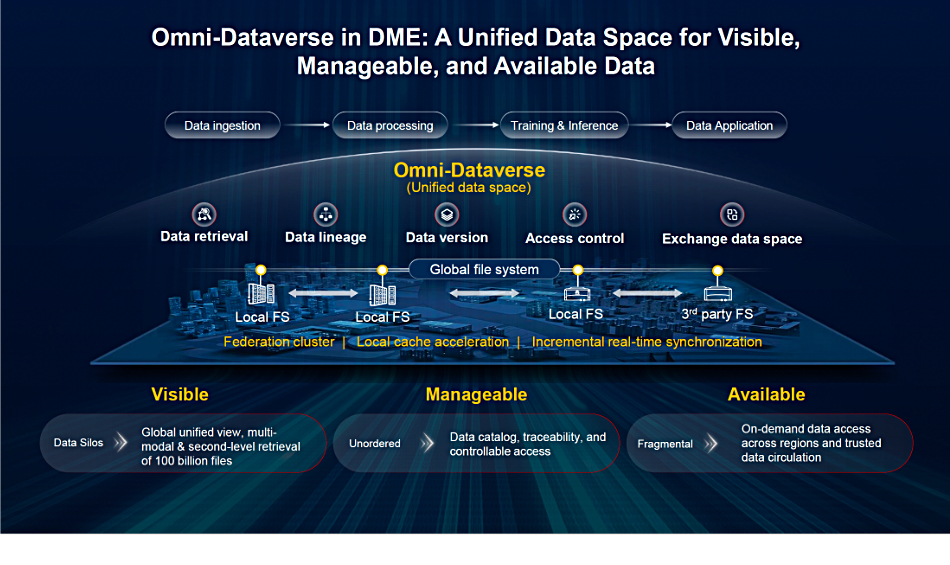
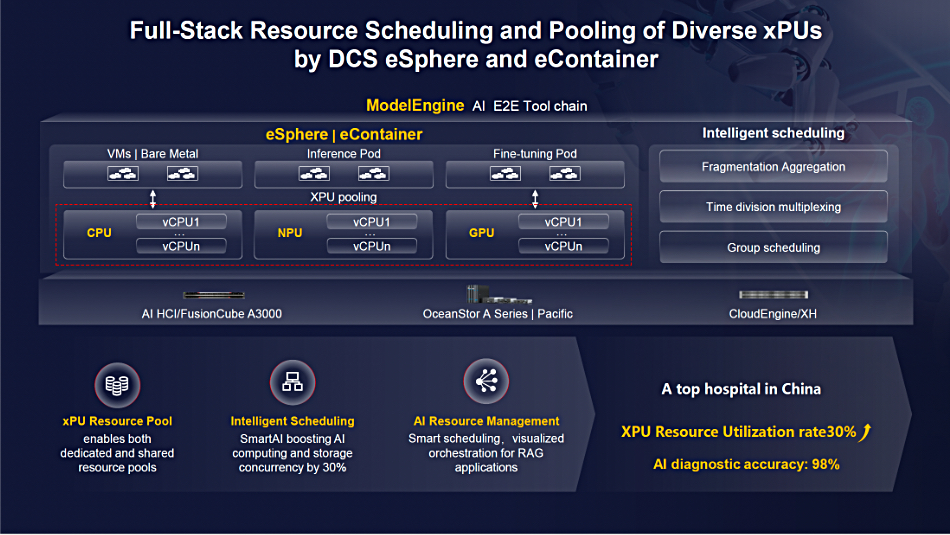
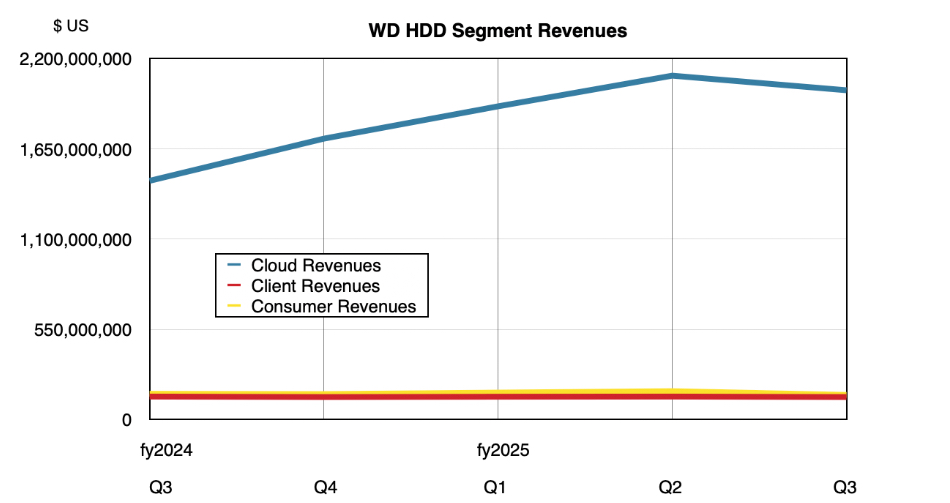
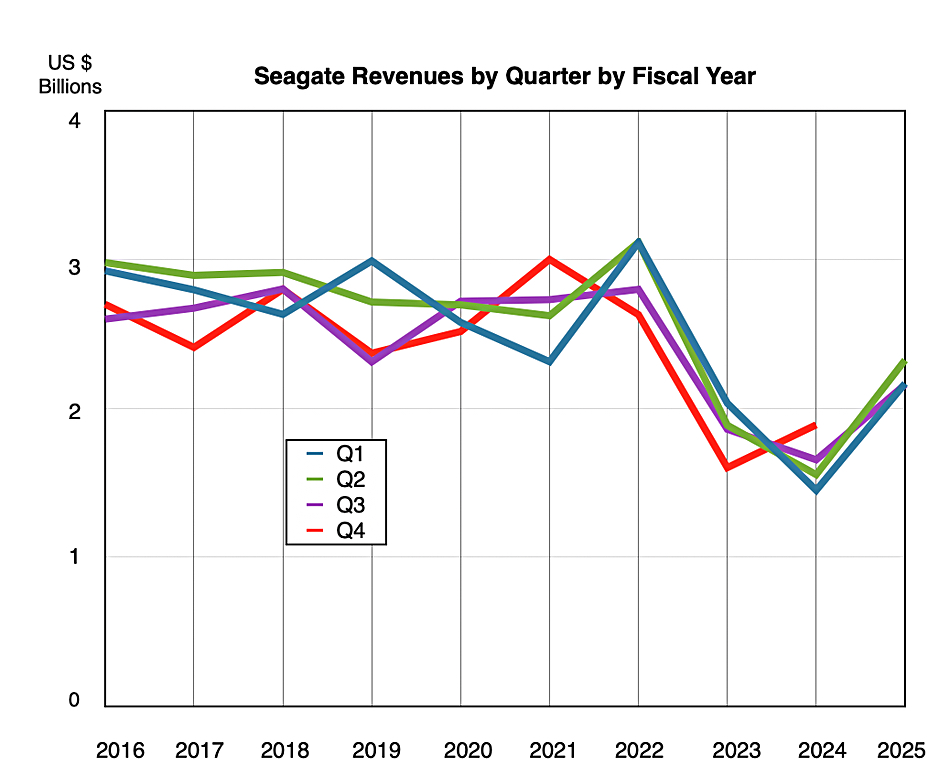
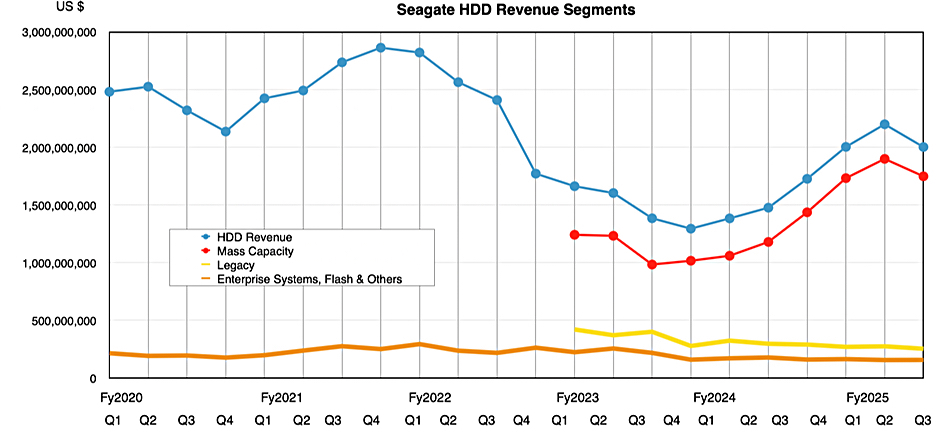
IBM is giving its customers a tidal wave of watsonx AI news at its THINK 2025 conference, saying that AI agents are shifting from AI that chats with you to systems that work for you.
It wants to supply the AI system building components, saying AI agents “must be able to work seamlessly across the vast web of applications, data and systems that underpin today’s complex enterprise technology stacks. Which means that orchestration, integration and automation are necessary to move agents from novelty into operation.”
Chairman and CEO Arvind Krishna stated: “The era of AI experimentation is over. Today’s competitive advantage comes from purpose-built AI integration that drives measurable business outcomes. IBM is equipping enterprises with hybrid technologies that cut through complexity and accelerate production-ready AI implementations.”
There are a large number of announcements to do with IBM’s watsonx AI and data offerings, also covering AI agent workflows, code assistance, feeding unstructured data to RAG apps, expanded GPU and accelerator coverage, Db2 developments, and AI-infused partnering. Let’s dive in to see what it’s introducing:
watsonx
IBM is evolving watsonx.data to help organizations use unstructured data, found in contracts, spreadsheets, presentations, etc. to have more accurate, effective AI. A watsonx.data development will bring together an open data lakehouse with data fabric capabilities, like data lineage tracking and governance, to help customers unify, govern, and access data across silos, formats, and clouds.
IBM says its testing shows that enterprises connecting their AI apps and agents with their unstructured data using watsonx.data can get up to 40 percent more accurate AI than conventional RAG.
There is watsonx.data integration, a single-interface tool for orchestrating data across formats and pipelines, and watsonx.data intelligence, which uses AI-powered technology to extract insights from unstructured data.
IBM is adding watsonx as an API provider within Meta’s Llama Stack, which it says is “enhancing enterprises’ ability to deploy generative AI at scale and with openness at the core.”
Both watsonx.data integration and watsonx.data intelligence will be available as standalone products, with select capabilities also available through watsonx.data. More info here.
IBM is introducing an upcoming watsonx Code Assistant for i, purpose-built to accelerate the production of IBM i applications. It is expected to accelerating RPG modernization tasks with AI-powered capabilities made available directly in the integrated development environment (IDE).
Big Blue says it is capable of providing context-aware RPG code explanations. Later enhancements are expected to include code generation, unit test case creation, and transformation functionalities. IBM watsonx Code for Assistant for i is being built on an IBM Granite code model that is fine-tuned for RPG and IBM i, and is currently in private preview.
watsonx Orchestrate
Customers will be able to build AI agents in watsonx Orchestrate that work with 80+ business applications from providers like Adobe, AWS, Microsoft, Oracle, Salesforce Agentforce, SAP, ServiceNow, and Workday..
The watsonx Orchestrate portfolio includes:
- Build-your-own-agent in under five minutes, with tooling that makes it easier to integrate, customize and deploy agents built on any framework – from no-code to pro-code tools for any kind of user.
- Pre-built domain agents specialized in areas like HR, sales and procurement – with utility agents for simpler actions like web research and calculations.
- IBM watsonx HR agents, available today, helping automate workflows for employee support, such as time off management, profile updates, leave and benefits – integrating with popular HR systems and human capital management applications.
- IBM watsonx Procurement agents designed to streamline procurement workflows such as procure to pay, supplier assessment, and vendor management processes, integrating with tools like Sirion and Dun & Bradstreet.
- IBM watsonx Sales agents built to automate sales processes, help identify new prospects, support outreach to qualified leads, and optimize research and enablement–connecting to technologies from Salesforce, Seismic, and Dun & Bradstreet.2
- Agent orchestration to handle the multi-agent, multi-tool coordination needed to tackle complex projects like planning workflows and routing tasks to the right AI tools across vendors.
- Agent observability for performance monitoring, guardrails, model optimization, and governance across the entire agent lifecycle.
- watsonx is now integrated as an API provider within Meta’s Llama Stack, enhancing enterprises’ ability to deploy generative AI at scale and with openness at the core.
- IBM recently announced its intent to acquire DataStax, enabling the harnessing unstructured data for generative AI. With DataStax, clients can also access additional vector search capabilities.
More info here.
A new Agent Catalog in watsonx Orchestrate will simplify access to 150+ agents and pre-built tools from both IBM and its partners, which includes Box, MasterCard, Oracle, Salesforce, ServiceNow, Symplistic.ai, 11x and others. The catalog will include a sales agent for discovering and importing prospects that works with and is available in Salesforce’s Agentforce and a conversational HR agent that can be embedded in Slack.
webMethods Hybrid Integration
IBM is introducing webMethods Hybrid Integrationto replace what it calls rigid workflows with intelligent, agent-driven automation. It should help users manage the sprawl of integrations across apps, APIs, B2B partners, events, gateways, and file transfers in hybrid cloud environments.
The product provides development, deployment, management and monitoring of diverse integration patterns across on-premises and multi-cloud environments through a hybrid control plane. IBM says it bridges the gap between existing investments and next-gen integration technology, whether accessing data inside mainframes and simplifying B2B data exchange or leveraging AI agents with IBM watsonx.
It uses agentic AI to enhance integration use cases, laying the foundations for model context protocol (MCP) and agent control protocol (ACP).
An included Integration Agent leverages IBM watsonx-powered AI and automatically generates integrations across language-based SDKs, APIs and events.
CAS and GPUs, Red Hat and db2
A new IBM content-aware storage (CAS) capability provides ongoing contextual processing of unstructured data to make extracted information easily available to RAG applications for faster-time-to-inferencing. It is available as a service on IBM Fusion, with support for IBM Storage Scale coming in the third quarter. Fusion is IBM’s containerized derivative of Spectrum Scale plus Spectrum Protect data protection.
Big AI-infused Blue has also expanded its GPU, accelerator and storage collaborations with AMD, CoreWeave, Intel, and Nvidia to provide choices for compute-intensive workloads and AI-enhanced data.
The AMD Instinct MI300X GPU is now generally available on IBM Cloud, with integration planned across the watsonx platform and Red Hat AI platforms. IBM Fusion HCI adds support for AMD Instinct MI210 GPUs.
IBM is also using Nvidia GB200 NVL72 rack-scale systems to develop its Granite family of enterprise-grade foundation models, and recently announced support for Nvidia’s H200 GPUs. It also offers Intel Gaudi 3 AI accelerators.
There is a new IBM API Connect API Agent to help develop AI agents faster. It has been trained on the API Connect platform APIs and has access to a customer’s enterprise resource catalog. It responds to requests given in plain English, using its knowledge of software engineering, API best practices, API Connect capabilities and the customer’s API estate to develop AI agents.
Red Hat AI InstructLab is now generally available as a service on IBM Cloud, helping businesses build and deploy custom GenAI models, while using private data, without needing software installations or GPU management. IBM says customers can build more efficient models tailored to their unique needs while retaining control of their data.
There is a Db2 Intelligence Center, an AI-powered database management platform designed specifically for Db2 database administrators and IT professionals managing databases. More info here.
IBM has launched Db2 and Db2 Warehouse SaaS on Azure using the Bring Your Own Cloud (BYOC) model, that builds upon the existing Db2 and Db2 Warehouse on Cloud. This will be generally available on 17 June 2025. More data here.
Db2 12.1.2 has new AI and cloud-related features, such as built-in support for vectorized data, so supporting semantic searching. Db2 12.1.2 has support for CRUD (create, read, update and delete) operations on Apache Iceberg data lake tables. It’s remote storage capability now includes support for Azure BLOB storage. GA of Db2 version 12.1.2 is set for 5 June 2025
There is an IBM Granite 4.0 Tiny Preview for the open source community, a preliminary version of the smallest model in the upcoming Granite 4.0 family of language models. Granite 4.0 Tiny Preview is extremely compact and compute efficient: at FP8 precision, several concurrent sessions performing long context (128K) tasks can be run on consumer grade hardware, including GPUs commonly available for under $350. More here.
IBM has announced the establishment of a new Microsoft Practice within IBM Consulting. This builds upon a multi-year partnership aimed to deliver stronger and more measurable business outcomes for clients who are navigating complex AI, cloud, and security transformations.
Partnering
There is a new planned integration between Amazon Q index and IBM watsonx Orchestrate. The Amazon Q index enables customers to create a central repository of data based on multiple third-party applications. It helps to fuel AI decision-making and serves as a foundation for retrieving content across various enterprise data sources. Through integration with Amazon Q index, customers will have the ability to enable any IBM watsonx agent to use domain-specific data from applications such as Adobe, Salesforce, Slack and Zendesk for more personalized experiences. A preview of this new integration is on display at IBM Think with expected availability in second half of this year.
IBM is working with Oracle to bring watsonx to Oracle Cloud Infrastructure (OCI), using OCI’s native AI services.
Salesforce and IBM are providing customers access to their business data in Z mainframes and Db2 databases so it can be used for AI use cases on the Salesforce Agentforce platform.
IBM will introduce new IBM agents built with watsonx Orchestrate that work with Salesforce technologies, and IBM Granite models. The new integration will enable AI agents to complete back-to-front office connections using data from IBM Z mainframes, using Salesforce Zero Copy via an integration between IBM watsonx.data and Salesforce Data Cloud, a hyperscale data engine natively integrated within the Salesforce Platform, making high speed data transfer possible without having to move or copy data. This is expected to be available in June.
Box, which provides an Intelligent Content Management (ICM) platform, and IBM are partnering to help customers have faster adoption of enterprise-level AI for content-driven workflows by using IBM watsonx and Box AI. Box is using IBM watsonx.governance internally for life-cycle management of AI models to monitor, govern and provide guardrails for various regulations. More here.
Comment
IBM is going full-tilt into the GenAI world, encouraging its customers to adopt LLM technology, RAG and AI agents to make their operations more efficient. The data in customer’s IBM data stores will be fed up stack through AI pipelines to LLMs and agents all orchestrated through its watsonx facilities. With wall-to-wall AI offerings it does not want to leave any gaps in its offerings through which aggressive competitors could penetrate its customer base.