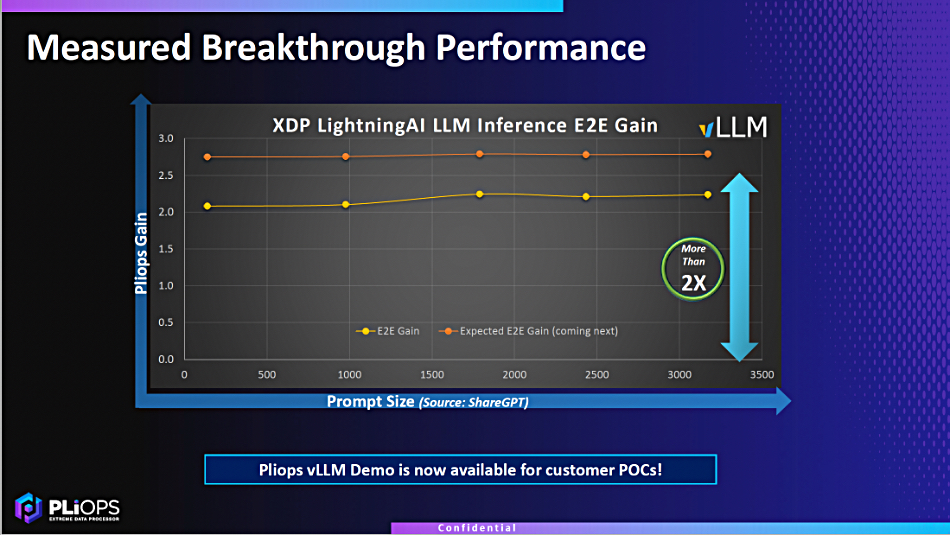
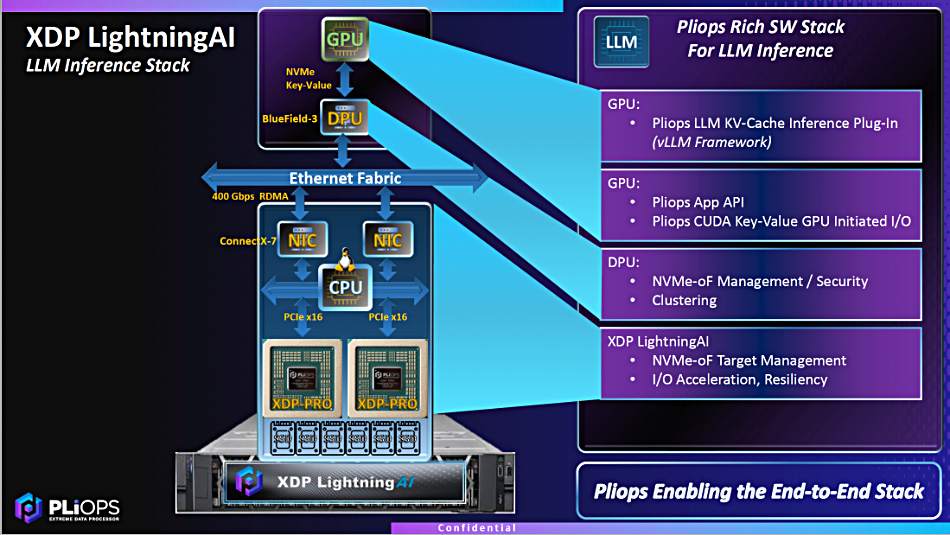
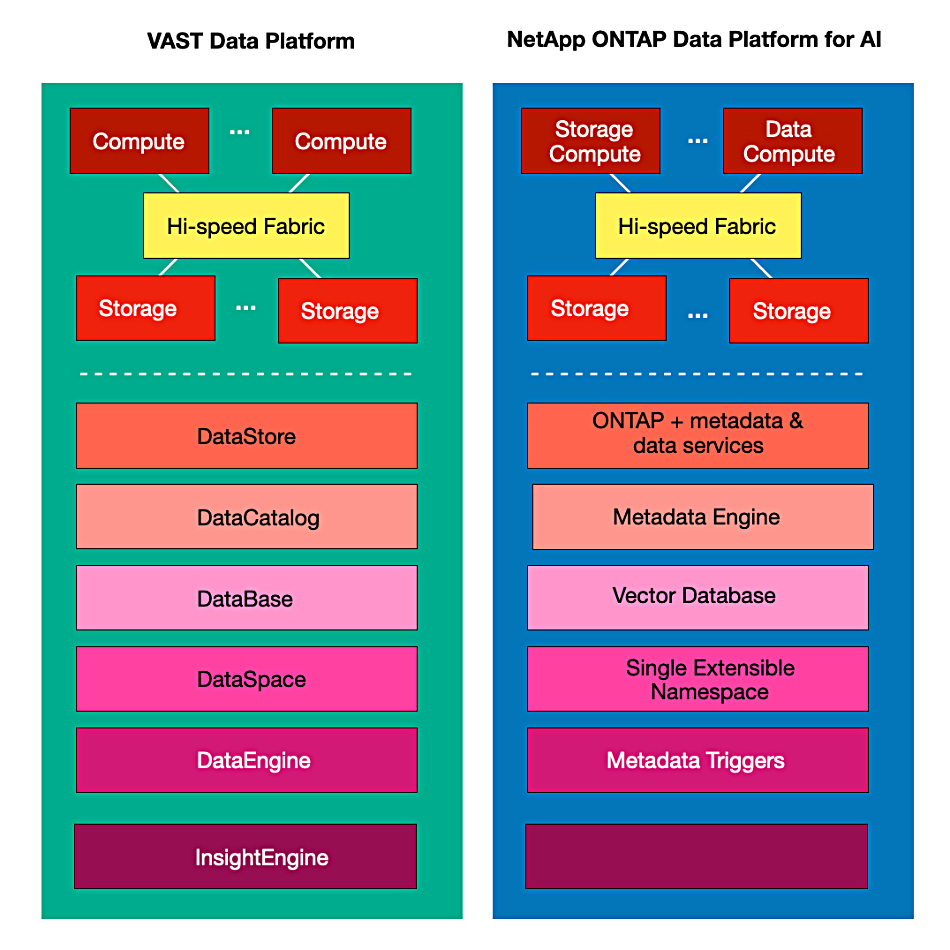
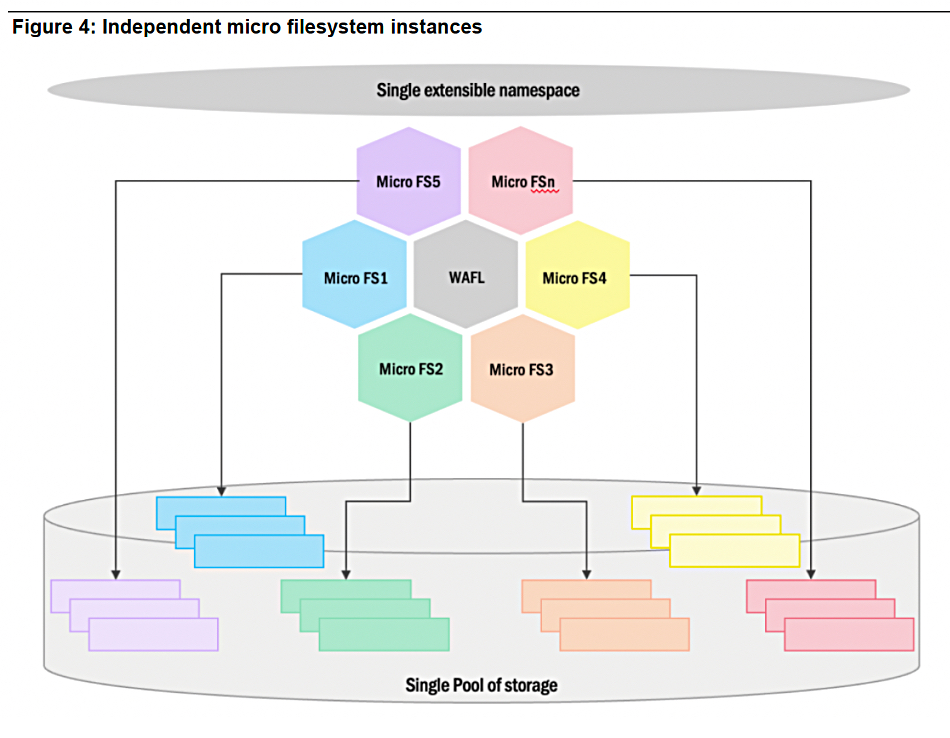
Database provider MongoDB has launched the latest version of its document-based system, claiming it can be at the center of moves toward commercial AI deployments.
Competing against traditional relational database heavyweights like Oracle and IBM, MongoDB sells both an on-premises version of its database and a cloud version, called Atlas, which is sold through the AWS, Azure, and Google Cloud.
MongoDB 8.0 is now generally available and comes with various data management and throughput improvements.
Architectural optimizations in 8.0 have significantly reduced memory usage and query times, and it has more efficient batch processing capabilities than previous versions. Specifically, 8.0 promises 32 percent better throughput, 56 percent faster bulk writes, and 20 percent faster concurrent writes during data replication.
In addition, 8.0 can handle higher volumes of time series data, and can perform complex aggregations more than 200 percent faster, with lower resource usage and costs, according to MongoDB.
Horizontal scaling is also “faster and easier than ever.” Horizontal scaling allows applications to scale beyond the limits of traditional databases by splitting data across multiple servers (sharding), without pre-provisioning additional compute resources for a single server. Sharding improvements in MongoDB 8.0 distribute data across shards “up to 50 times faster,” without the need for additional configuration or setup.
As part of the global launch of the improved database, a reveal in London took place at one of the company’s regular local events for customers, partners, and developers, which Blocks & Files attended. At the moment, MongoDB is believed to only hold about 2 percent of the total global database market by sales, although most analysts put it in the top five providers when it comes to developer use.
We wanted to know how the company intended to scale up through wider cloud use and, of course, as a result of wider AI-driven workloads. The business was notably upbeat. In fact, it has established a whole unit around commercial AI deployments in industry verticals, and claims it’s winning.

Greg Maxson, senior director of AI GTM (go-to-market), said businesses were being tested by the rapid marketing cycle of AI, uncertainty about which AI language models to use and which technology stacks to implement, and a lack of skills and resources to do it.
“Two months ago we established our MongoDB AI Application Program (MAAP), and have listed the seven general stack technologies that customers must start with, when it comes to AI projects. It’s foundational stuff, but we are already winning key customers around it on the services side.”
Maxson said a “large automotive company in France” wanted to better use its mechanical data, including video clips and manuals, to find out what the faults were in its cars when they were returned to dealers. “We came up with 20 AI models they could test to find the right solution, and now one of them is being used with MongoDB at dealerships across France,” said Maxson.
He claimed another firm – a “global household appliance manufacturer” – came to MongoDB because it wanted to integrate digital sound analysis from its products, including vacuum cleaners, into its manufacturing and quality control systems using AI. The chosen MongoDB system is now being used.
“We’ve brought all three main cloud providers into this process, and global system integrator Accenture is also involved, and we are aiming to set industry vertical standards to make AI projects work.”
The AI hype cycle is huge when it comes to data processing, data management, and data storage. But to make AI work across these areas, there has to be focus to enable delivery. Establishing an AI GTM unit at product and service providers is likely a solid first step in guiding potential AI customers through confusion.
Bootnote
MongoDB was initially called 10gen but wanted to indicate the product created in 2007, now called MongoDB, could scale to handle massive amounts of data – hence the name change.