

Separate scaling of compute and data is central to VAST’s performance claims. Here is a top-level explanation of how it is achieved.
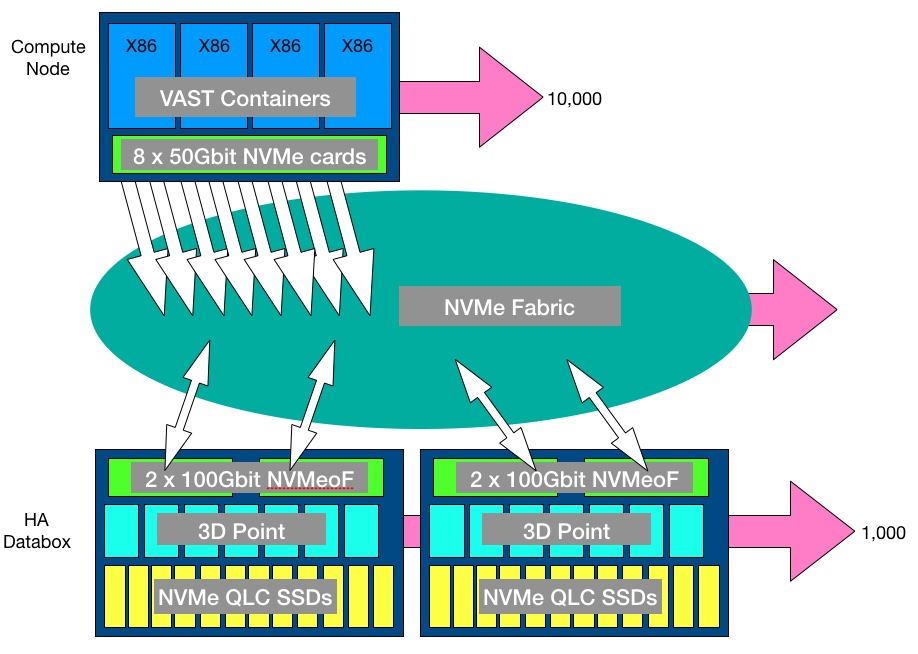
In VAST’s scheme there are compute nodes and databoxes – high-availability DF-5615 NVMe JBOFs, connected by NVMe-oF running across Ethernet or InfiniBand. The x86 servers run VAST Universal File System (UFS) software packaged in Docker containers. The 2U databoxes are dumb, and contain 18 x 960GB of Optane 3D XPoint memory and 583TB of NVMe QLC (4bits/cell) SSD (38 x 15.36TB; actually multiple M.2 drives in U.2 carriers). Data is striped across the databoxes and their drives.
The XPoint is not a tier. It is used for storing metadata and as an incoming write buffer.
The QLC flash does not need a huge amount of over-provisioning to extend its endurance because VAST’s software reduces write amplification and data is not rewritten that much.
All writes are atomic and persisted in XPoint; there is no DRAM cache. Compute nodes are stateless and see all the storage in the databoxes. If one compute node fails another can pick up its work with no data loss.
There can be up to 10,000 compute nodes in a loosely-coupled cluster and 1,000 databoxes in the first release of the software, although these limits are, we imagine, arbitrary.
A 600TB databox is part of a global namespace and there is global compression and protection. It provides up to 2PB of effective capacity and, therefore, 1,000 of them provide 2EB of effective capacity.
The compute nodes present either NFS v3 file access to applications or S3 object access, or both simultaneously. A third access protocol may be added. Possibly this could be SMB. Below this protocol layer the software manages a POSIX-compliant Element Store containing self-describing data structures; the databoxes accessed across the NVMe fabric running on 100Gbit/s Ethernet or InfiniBand.
Compute nodes can be pooled so as to deliver storage resources at different qualities of service out to clients.
Next
Explore other parts of the VAST Data storage universe;
- VAST data reduction
- VAST striping and data protection
- VAST universal file system
- VAST Data’s business structure and situation
- Return to main VAST Data article here.





