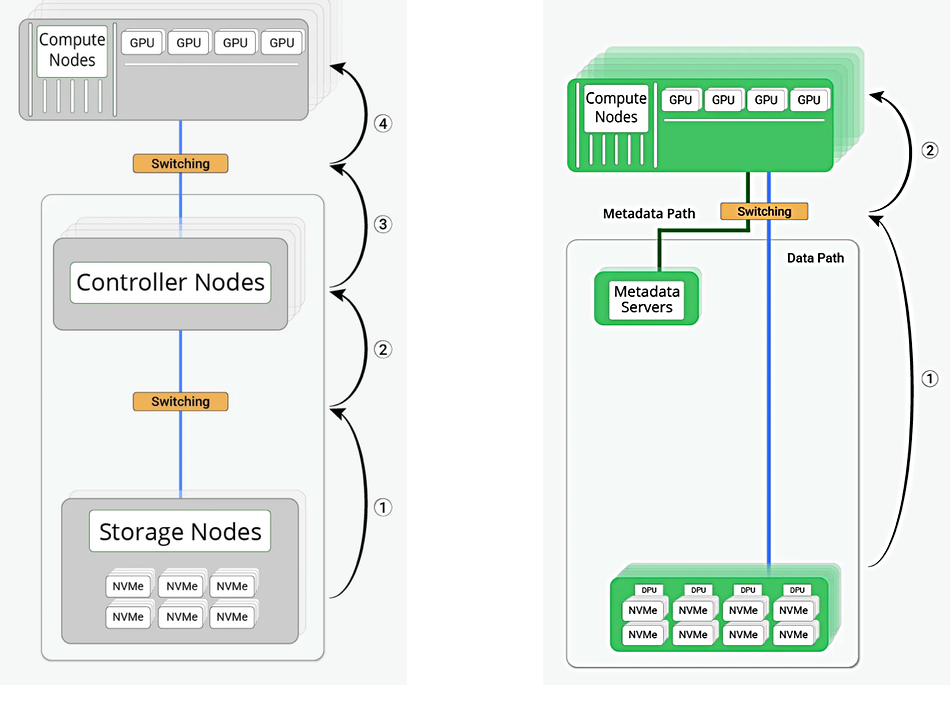
An Open Flash Platform (OFP) group is aiming to rewrite flash storage standards for AI by getting rid of all-flash arrays and their controllers, replacing them with shelves of directly-accessed OFP flash cartridges using pNFS and DPUs to provide parallel data access
OFP is a six-member group comprising Hammerspace, the Linux community, Los Alamos National Laboratory (LANL), ScaleFlux, SK hynix, and Xsight Labs. At its launch this week, it claimed: ”the convergence of data creation associated with emerging AI applications coupled with limitations around power availability, hot datacenters, and datacenter space constraints means we need to take a blank-slate approach to building AI data infrastructure.”
Hoshik Kim, SVP, Head of Memory Systems Research at SK hynix, said in a statement: “Flash will be the next driving force for the AI era. To unleash its full potential, storage systems must evolve. We believe that open and standards-based architectures like OFP can maximize the full potential of flash-based storage systems by significantly improving power efficiency and removing barriers to scale.”
The OFP group claims it unlocks “flash as the capacity tier by disintermediating storage servers and proprietary software stacks. OFP leverages open standards and open source – specifically parallel NFS and standard Linux – to place flash directly on the storage network.”
OFP diagram showing existing storage server design with 4 network hops (left) and OFP cartridge scheme with just 2 hops
Current systems, OFP said, are “inherently tied to a storage server model that demands excessive resources to drive performance and capability. Designs from all current all-flash vendors are not optimized to facilitate the best in flash density, and tie solutions to the operating life of a processor (typically five years) vs the operating life of flash (typically eight years).”
One might argue instead that Pure Storage and other all-flash-array (AFA) suppliers have licensing and support subscription schemes that provide automatic and non-disruptive controller upgrades. They can also support flash shelf upgrades. Pure also offers greater flash density than many SSD vendors. VAST Data already supports its software running on Nvidia BlueField-3 DPUs. Most all-flash array vendors support RDMA access to their drives with GPUDirect support.
The OFP scheme features:
Flash drives focused on QLC, but not exclusively, with flexibly sourced NAND purchasable from various fabs, “avoiding single-vendor lock-in.” [We think that NAND purchasing is flexible currently and a Kioxia SSD can be switched to a Solidigm SSD or to a Samsung SSD quite easily. Also, SSD suppliers like Kingston and Phison can use NAND chips from various vendors.]
OFP cartridge containing all of the essential hardware – NAND, DPU – to store and serve data in a form factor that is optimized for low power consumption and flash density.
IPUs/DPUs to provide cartridge processing power at a lower cost and lower power requirement than x86 processors.
OFP tray to hold a number of OFP cartridges and supplying power distribution and mounting for various datacenter rack designs.
Standard Linux running stock NFS to supply data services from each cartridge.
The OFP conceded: “Our goals are not modest and there is a lot of work in store, but by leveraging open designs and industry standard components as a community, this initiative will result in enormous improvements in data storage efficiency.”
The group claims its scheme can provide 1 EB of flash storage per rack, an over 10x density increase, 60 percent longer flash operating life, a 90 percent decrease in electrical power, and 50 percent lower total cost of ownership compared to the standard storage array way of doing things. How the OFP will deliver these benefits is not yet answered.
Comment
As a standards group aiming to disintermediate storage servers and proprietary software stacks, it seems lightweight. Unless there is more to this than it seems at first sight, the OFP could be consigned to marketing initiative status rather than to a serious all-flash storage standards effort.
Two members appear to have limited influence on standards development around all-flash storage. Most storage array vendors use Linux so there’s nothing revolutionary stemming from the Linux Foundation’s membership. The Los Alamos National Labs involvement seems nominal. Gary Grider, director of HPC at LANL, said: “Agility is everything for AI – and only open, standards-based storage keeps you free to adapt fast, control costs, and lower power use.”
Well, yes, but the AFA suppliers do use standards-based storage – NVMe, NFS, S3, PCIe, standard drive formats, etc. LANL is like a trophy HPC site adding a dash of high-end user glamour to the OFP but not a lot of substance.
Looking at the four core members – Hammerspace, ScaleFlux, SK hynix and Xsight Labs – we can consider who is not involved:
Every NAND and SSD supplier apart from SK hynix
Every IPU/DPU supplier apart from Xsight Labs
Every software-defined storage supplier supporting flash storage
Every storage data management/orchestration supplier apart from Hammerspace
Let’s follow the money. Who will profit if OFP takes off? Hammerspace may sell more of its GDE software. SK hynix may sell more NAND chips and could make OFP cartridges. Computational storage supplier ScaleFlux could make and sell OFP cartridges. Xsight may sell more E1 datacenter switches. Los Alamos might be able to buy cheaper kit. Linux could become more popular. It’s not difficult to see how vendors involved may benefit from broader adoption.
We have asked Hammerspace, ScaleFlux, SK hynix, and Xsight Labs the following questions about this OFP initiative:
How is the OFP funded?
How is the OFP governed?
What classes of OFP membership exist?
Who defines the OFP cartridge specification in terms of physical form factor, software interface, network interface, DPU form factor and interface, power interface, and amount?
Does an OFP cartridge specification exist?
Who defines the OFP tray specification?
Does an OFP tray specification exist?
Which datacenter rack designs does the OFP tray specification support?
Which suppliers build OFP trays?
We also asked how the OFP relates to Meta’s specification-rich Open Compute Project (OCP). OFP could be a solid and effective standards body, like OCP, but it is very early days with only four product-delivering members and a website with a single blog post delivering an assault on network-attached all-flash storage. Let’s see how it develops. It’s seeking members and you can join at the bottom of this webpage.
Bootnote
Seagate and others have floated the idea of Ethernet-accessed drives before as a way of simplifying storage arrays. Hammerspace CEO and founder David Flynn proposed an NFS SSD idea in 2023. The OFP cartridge is, in essence, an NFS-accessed SSD with a DPU and network connection.
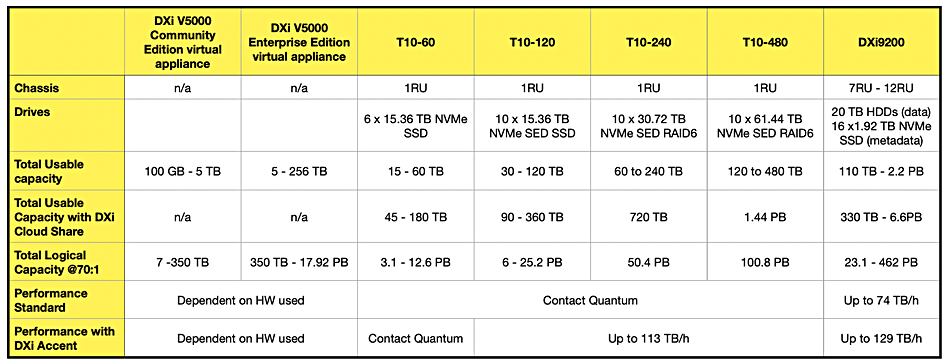
Quantum has added two more DXi all-flash deduplicating backup storage products to its range, doubling and quadrupling the previous all-flash maximum capacity.
The DXi product line is built to store backups from a dozen-plus backup suppliers, including Commvault, Cohesity-Veritas, Dell, HPE-Zerto, HYCU, IBM, and Veeam. Backups are deduplicated with a claimed ratio of up to 70:1. There is a software-only virtual V5000 offering, along with the pre-existing T10-60 and T10-120 products, where the number indicates the maximum usable capacity in terabytes. The top-end DXi9200 model has a 110 TB to 2.2 PB usable capacity range using a mix of disk drives, for data, and SSDs for metadata. Now Quantum has added T10-240 and T10-480 models, which use 30.72 TB and 61.44 TB SSDs, respectively, to achieve their higher capacities.
Sanam Mittal, general manager of DXi, stated: “With the DXi T10-240 and T10-480, we’ve quadrupled the usable capacity of our T-Series offerings in the same 1U footprint while preserving affordability and flexibility through software-based capacity activation. This is a breakthrough in efficient, high-performance backup operations.”
When compared to disk drive-based deduping backup targets, all-flash products can deliver faster ingest and restore. The T10 products provide up to 113 TB/hour throughput. This compares to disk-based ExaGrid’s maximum 20.2 TB/hour with its EX189 product. Dell’s all-flash DD9910 PowerProtect model delivers up to 130 TB/hour, which is in the same ballpark as Quantum.
ExaGrid CEO Bill Andrews has said his firm can build an all-flash product when it’s needed. That time could be approaching.
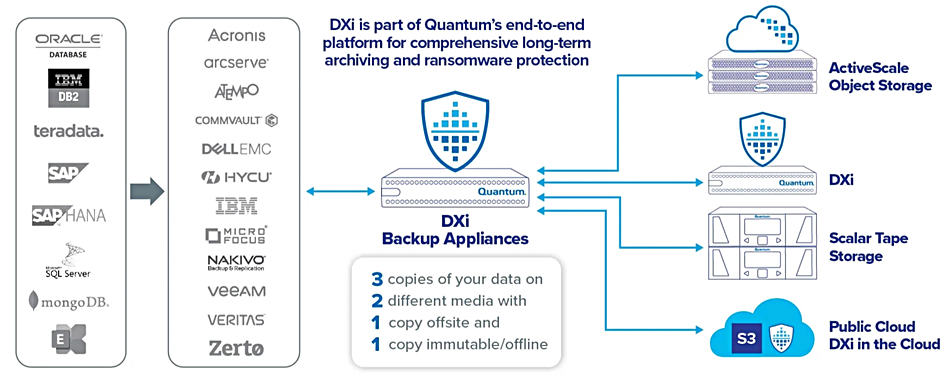
Quantum positions the DXi appliances as part of a 3-2-1-1 backup strategy, meaning 3 copies of a customer’s data on 2 different media with 1 copy offsite and 1 immutable copy offline. DXi appliances can send data to Quantum’s DXi 9200 for petabyte-scale on-premises retention, ActiveScale object storage, or Scalar tape libraries for long-term and immutable retention, and to DXi instances in the public cloud, to help customers implement a 3-2-1-1 backup scheme.
Quantum DXI place in its 3-2-1-1- backup strategy scheme
Quantum provides software-based pay-as-you-grow licensing. Customers can activate the capacity they need and then expand in increments of 15 TB or 30 TB over time.
The DXi T10-240 and T10-480 appliances are available now. Check out a DXi datasheet here.
Cloudian engineers have added Nvidia GPUDirect support to a PyTorch connector to accelerate AI and machine learning workloads.
In the machine learning world, the Torch open source software library interfaces with deep learning algorithms. It was started in 2001 and became PyTorch in 2018. The PyTorch ecosystem serves millions of developers worldwide, from individual researchers to enterprise operations. Meta is a major contributor to PyTorch, and companies like Tesla, Hugging Face, and Catalyst also use PyTorch for developing AI and deep learning models. Cloudian added GPUDirect support for objects to its HyperStore scale-out storage last year, and Milvus vector database functionality earlier this month. Now it has built a connector linking its HyperStore object storage to PyTorch libraries. This connector supports GPUDirect and RDMA, and is optimized for Nvidia Spectrum-X Ethernet networking and ConnectX SuperNICs.
Jon Toor
Cloudian CMO Jon Toor tells us: “This development represents a major advancement for organizations running artificial intelligence and machine learning workloads, delivering a remarkable 74 percent improvement in data processing performance while simultaneously reducing CPU utilization by 43 percent.”
This connector eliminates traditional network bottlenecks through direct memory-to-memory data transfers between Cloudian storage systems and GPU-accelerated AI frameworks. It processes 52,000 images per second versus 30,000 with a standard S3 connector, based on TorchBench testing.
Toor says it helps provide a more efficient AI infrastructure architecture. “This efficiency gain becomes increasingly valuable as AI models grow larger and more complex, requiring faster data access patterns to maintain training productivity.”
The Cloudian PyTorch connector is now available for evaluation by PyTorch users, AI researchers, and users involved in enterprise ML operations, computer vision, and other AI/ML applications.
Bootnote
Benchmark testing was conducted using Cloudian HyperStore 8.2.2 software running on six Supermicro servers equipped with Nvidia networking platforms in an all-flash media configuration, representing enterprise-grade storage infrastructure commonly deployed for GPU-accelerated AI workloads.
Seagate has announced global channel availability for its 28 and 30 TB Exos M datacenter and IronWolf Pro NAS disk drives, both conventionally recorded drives built with HAMR technology.
HAMR (heat-assisted magnetic recording) uses a laser to temporarily heat a high coercivity bit area, reducing its resistance to magnetic state change, and then cooling to achieve a higher areal density than the prior perpendicular magnetic recording (PMR) tech, which operates at room temperature. HAMR drives can have shingled (partially overlapped) write tracks to improve their capacity at the expense of slower data rewrite performance.
Seagate ships Exos M drives with 32 and 36 TB capacity using SMR technology. There are no SMR IronWolf Pro drives.
Melyssa Banda
Melyssa Banda, SVP of Edge Storage and Services at Seagate, stated: “Data gravity is increasingly pulling networks to the edge as nearly 150 countries adopt data sovereignty requirements, and AI workloads continue to expand. Datacenters – on-prem, private, and sovereign – are leveraging AI to unlock the value of their proprietary data. Our 30 TB drives are designed to support these rapidly growing trends, delivering the capacity, efficiency, and resilience needed to power the AI workloads.”
Exos M drives feature a 3.5-inch form factor, spin at 7,200 rpm, contain ten helium-filled platters, offer a 2.5 million-hour MTBF rating, a five-year limited warranty, and a 6 Gbps SATA interface. Seagate first announced the 30 TB Exos M in January last year. Following extended qualification by hyperscaler customers and the shipment of more than 1 million HAMR drives, it is now generally available.
IronWolf Pro drives are a variant of the Exos line and previously topped out at 24 TB. Now the line gets a lift to 28 and 30 TB capacity levels, courtesy of HAMR tech. They have an up to 550 TB/year workload rating, 2.5 million hours MTBF, and a five-year limited warranty.
Seagate is positioning the new Exos M drives as edge AI data storage devices, “empowering organizations to scale storage, optimize data placement, and support real-time edge analytics without compromising performance or sustainability.”
It added: “On-premises NAS systems are evolving into intelligent data hubs – supporting advanced workloads such as video analytics, image recognition, retrieval-augmented generation (RAG), and inferencing at the edge.” Seagate quotes recent market analysis projecting the global NAS market to grow at a CAGR of over 17 percent through 2034, driven by digital transformation and the rise of AI and big data analytics.
Seagate’s view is that HDDs complement SSDs in AI edge applications. It cites Ed Burns, Research Director, Hard Disk Drive and Storage Technologies at IDC, who said: “While not often associated with performance such as low latency, the highest capacity HDDs are a critical strategic asset in the AI development process, filling the need for mass capacity storage of the foundational data essential to building and improving the highest quality AI models in the market today and into the future.”
Seagate refers to HPE for an edge AI market growth number: “HPE forecasts the on-prem AI market will grow at a 90 percent CAGR, reaching $42 billion within three years.”
Until now, the AI edge market has not significantly boosted HDD sales.
Seagate’s disk competitors are presently playing catch-up. Western Digital’s Ultrastar HDDs top out at 26 TB with the CMR H590, and it uses SMR to take them to the 28 (HC680) and 32 (HC690) TB capacity levels. Its Red Pro NAS drive also has a maximum 26 TB capacity.
Toshiba’s shingled MA11 reaches the 28 TB level and it has a conventionally recorded MG11 drive with 24 TB.
Seagate’s disk product webpage provides more information about the new drives. The Exos M and IronWolf Pro 28 TB and 30 TB drives are available now through Seagate’s online store as well as authorized resellers and channel partners worldwide.
Exos M and IronWolf Pro 30 TB drives are priced at $599.99 with the equivalent 28 TB products set at $569.99. UK pricing is somewhat different. It’s £498.99 for the Exos M 30 TB and £478.99 for the Exos M 28 TB. But it is £559.99 for the IronWolf Pro 30TB and £526.99 for the IronWolf Pro 28 TB.
Meta is eyeing a massive AI datacenter expansion program with the chosen storage suppliers set for a bonanza.
CEO Mark Zuckerberg announced on Facebook: “We’re going to invest hundreds of billions of dollars into compute to build superintelligence. We have the capital from our business to do this,” referring to Meta Superintelligence Labs.
“SemiAnalysis just reported that Meta is on track to be the first lab to bring a 1 GW-plus supercluster online. We’re actually building several multi-GW clusters. We’re calling the first one Prometheus and it’s coming online in ’26. We’re also building Hyperion, which will be able to scale up to 5 GW over several years. We’re building multiple more titan clusters as well. Just one of these covers a significant part of the footprint of Manhattan.”
Facebook’s Hyperion datacenter illustration
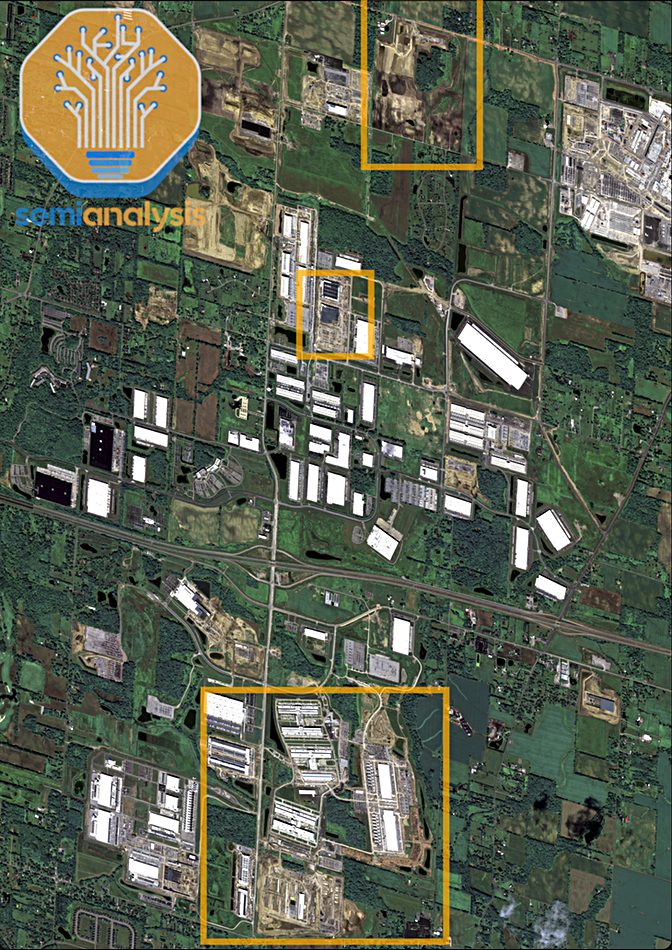
The SemiAnalysis post says Meta is involved in “the pursuit of Superintelligence” and its Prometheus AI training cluster will have 500,000 GPUs, draw 1,020 MW in electricity, and have 3,171,044,226 TFLOPS of performance. This Prometheus cluster is in Ohio and has three sites linked by “ultra-high-bandwidth networks all on one back-end network powered by Arista 7808 Switches with Broadcom Jericho and Ramon ASICs.” There are two 200 MW on-site natural gas plants to generate the electrical power needed.
Prometheus sites in Ohio
SemiAnalysis talks about a second Meta AI frontier cluster in Louisiana, “which is set to be the world’s largest individual campus by the end of 2027, with over 1.5 GW of IT power in phase 1. Sources tell us this is internally named Hyperion.”
Datacenter Dynamics similarly reports that “Meta is also developing a $10 billion datacenter in Richland Parish, northeast Louisiana, known as Hyperion. First announced last year as a four million-square-foot campus, it is expected to take until 2030 to be fully built out. By the end of 2027, it could have as much as 1.5 GW of IT power.”
Zuckerberg says: “Meta Superintelligence Labs will have industry-leading levels of compute and by far the greatest compute per researcher. I’m looking forward to working with the top researchers to advance the frontier!” These Superintelligence Labs will then be based on the 1 GW Ohio Prometheus cluster with 500,000 GPUs, the Hyperion cluster in Louisiana with 1.5 GW of power, and by extrapolation 750,000 GPUs in its Phase 1, and “multiple more titan clusters as well.”
Assuming three additional clusters, each with a Prometheus-Hyperion level of power, we arrive at a total of between 2.75 and 3 million GPUs. How much storage will they need?
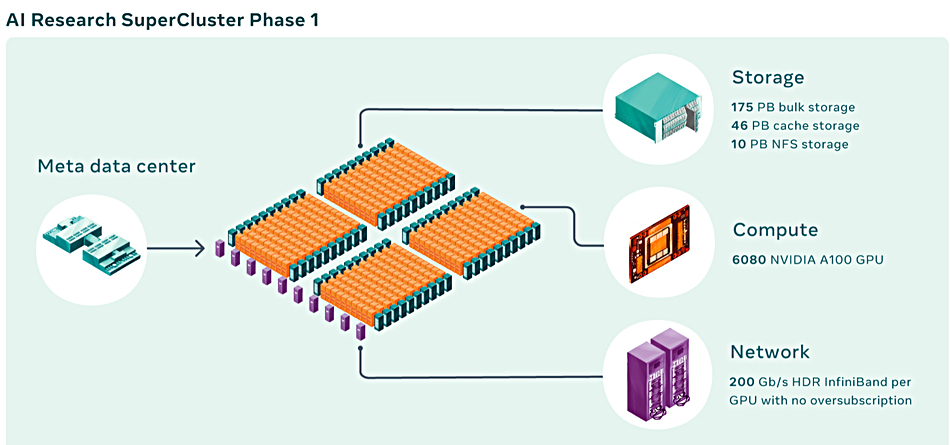
In January 2022, a Meta AI Research SuperCluster (RSC) had 760 Nvidia DGX A100 systems as its compute nodes for a total of 6,080 GPUs. These needed 10 PB of Pure FlashBlade storage, 46 PB of Penguin Computing Altus cache storage, and 175 PB of Pure FlashArray storage:
That’s 185 PB of Pure storage in total for 6,080 GPUs – 30.4 TB/GPU. On completion, this AI RSC’s “storage system will have a target delivery bandwidth of 16 TBps and exabyte-scale capacity to meet increased demand.”
Subsequent to this, Pure announced in April that Meta was a customer for its proprietary Direct Flash Module (DFM) drive technology, licensing hardware and software IP. Meta would buy in its own NAND chips and have the DFMs manufactured by an integrator. Pure CEO Charlie Giancarlo said at the end of 2024: “We expect early field trial buildouts next year, with large full production deployments, on the order of double-digit exabytes, expected in calendar 2026.”
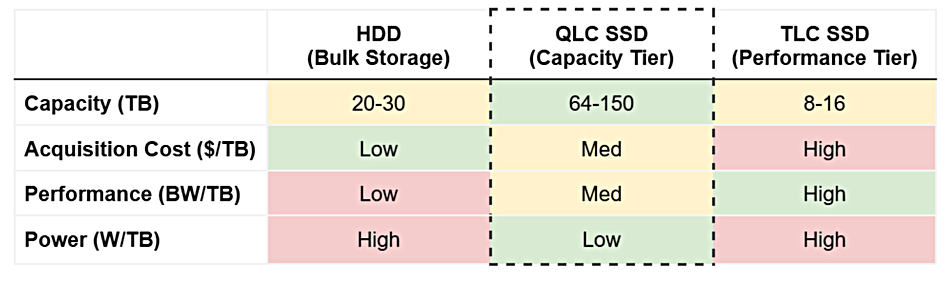
A March 2024 Meta blog discussed three tiers of Meta datacenter storage:
HDD – the lowest performance and the bulk data tier with 20-30 TB/drive
QLC SSD – the capacity tier and medium performance with 64-150 TB/drive
TLC SSD – the performance tier with 8-16 TB/drive
Meta will, we can assume, be buying both HDD and flash storage for its AI superclusters, with Pure Storage IP being licensed for the flash part and NAND chips bought from suppliers such as Kioxia and Solidigm. How much flash capacity? Training needs could be 1 PB per 2,000 GPUs, while inference could need 0.1 to 1 TB per GPU, so halve the difference and say another 1 PB per 2,000 GPUs.
We don’t know the mix of training and inference workloads on Meta’s AI superclusters and can’t make any realistic assumptions here. But the total flash capacity could approach 1.5 EB. We have asked Pure Storage about its role in these AI superclusters, but it had no comment to make.
Meta is also a Hammerspace Global Data Environment software customer for its AI training systems. We have asked Hammerspace if it is involved with this latest supercluster initiative and Molly Presley, Head of Global Marketing, told us: “Hammerspace is very involved in many architectural discussions and production environments at Meta. Some in data center and some in cloud / hybrid cloud. I am not able to comment on if Meta has finalized their data platform or storage software plans for these superclusters though.”
The disk drives will surely come from Seagate and Western Digital. Seagate has said two large cloud computing businesses had each bought 1 EB of HAMR disk drive storage, without identifying Meta.
Two more considerations. First, the 3 million or so GPUs Meta will be buying will have HBM memory chips, meaning massive orders for one or more HBM suppliers such as SK hynix, Samsung, and Micron.
Secondly, Meta will have exabytes of cold data following its training runs and these could be thrown away or kept for the long term, which means tape storage, which is cheaper for archives than disk or SSDs.
CIO Insight reported in August 2022 that Meta and other hyperscalers were LTO tape users. It said: “Qingzhi Peng, Meta’s Technical Sourcing Manager, noted that his company operates a large tape archive storage team. ‘Hard disk drive (HDD) technology is like a sprinter, and tape is more like a marathon runner,’ said Peng. ‘We use tape in the cold data tier, flash in the hot tier, and HDD and flash in the warm tier.'”
There is no indication of which supplier, such as Quantum or Spectra Logic, provides Meta’s tape storage, but it could be set for tape library orders as well.
Interview: Veeam is developing software to enable large language models (LLMs) and AI agents to trawl through reams of Veeam backup data and analyze it to answer user or agent requests. The work was disclosed by Rick Vanover, Veeam’s VP for Product Strategy in its Office of the CTO, during a briefing in London last week.
Blocks & Files: So here you are with Veeam, top of the data protection heap, and built on VMware to some degree. But now, with VMware switchers emerging as Broadcom changes licensing terms, is Veeam intending to support all the VMware switchers so that you don’t lose any momentum with virtualized applications?
Rick Vanover
Rick Vanover: Make no mistake, we started as VMware-only. I’m in my 15th year at Veeam and when I started, that’s what it was. It was only VMware backup in 2011. We added Hyper-V in 2014, we added physical 2016, we added Microsoft 365 and it just runs and runs. Recently we added Proxmox and we just announced Scale Computing. We just announced HPE VM Essentials. So we’re expanding the hypervisor footprint, but are we going to help [people] move? Are we an evacuation tool? Absolutely not. We’ve got another one planned, but we haven’t announced it yet. So we’re not done.
Blocks & Files: When considering virtualized server platforms, do you lean more toward enterprise adoption than small business?
Rick Vanover: It’s demand. That’s very accurate. But I will say we look at product telemetry, the percentages of who’s using what. The biggest benefactor [of VMware migration] has been Hyper-V. That’s the biggest. That makes sense. One that we’ve seen grow, but we’re definitely looking at this to support the platforms as they grow. And we have an opportunity to have parity across them. VMware is by far the most capable stack, then Hyper V, then Nutanix, and then it goes way down real quick.
Blocks & Files: Suppliers at the low end, like VergeIO, put themselves in the VMware switch target market. I imagine that, at the moment, they’re probably too small scale for you to bother with.
Rick Vanover: The way we approach it is not just market share, but we also have to look at what customers and partners are asking for, and is the money going to work out, and concurrently we’re going to assess the QA burden, the development cost to get there. And what we announced with HPE VM Essentials, those analyses were done and it was worth going into. So nothing to share with VergeIO other than we’re very aware.
Blocks & Files: The collected Veeam backed-up data, for a large customer especially, is huge. AI needs access to proprietary data for RAG (retrieval-augmented generation). And if the people implementing RAG in an enterprise can say, let’s point it at one place, go to the one place where everything is. Like the backups. The question is: are you doing anything to help enterprises source RAG content from your backups?
Rick Vanover: Yes. Do we have anything fully productized and available to do that today? No, but what I would say for you on that is, we have the plumbing to do that. In fact, there’s this blur between something that’s fully productized and then something you can do with a product. [Something] semi-productized, semi-supported. We have something like that now with what we are calling Retro Hunter, which is a way to scan through all the backups.
It’s not AI, but it’s an example of looking at the data under management by Veeam. Now that use case is for threats. It’s not yet at that level of building data insights in the AI RAG world. We announced Veeam Guardian at VeeamOn, and we did some showcasing of our Model Context Protocol work. But it’s not out yet. There’s several other things in the works, make no mistake. That is absolutely where we are going.
Blocks & Files: With that in mind, if we look at an AI stack as a data source at the bottom, and AI agents or large language models at the top, they’ve got to go look in a vector database for the vector embedding. So there has to be some kind of AI pipeline connecting the source through some ETL procedures to produce vectors and put them in a database so agents can look at them. Now, vectorizing the data has to be done as well. So, the Veeam backup repository, if its contents are going to be made available to an AI data pipeline, where does Veeam’s interest stop? And where does the AI data pipeline involve other suppliers?
Rick Vanover: Let me highlight the vector conversation, the vector database point. That is actually something that we’ve been protecting already. In fact, at KubeCon last year, we even had a session of how some of our engineers showed how you can protect that with our Kanister product to actually protect the vector data.
Then if we go down to the data layer, we can be that data. And we’ve had a number of storage partners actually start to work at taking copies and moving it around to feed other AI solutions. And at that point, we may be part of the data stack, but then the rest of the application is homegrown or otherwise. But make no mistake, there will be a time that we have AI solutions that are going to go the full distance there for organizations.
That acquisition we did in September, Alcion, that is a team that’s absolutely working on that very deliverable that you speak of. We showcased part of it at VeeamOn with what we’re going to be doing with Anthropic with the Model Context Protocol for data under management by Veeam.
Blocks & Files: You would have some kind of software layer above the data under management and it will support MCP so that an agent could come along and say, give me the data relating to this department over a period of time?
Rick Vanover: Exactly. That would be done in Veeam Data Cloud, our backup storage-as-a-service. And in the example we showed at VeeamOn, we are doing it from Microsoft 365 data. We used Model Context Protocol to crawl through years of data to answer questions about the business or the scenario. And I know how to use Veeam, but the example that was shown there within three minutes would’ve taken me a week to produce. And that’s the result that people want to talk to their data.
That’s the goal and we showed a piece of that. We’re on a journey. We are working on it, [and] we gave a preview.
Participating in a simulated ransomware attack showed up the glaring need for attack response playbooks and insulated clean room recovery facilities, as even immutable backups could contain undetected ransomware-infected data.
Cohesity runs Ransomware Resilience Workshops in which participants take on exec roles in a business that experiences a cyberattack that encrypts its data. The business had no pre-existing ransomware attack response plan and the workshop experience was eye-opening.
The workshop was run by Mark Molyneux, Cohesity’s EMEA CTO and an ex-director for global storage, virtualization, and cloud at Barclays Bank. He had set up a scenario in which a fictional retail business, which they dubbed “Dan’s Doughnuts”, with 12,900 stores worldwide and a $1.3 billion annual turnover, was hit by ransomware. Attackers encrypted files, exposed staff identity and system monitoring facilities, and then sent a message to company execs, saying they had 48 hours to pay a ransom of more than $1 million in Bitcoin:
The IT admin team couldn’t initially access the datacenter building, as the computer-controlled entry system was not functioning, and nor could they monitor datacenter operations remotely as that application was down. Most business IT operations, including finance and product distribution and billing, were down. Management was effectively blindfolded.
We attendees took on roles such as the business’s CEO, CIO, CISO, chief legal officer, and PR head with prepared background motivations and responses to each other’s questions. As we grappled with what to do, an attacker called Igor sent a series of threatening messages upping the tension and stakes.
What was immediately and devastatingly apparent was that we, as a mock exec team, had no idea how to cope. Non-IT people had to understand the role of a NOC SharePoint server, domain controllers, and so forth, and IT people were confronted with business implications, such as lost revenue, a damaged reputation, and legal risks in paying Bitcoin – how does a business even buy Bitcoin? – to an entity that may be based in a sanctioned country.
Eventually, the company’s board became involved and were aggressively angry with what they perceived as management shortcomings affecting stock price.
It became abundantly clear that asking business execs and managers to organize an effective response on the fly was chaotic and stressful. Identifying the affected business systems and recovery of data, even with a ransom paid to get encryption keys, was lengthy and time-consuming. Nothing could be restored directly into production environments as you cannot take the risk that the restored data, even if immutable, had been compromised as well.
There wasn’t even a plan to specify in what order IT systems and apps had to be recovered. Of course not; it was a simulation exercise. But does your organization actually have a ransomware attack playbook that specifies these things?
Who is responsible for what? And how they can be contacted out of hours? Who are the substitutes if the main people are unavailable? And do they know they must never switch off their work phones?
Data recovery was slowed because immutable backups may contain unclean data infected by ransomware that is newer than the ransomware detection engine used to scan backups for the last known good copy. The immutable copy has to be restored to a clean room and checked before it is released to production use. There is simply no silver restore bullet from immutable backups.
Tape backup restores take a long, long time, and they too have to pass through a clean room cycle.
The first critical lesson we learnt is that you have to have a plan, and the best way to build that is to experience a simulated attack. It has to be as close to reality as can be, and then assess what needs to be done, in what sequence and by whom, in order to get a fallback system in place and understand the minimum viable set of critical business systems required to operate.
This is not a trivial exercise and it had best involve board members so they too can understand the pressures and needs inside the business and how best they can help.
A second vital lesson is employee phishing attack training. Such attacks should be detected and reported. The training should encompass employees in partner organizations who can access your systems – and it should be ongoing.
How did we attendees do in our simulated attack? I’m not going to say as the result was rather embarrassing.
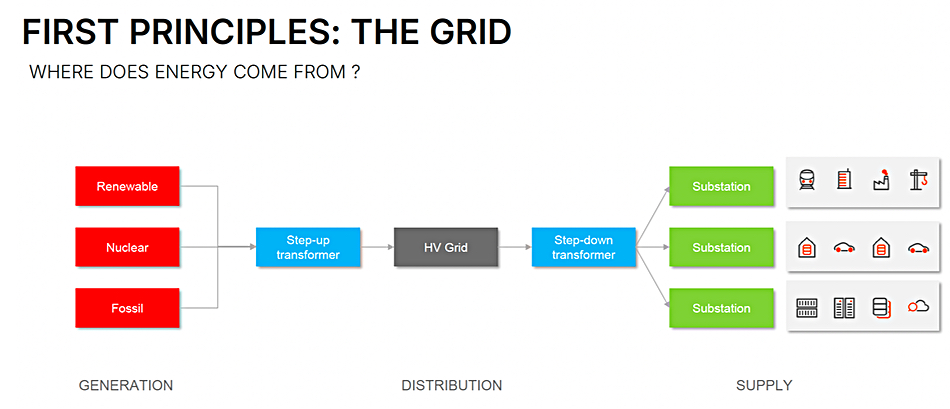
Datacenters face a period of power supply limitations that affect their growth and the growth of the IT services they will provide. Lower power-consuming IT devices will help but the GPUs needed for AI use vastly more electricity than X86 servers. Hyperscalers can build their own datacenter energy generators but the rest of us are dependent on national grids and they are slow-development systems, meaning we face a restriction on the growth of IT services for businesses and consumers as IT service demand will exceed electricity supply growth.
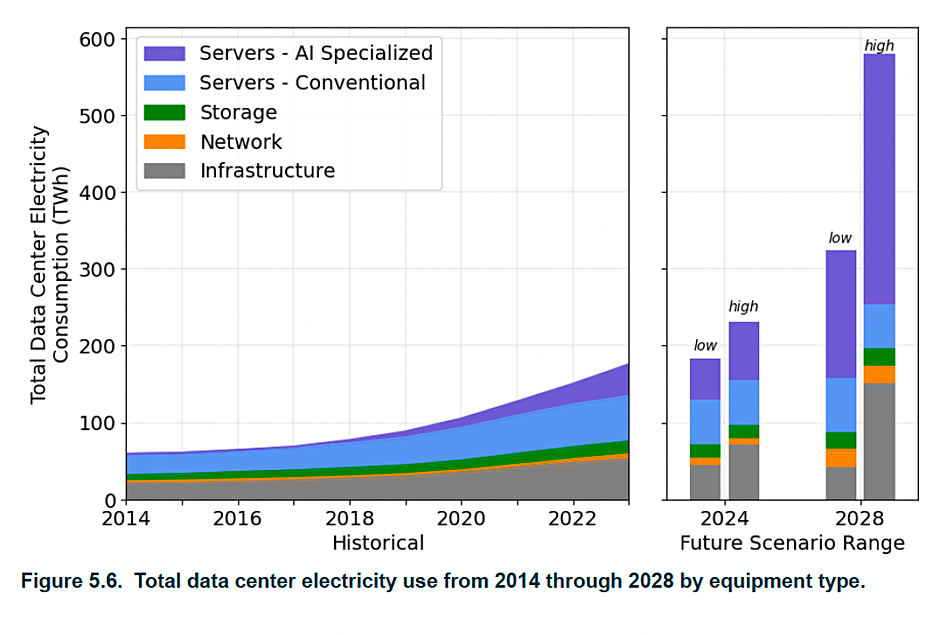
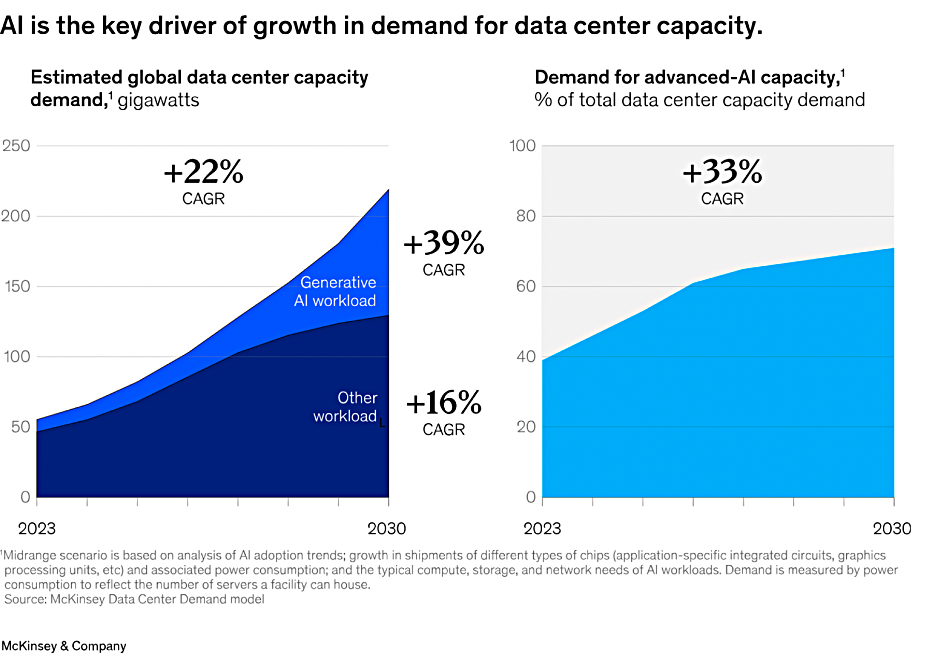
Datacenter growth is continuing. Research from the Dell’Oro Group shows the Data Center Physical Infrastructure (DCPI) market grew 17 percent YoY in 1Q 2025. This marks the fourth consecutive quarter of double-digit growth, fueled by continued investment from hyperscalers and colocation providers building out capacity to cope with demand of artificial intelligence (AI) workloads. It noted surging adoption of liquid cooling (DLC revenue doubled), high-density power racks nearing 600 kW, and 40 percent+ growth in power distribution systems like busways.
While all regions posted growth, North America outpaced the rest with a 23 percent Y/Y increase. A US DOE report found that datacenters consumed about 4.4 percent of total U.S. electricity in 2023 and are expected to consume approximately 6.7 to 12 percent of total U.S. electricity by 2028. The report indicates that total datacenter electricity usage climbed from 58 TWh in 2014 to 176 TWh in 2023 and estimates an increase between 325 to 580 TWh by 2028.
Alex Cordovil Araujo, Research Director at Dell’Oro Group, said: “The shift to accelerated computing is reshaping the datacenter landscape,” said Alex Cordovil, Research Director at Dell’Oro Group. “AI is more than a tailwind—it’s a structural force driving demand for new infrastructure paradigms. Liquid cooling is gaining traction fast, and high-density power architectures are evolving rapidly, with racks expected to reach 600 kW soon and 1 MW configurations already being under consideration.”
Its Data Center IT Capex 5-Year January 2025 Forecast Report says that worldwide datacenter capex is forecast for a CAGR of 21 percent by 2029. Accelerated servers for AI training and domain-specific workloads could represent nearly half of datacenter infrastructure spending by 2029.
The Dell’Oro Group forecasts that worldwide datacenter capex is projected to surpass $1 trillion by 2029. AI infrastructure spending will maintain its strong growth momentum despite ongoing sustainability efforts. It thinks that: “The proliferation of accelerated computing to support AI and ML workloads has emerged as a major DCPI market driver which is significantly increasing datacenter power and thermal management requirements. For example, the average rack power density today is around 15 kW/rack, but AI workloads will require 60 – 120 kW/rack to support accelerated servers in close proximity. While this jump in rack power density will trigger innovation and product development on the power distribution side, a bigger change is unfolding in thermal management – the transition from air to liquid cooling.
Pure Storage graphic
These new datacenters will require electricity supplies and national grid systems are becoming choke points in delivering that. Datacenters currently use about 3 percent of global electricity, and this could double by 2030, creating serious power generation and supply problems as well as environmental impact issues.
Alex McMullan
In one sense we are not constrained by energy generation, as we have oil, gas and coal-fired power stations, plus nuclear, hydro-electric, wind, and solar generation. However coal, oil and gas generation, the fossil fuel trio, harm the environment, with coal being the worst in that regard. The generation trend is to phase out coal-fired power stations, less so the oil and gas ones, with renewables, wind and solar, coming to the fore. They can both be expanded while hydro-electric generation is limited by restricted site availability. Nuclear power generation has been restricted due to radiation and nuclear fuel contamination and disposal issues but t is showing signs of a come back, with small, modular reactors playing a role. Pure International CTO Alex McMullan says the 3 largest hyperscalers consume >60TWh and all now either own (or are in the process of owning) their own nuclear power stations.
However, even if sufficient electricity can be generated, its delivery brings in fresh problems. A national grid connects power generating sites with power-consuming sites, such as datacenters. Such grids, which supply both businesses and domestic users, large and small consumers, have to maintain a balance between supply and demand. Overall demand rises in the day time and falls at night as millions of consumers follow a day:night activity profile. With renewables there can be shortfalls and over-supply because wind speeds can increase and decrease, and solar power is a day-time generation supply only.
Alex McMullan slide
Against this background grid operators have to balance supply and demand, switching generation on ir off, as well as generators’ connection to the grid on or off. This is not a simple operation as the 2025 Spanish power grid failure demonstrated.
They also have to upgrade the grid wiring and switching/transforming infrastructure to cope with changes in demand over the year, new cabling built, new core and edge (substations) units constructed and deployed. McMullan says that a datacenter’s electricity requirement is growing as more and more computation is carried out by power-hungry GPUs and not relatively frugal x86 CPUs. AI is driving usage upwards.
He reckons that a GPU represents the daily energy consumption of a “standard” 4-person home at ~30kWh. NVIDIA is shipping hundreds of thousands of GPUs every quarter. A GPU represents the daily energy consumption of a “standard” 4-person home at ~30kWh. NVIDIA is shipping hundreds of thousands of GPUs every quarter. One rack of GPUs now requires >100kW which represents the output of ~200 solar panels or ~0.01 percent of the output of a nuclear reactor.
Datacenters have been measured in Power Usage Effectiveness (PUE) terms. The PUE value is calculated by dividing the datacenter’s total energy consumption by the energy used by its IT equipment. A lower PUE value indicates higher energy efficiency. It was introduced by The Green Grid (TGG) in 2007 and is a widely recognized in the industry and by governments. However it does not reflect local climate differences; datacenters in cold climates need less cooling.
Green considerations
The datacenter electricity supply issue is often viewed as part of a wider concern, which is carbon emissions. Datacenter operators, like most of us, want to reduce carbon emissions to mitigate global warming. They may also want to have more generally sustainable operations and that can mean lowering water consumption in equipment cooling.
Switching to renewable energy supply can reduce carbon emissions. Switching to air-cooling and away from water-cooling will lower water consumption and can lower electricity usage, as fans and heat sinks use less power than pumps, radiator fans and water reservoirs. But water-cooling can handler higher heat loads, so it may be needed for GPU servers. Also, datacenters in equatorial regions will find air-cooling less effective than datacenters in temperate and cold regions.
We can’t locate datacenters just for cooling efficiency as they may be thousands of miles away from users with excess data access times due to network transit times. They also need to be not too far from electricity generating sources as a percentage of generated electricity is lost due to grid transit and step-up, step-down transformer operations.
Optimising for datacenter cost, IT equipment performance, user data access time, datacenter electricity supply and demand, and water consumption, is a complicated exercise
Datacenter electricity usage
A datacenter’s power budget is fixed; its grid power supply and edge connectivity devices are hardware and so have impassable upper bounds. If one portion of its internal infrastructure takes up more power, such as a switch from CPUs to GPUs, then there is less power available for other things. Power efficiency is becoming a key consideration
It’s been estimated that 26 percent of datacenter electricity supply is used by servers (20 percent) and storage (6 percent), with the rest being consumed by cooling and UPS’ (50 percent), power conversion (11 percent), network hardware (10 percent) and lighting (3 percent). These are approximate numbers as datacenters obviously vary in size and in cooling needs; datacenters in cold climates need less cooling.
Operators can look at individual equipment classes to reduce their power consumption with cooling and UPS power efficiency a key concern, as it is responsible for half the electricity needed by an average datacenter. Servers, storage and networking devices can also be optimized to use less power. For example, Pure Storage DirectFlash technology lowers NAND storage electricity needs by compared to off-the-shelf SSDs.
It’s not just datacenters that are the issue. To decarbonize economies countries need to move manufacturing, food production and industrial activities away from fossil fuel-powered energy generation. They will need to adopt electric vehicles, and that alone could require an up to 100x increase in power generation.
The whole electricity supply chain, from mining copper for cables, aluminium and steel for power generation and transmission equipment, power generation itself, building the end-to-end grid infrastructure, managing its operation better, developing more resilience and supplying large users more effectively, needs updating. This is going to be multi-billion if not trillion dollar project.
National governments need to become aware of the issue and enable their power generating and supply organizations to respond to it. IT suppliers can do their part by lobbying national and state policymakers but, fundamentally, a country’s entire business sector needs to be involved in this effort.
Beleaguered storage vendor Quantum, which replaced CEO and chairman Jamie Lerner in June and CRO Henk Jan Spanjaard earlier this month, has made “a very large reduction” in staff, according to a person close to the company.
This person, who requested anonymity discussing internal matters, say the headcount changes “went well beyond the CEO and Henk Jan Spanjaard.” We are told it included high-level marketing people. The company’s financial year 2024 annual report says it had “approximately 770 employees globally as of March 31, 2024, including 390 in North America, 200 in APAC, and 180 in EMEA.” New CRO Tony Craythorne told us: “We are in a quiet period so we can’t comment now, but we will share more information on our upcoming earnings call.”
Quantum’s current leadership web page shows no chief operations officer, no chief marketing officer, and no senior hardware or software engineering leadership. Ross Fuji is listed on LinkedIn as Quantum’s chief development officer, having taken the role in January, and he was still in that role in April, according to the WayBack Machine website. Natasha Beckley was noted as the chief marketing officer on the WayBack web archive then too. It appears both have left the company. One source confirms Beckley’s departure.
The WayBack Machine says Brian Cabrera was Quantum’s chief administrative officer back in April and still is, according to LinkedIn. Not so, says Quantum’s current leadership web page, where no such role exists.
Willem Dirven was chief customer officer in January 2025 and still is, according to LinkedIn, but Quantum’s leadership web page says Robert Buergisser is chief customer officer and SVP global services now. His LinkedIn profile says he took on the role this month after 7.5 years in real estate and property management in the Denver area, where Quantum is located. Before that, he was at storage networking supplier Brocade for 11 years as a senior global services director, leaving in 2018. Broadcom bought Brocade in December 2017.
Quantum has delayed reporting its Q4 FY 2025 and full FY 2025 results due to accounting problems. The company has a large debt burden and is in the throes of recapitalizing itself after years of loss-making quarters.
UK startup HoloMem is developing a ribbon-based cartridge and drive that uses multi-layer holographic storage with a 50+ year life span, and can be inserted as a rack shelf in LTO libraries with no change needed to upstream software.
Unlike previous holographic storage startups, the HoloMem technology uses off-the-shelf components, like a $5 laser diode, and mass-produced polymer sheets to make a robust and affordable drive and chassis with no high-cost, extreme-tech elements. And unlike Cerabyte and Microsoft’s Project Silica, it uses a tape ribbon read optically rather than glass slabs or platters.
This will allow HoloMem to enable existing LTO tape library system vendors to upgrade their existing installed systems with higher-capacity, lower-cost drive shelves. They function as LTO-drive shelves while actually and transparently using Holodrive technology to provide more capacity, using LTO-sized cartridges that can be transported by the library’s robot transporters with no change. It would be an in-place and non-disruptive upgrade, allowing the library to function as a hybrid LTO and Holodrive system using the LTO tape protocol.
The technology uses a laser light source to create visible structural changes to a volumetric area in a polymer that are fixed and unchanging and can be described as voxels. These are used to create micro-holograms in the polymer. The ribbon polymer is cut from mass-produced polymer sheets and sandwiched between transparent upper and lower surface layers. It is around 100 meters long, unlike LTO-10’s 1 kilometer ribbon, and can hold up to 200TB in a WORM (write-once, read-many) format.
Charlie Gale.
Company founder Charlie Gale worked at vacuum manufacturer Dyson, initially on robot vacuum cleaners and hair dryers, and helped devise multi-hologram security sticker labels, by writing multiple holograms in the same space so that the image changed with the angle of view. This was patented and licensed, and whisky bottles are available with personalized hologram labels.
This idea led to a multi-layer, machine-readable, smartphone-authenticated, hologram, which resulted in a technology called H010, a multiplex QR code. It uses holographic technologies to have two QR codes in one image. Gale said: “You hold it up to your (smartphone) camera. It’ll say this is a HO1O label … and it will scan the multiple QR codes in it and verify them.” Three patents were granted for this while he was at Dyson.
Interestingly, the patented device could have covert layers, using invisible wavelengths of light, such as infrared, which would reveal different holograms. There is a multi-channel idea here, with one multi-plexed data source being readable via multiple channels at the same time. Hold this thought.
Gale says the thinking moved on during the COVID lockdown period to “making layers of hologram images in some substrate.” He explains, “What we originally did at HO1O for prototypes was to use a light-sensitive polymer material that you just exposed to laser light and, a bit like old-school camera film, whatever you expose it to, it locks polymer change and retains that image. This is an internal polymer change. It’s in the emulsion.”
The laser was shone on the polymer as a flood through a stencil; a very slow procedure in data storage terms.
Gale said: “How many layers do we think we could add to them? Because surely, at some stage, we’ll get to an incredibly high-fidelity, data storage system rather than a smartphone scannable security label. … So the concept of HoloMem was formed in that moment and our question was, how small and how fast do we think we can start writing holograms?”
He didn’t need a high-energy laser to ablate (erode) a resistant ceramic surface like Cerabyte or Micosoft’s Project Silica, although Gale observed, “Silica is cool. I guess they are went to very, very high-power lasers. I think it’s actually three orders of magnitude difference on the pulse energy that we’re talking about.”
Instead, he said, “We have this light-sensitive polymer material that is essentially thirsty for light, and as soon as it sees it, it uses that as the catalyst to state-change internally. And we bought $5 pulse laser diodes and we blitzed it at the polymer, making very small voxels. It recorded a string of holographic microdots that we etched originally micro QR codes into.
“We kind of viewed it as a bit like a microfiche kind of World War II microdots stuff. … we wrote that string and then we used a small camera sensor to photograph those QR codes, scan them and give back the file.”
That was the birth moment of HoloMem. Gale and his team thought they could become experts in making multi-layer machine-readable data sets without crosstalk.
HoloMem tape.
The polymer was relatively cheap: “This light-sensitive poly is developed for the automotive industry to go into windscreen to the head-up displays. You can buy it by the tub and it costs buttons.” He said “Polymer itself is like a sticky jammy material. It needs to be laminated in a sandwich.” There is a16 micron thick polymer layer between two PET laminations, giving a 120 micron thick ribbon of polymer+PET tape.
The team thought they could get to a higher volumetric density than incumbent tape.
So, we asked, how many layers are possible?
Gale answered: “The question is theoretically how many layers and practically how many layers. We’ve done both. If you ask the academics we’ve got here, what is the fundamental resolution of what can be achieved in polymer? The numbers are absolutely bonkers. We’re not going to hit a glass ceiling. The challenge for us is what’s practical and buildable in a simple device?”
So, how many layers are practical?
Gale said, “Actually it doesn’t quite work like that. Have you heard of a Fourier transform?” [See bootnote.]
In effect, the holograms overlap. “It’s actually really good for us because what you don’t want to do with any optical technology is have black and white on the surface, because high contrast is hard. You want to achieve high contrast at depth. … [If you] actually focus through the film you get a sharp image at a focal point.”
So how do you get to a precise depth to read or to write data? Gale answered, “You control the focal point” and, for that: “We actually have a 3D-printed polymer lens now.”
We asked: “You didn’t have to manipulate a physical mirror?”
Gale replied: “No, were using a DMD (Digital Mirror Device). They’re in projectors and, for want of a better definition, laser light is a tube of light. We bounce it off the DMD, where it uses the mirror to decide ‘is that pixel on or off?’”
“You get a super high contrast binary outcome. We then send that now-pregnant beam with ons and offs through our optical system to demagnify it and focus it through the film to a focal point that we want to expose that image. And the polymer just sips that up and goes, fantastic. I will lock that into my polymer change. And then that voxel or micro hologram is recorded.”
It’s a instant writing process, so fast that the moving ribbon’s motion is irrelevant, Gale explained. “We are writing data pages of thousands of bits and we’re writing them at a 1,000+ Hertz now.”
“And for us the game only gets better and better. The smaller we manage to make the hologram,” the less energy is needed to expose it. … “[With] lower energy, higher data density in the lab, we have beaten tape as a proof to ourselves. We can beat the volumetric data density of LTO-10. It’s done. What I want to do is execute a low-cost device that automates that process.”
Holodrive with yellow LTO tape cartridge and black HoloMem cartridge
The HoloDrive is a step on that road, with Gale calling it a HO1O drive beta. “This is a very Dyson-style, get-it-done prototype. This writes and reads holographic data from our cartridge, which is … an LTO cartridge that we have put our film into.”
Holodrive internals
It has a combined read and write station (inside the dark grey 3D-printed structure in the image above). There are £30 prototype circuit boards and a “a cut and shut LTO loading mechanism.”
Gale says, “What this device isn’t is a world-achieving data density. We have intentionally de-tuned this system because we want it to be robust and reliable.” It generally operates at LTO-9 speed. There is no damage to the tape with repeated read: “It does not degrade the data set. There’s no such thing as data rot with this.”
The ribbon is robust, he says. “It’s spec’d for minus 40 to plus 160 degrees.” And it’s immune to electro-magnetic pulses, which could be interesting for defence-related archival storage.
He thinks tape is facing a somewhat dead end; it’s moribund so to speak. “What I think we’re trying to do here is demonstrate that there’s another angle of attack. We believe in photonic data storage. I think lots of people agree that’s kind of where things are going to go. But we’re coming at it from a another angle.” And: “The royal flush is CAPEX. This is a cheaper solution.”
He wants “to help people change their of holographic data storage,” because there is a perception of it being a failed archival storage technology.
So why put their recording medium in a tape format? Why not on a disk? “I’m not sure we can get to the volumetric data density of the hard disc drive. The aerial density of hard drives is actually really high,” Gale explained. “They’re like 500 gigabits per square inch on a half disc drive platter. Whereas LTO-10 is like 12 to 14.”
He said, “The feeling for us was the low hanging fruit is to disrupt LTO. And I think we can present a compelling comparison. We started when it was LTO-9. The fact that LTO-10 is out now doesn’t scare us a bit really.” It’s just twice the density of LTO-9 and the read speed hasn’t changed. Also the tape is fragile at 5.4 microns thick: ”The material’s so thin and so delicate now … so fragile, and over life it will stretch.”
HoloMem’s thinking is different. “It would be better to have a thicker photo polymer that you can put a lot more aerial density into, because then the mechanical challenge and the time to first byte is so much better. We probably only want to put a hundred meters of tape in our reels because then we say, we’ve got a 10th of the time to your first byte. But we can still put more data per cartridge in than they can with tape.”
Gale said, “ I think we can make a better drive. Call us LTO- 15, whatever. We make a better, higher density, longer life, more robust version of an LTO drive and cassette.”
IP protection
Gale: “We’re protected with four patents to date, primarily optical engine. How you make a high-fidelity storage and read system, holographic media handling, the cartridge of light-sensitive polymer, just the physical formatting of that.”
“We have also protected the storage of holographic data sets in a light sensing polymer that is thinner than at one millimetre.”
Funding
HoloMem has no VC funding and operates on a comparative shoestring compared with VC-backed startup standards. It received a £350,000 ($472,000) grant from the UK REsearch and Innovation fund in March 2023 to help it “optimise data storage densities, reduce noise/interference and identify the most efficient combination of laser intensity and exposure length to optimise for low-energy data recording and image clarity.”
It was awarded a £550,000 ($742,000) Smart Grant by Innovate UK for its HoloDrive project, in partnership with TechRe, the data centre consultants, in June. That’s £900,000 ($ 1.2 million) in grants and there are angel investors as well. We could view this as seed-type funding.
We understand TechRe will deploy prototype Holodrives inside LTO libraries in its UK data centers to test out the product’s performance, reliability and robustness. HoloMem has written device firmware so that, we understand, it presents itself as a kind of LTO drive.
It is partnering with Qstar, which will involve QStar integrating its Archive Manager (single server) and Global ArchiveSpace (multi-server) products with HoloMem drives and media to allow prospective customers to test early release product in their own environments. HoloMem’s plug-and-play system has been designed to integrate with legacy systems with minimal hardware or software disruption.
In our view, it would be a decent idea for HoloMem to consider building a relationship with BDT, the Germany-based manufacturer of tape automation products for customers such as IBM and Spectra Logic. A library rack shelf-level item, slotted in alongside LTO drives with no upstream SW changes, would be a great way to introduce Holodrive technology in a low-friction way.
Multi-channel
A development prospect is the concept of multi-channel recording. Voxels are created at specific spectral or wavelength values. Thus, voxels created by blue light, with wavelengths between 400 and 500 nanometers, are not visible at other spectral values. Voxels created by different light spectral values, or “channels” can co-exist in the same volumetric space, and can be read at the same time and written at the same time time. Each additional channel adds to the tape’s capacity, wth two channels doubling capacity, three tripling it, and so on. This multi-channel technique could be applied to existing HoloMem ribbon media with no change; backwards-compatibility with a vengeance.
It’s somewhat similar to light wavelength division multiplexing (WDM) in optical fibers.
Thank about having a software-defined capacity function whereby you start with a single channel, and then buy a license upgrade to get multiple channels with an Nx increase in cartridge capacity where N is the number of channels. How many channels? Double-digits would seem possible, although the amount of crosstalk increases as the channel number increases.
There would be no two-year wait between cartridge capacity increases as there is with LTO generations. You would buy a drive with, say, a hypothetical 20-channel capability, license one channel and then license more as needed up to 20x. If we, again hypothetically, imagine a 200TB HoloMem cartridge , that could become a 4,000 TB raw cartridge. We understand basic patents protecting this scheme have been filed.
Bootnote
Holographic storage records data as interference patterns between a signal beam (carrying data) and a reference beam in a photosensitive medium (e.g., photopolymer or photo-refractive crystal). Data is stored as holograms, which are diffraction patterns that can reconstruct the original signal when illuminated by the reference beam. Fourier transforms are used to encode data in the spatial frequency domain, enabling compact storage and efficient retrieval.
A Fourier transform converts a spatial pattern (e.g., an image of a data page) into its frequency components, which are recorded in the hologram. To do this, a lens performs an optical Fourier transform, focusing the signal beam’s light into a spatial frequency distribution at the focal plane, where the hologram is recorded. This allows data to be stored as a compact interference pattern in the frequency domain, which can be reconstructed by applying the inverse Fourier transform (optically, via a lens, or computationally).
Multilayer storage increases capacity by recording multiple holograms at different depths or spatial locations within the medium. Fourier transforms enable multiplexing techniques (e.g., angular, wavelength, or phase-code multiplexing) to selectively record and retrieve holograms without crosstalk between layers.
The Fourier plane is compact and depth-invariant, meaning the hologram’s interference pattern is relatively insensitive to small changes in depth. This allows multiple holograms to be recorded at different depths (layers) within the medium by focusing the beams at different planes.
By adjusting the focal plane of the lens, distinct layers can be created, each storing a unique hologram. The Fourier transform ensures that data is encoded efficiently in each layer.
A private Cohesity survey found that office workers in the UK would keep quiet about being targeted in a cyber-attack.
The results came from a survey of 4,500 workers across France, Germany and the UAE that was run to inform marketing strategy. The reasons given by respondents for not revealing a personally directed cyber-attack were that they wouldn’t want people to think it was their fault (17 percent), they don’t want to get into trouble (17 percent) and they are afraid of causing an unnecessary fuss (15 percent). One in ten (11 percent) would even try to fix it themselves rather than seek official help from their employer’s security experts.
According to Olivier Savornin, GVP Europe at Cohesity, “Staying silent if they suspect a malicious cyberattack is quite possibly the worst thing an employee could do, particularly when they claim to know the dangers. This reluctance to speak up leaves organizations in the dark and vulnerable to serious damage to the business.”
Cohesity believes that time is of the essence when dealing with a cyberattack to get back up and running quickly, in a secure state, and with limited impact on business operations and revenues. Savornin said: “We need to create a workplace culture where people feel comfortable raising the alarm and are properly trained on how to recognise a cyber threat and the correct action to take – no matter how small the issue might seem.”
As an example of why this is necessary, the damaging cyber-attack on retailer Marks and Spencer in the UK in April last year has caused a great loss in revenues, with a £300 million ($403 million) operating profit loss, as its online business was taken offline for seven weeks, and is being rebuilt in stages with the process not yet complete 14 months later.
The attack was enabled by a DragonForce ransomware group hacker impersonating an employee, reportedly at M&S contractor Tata Consultancy Services, and gaining unauthorized system access via the M&S help desk. Reports indicate the breach began as early as February 2024, when hackers stole the Windows domain’s NTDS.dit file, containing password hashes for domain users. By cracking these hashes, they accessed the network and deployed ransomware to encrypt virtual machines, disrupting services like contactless payments, click-and-collect, and online ordering.
M&S chairman Archie Norman believes that British businesses should be legally required to report material cyberattacks to the authorities. This should surely apply to all organizations in every country. And that means that staff in these organizations should be encouraged to report cyber-attacks to their security function. That means training, attack simulation training for example, so they can learn how to recognize an attack and reject flaky telephone calls, emails, text and Whats App messages, no matter whom they appear to be from.
Cohesity’s James Blake, Global Head of Cyber Resiliency Strategy, stated: “Our research, conducted by OnePoll across France, Germany, the UAE, and the UK, reveals a worrying gap in cyber resilience. While 68 percent of employees across Europe have received some form of cybersecurity training in the past year, nearly one in three (32 percent) said they have had no exposure to any training or resources whatsoever. That’s a significant blind spot.”
Such employees are “ill-equipped to recognize ransomware phishing emails — let alone understand how to respond appropriately.”
Blake concludes “When it comes to ransomware, people are the weakest link.” An organizational culture of encouraging transparent and timely communication of these threats needs to be established.
Bootnote
Cohesity conducted research amongst full-time office workers to understand their beliefs, knowledge, and behaviour when it comes to malicious cyberattacks including ransomware. It worked with OnePoll to question 4,500 respondents across EMEA (France – 1,000, Germany – 1,000, UAE – 500, UK – 2,000) in May/June 2025. We understand this research is not going to be published externally.
An IDC paper discussing AI-Ready Data Storage Infrastructure (AI-RDSI) has landed and is being distributed by Hammerspace.
The paper is the first in a 4-part series, with the other parts covering the Voice of the Customer, Competitive Landscape, and Market Size and Forecast.
The AI-RDSI document’s introductory IDC Opinion section says that “less than half of AI pilot projects advance into production.” It declares that “organizations must must approach AI projects from a data-centric perspective.” The authors also say “vendors must be prepared to operate within an ecosystem of partners and competitors to provide a full-stack AI infrastructure offering.”
An AI-RDSI is defined as:
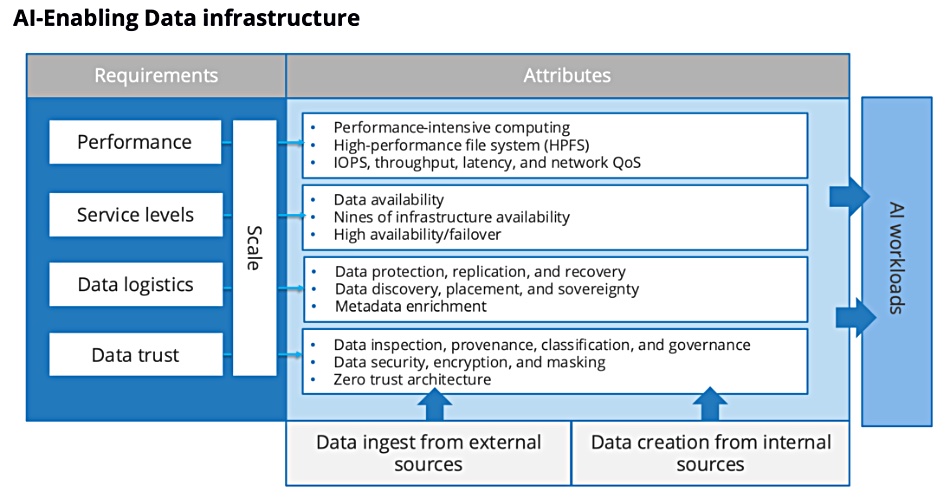
The IDC authors talk about data logistics, the journey of data from creation or ingest throughout an organization’s data processing environment, with a diagram illustrating the concept:
The AI system requires a single source of data truth, by either “having a Copy Data Management capability, or single unified metadata environment across all storage.”
There are five primary attributes of such a data infrastructure:
Performance – data throughput, IOPS, latency, network bandwidth and performance-intensive computing demands, noting “Achieving high throughput may require the use of technologies such as parallel file systems or parallel NFS (pNFS).”
Scale
Service levels – with 99.999 percent cited as a common requirement.
Data logistics
Data trust
There is much more detail as the analysts dive into each of these sections, and talk about an AI-RDSI ontology and software taxonomy. They wrap things up by providing advice to IT suppliers and IT buyers. A final synopsis declares that “Far too many AI projects fail. …we believe insufficient attention to the storage infrastructure, resulting in projects stymied by data silos, poor data quality, and insufficient storage performance.”
IDC Research VP, Infrastructure Software Platforms, Worldwide Infrastructure Research, Phil Goodwin, states at the end: “This study helps IT suppliers to define AI-ready data storage product requirements and IT buyers to identify the appropriate solutions for their needs.”
Hammerspace liked the content of this IDC primary research paper so much they obtained a reprint license.
Comment
We note the IDC paper ignores fast access object storage using flash hardware and GPU Direct for Objects – see Cloudian, Scality and MinIO – positioning object stores as suitable for moderate or lower-performance needs:
It declares that data availability is important:
With 1 PB of data and 99.999 percent availability we calculate that 0.001 percent of the data is at risk of being unavailable; 0.001 percent of 1 PB = 0.00001 x 1 x 1015 = 1 x 1010 bytes or 10GB.
In the object storage world Scality’s RING and Cloudian’s Hyperstore offer 14 nines (99.999999999999 percent) data durability and availability, meaning 1KB will be unavailable, just 0.00001 percent of 10 GB, which is better.