


A Canadian startup called Untether AI has built tsunAImi, a PCIe card containing four runA1200 chips which combine memory and distributed compute in a single die. We think the technology is representative of an emerging landscape in which general purpose CPUs are giving way to augmentation by specific application processors, most notably by GPUs. Let’s take a closer look.
Untether claims that in current general purpose CPU architectures, 90 per cent of the energy for AI workloads is consumed by data movement, transferring the weights and activations between external memory, on-chip caches, and finally to the computing element itself.
Untether goes further than the GPU approach by spreading app-specific AI processors throughout a memory array in its runA1200 chips.
The runA1200 chip co-locates compute and memory to accelerate AI processing by minimising data movement. Untether says the tsunAImi card delivers over 80,000 frames per second of ResNet-50 v 1.5 throughput at a batch=1 level, three times the throughput of its nearest competitor. Analyst Linley Gwennap says Untether’s “PCIe card far outperforms a single Nvidia A100 GPU at about the same power rating (400W).”
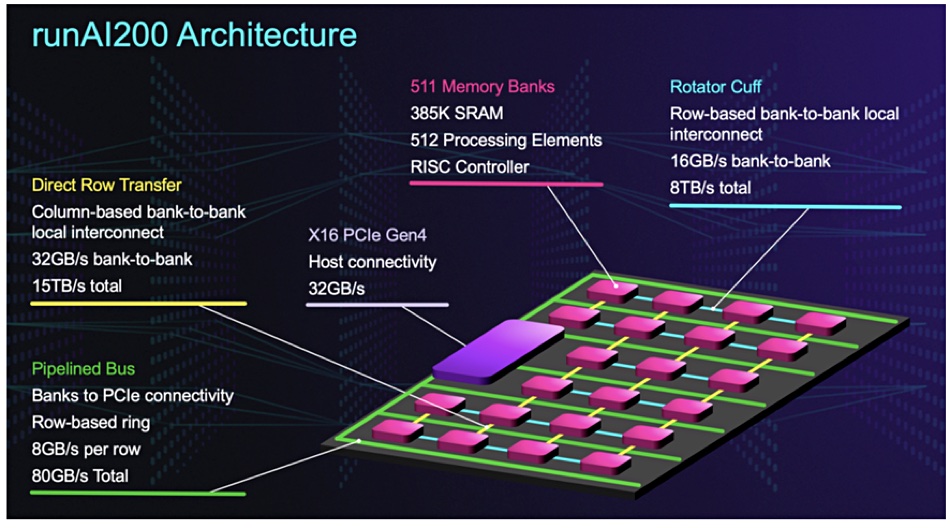
Each unA1200 chip contains 511 memory banks, with the individual bank comprising 385KB of SRAM and a 2D array of 512 processing elements (PEs). Each bank is controlled by a RISC CPU. There are 261,632 PEs in total per runA1200 chip with 200MB of memory, and the chip runs at 502 TeraOperations/sec TOPS or trillion operations per second).
The PEs operate on integer datatypes. Each PE connects to 752 bytes of SRAM such that the memory and the compute unit have the same physical width, minimising wasted die area. The PEs can execute multiply-accumulate operations and also multiplication, addition and subtraction.

Untether envisages its tsunAImi card being used to accelerate various AI workloads, such as vision-based convolutional networks, attention networks for natural language processing and time-series analysis for financial applications.
The Untether card distributes tiny PEs throughout the SRAM, compute being moved to the data, and these PEs are not general purpose CPUs. They are designed to accelerate specific classes of AI processing. We can envisage a purpose-built AI system with a host CPU controlling things and data loaded into the tsunAImi cards across the PCIe bus for relatively instant processing with very little extra data movement needed to get the data into the PEs.
Untether is shipping TsunAImi card samples and hopes for general availability in April-June.
Blocks & Files positions the runA1200 card as a PIM device – Processing In Memory with CPU and memory in a single package.
We envisage tsunAImi cards eventually being hooked to a Compute Express Link (CXL), which supports PCIe Gen 5, and so provide a shared resource pool of accelerated AI processing.




