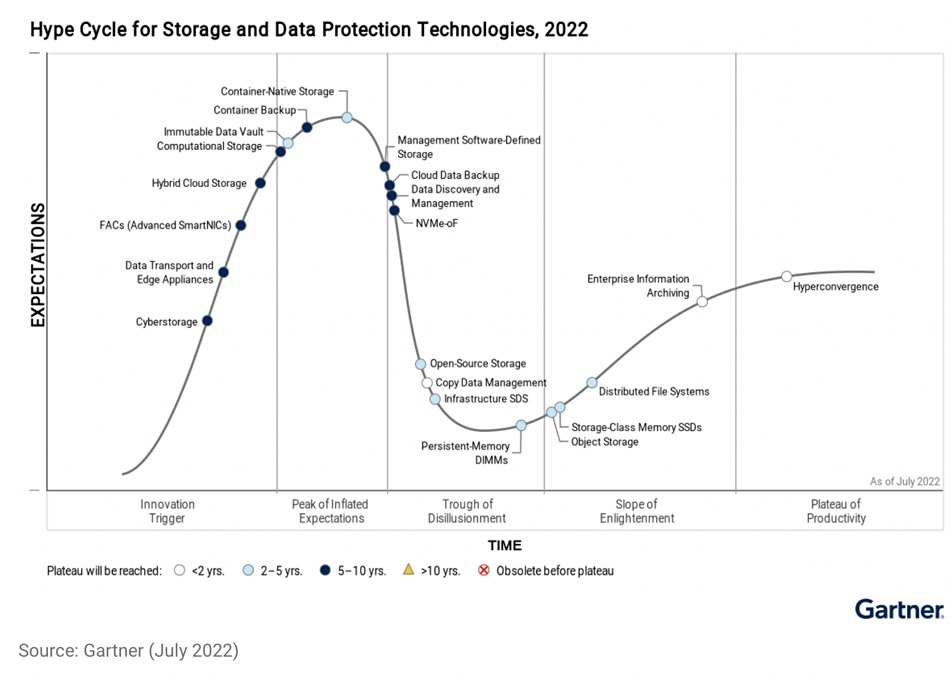
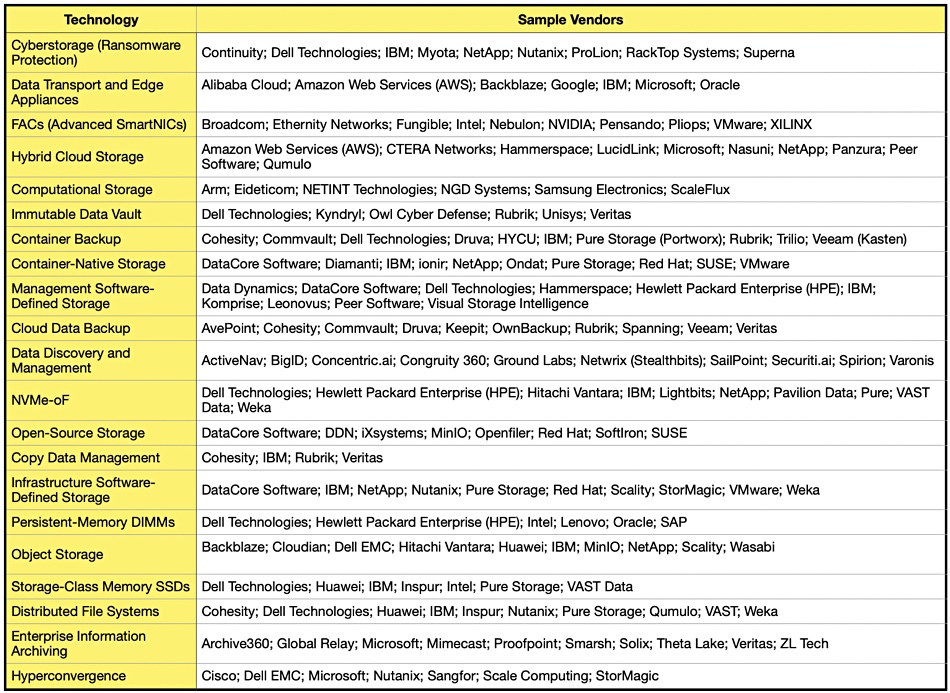
Gartner’s latest storage and data protection hype cycle is an amazingly long report and, this being Gartner, the basic idea is treated to exhaustive analysis by a team of consultants.
The hype cycle concept is a wave-like outline in a two axis space defined by time along the bottom and and expectations vertically. Technologies flow along this line. There is an initial rising line, in what is called the Innovation Trigger period. This leads to a high point, the Peak of Inflated Expectations, followed by a downward plunge to the Trough of Disillusionment. We then see technologies becoming more talked about again and adopted in the Slope of Enlightenment time, followed by them reaching the Plateau of Productivity.
This whole hype cycle idea with terms such as Peak of Inflated Expectations and Trough of Disillusionment is like something out of The Pilgrim’s Progress, John Bunyan’s book of theological allegory.
Gartner’s pundits place technologies at various points on the wave outline and justify their choices in great reams of text using a fixed format – Definition, Why This Is Important, Business Impact, Drivers, Obstacles, User Recommendations, followed by a set of sample vendors for each technology:
Mature technologies in the final Plateau of Productivity phase are ignored.
There is also a Priority Matrix table showing the expected number of years to mainstream adoption for each technology:
The whole thing is a great deal of fun to read and ponder.
But it does leave a meta question in B&F‘s mind: where in the overall hype cycle is Gartner’s storage hype cycle? Are we in the Trough of Disillusionment or the Slope of Enlightenment?
If it doesn’t already, your datacenter is more than likely going to feature software-defined storage (SDS) in the very near future.
SDS offers the prospect of vastly improved flexibility and automation right across on-prem, edge, and the cloud, with 3rd Gen Intel® Xeon® Scalable processors providing the perfect platform for reliable, scalable storage solutions. But not all software defined architectures are created equal, and storage admins remain understandably concerned about the prospect of vendor lock-in.
In which case open source SDS is more than likely on your agenda. But how does that work in practice? And what are the opportunities and potential pitfalls of different approaches?
The Register’s Martin Courtney will be joined by Steven Umbehocker, founder and CEO at OSNexus, Supermicro product director Paul McLeod, and Supermicro product manager Sherry Lin to discuss open source software-defined storage approaches, and how they future proof your architecture.
They’ll be picking apart the key issues around open-source SDS, including the benefits of scale-up versus scale-out and what this means for networking requirements, the best architectures for different use cases, such as backup and archive, and the advantages of deploying storage systems based on 3rd Gen Intel® Xeon® Scalable processors.
Everyone’s starting point is different, so they’ll cover the challenges of migrating data from legacy systems to SDS, and how you can confront them.
And they’ll explain in depth how Supermicro, Intel, and OSNexus are collaborating to optimize server and storage products which give customers what they need to implement software-defined storage.
So, if you want to get a complete overview of what’s happening in storage, now and in the future, head here and register for the entire event. Because the future of storage is wide open.
If it doesn’t already, your datacenter is more than likely going to feature software-defined storage (SDS) in the very near future.
SDS offers the prospect of vastly improved flexibility and automation right across on-prem, edge, and the cloud. But not all software defined architectures are created equal, and storage admins remain understandably concerned about the prospect of vendor lock-in.
In which case open source SDS is more than likely on your agenda. But how does that work in practice? And what are the opportunities and potential pitfalls of different approaches?
The Register’s Martin Courtney will be joined by Steven Umbehocker, Founder and CEO at OSNexus, Supermicro Product Director Paul McLeod, and Supermicro Solution Product Manager Sherry Lin to discuss open source software-defined storage approaches, and how they future proof your architecture.
They’ll be picking apart the key issues around open-source SDS, including the benefits of scale-up versus scale-out and what this means for networking requirements, as well as the best architectures for different use cases, such as backup and archive.
Everyone’s starting point is different, so they’ll cover the challenges of migrating data from legacy systems to SDS, and how you can confront them. They’ll also be looking to the future, by examining the advantages of PMEM over traditional SSDs.
And they’ll explain in depth how Supermicro, Intel®, and OSNexus are collaborating to optimize server and storage products which give customers what they need to implement software-defined storage.
So, if you want to get a complete overview of what’s happening in storage, now and in the future, head here and register for the entire event. Because the future of storage is wide open.
GFS– Global FileSystem. AWS says a global file system (GFS) presents a single global namespace to multiple locations. This means that a client mounting the file system at any of the locations will see the same file and folder structure as clients in any other location. The benefit of using a GFS over syncing the data to multiple locations is that a GFS can be more efficient with the amount of data it transfers.
A GFS works by keeping a file’s metadata, such as its creation date, size, name and location, separate from the main payload of the file content (sometimes referred to as the essence data). The metadata is continuously synced between locations, while the payload is only transferred when required. Since the metadata for even large files takes up only a couple of kilobytes, using this system in production ends up requiring less data transfer than a full syncing system would.
The GFS abstracts these concepts away from the user. From an application’s point of view, the file system behaves the same as a local file system would. The end result is that the workflows built on top of local file systems will not need any modifications to work with a GFS.
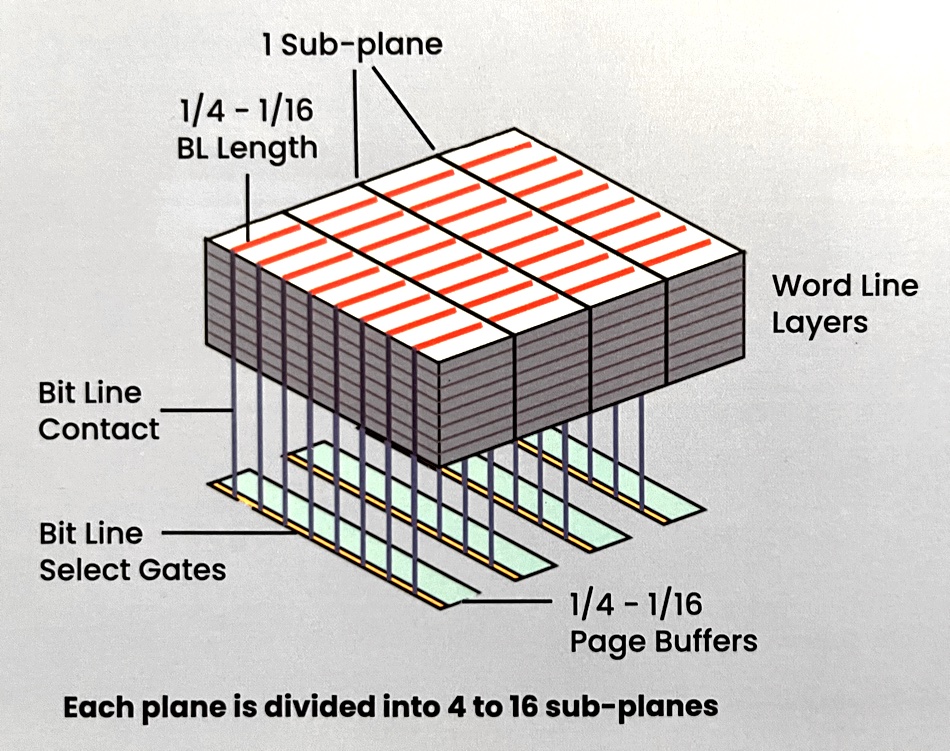
Startup Neo Semiconductor previously introduced X-NAND technology, which carves a NAND die into multiple parallel planes to speed IO. Now it says it has launched a second generation to speed it up twice as much again.
The technology takes a base NAND die with two to four access planes. Each plane is divided into four to 16 sub-planes, each accessed in parallel. Page buffers are used to optimize data throughput speeds. A brochure explains that with gen 1, a total of four planes are used for SLC/TLC parallel programming. Input data is programmed into three SLC word lines in three planes and then programmed to a TLC word line in a fourth plane.
This enables a gen 1 X-NAND SSD to deliver 1,600 MB/sec of sequential write throughput compared to the basic SSD’s 160MB/sec.
Neo Semiconductor brochure diagram
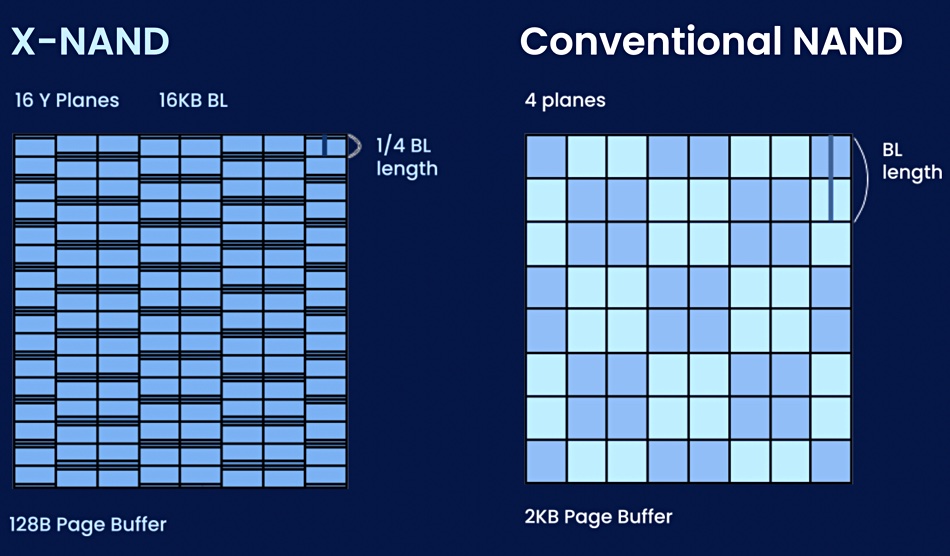
Gen 2 X-NAND does things differently. Two planes are used for SLC/TLC parallel programming. Input data is programmed into three SLC word lines, as before, but now only in one plane, and then programmed to a TLC word line in a second plane. This enables data writes to occur in parallel with fewer planes, and X-NAND delivers SLC-like performance from larger capacity and lower cost QLC memory.
X-NAND gen 2, says Neo Semiconductor, delivers 3,200MB/sec of sequential write throughput, 20x faster than a basic SSD. There are also unspecified latency improvements.
It also provides 3x the base random read/write speed and there is zero increase in die size.
Neo Semiconductor X-NAND diagram
X-NAND architecture supports SLC, MLC, TLC, QLC and PLC variants of NAND. The IP can be deployed by NAND manufacturers (Kioxia, Micron, Samsung, SK hynix, Solidigm, Western Digital, and YMTC), and is compatible with current technologies and processes with zero increase in manufacturing cost. At least this is the pitch by Neo Semiconductor.
The technology was awarded a “Best of Show” award for the Most Innovative Memory Technology at FMS 2022. So far we have not heard of any NAND manufacturers using Neo’s X-NAND technology. Find out more about it here.
Bootnote
Neo Semiconductor also has an X-DRAM technology, based on shorter bit lines and reduced capacitance, which adds parallelism. This, it says, increases DRAM performance with 400 percent refresh data throughput, lowers the voltage needed, and reduces overall power consumption.
Optimizing the digital data supply chain for SQL query processing is what drives the NeuroBlade founders and their hyper compute for analytics technology. Co-founders CEO Elad Sity, CTO Eliad Hillel, and also CMO Priya Doty, told us at FMS 2022 that they wish to optimize every stage of the data supply chain from storage drive to processor when executing a SQL query.
We discussed NeuroBlade’s Xiphos hardware using XRAM processing-in-memory technology here. This interview allowed us to explore why NeuroBlade was founded and how it is coming to market.
Sity and Hillel are two ex-SolarEdge execs. Doty is a former VP of product marketing for IBM. SolarEdge is an Israeli company building photovoltaic inverters and battery monitoring equipment. It IPO’d on NASDAQ in 2015, raising $126 million.
We asked Sity what the trigger was for starting NeuroBlade.
He said: “SolarEdge is taking off. Good company, great company. All of us are friends for many years. All of us knew each other from the army. I can tell you from my perspective, I was in New York [for] the IPO for SolarEdge. Five minutes after that we [went] from the NASDAQ building to the bar across the street. I asked myself, ‘How do I get here again? How do we do this again?’
“And we came back from New York. I [went] to the SolarEdge CEO and told him this is it. Like, it’s going to take six months, a year, but I’m starting my own company.
“I was playing around with stock trading. Like every good real-time engineer, I thought if it doesn’t run fast, you try to realize why. And what we figured out is CPUs for general purpose, GPU for compute-intensive [graphic] workloads. We said we’re just going to build a video [graphics] processor for data.
“When we said we are going to build the next video for data we were kind of crazy because Nvidia didn’t build in five years. They built it in 30. And they started from gaming. It took us a little bit of time to find what is going to be our ‘gaming,’ the use case that we are going to crush.”
And that core application was SQL-accessed analytics.
The memory key
Sity said the core issue was memory. “When you try to run data analysis, join tables together, and do data crunching, we saw that the memory is far from being optimized enough to support the IOs that come from drives and you don’t get to the full potential of your IOs, streaming from drives, terabytes and petabytes of data.
“You don’t get to the full IOPS of the system, getting bogged down either by memory or network, sometimes compute. And this is why we started on technology… the problem with a gap between NAND and the actual processor. You couldn’t get data from the NAND into the processor fast enough to keep all the cores busy. So there had to be a way to build new processors.”
We suggested it had to be a parallel design.
Doty said: “To be parallel, it had to be very memory-efficient. For us, it started from the memory. So how do we untie the memory bottlenecks in the system?”
Sity said his previous experience “was always about bringing a full solution that is mixing up different technologies and solving for the entire system.”
“I can say that, originally, we are not the best silicon people, not the best hardware people, not the best algorithms people. We learn how to bring all the best people to work together. Our expertise is how you look at it all from a system perspective and bring it all together. So in the case of problems like data analytics, or actually every problem that has a lot of data, you need to look at the storage, the memory, the networking, the computer itself.”
Supply chain optimization
B&F notes that there is a digital supply chain between the NAND drive and the processor, and asked NeuroBlade if it wants to optimize that digital supply chain, not just one component in it?
Sity said: “Entirely, we never intended to be a component company. We figured out very, very early on this is a game of compatibility and ease of use, which means it’s a lot of software. So we never wanted to be a component company.”
“This is also one other thing that we realized; if you optimize just in networking, if you optimize just the storage 10 percent,” you are just pushing the bottleneck somewhere else. “But if you’re looking at the entire system, as a whole, trying to optimize all the path from the storage all the way back to give the user an answer. Yes. If you also go through the entire software stack, then you can get to the 10x, 100x improvement.”
Doty said: “If you don’t handle the physical aspects of the actual infrastructure, then you can’t actually accelerate everything. You’re still leaving a lot on the table. And that’s our premise.”
Xiphos enclosure top down lid-off view showing the four NeuroBlade processors. There are 32 NVMe SSDs underneath the 4-processor hardware board, and the system has PCIe 4 support
Talking about their processor, Sity said: “Right now it’s based on FPGAs,” with an intent to move to ASICs. The whole system is modular so changes can be swapped in at each layer to improve performance even more; PCIe 4 for PCIe 5, for example.
Although the hardware and its firmware is proprietary there is a software stack to interface it to standard analytics applications. Doty said: “The idea being that you can go from analytics workloads down to our analytics engines [and] people don’t have to make any changes to what they’re doing.
“If you’re in your own datacenter, put it in your system, basically connect our devices to the network and install the plugin. And for end users, nothing changes. It’s on the infrastructure level… as long as you have a disaggregated storage and compute cluster, we plug in.”
The software stack can be extended, Doty said. “We’ll have a connector based on Spark in the download center.”
Customers
NeuroBlade’s early customers are akin to design partners, helping to improve the product’s design and usability, and they pay for the privilege – because the technology is promising.
We asked what kind of customers is NeuroBlade looking at?
Doty said it’s not a mid-market solution: “Primarily, we’re going after two different types of companies. We’re going after cloud providers; tier one and tier two. We have a two pronged approach. One is that a cloud provider puts the NeuroBlade system into their datacenter and resells it as an analytics accelerator on top of their existing solutions. Then the other is direct to customers who do have a datacenter. It’s mostly Fortune 1000 in terms of the end customers. And there doesn’t seem to be any specific industry that doesn’t need it.
“It’s almost like a silent-suffer problem where, if you actually go talk to people who do analytics, they’re like, ‘Oh, yeah, it’s a huge issue. I can’t keep up with my infrastructure to support the needs of my analytics users.’ But they just kind of suffer silently. This is the way it is.
“They’re focused on the data layer, the database, and the data warehouse in the data lake layer, but they’re not focused on the underlying infrastructure,” said Doty.
Which is where NeuroBlade comes in as a data analytics infrastructure technology and product play.
In effect, any enterprise with data and compute-intensive SQL queries can use NeuroBlade’s system to speed up their SQL queries by up to 100x. Doty showed a slide with an analytics company quote: “I have 1,000 cores for analytics and another 1,000 for ETL and still can’t meet the needs of 200 users.”
Doty introduced one NeuroBlade customer, CMA, a healthcare Medicaid administrator which handles a billion claims a year. It is building its third-gen analytics service with NeuroBlade, to leapfrog the limitations of RDBMS by using NVMe and software-defined storage to reduce IO bandwidth bottlenecks.
CMA said: “NeuroBlade is a game-changer: it allows CMA to run thousands of queries scanning hundreds of terabytes daily, delivering queries in less than 1 minute. Also allows CMA to eliminate commercial RDBMSes and 30 years of feature set ‘bloat’ to address the query IO bandwidth bottleneck, and there’s a significant price/performance advantage. NeuroBlade eliminates end-to-end the bottlenecks, accelerates processing, and reduces datacenter footprint.”
Summary
What CMA and other NeuroBlade customers have done is to go against conventional thinking that software can drive commodity server, storage, and networking components fast enough, and introduced a GPU-like approach with specific analytical processing hardware, designed with thousands of cores; a domain-specific processing approach. Store your hundreds of terabytes of analytics data in its Xiphos box, send it SQL query requests, and get more rapid responses back.
LPDDR – Low Power Double Data Rate refers to low power DRAM for mobile devices such as smart phones and tablets. It’s aimed at minimizing power consumption and features low voltage operation. LPDDR5X DRAM is the 7th generation product The ‘double data rate’ term refers to it transferring data on both the rise and fall of the clock signal. LPDDR standards are managed by JEDEC.
LPDDR1 – 1.8 volts compared to DDR1’s 2.5 volts. Two clock speeds;200MHz and 266.7MHz in LPDDR1E. Data transfer rate of 400MTs or 533.3MTs with a prefetch size of 2n.
LPDDR2 -1.2V or 1.8V in the LPDDR2E version. Clock speeds: 400MHz or 533.3MHz. Allowed for double the transfer rate of 800MTs or 1,067MTs, respectively, with a prefetch size of 4n.
LPDDR3 – same 1.2 or 1.8 volts as LPDDR2. JEDEC doubled the prefetch size to 8n, allowing the I/O clock rate and transfer rate to double. Data transfer rates rose to 1,600MTs or 2,133MTs for the LPDDR3E variant.
LPDDR4 – 1.1 or 1.8 volts, while the LPDDR4X variant had lower power state of 0.6 volts. JEDEC doubled the prefetch size and changed I/O bus from a single 32-bit bus to a pair of 16-bit buses. 3,200MTs transfer rate with LPDDR4X variant offering 4,267MTs transfer speeds.
LPDDR5 – 0.5 volts, 1.05 volts, or 1.8 volts. Kept same prefetch size as LPDDR4 of 16n but doubled transfer rate to 6,400Mts. LPDDR5X, added an 8,533MTs transfer speed.
LPDDR5X – Micron says this memory offers the best performance and power efficiency compared to LPDDR5, LPDDR4X and LPDDR4. It is designed for flagship smartphones, thin and light laptops and other mobile devices.
Infinidat is fighting three lawsuits alleging improper stock option dilution brought by employees. We knew about one lawsuit in October 2020 but two more surfaced in a Globes report at the end of July.
The basic situation is that Infinidat, which makes high-end memory-cached storage arrays, has been issuing Class B stock options to employees and advisors since 2015. These shares were worth $1,290 in 2018. The first lawsuit, filed by Tel Aviv law firm Horovitz, Even, Uzan & Co., claims the stock option value was emphasized by a company statute which said: “Class B shares will always receive the first 20 per cent of recompense and rights in the company in the case of an acquisition, without the possibility of dilution by anyone who isn’t an employee or advisor.”
After a June 2020 fundraising round, amounting to tens of millions of dollars, Infinidat devalued these shares to one thousandth of their 2018 amount. It stated: “Whoever holds Class B shares and no longer works for the company will have their share diluted so that it would be worth one thousandth of its former value … and that current employees will be offered a new option program (combining a new class of shares with a new maturation process) that would be worth 6 percent of the previous value of their holdings.”
The ex-employees’ Class B shares were suddenly worth $1.29 and current employees’ Class B stock was valued at $7.40. The lawsuit claims that the registered capital of Class B shares was increased in the June 2020 funding round “to allow an anti-dilution mechanism for two companies (Claridge Israel and ICP), who probably invested in the company in return for Class B shares and are meant to hold 54 percent of Class B shares in any situation,” and to issue thousands of new Class B shares for the company’s employees.
These investors were not advisors and so not entitled to Class B shares – if the claims of the first group of ex-employees are confirmed by the Israeli legal system.
Several dozen employees then left Infinidat.
Horovitz is representing 29 ex-Infinidat employees. A second group of suing employees are represented by Gad Ticho and Alon Kanety of Caspi & Co. A third case involves Dr Alex Winokur who worked at Infinidat and then co-founded Axxana, acquired by Infinidat in 2018.
Lawsuits have been filed in the Tel Aviv District Court (Economic Affairs court) and the Bat Yam Regional Labor Court. They name Infinidat, its board of directors, Infinidat founder Moshe Yanai, and Goldman Sachs.
The company tells us: “We believe that the claims are baseless, and in any case will be determined by the appropriate courts.”
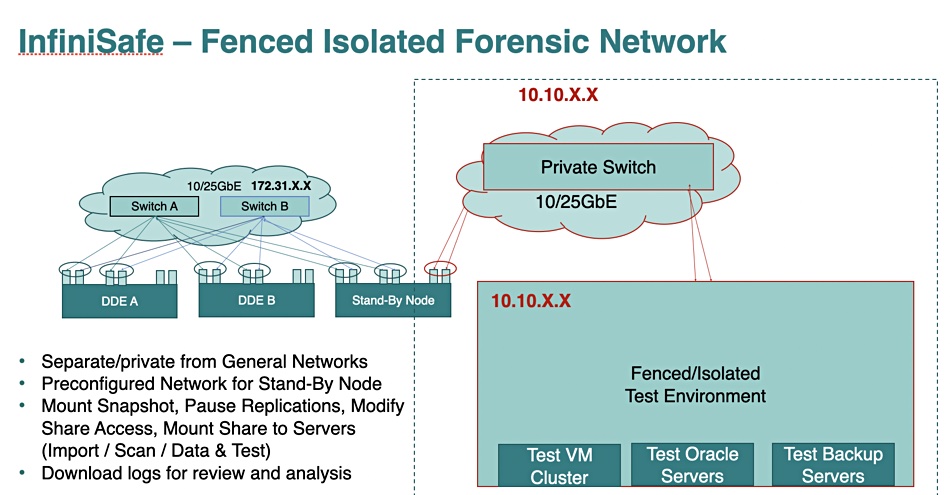
High-end storage array supplier Infinidat is making an InfiniSafe Cyber Storage guarantee for data recovery within one minute or less, and adding a performance guarantee too.
InfiniSafe was originally an InfiniGuard array which is fenced off and isolated from a customer’s main network via a private switch. It stores immutable snapshots and backups can be test restored inside this closed and isolated environment to find the last known good backup and recover uncompromised data in the event of a malware attack. An InfiniSafe Reference Architecture extended this to its InfiniBox and InfiniBox SSA II enterprise storage products.
Phil Bullinger
Infinidat CEO Phil Bulinger said in a statement: “With the introduction of our InfiniSafe Cyber Storage guarantee, our assured SLAs now span across availability, performance and recovery operations to meet the most demanding data center requirements.”
IDC Research VP Eric Burgener supplied a supporting quote: “With their new performance and cyber storage recovery guarantees, Infinidat is breaking new ground in these areas in ways that drive meaningful value for their enterprise customers.”
The guarantee is that enterprises and service providers recover and restore their data in the wake of a cyberattack by using a guaranteed immutable snapshot dataset with a guaranteed recovery time of one minute or less.
In June, VAST Data offered a “Zero Compromise Guarantee” for its all-flash Universal Storage arrays, with guarantees on uptime and data loss, fixed price maintenance for a decade, free access to future updates, and guaranteed best-in-class data reduction. We envisage that, given the VAST Data and Infinidat moves, other high-end array suppliers will follow suit, meaning Dell Technologies, HPE, IBM, and NetApp.
NetApp and OEM Lenovo have a storage efficiency guarantee dating from 2019. Also in 2019, Fujitsu offered an ETERNUS AF/DX Global Guarantee Program committing to zero downtime, data reduction and 100 percent SSD availability, some degree of customer satisfaction, and support for array expansion and growth.
Infinidat InfiniSafe graphic
Performance guarantee
Infinidat is adding a performance guarantee to assure customers that Infinidat’s primary storage products will outperform their existing storage products in production environments. The company says it works closely with customers to identify their specific needs for performance and analyze the requirements for each specific workload. Once the workload performance requirements are profiled, Infinidat then provides service level agreements (SLAs) aligned with the specific performance requirements profile and analysis of those workloads.
The company claims that its InfiniBox SSA II provides lower latency than any other comparable enterprise storage platform in the industry, delivering 35 microseconds.
The new guarantees join Infinidat’s existing 100 percent availability guarantee, which was announced in 2019. All four of the Infinidat SLA guarantees are available across all of its consumption models: FLX (storage-as-a-service offering), Elastic Pricing, and traditional purchase.
A customer lauded the guaranteed SLA concept. Laurent Ulrich, head of IT at Justice Court of Basel, Switzerland, said: “In this day and age, according to the cloud strategy we’re just writing, this kind of guaranteed SLA can make all the difference in the world for an enterprise and gives us peace of mind with Infinidat’s powerful commitment.”
An Infinidat blog will be posted to provide background context.
Sponsored It stands to reason that as enterprise apps get ever bigger and demand ever more data, storage infrastructure has to scale accordingly.
It’s become clear that software defined storage incorporating all-flash arrays, sophisticated data management tools, multi-thread CPUs, and large complements of memory, offer the best solution to the challenge.
But who should take the lead in building these systems? And what do storage architects need to know as they select the hardware and software that should be underpinning their strategy?
You can get a grip on all these issues by joining this Open Storage Summit session, Storage Intelligence for Data Growth, on August 25 at 10am PT / 1pm ET / 6pm BST.
The Register’s Timothy Prickett Morgan will be joined by Dilip Ramachandran, Sr. Director of Marketing at AMD, Devon Helms, Director of product marketing at Qumulo, and Matthew Thauberger, Supermicro’s vice president of strategy and business dev.
They’ll be picking apart the scale of the challenge facing organizations when it comes to coping with stupendous data growth, as well as catering for the applications and workloads that are causing it.
They’ll also break down the key considerations for customers when it comes to choosing the underlying hardware and software for their SDS setups, and consider how systems can be optimised for both on-prem and cloud requirements. And they’ll explain how they’re all working together to solve these problems.
Their aim is help you keep abreast of the latest storage techniques and advances, so you can make sure your organization stays in front. So, to get on top of the high performance storage agenda, just head here.
A Nutanix 8-K SEC filing reveals it’s planning to chop 270 employees, 4 percent of its workforce.
This follows “a review of its business structure and after taking other cost-cutting measures to reduce expenses. The headcount reduction is part of the Company’s ongoing efforts to drive towards profitable growth,” the hyperconverged software player says in the dcoument.
Nutanix expects to complete most of the headcount reduction by the close of its fiscal quarter ending October 31 (Q1 FY 2023). This action should incur a pre-tax charge in the range of $20 million to $25 million during this fiscal quarter, involving one-time severance and other termination benefit costs, all of which are expected to result in future cash expenditures.
This action comes before Nutanix has published its latest fiscal Q4 and full 2022 results. Third fiscal 2022 quarter results were announced in May, with revenues of $404 million, up 17 percent year-on-year, and a net loss of $111.6 million. It warned that supply chain issues with hardware partners and sales force attrition would cause weaker-than-expected sales for the remainder of its financial year.
President and CEO Rajiv Ravaswami said at that time: “We expect that these challenges in the supply chain are likely to persist for multiple quarters.“
Nutanix says it will announce its full 2022 results after US markets close on August 31.
Earlier this month, chief revenue officer Dominick Delfino resigned to join another company.
Nutanix has updated its outlook for its fiscal fourth quarter and full fiscal 2022 year with revenues, ACV billings, and non-GAAP gross margin expected to be at or above the high end of the respective prior guidance ranges and non-GAAP operating expenses expected to be in line with the prior ranges.
The hyperconverged pioneer is currently in a dispute with MinIO over its allegedly unacknowledged use of MinIO open-source object code. MinIO has revoked its license to use the code and expects Nutanix to stop shipping it as part of the Nutanix Object software.
We have asked Nutanix for further comment on the proposed job losses and the company said: “As an industry leader, Nutanix is constantly evolving to ensure we are appropriately positioned in the marketplace. Following a careful review of our business structure and after taking other cost-cutting measures to reduce expenses, we made the difficult but necessary decision to reduce our global headcount by approximately 4 percent. As hard as it is to make decisions that impact employees, we believe this will enable Nutanix to be more efficient and flexible going forward as we navigate a challenging macroeconomic environment. We are committed to treating our impacted employees with respect and supporting them through the transition.”
How does Micron view the world of CXL (Computer eXpress Link)? Blocks & Files had the opportunity to talk about this with Ryan Baxter, a Micron senior director of marketing and the segment lead for the datacenter (cloud and networking) area.
The background here is that Micron exited Optane (3D XPoint) manufacturing in favor of developing CXL-attached memory products in March last year. Seventeen months later, how has its thinking developed? We had a great conversation with Ryan, learning a lot, and have tidied the Otter.ai transcription of our messy questions and his answers.
Blocks & Files: What are your views on Optane and memory expansion?
Ryan Baxter
Ryan Baxter: When you looked at 3D XP, and the ability to use what was an interesting technology, you know, along several interfaces, the problem was that it was proprietary, right? There wasn’t a quote unquote, standard – it was a protocol defined by essentially a single company. And it was kind of stuck in its tracks because of the language standards.
Blocks & Files: How does Micron view CXL possibilities for its memory business?
Ryan Baxter: With CXL I think the the game has completely changed. The entire industry is behind the definition. Certainly when you when you look at media manufacturers, technology integrator groups, developers, software folks, everybody is all in and … singing from the same song sheet when it comes to CXL 2 or 3.0 standards. Everybody has a map this time, and everybody has a key to unlocking innovation. I think that’s really why it’s so different this time around.
It’s also generally a protocol that’s flexible, and extremely non-deterministic. … Customers really want that flexibility … to leverage CXL to expand memory footprint, to extend memory bandwidth to coherently leverage accelerators on the same exact electricals. … The building blocks just became significantly greater in terms of what you can do with with the server.
Fankly, servers needed something like this. Whether it was the CXL or something else that needed to come along, there’s very real near-term existential issues coming up right around the corner, from a server platform perspective. Core count growth [is] 20, 25 percent year on year … and from a memory innovation perspective, whether that be scaling in terms of capacity or scaling in terms of bandwidth, it’s nowhere near catching up or keeping up. Those cores need capacity, they need bandwidth. And the memory channels … aren’t able to keep up by themselves, and you need something like a CXL interface to help them out.
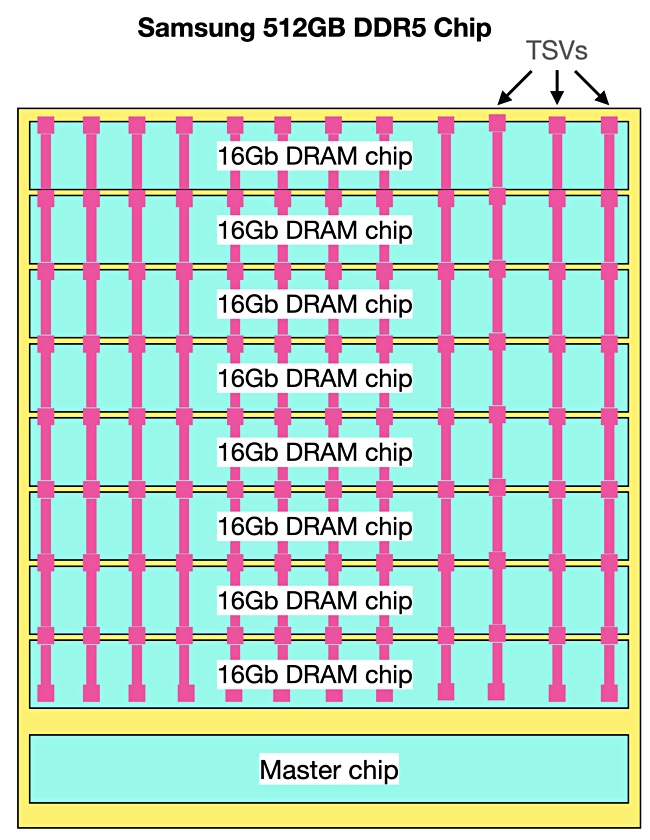
Blocks & Files: What about 512GB capacity DDR5 memory to increase memory capacity?
Ryan Baxter: A 512GB capacity is possible in DDR5, it certainly is. But what that leverages is stacked DRAM and in the DDR5 realm, because that DRAM has to signal at least 40 to 100 Mega transfers per second – that gets you out of the ability [to use] a traditional wire bond. Now wire bond is fairly cost-effective when it comes to industry feasibility. Once you have to go to a TSV-based stack because of the signal integrity, TSV, meaning through Through Silicon Vias, it’s both a front-end process as well as a back-end process and a number of steps required to get that stack just right. And that’s before you include yield loss associated with it. And so those 512GB modules, although possible, are extremely expensive.
Samsung 512GB DRAM diagram
Whenever you stack the RAM, and in a TSV-based fashion, your cost per bit goes nonlinear extremely quickly. You know, customers that are there, you know, kind of concerned about paying 35, 40, 45 percent of their entire system BOM cost. When you get into the mode of TSV-based items, that number becomes 60, 70 percent. And I don’t think anybody’s happy about that.
That’s why we embrace CXL. It really allows you to create a pressure release valve in the server. [It] really is required for customers to number one, meet their TCO goals and number two, for the industry to do full time innovation. It really is a standard for everyone and and it enables companies like Micron to really bring to the table innovative technologies for its customers that we never were able to do before because there simply wasn’t an interface available before.
Blocks & Files: You mentioned innovative technologies. Micron has standard DRAM and you have high-bandwidth memory. Are there going to be others?
Ryan Baxter: As a memory developer and manufacturer and supplier we are always looking at at new candidates outside of the standard DDR4 DRAM or 5 and HBM. We’re looking at all sorts of candidates. The hopper for our R&D is filled with really interesting technologies. … What’s interesting about CXL is it allows allows you to dial in the kind of interesting aspects of the technology you want to use and and not be shackled. … All of your media control is done on the backside and it’s obfuscated from whatever the user will have to do. Certainly we’re taking a hard look at potential candidates with nothing announced as of now, but the potential is there to to leverage more than just potentially DRAM or HBM or CX.
Micron 232-layer NAND wafer
Blocks & Files: Can I ask you about two particular types of possible innovative memory? One is 3D DRAM – is that something Micron is looking at, and the other is storage-class memory.
Ryan Baxter: We’ve made it public that at some point we’ll need to go to some some form of 3D DRAM just to maintain our our scaling capability in the standard DRAM roadmap. … Most certainly you’ll see 3D DRAM operate behind a CXL interface.
When it comes to storage-class memory again, we haven’t made any formal announcements … but certainly the capability is there, the potential is there. … Again, it’s a prime candidate for a media that can then bolt on CXL. Nothing formally announced but nothing that precludes us from being able to take a look.
Blocks & Files: Kioxia has announced a second generation of its XL_FLASH which is slightly faster than normal flash. The new generation has a great slug of MLC flash behind the SLC front end. That seems like a tiered SSD. I think Samsung’s has a drive with DRAM at the front and then NAND behind that. Both companies are using traditional technologies, standard DRAM, standard, NAND, without going to anything exotic like phase change memory or M-RAM or anything like that. Would that be Micron’s direction, rather than to go after exotic technologies?
Ryan Baxter: Nothing announced, as of now, but memory tiering or storage tiering is not a new idea. It’s been around for a number of years, perhaps decades. The reason is people want to take the best of one technology and combine it with the best aspects of another technology. In the case of tiered DRAM and NAND – you’re taking the the performance aspects of DRAM, and the cost and scalability aspects of NAND and pushing them together. Of course, in this world, nothing comes for free. You have to think about the implications on the entire stack for doing that meaning, how is your OS, your middleware, your applications? How are they going to have to adapt to be able to take advantage of it?
What about an exotic technology? It might be that that you want the persistence of a media that doesn’t forget, but you want it very fast, like DRAM. Maybe those two are the qualities you want to combine in this emerging media. There are gaps when you when you look at DRAM when combined with with NAND, when you look at other standard technologies combined with other standard technologies. … And that’s where emerging media comes into play – where we feel that there are a number of gaps. … That still lies sort of unaddressed, if you will, and … that’s why you would choose a non-traditional media to fill those gaps.
Comment
Ryan couldn’t comment on the Memory Coalition of Excellence idea being promoted by Micron and Western Digital – the news had broken to recently for that. MIcron today announced, in connection with US CHIPS and Science act, it was going to invest $40 billion in building semiconductor fabs in the USA between now and 2030.
Our sense of Micron’s storage-class memory thinking is that it is far from announcing any product effort involving exotic new technologies, such as some resistive RAM variant. We think tiered DRAM and tiered NAND drives might be working their way through its R&D labs, and that 3D NAND is present there as well.
TSV-based stacked DRAM was not viewed favorably at all. Our take-away thinking is that Micron is set on developing its 3D NAND and on developing 3D DRAM that can sit on the CXL link. Tiered memory products that are accessed over CXL seem a little less likely.
Chinese and US computational storage developer ScaleFlux has shown its CSD 3000 at the Flash Memory Summit and launched a channel program.
This is a PCIe 4 SSD with TLC flash, an NVMe interface, and ASIC based around an eight-core Arm processor with various hardware acceleration engines for compression and other storage-related functions. The previous CSD 2000 used an FPGA instead of an ASIC and was PCIe 3-based.
ScaleFlux CEO Hao Zhong told us: “This is a big shift and a huge investment.”
Computational storage offloads a host server processor by carrying out low-level and repetitive storage computations on the drive such as compression, encryption, and erasure coding. This avoids data transfer to and from the host’s DRAM, saving both time and electrical energy. Moving from an FPGA to an ASIC system-on-chip increases performance and decreases cost.
Performance:
Sequential read – 7.1GB/sec
Sequential write – 4.1GB/sec
Random read (4kB) – 1,500,000 IOPS
Random write (4kB) – 370,000 IOPS
Random write performance is boosted with compressible data up to 700,000 IOPS. A downloadable data sheet provides more details.
There are 4, 8, and 12TB capacity levels on offer with the CSD 3000, beating the 2000’s 4 and 8TB raw capacity limits. The CSD 2000 came in U.2 (2.5-inch) and a half-height, half-length add-in-card (AIC) format, and the newer product adds the E1.S format as well. It also has a capacity multiplier feature in addition to the CSD 2000’s hardware gzip compression, enabling it to reach an up to 4x compression ratio compared to the CSD 2000’s 2x.
There is no video transcoding acceleration, as Zhong explained: “Video transcoding needs an ASIC codec chip and we’re not integrating this at this time.”
The CSD 3000 has an API open to customers and ScaleFlux offers customization services.
We asked about ScaleFlux’s growth, and Zhong said: “We grew pretty strong in the pandemic.” When we mentioned competitor NGD’s difficulties, he said: “You need a very good baseline to make a product that’s enterprise-ready, and it’s costly to develop an enterprise-class baseline.”
ScaleFlux sold its initial CSD 1000 and then the CSD 2000 direct to customers, gaining some 50 CSD 2000 customers. It hopes to pass the 100 mark with the CSD 3000, supplying it to hyperscalers, CSPs, and OEMs, and has launched a channel program to help reach that goal. It is not a retail or consumer product. Eric Pyke was hired as VP business development in March this year along with four other go-to-market execs – one of whom is Marissa Strunk, director of channel sales.
ScaleFlux was founded in 2014 and is funded by SK hynix, Micron, AMD (Xilinx), and others along with financial investors. We think it’s taken in around $59 million in funding, with the latest round in 2021 for an unrevealed amount.