Qumulo has updated to its scaleout filer software to support 265 nodes in a cluster, added support for new third-party hybrid NVMe platforms and will add SMB protocol enhancements.
The company supplies scaleout Core filer software that runs on its Qumulo-branded hardware (P, C, K series) and also third-party file storage systems. These can be hybrid NVMe systems, including disk drives and NVMe SSDs. All data on Qumulo is written initially to SSD storage, delivering flash-level write performance. As data ages, Qumulo’s software monitors how often the data is re-accessed, moving it to the HDD layer as it “cools.”
Kiran Bhageshpur
Kiran Bhageshpur, Qumulo CTO, said in a statement: “Customers often feel stuck using a vendor’s exclusive hardware and are subject to price hikes, technological limitations, and even supply chain risk. We enable our customers to use their platform(s) of choice while making data management simple.”
The 265-node limit for a Qumulo cluster is a 165 percent uplift from the previous 100 limit. It means a clusters can scale to higher capacity. However, Qumulo web documentation, “Supported Configurations and Known Limits for Qumulo Core” says the On-Premises Cluster Size limit is 275 nodes while the Cloud Cluster Size limit is 100 nodes. Qumulo said there is documentation error and the upper limit should be 265, not 275. It is being corrected.
Dell PowerScale F900 clusters can be expanded to a maximum of 252 nodes.
A source close to Qumulo told B&F: “There was never any real hard limits for nodes. … For a time [the product management VP] wouldn’t allow anything larger than 50 nodes. Then a customer did it on their own – so they limited it to 100 nodes, and the same thing happened. They put a limit in code and the uplift to 265 is simply based on a customer wanting to grow their nodes beyond the current limitations.”
The uplifted cluster node limit means the maximum cluster capacity has expanded from 34.2PB to 100.7PB, an almost 3x increase. Cluster capacity can vary with the Qumulo model and hardware vendor.
Qumulo says it has added certifications for three new hybrid NVMe platforms offering 35-110 percent greater performance vs existing hybrids. The newly supported systems are:
HPE Apollo 4200 Gen10+ (as compared to Gen10)
SuperMicro A+ ASG-1014S-ACR12N4H (no previous hybrid on SuperMicro)
A whitebox solution from Arrow Electronics, Quiver 1U Gen2 Hybrid (replaces Arrow’s 1U SATA-based hybrid offering)
A Qumulo pitch is that its architecture allows customers to consolidate many workflows onto one system. It says five new workloads will soon be enabled by SMB protocol enhancements and S3 support. These new workloads are:
8K Native Video Editorial in the AWS Cloud (SMB MC)
Philips (formerly Algotec) PACS (SMB MC)
Media Ingest / Watch Folders (SMB CN)
Data Analytics with Hadoop/SPARK (S3)
Hybrid Cloud/Remote Access (S3)
Qumulo CEO Bill Richter said: “Our fundamental vision is to enable massive scale, simple operation, deployable anywhere a customer chooses. Qumulo ensures customers have the freedom to pick where their data resides… Customers can run in the cloud, on-premises in their datacenter, or at the edge.”
The post 2023 world is going to see an explosion in structured data alongside the flood of unstructured data, at least according to French data manager and protector Atempo.
Louis-Frédéric Laszlo
It is a truism that 80 percent of the world’s data is unstructured (file and object) and growing. Louis-Frédéric Laszlo, Atempo VP of product management told an IT Press Tour briefing about Atempo’s view of what’s happening in 2023, detailing incremental developments for its Miria, Tina, Lina and Continuity software, but then surprised his audience.
He said he ”sees the structured and unstructured worlds converging with a need for unified storage.” That means a single piece of storage software will be able to handle blocks, files and objects, as Ceph does today.
For Atempo, although no details were revealed, it surely means its data managing, moving and protection software products will have to operate in a unified block+file+object world.
Atempo product positioning.
Laszlo also said: “For File, VM, Emails – think object first.” This is another turnaround.
Data management and data protection have to recognize these changes and Atempo wants to work towards offering a unified data management platform.
We have not heard similar views from its competitors, such as Data Dynamics and Komprise, but, unless Atempo is talking to different analysts, they may be coming around to the same point of view.
The short term roadmap, for next year, has four pillars: end-to-end data immutability, data integrity, cost reductions for unstructured data storage, and sustainability, meaning carbon emission reductions, which should equate to savings in customer energy use with its products.
The E2E immutabiity has immutability on each storage tier apart from tier one production data. It encompasses both protection data and production data on the secondary tier, such as nearline disk storage. File systems can have an immutability flag and, when set, a new file version becomes a fresh file or object. Naturally S3 object lock will be supported.
Data integrity will involve background scanning to combat ransomware, sanity checks before VM restarts and data retrieval, and testing to validate automatic restarts.
Atempo’s data analytics functionality will be extended to provide automatic tiering based on storage costs. Self-service data movement will supported as well. This use of analytics to drive cost reduction will also be used to drive storage energy reduction, with a revival of tape storage as the low-cost and low energy-use storage medium. We think it will be possible to see the storage energy usage levels via a dashboard report or graphical display, and arrange data placement to lower energy use.
It would not be a surprise to see Data Dynamics, Komprise and other vendors introduce similar functionality.
Looking for a niche service perhaps too small for NetApp’s ONTAP engineering crew? Cleondris, a Switzerland-based NetApp skunkworks, might get involved. The firm, which has a big presence in add-on software for NetApp ONTAP storage systems, includes a 10-person engineering team and was first started in 2006 by comp sci PhD Dr Christian Plattner, who built software for enterprises.
Plattner became involved in the NetApp-VMware integration area in 2010 and Cleondris was registered as a global technical NetApp Alliance Partner in 2011.
Plattner told an IT Press Tour that Cleondris’ focus is purely on NetApp, mostly ONTAP, and it works on projects that are either too small and tactical for NetApp’s ONTAP engineering organization or need completing in a vastly shorter timeframe than the sometimes slow-reacting and political ONTAP engineering organization can manage, particularly for customer deals in the German-speaking regions of Europe.
Its main product is a Data Manager offering but its NetApp history started with an ONTAP backup facility in 2010, an ONTAP clustering product in 2012 – Cleondris supports 7-mode and 8-mode ONTAP by the way – followed by SnapDiff (2014), FPolicy (2016) and SnapMirror Cloud (2020) products.
It has three product families:
The Data Manager product pays most of Cleondris’s bills, while the HCC product, focused on Solidfire, is now obsolete and being discontinued. In the Data manager product, Plattner said, the restore options are wide-ranging and protection is snapshot-based, meaning there is no agent in each VM. Snapshot-based backup is good enough, he said.
Cleondris supports NetApp’s SnapMirror Cloud in Data Manager. It said this orchestrates and manages backup and recovery of data on ONTAP systems directly to Object storage (S3) using SnapMirror Cloud technology. Via ONTAP APIs integration, Cleondris backs up data from ONTAP using the native NetApp data mover directly to object stores – be it an S3 bucket in the public cloud or on-prem S3 like NetApp’s own StorageGRID. Cleondris provides a file catalog that scales to billions of files and allows for search and restoration of files and directories from S3 back to ONTAP.
Plattner said that, by using SnapMirror Cloud, customers can replace tape backups and keep thousands of snapshots in S3. The archived data is always available and can be recovered quickly.
He told the briefing attendees that, in the early VMware-NetApp integration days, there was a relatively bare-bones link between the two environments and a large German bank, a NetApp customer, had a Helpdesk problem. It found that their Helpdesk VMware people could access the NetApp storage array management but didn’t know how to navigate through the options as they couldn’t understand the, to them, complicated software entities and relationships in NetApp’s ONTAP software world.
Likewise the ONTAP helpdeskers could access the VMware vSphere environment but, having little or no VMware knowledge, were effectively blind. The customer told NetApp to fix it or remove the ONTAP filers. Plattner said the Sunnyvale ONTAP engineers said it was a tactical local problem, not a strategic one for them to fix. The German NetApp team and partner then asked Plattner to fix this and fix it quickly.
Cleondris developed interface software so the help desk staff could operate in the ONTAP and VMware SW territory better, and rescued the deal.
Plattner’s use of FPolicy for ransomware exemplifies Cleondris’ expertise. FPolicy is an ONTAP feature that watches every IO. It lets a file be set as immutable and no one can then change its status. In 2015 Cleondris set up a copy policy and then set the copies immutable, and this was the basis of a ransomware protection element in the SnapGuard offering.
Eventually, late last year, six years later, NetApp developed its own ransomware protection features within ONTAP. Plattner claimed: “No one knows how it works.”
Cleondris is still reacting quickly to NetApp developments; it supported AWS FSx for ONTAP from day one. Plattner said Cloud Volumes ONTAP (CVO) is a NetApp-managed ONTAP-as-a-service offering. “AWS FSx for ONTAP is effectively the same code but managed by AWS.”
Plattner said Cleondris has always been profitable and has never raised any outside funding. He and the other Cleondris engineers will not develop software for other storage suppliers’ systems. Retaining the trust of NetApp’s sales people is paramount in its business model and the business thus does not help sell competitors’ products.
There you have it. View Cleondris as a niche external engineering skunkworks for NetApp systems and customers.
Blocks & Files wanted to look more deeply into Xinnor’s claims about its faster-than-RAID-hardware software for NVMe SSDs, xiRAID, particularly in light of its performance tests results. We questioned Dmitry Livshits, Xinnor’s CEO, about the tech.
Blocks & Files: Can Xinnor’s xiRAID support SAS and SATA SSDs? What does it do for them?
Dmitry Livshits
Dmitry Livshits: Although xiRAID was designed primarily for NVMe, it can also work very well with SAS/SATA SSDs.
You just need to make sure that the server OS is properly enabled for multiple queues, that schedulers are properly selected, and that multipath is configured. We have guidelines for that.
There are some nuances that have to do with the capabilities of the SAS HBA controller, but in general there are no problems. NVMe has several significant advantages over SAS/SATA, but let’s not forget that SAS JBOD is the easiest and cheapest way to add flash capacity to a server or a storage system not to mention many SAS backplane-enabled servers are out there in the field.
We tested JBOFs from various vendors with xiRAID and got results close to 100 percent of IOM throughput. (Several dozen GBps with RAID5 and RAID6). The main nuance with SAS/SATA is random write operations. These generate additional reads and writes and as a result, the HBA chip gets clogged with IOs and performance is lower than expected.
Blocks & Files: When xiRAID is working on an HDD system how does it manage RAID rebuilds and how long do they take?
Dmitry Livshits: To work with spinning disks, we make several important changes to the xiRAID code, without which RAID is extremely difficult to use
Support of caching mechanisms with replication to the second node (for HA configurations)
Array recovery using declustered RAID technology
The basic idea of this technology is to place many spare zones over all drives in the array and restore the data of the failed drive to these zones. This solves the main problem of the speed of array rebuild.
Traditional RAID rebuild is limited by the performance of 1 disk that is being written. And disk performance growth is quite minimal these days, as the manufacturers are getting closer to areal density limits, since only one head is active at a time. At the same time, drive capacity is mostly increasing by adding more platters, so there’s a clear downward tendency for the MBsec per TB ratio. There are dual-actuator drives that are helping to some extent, but they’re not easily accessible and even with doubled performance still take a long time to rebuild. Today the largest CMR drive is 22TB, next we can expect 24TB and more after that.
The task of placing spare zones for recovery, for all its simplicity at first glance, is a serious problem. The zones must be set up so that they maintain the required level of fault tolerance and at the same time provide the best possible load balancing – the highest possible rebuild rate.
We spent about a year researching and making these “maps” and we hope to introduce our declustered RAID to the market in 2023.
Blocks & Files: Is xiRAID a good fit with ZFS and what does a xiRAID-ZFS combination bring to customers?
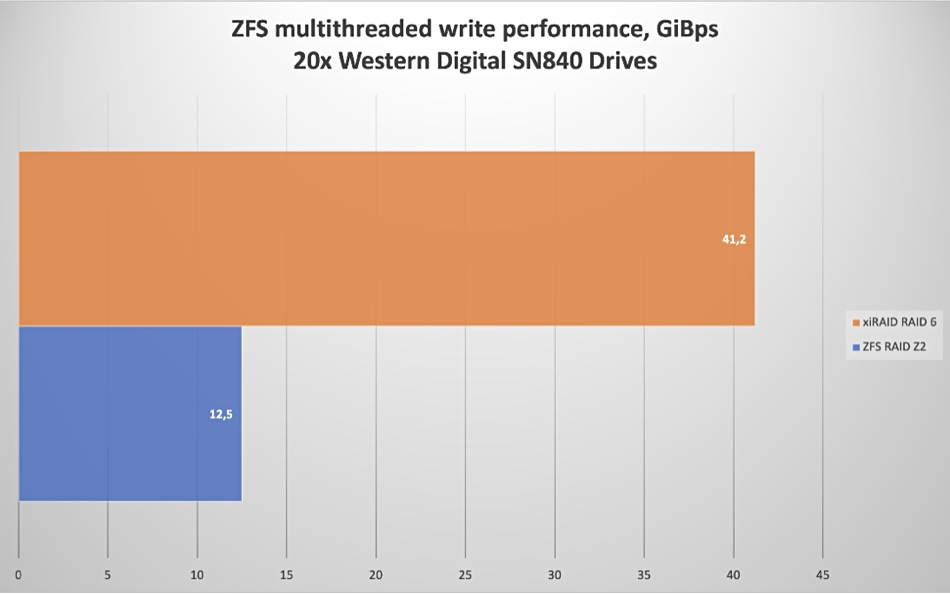
Dmitry Livshits: Now that we see many systems emerging with PCIe Gen5, the main interconnect for HPC and AI will switch to 400Gbps. Also, in HPC one of the most in-demand PFS (parallel file system) is Lustre, which uses ZFS as the back-end file system at the OSS level. The ZFS-integrated RAIDZ2 limits the write speed to 12.5 GBps, and this presents a major bottleneck. Replacing RAIDZ2 with striping is risky and mirroring doubles the cost. As a result, we get an unbalanced storage system that should be able to do much more, but in fact doesn’t utilize the underlying hardware fully. The ZFS developers understand the bottlenecks and made changes to improve performance, such as DirectIO.
By placing ZFS on top of xiRAID 6 we were able to increase the performance of sequential writes by several times, fully saturating 400 Gbit/s network.
Xinnor chart showing xiRAID performance with ZFS
Now we have work to do to optimize random small IOs.
Blocks & Files: Can xiRAID support QLC (4bits/cell) SSDs and how would a xiRAID+QLC SSD system look to customers in terms of latency, speed, endurance and rebuild times?
Dmitry Livshits: Logical scaling is one of the main ways to make flash cheaper, but it has several trade-offs. For example, QLC Solidigm drives have a very good combination of storage cost and sequential performance levels, they are even faster than many TLC-based drives at 64k aligned writes, but once you try small writes or unaligned, the drive’s performance drops drastically and so does endurance.
Today xiRAID can be used with QLC drives for read-intensive workloads and for specific write-intensive tasks that have large and deterministic block sizes, so that we can tune IO merging and array geometry to write fully aligned pages to the drives.
For non-deterministic workloads and small random IO, that’s not a good case for QLC, [and] we would have to develop our own FTL (Flash Translation Layer) to properly place data on the drives. But FTL requires significant processing resources, and it could potentially be a good addition to xiRAD when the product will have been ported to run on DPU/IPU.
For large capacity SSDs, our declustered RAID functionality under development will be very useful.
Blocks & Files: I understand xiRAID runs in Linux kernel mode. Could it run in user space and what would it then provide?
Dmitry Livshits: Yes, we started to develop xiRAID as a Linux kernel module so that as many applications as possible could take advantage of it without modification. Today we see a lot of possibilities to work inside SPDK, the ecosystem developed by Intel to use storage inside the user space. The SPDK itself does not have a data protection mechanism ready to use right now. RAID5f still does not have the functionality needed and is limited in use because only whole stripes must be written. xiRAID ported to SPDK will have full support for all important RAID functions, the highest performance on the market and work with any type of IO.
On top of that, it is designed with disaggregated environments in mind:
With smart rebuilds for network-attached devices (there’s more on that in one of our blogs on xinnor.io, but basically, we manage to keep the RAID volume online through many potential network failures, unless they happen to affect the same stripe).
RAID volume failover capability in case of host failure.
This should already make xiRAID interesting for current SPDK users who today need to use replication. Also, moving to SPDK and user space makes it much easier to integrate xiRAID with other vendors’ storage software.
Blocks & Files: Could xiRAID execute in a DPU such as NVIDIA’s BlueField? If so what benefits would it bring to server applications using it?
Dmitry Livshits: xiRAID alredy can run on DPU, but we want to use the SPDK ported version for further development. This is because the key DPU vendors rely specifically on the SPDK as part of their SDKs: Nvidia and the open source ipdk.
A DPU solves two important tasks at once: offloads storage services (RAID, FTL, etc.) and provides an NVMf initiator.
We have done a lot to make xiRAID consume a very modest amount of CPU/RAM, but still a lot of customers want to see all their server resources allocated to the business application. Here a DPU helps a lot.
Another advantage of a DPU that we see is plug-n-play capability. Imagine a scenario where a customer rents a server from a service provider and needs to allocate storage to it over NVMf. The customer has to set up a lossless network on the machine, the initiator, multipathing, RAID software and volumes. This is a challenge even for an experienced storage administrator, and the complexity could be prohibitive for many IaaS customers. A DPU with xiRAID onboard could move this complexity from the customer-managed guest OS back into the provider’s hands, while all the customer sees is the resulting NVMe volume.
We link our future with the development of technologies that will allow the main storage and data transfer services to be placed on a DPU, thus ensuring the efficiency of the data center. Herein lies our core competence – to create high-performance storage services using the least amount of computing resources. And if I briefly describe our technology strategy, it goes like this:
We develop efficient storage services for hot storage technologies
Today we make solutions for disaggregated infrastructures and DPU
Soon we will start to optimize for ZNS and Computational Storage devices
Blocks & Files: Could xiRAID support SMR (Shingled Magnetic Recording) disk drives and what benefits would users see?
Dmitry Livshits: Same as with QLC devices, we can work with Drive-Managed and Host-Aware SMR drives in deterministic environments characterized by read-intensive or sequential write loads: HPC infrastructures (Tier-2 Storage), video surveillance workloads, backup and restore. All three industries have similar requirements to store many petabytes with high reliability and maximum storage density.
SMR allows us to have the highest density at the lowest $/TB.
xiRAID with multiple parity and declustered RAID gives one of the best levels of data availability in the industry.
Host-managed SMR and other use cases require a translation layer. This is not our priority, but as software we can be easily integrated into systems with third-party SMR translation layers.
Blocks & Files: The same question in a way; could xiRAID support ZNS (Zoned Name Space) drives and what benefits would users see?
Dmitry Livshits: Like host-managed SMR, zoned NVMe will require us to invest heavily in development. We have already worked out the product vision and started research. Here again, we see FTL as a SPDK bdev device functioning on a DPU.
This would allow customers to work with low-cost ZNS drives, which by default are not visible in the OS as standard block devices, without modifying applications or changing established procedures, and all extra workloads would stay inside the DPU.
Blocks & Files: What is Xinnor’s business strategy now that it has established itself in Israel?
Dmitry Livshits: We are looking at the industry to see where we could add the most value. The need for RAID is ubiquitous – we’ve seen installations of xiRAID in large HPC clusters and 4-NVMe Chia crypto miners, in autonomous car data-loggers and in video production mobile storage units.
We definitely see HPC and AI as an established market for us, and we’re targeting it specifically by doing industry-specific R&D, proof of concepts and talking to HPC customers and partners.
We are also working with the manufacturers of storage and network components and platforms. RAID in a lot of cases is a necessary function to turn a bunch of storage devices into a ready datacenter product. Ideally, we are looking for partners with expertise to combine our software with the right hardware and turn the combination into a ready storage appliance. We believe that xiRAID could be the best engine under the hood of a high-performance storage array.
And of course, we are looking for large end-users that would benefit from running xiRAID on their servers to reduce TCO and improve performance. After all, RAID is the cheapest way to protect data on the drives. With the industry switch to NVMe, the inability of traditional RAID solutions to harness new speeds is a big issue. We believe that we’ve solved it.
Micron has launched a 232-layer client SSD – the first 232-layer NAND after Yangtze Memory Technology to pass the 200-layer boundary – and the diskmaker reckons it’s a winner thanks to its responsiveness and low power draw.
The 2550 is an NVMe drive with a PCIe 4 x 4 interface that comes in 256GB, 512GB, and 1TB capacity points – the same as the preceding 176-layer 2450. It has the same host memory buffer and M.2 format in three sizes: 2280mm, 2242mm, and 2230mm, to give PC and notebook OEMs flexibility in its use.
Praveen Vaidyanathan, VP and GM of the Client Storage Group at Micron, issued a quote: “We focused on delivering a superior user experience for PC users with this SSD. [Its] capabilities deliver impressive application performance and phenomenal power savings.”
Micron 2550 drive’s M.2 formats
These savings are real. The existing 2450 uses <3mW in sleep power state and <400mW in active idle power state. Its active read power consumption is <5.5 watts. Micron has optimized the low power states with the 2550 and it uses <2.5mW in sleep and <150mW in its active idle power state. Active read power consumption is the same <5.5 watts. These power savings – which Micron credits to optimized entry into self-initiated low power states – will help extend notebook battery life.
The performance improvements are real as well. The 2550 has a 6-plane NAND die with an independent word line on each of the six planes allowing concurrent reads. It also has predictive cache loading for its on-drive dynamic SLC cache.
The 2450 put out up to 3.6GBps read bandwidth and up to 3GBps write bandwidth. The 2550 ups these maximum numbers to 5GBps and 4GBps – noticeably faster. The maximum IOPS numbers are similarly improved, with the 2450’s 450,000/500,000 random read/write IOPS becoming 550,000/600,000 with the 2550 – noticeably faster again
Micron says it has better performance on the PCMark 10 storage performance benchmark than competitors:
Its endurance is the same as the 2450: 256GB – 150TBW, 512GB – 300TBW, and 1TB – 600TBW, with a 2 million hours MTTF rating. On this basis and with the improvement over the 2450’s performance and power consumption it should find a positive reception from its PC and notebook OEMs.
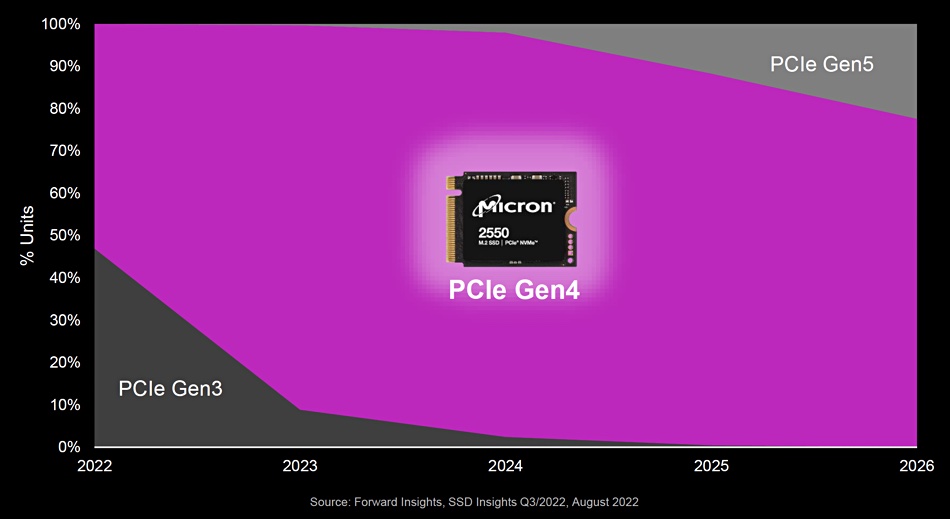
Micron believes that PCIe 4 is going to become the SSD sweet spot over the next few years, based on forecasts by analyst house Forward Insights, and has no revealed PCIe 5 client SSD plans.
China’s YMTC launched a 232-layer NAND chip using its Xtacking 3 technology last month, according to TechInsights. YMTC’s business has been compromised by technology export restrictions imposed by the USA. SK hynix has a 238-layer chip in development and Samsung one using 236 layers; all pretty much the same and >230-layers becoming table stakes.
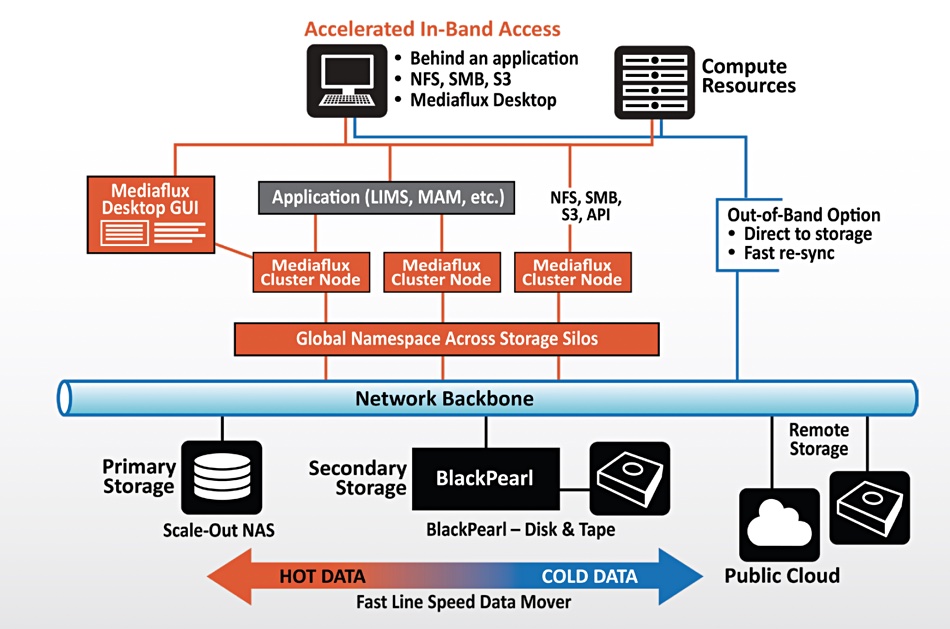
Australia-based Arcitecta has developed a product which provides continuous inline data protection for files and objects with zero RTO and near zero RPO, and rollback in milliseconds to any point in time.
The Mediaflux Point in Time product is based on metadata found in Arcitecta’s Mediaflux hyper-scale XODB database. Mediaflux itself is an unstructured data management platform, a silo-aggregating software abstraction layer with a single namespace. It can aggregate files, and also objects on disk or tape or, we understand, SSDs, be these drives on-premises or in the public cloud and store their details as compressed metadata in its database. The software has a data mover and can place files in the appropriate storage tier. The database can be accessed via NFS, SMB, sFTP, Dicom, S3 and other protocols via mount points or shares.
Jason Lohrey.
Jason Lohrey, Arcitecta’s founder, CEO and CTO, said in a provided statement: “We are now in the Data Age, where data volumes quickly grow to billions and trillions of files. Terabytes of data are rapidly becoming petabytes to exabytes of data and beyond. Traditional methods of backing up data are unviable at those scales.”
That consigns the whole gamut of traditional data protection suppliers; Acronis, Asigra through Cohesity, Commvault, HYQU, Rubric and on to Veeam and Veritas to history. Lohrey thinks: “Organizations need a new approach to backup and recovery designed for the scale and complexity of today’s data demands. With Mediaflux Point in Time, we are redefining petabyte-scale data resilience and enabling enterprise organizations to eliminate the cost and business impact of lost data.”
We are told the Point in Time product integrates metadata-based, continuous inline data protection into Arcitecta’s Mediaflux data fabric, placing data protection in the data path as an integral part of the data fabric and file system. When a data recovery is needed the XODB software can be instructed to roll back to a point-in-time at the seconds level and restore a file or object pretty much instantly.
Arcitecta diagram showing Mediaflux working with Spectra Logics Black Pearl.
Mediaflux PIT provides zero data loss as every structural and data change in the protected data sources is captured in real time by Mediaflux and recorded in the XODB database, ready for Mediaflux PIT to do its work. If there is a ransomware attack users can simply scroll a time-slider in a GUI, to roll back the entire file system structure to a point before the loss occurred. Mediaflux PIT can unwind the damage in, it says, at most, minutes – rather than days, weeks or more.
It has a self-service feature. Users can connect via their standard credentials to access the single, global namespace and find their data, using wildcard searches. They can, we’re told, find files in milliseconds, no matter when and where they existed, and even in a population of billions of files or more.
Arcitecta says its Mediaflux software can dynamically add or remove storage as required and mix technologies of different types from different vendors. The software can run on dedicated hardware, in virtual machines or containers, on-premises or in cloud infrastructure or any combination.
Position Arcitecta in your mental landscape alongside Data Dynamics, Komprise and Atempo, as a Coldago report suggests, and also with data orchestrator Hammerspace.
Mediaflux Point In Times is available now as a component of the Mediaflux platform. Contact Arcitecta for more info’.
Djuno is a supplier of AI technology that helps businesses optimize their cloud IT infrastructure for better performance and lower cost. A spokesperson got in touch and said that its CEO and Solution Architect Mohammad Sayadi believes that businesses need to embrace Web3 storage. This decentralized storage, they said, shifts control and decision-making from a centralized entity to a distributed network, which creates a trustless environment, improves data reconciliation, reduces points of weakness, and optimizes resource distribution.
He would be happy, we were told, to share his expertise on the following talking points:
How Web3 storage is going to change enterprise backup;
How companies can implement IT decentralization solutions;
Differences between the main network architectures: centralized, distributed, and decentralized;
We took him at his word and asked him a set of questions about these points to find out more.
Blocks & Files: What are the differences between the main network architectures: centralized, distributed, and decentralized?
Mohammad (Moe) Sayadi.
Mohammad Sayadi: Centralized network architecture refers to the architecture where systems and components in the systems are managed, permissioned, and orchestrated by one or multiple authorities, meaning that there is a central command center that decides how the system should run, who can access it, and what permissions are granted.
Centralized systems do not necessarily require having all the components be on the same underlying machine or infrastructure. Thanks to modern technologies such as cloud computing, Kubernetes, and containerization, systems can be heavily and geographically distributed but still managed, organized, and orchestrated in a centralized manner.
A decentralized network is a network configuration where there are multiple authorities serving as a centralized hub for the participants. In the computing world, a decentralized network architecture distributes workloads among several machines instead of relying on a single central server.
Blocks & Files: What are the benefits of decentralized architectures?
Mohammad Sayadi: There are many downsides and upsides for each network architecture, however, the biggest benefit of decentralized systems is – from my point of view – censorship resistance. Due to the lack of a central authority that controls everything, decentralized networks cannot censor or de-platform anyone due to their race, sex, age, etc.
Secondly, I believe that another benefit of the decentralized architecture is that of being trustless – a decentralized system does not rely on an authority, person, or organization to perform tasks. In contrast, the system is self-organized – it performs tasks via consensus among the network participants. This contributes to cutting out the middleman, hence lowering the price of services for parties.
And lastly, centralization also means a single point of failure in terms of security and availability.
Blocks & Files: Can we have decentralized architectures without cryptocurrencies? If not, then why not?
Mohammad Sayadi: Yes and no – a bit tricky question. Yes, it is possible to have a system organized and orchestrated in a decentralized manner. However, there should be a fair incentivization mechanism that incentivizes contributors in the network in a way that generates behaviors that are beneficial for the functioning of the system. However, this doesn’t mean that you need to build a complete blockchain to implement a Web3 storage architecture, as this introduces unnecessary performance limitations.
One alternative approach is to create a “headless” blockchain solution (or a “parachain” that attaches to a layer 1 blockchain) that is blockchain-agnostic and can be attached to any crypto ecosystem so that each side can focus on what it’s best in. (This is the approach we have adopted in djib.io).
Blocks & Files: Is Web3 storage enterprise-grade?
Mohammad Sayadi: There are three main pillars that underpin the entire digital world: network, computation, and storage. These three are the main fundamental cloud services too. In a better world, a digital application requires these three elements to be up and running, serving its clients. Currently, there are many various centralized storage technologies offered and orchestrated by cloud service providers and other infrastructure entities, but true enterprise-grade Web3 storage is just being developed.
Issues that are being solved in the field of performance and security are speed of access (via multi-CDN architecture), as well as security through decentralized key management systems (DKMS) to properly handle the management and delegation of access rights.
Blocks & Files: Is Web3 storage going to change enterprise backup?
Mohammad Sayadi: Web3 is not mature enough to be suitable for enterprise backup. I believe in backup, especially enterprise. There are well-managed procedures and well-developed mechanisms that ensure compliance of backup with regulatory bodies and enforce access segregation, etc.
I would suggest using Web3 storage technologies in different areas than backup storage services. Why? Let us look into what essentially Web3 storage offers you. Web3 technology offers you full ownership (less attractive for enterprises), trustless automation (very interesting for enterprises), and open standards (attractive for enterprises too). With this definition, I would say it may be good to use trustless automation to ensure compliance in a business process such as backing up rather than permanent storage.
Forrester has looked at the multi-model database market – what it calls translytical products – and decided that Oracle has the top translytical technology, with GigaSpaces last.
Forrester senior analysts and VPs Noel Yuhanna and Mike Gualtieri have produced a report called “TheForrester Wave: Translytical Data Platforms, Q4 2022“. In it, they define translytical platforms as “next-generation data platforms that are built on a single database engine to support multiple data types and data models. They are designed to support transactional, operational, and analytical workloads without sacrificing data integrity, performance, and analytics scale.”
The characteristics of such software products include optimization for both reads and writes, distributed in-memory architecture, multi-model, advanced workload management, AI/ML, and cloud architectures to support modern workloads. Example workloads are real-time integrated insights, scalable microservices, machine learning (ML), streaming analytics, and extreme transaction processing.
Forrester analyzed 15 vendors – the top vendors in the market place in its view, and not an exhaustive list. A table lists the vendors and their products:
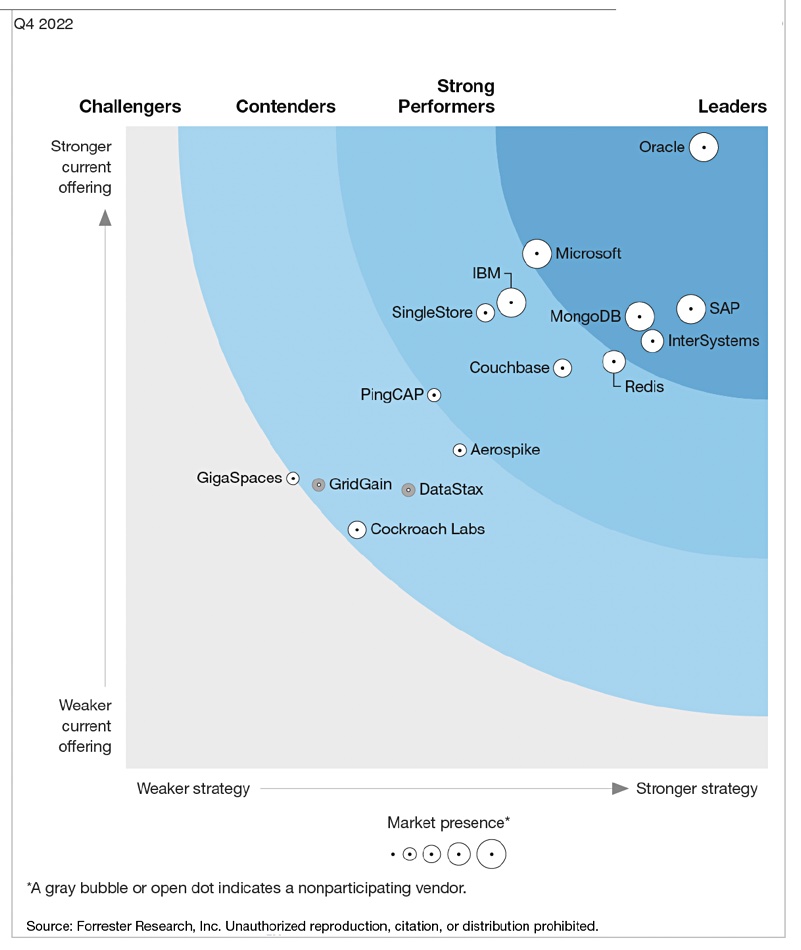
These are ranked in a Wave diagram, in sections called Challengers, Contenders, Strong Performers and Leaders – a typical four-way analyst’s way of grouping vendors. They occupy curved quadrants in a square space defined by a vertical weaker-to-stronger current offering axis and a weaker-strategy-to-stronger-strategy horizontal axis. The size of a vendor’s circular symbol indicates its market presence, with a bigger symbol equalling a stronger presence. Naturally the symbols tend to get bigger as we move from bottom left to top right in the Wave space.
There is only one challenger – GigaSpaces – and it’s on the boundary between Challengers and Contenders. There are five Contenders: Cockroach Labs, GridGain, DataStax, Aerospike and another boundary sitter, PingCAP. We have four Strong Performers, whose names may be more familiar: SingleStore, Couchbase, IBM and Redis.
Five vendors are in the Leaders section: Microsoft, InterSystems, MongoDB, SAP and the runaway number one, Oracle.
Then the report lists each vendor in turn, discussing their strengths and weaknesses. The leaders’ highlights start with Oracle, which has strong translytical capabilities in architecture, fault tolerance, multi-model, data modeling, transactions, analytics, access control, data protection, and performance. It has challenges relating to its ability to scale dynamically, the need for advanced database administration skills, and high initial cost. It also needs to improve its support for streaming, search, and developer tools.
SAP is strong in data modeling, streaming, and a broad set of translytical use cases, but it lags in administration automation, high-end scale, and availability of translytical consultants.
MongoDB has strengths in multi-model, data modeling, streaming, fault tolerance, dev tools and APIs, and a broad set of use cases. Three possible weaker areas are extensibility, handling a high volume of data and ultra-low latency.
InterSystems IRIS’s comprehensive translytical capabilities are proven at a massive scale, and its integrated development environment shines. The challenges are workload management, partnerships, innovation, maintaining an edge in a crowded marketplace and staying at the top vs competition.
Microsoft’s strengths are in multi-model, transactions, analytics, dev tools and APIs, and extensibility. There are concerns about latency.
For the Strong Performers the report singles out:
Redis is beloved by developers worldwide but must boost analytics capabilities;
IBM has exceptional translytical capabilities but lags in platform automation tools;
Couchbase offers strong capabilities but needs to work on analytics and insights;
SingleStore is architected for translytical prowess but needs more tooling;
PingCAP is MySQL-compatible and cloud-native but lags enterprise capabilities.
Interested parties can find out more about the translytical market landscape in another Forrester document – “The Translytical Data Platforms Landscape, Q3 2022” – which looks at 21 suppliers. You can purchase that here.
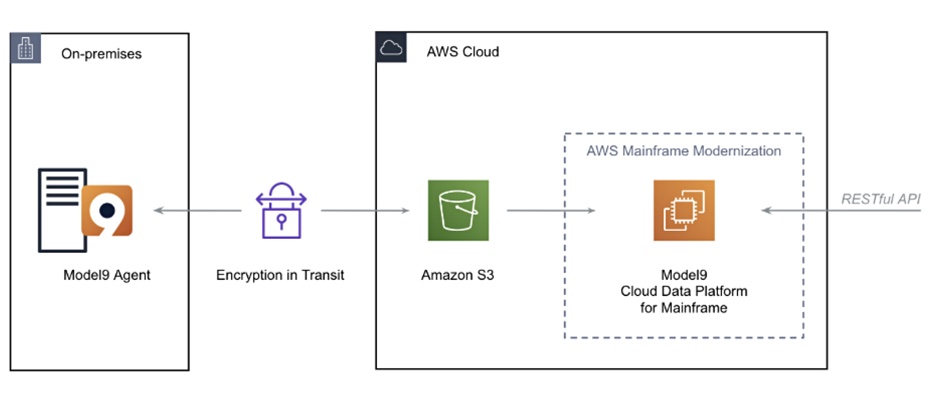
AWS is using Model9 as a data pump to draw file data off mainframes and sluice it into S3 buckets as part of a wholesale mainframe modernization exercise.
This includes replatforming and converting mainframe applications so they can run on AWS, and also having Model9’s Cloud Data Platform for Mainframe be a RESTful API-accessible repository for applications and AWS services needing to use mainframe data. Model9 is supplying software technology that will be integrated into AWS’ Mainframe Modernization services.
Gil Peleg
Gil Peleg, Model9 Founder and CEO, said in a statement that, by “incorporating the Model9 File Transfer solution into AWS Mainframe Modernization, customers can move their mainframe data into Amazon Simple Storage Service (Amazon S3) and start using AWS value added services like Amazon Athena or Amazon QuickSight without impacting their mainframe environment.”
Model9’s software performs parallel IO transmission of mainframe data at scale to the public cloud or on-premises object stores, and uses IBM’s non-billable zIIP facility to process mainframe file data, meaning its mainframe compute is free.
According to IBM, mainframes hold and generate roughly 80 percent of the world’s corporate data, including both active data from applications running on mainframes as well as decades of historical data kept for regulatory compliance, archival and data protection. Mainframes still run mission critical applications at the world’s top banks, insurers, telcos, retailers, airlines, manufactures and other large enterprises.
Model9 diagram.
The mainframe environment is proprietary and relatively static, with little ability to use the cloud for compute bursting or cloud-based apps to analyse mainframe data. Peleg said: “The Model9 File Transfer solution is addressing a major challenge holding back mainframe modernization initiatives of efficiently and securely migrating the vast amounts of mainframe data to the cloud from the various proprietary data formats and storage systems it is currently kept on.”
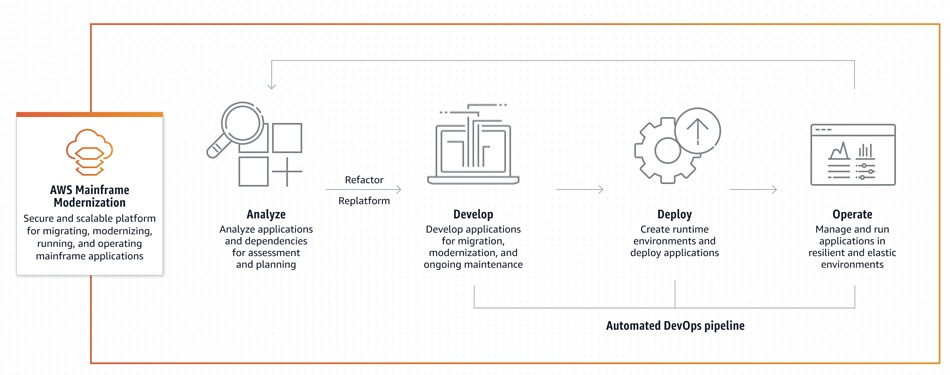
AWS Mainframe Modernization is a service for mainframe customers to migrate their workloads to an AWS managed runtime environment, and comprises a set of tools providing infrastructure and software for migrating, modernizing, and running mainframe applications in AWS.
Users can automate the process of transforming mainframe language applications into Java-based services with AWS Blu Age using web frameworks and cloud DevOps best practices.
AWS states “AWS Blu Age Refactor automatically creates modern applications from legacy monolithic mainframe or midrange source code. Applications in COBOL, generated COBOL, PL/1, NATURAL, RPG/400, COBOL/400 and their respective underlying databases and data files DB2, DB2/400, VSAM, IMS, IDMS are transformed into modern distributed applications relying on Angular, Java/Spring, PostgreSQL or other databases such as Amazon Aurora, RDS for PostgreSQL, Oracle database, IBM Db2.”
AWS diagram
COBOL and PL/I applications can be migrated with an integrated Micro Focus toolchain. AWS says its mainframe modernization customers can set up a highly available runtime environment and use automation to deploy applications in minutes.
It has a set of partners to help mainframe users migrate; AWS not having the competencies needed itself, and the list includes Accenture, Atos. Deloitte and others.
Ilia Gilderman, general manager for Migration Services at AWS, said: “Data is a core asset of any modernization project. Connecting Model9 capabilities directly to AWS Mainframe Modernization will allow customers to move data quickly and securely, with minimal domain expertise.”
He reckons AWS’ Mainframe Modernization service gives AWS customers a single overall process “for simplifying and accelerating the migration and modernization of mainframes to the cloud.”
We understand from people familiar with the situation that the Model9-AWS deal is at a significant, very significant, dollar level, and runs for more than five years. This is a first for any Israeli company and possibly a first for any company partnering with AWS.
Read a short AWS Mainframe Modernization FAQ to find out not much more. In fact there is much more detailed information on the AWS Mainframe Modernization webpages and you can talk to one of AWS’ partners to get a deeper understanding of what’s involved.
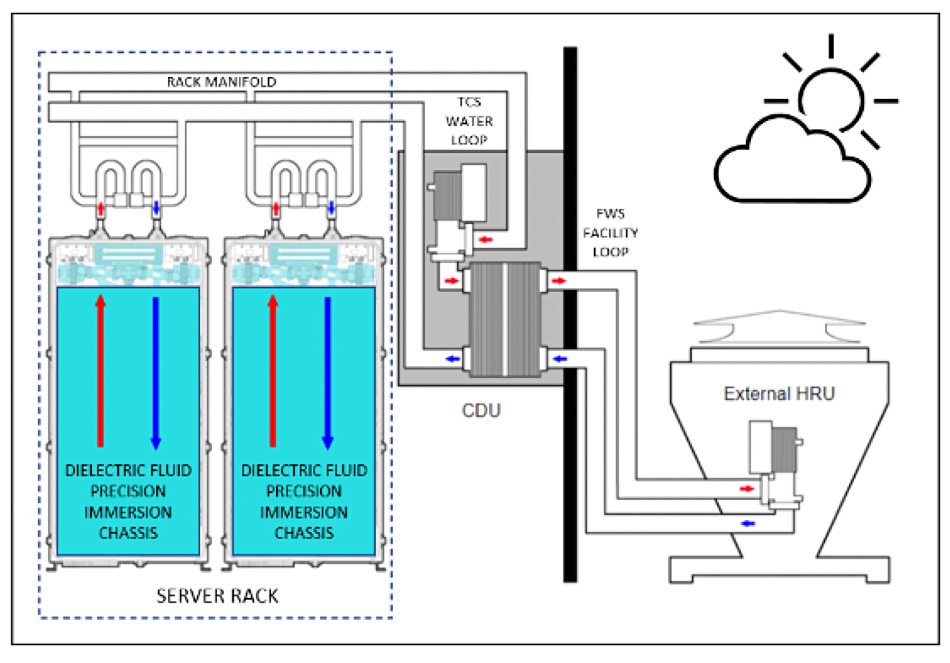
Iceotope has announced its liquid cooling system for disk drives – which, on examination, doesn’t do much at all.
The news came out on the first day of December that, with Meta, Iceotope had cooled disk drives in a high density enclosure with its immersion (liquid) cooling and found that it equalized temperature across a JBOD array. Iceotope said the system’s “virtually silent operation helps mitigate acoustic vibrational issues associated with air-cooled solutions.” The variation in temperature between all 72 20TB HDDs in the 4U OCP-compliant enclosure was just 3°C – less variation than with air cooling. The drives could operate with coolant temperature of up to 40°C. Iceotope said system-level cooling power was less than five percent of the total power consumption. That was basically it.
Neil Edmunds, Iceotope director of Innovation, said: “The study demonstrated that liquid cooling for high-density storage successfully cools the drives at a lower, more consistent temperature for fewer drive failures, lower TCO and improved ESG compliance.” Did it actually demonstrate this?
We took a look at the actual study report – “Single-Phase Immersion Cooling Study of a High-Density Storage System” – to see what exactly it proved. You can get your own copy by requesting it on an Iceotope webpage.
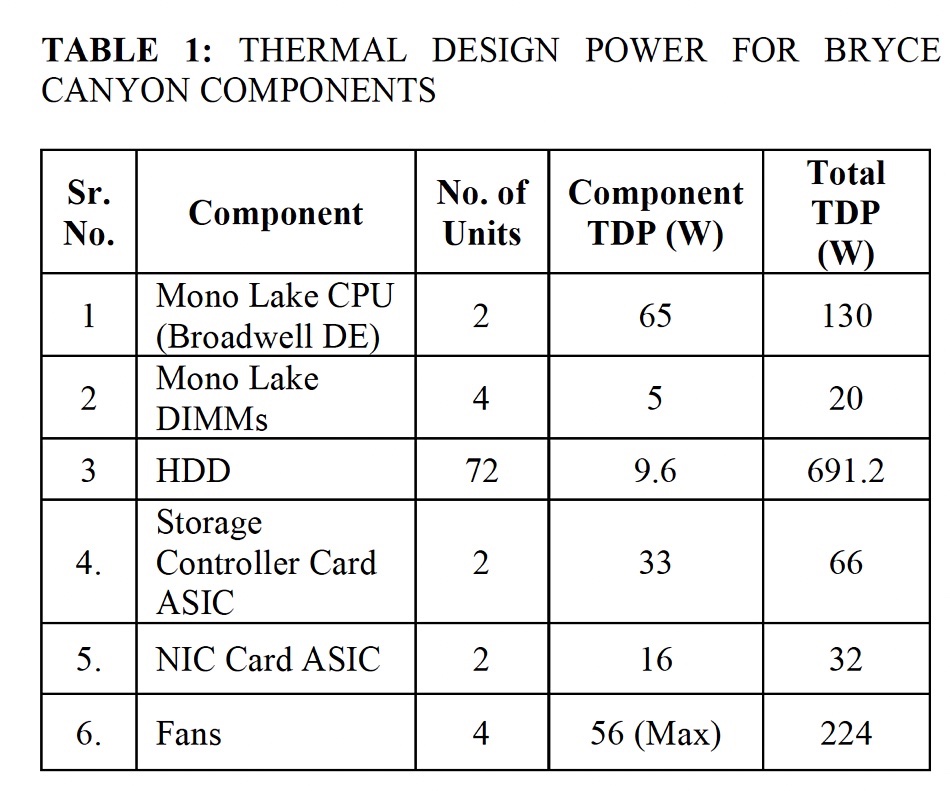
The maximum air-cooling fan power in the starting Bryce Canyon disk drive enclosure was 224 watts. The operational use would be less but no measurement was provided by the researchers.
It sums to 1163.2 watts and the air cooling fans, if operating at maximum power constantly, would be responsible for 19.3 percent of that. The liquid cooling component is said to be less than 5 percent of the total power consumption – 45.6 watts – so that is a definite benefit.
Saket Karajgikar, R&D engineer – strategic engineering and design at Meta, explained a little more, telling us: “[Air and water cooling are] comparable at lower temperature. However, at higher temperatures, pumps in immersion cooling draw lower power.”
An Iceotope spokesperson said: “I think one of the issues is that higher capacity storage disks will draw higher power therefore creating more heat. That will affect either space efficiency (they’ll need to be more spread out to allow air circulate within the storage enclosures), or reliability (air will not be able to cool effectively in high density JBODs, causing increased thermal shutdowns, potential data loss and higher service/replacement costs). In any case, there is general acceptance in the datacenter sector that air as a cooling medium is no longer effective for rising heat densities, whereas liquid cooling is seen as a ‘when not if’ technology.”
The paper was less assertive about the lower vibration experienced by the drives than Iceotope’s press release: “The proposed cooling solution may help mitigate acoustic vibrational issues for drives often encountered in air-cooling solution. The solution is virtually silent in operation.” It noted: “In the absence of fans, there would be no acoustic vibrations which could potentially hinder the drive performance. … the design approach could potentially eliminate acoustic vibration issues often encountered in an air-cooled solution.”
Iceotope scheme diagram.
In other words, the effect of liquid cooling on acoustic vibration experienced by the drives was not investigated. The amount of acoustic vibration was not measured – there is no data in the paper.
There was no test of drive failure rates with the immersion cooling in operation. When Iceotope’s Neil Edmonds declares “The study demonstrated that liquid cooling for high-density storage successfully cools the drives at a lower, more consistent temperature for fewer drive failures, lower TCO, and improved ESG compliance,” this should be taken to mean “potentially fewer drive failures.”
A May 2014 Backblaze blog by Brian Beach asked: “How much does operating temperature affect the failure rates of disk drives?” And answered: “Not much.” It read: “After looking at data on over 34,000 drives, I found that overall there is no correlation between temperature and failure rate. … As long as you run drives well within their allowed range of operating temperatures, keeping them cooler doesn’t matter.”
The Iceotope immersion cooling requires less electricity than air-cooling fans, but would appear to have no effect on drive failure rates, if Backblaze is to be believed. The potential effect of lower acoustic vibration was not tested by the researcher. The TCO over time was not investigated either. So don’t read too much into it.
Cirrus Data believes that the new challenge for storage in the public cloud, up to now largely built on object and file data, is moving block data to the cloud, meaning mission-critical databases.
In the current economic environment, according to Ron Croce, Cirrus EVP for Sales and Market and CRO, enterprises are moderating their expenditure and halting planned storage refreshes. The company hopes, as others do, that customers will see moving data to the public cloud as a transfer of capital expenditure to operating expenditure.
Ron Croce
He told us: “The next frontier is block in the cloud.”
With software like Pure’s Cloud Block Store the cloud destination can have a familiar on-prem SAN array interface. Vendors like Dell, with Project Alpine, and HPE are moving their block array software to the cloud. That provides a familiar SAN environment across the on-prem and cloud worlds for many of the installed SANs.
But the big obstacle is moving data there, and Cirrus Data can move block data to the cloud with no downtime and reasonably quickly. It can be seen as equivalent to a storage refresh in that there has to be a migration from the old SAN array to a new one, except that the new one is in a remote datacenter and running on storage instances rather than on a known storage array vendor’s hardware, albeit operating under the existing SAN vendor’s software abstraction layer.
According to Croce the biggest block data users are databases and the hardest to move to the cloud are high transaction rate DBMS – the mission-critical stuff that cannot have downtime. He said Oracle’s Golden Gate technology is a replication-based data protection product that can be used for migration, but claimed it could be disruptive, adding: “We do it five to seven times faster than a vendor’s own technology.”
He mentioned moving a 200TB Oracle database to the cloud for a large financial institution that took just a month from start to cutover. The customer couldn’t use ASM or Golden Gate for this.
Croce said: “All of the storage OEMs are partners of ours, except Huawei. … We are Pure’s exclusive partner for migration.”
He mentioned IBM, Infinidat, Hitachi Vantara and global system integrators like Kyndryl. Infinidat, he said, has only been using Cirrus’ appliance product so far but is about to adopt its Cirrus Migrate Cloud software product.
We can imagine Cirrus’ software being used for cloud-to-cloud data movement as well and, another interesting idea, since it moves blocks over time it could also do roll back and be used in data recovery scenarios.
We asked how Cirrus’ software can cope with SANs using NVMe-drives, which are not SANs in the traditional sense at all, as there are seemingly direct connections between the host application and the drives. He said: “That’s our future. We don’t see it being adopted yet. It’s five or so years away.”
The Cirrus engineering team is paying attention to this technology and Cirrus will support it when necessary.
Cirrus is also offering Migration-as-a-Service, with the software installed as part of a SAN and included as an operation during a storage refresh. This enables it to move on from being used just on a migration project basis and brings in recurring revenue.
If Croce is right, and moving block data to the cloud is the next frontier, then the future for block-based data movers looks bright. Certainly WANdisco, whose Live Datac tech can replicate Oracle and other data to the cloud, has reported a string of deals concerned with moving data to Azure and other clouds recently, and that supports Croce’s conviction that mission-critical data is moving to the cloud.
AWS announced Amazon DataZone, a new data management service that makes it faster and easier for customers to catalog, discover, share, and govern data stored across AWS, on-premises, and third-party sources. Administrators and data stewards can manage and govern access to data using fine-grained controls to ensure it is accessed with the right level of privileges and in the right context.
…
AWS announced two new integrations making it easier for customers to connect and analyze data across data stores without having to move data between services. Customers can analyze Amazon Aurora data with Amazon Redshift in near real time, eliminating the need to extract, transform, and load (ETL) data between services. Customers can now run Apache Spark applications on Amazon Redshift data using AWS analytics and machine learning (ML) services (e.g., Amazon EMR, AWS Glue, and Amazon SageMaker). Together, these new capabilities help customers move toward a zero-ETL future on AWS.
…
AWS announced DocumentDB Elastic Clusters, which scales customers’ document workloads to support millions of writes per second and store petabytes of data. It also debuted Amazon Athena for Apache Spark, which it said lets customers get started with interactive analytics using Apache Spark in less than a second rather than minutes. AWS Glue Data Quality cuts time for data analysis and rule identification from days to hours by automatically measuring, monitoring, and managing data quality in data lakes and across data pipelines. .
…
Amazon Redshift data sharing now supports centralized access control with AWS Lake Formation, enabling users to efficiently share live data across Amazon Redshift data warehouses. Amazon announced previews of AWS Data Exchange for Amazon S3 to enable data subscribers to access third-party data files directly from data providers’ Amazon S3 buckets. AWS Data Exchange for AWS Lake Formation is a new feature that enables data subscribers to find and subscribe to third-party data sets that are managed directly through AWS Lake Formation.
AWS Glue Service Delivery Specialization helps customers find validated AWS Partners with expertise and proven success delivering AWS Glue for data integration, data pipeline, and data catalog use cases.
…
AWS announced AWS Clean Rooms, a new analytics service that helps companies securely analyze and collaborate on their combined datasets—without sharing or revealing underlying data. Customers can create a secure data clean room in minutes and collaborate with any other company in the AWS Cloud to generate insights about advertising campaigns, investment decisions, clinical research, and more. AWS Clean Rooms provides a broad set of built-in data access controls that protect sensitive data, including query controls, query output restrictions, query logging, and cryptographic computing tools.
…
AWS announced Amazon Security Lake, a service that automatically centralizes an organization’s security data from cloud and on-premises sources into a purpose-built data lake in a customer’s AWS account so customers can act on security data faster. It manages data throughout its lifecycle with customizable data retention settings, converts incoming security data to the Apache Parquet format, and conforms it to the Open Cybersecurity Schema Framework (OCSF) open standard to make it easier to automatically normalize security data from AWS and combine it with pre-integrated third-party enterprise security data sources. Security analysts and engineers can use Amazon Security Lake to aggregate, manage, and optimize large volumes of disparate log and event data to enable faster threat detection, investigation, and incident response, while continuing to utilize their preferred analytics tools.
…
Cloud database supplier CouchBase announced a multi-year strategic collaboration agreement with AWS. The two have committed to offer customers integrated go-to-market activities, commercial incentives and technology integrations. This includes migrating workloads to the Couchbase Capella Database-as-a-Service (DBaaS) offering on AWS, as well as extending Capella App Services to run on AWS edge services.
…
Red Hat OpenShift Data Science is now listed in AWS Marketplace as a limited release with full general availability in the coming weeks. Supported on Red Hat OpenShift Service on AWS (ROSA), it’s a fully-managed cloud service that provides data scientists and developers with an AI/ML platform for building intelligent applications. It has MLOps capabilities and pre-integrated support for Pachyderm. Red Hat OpenShift Streams for Apache Kafka is also available in AWS Marketplace, making it easier for developers to create, discover and connect to real-time data streams. Also Red Hat Enterprise Linux for Workstations on AWS, Red Hat Enterprise Linux 8 with SQL Server 2019 Standard, Red Hat Ansible Automation Platform, Red Hat JBoss Enterprise Application Platform (EAP) and Red Hat Enterprise Linux for SAP Solutions are available in the AWS Marketplace..
…
Spin Systems has released its Multiplatform Data Acquisition, Collection, and Analytics (MDACA) Synthetic Data Engine (SDE) and Cloud Storage Explorer (CSE) in AWS Marketplace. Available as a single Amazon Machine Image for you to use with your preferred Amazon Elastic Compute Cloud (Amazon EC2) instance and type, the MDACA SDE is a web-based tool for taking in a de-identified data set as input and generating a synthetic dataset as output that is structurally and statistically similar to the de-identified data set. MDACA SDE is designed to safeguard the privacy of real data without the need for customers to develop a deep understanding of the complexities of generating synthetic data.
Other news
Cloudian announced the launch of its HyperStore on-prem object storage data lake storage system in partnership with cloud data warehouser Snowflake. Joint customers will now have access to data stored on HyperStore that is deployed on-premises in either a private cloud or hybrid cloud configuration.
…
Matt Dittoe
SaaS data protector Cobalt Iron has hired Matt Dittoe as VP Sales. He comes being SVP Sales at Gluware with a stints at Oracle, SolarWinds and AWS before that.
…
DDN’s Tintri organisation has hired Aaron Melin as Senior Director of Engineering. He comes from being FAE Director at Supermicro and Senior Director of Engineering at Liqid before that, with stints at Pivot3 and Dot Hill earlier in his career.
…
Katie McCullough
Panzura announced the appointment of Katie McCullough as Chief Information Security Officer, responsible for security and compliance for the company and customers alike. She joins Panzura with more than 25 years of experience executing and leading security operations, compliance, managed services, and cloud solutions while working for companies like OneNeck IT Solutions and CDW/Berbee.
…
Peer Software, which supplies the distributed file services platform, PeerGFS, announced an alliance with SSI, a vendor of SW for the design, engineering, construction, and maintenance of shipbuilding projects. PeerGFS helps expand the performance and reach of SSI’s SW across geographically dispersed project teams. Together the two reduce the impact of WAN speed and latency issues and allow shipyards to perform tasks with substantially improved performance and data availability.
…
Data integrity supplier Precisely is working with AWS on its AWS Mainframe Modernization service. The integration offers real-time replication of mainframe data to AWS with zero downtime, using Precisely Connect, allowing customers to migrate data, as well as access mainframe data on AWS for analytics.
…
Seagate Lyve Cloud storage as a service is expanding to the UK. In a new survey (available on demand) “The UK data management costs and opportunities index, 2022 edition” from Seagate Technology, states that British businesses are spending an average of £213,000 per year on storing and managing their own data. Seagate claims that, by using Lyve Cloud for data analytics, data repository for content collaboration, and backup/disaster recovery, organizations can dramatically reduce their total cost of ownership.
…
Seagate has joined the Active Archive Alliance, a collaboration of storage and IT vendors that collectively support the use of active archive systems for data lifecycle management. Seagate’s archive offerings include its Lyve Cloud, Lyve Cloud Analytics, a fully managed, end-to-end platform for DataOps, Lyve Cloud Tape Migration and Storage, and Lyve Mobile for physically transferring mass data sets.
…
SMART is now offering high performance, power efficient, data center solid state disk drives (SSDs) beginning with the DC4800 PCIe Gen 4 family. They have a hardware-accelerated controller that draws less power without compromising storage input/output (I/O) performance. Zero-induced throttling allows these SSDs to perform better under continued duress, even when pushed to their performance limit. This translates to significant power consumption improvement per server, as well as consistent latency performance up 99.99999% of the time. The drives are compliant to the Open Compute Project (OCP) 1.0 NVMe storage standard, available in capacities up to 7.68TB and in U.2 and E1.S form factors. Initial sampling is already in process with several OEMs and system builders.
…
Cloud data warehouser Snowflake’s Q3 fy23 revenues were $557 million, up 67 percent Y/Y with a loss of $201 million. The year-ago loss was $155 million. It now has 7,292 customers, up from6,808 in the previous quarter and 5,416 a year ago. Snowflake’s net revenue retention rate is 165 percent and it has 287 customers with trailing 12-month product revenue greater than $1 million.
…
Swissbit announced a technology collaboration with Micron to integrate Micron’s Authenta technology into select security and storage products, making Authenta root-of-trust secure element features available to its customer base in the industrial automation, automotive, NetCom, and medical technology sectors. The first Swissbit product with integrated Authenta technology will be a microSD card, good for retrofitting IoT systems. Swissbit and Micron plan to introduce an embedded e.MMC product.
…
Teradata and Vcinity announced an alliance that for connecting data over long network distances in cloud, hybrid or on-prem environments. Using the Teradata VantageCloud offering with Vcinity’s technology, organizations can more easily connect and leverage data that is slow to access or is physically very far away.
…
DataOPs observability supplier Unravel Data announced that Keith Roseland-Barnes has joined the company as its new Chief Revenue Officer. He will lead the go-to-market strategy for sales, solution engineering, and the channel. The addition of Roseland-Barnes follows the company’s recent announcements of Series D funding and Ravi Vedantam joining as VP Global Partnerships.
…
Veeam Software announced it was selected by California Dairies to protect its Microsoft 365 data and mitigate cyberattacks. Veeam is helping business continuity through verified disaster recovery (DR) strategies, fast-tracking data protection for multi-cloud ecosystems and offering additional ransomware resilience for the #1 dairy processing cooperative in California that produces fresh milk for all 50 states and more than 50 countries.
…
Veza announced its Open Authorization API (OAA) is now public on GitHub for community collaboration, extending the reach of identity-first security across the enterprise. Developers can create and share connectors to extend the Veza Authorization Graph to all sensitive data, wherever it lives, including cloud providers, SaaS apps, and custom-built internal apps, accelerating their company’s path to zero trust security.
…
Data integrator and ingester Equalum announced a strategic partnership with data warehouser Yellowbrick Data to enable a simpler, efficient, and higher-performance migration of data from legacy environments to the Yellowbrick Data Warehouse hosted in the user’s preferred commercial cloud environment. Equalum uses YBLoad to integrate data into the Yellowbrick Data Warehouse.