Israeli startup Illumex is focused on getting an organization’s structured data involved in stopping GenAI chatbot hallucinations and has just received $13 million in a seed funding round to develop its software.
GenAI chatbots are large language models (LLMs) trained on general and unstructured information sources such as files, objects, images, audio, and so forth. They can produce incorrect responses when asked about topics on which they have not been specifically trained. RAG (retrieval-augmented generation) technology adds in an organization’s proprietary data into the mix so that the LLM can more correctly source and generate request responses. Until now, that has meant using unstructured data as the RAG source. Illumex wants to change that and bring structured (database) data into play as well, which is a logical step.
Inna Tokarov Sela
Founder and CEO Inna Tokarev Sela says her startup has developed a Generative Semantic Fabric (GSF): “Our Generative Semantic Fabric aligns organizational data with business meaning and domain-specific context, allowing organizations to finally trust the results of their AI initiatives.”
Unstructured data has a lot of metadata associated with it – think file owner, type, creation date, length, etc. Structured data, such as a database record, has sparse metadata and no inherent context from which an LLM can deduce meaning, yet there is implied metadata, for example, in the record’s row and column address and its relationship with other row and column items.
The turnkey GSF software analyzes such metadata, without accessing the underlying sensitive information, to create a unified semantic knowledge graph. It works, Illumex says, “by automatically constructing a domain-specific ontology, which formally defines the entities, properties, and relationships that represent an organization’s knowledge structure.” GSF “automates the complex process of mapping data semantics and resolving terminological inconsistencies across business silos,” helping with information governance.
This graph aligns all data with consistent business terminology and context, and “serves as a foundation that enables LLMs to reliably map user questions to the relevant data points that should be retrieved in order to deliver accurate results while ensuring proper governance.” GSF is used to create, Illumex says, domain-specific Semantic AI engines that bring users a hallucination-free ChatGPT-like experience they can fully trust.
Illumex semantic graph
According to Sela: “By enabling business users to interact reliably with data using natural language, without teaching them the precise technical definitions, we’re democratizing AI and empowering enterprises to make better decisions.”
Before founding Illumex, Sela was VP of AI at Sisense, spending just over two years there, and Senior Director of Machine Learning at SAP, where she worked for more than 11 years. She led the product and GTM for cloud and machine learning, built AI-driven platforms within the organizations, and established data science departments. Sela has authored several patents on knowledge graphs, natural language, and deep learning.
Illumex was founded in 2021, taking in $4.3 million in initial seed funding that year. Its second and latest seed round brings total funding to $17.3 million. The round was led by Cardumen Capital, Amdocs Ventures, and Samsung Ventures, with participation from ICI Fund, Jibe Ventures, Iron Nation Fund, Ginnosar Ventures, ICON Fund, Today Ventures, and various angel investors.
The company says it has large enterprises like Teva and Carson using it for their data AI readiness, and has built agreements with Microsoft, Google Cloud, and AWS.
Cloud monitoring firm Datadog has unveiled its Kubernetes Autoscaling service, a set of capabilities that intelligently automate resource optimization. The technology automatically scales customers’ Kubernetes environments based on real-time and historical utilization metrics.
Datadog claims it is the first observability platform vendor to enable customers to make changes to their Kubernetes environments directly from the platform. When deploying applications on Kubernetes, teams often choose to over-provision resources as a way to avoid infrastructure capacity issues affecting end users. This can lead to a large amount of wasted compute and increased cloud costs.
Yrieix Garnier
“Containers are a leading area of wasted spend because so many costs are associated with idle resources, but organizations also can’t risk degrading performance or not having enough resources to scale,” said Yrieix Garnier, VP of product at Datadog. “The key for businesses is to find a balance between control and automation. Datadog is the only enterprise-grade, unified platform that provides end-to-end observability, security and resource management at scale for any Kubernetes-driven organization.”
According to Datadog research, 83 percent of container costs are associated with idle resources. “For this reason, it’s critical organizations have a solution in place which can monitor resource usage and optimize infrastructure performance and computing costs, while ensuring applications remain performant with enough resources to scale,” it said.
Datadog Kubernetes Autoscaling continuously monitors and automatically “rightsizes” Kubernetes resources. “This leads to significant cost savings for an organization’s cloud infrastructure, and helps to ensure optimal application performance for workloads, improved user experiences and better ROI on container assets,” said Datadog.
Customers are able to identify workloads and clusters with a high number of idle resources, implement a one-time fix through intelligent automation or enable Datadog to automatically scale the workload on an ongoing basis. These capabilities, we’re told, empower operators and their customers to decide the right balance on cost and user experience based on their risk profiles.
Teams can use a unified view and an “intuitive” UI that displays Kubernetes resource utilization and cost metrics, making it “simple” for any team member to understand and scale resources. Organizations gain full visibility into how rightsizing impacts their workload and cluster performance, backed by high-resolution trailing container metrics, so teams can take action based on this rich context, says the firm.
Earlier this month, Datadog introduced Data Jobs Monitoring, which allows teams to detect “problematic” Spark and Databricks jobs anywhere in their data pipelines, allowing them to remediate failed and long-running-jobs faster, and optimize over-provisioned compute resources.
Enterprise storage biz Infinidat has officially launched an automated cyber resiliency and recovery system that it claims will “revolutionize” how firms can minimize the impact of ransomware and malware attacks.
InfiniSafe Automated Cyber Protection (ACP) was first mooted earlier this year, and is designed to reduce the threat window of cyberattacks. The company says sophisticated cyberattacks, including new “sinister forms” of AI-driven attacks, target data storage infrastructure.
InfiniSafe ACP enables enterprises to “easily integrate” with their security operations centers (SOCs), Security Information and Event Management (SIEM), Security Orchestration, Automation, and Response (SOAR) software applications, and simple syslog functions for less complex environments.
A security-related incident or event, picked up by these systems, triggers “immediate” automated immutable snapshots of data, providing the ability to protect InfiniBox and InfiniBox SSA block-based volumes and/or file systems, and “ensure near instantaneous cyber recovery,” the company says.
“The merging of cybersecurity and data infrastructure has been compelling CIOs, CISOs and IT team leaders to rethink how to secure enterprise storage across hybrid multicloud deployments in light of increasing cyberattacks,” said Eric Herzog, CMO at Infinidat. “Enterprises need proactive strategies, seamless integration across IT domains, and the most advanced, automated technologies to stay ahead of cyber threats.”
Eric Herzog
“Infinidat’s newly launched InfiniSafe Automated Cyber Protection, that easily meshes with SIEM, SOAR or security operations centers, is exactly what enterprises need to include enterprise storage as a comprehensive approach to combat cyber threats,” said Chris Evans, principal analyst at Architecting IT.
InfiniSafe ACP orchestrates the automatic taking of immutable snapshots of data, at the speed of compute, to stay ahead of cyberattacks by decisively cutting off the proliferation of data corruption.
Evans said: “This proactive cyber protection technique is extremely valuable, as it enables taking immediate immutable snapshots of data at the first sign of a potential cyberattack. This provides a significant advancement to ensure enterprise cyber storage resilience and recovery are integral to an enterprise’s cybersecurity strategy, and enhances an enterprise’s overall cyber resilience by reducing the threat window.”
Last month, Infinidat upgraded its InfiniBox arrays to fourth-generation hardware, with a higher level of performance and added cyber protection, Azure support, and a controller upgrade program.
Korean memory manufacturer SK hynix is rolling out a sprint-speed SSD for AI PCs.
An AI PC is designed to run small-scale generative AI large language models (LLMs) locally, without relying on larger LLMs in a public cloud. Such PCs are described by Intel as having a Core Ultra processor with an integrated neural processing unit (NPU), and by Microsoft as a Copilot+ PC with an NPU capable of 40 TOPS (trillions or tera operations per second) or more. Dell, Lenovo, and other PC manufacturers are hoping that users and businesses will upgrade their workstations and PC fleets to these higher margin AI PCs.
SK hynix first publicly revealed its AI PC SSD ambitions at the 2024 Nvidia GTC event in March, showing its PCB01 PCIe gen 5 gumstick (M.2 2280) drive, also calling it a Platinum P51 drive. At the time, Jae-yeun Yun, head of NAND Product Planning and Enablement at SK hynix, said: “PCB01 will not only be highlighted for its use in AI PCs, but this high-performing product will also receive significant attention in the gaming and high-end PC markets.”
SK hynix PCB01 PCIe gen 5 flash drive
The drive uses 238-layer TLC (3bits/cell) 3D NAND with a fast SLC cache area and supports a gen 5 PCIe bus with 8 lanes. It will come in 512 GB, 1 TB, and 2 TB capacities, and have up to 14 GBps sequential read bandwidth and 12 GBps write bandwidth. The company has yet to disclose any IOPS numbers.
The sequential bandwidth numbers are good for the large mainstream PCIe gen 5 SSD suppliers but not record-breaking. ADATA’s Nighthawk matches them and FADU’s Echo does 14.6 GBps when reading, but a slower 10.4 GBps when writing.
Mainstream supplier Kioxia’s read-intensive and mixed-use CM7 reaches 14 GBps reads but is relatively poor at writes, notching up 6.75 GBps. Samsung’s PM1743 does 13 GBps reads and 6.6 GBps writes – a similar asymmetric pattern. The SK hynix drive certainly has a high write speed compared to its competitors, and the SLC cache will be helping there.
SK hynix says the PCB01 has onboard Root of Trust technology to prevent invalid accesses and preserve data integrity. We’re told it has 30 percent better power efficiency than the previous generation. The company introduced its earlier PS1010 PCIe gen 5 drive at CES in January 2023. This used 176-layer TLC NAND in an E3.S format.
The PCB01 will be available as an OEM product and also in a consumer version, which might drop the PCIe lane count from 8 to 4.
Ahn Hyun, head of the N-S Committee at SK hynix, said that numerous global providers of CPUs for on-device AI PCs want to have the PCB01 drive validated with their CPUs. The N-S Committee was created by SK hynix in January to strengthen its flash and NAND solutions (N-S) businesses.
Competing gumstick SSD suppliers will also be aware that sticking an “AI PC” marketing tag on their PCIe gen 5 drives may help raise their appeal in a market hyped up by AI. Expect more such drives to appear.
SingleStore has added bi-directional integration with data lake Apache Iceberg, to help users get to the data easier, and enable them to build intelligent applications.
SingleStore’s database combines real-time transactional and analytics features and has hundreds of customers, including Siemens, Uber, Palo Alto Networks and SiriusXM.
While Apache Iceberg is used to store massive datasets, enterprises can struggle to use the data, due to complex, and sometimes costly processes required to “thaw” it, including extensive ETL workflows and compute-intensive Spark jobs.
The SingleStore integration is said to address the “critical challenge” faced by enterprises, where an estimated 90 percent of data remains “frozen” in lakehouses, and is unusable for powering interactive applications, analytics or AI, maintains the provider.
SingleStore is promising low-latency ingestion, bi-directional data flow and real-time application performance at “lower cost” for intelligent applications and analytics. Its product is currently available in public preview, and customers will “soon” be able to create external tables in SingleStore based on Iceberg data, build projections on these tables, and go to work on frozen data.
“Our vision has always been to provide one single data store for all companies to be able to take advantage of speed, scale and simplicity,” said Raj Verma, CEO of SingleStore. “With this release we believe we are enabling a significant portion of the market that today cannot build real-time modern applications on data stored in data lakes.”
Raj Verma.
In addition to the Iceberg integration, SingleStore has added vector search features that include range searches and filters (in public preview), to help enterprises “easily build” and scale generative AI applications.
The company is also announcing the general availability of new capabilities in full-text search, including improved relevance scoring, phonetic similarity, fuzzy matching and keyword-proximity-based ranking. SingleStore says this means organizations can now simplify their data architectures by eliminating the need for additional specialty databases to build generative AI and real-time applications.
In addition, with the Autoscaling feature in the latest release (in public preview), customers can ensure application performance by scaling compute resources up or down “automatically in seconds” to adjust to unpredictable workloads, while “avoiding billing surprises”.
“The integration with Iceberg, plus enhancing our platform’s scaling and processing capabilities, will allow users to better access and harness their data in real time, for the next wave of generative AI and data applications,” said Nadeem Asghar, head of engineering at SingleStore.
SingleStore added features to its Pro Max database to make AI app development faster earlier this year.
Data management platform Denodo is the latest provider to update its technology to address ever more AI workloads.
Denodo Platform 9.0, we’re told, enables intelligent data delivery through AI-driven support for queries delivered in natural language, eliminating the need to know SQL.
It also has the ability to provide large language models (LLMs) with real-time, governed data from across the enterprise, powering retrieval-augmented generation (RAG) for “trusted, insightful results” from generative AI applications, among other features, the company reckons.
“Denodo Platform 9.0 advances logical data management into the next phase of AI and advanced analytics, one in which expectations are now being realised,” Denodo said.
The system “learns” as users interact with the data, and it provides automated recommendations of the best data to use, based on each user’s “need-of-the-moment”. This “greatly increases productivity” for a wide range of users, said Denodo, as they don’t have to stop and try to figure out which data to use, or where to find it.
Users can type their queries using natural language, and receive not only “instant results”, but also a detailed breakdown of how the query was constructed. Under the hood, the platform can optimise data delivery across multiple channels, as the system learns the fastest methods and automatically deploys them, “lowering costs by saving time”, Denodo adds.
The technology can be deployed to further strengthen data compliance too, using “more sophisticated” security measures that are built into the platform by design.
“We see Denodo 9.0 as a game-changer. The self-service data preparation and generative AI integration will now empower users of all backgrounds to customise and use datasets effortlessly,” said Ryan Fattini, VP of data and analytics at City Furniture, a Denodo customer. “The Iceberg and Delta integration enhances analytics, and the advanced security governance and inspection tools improve oversight and compliance.”
“In the ongoing effort to unify their diverse data, companies will leverage both physical and logical data architectures,” said Fern Halper, vice president and senior research director for advanced analytics at data training and research organization TDWI. “Denodo Platform 9.0 promises strong support for a data fabric that can accommodate both approaches, with enhanced AI capabilities to improve the data fabric’s flexibility in supporting a wider variety of different user personas.”
This April, Denodo announced a agreement with Google, integrating the Denodo Platform with Google Cloud’s Vertex AI, and combining logical data management capabilities with GenAI services with access to LLMs.
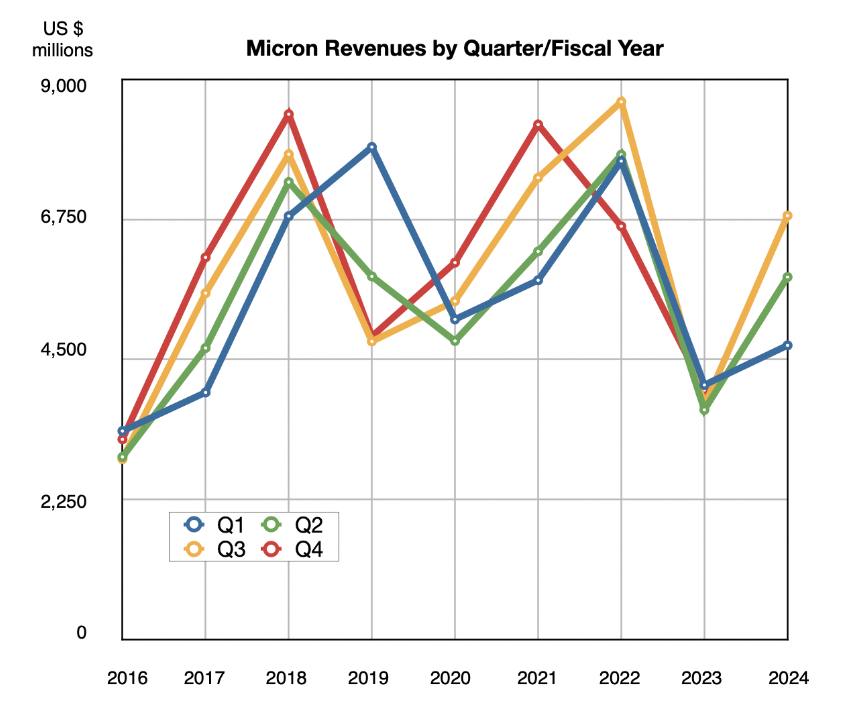
Micron revenues rose 81.5 percent year-on-year in its latest quarter as demand for AI server memory rocketed skywards.
Revenue for Q3 of Micron’s fiscal 2024 ended May 30 was $6.8 billion, beating its guidance and contrasting with the year-ago $3.8 billion when the memory market was bottoming out. It made a net profit of $332 million, much better than the $1.9 billion net loss last year.
President and CEO Sanjay Mehrotra said: “Robust AI demand and strong execution enabled Micron to drive 17 percent sequential revenue growth, exceeding our guidance range in fiscal Q3. We are gaining share in high-margin products like High Bandwidth Memory (HBM), and our datacenter SSD revenue hit a record high.”
Note the steep growth curves in FY 2024’s Q1, Q2, and Q3
Micron said it made robust price increases as industry supply-demand conditions continued to improve. This pricing, combined with a strengthened product mix, resulted in increased profitability across all its end markets.
Financial summary
Gross margin: 26.9 percent vs -17.8 percent a year ago
Operating cash flow: $2.48 billion vs $1.22 billion for the prior quarter and $24 million for the same period last year
Free cash flow: $425 million vs -$1.355 billion last year
Cash, marketable investments, and restricted cash: $9.22 billion
Diluted EPS: $0.30 vs -$1.73 a year ago.
DRAM revenue for the quarter was $4.7 billion, up 76 percent year-on-year. NAND revenues grew 107 percent year-on-year to $2.1 billion. NOR and other revenue of $54 million was down 19.4 percent.
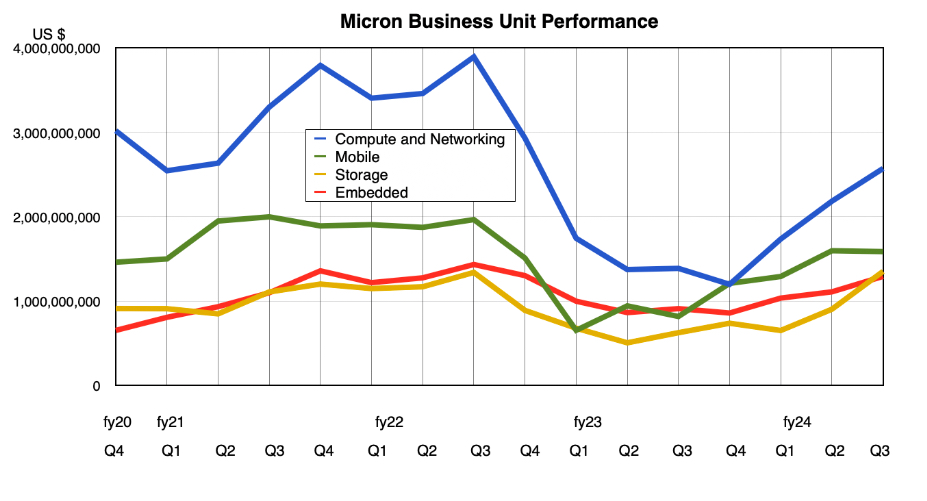
Business unit revenue performance:
Compute & Networking: $2.57 billion, up 85 percent year-over-year
Mobile: $1.59 billion, up 94 percent
Storage: $1.35 billion, up 116 percent
Embedded: $1.29 billion, up 42 percent, with record demand in the automotive sector
Storage revenues have edged past embedded for the first time in 12 quarters as AI demand exceeds automotive demand
Outlook
Next quarter’s $7.6 billion midpoint outlook would signify revenue growth of 89.5 percent year-on-year. That’s a big ask but then revenues grew 82 percent annually in Q3 and demand is accelerating as GPU server growth continues at its high rate.
Micron said it expects continued price increases throughout calendar 2024 as AI-driven demand for datacenter products may lead to shortages.
The company said its next generation, 300-plus-layer NAND technology is “on track, with high volume production planned for calendar 2025.” Mehrotra echoed views previously expressed by Western Digital EVP Rob Soderbery about slowing NAND node (layer count) transitions, saying: “I think it is certainly helpful given the bit growth that you get from those transitions to slow down the timing of the cadence of those node transitions so that your bit growth CAGR versus the gain of bits that you get from the wafers can be managed well.”
Turning back to AI, Mehrotra said: “We are excited about the expanding AI-driven opportunities ahead, and are well positioned to deliver a substantial revenue record in fiscal 2025.”
“We are in the early innings of a multi-year race to enable artificial general intelligence, or AGI, which will revolutionize all aspects of life,” he said in prepared remarks. “Enabling AGI will require training ever-increasing model sizes with trillions of parameters and sophisticated servers for inferencing. AI will also permeate to the edge via AI PCs and AI smartphones, as well as smart automobiles and intelligent industrial systems. These trends will drive significant growth in the demand for DRAM and NAND, and we believe that Micron will be one of the biggest beneficiaries in the semiconductor industry of the multi-year growth opportunity driven by AI.”
Let us hope that this multi-year AI race isn’t just a dot-com bubble with disastrous results for businesses going all in on the tech.
A Micron presentation slide said: “As we look ahead to 2025, demand for AI PCs and AI smartphones, and continued growth of AI in the datacenter, create a favorable setup that gives us confidence that we can deliver a substantial revenue record in FY 25.
“Due to expectations for continued leading-edge node tightness, we are seeing increased interest from many customers across market segments to secure 2025 long-term agreements ahead of their typical schedule.” That will increase Micron’s confidence in its FY 2025 revenue expectations.
High Bandwidth Memory (HBM) demand is a vital part of this, and Micron expects “to generate several hundred million dollars of revenue from HBM in FY 24, and multiple billions in revenue from HBM in FY 25 … Our HBM is sold out for 2024 and 2025, with pricing already contracted for the overwhelming majority of our 2025 supply.”
Another benefit to Micron of strong HBM demand is likely to be general DRAM price rises. “Industry wide, HBM3E consumes approximately three times the wafer supply as DDR5 to produce a given number of bits in the same technology node. We anticipate strong HBM demand due to AI, combined with increasing silicon intensity of the HBM roadmap, to contribute to tight supply conditions for DRAM across all end markets.”
A “substantial revenue record” suggests Micron is hoping to sail past its FY 2022 $30.8 billion number. Its nine-month total for the current FY 2024 year is $17.36 billion, which will provide a $25 billion full year if its outlook of $7.6 billion for the next quarter (+/-$200 million) is met. Beating $30.8 billion in revenues would require a minimum 19 percent revenue growth rate from FY 2024 to 2025. Mehrotra must be feeling confident to make such a suggestion.
However, all this good news failed to please the stock market, which saw Micron’s share price decrease 7 percent in trading after the results were published from $142.50 to $131.66 – due to some analysts’ disappointment with the outlook for the final quarter of fiscal 2024.
SPONSORED FEATURE: Pure Storage’s Evergreen subscription services, aimed at making on-premises storage service consumption as much like the public cloud as feasible has been proven across eight hardware generations and over 30,000 controller upgrades for customers.
There is a fair amount of flattering me-too imitation occurring in the storage industry but the Evergreen services portfolio retain their superiority with the latest advances concerning power and rack space customer cost payments.
We can better understand how Pure has led the industry in Storage-as-a-Service (STaaS) terms by taking a look at the origins of the program, rooted in array architectural choices, and then seeing how it has developed.
Image source: Pure Storage
Pure Storage first introduced its Forever Flash architecture and services in 2014 as a response to problems afflicting storage arrays at the time; disruptive hardware and software upgrades, forklift replacements when storage controllers needed changing, and such technology refreshes repeating every three to five years. The Evergreen concept was to make these problems disappear by designing the hardware and software to support non-disruptive upgrades and then to enable the reliable provision of storage as a service, following the example of the top public cloud providers, with array state monitoring, metering and management.
The hardware innovation was to continue to use a dual-controller architecture but with a significant difference. The traditional active-active design involved both controllers sharing the array’s workload. But they were configured to only operate at 50 percent capacity in terms of CPU performance and memory occupancy. If one of the controllers failed then the other could failover use that spare capacity to take in the entire array’s workload with no disruption of service to the array’s application users.
However, the disadvantage of this was that when a controller upgrade is needed the entire controller chassis has to be pulled out with the array going offline. Pure’s Prakash Darji, General Manager, Digital Experience, explains: “In the original design of our FlashArray, going back now 14 years, we didn’t do that. We decided to do an active-passive controller setup, where you’re using 100 percent of one, and 0 percent of the other.” The second controller “is just a hot standby. It’s completely idle and there’s no state in the controller.”
Prakash Darji.
That means that, if the first controller is pulled out for replacement, the second one fails over and there is no disruption of array service whatsoever. When the replacement controller is switched on and ready then the second one is extracted, operations fail over to the new controller, again with no service interruption, and the second one is then replaced. It’s all transparent to the applications and customers using the array.
Darji said: “That design of the hardware and the software of not managing state and an active-passive controller architecture was designed with Evergreen in mind, because evergreen means non-disruptive. It means in place, everything is in place.”
Extending the usable life of storage arrays
With these hardware and software underpinnings in place the Forever Flash program was launched in 2014 and it extended the usable life of all Pure Storage FlashArrays indefinitely, for both new and existing customers with current maintenance contracts. It was enabled by Pure’s arrays being modular, stateless, and having a software-defined architecture. The program featured flat maintenance pricing, software upgrades, a controller upgrade every three years, both included in the maintenance pricing, and an ongoing warranty for all components, including flash media.
The core principle was that customers could deploy storage once and seamlessly upgrade it in-place for multiple generations, avoiding disruptive “forklift” controller and storage chassis upgrades, and software and data migrations. The roots of the Evergreen program can clearly be seen here and it enabled a subscription model for on-premises storage, similar to the simplicity of cloud services where upgrades happen transparently in the background.
The very first Evergreen service was introduced in 2015, ten years ago, called Evergreen Gold and built on the existing Forever Flash program. It’s now called Evergreen//Forever.
The Evergreen//One option arrived in 2018 and, although it also related to on-premises storage, the array’s actual ownership was retained by Pure with customers paying – subscribing – for consumption of its services; paying for the storage they use, as with public cloud storage services. This changed the customer’s focus away from specific hardware. They paid for set levels of storage services, not for a specific array model or array configuration.
Customers can scale storage capacity up or down flexibly based on changing needs without over-provisioning. Pure delivers extra capacity to the array as needed if the customer’s workload increases its storage demands.
Satisfying performance and usage SLAs
It also featured non-disruptive upgrades and proactive monitoring, while satisfying performance and usage Service Level Agreements (SLAs). Currently there are ten such SLAs covering guarantee performance, buffer capacity, uptime availability, energy efficiency, cyber recovery, resilience, site relocation, zero planned downtime, zero data loss, and no data migration. An SLA could promise 99.5% uptime.
These SLAs are accompanied by Service Level Objectives (SLOs) which are internal goals that Pure needs to reach to meet the SLAs. Eg; 99.7% uptime. The arrays have on-board metering to provide metrics for these, Service Level Indicators (SLIs) with telemetry sending them to Pure so they can be tracked.
Darji explains: “An obligation is ‘we’re going to try’, and agreement is ‘we’re guaranteeing it’ with monetary remediation and no exclusions to the monetary remediation. No fine print.”
Pure customers can see their own SLIs in Pure1, Pure’s cloud-based data management and monitoring platform.
Darji says: “You actually can’t do Evergreen without Pure1.”
(There is more information about this in a Pure blog.)
Evolving the storage as-a-service proposition
A third Evergreen//Flex option was announced in 2022. It took the as-a-service idea a stage further by having customers own the array but only pay for the capacity they use. It provides a “fleet-level architecture” where performance and unused capacity can be dynamically allocated across the customer’s entire storage fleet as needed by applications and workloads.
In late 2023 Pure announced upgrades to its Evergreen//One and Evergreen//Flex portfolio members paying its customers’ power and rack unit space costs. Pure Storage will make a one-time, upfront payment to cover the power and rack space costs for customers subscribing to Evergreen//One or Evergreen//Flex. The payment can be made directly as cash or via service credits. It is based on fixed rates for kilowatt per hour (kWh) and Rack Unit (RU), proportional to the customer’s geographic location and contract size.
Power and rack space account for roughly 20 percent of the total cost of ownership (TCO) in the storage market.
By covering these costs, Pure eliminates a significant expenditure that still exists with on-premises STaaS deployments. For customers it deals with the problem of managing rising electricity costs and also rack space limitations, and it provides cost savings and aligns with long-term efficiency objectives for customers, helping them optimize resource and energy efficiency as per their sustainability and net-zero goals.
No other supplier does this. The Evergreen portfolio will continue to develop as Pure views its importance as the same as array hardware and software features. Darji says Pure wants to “stay focused on moving the industry forward to an outcome; that outcome being just predictability and performance and capacity in an ageless way.”
He says: ”If we could eliminate all labour required to run and operate storage that is due north for us. It’s like anything that takes work, minimise it, make it go away and be smart about that.” It’s this strand of thinking that is informing Pure’s Evergreen development roadmap. When we consider that some customers having more than a thousand Pure arrays distributed around their environment the opportunities for fleet management services look attractive.
StorONE has refreshed its software to accelerate auto-tiering, strengthen snapshot-based data protection, and recover faster after a malware attack.
The company provides clusterable storage nodes through its S1 software, now at v3.8, offering virtual storage containers with block, file or object storage. It supports both flash and disk storage, with older data migrated from fast NVMe SSD capacity to slower SAS TLC SSDs, QLC flash, and down to disk drives as a background operation when a StorONE node is less busy. The software supports all storage use cases in a single system, and can deliver 500,000 IOPS from a commodity server with six SSDs.
CEO and co-founder Gal Naor explained in a statement: “The high performance of StorONE efficiently handles data, ensuring universal access and strategic data placement, while seamlessly integrating with various locations and cloud services at the most competitive price.”
Gal Naor
StorONE first added auto-tiering between SSDs and disk tiers in July 2022. It claims it’s now “equipped with complex algorithms that can identify workloads and adjust data transfer rates accordingly.” This means the software uses real-time data usage patterns to automate data movement, “significantly enhancing efficiency while reducing administrative overhead and without user intervention.”
The company says it also has “an optimized method to move data to the hard disk tier” and data can be transferred at up to 30TB per hour.”
Marc Staimer, president of Dragon Slayer Consulting, commented: “Up until now, multi-tiered storage was too costly, too slow, limited protocol support, and/or missing essential enterprise functionality. StorONE is solving this problem with [its] Enterprise Data Storage Platform at a very affordable price.”
StorONE’s vSNAP can now store up to 100,000 immutable snapshots on the disk drive tier, offering a recovery point every 60 seconds. It says v3.8 “supports rapid ransomware recovery with high RTO maintaining 12–36 months of snapshots in the HDD tier.”
Its vRAID uses erasure coding and protects against disk failures with the system returned “to a fully protected state in less than three hours, even when using high-density (20TB-plus) hard disk drives.”
The new software is said to strengthen data breach defenses, act as the last line of defense in detecting breaches, and enables rapid recovery in case of a malware attack.
Version 3.8 also delivers a new product installation capability, allowing for full deployment on-site without any cloud connection or the option to connect to the cloud for statistics and management purposes.
Comment
StorONE, apart from its initial $30 million A-round in 2012, has stayed well away from any other VC funding. It is growing its business organically, selling through resellers, and steadily and incrementally developing its software capabilities. Its CEO and co-founder has been in place since it was started in Israel in 2011, as has co-founder and CTO Raz Gordon. The business, now headquartered in New York, has talked about going public next year.
Naor founded and ran Storwize in Israel from 2004, developing real-time, in-line, data compression technology. He sold Storwize to IBM in 2010.
StorONE has not been run like VAST Data or Rubrik or Cohesity. It has steadfastly avoided using VC funds to chase hypergrowth and reminds us of Scale Computing – the hyperconverged startup focusing on edge use cases. Scale is an HCI survivor that has built a sustainable business by sticking to its knitting and not risking everything in a frenzied dash for growth. That seems similar to StorONE’s approach.
StorONE is an individualistic storage software supplier. It’s not glamorous, nor hyper-energetic, nor screaming about its wares – just getting on with building out its all-in-one storage array software.
Data connectivity supplier CData announced a $350 million investment led by private equity operation Warburg Pincus. CData will use this new capital to accelerate investments in building innovative data integration solutions as it seeks to eliminate the significant hurdle of data access for organizations implementing AI and ML initiatives. It claims that – as the only data management vendor to offer a bi-modal integration stack – CData allows its customers to take advantage of both live data access and replicated data movement within one common connectivity platform, creating a solid foundation to support and scale AI/ML strategies.
…
Cloud connectivity supplier Cloudflare released its 2024 State of Application Security Report. Key findings include:
DDoS attacks continue to increase in number and volume. DDoS remains the most used threat vector to target web applications and APIs, comprising 37.1 percent of all application traffic mitigated by Cloudflare;
First to patch vs first to exploit – the race between defenders and attackers accelerates. Cloudflare observed faster exploitation than ever of new zero-day vulnerabilities, with one occurring just 22 minutes after its proof-of-concept (PoC) was published;
Bad bots – if left unchecked – can cause massive disruption. One-third (31.2 percent) of all traffic stems from bots, the majority (93 percent) of which are unverified and potentially malicious;
Organizations are using outdated approaches to secure APIs. Traditional web application firewall (WAF) rules that use a negative security model – the assumption that most web traffic is benign–are most commonly deployed to protect against API traffic;
Third-party software dependencies pose growing risk. Enterprise organizations use an average of 47 third-party scripts, 50 connections to JavaScript functions, and 12 cookies.
Commvault has announced the results of the Cyber Recovery Readiness Report. The survey, conducted with GigaOm, found that only 13 percent of 1,000 global respondents were categorized as cyber mature –meaning they have deployed at least four of the following five resiliency markers:
Security tools that enable early warning about risk, including insider risk;
A known-clean dark site or secondary system in place;
An isolated environment to store an immutable copy of the data;
Defined runbooks, roles, and processes for incident response;
Specific measures to show cyber recovery readiness and risk.
Based on this categorization, the survey revealed that cyber mature organizations:
Recovered 41 percent faster than respondents with only zero or one marker;
Experienced fewer breaches compared with companies that have less than four markers;
Are more likely (54 percent) to be completely confident in their ability to recover from a breach, compared to only 33 percent of less prepared organizations;
Are more likely (70 percent) to test their recovery plans quarterly, compared to 43 percent of organizations with only zero or one maturity marker.
…
Wedbush analysts attended a Databricks Data + AI Summit in San Francisco and reported: “Our conversations at the summit indicated that 1) the majority of use case for Databricks is Data Engineering, but there is increasing interest to consolidate and use Databricks as an Enterprise Data Warehouse; 2) we came across many joint Databricks and Snowflake customers; 3) we were told that architectural changes Databricks made last year materially improved its price/performance and should be a catalyst for migrations going forward; and 4) Databricks has an edge/advantage when it comes to developing Gen AI applications.”
…
DataStax made announcements covering advances in AI that deal with hallucinations and a major milestone for an open source community called Langflow. The news includes the following points:
Launch of Langflow 1.0. Langflow helps developers build generative AI applications and swap out components within the application to understand which are the best options for scaling;
Launch of RAGStack 1.0. RAGStack provides a complete stack for RAG deployment – this release includes support for advanced AI techniques GraphRAG and ColBERT, which reduce AI hallucinations;
Support for the largest number of vector embedding services. DataStax will support OpenAI, Azure OpenAI, Hugging Face, Jina AI, Mistral AI, Voyage AI, Upstage AI, and Nvidia NeMo;
Partnership with Unstructured.io. Unstructured makes it easier to prepare data for AI through its data extract-transform-load (ETL) approach.
…
Data protector HYCU has appointed Chris Nelson as VP, global sales and business development. He joins HYCU with more than 20 years experience in the storage, data protection, and disaster recovery industries with companies like Hitachi, Quantum, and Boston-based Zerto. Nelson reports directly to CRO Coley Burke.
…
Next DLP has introduced Secure Data Flow – a capability within its Reveal Platform that enhances data loss protection by tracking data origin, movements, and modifications, offering a more accurate and context-aware alternative to traditional methods. It addresses the limitations of legacy data protection technologies, providing comprehensive, false-positive-free data security that simplifies the work of security analysts. Secure Data Flow secures the flow of critical business data from any SaaS application including Salesforce, Workday, SAP, and GitHub, ensuring that sensitive information is always protected.
…
Nutanix announced the findings of its sixth annual global Financial Services Enterprise Cloud Index (ECI) survey and research report, which measures enterprise progress with cloud adoption in the financial services and insurance industry. While current adoption of hybrid multicloud deployments remains consistent year-over-year in the financial services sector, respondents expect a 3x increase in adoption in the next three years, making it the leading IT model in the sector.
…
Vinoth Chandar
Onehouse, founded in 2021 by creator and PMC chair of the Apache Hudi project Vinoth Chandar, has secured $35 million in Series B funding led by Craft Ventures. Existing investors Addition and Greylock Partners participated in this new round, bringing total funding to date to $68 million. The company provides a fully managed cloud data lakehouse supporting Iceberg, HUDI, and other standards.
…
Korean startup Panmnesia has developed a GPU memory expansion device using a CXL controller with two-digit nanosecond latency.
Panmnesia diagram
…
PEAK:AIO has appointed professor Sebastien Ourselin to its advisory board. “Dr Ourselin is a renowned expert and pioneer in the AI for healthcare sector and will be working with the team to drive corporate growth through innovation within the AI healthcare market,” it declared. Ourselin heads the School of Biomedical Engineering & Imaging Sciences at King’s College London. He is also the director of the London Institute for Healthcare Engineering and the AI Centre for Value Based Healthcare.
…
TechRadar reports that Phison has a 128TB version of its Pascari QLC SSD coming out in a few months. B&F expects all the SSD suppliers have 100TB-plus drives in development.
…
Wedbush analyst Matt Bryson attended the Pure Accelerate event in Las Vegas and told subscribers: “We believe much of what PSTG talked to yesterday at Accelerate expounds on our positive thesis.”
Larger flash modules. Not only did we get a 150TB part previewed, but PSTG talked about a forthcoming 300TB DFM. With space and power becoming more important factors for datacenters, we see the density of PSTG’s DFMs as a distinct advantage for Pure.
Hyperscale customer. The company believes it will be able to announce a hyperscale design win by the end of this year and talked to the combination of Purity and DFMs tailored to hyperscale customer needs as the basis for Pure’s expected success in this market.
Fusion. Pure is broadening the use of its Fusion software to support datacenter installations. We see the additional software capabilities as potentially advantaging Pure as enterprises work to consolidate their storage to better support their AI initiatives.
DGX Superpod certification. Pure expects to receive DGX SuperPOD certification by the end of the year. This result in our view should only improve PSTG’s traction in AI environments.
Evergreen One simplicity. Again, we would note that customers like PSTG. One reason we have cited for their favorable views is the simplicity of their Evergreen One contracts – something PSTG explicitly showed off yesterday.
…
Samsung Electronics has successfully built CXL infrastructure certified by Red Hat. Samsung claims this “historic development will enable Samsung to accelerate product development and provide tailored solutions to customers by optimizing products at earlier development stages.” Elements that configure servers, from CXL-related products to software, can now be directly verified at the Samsung Memory Research Center in Hwaseong, South Korea. Once CXL products are verified by Samsung, they can now be submitted for product registration to Red Hat, enabling faster product development.
…
DigiTimes notes that SK hynix has pulled forward the build of its M15X DRAM plant to mid 2025 to ramp HBM supply more quickly. The Taiwanese paper also reports that industry HBM capacity is now largely sold out through 2025, with orders starting to accrue for early 2026.
…
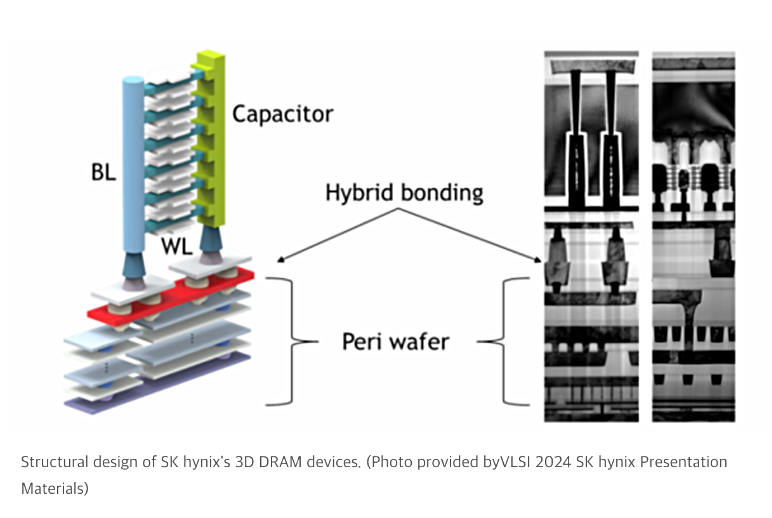
SK hynix is working to develop 3D DRAM, as a way of increasing DRAM per-die capacity. A SK hynix session at VLSI presented its progress with a five-layer chip. A Business Korea report said the manufacturing yield of its five-layer stacked 3D DRAM has reached 56.1 percent, but a significant amount of development is still required before it can be commercialized. To indicate the scope of problems remaining, SK hynix speakers said 3D DRAM exhibits unstable performance characteristics, and stacking 32 to 192 layers of memory cells is necessary for widespread use – not five.
…
Enterprise data management supplier Syniti says The Heraeus Group – a German technology company – has chosen Syniti software to establish a migration factory approach so it can better manage merger, acquisition, and divestiture activities.
Toshiba has developed a low-end nearline disk drive suitable only for SATA and SAS connectivity with a lower total cost of ownership than the drive it replaces.
The current MG10F drive was introduced in September last year as a 1–22TB product range with 12Gbit/sec SAS and 6Gbit/sec SATA connectivity options for its 7,200rpm platters. The range uses conventional (perpendicular) magnetic recording (CMR) and was split into two parts, with the 12–16TB products using helium-filled enclosures and the 1–10TB variants using less expensive air-filled casing. The cache buffer varies between 128MiB (134MB) and 256MiB (268MB) for the 1–14TB models and is 512MiB (537MB) for the higher capacity variants.
Larry Martinez-Palomo
The MG10D effectively replaces the 1–10TB MG10F products, being air an air-filled CMR drive with a 512MiB cache, giving it a speed advantage over the replaced MG10F HDDs. It provides an approximately 13 percent better maximum sustained transfer speed of 268MiB/sec (281MB/sec). The MG10D also reduces power consumption in active idle mode by approximately 21 percent to 5.74 W.
Larry Martinez-Palomo, VP and head of storage products at Toshiba, said: “The new cutting-edge design of the MG10-D Series is engineered for sustainable enterprise environments and fits seamlessly into existing infrastructure reducing TCO.”
The drive has only five platters instead of up to ten in the MG10F. Its MTBF (mean time before failure) rating is 2 million hours, whereas the replaced HDDs had a higher 2.5 million hour MTBF. The 550 TB/year workload rating though is unchanged, as are the sanitize instant erase (SIE) and self-encrypting drive (SED) options. The 1TB variant is a SATA-only product.
MG10D with lid off
The MG10D supports Advanced format 512e and 4Kn, and a 512n option is available on the 1, 2, and 4TB offerings to support legacy systems with native 512 byte block sizes. It is given a AFR (Annual Failure Rate) of 0.44 percent.
The MG10D will be available in the third 2024 quarter and can be used in email, data analytics, data retention, and surveillance applications. Check out Toshiba’s info about the MG10D here.
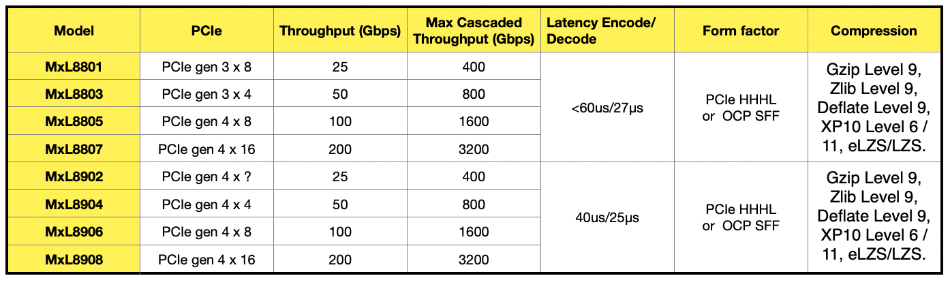
MaxLinear has launched the MxL8900 storage accelerator as an upgrade to its MxL8800 series, lowering latency and adding upcoming support for PCIe 5.
MaxLinear’s Panther III accelerator cards are similar to DPU (data processing unit) add-in cards, but more akin to CPU-offload cards – taking on compression, deduplication, and encode/decide functions from a host server CPU, doing them much faster and using less electricity. It claims data reduction ratios of up to 15:1 with structured data and 12:1 with unstructured data, increasing the effective capacity of NVMe SSDs by up to 15x and 12x respectively.
The MxL8800 series product range provides PCIe 3 and 4 support, and from 25 to 200 Gbit/sec throughput with encode/decode latencies of <60us/27μs. Up to 16 of the cards can be cascaded together to increase the throughput numbers to 400 to 3,200 Gbit/sec respectively.
MaxLinear marketing director Mark Moran spoke at a June IT Press Tour in Silicon Valley about the new products. Moran described the Panther product, saying: “We don’t necessarily call it a DPU anymore, because the term DPU has been taken over by the SmartNIC and people have now associated the DPU to something that has Arm processors inside of it. I don’t have Arm processors inside of mine because they would run too slow. We call it a storage accelerator.”
Panther III card using 8908 processing chip
The newer MxL8900 series products don’t change the throughput numbers, but have lower encode/decode latencies : 40us/25μs.
Moran said that Panther’s appeal as a storage drive physical space saver, with its 12:1 effective capacity increase and its consequent electricity draw reduction. Imagine every 12 drives being replaced by one, meaning power- and space-constrained datacenters could use Panther cards to keep up with AI-related storage demand.
He said: “Everybody wants to go off and buy AI today … The next question is, can I try and get all my data and how do I store it? Basically, people are wanting to route, generate, analyze, and store their data. They want to store this data securely, and they want to store all the data.
“Every year, we increase the amount of data we create. What you probably don’t realize is we only store a very small fraction of that data we create … All of a sudden now that everybody has AI this is becoming a big issue. They want to store all their data because they don’t know which data is going to be valuable anymore.”
Enter the Panther card, which can turn a server with 8x 10TB NVMe SSD capacity into an effective 960TB capacity machine and its cost per effective GB goes down.
According to Moran, PCIe 5 support is forthcoming, although he did not provide any performance numbers. As the gen 5 bus is twice as fast as the gen 4 PCIe spec, we expect throughput numbers will rise. About possible new features, Moran only said: “Being able to offload more deduplication is on the list. Being able to do better compression is on the list [with] new levels of compression potentially on the list.”
MaxLinear sells both the Panther chip and the Panther card to OEMs, one of which is Dell.