In response to our article, Neil Fleming, HPE’s Senior Manager of WorldWide PM, Sales, Presales and Alliances for HPE Cloud Data Services, responded via Twitter: “Late to the party but a few issues with this. AWS doesn’t sell storage they rent it. This is like looking at a town with an Avis car rental, a Ford dealership and a Chevy dealership and concluding Avis are the number 1 car dealer because they have more cars leaving the lot and ignoring the difference between a car being rented and sold.”
He followed this train of thought with a second idea: “It’s then concluding that as the revenue on renting a car is higher than selling it to a user that equates to more car sales. By this logic Hilton is one of the largest home builders in the world.”
Fleming hammered his points home with another example: “Raspberry Pis are used for server tasks (DNS etc). They sell about 600,000 units a month. [The] No 1 server vendor globally is not Dell/HPE but Raspberry Pi by a landslide (about +1.2m units). Comparing very different businesses like this is meaningless.”
But is AWS storage actually like renting a car, I asked Fleming: “I’d argue that public cloud storage is more akin to leasing a car than renting it. Someone leasing a car is doing so instead of purchasing it. So car leases should be added to the car sales total. Is this right?”
“Actually no,” He replied. “Car leases are already counted in car sales as the sale is counted to the leasing company. Same as ODM sales are counted to the CSPs – so this would be another issue. CSPs provide services akin to leasing (reserved services) I grant you, and car renting (spot prices).“
We are contacting Gartner and IDC to find out what they think about measuring public cloud enterprise storage revenues.
Interview: ScaleFlux computational storage flash drives offer quadruple the capacity, double the performance and halve the flash costs of ordinary SSDs – so says CEO Hao Zhong.
The startup has developed its CSD 2000 series computational storage drives with on-board processing to carry out processing directly on the stored data. Over 40 data centres are working with the drives, Zhong told us in a recent interview.
Hao Zhong.
The capacity increases comes from ScaleFlux compression algorithms and its way of mapping data in the drive. The second generation ScaleFlux CSD 2000 drives use an FPGA to provide the computation. ScaleFlux is developing its own Arm-powered SoC (System-on-Chip) for third generation drives. These will have much higher speed, lower power draw, lower costs, and significantly more features than ScaleFlux can fit in into the FPGA.
The gen 3 drive, possibly called a CSD3000, may arrive later in the second half of this year.
B&F: How are computational storage drives positioned against storage processing units from suppliers like Nebulon and DPUs from Fungible?
Hao Zhong: I think this is pretty simple. What do we do is we try to reduce data movement in the serve and connection fabric. So Nebulon or a DPU type of product is a good idea, however, … this will cost a lot of data movement and this means out of the gate intrusive integration for most data centre or enterprise customers to be able to use the SPU/DPU; a significant programming and software integration.
For the CSD we encapsulate all the complexity under the NVMe device protocol. So there’s no change for any application.
[See Nebulon note below.]
B&F: Is a computational storage standard coming?
Hao Zhong: There are two industry organisation are working on this. One is SNIA and the other is an NVMe one. Regarding SNIA, a working group was set up in 2018, and we were one of the founding members of that working group.
We were the first member to be able to come up with a product and start shipping from June 2019. Last year, Intel and Amazon partnered and also invested in SNIA. But for them, SNIA is a general industry standard process. Intel and AWS want to speed up the process and so they bring this to the NVMe working group.
I think that there has been significant progress made since then. Now I would say computational storage will definitely be part of any NVMe standard in the future. Computational storage will be some kind of extension of the general NVMe standard.
CSD 2000
B&F: What partners are you working with?
Hao Zhong: We’re not only working with data centre customers, but also the server OEMs, because, you know, most of the data centres want us to quantify with server vendors, for example, HPE, Dell, Lenovo, and Inspur.
B&F: What are the benefits of using your CSD product?
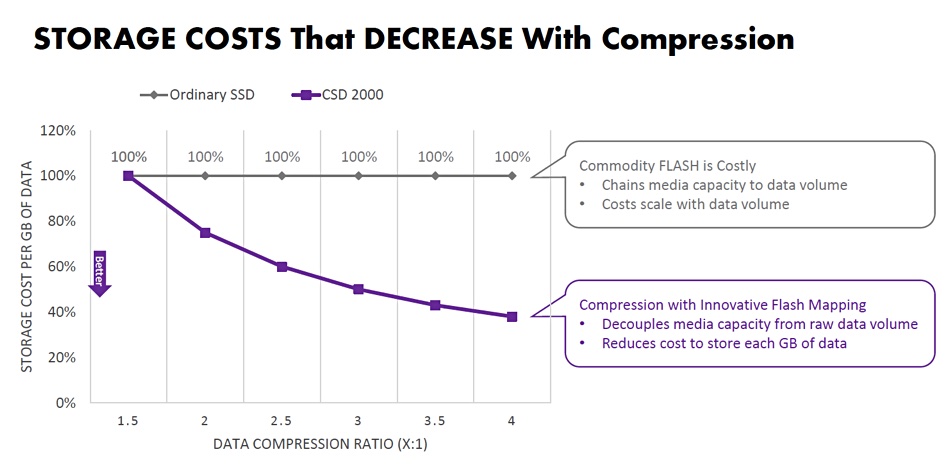
Hao Zhong: Number one is the cost saving. We increase capacity by using transparent, inline compression. By doing that, we are increasing the usable capacity for customers, and we also improve the performance and the latency by reducing the number of data writes into the flash media. That’s how we significantly improve the performance and endurance.
B&F: Do you have any numbers for that?
Hao Zhong: We can improve the endurance by three to six times. The performance increase depends on whether it is a read or write. For the random read, we know we can improve the average latency, but for the random write we have from over 200 per cent to as much as 600 per cent.
If you are talking about comparing to the average SSDs – let’s say the QLC drive from Intel – they have 34,000 random write IOPS. We can pump it up to all the way to 180,000. So this is nearly six times, which is almost 600 per cent, over Intel’s drive.
B&F: There’s a difference between reads and writes?
Hao Zhong: Right, For the random read as as mentioned, there’s not much we can save because, the latency and speed is dominated by the read latency from the NAND media. But with light writes is different, because you can avoid the standard write process.
B&F: So if you increase the capacity, and you increase the performance as well, then a server could have say 10 x 15 terabyte SSD to get 150 terabytes of capacity. But if you increase the effective capacity enough that server would only need half the number of SSDs and they’d probably go faster.
Hao Zhong: Yes, right. Yes.
B&F: How do you build your CSD products?
Hao Zhong: We take a standard U.2 NVMe SSD and replace the controller chip.
ScaleFlux CSD2000 components
B&F: Do you support the M.2 form factor
Hao Zhong: No, we’re no supporting M.2 yet, because M.2 has some limitations in terms of power consumption as well as how much footprint that we can get into this small form factor.
Hao Zhong: Yes, we can fit in that as well. But it’s just the volume is not there yet.
B&F: Do you think that Western Digital with its zoned SSD (ZNS) idea is moving slightly towards computational storage, or do you think the zoning is so trivial from a computational point of view that it doesn’t represent any future competition?
Hao Zhong: I think they are orthogonal and also complementary to each other. Zoning space is something like the namespace that NVMe has been working on as well. So, I think computational storage can dramatically help the namespace of ZNS by providing more capacity for the user.
Comment
ScaleFlux says it provides 5:1 compression for Aerospike, 4.2:1 with MySQL and 4:1 with Oracle databases. It claims its on-board compressed flash capacity comes at less than half the cost of commodity SSDs, while performing twice as fast at writes and lasting longer.
ScaleFlux chart showing cost saving from compression.
If ScaleFlux can deliver further increases in write speed and endurance with its third generation product the attractions of its plug-and-play technology should increase further.
NebulonNote
Nebulon CEO Siamak Nazari pointed out that, with Nebulon Cloud-Defined storage, “application, programming or software integration is … virtually non-existent,” being “equal to using a SAS array or RAID card.”
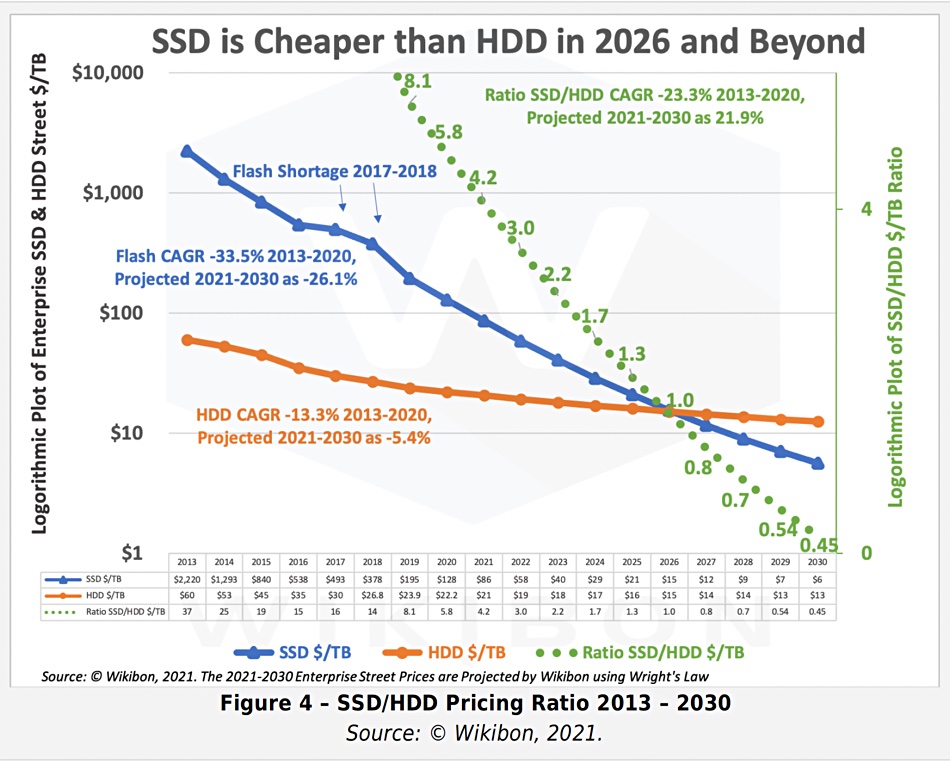
Let’s find out from Dr. John Morris, CTO at Seagate, the world’s biggest HDD maker. He notes that currently there is a 7-10x difference in raw cost per bit between flash and disk. Furthermore, raw cost per bit is the “dominant factor in a total cost of ownership equation today”.
Morris in a phone interview expressed confidence that the “economics [of flash vs HDD] are going to stay roughly in equilibrium, and the architectures that we see today are going to be the preferred architectures for the next five or 10 years.”
Dr. John Morris
He thinks that proponents of “SSDs will kill disks” fail to factor in the role of large data centre demand in driving storage capacity growth. “Maybe one or two years ago, we hit a point where about 50 per cent of the data is in a large data centre and about 50 per cent is everywhere else.”
“Large data centre growth rate is in the 30 per cent per year range, whereas any of the other use cases are kind of flat from an exabyte perspective and over time. Our expectation is that over the next five years we’re going to see 90 per cent of the data in this large data centre use case. – whether it’s public or private is kind of irrelevant.”
In these large, exabyte-scale data centres there will be a “fairly robust mix of flash and disk – something on the order of 90 per cent on disk and approximately 10 per cent on flash”.
So, the two storage mediums will continue to co-exist. “Flash and disk actually have a symbiotic relationship,” he said. “Today, you can’t scale a storage system without both. They both have a unique value proposition. And it’s the combination of those unique value propositions that they offer that allows you to create the massive data centre that we all benefit from today.”
Raw capacity cost comparisons
The flash and hard disk industries are both forecasting cost per bit improvements of about 20 per cent a year, according to Morris. If those expectations pan out, “we’re going to stay roughly in equilibrium in terms of rough cost per bit for the foreseeable future.” This view is shared publicly by some of the large cloud companies, he adds.
Wikibon chart showing SSDs becoming lower cost than disk drives.
Smaller data centres
Flash will not takeover from disk in smaller, petabyte-scale data centres either, according to Morris.
“It comes down to what is the use case dominated by – a performance-centric metric or a cost-centric metric? I think there’s both. In those infrastructure that have an extreme sensitivity to cost people are going to exploit the capabilities of of hard disk. whereas if your performance or power-sensitive, I think you’re going to see a gravitation towards a flash architecture.”
Asymmetric IO
Morris points to the asymmetric IO profiles of data in large repositories: “At any given point in time, the IO into that volume storage; up to 10 per cent of the total storage has active IO and 80 to 90 per cent of that storage volume does not have active IO.”
“Active IPOs are tiered or cached on flash, providing a very good … random IO capability, and everything else is committed to a lower cost infrastructure which is on hard disk.”
The data held on disk is not inert: “It’s also a little bit of a misnomer, to think that there’s no IO happening on everything else, it is happening, but it can be done in a way that is able to efficiently use the disk drive architecture so you’ll see relatively large block IO happening on the disk. You’ll see 10s of megabytes per second of bandwidth, on every disk in that architecture and you’ll see good utilisation of all the disks. It’s that very good IO capability that you get out of that large pool of disk that actually makes the whole work well together.”
Influence of QLC flash
The arrival of QLC (4bits/cell) flash will not change flash-HDD dynamics, according to Morris. He thinks supporters of a QLC SSD takeover of disk drives base their argument on data reduction: “They’ll use data reduction and make a statement like because flash has orders of magnitude more random capability, you can do on the fly dedupe and compression with QLC; you can’t do that with hard disk. Therefore, I’m going to apply a 4 x or better multiplier on the effective capacity of flash and I won’t apply that to disk. If I do that in five years there’s parity of costs.”
In other words the raw cost per bit of disk is being compared to the effective cost per bit of flash, after data reduction. However, cost comparisons should be made on a raw capacity basis for both mediums, he argues.
“It is true that flash is able to do on the fly dedupe and compression very effectively. It’s actually not true that you can’t do it with hard disk. In fact, it is done with the hyperscale architectures today. Dedupe and compression are done higher up in the stack. and when data is ultimately committed to the media it’s already been deduped and compressed and in many cases encrypted.”
Our IPO sensing organ is twitching strongly following a couple of Backblaze announcements. NAND and SSD fabber Kioxia has made a loss in its latest quarter. Index Engines has announced APIs so third-party storage and backup supplies can add automated ransomware attack detection into their software.
Backblaze gussying up for IPO?
Cloud storage supplier Backblaze has recruited three independent non-exec board directors to serve on compensation, audit, and nominating and governance committees, and a specialist financial PR firm, the San Francisco-based Blueshirt Group.
This month it announced the hiring of Frank Patchel as CFO and Tom MacMitchell as General Counsel and Chief Compliance Officer. Interestingly, to me at least, they were actually hired in Spring 2020. MacMitchell came on board in April 2020 according to his LinkedIn profile and Patchel left his previous job in February last year.
This all looks like BackBlaze is laying the groundwork for an IPO.
Kioxia attributes Q3 loss to weak enterprise demand and smartphones fallback
Kioxia’s third fiscal 2020 sales ended Dec. 31 were ¥287.2bn ($2.72bn) with a loss of ¥13.2bn ($130m). This compares to the year-ago sales of ¥254.4bn ($2.41bn) and ¥25.3bn ($240m) loss. The numbers are going in the right direction, with a 13 per cent sales rise Y/Y.
Kioxia said smartphone-related shipments decreased from previous high levels and enterprise demand was weak, But it reported solid growth in gaming devices, PCs and data centres, which enable modest positive bit growth in the quarter.
However average selling prices declined driven by a supply/demand imbalance. In other words, A NAND glut has been driving down prices. Kioxia said this was primarily caused by the COVID-19 pandemic and China-US trade friction. The general consensus is that the NAND market will stabilise towards the second half of CY2021 as demand for data center SSDs, client SSDs and smartphones is expected to remain strong, and demand for enterprise SSDs is expected to recover steadily.
Index Engines opens APIs to protect backup vendors from ransomware attacks
Index Engines has released an API-based developer kit to enable third-party backup and storage vendors to integration of CyberSense analytics and reporting software into their products.
The company says its CyberSense software provides advanced integrity analysis of data to detect signs of corruption due to a ransomware attack on backup and storage data. The new APIs enable third parties to hook into full-content indexing of data, alerts if suspect corruption is detected, post-attack forensic reporting that allows rapid diagnosis and recovery from an attack.
APIs are available to initiate indexing jobs for data in both primary and backup storage environments via NFS/CIFS or NDMP protocols. CyberSense can directly index files in backup images, including Dell EMC NetWorker/Avamar, Veritas NetBackup, IBM Spectrum Protect, and Commvault without the need to rehydrate the data.
Shorts
Ctera‘s global file system is now supported on HPE Nimble Storage dHCI systems. Nimble Storage dHCI users can visit www.ctera.com/hpe-hci to get their free download for the CTERA virtual filer with public and private cloud service extension options.The software is already available on HPE SimpliVity HCI systems.
Search company Elastic has announced the general availability of searchable snapshots and a new cold data tier to enable customers to retain and search more data on low-cost object stores without compromising performance. Customers discover new data and new workflows by creating a schema on the fly with the beta launch of schema on read with runtime fields. There is also a web crawler for Elastic App Search to make content from publicly accessible websites easily searchable.
One fifth of the UK public does not know how to permanently erase data from a device, according to a Kaspersky survey. The research, which included a data retrieval experiment on second-hand devices, found that 90 per cent contained traces of private and business data, including company emails.
UK-based digital archiving specialist Arkivum, in partnership with Google Cloud, have been selected for the second prototyping phase of the €4.8m multinational ARCHIVER project led by CERN. The team were awarded a role in the pilot phase, announced in June 2020. This phase will run for eight months.
Quantum‘s ActiveScale S3-compatible object storage system has achieved Veeam Ready qualification for Object and Object with Immutability, meaning it now has ransomware protection. Quantum said it is ensuring that all its products have a built-in option for ransomware protection.
Redis Labs has announced RediSearch 2.0 which allows users to create secondary indexes to support their queries instead of writing manual indexes. It scales to query and index billions of documents, and use sRedis Enterprise’s Active-Active technology to deliver five-nines (99.999 per cent) availability across geo-distributed read replicas.
Data lake query tech supplier Varada has a new feature that enables a 10x-100x queries speed increase when running on Trino clusters (formerly known as PrestoSQL) directly on the data lake. Varada can now be deployed alongside existing Trino clusters and apply its dynamic and adaptive indexing-based acceleration technology. It is available on AWS and is compatible with all Trino and previous PrestoSQL versions.
Appointment setting
Commvault has appointed Jamie Farrelly, formerly at Veritas, as EMEA VP for Channel and Alliances.
Druva has appointed Scott Morris as VP Sales or Asia-Pacific and Japan (APJ) based in Singapore. Most recently, he served as vice president and GM for Asia-Pacific at HPE.
Edge computing company Fastly has recruiteed Brett Shirk as Chief Revenue Officer. Shirk was previously Rubrik’s Chief Revenue Officer and left abruptly earlier this month.
Database supplier SingleStore has hired Paul Forte as chief revenue officer (CRO). Forte comes to SingleStore from data management company Actifio (recently acquired by Google) where he served as the president of global field operations, including sales, marketing, customer service and post-sales.
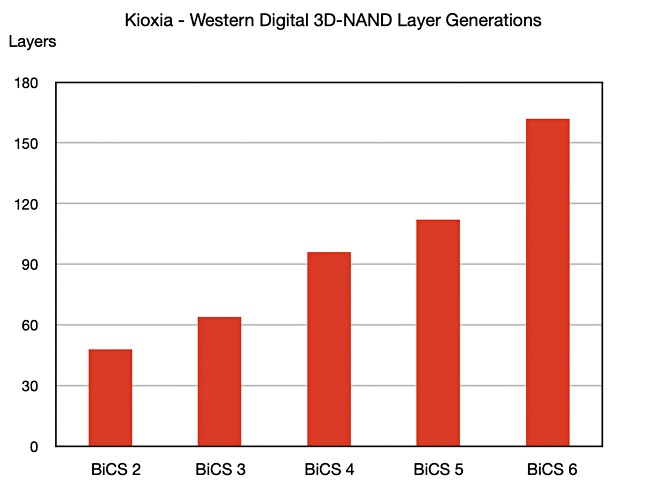
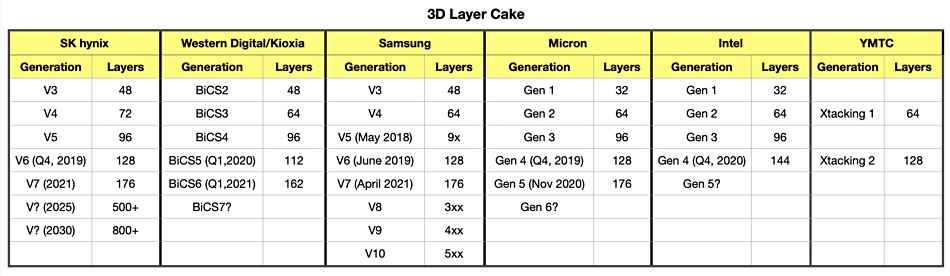
Kioxia and Western Digital have announced the sixth generation of their BiCS 3D NAND technology, with 162-layers and a 40 per cent smaller die than their gen 5 BiCS 112-layer technology.
Each new BiCS (Bit Cost Scaling) generation should have a lower cost per bit than its predecessor. The two suppliers did not disclose how much this is reduced in Gen 6, but they revealed that manufactured bits per wafer are increased by 70 per cent over gen 5.
Siva Sivatram
Dr. Siva Sivaram, Western Digital’s President of Technology & Strategy, cited performance, reliability and cost benefits for Gen 6. He said the new generation introduces “innovations in vertical as well as lateral scaling to achieve greater capacity in a smaller die with fewer layers”.
We think product will announced and available by the first 2022 quarter – but note the companies did not say what capacity dies could be built using gen 6 BiCS NAND or when SSDs using the technology might appear.
Gen 6 BiCS NAND improves various parameters compared to gen 5:
Up to 10 per cent greater lateral cell array density
Nearly 2.4x program performance improvement through 4-plane operation
10 per cent lower read latency
66 per cent IO speed increase
The 162-layer count represents a 44 per cent increase on gen 5, which is a larger increase than in previous BICS generations. The companies are not saying if the die is built by string stacking, where two 81-layer components one above the other.
Three NAND suppliers have developed 3D NAND with greater layer counts than Kioxia and Western Digital. Micron, SK hynix and Samsung have each achieved 176, leaving Intel at the 144-layer level and YMTC trailing with 128. Intel’s future development is moving into the hands of SK hynix, as that company is buying Intel’s NAND operation.
SK hynix revealed a roadmap to 500+ and even 800+ layers in August 2019. Other suppliers are understood to have similar internal roadmaps. Kioxia and Western Digital announced the 112-layer BiCS in January 2020. Based on the industry trend to add more layers and on Kioxia and Western Digital’s actual layer count increases, we could anticipate a potential BiCS 7 announcement with 250+layers in 2022.
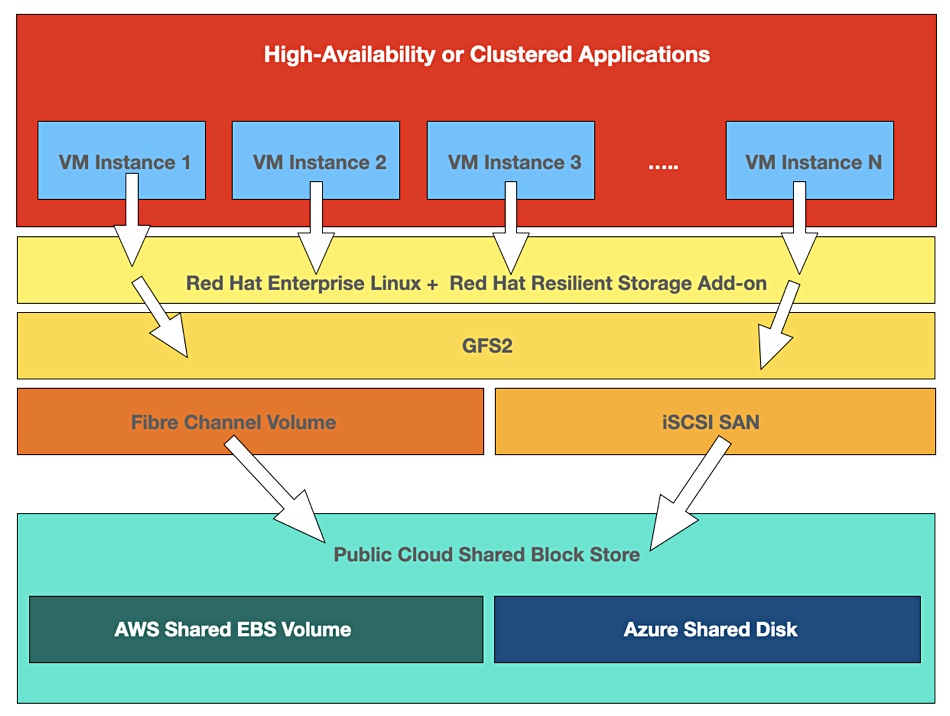
Red Hat Linux running in the AWS and Azure public clouds now supports high-availability and clustered applications with its Resilient Storage Add-On (RSAO) software. This means apps like SAS, TIBCO MQ, IBM Websphere MQ, and Red Hat AMQ can all run on Red Hat Linux in AWS and Azure for the first time.
Announcing the update in a company blog post, Red Hat Enterprise Linux product manager Bob Handlin wrote: “This moment provides new opportunities to safely run clustered applications on cloud servers that, until recently, would have needed to run in your data centre. This is a big change.”
No cloud block sharing – until now
AWS and Azure did not support shared block storage devices in their clouds until recently. One and only one virtual machine instance, such as EC2 in AWS, could access an Elastic Block Storage (EBS) device at a time. That meant high-availability applications, which guard against server (node) failure by failing over to a second node which can access the same storage device, were not supported.
Typically, enterprise high-availability applications such as IBM WebSphere MQ have servers accessing a SAN to provide the shared storage. These applications could not be moved to the public cloud without having shared block storage there.
Azure announced shared block storage with an Azure shared disks feature in July 2020. And AWS announced support for clustered applications using shared (multi-attach) EBS volumes in January this year. The company said customers could now lift-and-shift their existing on-premises SAN architecture to AWS and Azure without refactoring cluster-aware file systems such as RSAO or Oracle Cluster File System (OCFS2).
Blocks & Files RSAO diagram.
RSAO
Red Hat’s Resilient Storage Add-On lets virtual machines access the same storage device from each server in a group through Global File System 2 (GFS2). This has no single point of failure and supports a shared namespace and full cluster coherency which enables concurrent access, and cluster-wide locking to arbitrate storage access. RSAO also features a POSIX-compliant file system across 16 nodes, and Clustered Samba or Common Internet File System for Windows environments.
AWS and Azure ‘s shared block storage developments have enabled Red Hat to port RSAO software to their environments. RSAO uses the GFS2 clustered filesystem and it passes Fibre Channel LUN or iSCSI SAN data IO requests to either an AWS shared EBS volume or Azure shared disk as appropriate.
Handlin said Red Hat will test RSAO on the Alibaba Cloud “and likely other cloud offerings as they announce shared block devices.”
StorCentric, the mini data storage conglomerate, has launched its first Violin-branded system since buying the company’s assets last October.
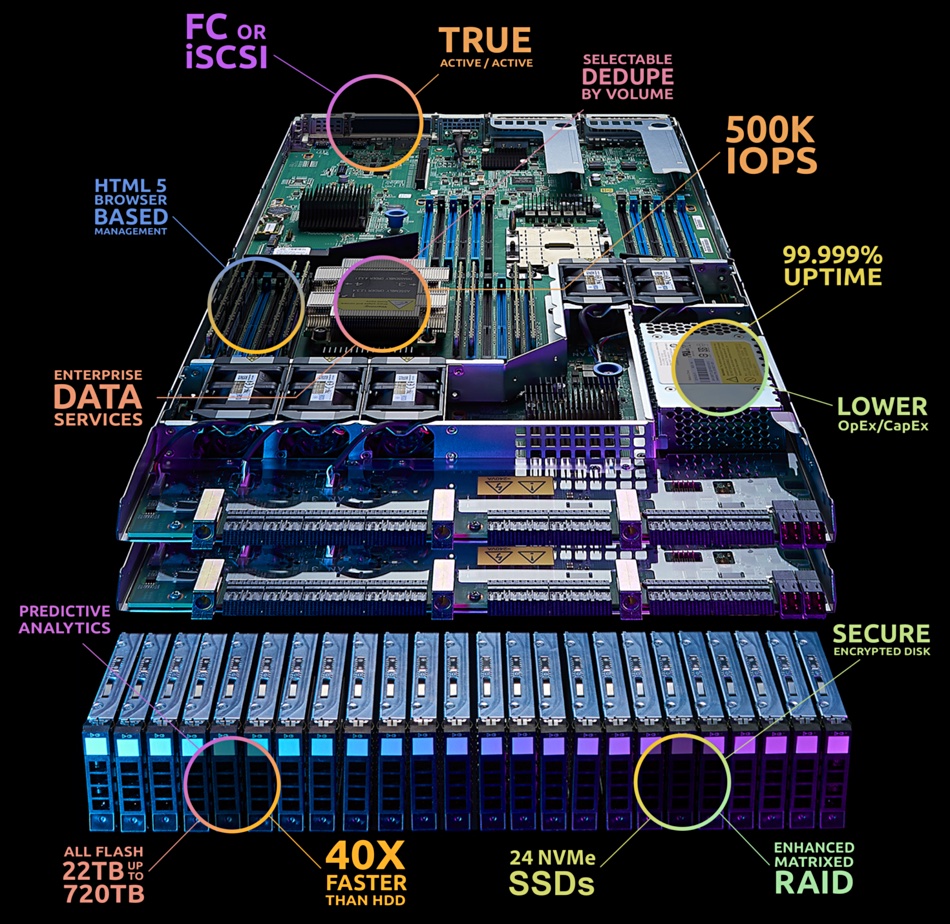
This is the Violin QV1020, an entry level NVMe drive all-flash array, which has basically the same chassis, software and performance as the current QV2020.
However, it starts at a lower capacity and can have fewer Fibre Channel ports, thus lowering its ticket price. A StorCentric spokesperson told us there is an up to 25 per cent cost savings on the QV1020, compared with the older version of the QV2020.
StorCentric CTO Surya Varanasi said in a press statement: “NVMe has taken hold in the enterprise, driven by the demands of high-performance applications such as big data analytics, machine learning, artificial intelligence, OLTP and data warehousing and their need for high-speed, low-latency access to storage media. The Violin QV1020 answers the call for these exact same NVMe capabilities, but for companies that have smaller capacity requirements with corresponding pricing.”
The QV1020 keeps the active-active QV2020 controller design and all its software. The QV1020 has a 15TB to 116TB usable capacity range (60TB to 464TB after data reduction), while the QV2020 usable capacity range is 116TB to 479TB (464TB to 1.7PB effective). There are two or four QV1020 Fibre Channel ports; the QV2020 has up to eight.
StorCentric QV2020 graphic
The Violin QV2020 launched in February 2020 in a 2RU chassis with 24 x NVMe hot-swap and encrypted SSDs, dual active-active controllers, 8 x 16Gbit/s FC ports and 10/25GbitE support. The capacity range was then 15TB to 479TB and a 4:1 data reduction ratio made the effective capacity range 60TB to 1.7PB. To avoid overlap with the QV1020, the capacity start point has been bumped up to 116TB.
QV software includes data deduplication, applicable at a volume level, snapshots and synchronous replication. Data writes are balanced across the SSDs to prolong their endurance. Both QV arrays have up to 7.1GB/sec bandwidth and sub-millisecond latency at 500,000 IOPS.
Toshiba is using energy assist technology in its first 18TB disk drive. The MG09 – out later this year – will be its highest capacity HDD to date, but rivals Seagate and Western Digital are already shipping 20TB drives.
The MG09 is a 9-platter design in a 3.5-inch format helium-filled enclosure. It comes in 16TB and 18TB capacities, has a Marvell controller and preamplifier, spins at 7,200rpm, has a 550TB/year workload rating and features either a 12Gbit/s SAS or 6Gbit/s SATA interface.
The drive is an evolution of Toshiba’s MG08 series which tops out at 16TB. The MG09 data transfer speed is 268MiB/s (281MB/sec) – better than the MG08’s 262MiB/s (274MB/s).
Toshiba MG09
The drive uses flux control – microwave assisted magnetic recording (FC-MAMR) energy assistance – to overcome the difficulty of writing data bits to a recording medium that strongly retains magnetic polarity at room temperature. This is similar to Western Digital’s microwave-assisted magnetic recording (MAMR) technology.
We note that WD has not yet actually launched a drive that uses full MAMR technology. The company’s 18TB uses a precursor of MAMR called partial microwave-assisted magnetic recording technology (ePMR) to increase write efficacy with a write bias current.
For its 20TB drive, Western Digital uses ePMR plus shingling. Shingled magnetic recording crams more read tracks on a platter than conventional disks and so increases drive capacity. However, this technique slows write performance compared to the conventional recording used in the Western Digital, Seagate and Toshiba 18TB drives, and Seagate’s 20TB drive.
Seagate has taken a different tack for its 20TB drives, using HAMR (Heat Assisted Magnetic Recording), using heat to overcome the same difficulty (which is technically known as high coercivity).
Sample shipments of Toshiba’s 18TB MG09 Series disk drive are expected to start at the end of March 2021.
Zadara, the enterprise storage as a service vendor, has gone full-stack by acquiring a compute-as-a-service startup called NeoKarm.
Zadara first teamed up with NeoKarm, a one year-old Tel-Aviv based company, in October, in order to provide a turnkey compute-as-a-service for managed service providers (MSPs) and enterprises. MSPs could equip their data centres with servers without any CAPEX spending. Customers could get on-demand compute and storage services in an existing on-premises data centre, in a private colocation facility, or in a Zadara cloud location.
Now Zadara finds it likes the NeoKarm technology so much that it is buying the company. The price has not been revealed but is being paid with Zadara cash. NeoKarm CEO Simon Grinberg, and some DevOps and engineering colleagues will join Zadara to continue the development of the technology and drive new compute-focused initiatives.
Nelson Nahum
Nelson Nahum, Zadara’s CEO, said in a statement: “The NeoKarm technology seamlessly integrates with our storage solution and offers a vastly improved performance for our customers and partners. I am thrilled to welcome the NeoKarm team to Zadara.”
Simon Grinberg
Simon Grinberg said the companies share a “vision of offering a competitive on-demand cloud for service providers. I am excited to join the team at Zadara to continue developing our seamless on-demand private cloud for providers, available at existing data centers, collocations or other cloud locations, built and fully-managed by Zadara.”
Added NeoKarm
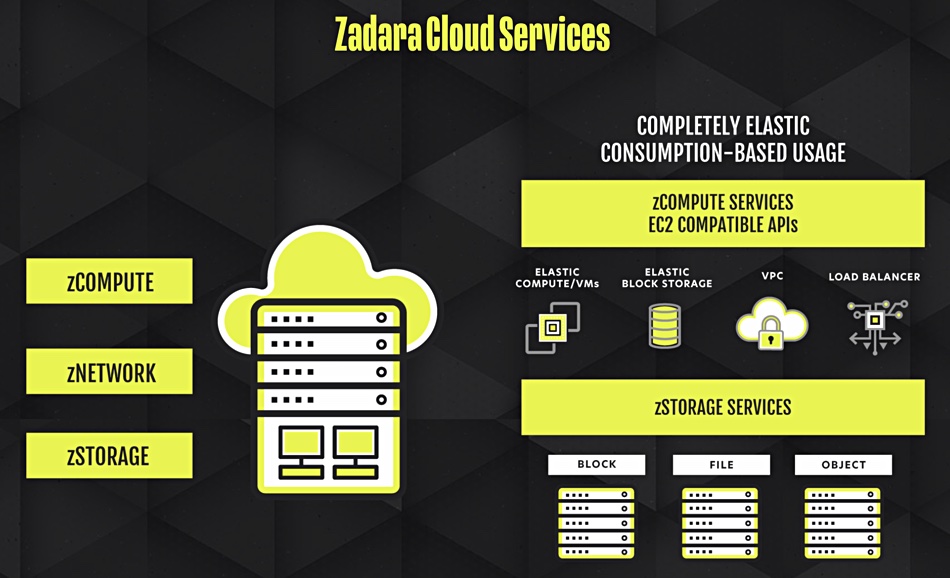
Zadara graphic.
The Zadara cloud services platform with added NeoKarm provides automated end-to-end infrastructure provisioning of compute, storage and networking resources. The service features AWS-compatible APIs, which enables customers to deploy applications via the same scripts they use to deploy in AWS.
MSP and enterprise users can self-provision multiple VMs. Zadara says its cloud service platform is good for edge locations, perhaps anticipating continual public cloud erosion of core on-premises data centre use.
As of today Zadara has more than 300 MSP customers for its storage and compute-as-a-service offerings. The company said it has deployed more than 20 private compute clouds using the NeoKarm software.
Chasing clouds
NeoKarm was formed from the ashes of Stratoscale, a Tel Aviv-based company that crashed in December 2019. Stratoscale had developed private cloud hyperconverged system software. This turned an HCI system into an AWS-compatible region capable of running supporting EC2, S3, EBS, and RDS instances, and supporting Kubernetes.
Stratoscale’s software IP assets were obtained by newly-founded NeoKarm, in February 2020. NeoKarm’s founder and CEO was Simon Grinberg, the ex-VP for Product and Cloud Architecture at Stratoscale.
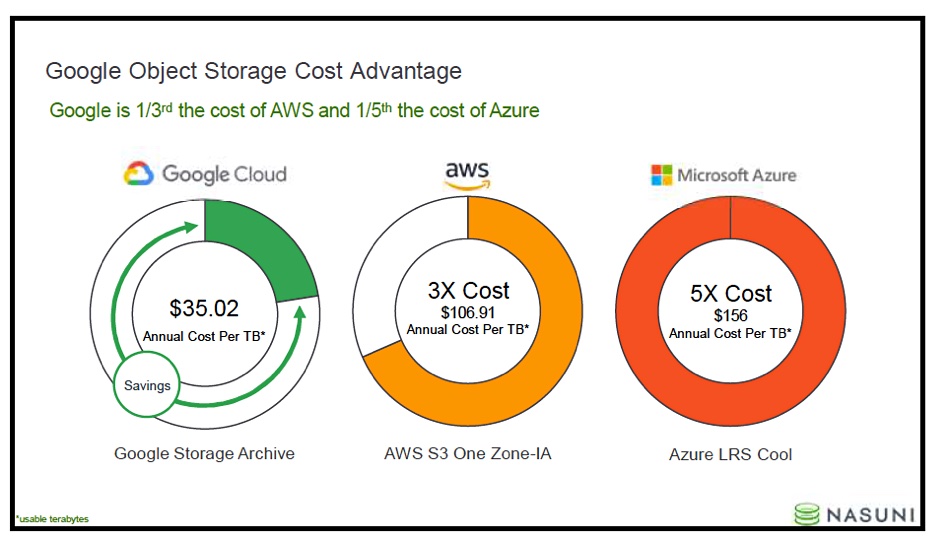
Google has expanded its relationship with Nasuni, integrating company’s the object-based file system with Google Cloud Platform, and agreeing to co-sell/ co-market the company’s software.
Google’s sales reps will be paid on Nasuni-GCP license sales and customers can buy Nasuni’s service directly through the Google Marketplace.
Nasuni’s object-based file system is already available on Google Cloud, and the company has co-sell agreements in place with AWS and Azure. CTO Andres Rodriguez told us: “In the past [Nasuni] customers could ‘hack’ and use Google with an AWS connector but what we are announcing is native integration, marketplace inclusion, and the fact they are co-selling with us. All new.”
Andres Rodriguez
The deeper GCP integration delivers speed, Rodriguez said. “Accessing the file system directly in the object layer can be faster.”
A full scan of a billion files can be completed more quickly with Nasuni’s object layer storage than by using a file system directory-level inspection (a so-called treewalk).
Nasuni Google cost advantage
Rodriguez said Google is hungry for Windows file workloads (SMB) to move from on-premises filers to its GCP service and Nasuni can help with that migration. He claimed: “Everyone is moving to virtual machines running in the public cloud.”
Rodriguez said Google’s own high-performance FileStore product, Elastifile, is less well suited to the on-premises Windows filer migration task.
Nasuni cost comparisons
Nasuni background
Nasuni has around 400 employees, more than 530 enterprise customers and has more than 125PB of data (26.7 billion files) under management. The company claims 42 per cent CAGR in annual recurring revenue (ARR) since 2017. It is targeting $100m in ARR in the next 12 to 18 months.
Nasuni’s UniFS file system provides a Network Attached Storage (NAS) interface to users in the cloud or on-premises. The object storage base makes Nasuni’s UniFS less expensive than public cloud file-level storage, and the edge caching appliances add the access speed that object storage in the cloud lacks.
Caching edge appliances are used on-premises to provide fast access to data. These can scale to the hundreds with thousands of users. The public cloud stores a golden master of the file data and this is used for sharing across a customer’s edge locations and also, via in-cloud edge appliances, fast access within public cloud regions.
Its focus is on storing mainstream unstructured data files and not the high-performance computing file market – leaving that to Panasas, VAST Data and WekaIO. Nasuni’s main competitive supplier focus is on NetApp, according to Rodrigues.“We go toe to toe with NetApp.”
A future development could see scale-out edge appliances. Asked if Nasuni’s file software supported the provisioning of storage to Kubernetes-orchestrated containers, CTO Rodriguez said: “Not yet.”
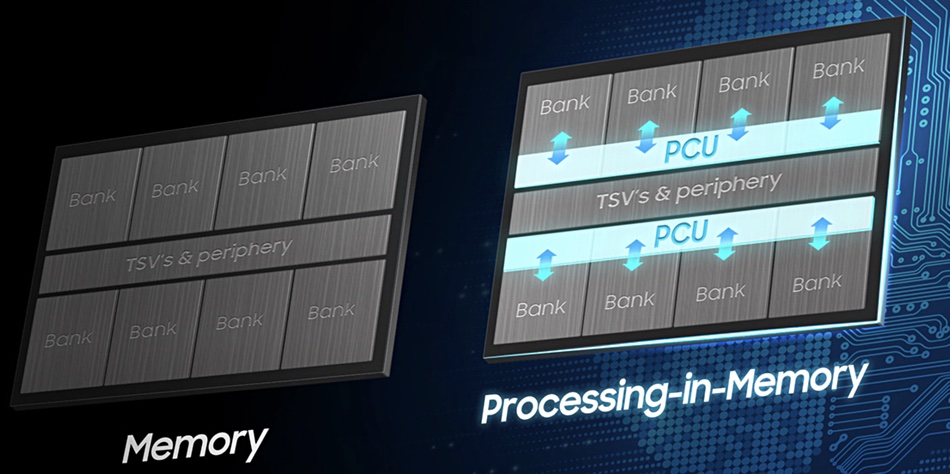
Samsung has announced a high bandwidth memory (HBM) chip with embedded AI that is designed to accelerate compute performance for high performance computing and large data centres.
The AI technology is called PIM – short for ‘processing-in-memory’. Samsung’s HBM-PIM design delivers faster AI data processing, as data does not have to move to the main CPU for processing. According to the company, no general system hardware or software changes are required to use the technology.
Samsung Electronics SVP Kwangil Park said in a statement: “Our… HBM-PIM is the industry’s first programmable PIM solution tailored for diverse AI-driven workloads such as HPC, training and inference. We plan to build upon this breakthrough by further collaborating with AI solution providers for even more advanced PIM-powered applications.”
A number of AI system partners such as Argonne National Laboratory are testing Samsung’s HBM-PIM inside AI accelerators, and validations are expected to complete by July.
Rick Stevens, Argonne Associate Laboratory Director, said in prepared remarks: “HBM-PIM design has demonstrated impressive performance and power gains on important classes of AI applications, so we look forward to working [with Samsung] to evaluate its performance on additional problems of interest to Argonne National Laboratory.”
Samsung HBVM-PIM graphic.
High Bandwidth Memory
Generally, today’s servers have DDR4 memory channels that connect memory DIMMs to a processor. This connection may be a bottleneck in memory-intensive processing. High bandwidth memory is designed to avoid that bottleneck.
High Bandwidth Memory involves layering memory dies in a stack above a logic die, and connecting the stack+die to a CPU or GPU through an ‘interposer’. This is different from a classic von Neumann architecture setup, which separates memory and the CPU. So how does this difference translate into performance?
Let’s compare DDR4 DIMM with Samsung’s Aquabolt 8GB HBM2, launched in 2018, which incorporates eight stacked 8Gbit HBM2 dies. DDR4 DIMM capacity is 256GB and the data rate is up to 50GB/sec. The Aquabolt 8GB HBM provides 307.2GB/sec bandwidth – six times faster than DDR4 – and 2.4Gbit/s pin speed.
Samsung’s new HBM-PIM is faster again. This design embeds a programmable computing unit (PCU) inside each memory bank. This is a “DRAM-optimised AI engine that forms a storage sub-unit, enabling parallel processing and minimising data movement”. The engine performs half-precision binary floating point computations and the memory die loses some capacity due to each bank having an embedded PCU. This takes up space on the die.
An Aquabolt design incorporating HBM-PIM tech delivers more than twice HBM2 performance for image classification, translation and speech recognition, while reducing energy consumption by more than 70 per cent. (There are several HBM technology generations: HBM1, HBM2, which comes in versions 1 and 2, and also HBM2 Extended (HBM2E.)
A Samsung paper on the chip, “A 20nm 6GB Function-In-Memory DRAM, Based on HBM2 with a 1.2TFLOPS Programmable Computing Unit Using Bank-Level Parallelism, for Machine Learning Applications,” will be presented at the February 13-22 virtual International Solid-State Circuits Conference.
VAST Data was cash flow-positive “going out of 2020” and finished the fourth quarter on a $150m run rate. The high-end all-flash array startup’s revenues in FY2021 ended Jan 31 were 3.5 times higher than FY 2020 and it has not spent any of the $100m raised in its April 2020 funding round.
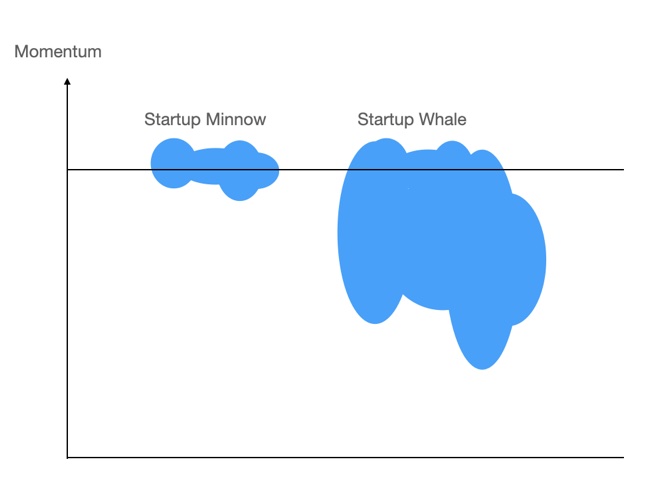
Startups use ‘momentum releases’ as a PR tool to encourage new customers to jump aboard a bandwagon without actually revealing the bandwagon size. Blocks & Files pores over these momentum announcements in an attempt to understand the size of the iceberg below the surface but typically they are bereft of useful information. However, VAST has been a bit more forthcoming than most.
Is VAST a minnow or a whale?
In its press briefing, VAST teased some clues about the size of its business underneath the surface. One concerned the size of customer orders.
Denworth said VAST has just achieved its third $10m-spend account – a customer in the defence sector. He said the company has dozens of $1m customers and is “getting first orders of $5m from customers.”
VAST won its first $10m deal from a hedge fund in December 2019. The customer now has 30PB of VAST storage. The second $10m customer is a large US government agency in the bioinformatics and health sector.
A second clue relates to VAST’s headcount. At the end of fy2021 it was 186. VAST said it is averaging a nearly $1m run rate per employee, which is a tad over-enthusiastic with a $150m run rate. The company wants to hire 200 people in 2021, with Peter Gadd, VP International, aiming to hire 30 to 50 outside North America. He is focusing on Europe and Asia.
A third clue is that VAST compares itself to Pure Storage, saying it has fewer employees than Pure and is growing faster. Denworth characterises Pure as selling medium and small enterprise deals that are susceptible to migration to the public cloud. VAST’s on-premises business deals are more sustainable as they involve larger volumes of data that are difficult to move to the cloud, he claimed.
VAST background and direction
VAST markets its Universal Storage Array as a consolidator of all enterprise storage tiers onto its single scale-out, QLC flash-based platform.The system relies on its software, NVMe-over-Fabrics, Optane SSDs, metadata management and data reduction features to provide high-speed and enterprise disk drive array affordability.
Denworth revealed VAST plans a gen 3 hardware refresh later in the year. He said the company has a single data centre product – we press briefing participants detected hints of smaller VAST arrays coming, cross-data centre metro/geo technology, and some kind of future compute/application processing in the arrays.
VAST Data marketing VP Daniel Bounds said on the press call that VAST ”is building the next great independent storage company.” In other words, its ambition is to dress itself for IPO as opposed to a trade sale.