The Competitive Corner provides the best and most detailed analysis of vendor ratings in the 2025 Gartner Magic Quadrant (MQ) for Backup and Data Protection Platforms that we have encountered.
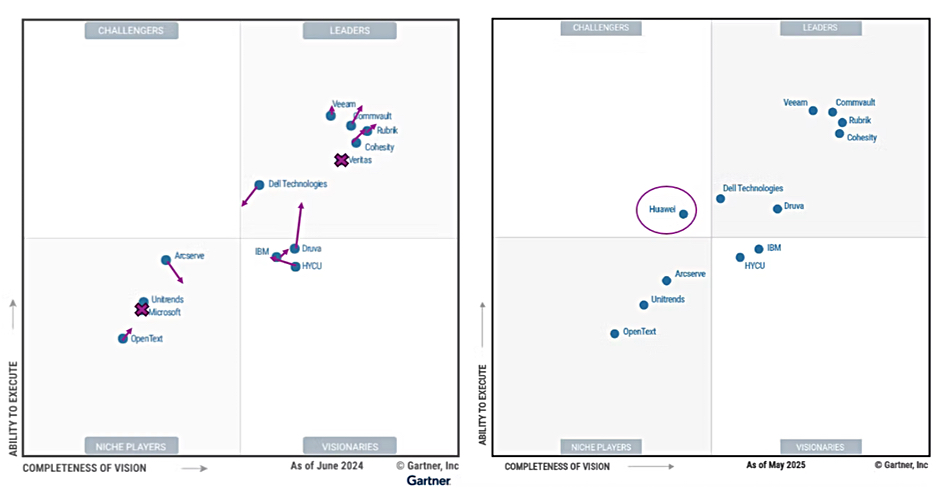
We covered this MQ in a storage ticker on June 30, noting Druva got promoted from Visionary to Leader, Huawei entered as a Challenger, the separate Cohesity and Veritas entries have been combined, and Microsoft exits as a Niche Player. Otherwise it was pretty stable with small vendor position changes. Competitive Corner analyst Matt Tyrer applied his microscope to the MQ, plotting the changes in detail, looking at why they took place, and comparing the positioned vendors to a depth we have not seen before.
Matt Tyrer
Tyrer is an ex-head of competitive intelligence at Druva and Commvault.
He notes: “We did see some significant changes in the Leaders quadrant. First off, Druva makes their debut as Leader this year – making them the only 100 percent SaaS platform in the Leaders quadrant and first new entrant to that space since 2020. Veritas is no longer separately listed now that their acquisition by Cohesity is complete, and Dell Technologies continues their inexorable slide out of the Leaders space – something I’m expecting to see in the 2026 MQ.”
Tyrer comments: “Technically, Veeam barely holds onto their position as ‘Highest in Ability to Execute’ (by a sliver) and Rubrik stays just ahead of Cohesity to be a repeat ‘Furthest in Vision.’ We’ll explore why in the next section when we delve into each Leader in more detail.”
“Outside of the Leaders there were a few things of note. As previously mentioned, Microsoft dropped out of the Magic Quadrant this year after a brief appearance in last year’s report. Huawei is the only new vendor this year, serving as the only representative in the Challenger’s space. HYCU lost some ground in terms of Vision, while Arcserve gained position on that axis. Lastly, IBMslightly moved closer to that Leader space.”
Tyrer looks at the leader vendors in some detail and issues verdicts:
Cohesity: With the addition of NetBackup, Cohesity’sworkload support across the board is unmatched. Only Commvaultcan compare to the sheer diversity of workloads and data sources that Cohesitycan protect. While there is indeed some expected chaos associated with the Cohesity+ Veritaspost-merger initiatives, those won’t be a distraction for long and Cohesityhas the very real potential to be THE platform to beat in the enterprise with their combined technology stack – if executed properly.
Commvault has expanded their portfolio faster than ever over the past 12 months, which has introduced the previously mentioned challenges around complexity and usability, but those are issues Commvaulthas successfully addressed in the past and can likely correct moving forward. Despite these concerns, they remain one of the most feature-rich technology stacks in the industry and can address many use cases and data sources others cannot.
For customers that are invested in the broader Dell technology portfolio, the Delldata protection suite (DPS) should be adequate for their needs. The solutions are proven, but do lag behind the market leaders in terms of innovation and features. Customers with mixed heterogeneous vendor environments, particularly those with investments in cloud, will need to properly evaluate which of the many Dellsolutions they will need to deploy – Dell PowerProtect Backup Service (OEM’d from Druva) is by far the best option for those types of Dellcustomers needing on-prem, hybrid, cloud, and SaaS workload coverage.
Druva’s SaaS solution delivers an easy to deploy, simple to manage solution that truly hits the “secure by design” cyber security goals by not having any infrastructure for bad actors to directly attack – something customers would otherwise have to design/architect themselves if using competing solutions in the MQ. This is a great fit for security-minded customers and those investing into hybrid and cloud.
Rubrik’s portfolio continued to grow, and with a pivot back to more of a data protection focus they appear to be finding balance between expanding their core backup capabilities and enhancing their cyber security products. Rubrik doesn’t yet have the broad workload coverage available from Commvault or Cohesity, but it is quickly catching up. Rubrik remains simple to deploy and operate, but that simplicity also translates into Rubrik’s platform being more limited in terms of more advanced features and functionality many enterprise customers need such as in depth reporting and robust cross-platform disaster recovery.
Veeam’s well established market presence and customer base are quick to adopt new Veeam features and products, but Veeam very often shares their footprint with other backup solutions – seeing multiple backup products on the customer floor to address different needs. The Veeam roadmap is ambitious, striving to deliver on 34 new products and enhancements, including significant expansion of their VDC offering and a new release of their core platform. So, look for Veeam to continue to impact the data protection market with a host of new capabilities over the next year.
He also has a look at Arcserve, Huawei, HYCU, and IBM, saying:
Arcserve’s simple, turnkey UDP appliance offering is well proven in the market and a great fit for midmarket customers or enterprise customers with multiple sites they need to easily manage for protection. Their pricing is flexible and with these latest investments into their product, the Arcserve solution supported by these new resilience features is one to watch.
Huawei is an emerging player in the enterprise market, and while their support for multi-cloud and availability is mainly limited to their own cloud they are slowly expanding. For now, it’s likely that customers that are invested in the Huawei cloud ecosystem and those with many sites in APAC will be better suited for their solution, but as workloads and geographic availability/support grow so too will their suitability for a broader market.
HYCU’s focus on Nutanix and SaaS applications gives them a solid advantage for customers heavily invested in either. There is no other vendor close to providing the SaaS coverage available from HYCU R-Cloud. Customers with larger multi-cloud and on-prem environments may need to look at other solutions outside of HYCU to complete their backup coverage, but the differentiated approach HYCU is taking to the backup market continues to see some interesting innovations. If they continue to expand their cyber resilience features and workload support they will be moving in the right direction again on the MQ.
IBM’s technology is proven and steadily catching up with today’s business needs for data protection. Their innovations in cyber security integrations and broad channel support make them a reliable partner for enterprises. With some cloud expansion and continued development of their first party IBM Storage Defender solution, we could see them eventually punch into the Leaders quadrant.
Tyrer’s analysis is available as a blog at his Competitive Corner website, with a 14-minute read time. We’d recommend it as the single best Gartner enterprise backup MQ analysis we have ever seen.
Storage array customers, like those using Rubrik and Nutanix, increasingly require as-a-service backup and disaster recovery. ADP is looking to expand into this area, and is also exploring how it might use AI with the customer data it collects.
Assured Data Protection (ADP) is a global managed services provider, offering Backup-as-a-Service and DR-as-a-Service. It is Rubrik’s largest MSP and, as of this year, also supports Nutanix. It has main offices in both the UK and US, and operates 24/7 in more than 40 countries where it has deployments, with datacenter infrastructure in six worldwide locations. The UK operation is helmed by co-founder and CEO Simon Chappell and his US counterpart is co-founder Stacy Hayes in Washington, DC.
Simon Chappell
We met Simon Chappell in London and discussed how ADP is doing and where it might be going in the future.
ADP launched operations in the Middle East in October last year via a strategic partnership with local value-added distributor Mindware. Mindware will establish local datacenters to help clients manage data sovereignty issues and minimize latency in data transfer. In February, ADP partnered with Wavenet, the UK’s largest independent IT MSP, to provide enterprise-grade backup and disaster recovery solutions to UK customers.
ADP has set up an Innovation Team aimed at expanding the company’s DR, backup, and cyber resiliency services with the addition of new technologies that complement current data protection services.
Rubrik recently acquired Predibase to help with AI agent adoption. The agents would be helped to generate responses by accessing Rubrik-stored data, a Rubrik data lake. You can use AI to clean the data but you can also use AI to look into it and analyze it.
What would Chappell think about providing AI support services for Rubrik customers who are using Rubrik as a data source for their AI? Chappell said: “There you go. That’s the $64 million question. The thing we are really good at is disaster recovery and cyber resilience. If we start to think, oh we’ve got all this data, are we as Assured going to do some service analytics around that? That is a big leap because we’ve gone from being pre-eminent at cyber resilience and disaster recovery to something else.”
Our understanding is that ADP is the custodian of the customer data it has backed up using Rubrik, and it could provide the data to large language models. In fact, it could go so far as to build its own LLM. Such an LLM could be used to clean recovered data in a clean room environment. We’re familiar with Opswat and Predatar malware presence scanning capabilities and wonder if ADP might be thinking along these lines.
This is all speculation on our part, based on the conversation with ADP and how it could potentially evolve. We think that there would need to be some kind of metadata filtering as the dataset size could be enormous, in the 500 TB+ area, leading to prolonged full scan time. You would use metadata to reduce the scan set size.
Another potential direction for ADP’s evolution could be to look for adjacent services possibilities, such as a strategic storage array partner. It could provide BaaS and DRaaS capabilities using the Rubrik and Nutanix-focused infrastructure it has built up in North and South America, the Middle East and Europe. Our understanding is that such a vendor would not be a legacy incumbent but rather a storage array supplier similar in its field to Rubrik and Nutanix in theirs. That would mean a relatively new-ish supplier with a strong and growing upper-mid-market-to-lower-enterprise customer base and a long runway ahead of it; an incumbent-to-be so to speak.
We would not be surprised to find out that, in 6 to 12 months time, ADP has a third strategic partner alongside Rubrik and Nutanix, and that it would be a storage supplier. Similarly, we wouldn’t be surprised to discover that ADP is offering malware cleansing services for recovered data.
The SNIA’s DNA Storage Alliance has published a 52-page technology review looking at the data encode/decode tech, commercial readiness metrics, and the challenges ahead.
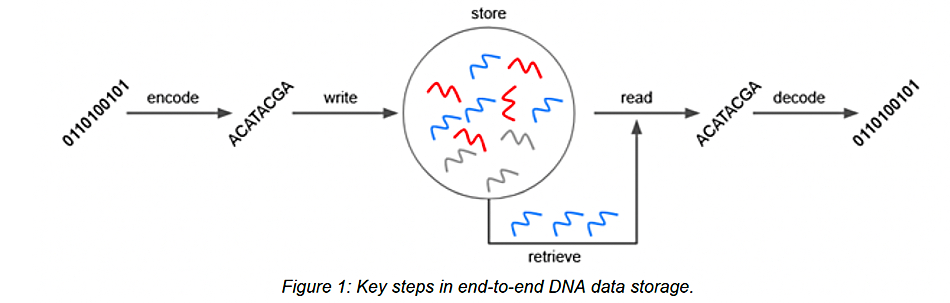
DNA data storage relies on the encoding of digital information using sequences of the four nucleotides in strands of DNA. The four nucleotides are adenine (A), guanine (G), cytosine (C), and thymine (T), and they are found in the double helix formation of the DNA biopolymer molecule, located in the cells of all living organisms. Synthetic DNA can store data in a form orders of magnitude smaller than other storage media and can endure for centuries. It relies on chemical reactions at the molecular level and these are slower than electrical operations in semiconductors. Therein lies its core challenge.
DNA data storage has been demonstrated in research projects, but the data write/read speeds, as well as equipment size, complexity, and cost, are all far from any successful commercial product. This technical document reviews the field, looking at the DNA codec, synthesis, storage and retrieval, sequencing, and commercialization challenges.
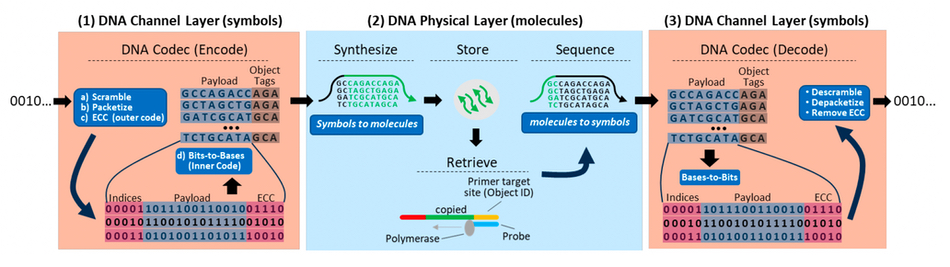
DNA Storage Alliance tech review paper diagram showing an example of a DNA Channel: In step 1, the source bitstream is randomly scrambled, mitigating problematic sequences, packetized into large blocks which are then coded with ECC (outer code), and encoded from bits-to-bases (inner code), which divides the large blocks into small DNA sequences that are compatible with the properties of the Physical Layer chemistry. Also, object tags (primers) may be added that can be used to retrieve all DNA segments in a pool associated with a particular digital object. Next, the now fully “line coded” DNA sequences are passed to the DNA Physical Layer for writing (synthesis), storing, retrieval, and reading (sequencing). Lastly, the recovered DNA sequences are passed back to the codec where they are converted back to bits and decoded, reversing all the transformations, error correction, packetization etc. done on the encoding side.
A look at the challenges reveals five: data throughput, total ownership costs, media endurance and data retention metrics, bio-security and data security, and standardization. On the throughput topic, the paper reveals: ”The requirements for moving data into and out of traditional storage far exceed the current capabilities of writing and reading DNA in biotechnology use cases.”
It says: “The most fundamental challenge for DDS (DNA data storage) systems is to increase the throughput of DNA write and read operations. The underlying write and read operations for DNA are relatively slow chemical reactions (high latency), so the emphasis for increasing throughput involves enabling parallelism.”
It recommends: “DDS technology providers must increase the throughput of the underlying write and read operations, as well as reducing the time required to move molecules between operations, all while maintaining a competitive TCO for the use case at hand.”
The paper ends on an optimistic note: “While DNA data storage is still quite nascent and there remain significant challenges to commercialization, the foundations of writing, storing, retrieving, and reading data using DNA have been shown to work on scalable technology platforms. Moreover, the ongoing investment in DNA technology, driven by biological and scientific applications, will continue to drive innovations that enhance DNA data storage capabilities.”
DNA data storage will augment, not replace, existing archival storage technologies, “resolving the ‘save/discard’ dilemma with a viable TCO for zettabyte scale and data preservation.”
Use cases, it says, will emerge over the next three to five years for DNA archival data storage.
The paper has lots of terminology that will be unfamiliar to people working with electricity-based digital storage, such as homopolymer, oligonucleotide, ligation, and polymerases, but that’s because it’s molecular organic chemistry. The document is freely downloadable and an excellent introduction to DNA data storage.
Bootnote
The DNA Storage Alliance is an SNIA community, with around 35 members and a six-member board:
Esther Singer, Director, DNA Data Storage. Twist Bioscience
Stephane Lemaire, Co-founder and Senior Innovation Officer, Biomemory
David Landsman, Director Industry Standards, Western Digital
Marthe Volette, Director of Technology, Imagene (an AI biotech company in Israel)
Julien Muzar, Technologist, Life Science, Entegris (8,000 employee supplier of advanced materials and process solutions for the semiconductor and other high-tech industries)
Twist Bioscience is a member and has board representation and recently changed its stance towards DNA data storage. It spun off its DNA business as Atlas Data Storage, a commercializing startup led by Varun Mehta, co-founder and CEO of HPE-acquired Nimble Storage. Twist retains an ownership stake and Atlas raised a $155 million seed funding round in May. We expect Atlas will take over the Bioscience membership and possibly its board position.
Esther Singer is still a Twist employee, being Director of Product and Market Development. In our opinion, the three most important DNA storage technology companies are Biomemory, Catalog and Atlas Data Storage.
DDN has released performance benchmarks showing it can can speed up AI processing time by 27x because of the way it handles intermediate KV caching.
An AI LLM or agent, when being trained on GPUs or doing inference work on GPUs and possibly CPUs, stores existing and freshly computed vectors as key-value items in a memory cache, the KV cache. This can have two memory tiers in a GPU server; the GPUs’ HBM and the CPUs’ DRAM. If more data enters the KVCache, existing data is evicted. If needed later, it has to be recomputed or, if moved out to external storage, such as locally attached SSDs or network-attached storage, retrieved, which can be faster than recomputing the vector. Avoiding KV cache eviction and recomputation of vectors is becoming table stakes for AI training storage vendors, with DDN, Hammerspace, VAST, and WEKA as examples.
Sven Oehme
Sven Oehme, CTO at DDN, states: “Every time your AI system recomputes context instead of caching it, you’re paying a GPU tax – wasting cycles that could be accelerating outcomes or serving more users. With DDN Infinia, we’re turning that cost center into a performance advantage.”
Infinia is DDN’s multi-year, ground-up redesigned object storage. It provides sub-millisecond latency, supports more than 100,000 AI calls per second, and is purpose-built for Nvidia’s H100s, GB200s, and Bluefield DPUs. DDN reminds us that Nvidia has said that agentic AI workloads require 100x more compute than traditional models. As context windows expand from 128,000 tokens to over 1 million, the burden on GPU infrastructure skyrockets – unless KV cache strategies are deployed effectively.
The company says that the traditional recompute approach with a 112,000-token task takes 57 seconds of processing time. Tokens are vector precursors, and their counts indicate the scope of an AI processing job. When the same job was run with DDN’s Infinia storage, the processing time dropped to 2.1 seconds, a 27-fold speedup. It says Infinia can cut “input token costs by up to 75 percent. For enterprises running 1,000 concurrent AI inference pipelines, this translates to as much as $80,000 in daily GPU savings – a staggering amount when multiplied across thousands of interactions and 24/7 operations.”
Alex Bouzari, CEO and co-founder of DDN, says: “In AI, speed isn’t just about performance – it’s about economics. DDN enables organizations to operate faster, smarter, and more cost-effectively at every step of the AI pipeline.”
It is unclear how DDN’s implementation compares to those from Hammerspace, VAST Data, and WEKA, as comparative benchmarks have not been made public. We would suppose that, as KV caching is becoming table stakes, suppliers such as Cloudian, Dell, IBM, HPE, Hitachi Vantara, NetApp, PEAK:AIO, and Pure Storage will add KV cache support using Nvidia’s Dynamo offload engine.
Bootnote
The open source LMCache software also provides KV cache functionality, as does the Infinigen framework.
AWS said customers can boot Amazon Elastic Compute Cloud (Amazon EC2) instances on AWS Outposts using boot volumes backed by NetApp on-premises enterprise storage arrays and Pure Storage FlashArray, including authenticated and encrypted volumes. This enhancement supports both iSCSI SAN boot and LocalBoot options, with LocalBoot supporting both iSCSI and NVMe-over-TCP protocols. Complementing fully managed Amazon EBS and Local Instance Store volumes, this capability extends existing support for external data volumes to now include boot volumes from third-party storage arrays, providing customers with greater flexibility in how they leverage their storage investments with Outposts.
…
Rai Way, part of the RAI group (Italy’s state TV broadcaster), and a specialist in digital infrastructure and media, has signed a Business Alliance Partnership with decentralized storage and compute provider Cubbit, adopting its DS3 Composer technology to integrate cloud storage services into its portfolio. Rai Way now offers a fully Italian edge-to-cloud service for storing customer data, enabled by Cubbit. The joint system ensures maximum resilience, data sovereignty, cost-effectiveness, and performance – even in low-connectivity areas – thanks to Rai Way’s distributed datacenter network, proprietary fibre infrastructure, and Cubbit’s geo-distributed technology. The initial capacity is 5 petabytes, with data hosted across Rai Way’s first five newly built edge datacenters in Italy.
…
DapuStor announced the launch of its ultra-high capacity J5060 QLC SSD, delivering 22.88 TB of capacity. Delivering up to 7,300 MBps read speeds at just 13 W, and maxing out under 25 W, it offers a best-in-class data-per-watt ratio. The J5060 is engineered for large, sequential data workloads. It uses coarse-grained (large-granularity) mapping and a dual-PCB hardware design to minimize DRAM usage and overcome capacity limitations.
– Sequential Read up to 7.3 GBps – Sequential Write up to 2.8 GBps – 4K Random Read 1.5M IOPS – 32 KB Random Write 15K IOPS – 4K Random Read Latency as low as 105 μs
…
Research house DCIG is researching the unstructured data management space. It says that, in the last several years, DCIG has published more than ten TOP 5 reports covering various aspects of unstructured data management. However, DCIG discovered a significant gap in the marketplace. “There’s really no good mental model for people to understand the overall unstructured data management space,” Ken Clipperton explains. After meeting with nearly 20 solution providers, he found widespread confusion about what constitutes unstructured data management. DCIG has devised a “7 Pillars of Unstructured Data Management” framework which provides a cohesive, vendor-neutral, actionable model for understanding the data management challenges faced by organizations today. It is creating a technology report on the seven pillars framework. This report will be available for licensing by solution providers in the second half of 2025.
…
Fast file and object storage array supplier DDN announced a strategic partnership with Polarise to deliver high-performance, resource-efficient AI infrastructure designed for the next generation of sovereign European AI workloads – at scale, with speed, and with sustainability in mind. Polarise specializes in building turnkey AI factories – end-to-end, AI-centric datacenters based on the Nvidia reference architecture. With locations in Germany and Norway, Polarise offers customers a sovereign alternative for consuming AI computing power through colocation, dedicated/private cloud, or direct API access via its own cloud platform. The companies will initially focus on joint deployments across Germany and Norway, with further European expansion planned in 2025 and beyond.
…
Deduping and fast restore backup target supplier ExaGrid announced its Tiered Backup Storage appliances can now be used as a target for Rubrik backup software. With advanced data deduplication, it will lower the cost of storing backups using the Rubrik Archive Tier or Rubrik Archive Tier with Instant Archive enabled, as compared to storing the data in the cloud or to an on-premises traditional storage. ExaGrid can achieve an additional reduction of 3:1 to 10:1 in addition to Rubrik’s compression and encryption, further reducing storage by as much as 90 percent. The combined deduplication is between 6:1 and 20:1 depending on length of retention and data types.
…
Streaming log data company Hydrolix announced support for AWS Elemental MediaLive, MediaPackage, and MediaTailor, as well as client-side analytics from Datazoom. The new integrations provide media and entertainment companies with real-time and historical insights into video streaming performance and advertising delivery, helping optimize viewer experience and ad revenue while significantly reducing the cost and complexity of data storage and analysis. The AWS Elemental and Datazoom integrations complement existing integrations with AWS CloudFront and AWS WAF, as well as other data sources.
…
HighPoint Technologies’ Rocket 1628A and 1528D NVMe Switch Adapters empower enterprise IT and solution providers to deploy up to 32 NVMe drives and 8 PCIe devices in a single x16 slot. Read more here.
…
Lexar NM990
Chinese memory supplier Longsys now owns the Lexar brand. Lexar has launched the NM990 PCIe 5.0 SSD with up to 14,000 MBps read and up to 11,000 MBps write (4 TB model), engineered for high-end gamers, professional creators and AI developers. It features:
1-4 TB capacity range
Thermal Defender Technology: Ensures 23 percent more efficient power consumption and a smoother experience
HMB and SLC Dynamic Cache: Delivers random read/write speeds up to 2000K/1500K IOPS for faster load times and reduced latency
3,000 TBW (4 TB model): Built for long-term durability and heavy workloads
Microsoft DirectStorage Compatible: Optimized for next-gen gaming performance
…
F5 and MinIO are partnering. The use cases addressed by F5’s Application Delivery and Security Platform (ADSP) combined with MinIO AIStor are:
Traffic Management for AI Data Ingestion (Batch and Real-Time): Enabling high-throughput, secure ingestion pipelines for data training and inference while eliminating pipeline bottlenecks and hotspots.
Data Repatriation from Public Clouds: Supporting organizations that are bringing data back to on-prem or hybrid environments to manage costs and comply with regulations.
Data Replication, Secure Multicloud Backup, and Disaster Recovery: Ensuring data availability, reliability, and security across geographies.
AI Model Training and Retrieval-Augmented Generation (RAG): Accelerating model development through real-time access to distributed data.
…
Cloud file services supplier Nasuni says it achieved top honors in the NorthFace ScoreBoard awards for the fifth year running. The NorthFace ScoreBoard Award is one of the industry’s most respected benchmarks for customer satisfaction. Nasuni achieved a Net Promoter Score (NPS) of 87, a Customer Satisfaction (CSAT) score of 98 percent and an overall ScoreBoard Index rating of 4.8 out of 5 – all above the industry average. Nasuni has also been awarded seven badges in G2’s Summer 2025 Reports, which are awarded based on real-user reviews and market presence.
…
Memory and storage semiconductor developer Netlist has expanded recently filed actions against Samsung and Micron in the U.S. District Court for the Eastern District of Texas. The two actions were originally filed on May 20, 2025, to assert Netlist’s new U.S. Patent No. 12,308,087 (“the ‘087 patent”) against Samsung’s and Micron’s High-Bandwidth Memory (HBM) products. The amended complaints add another Netlist patent, U.S. Patent No. 10,025,731 (“the ‘731 Patent”), against the two defendants’ DDR5 DIMM products, as well as their distributor Avnet, Inc. to these actions.
Netlist’s ‘087 patent entitled “Memory Package Having Stacked Array Dies and Reduced Driver Load” covers HBM for current and future AI applications. Analysts currently project U.S. HBM revenues to exceed $25 billion annually for each Samsung and Micron by 2031. The ‘087 patent will expire in November 2031. Netlist’s ‘731 patent reads on DDR5 DIMM with DFE and ODT/RTT circuits. Analysts currently project U.S. DDR5 DIMM revenue to exceed $65 billion annually in 2029. The ‘731 patent will expire in July 2029.
During the past two years, Netlist has obtained jury verdicts awarding combined total damages of $866 million for the willful infringement of its patents by Samsung and Micron.
…
Patriot Memory announced the launch of its latest flagship PCIe Gen5 SSD – the PV593 PCIe Gen 5 x4 M.2 2280 SSD, delivering industry-leading speeds of up to 14,000 MBps read and 13,000 MBps write. Powered by the advanced SMI SM2508 controller and built on TSMC’s 6nm process, the PV593 redefines next-gen storage for demanding workloads such as AI training, 4K/8K video editing, AAA gaming, and high-throughput multitasking. It features DRAM cache and dynamic SLC caching technology to reduce latency, accelerate system startup, and improve application launch times. With 4K random read/write speeds reaching up to 2000K/1650K IOPS, users can experience lightning-fast responsiveness across all tasks.
…
Vector search company Qdrant announced the launch of Qdrant Cloud Inference. This fully managed service allows developers to generate text and image embeddings using integrated models directly within its managed vector search engine offering Qdrant Cloud. Users can generate, store and index embeddings in a single API call, turning unstructured text and images into search-ready vectors in a single environment. Directly integrating model inference into Qdrant Cloud removes the need for separate inference infrastructure, manual pipelines, and redundant data transfers. This simplifies workflows, accelerates development cycles, and eliminates unnecessary network hops for developers.
Qdrant Cloud Inference is the only managed vector database offering multimodal inference (using separate image and text embedding models), natively integrated in its cloud. Supported models include MiniLM, SPLADE, BM25, Mixedbread Embed-Large, and CLIP for both text and image. The new offering includes up to 5 million free tokens per model each month, with unlimited tokens for BM25. This enables teams to build and iterate on real AI features from day one.
…
We’re told the CEO of Redis halted all product development for a week, just to ensure the entire team knew how to code with AI. Rowan Trollope, a developer-turned-CEO, was initially sceptical of vibe coding – a new phenomenon where developers use AI to help code. Now he’s pushing it across Redis after seeing first-hand how much vibe coding can accelerate delivery, improve code reviews, and reshape workflows. He vibe codes in his spare time, mostly for side projects, and while he knows AI won’t give him perfect code, he sees it as an accelerant. He’s one of the few CEOs with first-hand experience of vibe coding who has both the technical chops and the authority to enforce AI adoption from the top down.
…
Cyber-resilience supplier Rubrik unveiled upcoming support for Amazon DynamoDB, AWS’s flagship serverless, distributed NoSQL database service, and launched a proprietary cyber resilience offering for relational databases, beginning with Amazon RDS for PostgreSQL. Rubrik enables storage-efficient, incremental-forever backups and provides the flexibility to choose from a full range of Amazon Simple Storage Service (Amazon S3) storage classes, including Amazon S3 Standard, S3 Standard-Infrequent Access, S3 One Zone-Infrequent Access, S3 Glacier Instant Retrieval, S3 Glacier Flexible Retrieval, and S3 Glacier Deep Archive. Read a blog to find out more.
…
AI Data Cloud company Snowflake announced the appointment of Chris Niederman as Senior Vice President of Alliances & Channels. He joins Snowflake with more than 30 years of technology experience and previously spent 11 years at Amazon Web Services (AWS), most recently serving as Managing Director of the AWS Industries and Solutions team, leading the organization responsible for AWS’s worldwide partner strategy and industry transformation initiatives. Niederman will be responsible for leading the Snowflake global channel and partner ecosystem, and driving growth and collaboration through the Snowflake AI Data Cloud to empower every enterprise to achieve its full potential through data and AI.
…
DDN subsidiary Tintri announced “a game-changing and award-winning refresh to its global Partner Programme – introducing powerful new tools, exclusive benefits, and a reinvigorated partner experience designed to ignite growth, accelerate sales, and fuel innovation across the channel.” It includes technical certifications, pre-sales experts, marketing development funds, rewarding incentives and no barriers to entry to join the partner program. Click here to find out more.
…
Glenn Lockwood
VAST Data has hired Glenn Lockwood as Principal Technical Strategist. He joins from Microsoft, where he helped design and operate the Azure supercomputers used to train leading LLMs. Prior to that, he led the development of several large-scale storage systems at NERSC – including the world’s first 30+ PB all-NVMe Lustre file system for the Perlmutter supercomputer. Glenn holds a PhD in Materials Science. On AI inference, he says: “The hardest data challenges at scale went from ‘read a big file really fast’ to ‘search a vector index, rank and filter documents, load cached KV activations, cache new KV activations, and repeat.’ Not only are access sizes and patterns different across memory and storage, but application developers are expecting data access modalities that are much richer than the simplistic bit streams offered by files.” Read more in a VAST blog.
…
Veeam ran a survey into six months after the EU’s Digital Operational Resilience Act (DORA) came into effect. It found organizations are lagging: 96 percent of EMEA FS organizations believe they need to improve their resilience to meet DORA requirements.
DORA is a priority: 94 percent of organizations surveyed now rank DORA higher in their organizational priorities than they did the month before the deadline (Dec 2024), with 40 percent calling it a current “top digital resilience priority.”
The mental load of mounting regulations: 41 percent report increased stress and pressure on IT and security teams. Furthermore, 22 percent believe the volume of digital regulation is becoming a barrier to innovation or competition.
Barriers to compliance: Third-party risk oversight is cited by 34 percent as the hardest requirement to implement. Meanwhile, 37 percent are dealing with higher costs passed on by ICT vendors, and 20 percent of respondents have yet to secure the necessary budget to meet requirements.
…
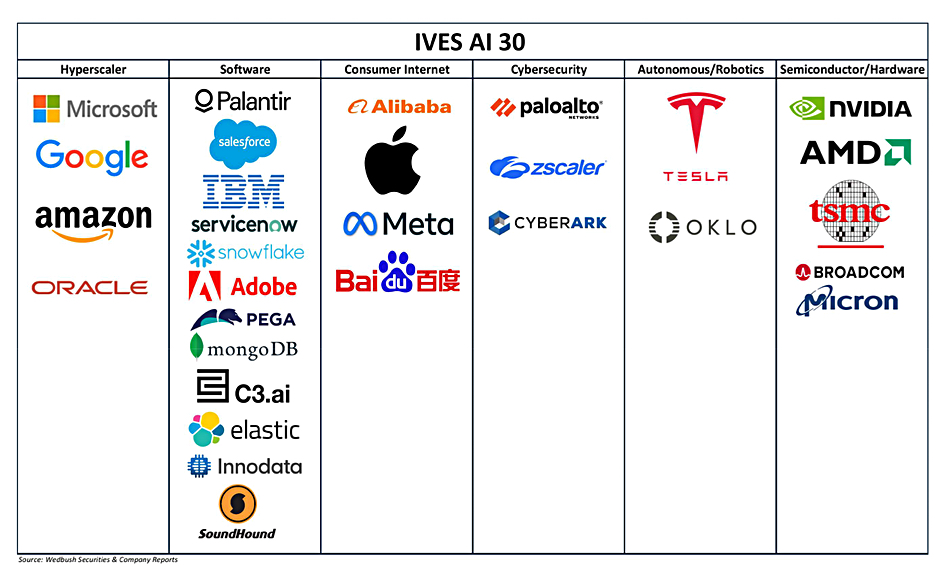
Wedbush analysis about the AI phenomenon: “Our bullish view is that investors are still not fully appreciating the tidal wave of growth on the horizon from the $2 trillion of spending over the next 3 years coming from enterprise and government spending around AI technology and use cases. We have barely scratched the surface of this 4th Industrial Revolution now playing out around the world led by the Big Tech stalwarts such as Nvidia, Microsoft, Palantir, Meta, Alphabet, and Amazon.”
“Now the time has come for the broader software space to get in on the AI Revolution as we believe the use cases are exploding, enterprise consumption phase is ahead of us for 2H25, launch of LLM models across the board, and the true adoption of generative AI will be a major catalyst for the software sector and key players to benefit from this once in a generation 4th Industrial Revolution set to benefit the tech space. 2025 so far has been an inflection year within enterprise generative AI as true adoption has begun by going from idea to scale as more companies are looking to invest into AI to decrease costs/increase productivity. Looking forward its all about the use cases exploding which is driving this tech transformation being led by software and chips into the rest of 2025 and beyond and thus speaks to our tech bull and AI Revolution thesis further playing out over the next 12 to 18 months.”
It has “identified the 30 tech companies in our ‘IVES AI 30’ … that define the future of the AI theme over the coming years as we believe these tech stocks are closely tied to the AI Revolution ranging from hyperscalers, cybersecurity, software, semis, internet, and autonomous/robotics.”
…
WEKA co-founder and sometime COO Omri Palmon is departing for something, possibly a startup, that’s not public yet. A LinkedIn post and comments discuss this.
South Korea’s CXL memory-focused Panmnesia believes that AI clusters need both GPU node memory sharing and fast inter-GPU networking with a combined CXL and UALink/NVLink architecture.
Panmnesia has released a 56-page technical report titled “Compute Can’t Handle the Truth: Why Communication Tax Prioritizes Memory and Interconnects in Modern AI Infrastructure,” written by CEO Dr Myoungsoo Jung. The report outlines the trends in modern AI models, the limitations of current AI infrastructure in handling them, and how emerging memory and interconnect technologies – including Compute Express Link (CXL), NVLink, Ultra Accelerator Link (UALink), and High Bandwidth Memory (HBM) – can be used to overcome the limitations.
Dr Myoungsoo Jung
Jung stated: “This technical report was written to more clearly and accessibly share the ideas on AI infrastructure that we presented during a keynote last August. We aimed to explain AI and large language models (LLMs) in a way that even readers without deep technical backgrounds could understand. We also explored how AI infrastructure may evolve in the future, considering the unique characteristics of AI services.”
The technical report is divided into three main parts:
Trends in AI and Modern Data Center Architectures for AI Workloads
CXL Composable Architectures: Improving Data Center Architecture using CXL and Acceleration Case Studies
Beyond CXL: Optimizing AI Resource Connectivity in Data Center via Hybrid Link Architectures (CXL-over-XLink Supercluster)
The trends section looks at how AI applications based on sequence models – such as chatbots, image generation, and video processing – are now widely integrated into everyday life. It has an overview of sequence models, their underlying mechanisms, and the evolution from recurrent neural networks (RNNs) to LLMs. It then explains how current AI infrastructures handle these models and discusses their limitations:
Communication overhead during synchronization
Low resource utilization resulting from rigid, GPU-centric architectures
Jung writes in the report that no single fixed architecture can fully satisfy all the compute, memory, and networking performance demands for LLM training, inference prefill and decode, and retrieval-augmented generation(RAG). He suggests the best way to address the limitations is to use CXL, and specifically CXL 3.0 with its multi-level switch cascading, advanced routing mechanisms, and comprehensive system-wide memory coherence capabilities.
Panmnesia has developed a CXL 3.0-compliant real-system prototype using its core technologies, including CXL intellectual property blocks and CXL switches. This prototype has been applied to accelerate real-world AI applications – such as RAG and deep learning recommendation models (DLRMs) – and has proven practical and effective.
Jung then proposes methods to build more advanced AI infrastructure through the integration of diverse interconnect technologies alongside CXL, including UALink, NVLink, and NVLink Fusion, collectively called XLink.
He says “CXL addresses critical memory-capacity expansion and coherent data-sharing challenges.” But there are “specific accelerator-centric workloads requiring efficient intra-accelerator communications” such as “Ultra Accelerator Link (UALink) and Nvidia’s NVLink, collectively termed Accelerator-Centric Interconnect Link (XLink) in this technical report.”
Both CXL and XLink are needed to optimize AI super-clusters: “XLink technologies provide direct, point-to-point connections explicitly optimized for accelerator-to-accelerator data exchanges, enhancing performance within tightly integrated accelerator clusters. In contrast to CXL, these XLink technologies do not support protocol-level cache coherence or memory pooling; instead, their focus is efficient, low-latency data transfers among accelerators with a single-hop Clos topology interconnect architecture.”
He notes: “UALink employs Ethernet-based communication optimized primarily for large-sized data transfers, whereas NVLink utilizes Nvidia’s proprietary electrical signaling, tailored for small-to-medium-sized data exchanges, such as tensor transfers and gradient synchronization between GPUs.”
Panmnesia Technical Report diagram
So “integrating CXL and XLink into a unified data center architecture, termed CXL over XLink, including CXL over NVLink and CXL over UALink, leverages their complementary strengths to optimize overall system performance. … this integration adopts two architectural proposals: i) ‘accelerator-centric clusters,’ optimized specifically for rapid intra-cluster accelerator communication, and ii) ‘tiered memory architectures,’ employing disaggregated memory pools to handle large-scale data.”
Jung then proposes “an extended, scalable architecture that integrates a tiered memory hierarchy within supercluster configurations, explicitly designed to address the diverse memory-performance demands of contemporary AI workloads. This structure comprises two distinct memory tiers: i) high-performance local memory managed via XLink and coherence-centric CXL, and ii) scalable, composable memory pools enabled through capacity-oriented CXL.” The report discusses how these would be deployed in an AI data center, with notes on hierarchical data placement and management.
Composable server infrastructure startup GigaIO has raised $21 million in what it calls “the first tranche of its Series B financing.”
GigaIO produces SuperNODE, a 32-GPU, single-node AI supercomputer, and Gryf, a mini supercomputer-on-wheels with patented FabreX memory fabric architecture. This enables the scale-up and dynamic composition of compute, GPU, storage, and networking resources. It claims this unlocks “performance and cost efficiencies that traditional architectures are unable to deliver. As AI models grow larger and more complex, FabreX provides the flexibility needed to scale infrastructure on demand, at the rack level and beyond.”
CEO Alan Benjamin said in a statement: “Our vendor-agnostic platform uniquely frees customers from dependency on single-source AI chips and architectures. Whether it’s GPUs from Nvidia and AMD or new AI chips from innovators like Tenstorrent and d-Matrix, GigaIO enables customers to leverage the best technologies without vendor lock-in. This funding gives us the fuel to move faster and meet the surging demand.”
Jack Crawford, founding general partner at Impact Venture Capital, added: “As enterprises and cloud providers race to deploy AI at scale, GigaIO delivers a uniquely flexible, cost-effective, and energy-efficient solution that accelerates time to insight. We believe GigaIO has assembled a world-class team and is poised to become a foundational pillar of tomorrow’s AI-powered infrastructure, and we’re proud to back their vision.”
Alan Benjamin
GigaIO says it has a clear focus on AI inference. The new funding will be used to:
Ramp up production of SuperNODE, which it calls “the most cost-effective and energy-efficient infrastructure designed for AI inferencing at scale.”
Accelerate the deployment of Gryf, “the world’s first carry-on suitcase-sized AI inferencing supercomputer, which brings datacenter-class computing power directly to the edge.”
Invest in new product development to broaden GigaIO’s technology offerings.
Expand the sales and marketing teams to serve the increasing demand for vendor-agnostic AI infrastructure.
The round naming is unusual, as back in 2021, it raised $14.7 million in “the completion of a Series B round of funding.” Oddity aside, this latest “B-round” was led by Impact Venture Capital, with participation from CerraCap Ventures, G Vision Capital, Mark IV Capital, and SourceCode Cerberus.
Total public funding is now $40.25 million, and GigaIO plans “a second close of the Series B in the coming months, citing continued strong interest from strategic and financial investors.”
Yesterday we reported on Liqid’s refresh of its composable GPU server infrastructure to accommodate PCIe Gen 5 and CXL. It supports up to 30 GPUs versus GigaIO’s 32.
Liqid has announced products enabling host server apps to access dynamically orchestrated GPU server systems built from pools of GPU, memory, and storage, focused on AI inferencing and agents.
Liqid originally composed systems made up from CPUs and DRAM, GPUs and other accelerators, Optane, and NVMe SSDs. It offered dynamic system setup to provide precisely the amount of such resources needed for a workload, enabling better overall resource efficiency. Its design was based on PCIe Gen 4 in 2023. Since then, Optane has gone away, PCIe Gen 5 has arrived, and CXL memory sharing has developed. Liqid has now moved on to a PCIe 5 architecture, which has enabled it to support CXL 2.0 memory pooling.
Edgar Masri
CEO Edgar Masri said of this: “With generative AI moving on-premises for inference, reasoning, and agentic use cases, it’s pushing datacenter and edge infrastructure to its limits. Enterprises need a new approach to meet the demands and be future-ready in terms of supporting new GPUs, new LLMs, and workload uncertainty, without blowing past power budgets.”
Liqid’s latest development enables customers to get “the performance, agility, and efficiency needed to maximize every watt and dollar as enterprises scale up and scale out to meet unprecedented demand.” They can, Liqid says, achieve balanced, 100 percent resource utilization across on-prem datacenter and edge environments.
Its products are the Matrix software, composable GPU servers, composable memory, and I/O accelerators, which are souped-up SSDs such as the 64 TB AX-5500 in PCIe Add-in Card format. The Matrix software runs the composability show and talks via Fabric-A to a PCIe switch for composing storage and accelerators, and Fabric-B to a CXL switch for composing memory, DRAM, not HBM. Both fabrics access a compute (GPU server) pool to deliver their resources to GPUs and thus composed chunks of GPU+memory+storage capacity to hosts.
This latest Liqid setup uses v3.6 of the Matrix software and has six hardware elements:
EX-5410P 10-slot GPU box supporting 600 W GPUs (Nvidia H200, RTX Pro 6000, and Intel Gaudi 3), FPGAs, DPUs, TPUs, NVMe drives, and more.
EX-5410C with up to 100 TB of disaggregated composable memory using CXL 2.0.
LQD-5500 accelerated SSD now supporting up to 128 TB capacity, delivering <6 million IOPS and 50 GBps bandwidth in a FHFL PCIe Gen 5×16 card that hosts 8 x E1.S standard form factor NVMe Gen5 NAND drives. These drives are permanently affixed to the card.
PCIe Gen 5 switch.
CXL 2.0 switch.
Host bus adapters (HBAs).
There are two configuration options:
UltraStack dedicates up to 30 GPUs and 100 TB of DRAM to a single server.
SmartStack pools up to 30 GPUs across up to 20 server nodes and 100 TB of DRAM across up to 32 servers.
Matrix v3.6 has native compatibility with Kubernetes, Slurm, OpenShift, VMware, Ansible, and more. The fabric support will include Nvidia Fusion, Ultra Accelerator Link (UAL), or Ultra Ethernet Consortium (UEC) as they become available.
Updated datasheets were not available when we looked on Liqid’s website but they should be there soon.
Bootnote
In Liqid’s fourth generation, GPUs were installed in a 30-slot EX-4410 Expansion Chassis and connected to hosts across a PCIe Gen 4 network. Physical GPUs are provisioned from this pool to bare metal hosts with the Matrix software, which runs in a 1RU Liqid Director server.
A SmartStack 4410 system supports heterogeneous GPUs, up to 30 per host, and up to 16 host servers, PCIe Gen 4 with a 48-port PCIe switch, and up to three EX-4410s. A smaller SmartStack 4408 supports up to 24 GPUs per host with up to 16 hosts.
The UltraStack system supports bringing up to 30 Nvidia L40S GPUs to a single Dell PowerEdge server, either an R760 or R7625.
Vector buckets have been added to AWS S3 object storage to lower the cost of having infrequently accessed vectors stored in Amazon’s OpenSearch Service.
Unstructured data is being seen as increasingly important to organizations adopting large language model-based AI, with retrieval-augmented generation (RAG) and agents being part of that. RAG brings proprietary information to the LLMs and agents. The bulk of it is unstructured and needs vectorizing so that the LLMs and agents can bring their vector-based analysis to bear. Special LLMs do the vectorizing and then the vectors need storing. AWS is already doing that with its OpenSearch Service. However, it has a disadvantage compared to on-prem object stores and databases that store vectors. An AWS database instance costs in terms of storage capacity and also compute. By storing infrequently accessed vectors in S3, AWS can reduce compute costs for vector databases and save customers money.
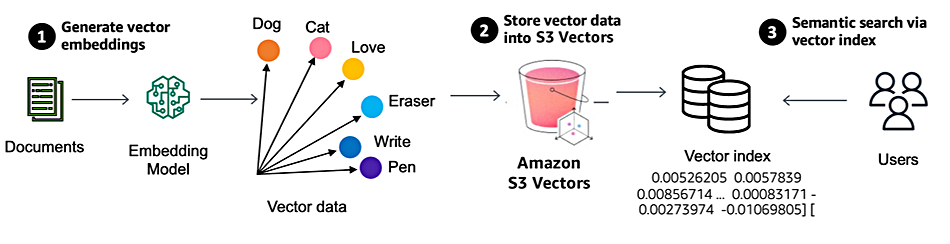
Channy Yun, AWS Principal Developer Advocate for AWS cloud, writes in a blog: “We’re announcing the preview of Amazon S3 Vectors, a purpose-built durable vector storage solution that can reduce the total cost of uploading, storing, and querying vectors by up to 90 percent.”
This makes it cost-effective to create and use large vector datasets to improve the memory and context of AI agents as well as semantic search results of customers’ S3 data. The S3 Vectors feature is, an AWS announcement says, “natively integrated with Amazon Bedrock Knowledge Bases so that you can reduce the cost of using large vector datasets for retrieval-augmented generation (RAG). You can also use S3 Vectors with Amazon OpenSearch Service to lower storage costs for infrequent queried vectors, and then quickly move them to OpenSearch as demands increase or to enhance search capabilities.”
S3 vector support comes via a new vector bucket, which Yun says has “a dedicated set of APIs to store, access, and query vector data without provisioning any infrastructure.” The bucket has two types of content: vectors and a vector index used to organize the vectors. “Each vector bucket can have up to 10,000 vector indexes, and each vector index can hold tens of millions of vectors,” Yun says.
There’s a neat extra twist: “You can also attach metadata as key-value pairs to each vector to filter future queries based on a set of conditions, for example, dates, categories, or user preferences.” This cuts down vector selection and scan time.
S3 Vectors automatically optimizes the vector data to achieve the best possible price-performance for vector storage as bucket contents change.
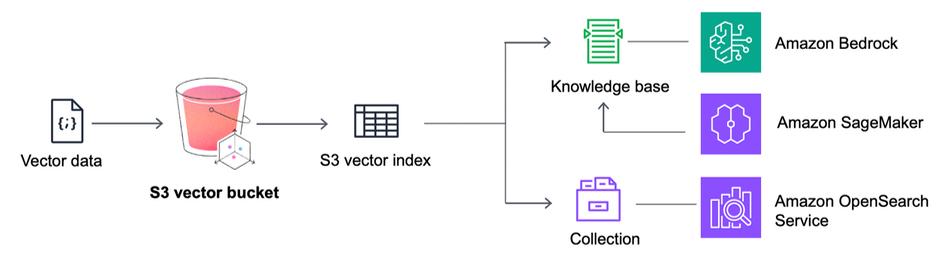
The S3 Vectors feature is integrated with Amazon Bedrock Knowledge Bases, including within Amazon SageMaker Unified Studio, for building RAG apps. When creating a knowledge base in the Amazon Bedrock console, you can choose the S3 vector bucket as your vector store option.
AWS S3 Vectors integrations
S3 Vectors also has an integration with the Amazon OpenSearch Service. If you do lower storage costs by keeping low access rate vectors in S3 Vectors, you can move them to OpenSearch if needed and get real-time, low-latency search operations.
Andrew Warfield, a VP and Distinguished Storage Engineer at AWS, said: “S3 vectors anchors cost in storage and assumes that query demand fluctuates over time, meaning you don’t need to reserve maximum resources 100 percent of the time. So when we look at cost, we assume you pay for storage most of the time, while paying for query/insertion costs only when you interact with your data.
“When we looked across customer workloads, we found that the vast majority of vector indexes did not need provisioned compute, RAM or SSD 100 percent of the time. For example, running a conventional vector database with a ten million vector data set can cost over $300 per month on a dedicated r7g.2xlarge instance even before vector database management costs, regardless of how many queries it’s serving.
“Hosting that same data set in S3 will cost just over $30 per month with 250 thousand queries and overwriting 50 percent of vectors monthly. For customers who have workloads that heat up, they can also move their vector index up to a traditional vector store like Open Search, paying instance-style cost for the time that the database is running hot.”
Yun’s blog post explains how to set up and use S3 Vectors.
AWS is not alone in adding vector support to object storage. Cloudian extended its HyperStore object storage with vector database support earlier this month, using the Milvus database.
The Amazon S3 Vectors preview is now available in the US East (N. Virginia), US East (Ohio), US West (Oregon), Asia Pacific (Sydney), and Europe (Frankfurt) Regions. To learn more, visit the product page, S3 pricing page, documentation, and AWS News Blog.
Just over half of enterprises with more than 10,000 employees have integrated storage security into their overall cybersecurity strategy, with another fifth planning to do so.
The finding was revealed by an Infinidat-sponsored survey by The Register and Blocks & Files that looked at cyber strategies for data infrastructure protection, priorities, and buying patterns of CISOs, CIOs, and VPs of IT Infrastructure of such large enterprises.
Eric Herzog
Infinidat CMO Eric Hezog stated: “Being able to recover business-critical and mission-critical data as fast as possible after a cyberattack, such as ransomware or malware, is an organization’s last line of defense. Any enterprise that does not deploy cyber resilient storage leaves themselves at high risk and defenseless.”
In the surveyed organizations, CISOs were the main drivers for cybersecurity (55.6 percent), with CIOs next (27.5 percent), and few relying on a VP of infrastructure (7.5 percent), chief legal officer (6.2 percent), and VP or director of storage (3.1 percent).
Cyber strategy investment areas followed an outside-in and overlapping pattern, with endpoint security first (62.5 percent), network security (60 percent) next, and a security operations center third (58.1 percent). SIEM or SOAR software was fourth at 51.9 percent, then storage and data protection came in at 42.5 percent. Just 4.1 percent looked at server or app workloads and cybersecurity software as a key technology investment area.
Unsurprisingly, only 13.1 percent of respondents thought it unimportant to have automated detection and recovery processes. 30 percent said it was mandatory, 30 percent said very important, and 26.9 percent said somewhat important.
A majority of respondents (56.2 percent) took the view that storage security information, such as logged events, should be integrated into the overall security environment. Only 17.5 percent of respondents took the view that such integration was not necessary, with a further 6.9 percent having no integration plans. Partial integration was being undertaken by 15 percent, while 4.4 percent were planning such integration in the future.
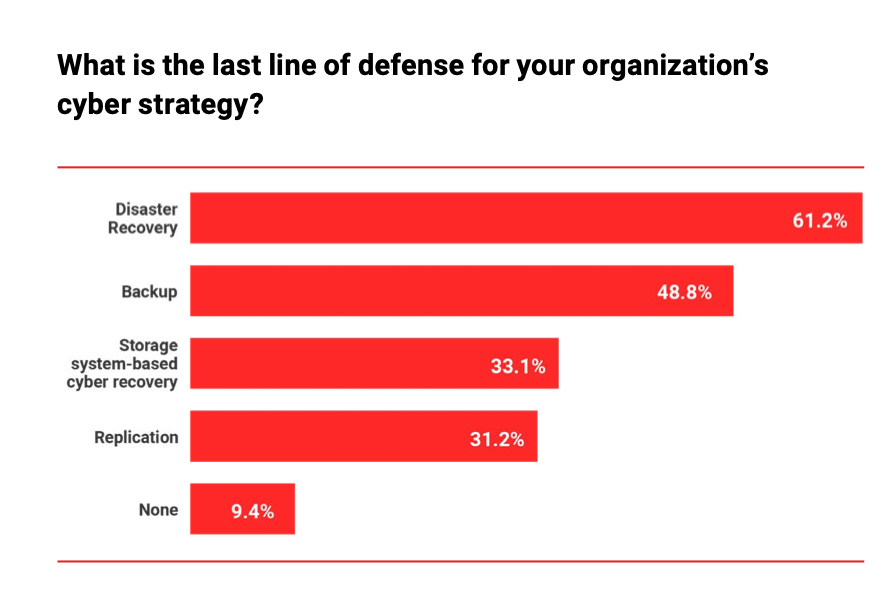
When asked about their last line of cybersecurity defense, multiple options were mention. Most respondents (61.2 percent) answered disaster recovery, 48.8 percent said backup, 33.1 percent said cyber recovery was storage system-based, and 31.2 percent said it was replication. A minority (9.4 percent) said they had no last line at all.
The distribution of recovery SLAs was surprisingly variable:
<30 minutes – 21.2 percent
30-60 minutes – 10.6 percent
1-12 hours – 30 percent
24 hours – 16.2 percent
1-10 days – 21.9 percent
Infinidat says its cyber recovery guarantee for InfiniBox and InfiniBox SSA – one minute or less, regardless of dataset size – meets the fastest recovery SLA listed.
Finally, there were multiple ways to verify restored data to ensure it was fully present and malware-free. Application owners had the most responsibility (50.6 percent), followed by vendor-supplied backup or storage tools (47.5 percent), then security/forensic consultants (40 percent), and tools from security vendors (37.5 percent).
The survey report notes: “Keeping critical data and applications safe from threats is a constant battle for every organization, and orchestrating and validating a fast recovery in the event of any incident is an equally important element of any effective cybersecurity defense.”
Enterprise storage vendor Infinidat has hardened its product line with InfiniSafe offerings to help keep its users safe from cyberattacks. InfiniSafe Cyber Detection provides AI and ML-based deep scanning and indexing of the stored data estate to identify potential issues and help enterprises react, resist, and quickly recover from cyberattacks.
InfiniSafe Automated Cyber Protection (ACP) integrates with an enterprise’s security operations center (SOC) and/or their datacenter-wide cybersecurity software applications.
Herzog believes that there is “a shift happening in the enterprise market toward embracing a cyber-focused, recovery-first approach to mitigate the impact of cyberattacks.” First stop the attack, then aim to identify and recover the affected data, followed by forensic analysis and procedural changes to IT systems and processes. Such changes should include integrating automated cyber protection, accelerating cyber detection, and incorporating cyber storage resilience and rapid recovery into an enterprise’s overall cybersecurity strategy if that hasn’t already been done. The increasing incidence and scope of malware attacks shows no sign of slowing down.
Malware resistance and recovery require constant vigilance by every employee against phishing attacks, for example, and the provision of cyber-resilience for storage and the data estate integrated into the organization’s overall cybersecurity arrangements. Inadequate storage array security is an open door to malware miscreants.
Interview: The Open Flash Platform (OFP) group aims to replace all-flash arrays with directly accessed flash cartridges that have a controller DPU, Linux and parallel NFS (pNFS) software, and a network connection. That outline was revealed yesterday. We now have more details from the OFP and a context statement.
Molly Presley
Hammerspace is effectively leading the initiative, and global marketing head Molly Presley told us more about the background that led to the OFP group being set up. “As datacenter designs evolve, particularly in neoclouds, hyperscalers, and large AI companies, several constraints on infrastructure have appeared that legacy architectures don’t accommodate for. Storage systems that are focused on power efficiency, scalability, and simplicity of design are urgently needed in AI architectures in order to liberate power for GPUs, scale to the data capacity demands, and deploy fast.
“The OFP initiative would like to see a new solution that provides the most scalable, dense system for storing data power efficiently and cost effectively. With AI driving the need to move from PB scale to EB scale, more efficient and scalable architectures are needed beyond what the current systems defined on legacy building blocks can provide.
“The current default shared storage architecture and platforms have limitations to scaling and density that make them ill suited to the needs of environments that face massive data growth to fuel AI applications. Customers are currently using power-hungry servers running proprietary storage software, often backed by enclosures that are based on a disk drive form factor rather than a design that is optimized for flash density.
“The current generation of IPUs/DPUs has made this new low-power, high-density form factor possible. By coupling them with a flash-optimized enclosure and leveraging the advancements in standard Linux protocols for high-performance data services, we can deliver storage solutions that are extremely efficient while also driving down costs (i.e. no node level licensing, extending the service life to the flash lifetime of eight years, rather than server refresh cycle of five years, dramatically reducing power, space and cooling requirements).
“None of this is new on its own, but the OFP initiative seeks to combine the advancements in the capabilities of offload engines, NAND technology, and Linux capabilities available today into a design targeting an urgent industry need. This cannot be accomplished with another proprietary silo, and thus wider industry participation and adoption will be an essential goal of the initiative.”
We asked the group a set of questions and Presley sent the answers back.
Blocks & Files: How is the OFP funded?
OFP: Hammerspace has funded the initial engineering study to explore options for a working POC/reference design. ScaleFlux, Samsung and two other SSD vendors (who we do not yet have corporate approval to reference in the OFP initiative) provided SSDs. Xsight and other IPU/DPU vendors (who we do not yet have corporate approval to reference in the OFP initiative) have supplied development boards for the project. SK hynix and LANL have been doing demonstrations of pNFS capabilities leveraging native Linux storage and NFS functions. In summary, the initiative’s members are all bringing their technology and expertise to the table.
Blocks & Files: How is the OFP governed?
OFP: We are actively recruiting partners, but have not considered wider governance rules beyond the initial engineering-level collaborations between the participants. We have some concept of existing governing bodies that might get involved in the future and have some proposals in preparation for them. But those are future discussions.
Blocks & Files: What classes of OFP membership exist?
OFP: Participation falls into one of two categories: 1) technology providers; and, 2) end-user advisors. The OFP concept has been socialized with dozens of large-scale end users as well. Their input is being taken into design considerations.
Blocks & Files: Who defines the OFP cartridge specification in terms of physical form factor, SW interface, network interface, DPU form factor and interface, power interface and amount, etc.?
OFP: Initially, Hammerspace has developed a proposed reference specification for the tray, cartridge, electrical interfaces, software, thermals, etc. We are actively seeking feedback from not only members of the initiative, but prospective customers as well. Other implementations would also be welcome.
Blocks & Files: Does an OFP cartridge specification exist?
OFP: We have a preliminary specification that allows both standard and new form-factor SSDs to reside in the cartridge, and are working within the group of initiative partners to solicit feedback before announcing anything publicly. We anticipate further announcements regarding the canister and tray designs during the second half of 2025, including a working prototype for public demonstration toward the end of the year.
Blocks & Files: How is OFP cartridge product specification compliance validated?
OFP: TBD.
Blocks & Files: Who defines the OFP tray specification?
OFP: Same as above. Initially.
Blocks & Files: Does an OFP tray specification exist?
OFP: Yes, see above.
Blocks & Files: Which datacenter rack designs does the OFP tray specification support?
OFP: First reference design will be EIA 19″ rack but we also have plans for an OCP 21″ rack design.
Blocks & Files: Which suppliers build OFP trays?
OFP: Initially, only a contract manufacturer but discussions with OEM and system integrators are in progress.
Blocks & Files: How is OFP tray product specification compliance validated?
OFP: We are already working with Meta on ultimately having this OFP initiative subsumed into OCP. That is the ultimate goal.
We have seen considerable industry-wide interest, with more partners joining the conversation in the design requirements as well as likely new members joining the public effort in the coming weeks. We also have substantial early customer interest. Releasing information about the initiative as it matures is incredibly important to the datacenter designs and infrastructure strategies being planned for the coming years. As you well know, massive investments in AI are in the works. Visibility to emerging architectures is very valuable as the industry evolves at such breakneck speed.
Index Engines has a newly patented process for continuous training of AI/ML models on real-world attack patterns.
The company supplies a CyberSense product that uses AI and machine learning analysis to check changes in unstructured data content over time in order to detect suspicious behavior and ransomware-related corruption. Storage suppliers using CyberSense include Hitachi Vantara, Dell, IBM, and Infinidat. The Index Engines CyberSense Research Lab developed software to automate the ingestion and behavioral analysis of ransomware variants in a controlled clean-room environment, and so train its AI and ML models on real-world attack patterns. This is intended to boost accuracy and cuts down on false positives.
Geoff Barrall
Geoff Barrall, chief product officer at Index Engines, stated: “Cyber resilience requires more than reactive tools – it demands AI that’s been rigorously trained, tested, and proven in real-world conditions. Our patented automated facility downloads, detonates, and monitors real ransomware to continuously train and refine our models – something no simulation can replicate.”
Index Engines CMO Jim McGann added: “To truly defend against ransomware, you have to think like the adversary. That means studying how these threats behave – not just guessing what they might do. At Index Engines, we’ve patented a process that does exactly that.”
Its augmented training is claimed to result in “faster corruption detection to maintain currency with the threat landscape, smarter recovery decisions, and stronger data integrity.”
US patent 12248574 refers to “AI identification of computer resources subjected to ransomware attack.” It states: “A method provides a set of computer data statistical profiles derived from a corresponding set of samples of computer data to a ransomware detection system and obtains a prediction of the likelihood of a ransomware attack in the set of samples of computer data.” You can check out its text and diagrams by searching for 12248574 on the US Patent Public Search 2.2.0 website.
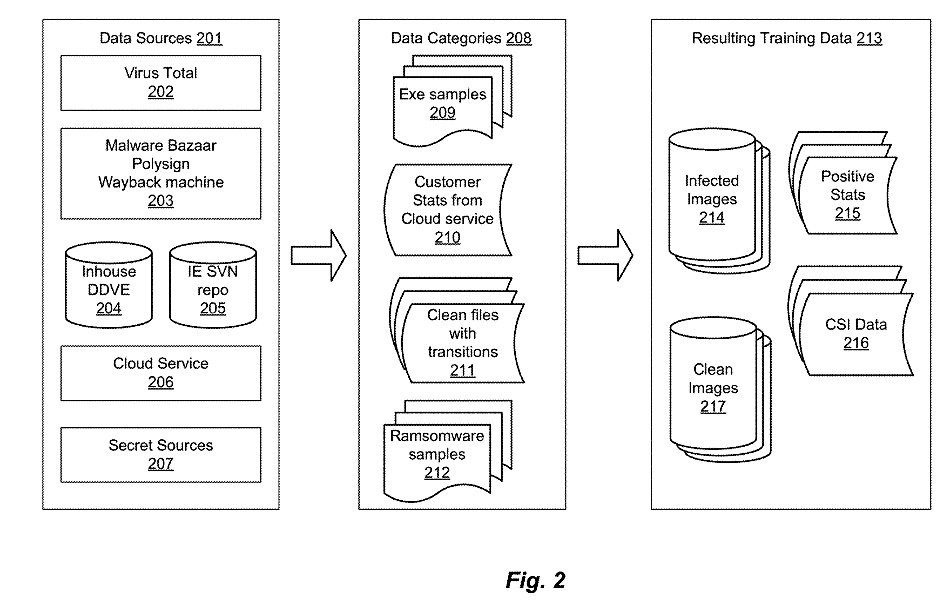
Diagram in #12248574 patent showing the data sources used for developing training data, the categories of data obtained during the acquisition process, and the resulting training data generated after acquisition
We’re told that Index Engines’ new approach to CyberSense model training has been validated 99.99 percent effective in detecting ransomware-induced corruption by Enterprise Strategy Group (ESG). Its testing involved 125,000 collected data samples, some 94,100 infected with ransomware. The Index Engines CyberSense product detected 94,097 with three false negatives. The ESG report can be downloaded from an Index Engines webpage.