Promo WekaIO co-founder and CEO Liran Zvibel thinks enterprise data storage buyers should be aware of six traps lying in wait when contemplating legacy solutions.
Liran says the pitfalls are:
Proprietary hardware,
Software chasm between the on-premises and public cloud worlds,
Separate silos for different workloads,
Hobbled GPU hardware,
Additional data protection requirement,
Multi-product integration instead of consolidation around one.
He explained his reasoning to me in a recent webcast which is now available on demand. Register and decide for yourself if this data management supplier with its fast filesystem has a good case for saying legacy storage should be heading for the scrapyard.
A new memory hierarchy is emerging, as two recent developments show. In no particular order, Micron walked away from 3D XPoint and SK hynix revealed new categories and of memory product in a hierarchy of access speed. In both cases the Compute Exchange Link (CXL) is envisioned as the glue that links shared memory and processing devices such as CPUs, GPUs, and app-specific accelerators.
Moore’s Law end game
As Moore’s Law speed improvements come to an end, new techniques are being developed to sidestep bottlenecks arising from the traditional Von Neumann computer architecture. ‘Von Neumann’ describes a system with a general purpose CPU, memory, external storage and IO mechanisms. Data processing demands are increasing constantly but simply putting more transistors in a chip is no longer enough to drive CPU, memory, and storage speed and capacity improvements.
A post-Von Neumann CXL-linked future is being invented before our eyes and it is going to be more complicated than today’s servers as system designers strive to get around the Moore’s Law end game limitations.
Computer architects are devising ways to defeat CPU-memory and memory-storage bottlenecks. Innovations include storage-class memory, developing app-specific processors and new processor-memory-storage interconnects such as CXL, for faster IO. This should enable more powerful, more power-efficient processing systems to run a deluge of AI and machine learning-related applications.
CXL is a big deal, as the in-memory compute supplier MemVerge told us recently: “The new interconnect will be be deployed within the next two years at the heart of a new Big Memory fabric consisting of different processors (CPUs, GPUs, DPUs) sharing heterogenous memory (DRAM, PMEM, and emerging memory).”
MemVerge’s Big Memory technology uses in-memory computing, with memory capacity boosted by Optane storage-class memory to reduce storage IO and so speed applications such as gene sequencing.
Memory developments
The commodity server has a relatively simple design, with CPUs accessing DRAM via socket connections with storage devices sending and receiving data from the CPU-DRAM complex via the PCIe bus. A few years ago, 3D XPoint-based storage-class memory (SCM) arrived on the scene to address DRAM capacity limitations and speed storage-memory IO.
Intel has implemented the technology as Optane SSDS which use the PCIe bus and also as Optane Persistent Memory (PMem), which come in DIMMs and connect to the CPU via sockets. Optane PMem is addressed as memory, with software coping with its slower access latency of about 300ns compared to faster DRAM with a 14ns or so access latency.
In explaining its decision to stop 3D Xpoint development and manufacture, Micron argued that there will be insufficient demand for 3D XPoint chips in the future because memory capacity and speed limitations will addressed by two technologies: High Bandwidth Memory (HBM) and CXL fabrics.
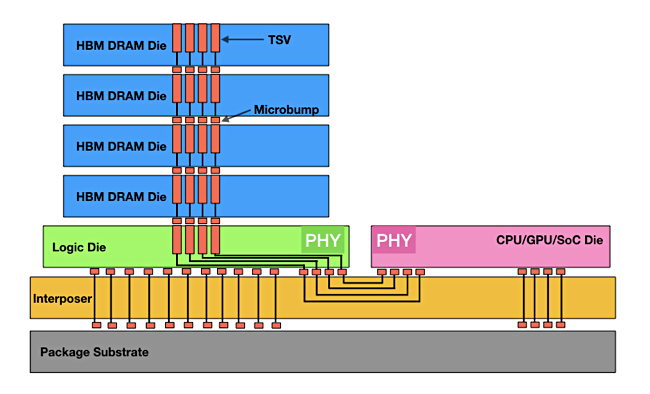
High-Bandwidth Memory diagram.
HBM has a faster connection to CPUs than the existing socket-based scheme. This is based on a single SoC design with stacked memory dies sitting on top of an interposer layer that extends sideways to link to a processor. The arrangement provides a lower latency and greater bandwidth connection than the DRAM socket-based scheme. Nvidia GPU servers are using HBM to help them process data faster. Micron’ and SK Hynix both think HBM is slso coming to X86 servers.
Micron and SK hynix see a basic three-layer memory hierarchy running from HBM though DRAM to SCM. SK hynix thinks HBM can also improve energy efficiency by about 40 per cent in terms of power consumption.
CXL enables memory pooling
TheCompute Express Link (CXL) is being developed to supersede the PCIe bus and is envisaged by its developers as making pools of memory (DRAM + SCM) sharable between CPUs and also GPUs; but not HBM.
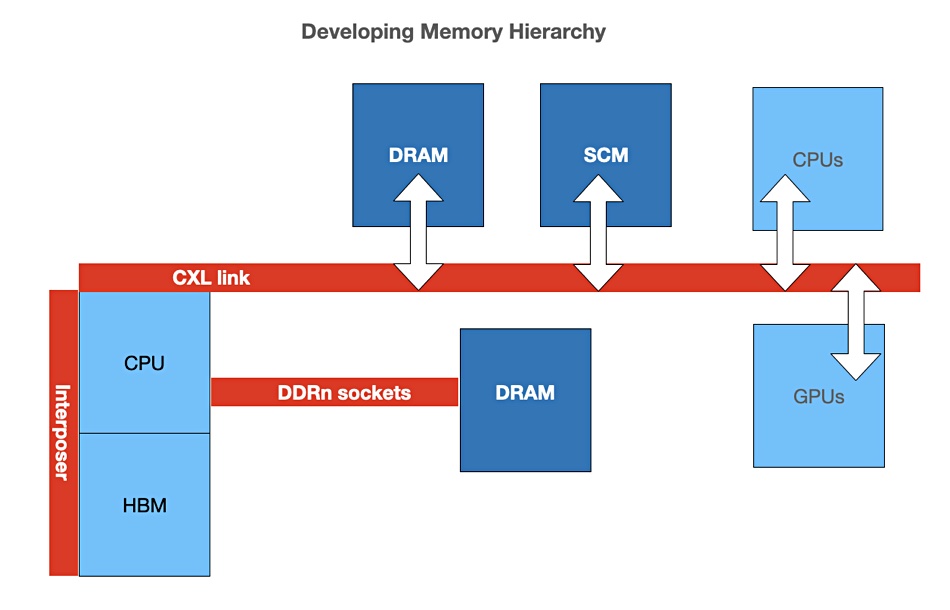
Blocks & Files diagram.
This would mean that individual servers can augment their own local socket-connected DRAM with pools of memory accessed across the CXL bus. These pools could contain DRAM and SCM – but likely not HBM.
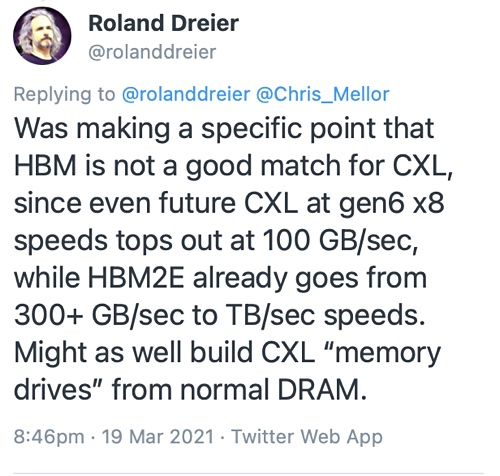
Roland Dreier, a senior staff engineer at Google, has tweeted that “HBM is not a good match for CXL, since even future CXL at gen6 x8 speeds tops out at 100 GB/sec, while HBM2E already goes from 300+ GB/sec to TB/sec speeds.” He suggests the industry could “build CXL “memory drives” from normal DRAM.”
Dreier says: “You could imagine a future memory hierarchy where CPUs have HBM in-package and another tier of CXL-attached RAM, and DDR buses go away. (Intel is already talking about Sapphire Rapids SKUs with HBM, although obviously they still have DDR5 channels.)”
He also sees scope for 3D XPoint with CXL: “a 3DXP drive with a 50 GB/sec low-latency byte-addressable CXL.mem interface seems like a killer product that gives new capabilities without forcing awkward compromises.”
HBM brings compute and memory closer together and so reduces data transmission time between them. But SK hynix foresees even closer links that will reduce data transmission delays even further.
Bring processing and memory closer still
SK hynix CEO Seok-Hee Lee discussed four more kinds of memory, in a presentation this week at the Institute of Electrical and Electronics Engineers (IEEE) International Reliability Physics Symposium (IRPS). The first was Ultra-low Power Memory (ULM) that much less power than DRAM and HBM. The second was a set of memories which are closer to the CPU and, faster to access, than HBM:
PNM – Processing Near Memory with CPU and memory in a single module,
PIM – Processing In Memory with CPU and memory in a single package; faster than PNM,
COM – faster still Computing In Memory with CPU and memory integrated in a single die.
Lee implied that PNM would come first, then PIM which would be followed by COM. Ultimately Lee sees memory technology evolving towards neuromorphic semiconductors which imitate the structure of a human cranial nerve, and possibly DNA semiconductors.
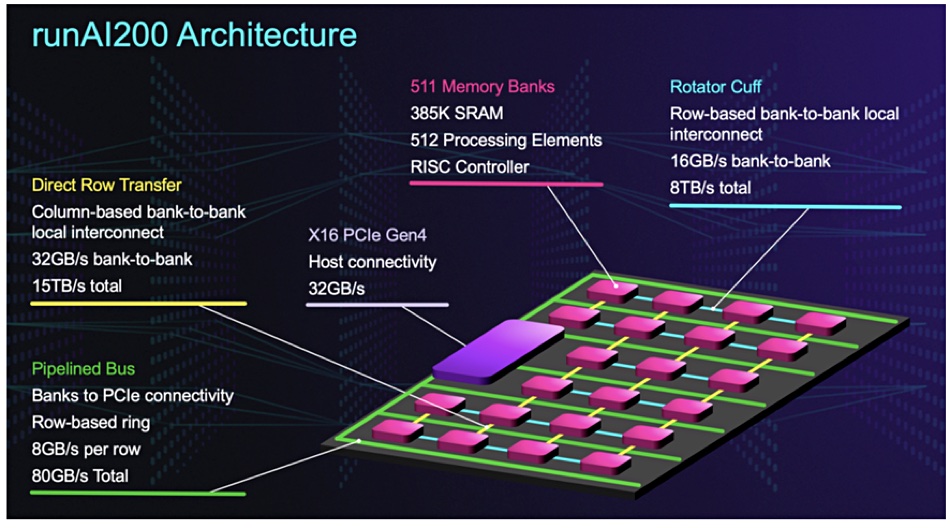
An implementation of PIM is under development by AI chip startup Untether AI, whose TsunAImi PCIe card uses runA1200 chips with processing events distributed throughout SRAM memory.
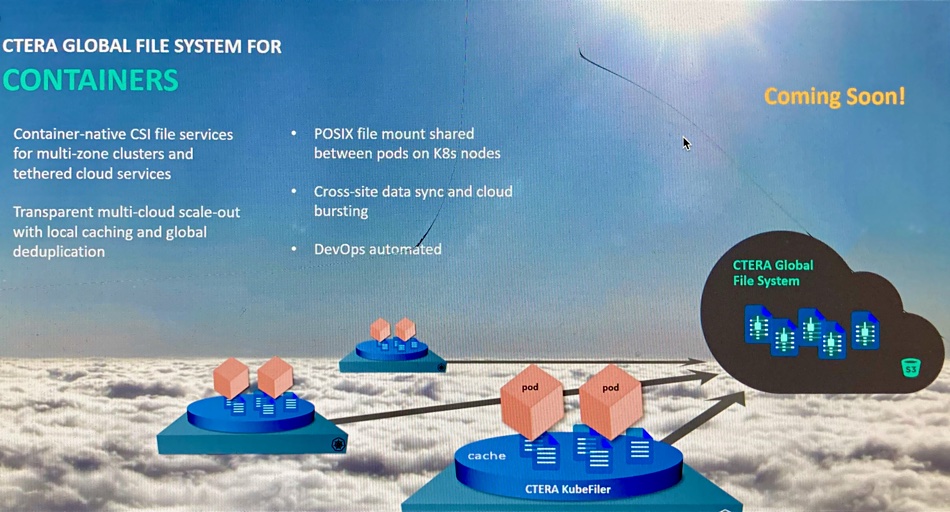
CTERA plans to deliver a global file system for containers. ‘KubeFiler’ will provide container-native file services and act as a shared file resource for Pods in a Kubernetes cluster, CEO Liran Eshel told a press briefing yesterday “We’re finalising it to provision file services in a Kubernetes environment.”
CTERA provides file-based unstructured data management services using local cache systems or edge filers, connected to a central object store. It will release a version of its filesystem software providing file services to Kubernetes-orchestrated containers from local caches connected to its public-cloud-based global filesystem.
KubeFiler uses the Container Storage Interface (CSI) to provision file facilities to application containers. It functions effectively as a CTERA edge filer, providing a cache copy of global file system data stored in the public clouds. KubeFiler is a Posix mount point for Pods on Kubernetes cluster nodes.
The software will provide file data synchronisation cross customers sites and support bursting workloads to the public cloud.
CTO Aron Brand said CTERA is also re-architecting its software to be cloud-native, and turning it into micro-services – ‘This is a long-term process.” He was asked if adoption of Kubernetes by filesystem suppliers, such as NetApp with Astra, will level the competitive playing field. “Containers don’t change the competitive situation,” he replied. “Suppliers will serve different use cases and have their differing strengths.”
Nasuni, a competitor to CTERA, has hinted strongly that it will provide cloud-native file services. Blocks & Files anticipates that Pure Storage will also provide file services to containers through its Portworx acquisition.
A Canadian startup called Untether AI has built tsunAImi, a PCIe card containing four runA1200 chips which combine memory and distributed compute in a single die. We think the technology is representative of an emerging landscape in which general purpose CPUs are giving way to augmentation by specific application processors, most notably by GPUs. Let’s take a closer look.
Untether claims that in current general purpose CPU architectures, 90 per cent of the energy for AI workloads is consumed by data movement, transferring the weights and activations between external memory, on-chip caches, and finally to the computing element itself.
Untether goes further than the GPU approach by spreading app-specific AI processors throughout a memory array in its runA1200 chips.
The runA1200 chip co-locates compute and memory to accelerate AI processing by minimising data movement. Untether says the tsunAImi card delivers over 80,000 frames per second of ResNet-50 v 1.5 throughput at a batch=1 level, three times the throughput of its nearest competitor. Analyst Linley Gwennap says Untether’s “PCIe card far outperforms a single Nvidia A100 GPU at about the same power rating (400W).”
Each unA1200 chip contains 511 memory banks, with the individual bank comprising 385KB of SRAM and a 2D array of 512 processing elements (PEs). Each bank is controlled by a RISC CPU. There are 261,632 PEs in total per runA1200 chip with 200MB of memory, and the chip runs at 502 TeraOperations/sec TOPS or trillion operations per second).
The PEs operate on integer datatypes. Each PE connects to 752 bytes of SRAM such that the memory and the compute unit have the same physical width, minimising wasted die area. The PEs can execute multiply-accumulate operations and also multiplication, addition and subtraction.
The Untether TsunAImi PCIe card generates more than twice as many trillion operations per second (TOPS) as other accelerators.
Untether envisages its tsunAImi card being used to accelerate various AI workloads, such as vision-based convolutional networks, attention networks for natural language processing and time-series analysis for financial applications.
The Untether card distributes tiny PEs throughout the SRAM, compute being moved to the data, and these PEs are not general purpose CPUs. They are designed to accelerate specific classes of AI processing. We can envisage a purpose-built AI system with a host CPU controlling things and data loaded into the tsunAImi cards across the PCIe bus for relatively instant processing with very little extra data movement needed to get the data into the PEs.
Untether is shipping TsunAImi card samples and hopes for general availability in April-June.
Blocks & Files positions the runA1200 card as a PIM device – Processing In Memory with CPU and memory in a single package.
We envisage tsunAImi cards eventually being hooked to a Compute Express Link (CXL), which supports PCIe Gen 5, and so provide a shared resource pool of accelerated AI processing.
IBM COS File Access, launched last November, is a rebranded version of CTERA file system, CTERA CEO Liran Eshel revealed today. “IBM is one of the top vendors of private object storage. This could give very good access to our technology to Fortune 2000 customers,” he said in a press briefing.
IBM has a similar OEM deal already in place with Panzura, a CTERA rival, and we have not clarified if the new deal with CTERA changes that relationship.
This OEM deal builds on an earlier arrangement with CTERA’s file system integration with IBM Cloud Object Storage (COS).
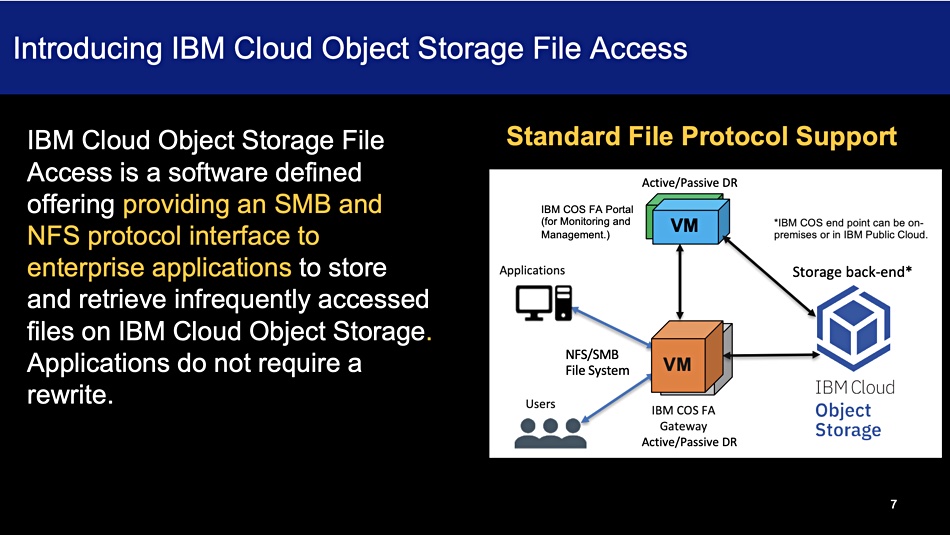
IBM’s COS File Access (COSFA) is gateway software that provides SMB and NFS access to legacy applications, and stores and retrieves files on IBM’s Cloud Object Storage. The target use case is active archiving. The software is deployed on-premises as a virtual machine, and the back-end COS bucket endpoint can be on-premises or in IBM’s Public Cloud.
COSFA enables the consolidation of archive, backup and other infrequently accessed files onto IBM COS, freeing up capacity on primary storage such as tier-1 filers. The SMB and NFS archive data in COS is stored with high-availability and ready for disaster recovery.
Eshel today also said that HPE is making CTERA services available through the GreenLake subscription service. This deal builds on CTERA’s existing integration with the Nimble dHCI and SimpliVity HCI products.
Micron’s 3D XPoint withdrawal last week prompted much debate about the implications for Intel, the future of storage-class memory, the prospects for CXL, and the direction of Micron’s product plans.
I sat down – virtually – with Brian Beeler, Storage Review editor and founder, to discuss these topics on his video podcast. The show is is now available on YouTube.
Storage Review/Blocks & Files video podcast screen grab.
Some of the points we considered were:
Is there a real Storage Class Memory market? Any SCM that is slower or faster than DRAM will need software accommodations and an interface to processors (CPU, GPU, FGPA.)
Will PCIe 4 speed reduce need for SCM, because storage (SSD) access speed will increase?
Will High Bandwidth Memory reduce the need for SCM?
The Jim Handy view that Optane SSDs are a niche
If Intel doesn’t buy Micron’s Lehi fab then that indicates it sees no need for Lehi’s XPoint build capacity in the next few years?
Will Intel add a Compute Express Link interface to Optane Persistent Memory? This could enable AMD and Arm processors to use Optane.
Micron intends to compete with Optane PMem in the future with its new SCM products which use 3D XPoint learnings and knowledge
Micron does not need the Lehi fab to build its new SCM products – otherwise it wouldn’t sell it.
It was a free-flowing wide-ranging discussion with few holds barred. Brian and I hope you enjoy it.
Model9, a storage startup, is parlaying its software that replaces mainframe tape backup into a cloud data services gateway. The company has a big ambition – namely to replace virtual tape libraries (VTLs) in mainframe installations and enable cloud data services for mainframe users. Let’s take a closer look.
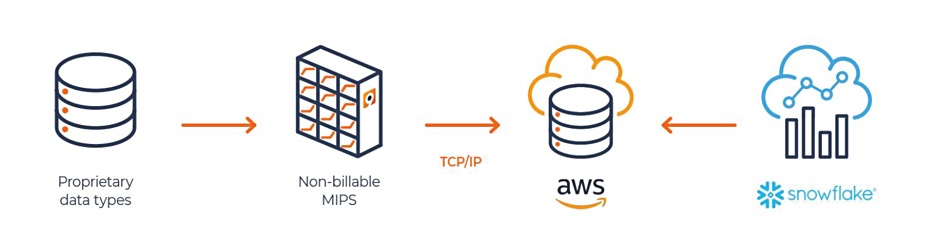
Nearly all mainframe customers use tape-based backup, either to actual tape libraries or to disk-based VTLs. Model9’s software runs on a IBM mainframe and backs up data to networked object storage – either an on-premises object store using the S3 protocol or to the AWS S3 or Azure Blob storage repositories.
Model9 provides backup, restore, archive/migrate, and automatic recall for mainframe data sets, volume types and z/OS UNIX files, plus space management, stand-alone restore, and disaster recovery. It supports AWS S3, Glacier, EBS (Elastic Block Store) and EFS (Elastic File System) with a Model9 Management and Proxy server running in AWS and a lightweight agent running in z/OS.
In 2019, the product was branded Cloud Data Gateway for z/OS – reflecting its function as a mainframe backup and database image copy data mover to the cloud. Last year the company changed the product’s name to Cloud Data Manager for Mainframe (CDMM), in order to plant the idea that the data could be used in business intelligence and analytics routines once it had been moved to the cloud. The neat thing was that such processing could return faster results than analysing the mainframe data on premises, according to CEO Gil Peleg.
In a press briefing this week, he claimed: “IBM doesn’t offer a mainframe compute service in the cloud,” so mainframe users have no easy way in the IBM environment for moving mainframe data and workloads to the public cloud. This is Model9’s big market opportunity.
The worldwide mainframe market comprises maybe 5,000 customers, mostly very large enterprises, that run mission-critical applications on their expensive big iron. Their data footprint is growing. Of course these customers also have X86 servers and can run business intelligence or data warehouse routines to analyse the data on those servers. Alternatively, they can send mainframe data to the cloud for analysis. But this is costly.
Model9 software sends mainframe data to the cloud for analysis.
Mainframe backup to tape is a serial process whereas Model9 backup to the cloud or on-premises object stores is a parallel process.
Also, mainframe data has to pass through an Extract, Transform and Load (ETL) process to be converted into a form analytics routines on connected servers could use, Peleg said. The ETL processing consumes chargeable mainframe processor cycles (MSUs or Million Server Units) as do the FTP routines to ship the transformed data across network links to the analytic servers. Customer software monthly license charges are also increased.
Model9’s application uses a non-billable zIIP (z Systems Integrated Information Processor) and so doesn’t consume chargeable MSUs. That makes it cheaper to run. The software ships the data across TCP links to on-premises object stores or to the public cloud, and data delivery can be scheduled at a desired frequency – every 30 minutes, for example – to analyse up-to-date data.
The backup data can be put into S3 Object Lock stores for immutability, in order to provide equivalent ransomware protection to mainframe air-gapped tapes.
Model9 has built Data Transformation Service in AWS to convert the backed up mainframe data from its native format into CSV or JSON files which can then be used by Amazon Athena, Aurora, RedShift, Snowflake, Databricks and Splunk. Peleg said: “This is a strategic direction for us.”
The company has also extended the features of its mainframe software so that data transfer to the cloud is improved and mainframe users can operate the in-cloud processes directly. Here is a list of recent updates.
March 2020 – CDMM v1.5 – supported transferring tape data directly to the cloud with no need for interim disk storage.
September 2020 – CDMM v1.6 – perform on-demand data set level archiving operations directly from the mainframe to any cloud or on-premises system.
November 2020 – CDMM v1.7 – perform all backup, archive, and restore operations directly from the mainframe to any cloud or on-premises system, eliminating the need to manage cloud data using external, non-mainframe systems.
January 2021 – CDMM v1.8 – streamlined processes and at-a-glance system health and connectivity data for the Model9 management server and database, and object storage service.
Model9 partners. Cloudian and MinIO should be in the storage and private cloud providers’ box
Model9 this month joined the AWS Marketplace and achieved AWS Migration Competency. It is partnering with public cloud suppliers, on-premises object store providers and is also an IBM partner as Big Blue sees its software as a way to keep mainframes relevant in the cloud era.
Peleg said: “The cloud market and data are both growing. The opportunity is huge.” Model9 intends to develop its cloud data services further, adding data discovery, audit and reporting services.
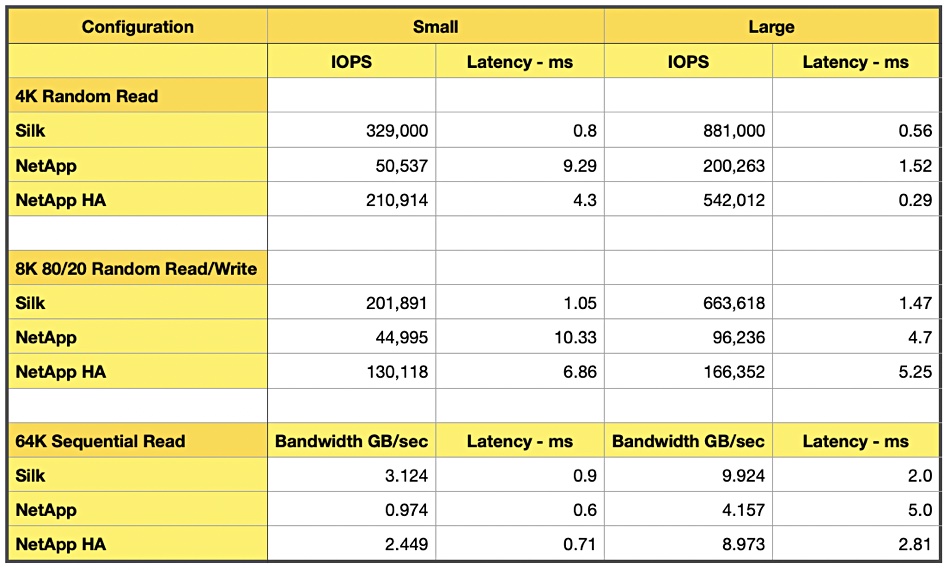
Silk, the storage array software vendor, claims its AWS numbers for IOPS, latency and bandwidth are superior to NetApp Cloud Volumes ONTAP performance on the public cloud.
Derek Swanson, Silk CTO, has written three blog posts that compare Silk and NetApp on small and large AWS configurations and also small and large NetApp high-availability configurations (2 active:active controllers).
For the Silk software, Swanson ran three groups of tests looking at 100 per cent 4KB random reads, an 80/20 mix of 8KB random reads and writes, and 64KB sequential reads. He then measured IOPS (bandwidth for sequential reads) and also latency for each group. He gleaned the NetApp data from the company’s published performance papers.
We’ve tabulated the results.
The chart shows Silk is faster than NetApp’s small and large configurations in the IOPS and bandwidth categories across the three test groups, and, generally speaking, has a lower latency. NetApp’s high-availability results are closest to those of Silk, which also runs in AWS in high-availability mode with two active:active controllers.
Swanson is planning a new blog post. “Next up we will take a close look at NetApp’s next test – Large block Sequential Writes. Don’t worry, we’ll expand that selection with a Random Write test as well, both for large and small block. The results will shock you!” [Swanson’s emphasis.]
StorONE is running a technology preview of its TRU S1 software installed on Azure.
The company chose Azure cloud over AWS because of customer demand, StorONE marketing head George Crump told us in a briefing last week.
An Azure S1 instance could be a disaster recovery facility for an on-premises StorONE installation. It will be interesting to compare StorONE in Azure with Pure’s Cloud Block Store which is also available in Microsoft’s cloud. The GUI and functionality are identical to the on-premises StorONE array. The software might become generally available around May.
StorONE was founded in 2011, raised $30m in a single funding round in 2012 and promptly went into development purdah for six years. It announced TRU S1 software in 2018. This was described as enterprise-class storage and ran on clusterable Supermicro server hardware with Western Digital 24-slot SSD chassis.
Since then, StorONE has supported a high-performance Optane Flash Arrays, with Optane and QLC NAND SSDs, as well as a mid-performance Seagate hybrid SSD/HDD array. Crump told us that although all-flash arrays occupy the performance high-ground, the Seagate box is a “storage system for the rest of us with a mid-level CPU, affordability and great performance. … 2.5PB for $311,617 is incredible”.
“Seagate originally designed the box for backup and archive. We make it a mainstream, production workload-ready system.” StorONE’s S1 software provides shared flash capacity for all hybrid volumes. Crump said the flash tier is “large and affordable – 100TB, for example – and typically priced 60 per cent less than our competitors.”
The sequential writes to the disk tier provide faster recall performance. Overall the hybrid AP Exos 5U84 system delivers 200,000 random read/write IOPS.
According to Crump, competitor systems slow down above 55 per cent capacity usage – and StorONE doesn’t: “We can run at 90 per cent plus capacity utilisation.” This was because StorONE spent its six-year development purdah completely writing and flattened the storage software stack to make it more efficient .
Speeding RAID rebuild
Crump noted two main perceived disadvantages of hybrid flash/disk storage; slow RAID rebuilds, and performance. Failed disk drives with double-digit GB capacities can take days to rebuild in a RAID scheme, writing the recovered data to a hot spare drive, for example. That means a second disk failure could occur during the rebuild and destroy data, meaning recovery has to be made from backups.
StorONE’s vRAID protection feature uses erasure coding and has data and parity metadata striped across drives. There is no need for hot spare drives. A failed disk means that the striped data on that disk has to be recalculated, using erasure coding, and rewritten to the remaining drives in the S1 array.
Crump said: “We read and write data faster. We compute parity faster. It’s the sum of the parts.”
S1 software uses multiple disks for reading and writing data in parallel, and writes sequentially to the target drives. In a 48 drive system, vRAID reads data from the surviving 47 drives simultaneously, calculating parity and then writing simultaneously to those remaining 47 drives.
Seagate AP Existing 5U84 chassis.
Crump told us: “We have the fastest rebuild in the industry; a 14TB disk was rebuilt in 1 hour and 45 minutes.” This was tested in a dual node Seagate AP Exos 5U84 system with 70 x 14TB disks and 14 SSDs. The disks were 55 per cent full.
Failed SSDs can be rebuilt in single-digit minutes. The fast rebuilds minimise a customer’s vulnerability to data loss due to a second drive failure overlapping the rebuild from a first drive failure.
Crump said StorONE has continued hiring during the pandemic, and that CEO Gal Naor’s ambition is to build the first profitable data storage company to emerge in the last 12 years.
Datera, the high-end storage software startup, has gone into liquidation. All of the company’s assets are being transferred to the assignee of the creditors, according to a letter dated February 19 seen by Blocks & Files.
Michael Maidy, who signed the letter, is a managing member at Sherwood Partners, a business advisory firm specialising in restructuring. He noted in the letter that Datera was originally known as Rising Tide Systems.
A senior source close to the company has confirmed the liquidation.
Datera raised at least $63.9m in funding. The investors, led by Khosla Ventures, look to have taken a bath. Customers, channel partners and staff have lost out as well.
Datera’s tide goes out
Datera was founded in 2013 by ex-CEO Mark Fleischmann, ex-CTO Nicholas (Nic) Bellinger, and Chief Architect Claudio Fleiner. The company developed Elastic Data Fabric (EDF) software, providing block-access, scale-out, server-based storage running in x86 servers. Datera sold hardware appliances for a while, before becoming a software-only supplier.
The company touted EDF to enterprises and cloud service providers and supported DevOps and Cloud Native apps. Datera said the software provided webscale economics and integrated it with workload orchestration frameworks such as VMWare, Openstack, Docker, Kubernetes, Mesosphere/DC-OS and Cloudstack.
EDF competed with block storage arrays from Dell EMC, Hitachi Vantara, HPE, IBM, NetApp and Pure Storage. It also had to make progress against the hyperconverged systems and never managed to have an outstanding set of advantages against all-flash arrays like those from Pure. Partners like HPE treated it as just another software way to sell servers and had no real commitment to Datera.
Downturn and departures
There was a C-round of funding in May 2018 ,accompanied by cost-cutting and layoffs. Fleischmann resigned the CEO role in December that year. Board member, ex-EMC exec and Data Torrent CEO Guy Churchward then took on the Datera CEO position.
Churchward had two heart attacks in May 2019 but recovered and achieved selling partnerships with HPE and Fujitsu, amongst others. Fleischmann quit altogether in April 2020. And Feiner left in May 2020.
Fast forward to February 2021 and Churchward resigned for health reasons. At the same time, Chief Product Officer Narasimha Valiveti quit to join Oracle. That was, with hindsight, the writing on the wall.
At that time Chief Revenue Officer Flavio Santoni told us: “Guy had a prior agreement with the board to step back at the end of 2020. Our lead investor stepped in as interim CEO to work through the next few moves.”
The liquidation letter is dated four days after we were told this.
In this week’s roundup, computational storage says hello to Nvidia’s GPUDirect; AWS cuts Glacier prices by a smidge and Dell has upgraded a server line with AMD’s Milan and Intel’s Ice Lake CPUs.
ScaleFlux and GPUDirect
ScaleFlux makes the CSD 2000 Computational storage SSD which has an on-board processor and can compress and decompress data in real time. The drive supports NVIDIA Magnum IO GPUDirect Storage and the company says this is the first use of computational storage for AI/ML and data analytics with GPUs.
CSD 2000 components.
The compression/decompression is transparent to applications, requires no code changes, does not incur latency or performance penalties, reduces data movement, and scales throughput with storage capacity. It also expands the capacity per flash bit by 3-5x.
Hao Zhong, ScaleFlux co-founder and CEO, said the CSD 2000 “handles the decompression process and eliminates up to 87 per cent of the data loading time so the GPU can get to work faster on the training activity.”
We asked for performance numbers and a spokesperson said: “We will not be showing any specifics on run time reduction for the model training or capacity expansion with specific training data sets at this time. As we expand engagements with customers, we expect to gather that information and make a subsequent announcement in the coming months.”
Trivial AWS Glacier data movement price cut
A few days ago we ran this story – AWS slashes Amazon S3 Glacier data movement prices – about a 40 per cent cut in AWS S3 Glacier prices for Data PUTs and Lifecycle requests. The percentage cut sounded great but there were no actual numbers. Now we have them and the net effect is trivial.
We were told the S3 pricing page – aws.amazon.com/s3/pricing/ – has a tab for Requests and data retrievals. There, you will find all the PUT and Lifecycle costs for every storage class.
AWS told us: “The price reduction for PUTs and Lifecycle transitions requests for S3 Glacier reduced prices by 40 per cent in all AWS Regions. For example, for US East (Ohio) Region we reduced the price from $0.05 down to $0.03 per 1,000 requests for all S3 Glacier PUTs and Lifecycle transitions.”
Gosh, we see a $0.02 cut per 1,000 requests. Colour us unexcited.
Dell brings AMD and GPU power to its servers
Dell has updated the PowerEdge server line with 17 models featuring AMD Milan as well as Intel Ice Lake gen 3 Xeon CPUs, and PCIe gen 4 bus support.
The core of the range is a set of rack servers, accompanied by edge and telecom models, a modular compute sled, GPU-optimised and C-Series machines for HPC use cases.
The R7nn5 and R6nn5 systems use the Milan processors. An R750 server will use Intel’s Ice Lake gen 3 Xeon CPUs.
The XE8545 combines up to 128 cores of AMD Milan processors, four NVIDIA A100 GPUs, and NVIDIA’s vGPU software in a dual socket, 4U rack server.
Dell XE8545 server.
The R750xa delivers GPU-dense performance for machine learning training, inferencing and AI with support for the NVIDIA AI Enterprise software suite and VMware vSphere 7 Update 2. It is a dual socket, 2U server with Ice Lake CPUs and supports up to four double-wide GPUs and six single-wide GPUs. It also supports Optane PMEM 200 storage-class memory.
Customers can expect the systems to begin rolling out soon.
Shorts
Datadobi has released DobiProtect support for Azure Blob storage. The data migration company can now protect unstructured data by moving copies into Azure Blob storage.
Datto’s revenues in the quarter ended Dec 31, 2020, were $139m, up 16 per cent Y/Y, with $129m coming from subscriptions. There was a loss of $7.2m. These numbers beat Wall St expectations. Full year revenues were $485.3m, up 18 per cent Y/Y, with a loss of $31.2m. The company provides cloud data protection storage services sold by MSPs.
Cloud computing provider Linode has published a Cloud Spectator report revealing benchmarking data for cloud computing virtual machines (VMs) across Alibaba, Amazon Web Services (AWS), DigitalOcean, Google Cloud Platform, Linode and Microsoft Azure. Linode’s cloud servers based on AMD performed better than competing instances running on Intel chipsets.
WekaIO this week said the Oklahoma Medical Research Foundation is using its software to run more and concurrent research jobs in a shorter amount of time. OMRF is an independent, nonprofit biomedical research institute with more than 450 staff and over 50 labs studying cancer, heart disease, autoimmune disorders, and diseases of ageing.
Open-E has released an update for its ZFS- and Linux-based Open-E JovianDSS Data Storage Software. The up29 version, which performs better and has more configuration options, is free of charge for all software users and is available for download on the company’s website.
SaaS-based data protector Druva has promoted Robert Brower to be SVP of Worldwide Partners and Alliances. He’s going to recruit new partners. Brower is currently VP of Strategic Operations and Chief of Staff.
AIOps-supplying Virtana has announced a SaaS-based Virtana Platform to estimate costs for migrating applications to the public cloud. It’s appointed Alex Thurber as SVP Customer Success and Channel Strategy and Jonathan (Jon) Cyr as VP of Product Management.
Dell extended its lead over Nutanix in branded hyperconverged infrastructure (HCI) sales in the fourth 2020 quarter. Nutanix also fell back compared with VMware when measured by HCI software revenues, the latest IDC figures show.
However, Nutanix now recognises revenues over the lifetime of the contract and not at the point of sale, and this transition could mask underlying performance. Market watcher IDC notes that Nutanix’ Y/Y comparison is highly influenced by its shift away from software licenses to subscription sales, recent incentives targeting annual contract value over total contract value, and a go-to-market shift towards OEM partners.
IDC estimates the global HCI market grew 7.4 per cent in Q4. HCI is part of the overall converged systems market which IDC slices three ways in its Worldwide Quarterly Converged Systems Tracker: certified reference systems and integrated infrastructure; integrated platforms; and HCI systems. The HCI systems are tracked by the HCI brand and also by the HCI software owner to take account of OEM sales.
IDC research analyst Greg Macatee said in the press release: “The converged systems market closed out the year with tepid 0.2 per cent year-over-year growth in the fourth quarter, while the market for the full year 2020 finished down 0.6 per cent annually. That said, hyperconverged system sales were the market’s main pocket of growth in 4Q20, finishing up 7.4 per cent year over year, which is an acceleration over what we have witnessed over the past few quarters.”
Certified reference systems and integrated infrastructure market grew revenues 0.1 per cent Y/Y to $1.6bn; 35.6 per cent of all converged systems revenue.
Integrated platforms revenues declined 25.9 per cent Y/Y to just under $460m; 10.1 per cent of the market.
HCI revenues grew 7.4 per cent Y/Y to $2.5 bn; 54.2 per cent of the market.
HCI numbers
Dell led the top three branded HCI sales suppliers with revenue increasing 11.1 per cent Y/Y to $801.8m revenue, giving it 32.6 per cent share – up 0.9 per cent. HPE was second, with $331.7m revs, up 25.4 per cent, and 13.5 per cent share. Nutanix was third with $254.1m revenues, down 18.8 per cent and 10.3 per cent share.
Tom Black, HPE’s SVP and GM for Storage, said in a statement: “The momentum in HPE’s HCI business continues to accelerate. This is now the second consecutive quarter in which we have clearly outperformed the market.”
Nutanix software is sold by OEMs such as Dell and HPE , and so the HCI cut by software owner presents a different revenue picture.
By this yardstick, VMware is top with $953.8m in revenues, up 1.7 per cent Y/Y, giving it 38.7 per cent share. Nutanix is in second place, with $575.5m in revenues, down 6.6 per cent Y/Y and 23.4 per cent revenue share. Unexpectedly, Huawei is in the joint third spot, with revenues of $154.5m, up 75.7 per cent, and 6.3 per cent share. It is tied with Dell Technologies, which had revenues of $137.4m, an even higher 102.4 per cent growth rate, and 5.6 per cent share.
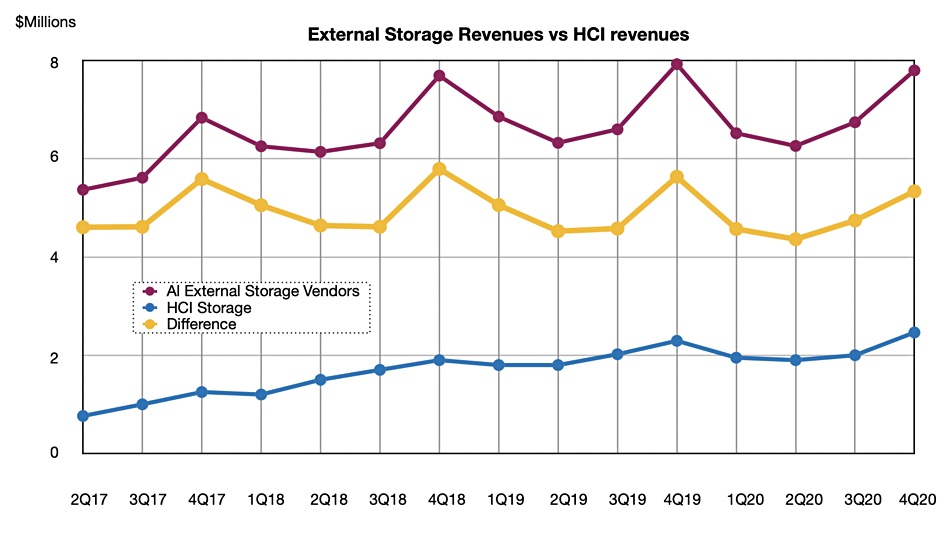
HCI systems are taking slightly more of the overall storage market than before, as a chart indicates – if you look closely;
B&F chart using filed IDC tracker numbers.
IDC said the external storage market (arrays, filers and object stores) declined 2.1 per cent Y/Y to $7.8 bn in revenues in the quarter. As HCI revenues were up 7.4 per cent in the same period, to $2.5bn, they gained share. The most recent three 4Q peaks in the yellow line on the chart show a gentle downward trend in the difference between HCI and external storage revenues over three years, as HCI revenues gain on external storage revenues.