


Amazon Web Services AQUA (the Advanced Query Accelerator) is a scale-out set of hardware nodes that provides parallel processing of data sets moving from S3 buckets to the Redshift data warehouse.
Let’s take a closer look to see why AWS chose the custom home-grown route with AQUA, announced this week, instead of relying on commodity hardware.
The AQUA hardware sits inline in the network between the S3 storage and Redshift cluster, acting as a caching bump in the wire and also as a sub-query offload processing system. AQUA offloads certain repetitive tasks to dedicated hardware, enabling a cluster of Redshift processors to do their work quicker. It pre-processes the dataset being moved to the Redshift cluster so that less data hits this cluster and the cluster can run its application routines without having to do so much system-level work.
The claimed result is up to 10-times better query performance than other cloud data warehouse providers. How does AQUA do this?
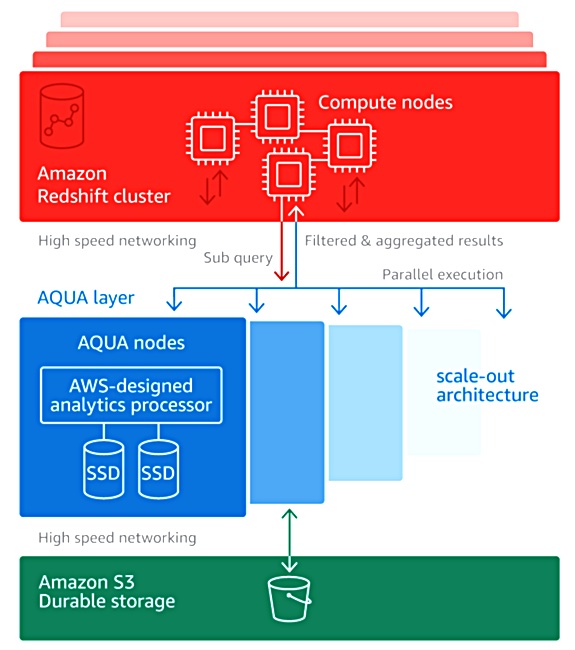
The AQUA module hardware consists of FPGAs to run customised analytics routines and AWS Nitro chips. AQUA modules scale out as needed and operate simultaneously. Data is stored in SSDs.
The FPGA hardware does dataset filtering and aggregation. Filtering removes unwanted information from a data set to create a sub-set. Aggregating provides summing, counts, average values and so forth of records in a data set. The result is that less data is sent to the Redshift cluster. The cluster has to do less work on it because of the pre-processing, and can offload certain sub-query processing to the AQUA nodes.
The Nitro hardware deserves a closer look and its origin needs putting in context.
AWS Nitro
Nitro is both a hypervisor and hardware. AWS EC2 compute users have their applications run as Amazon Machine Instances (AMIs) in virtual machines (VM) on a server. As Metricly blogger Mike Mackrory said;”EC2 is a Service of Virtual Machines.”
When the EC2 service launched in 2006 AWS used Xen Paravirtualization for its physical servers to enable and support its VMs. A VMM (Virtual Machine Manager) function receives calls from the VM for network and storage IO and similar system-level requests.
The VMM dealt with many of these requests by passing them to software routines called device models (DMs) to handle tasks such as sending data across a network to a different server or accessing storage.
The Xen hypervisor uses the server CPUs to run the VMM and DM software, taking up CPU cycles. AWS developed ASIC (Application-Specific Interface Card) hardware, Nitro ‘cards’, to replace these DMs and run their functions faster.
They handle networking, storage (via NVMe to EBS), security, management and monitoring functions as hardware invocations from the VMM, via a Nitro hypervisor, and replace the software DMs. The Nitro hypervisor replaces the Xen hypervisor on Nitro-based systems.
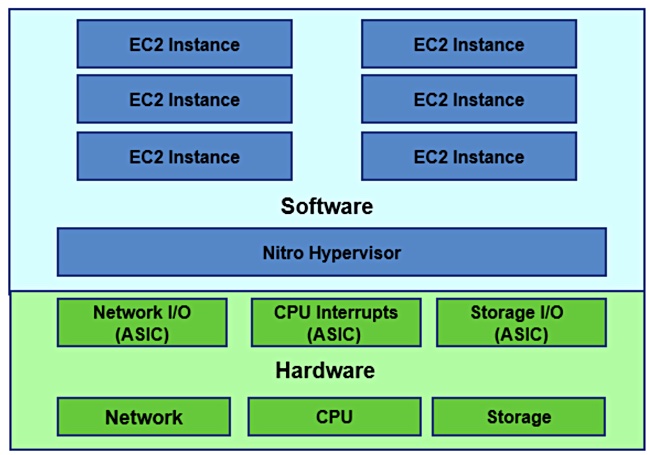
Other Nitro cards provide handling PCIe network interfacing, local NVMe storage, Remote Direct Memory Access (RDMA), and EBS storage, where it handles encryption and flash drive monitoring. Think of Nitro as a family of cards and ASICs, some of which are used by AQUA.
Redshift-only?
The AQUA nodes contain unspecified Nitro ASICs which handle compression and encryption. Together with the FPGAs they provide a Redshift data warehouse acceleration engine which is denied to on-premises data warehouse hardware buyers.
AQUA signals that Amazon does not limit itself to commercial off-the-shelf (COTS) hardware and is so vast that it is worth AWS or suppliers at its behest building customised technology to run services faster and more cost-effectively.
AQUA is slated for delivery in the middle of next year. It will be interesting to see how AWS Redshift compares in query speed and cost with Snowflake and Yellowbrick Data cloud data warehouses. These Redshift competitors can run Nitro-enabled EC2 instances.
AWS exposes services based on its hardware and software infrastructure. These services abstract the details of its infrastructure. Will it expose the specific AQUA Nitro cards and chips and FPGAs as services to customer-competitors Snowflake and Yellowbrick? We ask this because AWS has AQUA ‘secret sauce’ to accelerate Redshift. It has no incentive to provide this to Redshift competitors.





