Rubrik is joining forces with Cisco to enhance organisations’ cyber resilience, with Rubrik integrating with the Cisco XDR (extended detection and response) platform, and joining its SolutionsPlus program.
The integration will make it easier for enterprises to quickly identify targeted attacks on data, and deliver a secure recovery, the partners said.
The partnership will deliver combined threat intelligence and data context to prioritise and respond effectively to threats targeting critical data, as well as streamlined security and IT operations to help repair after attacks.
Automated, multi-site scaling and lifecycle management technology from Cisco Intersight will also enable the deployment and tuned configuration of the Rubrik Data Management Platform on Cisco UCS (Unified Computing Systems) server infrastructure at a global scale.
Rubrik will join Cisco’s SolutionsPlus program as well, with all of Rubrik’s products being added to Cisco’s global price list. As part of SolutionsPlus, Cisco’s direct and channel sales network can now offer Rubrik Security Cloud with Cisco UCS and Cisco XDR systems.
Rubrik’s Data Security Posture Management (DSPM) technology is also on the price list, allowing joint customers to proactively reduce the risk of data exposure and exfiltration across on-premises, cloud, and SaaS environments, through knowing where all the data is and how to secure it, we are told.
Ghazal Asif Farhadi.
“As the volume of data continues to grow and exacerbate visibility challenges, organizations must find ways to manage and protect their constantly expanding data,” said Ghazal Asif Farhadi, VP of global channels, alliances and inside sales at Rubrik. “Therefore, Rubrik and Cisco have joined forces to enhance organizations’ cyber resilience and protect mission-critical data against cyber attacks.”
“Complex, siloed systems create gaps in visibility that hinder operations and slow down organizations’ ability to detect and respond to threats,” added Jeremy Foster, senior vice president and general manager of Cisco Compute. “We are now delivering threat detection and data context in one place, enabling security teams to effectively prioritize critical attacks and respond to them quickly.”
Jim Finn, sales VP, cyber at Presidio, said: “As a major partner to Cisco and Rubrik, we believe their collaboration will help our customers proactively advance and simplify their data security.”
Earlier this month, Rubrik extended its SaaS app data protection to Salesforce Core platform data.
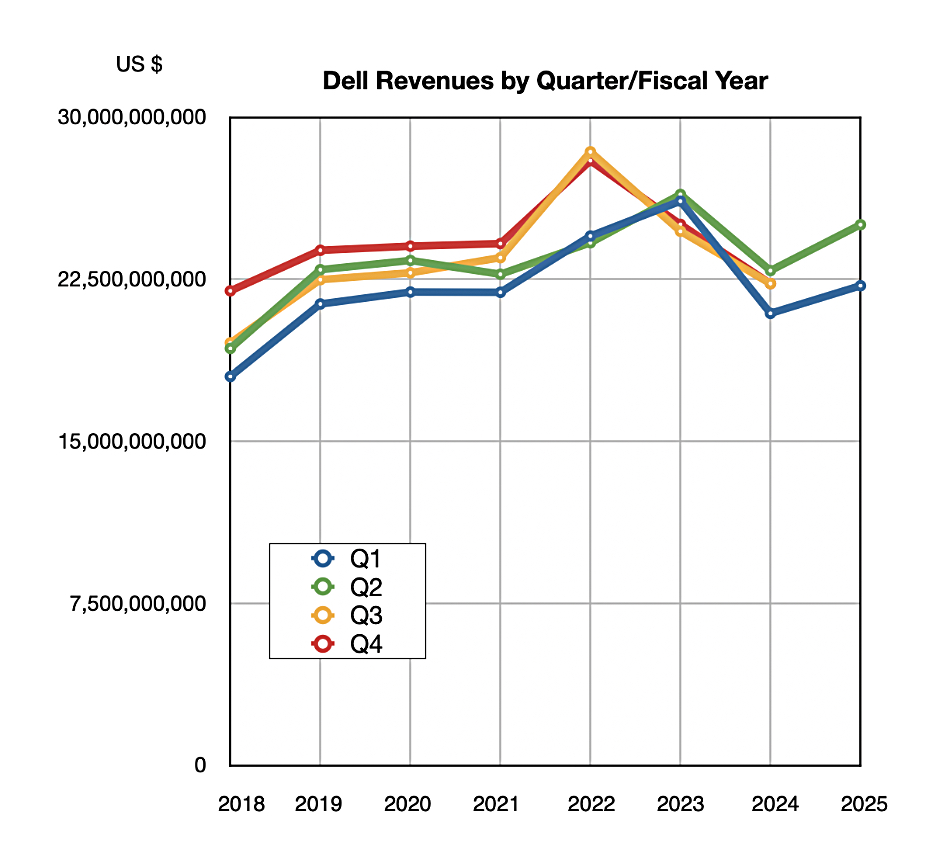
A massive rise in server sales led Dell’s second fiscal 2025 quarter revenues to a 9 percent year-on-year rise to $25 billion, with an $841 million profit, more than Nutanix’ entire $524.6 million quarterly revenue, but there was a slowdown in HCI sales.
Dell said there was: “Exceptional AI-optimized server demand and improved traditional server demand growth,” in the quarter ended August 2, 2024.
Jeff Clarke.
Vice-chairman and COO Jeff Clarke stated: “We executed well in Q2, and I’m really proud of our team and our performance.” The revenue number was “another record for our servers and networking business.”
Quarterly financial summary
Gross margin: 21.2 percent vs 23.5 percent a year ago
Operating cash flow: $1.3 billion
Free cash flow: $1.28 billion vs $3.1 billion last year
Cash, cash equivalents, and restricted cash: $6.0 billion vs $7.9 billion last year
Diluted earnings per share: $1.17, up 86 percent y/y
The $1.7 billion downturn in cash and investments was the result of Dell making capital returns of $1 billion; repurchasing 5.5 million shares of stock at an average price of $130.03 plus paying a $0.45 per share dividend, and net debt paydown of $1 billion during the quarter.
Dell has resumed a growth trajectory after 6 quarters of declining revenue.
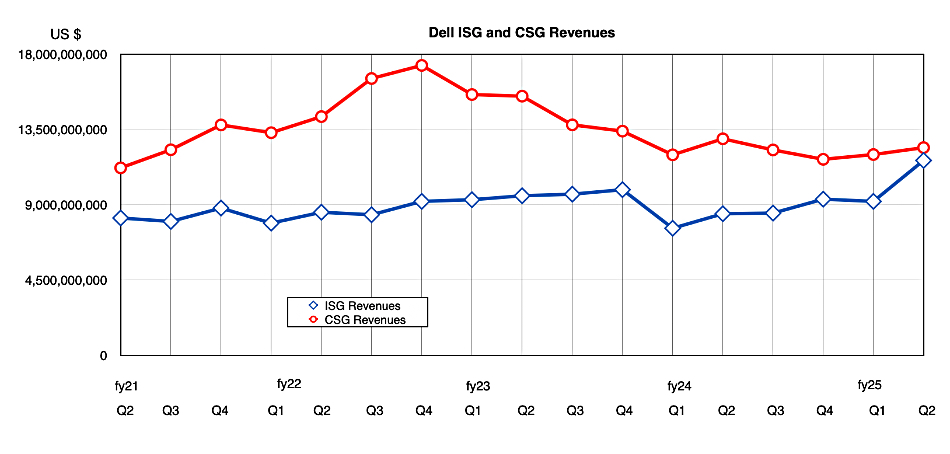
The two main Dell business units, the Infrastructure Solutions Group (ISG) and Client Solutions Group (CSG), had differing results with ISG (servers, storage and networking) revenues rising 38 percent Y/Y to a record $11.6 billion, while CSG (PCs, etc.) revenues went down 4 percent to $12.4 billion. In the CSG unit, commercial client revenue was flat at $10.6 billion, and consumer revenue was 22 percent down at $1.9 billion. ISG is now in a position to overtake CSG revenues after years of CSG being far ahead.
ISG revenues could overtake CSG revenues if the AI server sales boost continues.
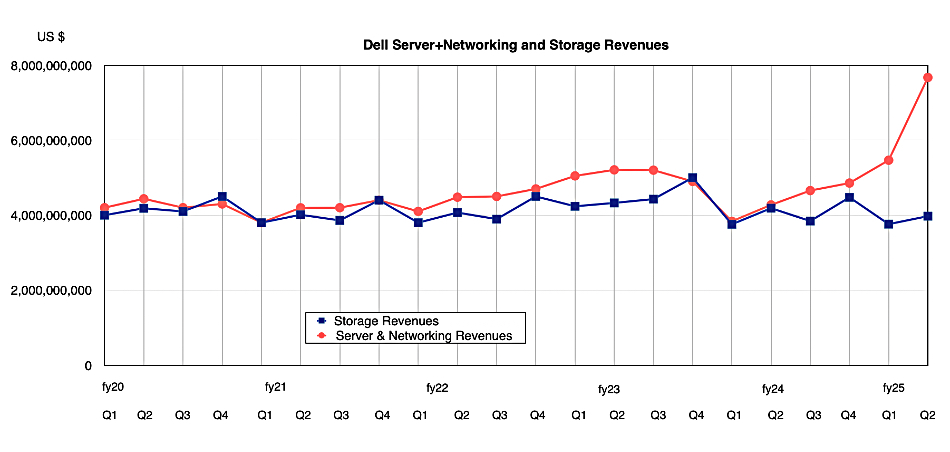
The ISG revenue driver was and is server sales, with a remarkable 80 percent rise in the combined server and networking revenue number to a record $7.7 billion. Storage revenue was $4.0 billion, down 5 percent.
Note the sudden rise in ISG’s server and networking revenues this quarter.
Clarke’s prepared remarks expanded on this: “Our AI momentum accelerated in Q2, and we’ve seen an increase in the number of enterprise customers buying AI solutions each quarter. AI-optimized server demand was $3.2 billion, up 23% sequentially, and $5.8 billion year to date. Backlog was $3.8 billion, and our pipeline has grown to several multiples of our backlog.” This hints that next quarter’s server revenues should be impressive as well.
There was demand growth in storage, with Clarke saying in the earnings call: “Dell IP core storage demand, including PowerMax, PowerScale, PowerStore and PowerProtect/Data Domain grew double-digits in the quarter, a positive sign as we move into the second-half of the year.”
CFO Yvonne McGill said storage did well under the covers: ”We’re pleased with the sequential improvement in storage profitability. We gained scale with 6 percent sequential revenue growth. We were more disciplined in our pricing. We had a higher mix of Dell IP storage solutions and a better geographic mix with more North America activity.”
She also identified the storage weak point: ”This strong storage performance was offset by headwinds in the partner IP portion of our HCI (hyper-converged infrastructure) portfolio.”
Earnings call analyst Tony Sacconaghi suggested “that hyperconverged is either an enormous part of your business or was down by a huge amount.” Clarke confirmed that: “obviously, your conclusion is correct. The partner IP business was down quarter-over-quarter.”
Dell’s Investor Relations head Rob Williams added: “We haven’t broken it out specifically, but it [HCI] is obviously a large part of the business. And data protection would be the other area where there was a bit of decline year-over-year. So those two offset the increases in the other four businesses we mentioned.” The other four being PowerMax, PowerScale, PowerStore and PowerProtect/Data Domain.
Dell supplies VxRail HCI running vSphere and also PowerFlex HCI systems. There are well known VMware market issues following Broadcom’s acquisition of VMware. Dell signed an HCI partnership deal with Nutanix in the quarter, looking to grow its HCI business.
Back to AI
AI server sales dominated the quarter, with Clarke saying: ”Our unique capability to deliver leading-edge air and liquid cooled AI servers, networking and storage tuned and optimized for maximum performance at the node and rack level combined with leading ecosystem partners and world-class services and support continues to resonate with customers.”
There’s more to come: “Enterprise remains a significant opportunity for us as many are still in the early stages of AI adoption. We are also excited about the emerging sovereign AI opportunity, which plays to our strengths given our position with governments around the world.”
And: ”Most exciting, our AI server pipeline expanded across both Tier-2 CSPs and enterprise customers again in Q2, and now has grown to several multiples of our backlog. As we begin the second-half of the year, we have optimized our sales coverage to better focus on AI opportunities across CSPs, and both large and small customer segments and geographies.”
The outlook is excellent: “Our AI opportunity with Tier-2 CSPs, enterprise and emerging sovereign customers is immense. Our view is supported by an AI hardware and services TAM of $174 billion, up from $152 billion, growing at a 22 percent CAGR over the next few years. We are competing in all of the big AI deals and are winning significant deployments at scale.”
McGill said: ”We expect solid top line growth in the second-half of the year even as we continue to optimize our cost structure to enhance our competitiveness over the long-term.
“A big part of this optimization effort is leveraging AI to reimagine our business processes and drive higher productivity. To that end, in Q2, we took a $328 million charge for workforce reduction as we continue to position our business for the long-term.”
She added: “We’re using it [AI] to improve customer and team member experiences in sales, software development, services, content management and our supply chain. And in turn, we’re using our experiences to help our customers realize benefits of AI for themselves.”
It looks like fears about AI replacing human jobs are real.
Clarke said: “If you think about the use cases, the use cases are generally around large language models; small language models are coming. We’re already talking about technologies like agents and agent is a buzzword of our industry today, and we’ve just scratched the surface of how agents are going to help each individual’s productivity, help with specific skills, which provide an opportunity to take the millions of processes that are in businesses today and help automate them.”
Outlook
Although lagging currently, CSG has a positive outlook, according to Clarke, with: “modest commercial PC demand growth in the quarter …we continue to pursue profitable share focusing on commercial PCs, high-end consumer and gaming with our strong attach motion.
“We are optimistic about the coming PC refresh cycle, as the installed base continues to age, Windows 10 reaches end-of-life later next year and the significant advancements in AI-enabled architectures and applications continue.”
McGill said: “We expect [CSG] growth in the second-half of the year, particularly in the fourth quarter.”
The outlook of $24.5 billion +/- $500 million for the next quarter represents 10 percent Y/Y growth, with ISG revenues growing in the 30 percent region. The full fy2025 outlook has been revised upwards slightly, with revenues of $97 billion +/- $1.5 billion, again 10 percent higher than a year ago, with ISG up 30 percent or so and CSG flat. It looks highly likely that ISG revenues will overtake CSG revenues by the end of the fiscal year.
Nutanix beat the street with its latest results driven by a strong contract renewals performance and increased sales in its customer base, despite large deals taking longer to close.
Revenues in its fourth fiscal 2024 quarter, ended July 31, were $548 million, a 21 percent annual increase, and a loss of $126.1 million mainly due to a $106.4 million expense item. Full year revenues were $2.15 billion, up 15 percent from fy 2023’s $1.86 billion, and beating its guidance, but with a loss of $124.8 million. There was 22 percent year-over-year annual recurring revenue (ARR) growth in the quarter to $1.91 billion, strong free cash flow generation and a first full year of positive GAAP operating income ($8 million).
Rajiv Ramaswami.
President and CEO Rajiv Ramaswami stated: “Our fourth quarter was a solid finish to a fiscal year that showed good progress on our financial model with solid top line growth and sharp year-over-year improvement in profitability.” That is the non-GAAP profitability of $8 million, which Nutanix called an “important milestone.”
The revenue increase happened despite a problem, as Ramaswami explained: “Our land and expand business underperformed related to our internal expectations due to the longer-than-expected sales cycles.”
Financial summary:
Gross margin: 85.2% vs 83.7% last year
Free cash flow: $224.3 million vs year-ago’s $45.5 million
Operating cash flow: 244.7 million compared to $58.3 million a year ago
Cash, cash equivalents and short-term investments: $994 million compared to $1.7 billion at the end of the prior quarter
CFO Rukmini Sivaraman said: “The primary reason for the reduction in our cash balance was Bain Capital’s conversion of the 2026 notes, which we announced in June. We settled the conversion in Q4 by paying $817.6 million in cash and delivering approximately 16.9 million shares of common stock.”
Rajiv Ramaswami became Nutanix CEO in fy 2021, Since then Nutanix’ revenue growth rate has increased to a consistent high level – apart from a Q4 fy2022 blip.
The company gained 670 new customers in the quarter, its highest number for 3 years, attributed to new partners and sales programs. That means it now has 26,530 customers. It signed partnership deals with Dell, Cisco and Nutanix during fy2024. Ramaswami said: ”We see these partnerships as both expanding our addressable market and providing us with meaningful go-to-market leverage.”
William Blair analyst Jason Ader told subscribers that the current Nutanix-Cisco OEM partnership (Cisco Compute HyperConverged) contributed to significant new logo additions in the second half of fiscal 2024 with expectations for solid growth in revenue contribution in fiscal 2025.
Nutanix is finding that large deals are taking longer to close, Ader telling subscribers: “Nutanix’s largest win in the fourth quarter was a multimillion-dollar deal with a Fortune 100 financial services company that took 18 months to close, not unlike the eight-figure win announced last quarter that took over two years to close.”
Ader pointed out that: “While moving upmarket is a top go-to-market priority, Nutanix stressed that it remains very active in its traditional sweet spot at the lower end of the enterprise market. This segment of the market is particularly ripe for displacement of VMware as many of these smaller accounts have seen their VMware bills skyrocket under the new Broadcom pricing scheme.”
Nutanix noted that, where VMware is running on a 3-tier architecture, a switch to Nutanix and its hyper-converged infrastructure (HCI) necessitates a hardware refresh and this can push deals out to a scheduled hardware refresh date.
Ader also said: “Nutanix reached a Rule-of-40 score of 43 in fiscal 2024 (defined as revenue growth plus free cash flow margin), boosted by stellar free cash flow generation of $598 million.”
Ramaswami was asked about progress with AI and Nutanix’ GPT-in-a-box Gen AI offering in the earnings call. He replied: “I think a lot of initial interest in Gen AI has been in creation and training of LLMs, large language models, and a lot of that is being done in the public cloud and massive GPU farms. And we don’t play there fully.
“But on the other hand, we think the bulk of the enterprise opportunity in terms of how companies are actually going to use it, is potentially going to be on-prem because, at the end of the day, the Gen AI workloads, applications have to run wherever the customer data is. And in a lot of cases, sensitive customer data is either inside data centers or at the edges, and so a platform like our GPT-in-a-Box provides a very simple, easy-to-use, secure, way of running Gen AI applications.”
It is still early days for GPT-in-a-box adoption but the opportunity “for fine tuning, RAG (Retrieval, Augmented Generation) and for inferencing in terms of running these AI workloads close to the data in a private and secure way” is coming.
The outlook for the next quarter is $570 million +/- $5 million, meaning an 11.5 percent increase on the year-ago quarter. Nutanix is guiding full fy2024 revenues of $2.45 billion +/-$15 million in revenues; a 14 percent Y/Y increase.
DRAM and NAND fabricator SK hynix has revealed the industry’s first 16Gb DDR5 memory system using a 1c node – the sixth generation of the 10nm process, building on 1b.
The silicon slinger promised it will be ready for mass production of the 1c DDR5 “within the year” to start volume shipments next year.
The product improves cost competitiveness in manufacturing, compared with 1b, by adopting new materials and processes, said the South Korea-headquartered manufacturer.
SK Hynix 1c DDR5.
In May 2023, Samsung Electronics announced it had succeeded in mass-producing 1b-nanometer DRAMs for the first time in the industry. SK hynix then followed suit. Samsung said earlier this year it planned to start mass-producing a 1c DRAM by the end of this year – but no updates have been forthcoming, so SK hynix now seems to be ahead.
Double Data Rate 5 (DDR5) Synchronous Dynamic Random-Access Memory (SDRAM) promises to reduce power consumption and increase bandwidth, compared to its predecessor DDR4 SDRAM.
The operating speed of 1c DDR5 – expected to be adopted for high-performance datacenters – has been improved by 11 percent from the previous generation to 8Gbit/sec, said SK hynix. Power efficiency is also improved by more than 9 percent, we are told, as datacenters of course face increased power demands as a result of having to deal with AI workloads.
“We are committed to providing differentiated values to customers by applying the 1c technology, equipped with the best performance and cost competitiveness, to our major next-generation products, including HBM, LPDDR6, and GDDR7 systems,” said Kim Jonghwan, head of DRAM development at SK hynix. “We will continue to work towards maintaining our leadership in the DRAM space, to position SK hynix as a trusted AI memory solution provider.”
Earlier this month, SK hynix said it was developing a computational object storage system (OCS) with Los Alamos Nuclear Labs (LANL) to streamline analytics workloads. Object data is stored in Parquet files on NVMe SSDs, and when LANL wants to do a large scale simulation run, the data on the SSDs is preprocessed by the OCS to reduce the dataset sent to the analysis servers.
Veeam has widened its support for different platforms with the unveiling of its latest version of the Veeam Data Platform, including extra support for those migrating from VMware.
Since completing its acquisition of VMware at the end of last year, Broadcom has shifted its focus to larger customers. As a result, Veeam reports that its SMB customers are considering Proxmox VE as an alternative. Proxmox VE is an open source server virtual machine and container environment. Its toolset includes vzdump for backing up guest virtual machines and integrates with Proxmox Backup Server for centralized backup management.
Withv12.2 of the Veeam Data Platform, there is full backup support for Proxmox VE, protecting the hypervisor without requiring the management or use of backup agents. Users have flexible recovery options, including VM restores from and to VMware, Hyper-V, Nutanix AHV, oVirt KVM, AWS, Azure, and Google Cloud. They can also restore physical server backups directly to Proxmox VE for disaster recovery (DR) or virtualization/migration purposes.
“We see Veeam’s support for the Proxmox VE hypervisor as a valuable addition for organizations seeking open source flexibility and cost-effectiveness. It allows customers to stick with their preferred single platform for data backup and recovery while embracing the preferred hypervisor of their choice,” said Martin Maurer, CEO of Proxmox Server Solutions.
James Westendorf
“With the recent changes at VMware, we were forced to re-evaluate which hypervisor to choose for our datacenter – a situation nobody wants to be in. Veeam remains a critical partner for us as we look forward to being able to choose to move to Proxmox,” said James Westendorf, director of technical services at Lake Land College in Illinois, US.
“Using Veeam’s trusted tools for data migration will provide us with the peace of mind we need during these tumultuous times.”
With v12.2, there is also “enhanced” Nutanix AHV integration to protect critical data from replica nodes without affecting the production environment. Users can benefit from “deep” Nutanix Prism integration with policy-based backup jobs, “increased” backup security, and “flexibility” in network design, Veeam said.
The upgraded platform also provides backup for MongoDB, offering immutable backups, backup copies, and “advanced” storage capabilities, we are told.
In addition, there is expanded AWS support, allowing users to extend native resilience to Amazon FSx and Amazon Redshift through policy-based protection and “fast, automated recovery”. There is also wider Microsoft Azure support with native resilience to Azure Cosmos DB and Azure Data Lake Storage Gen2 for “resilient protection and automated recovery.”
“We are seeing customers evaluate a vast array of hypervisor and cloud infrastructure options to optimize both cost and functionalities, making data mobility more important than ever before,” said Krista Case, research director at analyst house The Futurum Group.
Earlier this month, analyst Gartner named Veeam the leader in market share for the global enterprise backup and recovery software market, displacing Veritas from the top position.
Pure Storage revenues grew in its second fiscal 2025 quarter, with hyperscalers and AI showing promise for the future.
Revenues in the quarter were $763.8 million, up 11 percent on a year ago and beating its $755 million guidance. Profit was $35.7 million, much better than $7 million loss last year. Pure said its discussions with hyperscalers to replace their core (disk) storage with Pure’s all-flash technology “continue to progress positively.”
Charles Giancarlo
Chairman and CEO Charles Giancarlo stated: “We were pleased with our Q2 revenue growth of 11 percent year-over-year. Pure continues to pick up market share, and outpace the industry, both in innovation and in growth.”
Quarterly financial summary:
Gross margin: 70.7 percent, flat year-on-year
Free cash flow: $166.6 million vs $46.5 million a year ago
Operating cash flow: $226.6 million vs $101.6 million a year ago
Total cash, cash equivalents, and marketable securities: $1.82 billion vs $1.2 billion a year ago
Remaining Performance Obligations: $2.34 billion, up 24 percent year-on-year
Pure’s revenue was made up of $361 million subscription services and $403 million product sales, with the year-ago numbers being $289 million and $400 million respectively. Subscription services are growing faster, at 25 percent, compared to product revenues, which had a 0.71 percent growth rate.
Pure noted strong FlashArray//E and FlashBlade//E capacity-optimized array sales performance. The FlashArray//C did well too.
There was 24 percent year-on-year growth in Pure’s Annual Recurring Revenue (ARR), driven by its EverGreen//One service offering. However, large EverGreen//One deals, those in excess of $5 million, took longer to close.
Pure gained some 261 new customers in the quarter, including two from the Fortune 500, taking its total customer count past 13,000.
Hyperscalers
It is continuing discussions with prospective hyperscaler customers. Giancarlo said: “Our lead prospect has advanced from extensive evaluation of our core technology to testing an integrated solution, and we have been engaged in detailed contractual negotiations for many months. We remain confident that we will secure our first hyperscaler design win by year end.”
CFO Kevan Krysler added: “Our most significant capital expenditures during the quarter were concentrated in engineering for new test equipment supporting key strategic growth initiatives, including our pursuit of hyperscaler infrastructure opportunities.”
CTO Rob Lee said: ”What we’ve done over the last many months is really move forward on our testing in phases from initial proof of concept to testing of that core IP to now extensive testing of really an integrated, think of it as a co-engineered solution. And as you’d imagine, this involves detailed performance, operational testing, so on and so forth.”
Giancarlo sees high potential with hyperscalers. ”The longer-term opportunity for Pure with hyperscalers is significant,” he said. “To provide a sense of scale, the top ten hyperscalers are projected to buy almost 70 percent of all disk drives, over 600 exabytes in total, this year alone. Because of Pure’s unique Direct to Flash technology, we can offer hyperscalers better performance, reliability, and power and space savings than hard disks, at a similar or better total cost of ownership.”
Krysler spoke in more detail about the hyperscaler opportunity for Pure’s Direct Flash Module (DFM) technology. ”They’re looking to make it an architectural shift in their infrastructure, whereby it would replace not only higher-performance workloads but lower-performance workloads, including disk, and once implemented, there’s no reason for it not to replace, for example, even their use of SSDs.”
Lee noted: “We think, in the long term, we’ve got opportunity to go provide value across the board with our Direct-to-Flash technology. But certainly, as an initial step, we’d be focusing on the replacement of the disk-based environments in that infrastructure.”
AI
Turning to AI, Giancarlo said: ”The AI market for data storage has progressed as we have consistently predicted,” with three identified opportunities. “First, storage for machine learning and training environments where Pure provides high-performance storage for public and private GPU farms.
“Our view is that in total, the total market for storage for large language type models – training models – is less than $1 billion a year currently.
”The second AI opportunity we foresee focuses on tailored storage for enterprise inference or RAG [retrieval-augmented generation] environments. Many, if not most, enterprises will use commercial LLMs or other models to operate on their own proprietary data in-house. These systems will use relatively small GPU environments to provide AI insight from their data. Pure is working closely with Nvidia on a number of vertical market offerings to satisfy this market.
“We continue to believe that our largest opportunity opened by AI is to address the siloed nature of enterprises’ existing data storage architectures. Current data stores sit behind application stacks and generally have neither the performance nor the connectivity to serve data directly for AI engines and analytics. Customers that are the most advanced in their AI investigations all acknowledge that data access and preparation are major barriers to AI deployment.
“Pure Fusion will allow customers to upgrade their enterprise storage to function as a storage cloud, simplifying data access and management, and eliminating data silos to enable easier access for AI.”
The Fusion offering unifies arrays and optimizes storage pools on the fly across structured and unstructured data, on-premises, and in the cloud. It also automates orchestration and workload placement.
CTO Lee said: “With our latest release of Fusion coming later this year, we’ll be able to deliver all of those capabilities that Fusion was designed for, being able to fully automate the management multiple environments, allow customers to manage their Pure Storage estate through policy declaration as opposed to individual operational steps and really step back and unify that as one pool of resources, one storage cloud, if you will. Later this year, customers will be able to take advantage of all these capabilities on all of their existing arrays and data storage estates.”
Giancarlo highlighted Pure’s electricity savings: “In a world where energy demands are soaring, the power savings of Pure Storage alone make the move from hard disks to Pure technology a smart choice for both hyperscaler and enterprise data centers. Businesses can grow their data storage and reduce their energy footprint with Pure on a platform that eliminates existing data silos and simplifies customers’ data centers with guaranteed service-level agreements.”
He added: “Energy and space savings generated by our Direct-to-Flash advantage are significant – we reduce space, power, and cooling requirements by a factor of 5 to 10 compared to hard disks. In a world of greater power demands and limited electrical supply, the savings on electricity alone provides a compelling incentive to switch from hard disks in both hyperscaler as well as enterprise data centers.”
William Blair analyst Jason Ader noted: “Investors remain on pins-and-needles with respect to a major hyperscaler win.”
If Pure does succeed in selling its flash storage to hyperscalers, perhaps it will start repeating its flash-will-replace-disk-drives message about which we have heard little recently.
Giancarlo is confident about Pure’s competitive strength. He told analysts: “We know we are gaining ground as our growing strength has forced competitors to intensify their efforts and mimic our messaging. It is clear now that legacy competitors in our market see Pure as the alpha competitor and have focused their messaging and strategies on us. We appreciate the attention and look forward to the competition.”
Krysler said: “We’re now the number two vendor of all-flash systems into the enterprise [and] firmly in that spot and only a few points behind the number one in that area … Competition is tough, but our lead in QLC remains.” Number one would be Dell.
The outlook for the third fiscal 2025 quarter is revenues of $815 million, up 6.8 percent year-on-year, with the full-year outlook unchanged at $3.1 billion, representing a 10.5 percent year-on-year growth rate. Giancarlo commented: “We believe that the storage market will be resilient in this IT economy, but we have yet to see a positive inflection.”
Wedbush analyst Matt Bryson commented: “Pure Storage ostensibly outperformed their prior outlook and guided Q3 above prior consensus revenue estimates, but the growth forecast wasn’t good enough in light of elevated expectations, particularly given other less-than-perfect metrics. We’d note that Pure Storage’s results contrast significantly with storage peer NetApp, which noted accelerating sales momentum and significantly stronger product growth for its July quarter.”
NetApp revenues are up, driven by all-flash array sales, making Q1 fiscal 2025 the company’s third successive growth quarter.
Revenues were $1.54 billion, which is 8 percent higher than a year ago, with a $248 million profit, a 66.4 percent increase from the previous year. NetApp generated $669 million in product revenues, a 13.4 percent increase, and its all-flash array annual run rate rose by 21 percent to $3.4 billion.
George Kurian
CEO George Kurian commented: “We started fiscal year 2025 on a high note, delivering strong revenue growth and setting records for first quarter operating margin and EPS … I am confident in our ability to capitalize on this momentum as we address new market opportunities, extend our leadership position in existing markets, and deliver increasing value for all our stakeholders.”
He added: “We are raising our FY25 outlook for both revenue and profit.”
Quarterly financial summary
Consolidated gross margin: 71.3 percent vs 69.6 percent a year ago
Operating cash flow: $341 million vs $453 million a year ago
Free cash flow: $300 million vs $418 million last year
Cash, cash equivalents, and investments: $3.02 billion
EPS: $1.17 vs $0.69 a year ago
Share repurchases and dividends: $507 million in stock repurchases
Kurian said NetApp experienced momentum in flash, block, cloud storage, and AI. He commented: “Both our capacity flash and block-optimized all-flash array families exhibited strong growth year-over-year, addressing an expanded TAM and driving share gains.”
He expanded on this in the earnings call, saying there were “really strong results across the board … in the block storage part of that portfolio, which is pure share gain against competition. We are demonstrating the price performance leadership against the high-end product of our competitors, as well as the price performance and feature set leadership against the midrange products of our competitors.”
In the performance flash block storage market, Kurian said: “We compete in that part of the market against frame arrays. It could be the Dell PowerMax or a large frame array from Hitachi [Vantara] or HPE.”
According to Kurian, QLC flash is being used in “the refresh or the migration of a very, very large 10K install base of hard drives, both ours as well as our competitors’, to that flash product portfolio … The total installed base of 10K drives is enormous. It was roughly, from a volume perspective, somewhere around 35 percent to 40 percent of the total storage market for a very long period of time. And so there’s a huge installed base to go refresh.”
Kurian noted strong performance in AI-led sales, saying: “While we believe the large opportunity for enterprise AI is still ahead of us, we are seeing good momentum today, with our AI business performing well ahead of our expectations. In Q1, we had over 50 AI and data lake modernization wins.”
He believes that NetApp is “in the early innings. It is when that inferencing trend, as well as large-scale generation of data come into play, that you’ll really see the inflection in data storage.”
“Inferencing is expected to be the preponderant majority of the storage market for AI and the enterprise AI landscape. It’s about 80 percent, maybe 90 percent of the total market. And RAG (retrieval-augmented generation) is expected to generate about 8x more data than the data that is fed into the RAG pipeline. So there’s a lot of new generation going to happen when and if these applications become mainstream.”
CFO Mike Berry commented about growth in general in the earnings call, saying: “Customers are prioritizing spend on strategic projects and so that part of our business continues to do really well … What we haven’t yet seen is large-scale datacenter refreshes, which would signal a broader base economic recovery and confidence in the business.”
He said customers want to use innovative AI tools in the public cloud, “where broader frameworks that combine databases, data warehouses, data lakes, together with AI models are progressing at a really rapid rate.”
But the necessary unstructured data sits in both on-premises storage as well as in the public cloud. “We are able to make that entire workflow much, much more secure and easy to manage, which is a part of the reason why we saw strength both in the data foundation for AI as well as in the cloud storage portfolio, where we’re seeing our ability to create a non-siloed, unified architecture come through for us.”
The public cloud portion of its revenues was $159 million, 3.2 percent higher than in the year-ago quarter. Kurian said: “Our highly differentiated first-party and hyperscaler marketplace storage services remain our focus and top priority. These services continue to grow rapidly, increasing roughly 40 percent year-over-year and performing ahead of our expectations at each of our hyperscaler partners.”
Berry said: “We expect cloud to return to a pattern of consistent growth through the rest of the year.”
Hybrid cloud revenues grew more strongly than public cloud, up 7.8 percent, to $1.38 billion. Flash arrays represented roughly 60 percent of NetApp’s hybrid cloud revenues. About 40 percent of NetApp’s installed base has adopted flash with the majority still using disk drives.
The Keystone storage-as-a-service offering experienced 60 percent year-on-year revenue growth.
Kurian thinks storage suppliers are doing better than broad systems vendors, saying: “The pure play storage players are outperforming the integrated system vendors. And so you look at a broad range of the integrated system vendors, they have struggled now for many quarters in their storage business, and it remains to be seen whether that is a strategic focus for them going forward.”
These are vendors, we understand, such as Hitachi Vantara, HPE, and IBM, but not Dell, with Kurian saying: “With GenAI, the two market players that have the installed base, Dell and us, are super well positioned.”
NetApp’s revenue outlook for the next quarter is $1.64 billion +/- $75 million and a 5 percent increase year-on-year at the midpoint; a lower increase than the current quarter’s 8 percent. Full year guidance is now $6.58 billion +/- $100 million, 4.9 percent up on fiscal 2024 revenues at the midpoint, and an increase from its previous $6.55 billion guidance last quarter.
EVP and CFO Mike Berry is retiring and a search is under way for his successor.
Startup QiStor claims it can accelerate storage engine key-value processing so much that two servers can do the work of 20, saving time, money, and reducing carbon emissions.
We were introduced to QiStor in February and have now learned more about its technology from CEO and co-founder Andy Tomlin, providing a clearer picture of its value proposition. It starts from the recognition that much database processing involves a software stack with a storage engine component.
OSS is Open Source Software
This piece of software talks across a network link, using a protocol like NVMe KV, to the storage drive hardware. But having applications talk through file systems to SSDs, which have Flash Translation Layers (FTLs) to map file storage IO requests to the drive’s block structure, is intrinsically inefficient. At heart, these layered constructs perform the allocation of space and the tracking of data locations on the drive. It’s simpler and more efficient to do this in one place through a key-value (KV) interface. Tomlin said: ”We’re doing it in hardware with full knowledge of how it’s actually working in the device.”
Andy Tomlin
QiStor is, in effect, replacing an SSD’s controller, or building an abstraction of a controller. Tomlin said: “I originally started the company to build a controller. But I abandoned that because just getting funding requires raising, ultimately, $100 million to build a controller, and no one was interested. So I figured out a cheap way to do this [and] we’re building an FPGA now.”
Tomlin says that key-value stores (KV stores) underlie NoSQL databases such as Aerospike, Amazon’s DynamoDB, Redis, Couchbase, LevelDB, and RocksDB. KV storage engine processing is computationally intensive and needs offloading from host server CPUs as it’s a waste of their resources and best handled by dedicated hardware.
Vector databases such as Milvus, Pinecone, and Vespa are used in large language model (LLM) processing for training and inferencing. Their operation can be accelerated by QiStor’s technology, reducing the necessary server infrastructure and speeding LLM responsiveness.
Tomlin says most large scale web applications today are built on key-value storage. He is firmly in the hardware acceleration and offload camp, strongly established by GPUs offloading graphics processing from x86 CPUs, and encompassing data processing units (DPUs) such as Intel’s IPU and Nvidia’s BlueField devices, smart NICs, and dedicated AI hardware. This kind of hardware acceleration is becoming mainstream.
He believes that hardware acceleration is needed for KV store software engines as well, and that relatively simple FPGAs can be used for this; Xilinx FPGAs, for example. Such FPGAs could be housed in database servers fitted in service provider datacenters, public clouds, or on-premises datacenters, and consumed through a Platform-as-a-Service (PaaS) facility.
Amazon EC2 F1 instances use FPGAs to enable delivery of custom hardware accelerations, and QiStor storage engine operations run on them as well as on Xilinx FPGAs.
QiStor is developing FPGA programs to provide functionality needed by the storage engine. The databases higher up the stack “talk” to the engine through existing access methods, Object-Relational-Mappers (ORMs) and libraries. It talks to the drive through a standards-based NVMe-KV interface. Tomlin says of the databases: “Most of the databases today already have plug-in storage engines … The idea is that the customer, the service, effectively, will run their databases, and they’ll just think they’re running on RocksDB as their back end.”
Tomlin says QiStor does not want to sell hardware. Other parties can do that, with QiStore producing the code that runs on or in it.
An initial task was to develop coding tools that can be used to write FPGA code, the hardware description language (HDL) describing the logic implemented on the FPGA. HDL code is converted by a synthesis tool into a netlist detailing the logic gates and interconnections needed on the FPGA, and this is converted into a bitstream, which is transferred to the FPGA. Now QiStor has developed its FPGA coding toolset, it can produce its code faster.
All this seems complex but it is more practicable and simpler than developing a storage engine-specific ASIC or other hardware, such as the Pliops XDP card.
Tomlin and QiStore are doing more than this. They are replacing an SSD’s block-based low-level structure with a KV storage system so that no traditional FTL is needed to map the KV data constructs to a target SSD’s block structure. He reckons this is inherently more efficient, with payoffs in eliminating FTL processing, simplifying garbage collection (recovery of deleted cells), and reducing memory requirements for SSD metadata. There is no need to use complex zoned infrastructure and the drives, with less write amplification, last longer.
Couple this with hardware acceleration and multiplicative performance advantages result.
A QiStor prototype demonstration ran with a 1 PB Aerospike database. When instantiated on x86 servers, this needed 20 x 60 TB servers, with 1,200 TB total capacity, delivering 753,000 write IOPS, and 3,017,000 read IOPS. The latency was 1 ms and the modeled three-year total cost of ownership (TCO) was $4.17 million.
This was set against just two servers with QiStor FPGAs and 1,000 TB of total capacity. They delivered 1.5 million write IOPS and 6 million read IOPS with a 250 μs latency. The modeled three-year TCO was less than $1 million.
Because fewer servers and SSDs were needed, the 58.2 kW of power needed for the pure x86 server setup was reduced to 5.8 kW for the pair of QiStor servers – a saving of 325 metric tons of CO2 per year.
It is becoming a truism that datacenters using GPU servers need lots of power, and the datacenter electricity budget left over for x86 servers, storage, networking, and cooling is much lower than in pre-GPU server days. This situation is likely to get worse. By lowering the amount of electricity needed to run petabyte-scale NoSQL databases ten times more efficiently, QiStor can make better use of that power budget.
Using QiStor technology can make NoSQL databases, including vector databases, run much faster on far fewer servers, saving cash, electricity, and carbon emissions. It’s the sort of technology customers, once they have adopted it, will see no going back. Many can’t wait to check out a beta test product.
Enterprise application lifecycle data manager and SAP data migration expert Syniti has been bought from its private equity owner by Paris-based Capgemini.
Capgemini, a global IT services business, with 340,000 staff in more than 50 countries, stated the acquisition “will augment the Group’s data-led solutions for clients across the globe, in particular large scale SAP transformations, such as the move to SAP S/4HANA.” Capgemini reported global revenues of €22.5 billion ($25.01 billion) in 2023 and is a vastly larger business than Syniti.
Aiman Ezzat
As we wrote in March “Syniti is a structured data lifecycle management supplier – with a focus on enterprise applications such as SAP and Salesforce – and not a file lifecycle management supplier.” It manages complex data quality, data migration and data governance initiatives for some of the world’s largest companies. The company’s Syniti Knowledge Platform is a cloud-based management platform and a SAP Endorsed App, sold as a SAP Solution Extension called SAP Advanced Data Migration & Management, by Syniti for 10 years or so.
The combination of generative AI and SAP expertise has made Syniti an attractive buy to Capgemini.
Aiman Ezzat, Capgemini CEO, said: “A strong data foundation is key to enable relevant, trusted and quality insights. It’s a top priority for clients as they look to unlock further value from their enterprise data thanks to generative AI.”
“Syniti and Capgemini share the philosophy that digital transformation will always require data transformation to drive critical business benefits.Syniti is a leader in its field and a trusted global partner for major SAP data migrations. Its global team will reinforce Capgemini’s data-driven digital core business transformation services.”
Kevin Campbell
Kevin Campbell, Syniti’s CEO, said: “Capgemini’s deep industry expertise and leadership in data & AI services highly complement Syniti’s data first approach in the market, to ensure that more organizations bring data to the forefront of their business and digital transformation projects.”
Bridge Growth Partners CEO Alok Singh said: “We are incredibly proud of the growth and development Syniti achieved. With the active support of our full team, including our highly experienced advisors, Syniti’s leadership team and employees transformed the company into a true market leader in data management that we believe will be an excellent strategic fit with Capgemini.”
Syniti, formerly known as BackOfficeAssociates, was started up in 1996, and raised $30 million from Goldman Sachs in a venture round in 2008. It was bought by private equity house Bridge Growth Partners in 2017 for an undisclosed amount.
Once bought by Bridge Growth Partners it stared expanding by acquisition to broaden its portfolio, buying HiT Software in 2010, and then Entota (2013), CompriseIT and Quadrate (2016), BackOffice Associates (2019), DataStewardshipPlatform (2019), Data Migration Resources, 360Science, Data Insiders and Sledgehammer all in 2021. Now it, with its more than 1,200 staff, has been bought again, and once more for an undisclosed amount.
The transaction is expected to close in the coming months, subject to regulatory approvals and other customary closing conditions.
Backup target system supplier ExaGrid now supports Commvault’s Metallic backup software.
ExaGrid supplies deduplicating backup appliances that have a direct-to-disk landing zone with post-ingress deduplication to a virtually air-gapped, non-network-facing tier of disk storage for long-term retention, with a Retention Time-Lock option. The landing zone provides fast backup ingest, quick restores, and instant VM recoveries. ExaGrid includes Commvault as a supported backup vendor and has done for nearly 15 years. Commvault’s Metallic is a SaaS backup application and it leads the cloud-native data protection market according to a GigaOm Sonar report. ExaGrid is providing support to Metallic users who want to back up data on-premises.
Bill Andrews, ExaGrid’s president and CEO, said in a statement: “ExaGrid has been a target for Commvault software for nearly 15 years. We are excited to offer even more value to Commvault users by expanding our support to Metallic as well.”
Incoming Metallic backup data can be deduplicated and compressed with an up to 5:1 data reduction ratio. ExaGrid applies its own deduplication on top of that and can achieve an up to 15:1 total data reduction ratio, three times more than Commvault alone. This increases the effective capacity of the ExaGrid system, lowering its cost/TB.
For flexibility, ExaGrid supports Commvault Metallic with dedupe on or off, compression on or off, and any combination of these options.
ExaGrid supports many other backup source systems, and protocols:
Acronis
Arcserve
Bacula
BridgeHead Healthcare Data Management
Dell EMC Networker
HPE Zerto
HYCU
IBM Spectrum Protect, IBMi/LaserVault
MicroFocus
Veeam Backup & Replication
Veeam backup to S3 object storage
Veritas BackupExec, NetBackup (NetBackup Accelerator, OST Integration, integration with NetBackup media server hardware, AIR (Auto Image Replication), GRT (granular level restore), optimized deduplication, and instant recovery)
ExaGrid also accepts backup data directly from applications such as IBM, IDERA, Microsoft SQL, Oracle (Dump and RMAN dump), and Redgate. It can be a target system for Linux/UNIX Direct Tar. Check out more source data sender details here.
Metallic supports a variety of other on-premises backup storage target systems, such as Dell PowerProtect and HPE StoreOnce plus on-premise S3 object storage systems like Cloudian HyperStore and Dell ECS and others.
The Acronis Threat Research Unit is sharing new insights regarding a misconfiguration in Microsoft Exchange Online settings that could result in email spoofing. Users who have a hybrid configuration of on-premises Exchange and Exchange Online that communicate via connectors, as well as those who use a third-party email security solution, could be vulnerable to misconfiguration exploitation. The details are as follows: In July 2023, Microsoft announced changes to its Domain-based Message Authentication, Reporting and Conformance (DMARC) policy. If a tenant recipient’s domain points to a third-party email security solution that sits in front of Microsoft 365, then Honor DMARC will not be applied. Honor DMARC will be applied if enhanced filtering for connectors is enabled. However, if it is misconfigured, Honor DMARC will be ignored. You can find the full report here.
…
Steven Campbell
Ceramic-based archive storage startup Cerabyte has hired Steven Campbell, a former CTO with Hitachi Global Storage Technology (HGST) and Western Digital, as its CTO. He will define the company’s technical vision, integrating evolving customer needs to execute a leadership roadmap. Cerabyte says that throughout his career, Campbell’s contributions have been pivotal in shaping data storage technology – including implementing shingled magnetic recording (SMR) and driving the development and launch of the first helium-filled hard drive. In addition to HGST and Western Digital, Steve was previously CEO of Singapore-listed Magnecomp International, Thai-listed Magnecomp Precision Technology, and InnoTek.
…
Object storage supplier Cloudian has won Fastweb – one of Italy’s main telecommunications operators with 3.3 million wireline and 3.6 million mobile customers – as a customer. Fastweb’s Cloudian deployment includes 3.4PB of capacity in two datacenters. Cloudian CMO Jon Toor tells us: “Telcos continue to be a major market for us worldwide. Cloudian’s first customer, way back when, was a telco in Japan, so it makes sense.”
…
Backup and data management supplier Cohesity has recorded 26 percent revenue growth for its latest fiscal year, according to CEO Sanjay Poonen talking to Bloomberg.
…
IT and security data engine startup Cribl has raised $319 million in a Series E round, bringing its total capital raised to over $600 million and increasing its valuation by 40 percent to $3.5 billion. The funding round is led by new investor Google Ventures, with participation from GIC, Capital G, IVP, and CRV. This is one of Google Ventures’ largest investments to date and marks the first by general partner Michael McBride, who will also join Cribl’s board of directors where he will work closely with CEO Clint Sharp to help steer the business toward IPO. Cribl has doubled its annual recurring revenue (ARR) year-over-year and had over 140 percent net dollar retention (NDR) growth over the past 12 months.
Cribl has seen triple-digit customer growth for five straight years and a quarter of Fortune 500 companies are Cribl customers. Last year, Cribl surpassed $100 million in ARR, becoming the fourth-fastest infrastructure company to reach centaur status, following Wiz (1.5 years), HashiCorp (three years), and Snowflake (3.5 years). Recently, Cribl appeared on the Forbes Cloud 100 list (second consecutive year), Fortune Cyber60, Inc. 5000’s Fastest Growing Private Companies, CRN Security 100, and more. With more than 700 employees worldwide, Cribl is actively broadening its business footprint, with a presence in the US, Europe, and Australia.
…
Joseph George
Supercomputer and enterprise storage supplier DDN says Joseph George has joined the DDN team as field CTO and VP for Strategic Alliances. He was previously VP for strategic alliances at HPE, and with Cray until September 2018.
…
Dell says its PowerScale OneFS v9.9 OS adds support for 61TB QLC SSDs and 200 GbE networking support for both front-end and back-end fabrics. The front-end fabric provides 200GbE connectivity between clients and the PowerScale cluster enables seamless ingestion of massive datasets, ensuring your GPUs never go hungry for information. Back-end fabric 200 GbE interconnects between storage nodes, meaning the PowerScale cluster itself becomes a high-speed data highway, ensuring rapid communication and efficient data distribution. Support will initially be for the Nvidia CX-6 VPI 200 GbE network card.
Dell says the AI market is rapidly evolving, and the infrastructure supporting it must evolve as well. 200 GbE Ethernet is proving to be a critical technology for enabling the next generation of AI applications. Its speed, scalability, and low latency make it the perfect match for the demanding requirements of AI workloads. It may well support 400 GbE and 800 GbE speeds in the future.
…
Gartner gurus have predicted that 75 percent of enterprises will prioritize SaaS app backup as a critical requirement by 2028, compared to 15 percent in 2024, due to the increasing risk of IT outages. Worldwide end-user SaaS spending is projected to grow by 20 percent, totaling $247.2 billion in 2024 and forecast to reach nearly $300 billion in 2025. Michael Hoeck, senior director analyst at Gartner, said: “Given the vulnerability of SaaS data to errors, cyber attacks, and vendor mishaps, robust backup solutions are indispensable. Integrating backup as a service (BaaS) is essential for safeguarding cloud workloads and maintaining operational continuity.”
The SaaS application backup market is rapidly growing, initially led by specialized startups, but now also includes established enterprise backup and recovery software solutions companies. Users should use third-party SaaS backup solutions to complement the native capabilities of SaaS vendors. By 2028, 75 percent of large organizations will adopt BaaS alongside on-premises tools to back up cloud and on-premises workloads. Gartner clients can read more in “Top Trends in Enterprise Backup and Recovery for 2024.“
…
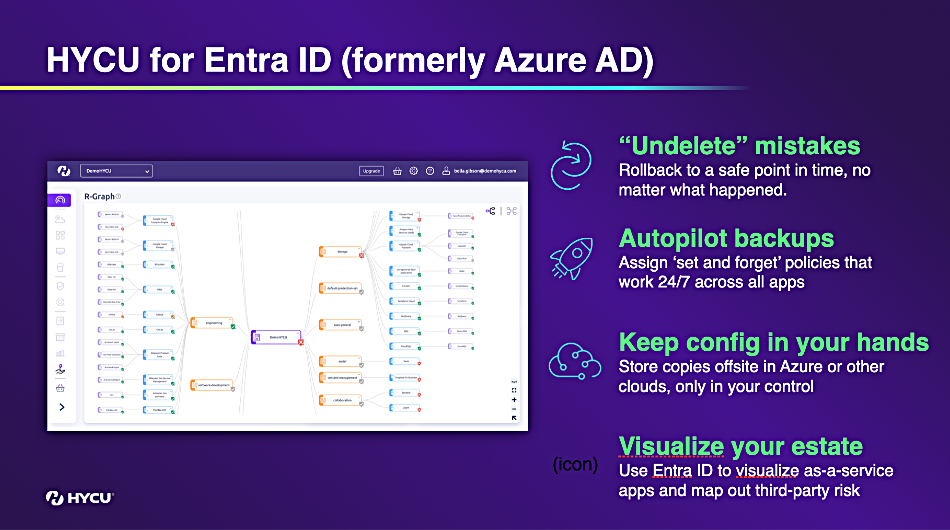
On-prem and SaaS backup supplier HYCU now supports Microsoft’s Azure AD replacement Entra ID within its R-Cloud platform. This latest SaaS integration brings the total number of HYCU supported applications and cloud services to more than 80. HYCU says Entra ID is the cornerstone of identity management for millions of organizations worldwide. With over 610 million monthly active users as of 2023 – including approximately 400 million from Microsoft tenants and 210 million from non-Microsoft workloads. HYCU for Microsoft Entra ID is available immediately in the HYCU Marketplace.
R-Cloud’s Entra ID support includes:
One-click restore of configurations, from individual items to the entire Microsoft Entra ID tenant ;
Autopilot backups with “backup assurance,” providing 24/7 protection with complete logging and notifications;
Ransomware-proof copies stored in customer-controlled, immutable cloud storage;
Instant visualization of the entire data estate, exposing unprotected applications and third-party risks;
Unified protection and recovery across Microsoft Entra ID and Okta (Workforce Identity Cloud and Customer Identity Cloud) along with AWS IAM;
Additional protection and restore of Amazon Virtual Private Cloud (VPC), Amazon Route 53, AWS Web Application Firewall (WAF), AWS Parameter Store, Amazon Key Management Services (KMS).
…
Cloud file services supplier Nasuni has announced rapid growth in the media and advertising industry, claiming a 121 percent increase in data under management over the last 24 months. Leading media companies are actively looking to implement GenAI into production processes such as 9Rooftops Marketing, Centaur Media, TBWA, Omnicom, and Crain Communications.
…
Data protector N2WS has named Jay Iparraguirre as global VP of sales and Nir Veledniger as head of customer success. These appointments come on the heels of hiring Alon Maimoni as CRO in March 2024. N2WS’s statement refers to its transformation to maximize the value of the N2WS platform and drive revenue growth by reshaping the company’s customer success, go-to-market strategy, and channel business. Iparraguirre will help move the company’s sales strategy from a reactive to a proactive approach, with an increased emphasis on outbound sales and channel partnerships. As head of customer success, Veledniger will focus on implementing robust onboarding processes and educational initiatives to ensure customers maximize product value.
From left, Alon Maimoni, Jay Iparraguirre, and Nir Veledniger
…
GPU supplier Nvidia announced its NIM Agent Blueprints catalog of pretrained, customizable AI workflows. NIM Agent Blueprints provide a jump-start for developers creating AI applications that use one or more AI agents. They include sample applications built with Nvidia NeMo, Nvidia NIM and partner microservices, reference code, customization documentation, and a Helm chart for deployment. The first NIM Agent Blueprints now available include a digital human workflow for customer service, a generative virtual screening workflow for computer-aided drug discovery, and a multimodal PDF data extraction workflow for enterprise retrieval-augmented generation (RAG) that can use vast quantities of business data for more accurate responses. NIM Agent Blueprints are free for developers to experience and download and can be deployed in production with the Nvidia AI Enterprise software platform.
…
Korea’s Chosun Daily reports that SK hynix is gradually increasing wafer input at its M15 production line in Cheongju, with the goal of boosting monthly wafer output by approximately ten percent early next year. Subsidiary Solidigm, facing strong SSD demand, turned a profit in the second quarter and plans to increase production by around five percent starting early next year. Solidigm leads the market with its 60TB QLC enterprise SSDs. SK hynix plans to release 128TB SSDs in early 2025.
…
Virtualized datacenter supplier VergeIO closed one of its most successful quarters ever with record sales, a full pipeline, partner wins, and an expanding presence in Europe, Asia, and Latin America. It set a record for new customers that was 50 percent higher than any prior quarter, and twice what were closed in the first quarter – due in no small part to organizations seeking alternatives to VMware. Sales were also four times the second quarter of 2023. The biz saw a fivefold increase in its sales pipeline including double-digit large enterprise prospects, and incoming interest from more than 6,000 potential new customers. Ten new reseller partners signed on during the quarter, and 80 percent of enrolled partners brought in new business opportunities. Outside the US, VergeIO now boasts active resellers in Canada, England, and elsewhere in Europe, Asia, and South America. New customers have signed on from Liechtenstein, Australia, Indonesia, Taiwan, England, and Canada.
…
Western Digital’s PCIe 5.0 DC SN861 enterprise SSD uses a controller from South Korean company Fadu, according to an Anand Tech teardown.
…
Western Digital is investing ฿23.5 billion ($693 million) to expand its HDD manufacturing capacity in Thailand. It is likely to generate an additional ฿200 billion ($5.897 billion) per year in exports. WD’s disk drive ASP is $163 so the export uplift implies the manufacturer is building an extra 36.18 million HDDs a year. In its latest quarter, WD manufactured 12.1 million drives – meaning 36 million a year. The Thailand investment will thus increase its HDD manufacturing capacity by ten percent.
A joint venture between Rubrik and MSP Assured Data Protection is taking managed Rubrik data protection and security services to prospective customers in Latin America.
Simon Chappell
Assured Data Protection (ADP) is Rubrik’s largest global managed services supplier. It has main offices in both the UK and US, and operates 24/7 in more than 40 countries where it has deployments. It has datacenter infrastructure in six worldwide locations.
ADP has expanded operations into Latin America, including the joint venture establishing Rubrik’s presence in the region through Assured’s 24/7/365 managed service. It reckons enterprises of all sizes across the continent will benefit from a more flexible approach to Rubrik deployment and be able to “rapidly recover” from cyberattacks, including ransomware.
Ghazal Asif Farhadi, Rubrik’s VP for Global Channels & Alliances, stated: “Rubrik is proud to support Assured’s new expansion into Latin America. Organizations need to enable cyber resilience in the face of the increasing cyber threat landscape and there is no better way for Latin American companies to do that than working with Rubrik and Assured.”
Ghazal Asif Farhadi
ADP has set up operations in markets such as Mexico, Peru, Costa Rica, Chile, and Colombia, with customers including Niubiz, América TV, Ferromex, Farmacias Roma, and others.
Fiorella Minaya Rey, ADP’s Latin America Channel Account Manager and a former Rubrik LATAM sales rep, stated: “To ensure that enterprises of all sizes can take advantage of Rubrik, there will be no limitations on the amount of data that customers can secure – it can be as small or as large as required.”
ADP is launching a regional Center of Excellence located in Costa Rica, staffed by engineers, and has hired Spanish-speaking technical, sales, and client services staff across the region to provide 24/7 support in all countries, across sectors including manufacturing, banking, education, and others.
Fiorella Minaya Rey
Simon Chappell, ADP CEO, said: “Our launch into Latin America is another important step forward in our ambitious growth plans for 2024 and beyond … Our new Center of Excellence is a strategic move to help build on our best-of-breed customer service for customers and will see all of our customers across the globe benefit from its expertise.”
ADP’s Costa Rica Center of Excellence will operate with a mix of human technical skills and automation, and many threats will be negated before customers are aware of them. This model and approach to cyber resiliency will be deployed by ADP as it expands into other regions, beyond Latin America, North America, and Europe.
The company launched its first Canadian datacenter in April.