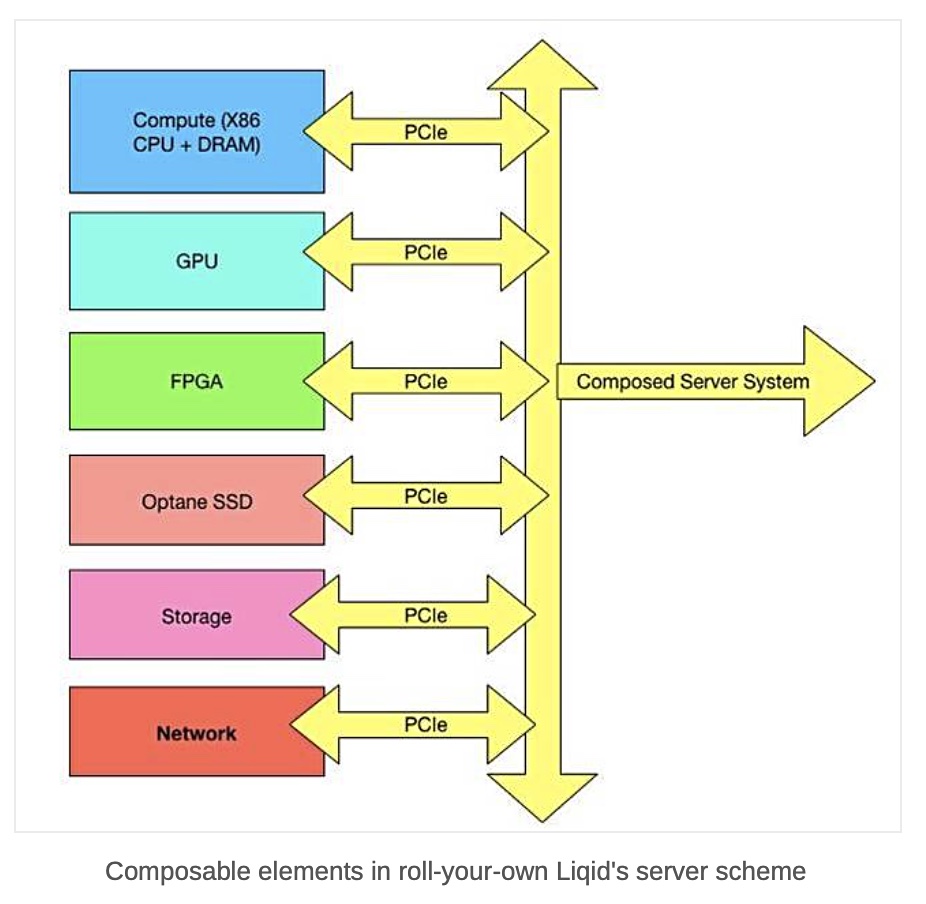
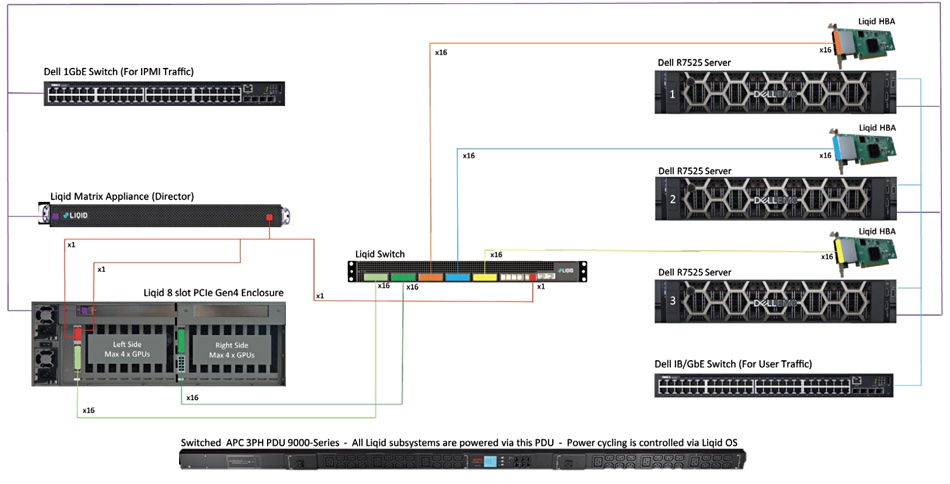
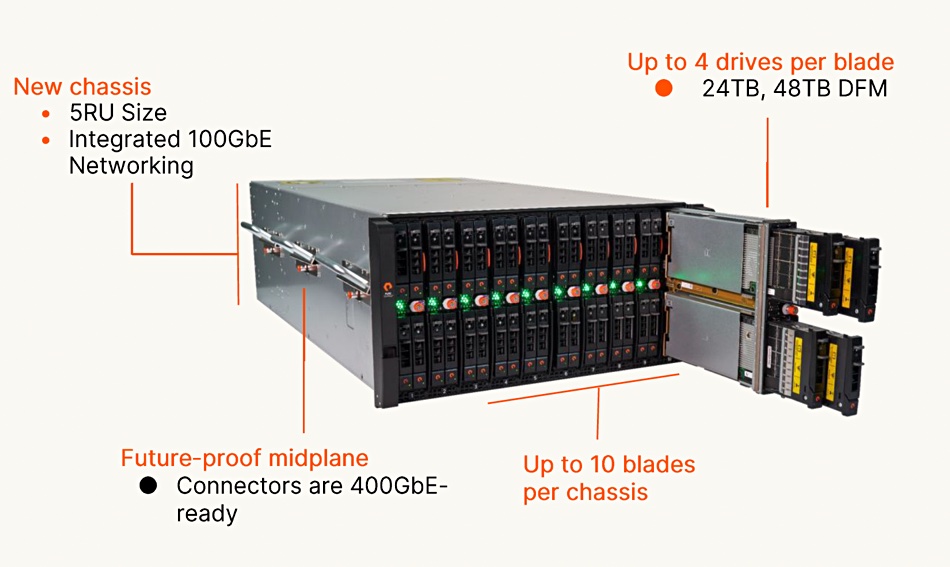
Backblaze says it is the first independent cloud provider to offer a cloud replication service which helps businesses apply the principles of 3-2-1 data protection within a cloud-first or cloud-dominant infrastructure. Data can be replicated to multiple regions and/or multiple buckets in the same region to be protected from disasters, political instability, for business continuity and compliance. Cloud Replication is generally available now and easy to use: Backblaze B2 Cloud Storage customers can click the Cloud Replication button within their account, set up a replication rule, and confirm it. Rules can be deleted at any time as needs evolve.
…
William Blair analyst Jason Ader told subscribers about a session with Backblaze’s CEO and co-founder, Gleb Budman, and CFO, Frank Patchel, at William Blair’s 42nd Annual Growth Stock Conference. Management sees a strong growth runway for its B2 Cloud business (roughly 36% of revenue today) given the immense size of the midmarket cloud storage opportunity (roughly $55 billion, expanding at a mid-20% CAGR). Despite coming off a quarter where it cited slower-than-expected customer data growth in B2 (attributed to SMB macro headwinds), management expects that a variety of post-IPO product enhancements (e.g., B2 Reserve purchasing option, Universal Data Migration service, cloud replication, and partner API) and go-to-market investments (e.g., outbound sales, digital marketing, partnerships and alliances) will begin to bear fruit in coming quarters.
…
DPaaS supplier Cobalt Iron has received U.S. patent 11308209 on its techniques for optimization of backup infrastructure and operations for health remediation by Cobalt Iron Compass. It will automatically restore the health of backup operations when they are affected by various failures and conditions.The techniques disclosed in this patent:
- Determine the interdependencies between various hardware and software components of a backup environment.
- Monitor for conditions in local or remote sites that could affect local backups. These conditions include:
- Indications of a cyberattack
- Security alert conditions
- Environmental conditions including severe weather, fires, or floods
- Automatically reprioritize backup operations to avoid or remediate impacts from the conditions (e.g., discontinue current backup operations or redirect backups to another site not impacted by the condition).
- Dynamically reconfigure the backup architecture to direct backup data to a different target storage repository in a different remote site, or in a cloud target storage repository, that is unaffected by the condition.
- Automatically extend retention periods for backup data and backup media based on the conditions.
- Dynamically restrict or remove access to or disconnect from the target storage repository after backup operations complete.
…
Cohesity is playing the survey marketing game. The data protection and management company transitioning to as-a-service commissioned research that looked at UK specific data from an April 2022 survey of more than 2,000 IT decision-makers and Security Operations (SecOps) professionals in the United States, the United Kingdom and Australia. Nearly three-quarters of respondents (72%) in the UK believe the threat of ransomware in their industry has increased over the last year, with more than half of respondents (51%) saying their organisation has been the victim of a ransomware attack in the last six months. So … naturally … buy Cohesity products to defeat ransomware.
…
Commvault says its Metallic SaaS backup offering has grown from $1 million to $50 million annual recurring revenue (ARR) in 6 quarters. It has more than 2,000 customers, with availability in more than 30 countries around the globe. The Metallic Cloud Storage Service (MCSS), which is used for ransomware recovery, is getting a new name: Metallic Recovery Reserve. Following Commvault’s acquisition of TrapX in February, it’s launching an early access programme for ThreatWise this week. ThreatWise is a warning system to help companies spot cyberattacks, and enable a response helped with tools for recoverability.
…
The STAC benchmark council says Hitachi Vantara has joined it. Hitachi Vantara provides the financial services industry with high-performance parallel storage, including object, block, and distributed file systems, along with services that specialize in storage I/O, throughput, latency, data protection, and scalability.
…
Kioxia has certified Dell PowerEdge R6525 rack servers for use with its KumoScale software. Certified KumoScale software-ready system configurations are available through Dell’s distributor, Arrow Electronics. Configurations offered include single and dual AMD EPYC processors, Kioxia CM6 NVMe SSDs and have capacities of up to 153TB per node. Kumoscale is Kioxia’s software to virtualise and manage boxes of block-access, disaggregated NVMe SSDs. “Kumo” is a noun meaning ‘cloud’ in Japanese.
…
William Blair analyst reported to subscribers about a fireside chat with Nutanix CFO Rukmini Sivaraman and VP of Investor Relations Richard Valera at William Blair’s 42nd Annual Growth Stock Conference. Management still has high conviction in the staying power of hybrid cloud infrastructure, and Nutanix’s growing renewal base will provide it with a predictable, recurring base of growth as well as greater operating leverage over time. Management also noted that beyond Nutanix’s core hyperconverged infrastructure (HCI) products, Nutanix Cloud Clusters is serving as a bridge for customers looking to efficiently migrate to the cloud.
…
Pavilion Data Systems, describing itself as the leading data analytics acceleration platform provider and a pioneer of NVMe-Over-Fabrics (NVMe-oF), said that EngineRoom is using Pavilion’s NVMe-oF tech for an Australian high-performance computing cloud. Pavilion replaced two full racks from a NAS supplier with its HyperOS and its 4 rack-unit HyperParallel Flash Array. It says EngineRoom saved significant data center space by using Pavilion storage to improve HPCaaS analytics. The data scientists at EngineRoom deployed Pavilion with the GPU clusters in order to push the boundaries of possibility to develop and simulate medical breakthroughs, increase crop yields, calculate re-entry points for spacecraft, identify dark matter, predict credit defaults, render blockbuster VFX, and give machine vision to robotics and UAVs.
Stefan Gillard, Founder and CEO of EngineRoom, said: “We need NVMe-oF, GPU acceleration, and the fastest HPC stack. Pavilion is a hidden gem in the data storage landscape.”
…
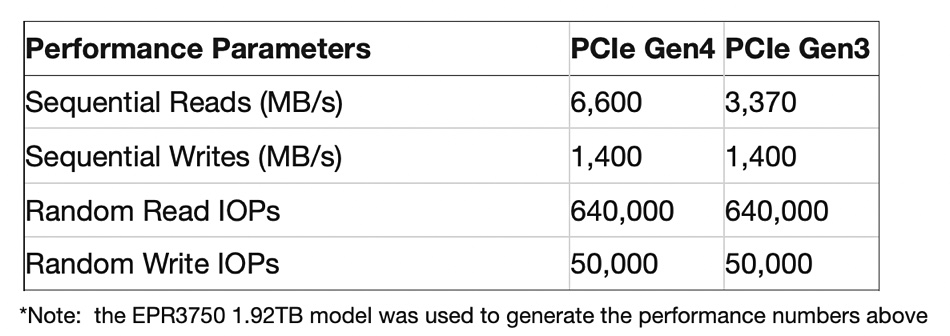
Phison Electronics Corp. unveiled two new PCIe Gen4x4 Enterprise-Class SSDs: the EPR3750 in M.2 2280 form factor and the EPR3760 in M.2 22110 form factor. Phison says they are are ideal for use as boot drives in workstations, servers, and in Network Attached Storage (NAS) and RAID environments. The EPR3750 SSD is shipping to customers as of May 2022, and the EPR3760 SSD will be shipping in the second half of 2022.
…
Qumulo has introduced a petabyte-scale archive offering that enhances Cloud Q as a Service on Azure. It is new serverless storage technology, the only petabyte-scale multi-protocol file system on Azure, enabling Qumulo to bring out a new “Standard” offering with a fixed 1.7 GB/sec of throughput with good economics at scale. Qumulo’s patented serverless storage technology creates efficiency improvements resulting in cloud file storage that is 44% lower cost than competitive file storage solutions on Azure. Qumulo CEO Bill Richter said: “The future of petabyte-scale data is multi-cloud. … Qumulo offers a single, consistent experience across any environment from on-premises to multi-cloud, giving our customers the tools they need to manage petabyte-scale data anywhere they need to.” Qumulo recently unveiled its Cloud Now program, which provides a no-cost, low-risk way for customers to build proofs of concept up to one petabyte.
…
SK hynix is mass-producing its HBM3 memory and supplying it to Nvidia for use with its H100, the world’s largest and most powerful accelerator. Systems are expected to ship starting in the third quarter of this year. HBM3 DRAM is the 4th generation HBM product, succeeding HBM (1st generation), HBM2 (2nd generation) and HBM2E (3rd generation). SK hynix’s HBM3 is expected to enhance accelerated computing performance with up to 819GB/sec of memory bandwidth, equivalent to the transmission of 163 FHD (Full-HD) movies (5GB standard) every second.
…
Cloud data warehouser Snowflake announced a new cybersecurity workload that enables cybersecurity teams to better protect their enterprises with the Data Cloud. Customers gain access to Snowflake’s platform to natively handle structured, semi-structured, and unstructured logs. They can store years of high-volume data, search with scalable on-demand compute resources, and gain insights using universal languages like SQL and Python, currently in private preview. Customers already using the new workload include CSAA Insurance Group, DoorDash, Dropbox, Figma, and TripActions.
…
SoftIron says Earth Capital, its funding VC, made a mistake, a quite big one, when calculating how much carbon dioxide emissions were saved by using SoftIron HW and SW. In the original report by Earth Capital, the report stated that for every 10PB of data storage shipped by SoftIron, an estimated 6,656 tonnes of CO2e is saved by reduced energy consumption alone. The actual saving for a 10PB cluster is 292 tonnes. This is 23 times less and roughly the same weight as a Boeing 747 – still an impressive number when put into full context. Kudos to SoftIron for ‘fessing this upfront.
…
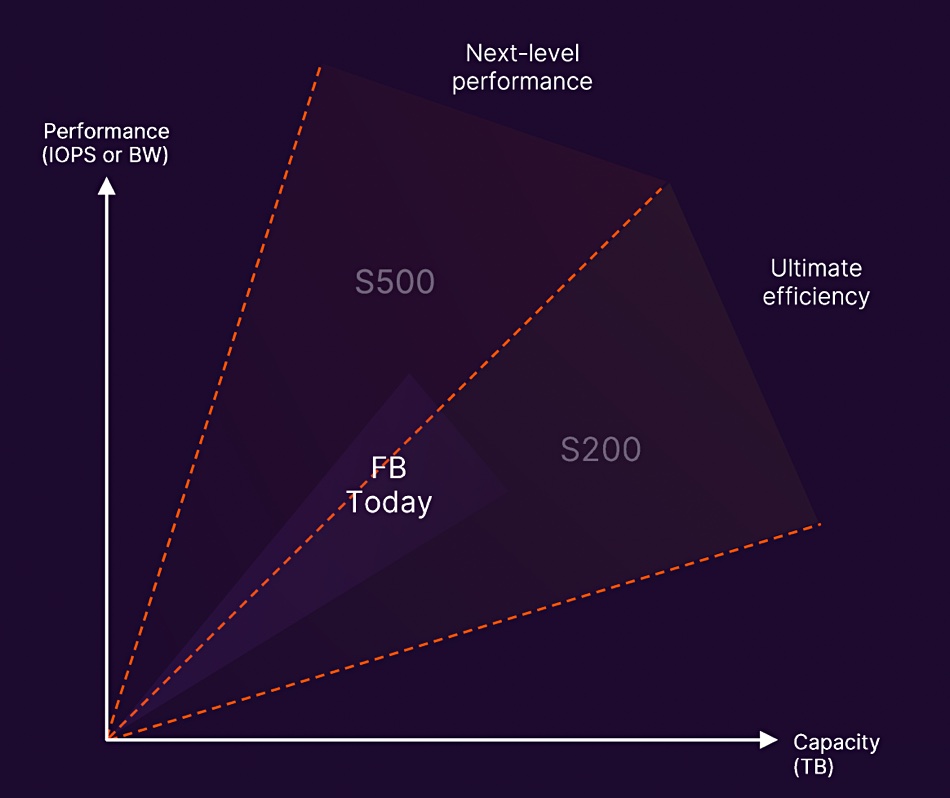
VAST Data CMO and co-founder Jeff Denworth has blogged about the new Pure Storage FlashBlade//S array and Evergreen services, taking the stance of an upstart competing with an established vendor. Read “Much ado about nothing” to find out more.
…
Distributed data cloud warehouser Yellowbrick Data has been accepted into Intel’s Disruptor Initiative. Intel and Yellowbrick will help organizations solve analytics challenges through large-scale data warehouses running in hybrid cloud environments. The two are testing Intel-based instances on Yellowbrick workloads across various cloud scenarios to deliver optimal performance. Yellowbrick customers and partners will benefit from current and future Intel Xeon Scalable processors and software leveraging built-in accelerators, optimized libraries, and software that boost complex analytics workloads. Yellowbrick uses Intel technology from the CPU through the network stack. Intel and Yellowbrick are expanding joint engineering efforts that will accelerate performance.
…