlasting archive system and these durability numbers are appropriate for that role.
Objects are chunked, and data can be dispersed across three geographic locations and use Quantum’s dynamic data placement (DDP), a form of erasure coding. There is ongoing background object monitoring and repair. All this provides continuous data availability and operations even with a full data centre outage.
The software provides immutability with object locking and sustained performance with large or small files and objects, or a mix of these.
The v6 ActiveScale software is sold with a capacity-based subscription license.
We understand that Quantum’s acquired CatDV tagging software will be integrated with ActiveScale, and also that CatDV tag information could be used to generate object metadata.
Check out the ActiveScale datasheet to find out more.
IDC’s beancounters reported a small 1.7 per cent rise in enterprise external OEM storage systems revenues in 2021’s first quarter, to $6.7bn from $6.57bn the year before. But it was growth after a year of decline.
We also note that it still hasn’t gained enough ground to recover to sales levels seen in Q1 2019, which were $6.85bn.
This is rather lower than the 12 per cent rise in server revenues IDC has reported over the same period. Perhaps a heralded increase in server-based storage is taking place; we’ll have to wait for IDC’s hyperconverged infrastructure (HCI) revenue tracker to get more information.
According to the IDC Worldwide Quarterly Enterprise Storage Systems Tracker, total external storage capacity (external OEM + ODM direct + server-based storage) shipped was up vastly more, 20.6 per cent Y/Y to 118.8 EB. The $/TB cost must have fallen substantially Y/Y.
Storage revenues generated by original design manufacturers (ODMs) selling directly to hyperscale data centres grew at 14.1 per cent Y/Y to $5.6bn and involved 70.2EB of capacity. This means that public clouds and Facebook-like businesses accounted for 84.6 per cent of the storage revenues, leaving just 15.4 per cent for on-premises data centres.
Zsofia Madi-Szabo, IDC’s research manager, Infrastructure Platforms and Technologies, issued a statement saying: “After four quarters of market contraction, the first quarter of 2021 represented an important moment of recovery for the external storage systems market.”
The analyst noted that the total All Flash Array (AFA) market generated $2.7bn in the quarter, down 3.3 per cent Y/Y. The Hybrid Flash Array (HFA) market was worth nearly $2.5nn and increased 1.4 per cent from the year ago quarter.
It seems to Blocks & Files that disk drive and hybrid flash/disk storage revenues provided the growth in the market – and not flash. In other words, buyers prized capacity over access speed..
Madi-Szabo said: “Geographic results for the external enterprise storage market were mixed. Asia/Pacific and EMEA lead the recovery with 11.5 per cent and 4.9 per cent respective increase in spending, while sales within the Americas fell by 5.4 per cent during the quarter. Clearly it is going to take time for the global enterprise storage market to fully recover from the substantial negative impacts of COVID-19.”
The top five supplier rankings were:
Dell – $2.16bn with 32.3 per cent of w-w revenues
NetApp – $728.9m and 10.9 per cent of revenues
HPE – $626.9m and 9.4 per cent
Hitachi – $390.5m and 5.8 per cent
Huawei – $365.1m and 5.4 per cent
We have updated our historical chart of IDC external OEM storage revenues to add the 1Q21 numbers:
Dell still rules the supplier roost with NetApp in second place, having overtaken HPE and Huawei which were numbers 2 and 3 last quarter.
NetApp’s Q1 storage revenues seasonally exceed those of HPE and did so in 2020, 2019, 2018 and 2017. In each year HPE revenues subsequently climbed past NetApp’s (or equalled them in 2018) so we shouldn’t read anything significant into NetApp surpassing HPE storage revenues this quarter.
Huawei also exhibits a significant peak in Q4 and a drop to Q1 revenue historically so its revenues may well rebound as well.
Neither IBM storage nor Pure were included in IDC’s top 5 supplier list.