


The ceaseless quest for avoiding storage IO delays has alighted on GPUs and Nvidia has devised a way to bypass the host server CPU and memory and accelerate data moving speeds up to 20x.
CEO Jensen Huang launched Nvidia’s Magnum IO technology yesterday at SC19 in Denver. He reckons it will speed AI and machine learning processing so much that “now, AI researchers and data scientists can stop waiting on data and focus on doing their life’s work”.
Magnum IO leans on NVMe, NVM-oF and RDMA (Remote Direct Memory Access) to load GPUs with data faster. The upshot is up to 20x faster overall processing time, for example cutting a one hour run to three minutes, according to Nvidia.
The existing way
Traditionally, data takes three hops to move from storage to the GPU. Each hop takes time and the host server memory acts a temporary bounce buffer between storage and the GPU. The GPU is fed with data fetched from local or external storage via network interface cards. This is stored temporarily in the host server’s DRAM and transferred to the GPU via PCIe connections.
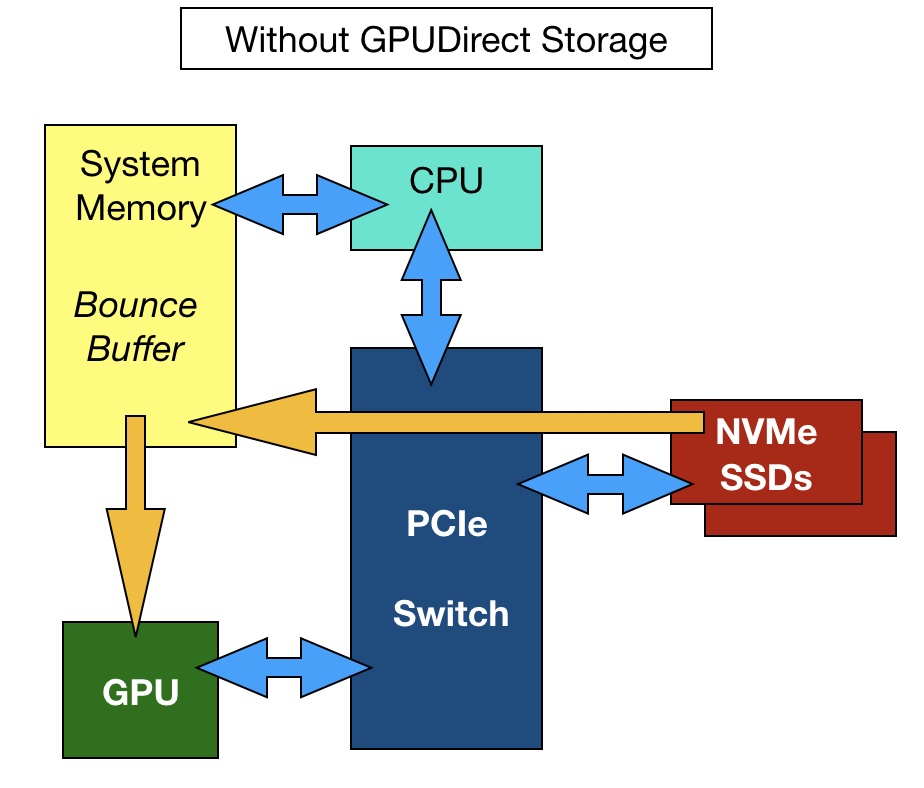
But the GPU is also hooked up to PCIe and it is a single hop for data to move direct from storage to the GPU. System software is required to connect the storage to the GPU directly, thus bypassing the host server’s CPU and DRAM bounce buffer.
And this is what Nvidia has created with Magnum IO, working with DDN EXA5 arrays, Excelero NVMESH storage, IBM Spectrum Scale file software, Mellanox switches, NetApp EF600 NVMe-oF arrays and WekaIO Matrix file softwar).
The new way
Magnum IO is a set of software modules providing a framework for direct Storage-to-GPU data transfer:
- Collective Communications Library (NCCL),
- GPUDirect RDMA moves date between a NIC and a GPU memory, improving bandwidth and latency,
- GPUDirect Storage moves data from local or remote NVMe drives, using NVME-oF, to a GPU’s memory
- Fabric Manager.
GPUDirect Storage is the specific module providing the direct GPU-storage connectivity.
The bandwidth from a host server’s DRAM to Nvidia DGX-2 GPUs is a max of 50GB/sec. Magnum IO will support multi-server, multi-GPU compute node configurations. The bandwidth from many NVMe SSDS and their NICs can be combined to reach 215GB/sec.
All Nvidia’s GPU data intensive workloads should benefit from this. Check out Nvidia’s blog on the topic by senior solutions architect Adam Thompson and principal architect CJ Newburn.
Magnum IO is available now and GPUDirect Storage functionality expected in the first half of 2020. DDN expects to support the full NVIDIA Magnum IO suite, including GPUDirect Storage, in an EXAScaler EXA5 release in the middle of 2020.




