Zadara has launched a global Federated Edge offering for managed service providers (MSPs), who will sell private cloud services to their customers using Zadara’s global infrastructure and so fend off the public cloud giants.
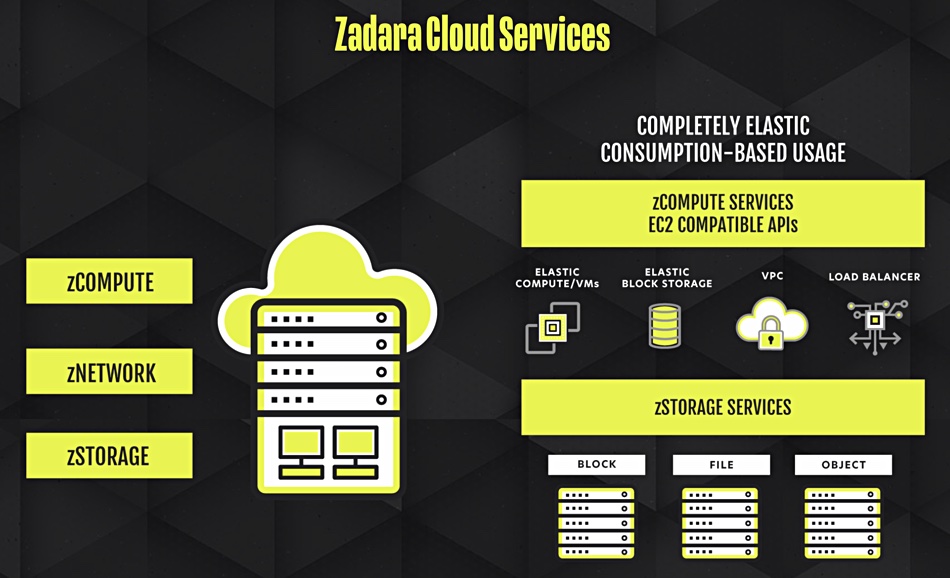
The firm supplies zStorage – on-premises or co-lo storage arrays as a service – zNetwork and zCompute – on-premises servers with VM images – based on its recent acquisition of NeoKarm. The storage, network and compute resources are used on a pay-as-you-go basis.
The idea is that MSPs don’t have to make capital expenditures to set up points-of-presence near their customers. Instead they can use Zadara’s Federated Edge program to provision IT ‘as-a-service’ private cloud offers as close as necessary to those customers’ workloads. Zadara provides all of the hardware and software on a shared revenue basis.
Nelson Nahum, Zadara’s CEO, said in a statement: “We strive to be a true partner to MSPs, not just a technology provider. We understand their unique challenges and have designed the Federated Edge Program with their specific needs in mind…[It] harnesses the collective power of MSPs, where the whole is greater than the sum of its parts.”
Zadara graphic.
All the infrastructure – servers, network and storage – is provided and available on-demand via the Zadara’s Federated Edge network. Operators pay only for usage. Zadara says Federated Edge Zones, or points of presence, available in cities across the world ease concerns around data sovereignty and compliance issues. ;
Dave McCarthy, research manager, edge strategies, for IDC, supplied a supporting statement: “With their Federated Edge, Zadara is providing a lifeline for MSPs looking to boost their points of presence and deploy anywhere in the world the same way that they deploy in their own data centres.
“Latency requirements, cost considerations, operational resiliency, and security/compliance factors all contribute to the need to deploy infrastructures closer to where data is generated and consumed – at the far edge of a networks’ reach, away from the centralised cloud.”
Dell is developing a managed storage service with Project APEX. It’s not much of a stretch to see APEX including PowerEdge servers as a service too. Pure Storage has a similar deal through Equinix.
Public cloud suppliers have started supplying on-premises kit. For example, Amazon with Outposts, and Azure with its Azure Stack which is supported by Dell EMC and Pure Storage.
Zadara is responding to this increased competition by recruiting MSPs to act as service channel partners and suggesting they can get closer to customers and offer more tailored services than the cloud titans.
Zerto made three announcements at ZertoCon 2021 today: Zerto Backup for SaaS; support for Kubernetes; and expanded AWS backup services. The disaster recovery specialist also outlined features of its next major software release, Zerto 9.0.
Zerto Backup for SaaS (ZBaaS) runs on a secure private infrastructure, that delivers – the company says – data immutability, compliance, and guaranteed data availability. The service uses technology from Copenhagen-based Keepit to support Microsoft 365, Dynamics 365, Salesforce, and Google Workspace.
David Osman, Zerto director, technology alliances, said in a statement: “The cloud has enabled people to do business anywhere and at any time, resulting in more critical data constantly being placed in the cloud. The problem is that leaving SaaS backup as an afterthought can result in debilitating loss, especially since most SaaS vendors do not provide this critical service as a standard inclusion.”
Frederik Schouboe, Keepit CEO, said his company was “excited to partner with an industry leader like Zerto and … thrilled our platform is being recognised for true cloud SaaS data protection and management, with added capabilities like archiving, eDiscovery, and open APIs.”
ZBaaS features granular recovery, data availability outside the normal production data centre, and an independent secure data backup stored at a different location for added ransomware protection.
Z4K
Zerto for Kubernetes (Z4K) takes Zerto’s continuous data protection technology to Kubernetes-orchestrated containers, providing backup and disaster recovery for on-premises and public cloud workloads. Z4K supports Microsoft Azure Kubernetes Service (AKS), Amazon Elastic Kubernetes Service (EKS), Google Kubernetes Engine (GKE), IBM Cloud Kubernetes Service, and Red Hat OpenShift.
Kubernetes’ CSI interface has opened the door to widespread container data backup competition. Zerto has joined the fray to jostle with Commvault’s Metallic, Druva, HYCU, Mayadata, Pure Storage’s Portworx-based technology, Replix, Robin, Trilio, Veeam’s Kasten acquisition and more.
Zerto 9.0, the next major software release, will add disaster recovery across AWS Regions or Availability Zones; backup to S3-compatible storage such as Cloudian HyperStore; cloud tiering for AWS and Azure; and immutability in the public cloud.
Gil Levonai, Zerto CMO, said in his statement: “Zerto and AWS customers can build cloud-native solutions and infrastructure, underpinned by a single solution that delivers data protection, recovery, and migration of data to and across AWS.”
Organisations hit limits when trying to replicate thousands of Elastic Compute Cloud (EC2) instances across AWS Regions, according to Zerto. Zerto’s DR for AWS will improve volume replication concurrency across regions, use data APIs to reduce reads and writes, and optimise orchestration workflows to complete RPOs and RTOs in minutes without using agent software.
A Zerto spokesperson said: “Zerto DR for AWS is aimed towards protecting EC2 instances cross-region and cross availability zones. The focus for us was to deliver a solution that can protect at scale, this means an RPO of 15 mins when protection up to a 1000 EC2 instances across regions/zones. “
Cloud tiering for AWS and Azure tiers cloud data from online frequent access storage classes into cheaper infrequent access storage classes all the way through to archive storage such as Amazon S3 Glacier and Azure Archive. Users define retention policies in Zerto.
Immutability settings for backups in AWS can be managed within the Zerto UI to set how long backups can remain unaltered. This is intended to safeguard cloud backups against ransomware and its malicious deletion or modification of data.
Other new features include Enhanced Backup Management, Instant VM Restore From journal and File Restore from LTR.
Zerto 9.0 is available in beta test and is generally available in July 2021.
Computational storage – adding compute capability to a storage drive – is becoming a thing. NGD, Eideticon, ScaleFlux have added compute cards to SSDs to enable compute processes to run on stored data, without moving that data into the host server memory and using its CPU to process the data. Video transcoding is said to be a good use case for computational storage drives (CSDs).
But how does the CSD interact with a host server. Blocks & Files interviewed ScaleFlux’s Chief Scientist, Tong Zhang, to find out.
Tong Zhang
Blocks & Files: Let’s suppose there is a video transcoding or database record processing application. Normally a new video file is written to a storage device in which new records appear in the database. A server application is aware of this and starts up the processing of the new data in the server. When that processing is finished the transformed data is written back to storage. With computational storage the overall process is different. New data is written to storage. The server app now has to tell the drive processor to process the data. How does it do this? How does it tell the drive to process a piece of data?
Tong Zhang: Yes, in order to off-load certain computational tasks into computational storage drives, host applications must be able to adequately communicate with computational storage drives. This demands the standardised programming model and interface protocol, which are being actively developed by the industry (e.g., NVMe TP 4091, and SNIA Computational Storage working group).
ScaleFlux CSDs
Blocks & Files: The drive’s main activity is servicing drive IO, not processing data. How long does it take for the drive CPU to process the data when the drive is also servicing IO requests? Is that length of time predictable?
Tong Zhang: Computational storage drives internally dedicate a number of embedded CPUs (e.g., ARM cores) for serving drive IO, and dedicate a certain number of embedded CPUs and domain-specific hardware engines (e.g., compression, security, searching, AI/ML, multimedia) for serving computational tasks. The CSD controller should be designed to match the performance of the domain-specific hardware engines to the storage IO performance.
As with any other form of computation off-loading (e.g., GPU, TPU, FPGA), developers must accurately estimate the latency/throughput performance metrics when off-loading computational tasks into computational storage drives.
Blocks & Files: When the on-drive processing is complete how does the drive tell the server application that the data has been processed and is now ready for whatever happens next? What is the software framework that enables a host server application to interact with a computational storage device? Is it an open and standard framework?
Tong Zhang: Currently there is no open and standard framework, and the industry is very actively working on it (e.g., NVMe.org, and SNIA Computational Storage working group).
ScaleFlux CSD components.
Blocks & Files: Let’s look at the time taken for the processing. Normally we would have this sequence: Server app gets new data written to storage. It decides to process the data. The data is read into memory. It is processed. The data is written back to storage. Let’s say this takes time T-1. With computational storage the sequence is different: Server app gets new data written to storage. It decides to process the data. It tells the drive to process the data. The drive processes the data. It tells the server app when the processing is complete. Let’s say this takes time T-2. Is T-2 greater or smaller than T-1? Is the relationship between T-2 and T-1 constant over time as storage drive IO rises and falls? If it varies then surely computational storage is not suited to critical processing tasks? Does processing data on a drive use less power than processing the same data in the server itself?
Tong Zhang: The relationship between T-1 and T-2 depends on the specific computational task and the available hardware resource at host and inside computational storage drives.
For example, if computational storage drives internally have a domain-specific hardware engine that can very effectively process the task (e.g., compression, security, searching, AI/ML, multimedia), then T2 can be (much) smaller than T-1. However, if computational storage drives have to solely rely on their internal ARM cores to process the task and meanwhile the host has enough idle CPU cycles, then T-2 can be greater than T-1.
Inside computational storage drives, IO and computation tasks are served by different hardware resources. Hence they do not directly interfere with each other. Regarding power consumption, computational storage drives in general consume less power. If current computational tasks can be well served by domain-specific hardware engines inside computational storage drives, of course we have shorter latency and meanwhile lower power consumption.
If current computational tasks are solely served by ARM cores inside computational storage drives, the power consumption can still be less because we largely reduce data-movement-induced power consumption and the low power nature of ARM cores.
Blocks & Files: I get it that 10 or 20 drives could overall process more data faster than having each of these drive’s data be processed by the server app and CPU – but how often is this parallel processing need going to happen?
Tong Zhang: Data-intensive applications (e.g., AI/ML, data analytics, data science, business intelligence) typically demand highly parallel processing over a huge amount of data, which naturally benefit from the parallel processing inside all the computational storage drives.
Comment
For widespread use, CSDs will require a standard way to communicate with a host server so that it can request them to do work and be informed when the work is finished. Dedicated processing hardware on the CSD, separate from the normal drive IO-handling HW, will be needed for this to ensure predictable time is taken for the processing.
Newer analytics-style workloads that require relatively low-level processing of a lot of stored data can benefit from parallel processing by CSDs instead of the host server CPUs doing the job. The development of standards by NVMe.org, and the SNIA’s Computational Storage working group will be the gateway through which CSD adoption has to pass for the technology to become mainstream.
We also think that CSDs will need a standard interface to talk to GPUs. No doubt the standards bodies are working on that too.
Nebulon, which launched its hardware-assisted cloud-defined storage in June last year, has broadened its scope to become a smart infrastructure SaaS supplier providing a better hyper-converged infrastructure (HCI) offering.
The startup’s first product was a Storage Processing Unit (SPU), an add-in, FH-FL PCIe card, with an 8-core, 3GHz ARM CPU plus encryption/dedupe offload engine. This is fitted inside servers and managed through a data management service delivered from Nebulon’s cloud. Server-attached storage drive capacity is aggregated across servers delivering a hyper-converged (HCI) system experience. The company has expanded this remotely-managed storage remits to become a – wait for it – server-embedded, infrastructure software delivered as-a-service.
Nebulon is calling this ‘smartInfrastructure’. CEO Siamak Nazari explained in a statement: “Customers want the cloud experience for their on-premises infrastructure across their core, hosted and edge deployments.”
The company is introducing two reference architecture products, branded smartEdge and smartCore, using Supermicro Ultra servers. The products deliver self-service infrastructure provisioning, infrastructure management-as-a-service, and enterprise shared and local data services. These include dedupe, compression, erasure coding, encryption, snapshots, clones and mirroring in a scale-out storage architecture. smartInfrastructure supports any application: containerised, virtualised and bare-metal, and is available anywhere, from core to edge to hosted data centres.
Nebulon said IT administrators and application owners benefit from simple deployment, zero-touch remote management, easy at-scale automation, AI-based insights and actions, and behind-the-scenes software updates. Zero server resources are used in delivering Nebulon’s enterprise data services, eliminating HCI limitations on server density and keeping 100 per cent of the server CPU, DRAM and network usable for applications.
DPU angle
In essence, Nebulon’s SPU is a type of data processing unit (DPU) or SmartNIC, like the Fungible product and Nvidia’s BlueField SmartNIC, which offloads low-level storage, network and security tasks from the host CPU.
Nebulon – like Fungible and Nvidia – has a composability angle, stating on its website that you can “dynamically compose your infrastructure for your application when combining servers and storage media in a cluster.”
smartInfrastructure details
Nebulon’s smartInfrastructure comprises its ON AI-assisted, cloud control plane which powers the SPU, described as an IoT endpoint-based data plane. This is embedded in a vendors’ application server and used to provide the data services. Nebulon claims the ON service and SPU products can replace an enterprise SAN – so storage is still a prime feature of Nebulon’s offering.
Nebulon SPU
Nebulon provides a catalog of services for different applications. These services will cover the provisioning of O/S and software packages, data volumes and data services for selected compute nodes. A customer’s IT organisation can contribute their own services to the catalogue. Users can then provision on-premises IT infrastructure that includes compute services (servers), the operating system on these compute nodes and its configuration, data storage for the clustered application installed on the servers, and associated data services.
The smartInfrastructure is delivered to customers as a service in the cloud and does not require customer maintenance. Updates to the on-premises infrastructure software components, including data plane, or server drive firmware can be rolled out enterprise-wide by a click of a button.
Nebulon smartCore and Nebulon smartEdge are reference architectures under the smartInfrastructure solution that are focused on specific deployment scenarios in enterprise data centres or as a hosted solution (smartCore), and at the enterprise edge (smartEdge).
Nebulon infrastructure software is a subscription-based offering. It told us the SPUs/IoT endpoints come as a standard option from the customer’s default server vendor.
Takeway
The takeaway message here is that Nebulon smartInfrastructure is server-embedded, infrastructure software and an alternative to hyperconverged infrastructure software. The Nebulon Supermicro reference architecture offerings are available now.
IBM’s quarterly storage hardware revenues have continued their long term decline. In the first 2021 quarter earnings report the company disclosed that “Power and Storage Systems declined,” with Power servers falling by 13 per cent and storage hardware 14 per cent.
Update: story amended reflecting discovery of storage hardware sales number. 21 April 2021.
IBM noted in the earnings presentation yesterday that “Storage and Power performance reflects product cycle dynamics.” Sales of the recently launched FlashSystem 5200 have not pushed storage hardware revenues higher as the product was not fully available in the quarter.
In its first 2021 quarter, ended March 31, IBM reported revenues of $17.7bn, up 1 per cent Y/Y and its first growth quarter after declines in all four 2020 quarters.
IBM segment revenue results:
Cloud and Cognitive Services – $5.4bn – up 34 per cent Y/Y
Global Business Services – $4.2bn – down 1 per cent
Global Technology Services – $6.4bn – down 5 per cent
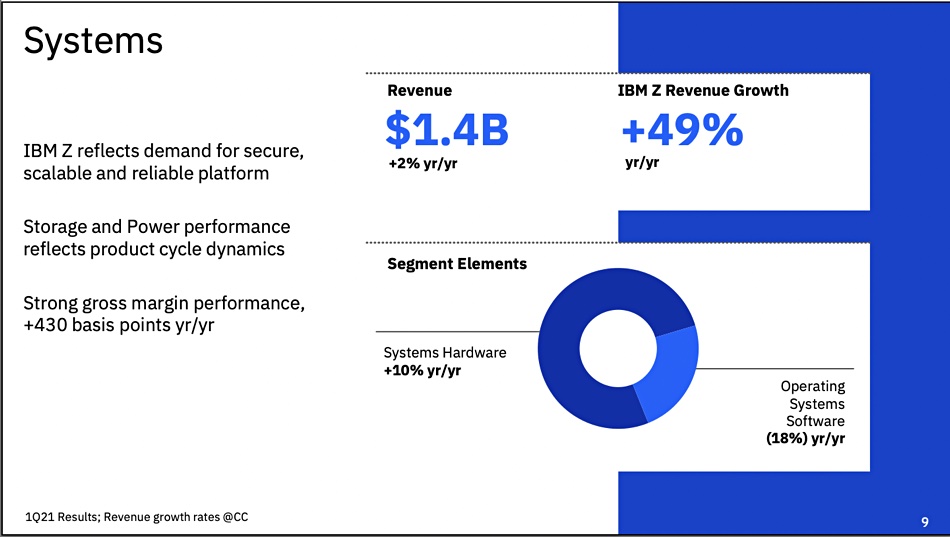
Systems – $1.4bn – up 2 per cent
Global Financing – $240m – down 20 per cent
Within the systems segment, the smallest of its four main business segments, overall hardware revenues rose 10 per cent Y/Y while operating systems software declined 18 per cent. Z mainframe business revenues were up 49 per cent Y/Y, acting as the Systems segment growth engine. CFO James Kavanaugh said in prepared remarks: “That’s very strong growth, especially more than six quarters into the z15 product cycle.’
The sales jump was attributed to customers appreciating mainframe reliability and security in the time of the pandemic with increased online purchases and remote working.
In the earnings report the company disclosed that “Power and Storage Systems declined,” with Power servers falling by 13 per cent and storage hardware 14 per cent. We calculate this to mean storage hardware brought in $359m compared to the year-ago $417.6m.
Storage hardware is a tiny fraction of IBM’s results, representing 2 per cent of its $17.7bn overall revenues.
IBM chairman and CEO Arvind Krishna is concerned with big picture issues, such as spinning off Global Technology Services – Kyndryl – and returning IBM to growth in a hybrid cloud world, using AI, Red Hat and quantum computing.
His prepared remarks included this comment: “We see the hybrid cloud opportunity at a trillion dollars, with less than 25 per cent of workloads having moved to the cloud so far. … We are reshaping our future as a hybrid cloud platform and AI company. … IBM’s approach is platform-centric. Linux, Containers and Kubernetes are the foundation of our hybrid cloud platform which is based on Red Hat OpenShift. We have a vast software portfolio, Cloud Paks, modernised to run cloud-native anywhere.”
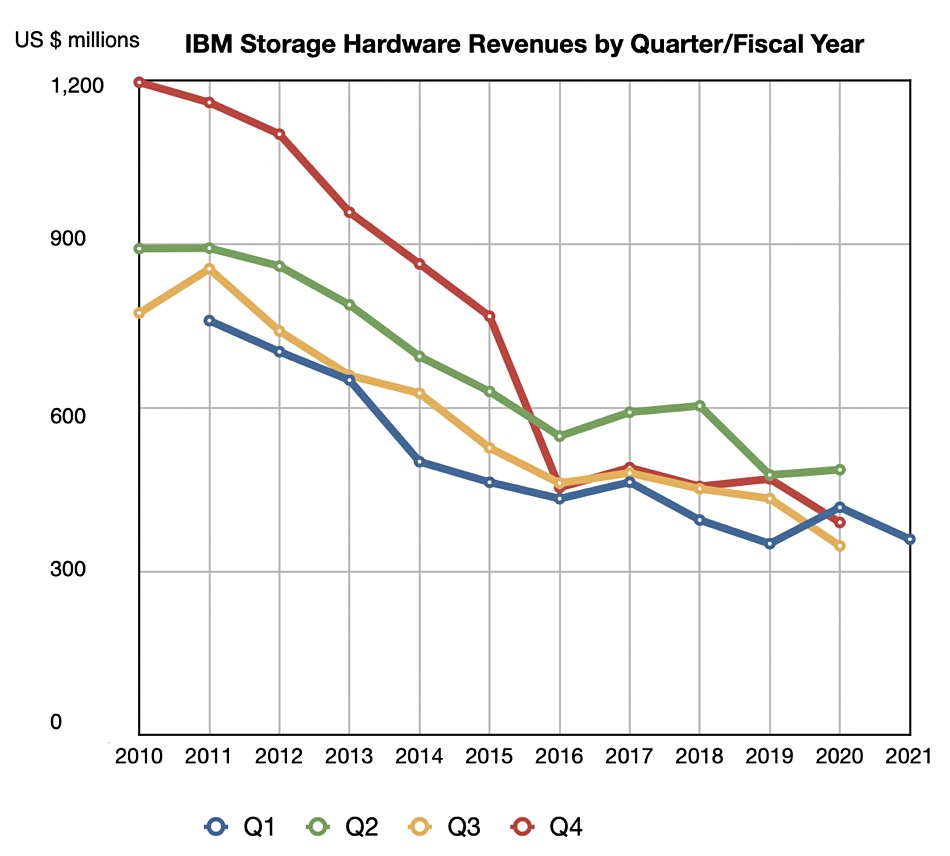
Compared to this multi-billion dollar future, storage hardware, bringing in a few hundred million dollars, is small and shrinking potatoes. Its sales have seen an overall consistent and long-term decline, as a chart showing them by quarter each year shows;
There have been transitory storage hardware revenue rises, for example, one from Q1 2019 to Q1 2020, but that has not been repeated over the Q1 2020 to Q1 2021 period. Instead there has been another decline of 14 per cent.
IBM also sells storage software, such as Spectrum Scale, and storage services such as its IBM Cloud Object Storage. There is also a storage element in Red Hat’s sales. These various storage software revenues are not aggregated and revealed by IBM, and so we cannot know how IBM’s total storage business; hardware and software, is doing. All-in-all, it is a confusing and incomplete picture with a disappointing storage hardware element.
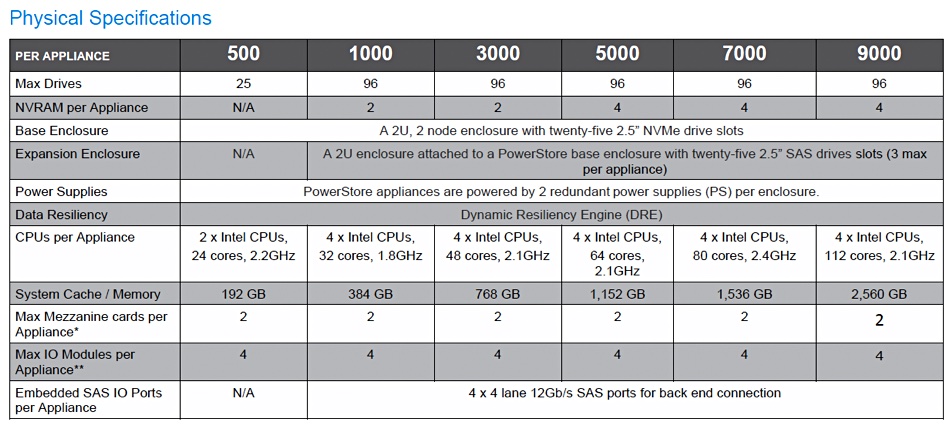
Dell Technologies has announced a PowerStore 500 entry-level system and updated PowerStore software with performance enhancements.
Jeff Boudreau, GM of Dell Technologies infrastructure solutions group, proclaimed today: “PowerStore is the fastest-growing new architecture in Dell history. With today’s announcements, we’ve made PowerStore faster and smarter while making it easier for a broader range of businesses to get started with the platform.”
PowerStore, Dell EMC’s mid-range unified file, block and VVOL storage array, made its debut in May 2020. The product line up is the successor to the existing Unity product line and its capabilities converge with the XtremIO all-flash arrays. Dell EMC had already folded the functionality of Compellent SC array – yet another midrange product – into the Unity line. PowerStore sales were initially slow and HPE, NetApp and others played down its chances as they pounced on a product transition opportunity.
However, Dell in February reported that PowerStore was positioned for strong growth, and would help return company-wide storage revenues to growth after two years of decline. Today the company, said it has experienced fourfold PowerStore sales growth Q-on-Q in the most recent quarter, without providing any figures for us to compare.
PowerStore bezel.
Let’s take a run-through today’s Powerstore announcements.
Powerstore software
PowerStore OS 2.0 adds:
Performance improvements with up to 25 per cent more IOPS on PowerStore 5000 with a 70/30 random read/write mix with 8K block size and writes up to 60 per cent faster.
NVMe over Fibre Channel (NVMe-FC) using 32Gbit/s Fibre Channel, with no additional hardware needed, providing end-to-end NVMe access,
The AppsON run-virtual-machines-in-the-array feature has been extended to operate in clusters of up to four PowerStores with apps moveable between the nodes.
A single stretched vVols container spans appliances and presents a single pool of storage available to all cluster nodes.
A 4:1 average data reduction rate, with hardware assist and larger dedupe cache, guaranteed across customer applications with data reduction limited at times of the heaviest IO. Machine learning capabilities track and manage deduplication at times of the heaviest IO, providing up to 20 per cent more IOPS during peak bursts with no impact on data reduction ratios.
Better high-availability with dual-parity Dynamic Resiliency Engine (DRE) protecting against dual drive failures and needing up to a claimed 98 per cent less management effort than traditional RAID configurations.
Smarter tiering with metadata stored on Optane storage class memory (SCM) and data on NVME drives, speeding metadata access for up to 15 per cent lower workload latency with just a a single Optane drive.
The AppsON extension provides additional compute power for storage-intensive applications at the edge in areas such as healthcare and big data analytics.
PowerStore 500
Dell EMC has added a lower-cost, all-flash PowerStore 500 to the existing 1000, 3000, 5000, 7000 and 9000 models. They all have dual controllers, each with two Intel CPUs and increasing core counts up the range. The 2 rack unit 500 has a single Intel CPU per controller.
PowerStore range summary.
It also has the lowest maximum raw capacity, at 384TB. The next model in the range, the 1000, has 898.6TB. A cluster of four PowerStore 500s supports up to 1.2PB of raw capacity, with the 4:1 dedupe bulking that out to 4.8PB.
Customers can add PowerStore 500 to existing PowerStore clusters.
An Anytime Upgrades feature lets customers enhance or expand their PowerStore performance and capacity after 180 days of ownership. This requires purchase of a minimum 3-year ProSupport Plus with Anytime Upgrade Select or Standard add-on option at point of sale to qualify.
The non-disruptive PowerStore software updates will be available for download on June 10, 2021 and the PowerStore 500 will be available for ordering on May 4, 2021 with shipments starting June 10, 2021.
Comment
The combination of a performance-tuned IO stack, Optane metadata caching, NVMeFC access and a lower cost PowerStore 500 will significantly add to the competitive pressure that Dell EMC can bring to the mid-range array arena. We might expect that the win rates against PowerStore seen by HPE, Hitachi Vantara, IBM, NetApp, Pure Storage and others will take a downturn.
SaaS data protector Druva has raised $147m in an eighth funding round at a $2bn-plus valuation, and taking the total raised to $475m. The company will use the cash to develop its business in APAC and EMEA.
Jaspreet Singh
Jaspreet Singh, Druva co-founder and CEO, said today in a press statement: “The unprecedented events of 2020 have ushered in a generational cloud transformation for businesses, and data‘s increasing value is at the very heart of it. Druva pioneered the cloud data protection category almost a decade ago … This investment and our continued, rapid growth is further validation of our vision for a simple, open, and unified data protection and management platform.”
The SaaS backup trend has strengthened as has public cloud use and Druva’s business has grown in sync, as it were. Competitors such as Clumio, Cohesity, Commvault and HYCU, have entered the SaaS market and Druva has decided it need to grow as fast as it can to maintain its position in the market.
Gartner predicts public cloud services adoption will reach a five-year compound annual growth rate (CAGR) of 20.7 per cent from 2019 to 2025. The tech analyst firm also forecasts that 40 per cent of organisations will supplement or completely replace traditional backup applications with public cloud-based systems by 2022.
Druva is seeing rising demand and wants to rapidly scale in response. It told us it plans to grow its presence in APAC and EMEA regions, such as Australia, New Zealand, and the Nordics. A spokesperson said: “These regions are increasingly turning to the cloud to improve business operations, drive agility, and scale with changing needs,” and pointed out;
According to IDC, APAC is expected to have the highest revenue growth rate for cloud system and service management software between 2020-2024.
More than 80 per cent of IT decision-makers in the Nordic region estimate that the use of cloud services will increase in the near future.
Comment
Druva believes that expanding its footprint in these regions will provide an opportunity to grow its business faster than otherwise. We think that it is facing rising competition from well-funded and strong companies and needs to grow quickly to avoid being swamped and overtaken by them.
An IPO is a possible eventual outcome and Druva will have to have demonstrated it can survive and prosper against the likes of Cohesity, Commvault, HYCU and Veeam.
The headline story in this week’s storage digest is concerns NGD’s computational storage drives reducing deep neural net training time by up to two thirds. That’s a new use for such drives.
DNNs are deep neural nets and it can take days or weeks to train a neural network to an acceptable accuracy level. Distributing the training across a GPU cluster shortens this time but at the expense of much greater electricity usage.
Using CSDs means all the training procedures can be done on these drives, reducing data movement. Only the final parameters, significantly smaller in size than the raw input data, are shared with other nodes.
The paper cites the use of Stannis, a DNN training framework that works better than existing distributed training frameworks by dynamically tuning the training hyperparameters in heterogeneous systems to maintain the maximum overall processing speed in term of processed images per second and energy efficiency.
Experimental results on image classification training benchmarks show up to 3.1x improvement in performance and 2.45x reduction in energy consumption when using Stannis plus NGD drives compared to the generic systems.
Shorts
Italian cloud provider Aruba has introduced a managed Database as a Service (DBaaS) which increases the computational resources available as a database grows. It features transparent costs with breakdown of spending, which can be monitored at any time. Aruba DBaaS is available in two plans, both billed monthly: shared DBaaS, for “non mission critical” applications; and dedicated DBaaS, for production environments with guaranteed computational resources. Both plans include one public IP address, seven daily backups and optional backups on demand.
DDN has launched its certified DDN and NVIDIA joint offering for AI integration use cases, consisting of pre-integrated configurations of DDN’s A3I (Accelerated, Any-Scale AI) system and NVIDIA’s DGX A100 systems. This is sold through distributor Arrow Electronics.
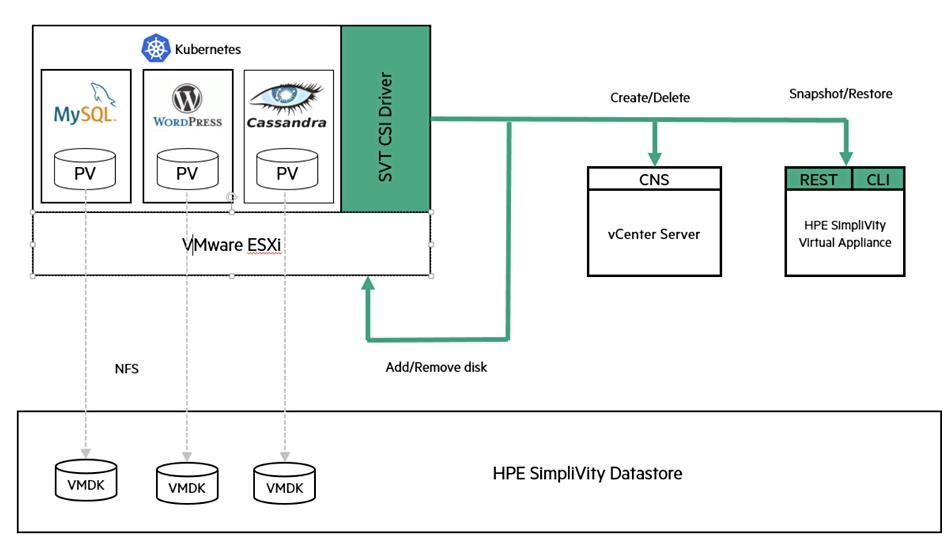
HPE has added a Container Storage Interface (CSI) plug-in forSimpliVity HCI systems. Users can provision SimpliVity storage to Kubernetes containers by creating and using the persistent storage on the same datastore used by their virtual machines. The plugin uses an internal REST API to create and restore persistent volume snapshots in a SimpliVity datastore. It enables users perform static and dynamic provisioning, create volume snapshots, and perform a number of other HPE SimpliVity operations.
HPE SimpliVity CSI plug-in diagram..
At its 18th Global Analyst Summit last week, Huawei announced several changes to boost business resilience, optimise its portfolio in software capabilities and components for intelligent vehicles, and focus on developments to address energy consumption and supply chain challenges. William Xu, head of Huawei’s Institute of Strategic Research, discussed moving beyond von Neumann architecture to build 100x denser storage systems.
Kioxia announced its CM6 SSDs, which have a PCIe 4.0 NVMe interface, are certified by Nvidia for use with its Magnum IO GPUDirect Storage. GPUDirect enables stored data to move directly from an SSD in a host system to an Nvidia GPU server without having to be moved to the host system’s memory by a system software IO stack running in the host’s CPU. This CPU-bypass technology greatly increases data transfer speed to Nvidia’s GPUs.
Pure Storage last week said its annual subscription services revenue, which includes Pure as-a-Service and Evergreen and makes up more than 30 per cent of total revenues, exceeded $500m in FY21, representing 33 per cent Y/Y growth.
Robin.io, which builds its Cloud Native Storage (CNS) software to provision storage to Kubernetes-orchestrated containers, says its CNS product is now available on a pay-as-you-go basis in the Red Hat Marketplace. Payment is for hourly periods and the product runs on Red Hat OpenShift..
Chinese supplier TerraMaster has announced its D5-300 5-bay RAID storage designed for professionals working in small office/home office (SOHO) setups. It comes with up to 90TB of capacity and USB 3.1 Gen1 Type-C capable of reaching speeds of up to 220MB/sec. It’s priced at $269.99.
TerraMaster D5-300
Wasabi Cloud Storage has announced the launch of its new centralised management system for channel partners, Account Control Manager. They can now automate cloud storage account creation, management and user billing and get increased administrative simplicity, reduced time-to-market for new cloud storage offerings, and new data-driven utilisation insights to make better capacity decisions.
Analysis Nvidia has updated its SuperPOD GPU server for AI by adding BlueField DPU support to accelerate and secure access to data. DDN is the first Nvidia-certified SuperPOD-BlueField storage supplier. The road is now open to a BlueField fabric future that interconnects x86/VMware servers, Nvidia GPU servers and shared storage arrays in a composable pool of data centre resources.
Nvidia announced general availability for the BlueField-2 DPU (Data Processing Unit) this week and heralded its powerful successor; BlueField-3, which will sample ship in the first 2022 quarter. DDN has integrated its EXAScaler parallel filesystem array with BlueField-2.
Charlie Boyle, Nvidia’s VP and GM for DGX systems, issued a statement: “The new DGX SuperPOD, which combines multiple DGX systems, provides a turnkey AI data centre that can be securely shared across entire teams of researchers and developers.”
A SuperPOD is a rack-based AI supercomputer system with 20 to 140 DGX A100 GPU systems and HDR (200Gbit/s) InfiniBand network links. An Nvidia image shows an 18-rack SuperPod system;
18-rack Nvidia SuperPOD
DDN has integrated its EXAScaler parallel filesystem array with BlueField-2. NetApp and WekaIO are also supporting BlueField.
The secure sharing that Nvidia’s Boyle refers to, is supplied courtesy of SuperPOD having a pair of BlueField-2 DPUs integrated with each DGX A100. This means that multiple clients (tenants) share access to a SuperPOD system, each with secure data access. It also means that stored data is shipped to and from the DGX A100s across Bluefield-controlled links.
The SuperPOD system is managed by Nvidia Base Command software which provisions and schedules workloads, and monitor system health, utilisation and performance. These can use one, many or all of the A100s in the SuperPOD, facilitation what Tony Paikeday, Nvidia senior director for product marketing, calls “cloud-native supercomputing.”
“IT administrators can use the offload, accelerate and isolate capabilities of NVIDIA BlueField DPUs to implement secure multi-tenancy for shared AI infrastructure without impacting the AI performance of the DGX SuperPOD.”
BlueField and x86 servers
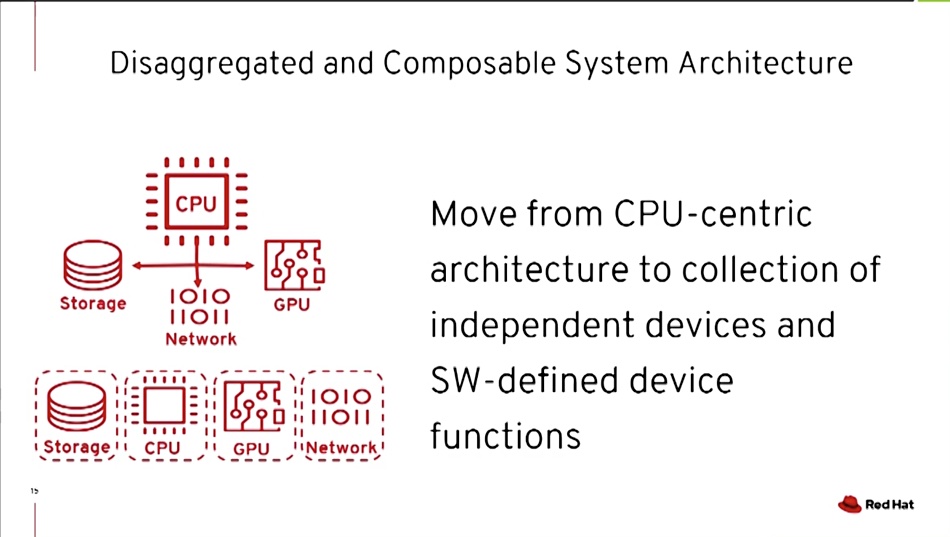
Last September, VMware signalled its intention to support BlueField via the company’s Project Monterey. This entails vSphere handling networking and storage IO functions on the BlueField Arm DPU, and running applications in virtual machines on the host x86 servers. At the time, Paul Perez, Dell Technologies CTO, said: “We believe the enterprise of the future will comprise a disaggregated and composable environment.”
Red Hat is also supporting BlueField with its Red Hat Linux and OpenShift products. A blog by three Red Hat staffers states: “In this post we’ll look at using Nvidia BlueField-2 data processing units (DPU) with Red Hat Enterprise Linux (RHEL) and Red Hat OpenShift to boost performance and reduce CPU load on commodity x64 servers.”
Red Hat Enterprise Linux 8 is installed on the BlueField card, along with Open vSwitch software, and also on the host server. The Red Hat authors write: “The BlueField-2 does the heavy lifting in the following areas: Geneve encapsulation, IPsec encapsulation/decapsulation and encryption/decryption, routing, and network address translation. The x64 host and container see only simple unencapsulated, unencrypted packets.”
They say: “A single BlueField-2 card can reduce CPU utilisation in an [x86] server by 3x, while maintaining the same network throughput.“
A video of a presentation by Red Hat CTO Chris Wright at Nvidia’s GTC’21 virtual conference, has him discussing composable compute, saying this includes “resource virtualisation and disaggregation”.
A Wright slide shows that composability is on Red Hat’s Bluefield agenda
Wright says Red Hat sees a trend of moving towards a composable compute model where compute capabilities are software-defined.
A BlueField composability fabric
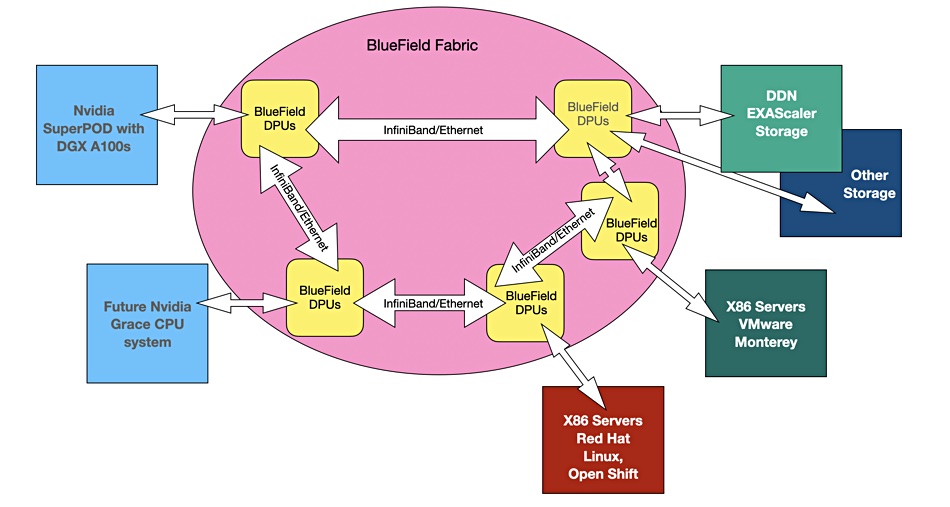
Blocks & Files envisages a Bluefield-managed fabric interconnecting x86 Red Hat and VMware servers, Nvidia’s SuperPOD, other DGX GPU servers, the company’s impending Arm-powered Grace general purpose processing system, and storage – certainly from DDN and probably from NetApp and WekaIO.
Blocks & Filesdiagram of a BlueField composability fabric
BaseCommand will provision or compose SuperPOD workloads for tenants at, we envisage, A100 granularity, with EXAScaler capacity being provisioned for tenants as well. Red Hat and VMware will also provision/compose workloads for their x86 application servers.
We asked Nvidia’s Kevin Dierling, SVP for Networking, about Nvidia and composability. He said: “It’s certainly real.” His session at GTC21 with Chris Wright “specifically talks about the composable data center.”
At this early stage of the composable data centre game two suppliers base their offerings on proprietary hardware, while Liqid has a software approach using the PCIe bus. Does the composability burden require speciality hardware? That will become an important question.
NetApp is moving its headquarters a few miles south from Sunnyvale CA to central San Jose. The company is sub-leasing 700 Santana Row from Splunk. and new HQ is half the size of the previous, 702,000 square feet, four-building, HQ in a 21 acre campus, which it has sold for $365m. NetApp said the move is part of its “ongoing transformation, accelerated by the pandemic, and its future of work strategy to thrive in the next normal.”
700 Santana Row
CEO George Kurian said in a statement: “NetApp is evolving to a flexible hybrid work model that allows us to deliver on our strategy to help more organisations put their data to work while further building a winning employee experience.”
“Our constructive approach to the future of work and our new global headquarters will enable us to create a differentiated work experience that empowers our employees to deliver their best team-based work in a more connected space.”
The building’s architects, WRNS Studio, describe the building this way: “700 Santana Row presents a sweeping façade that captures energy of the shopping arcades and creates a gracious elliptical plaza at the terminus of Santana Row’s main axis. A second curve at the building’s upper portion bends southeast, creating a sense of elegant tension between the surfaces, as if a sheet of paper has been ripped and gently pulled in opposite directions.”
They add: “Diaphanous in appearance, the design of the curtainwall softens the eight-story structure and permits abundant natural light into the loft-like interiors.
Santana Row is a prestigious retail, restaurant, hotel, residential and office street in the heart of San Jose. It was developed as a quasi-village in a city, and the eight-storey 700 Santa Row building stands at the south end of the street, facing up the thoroughfare.
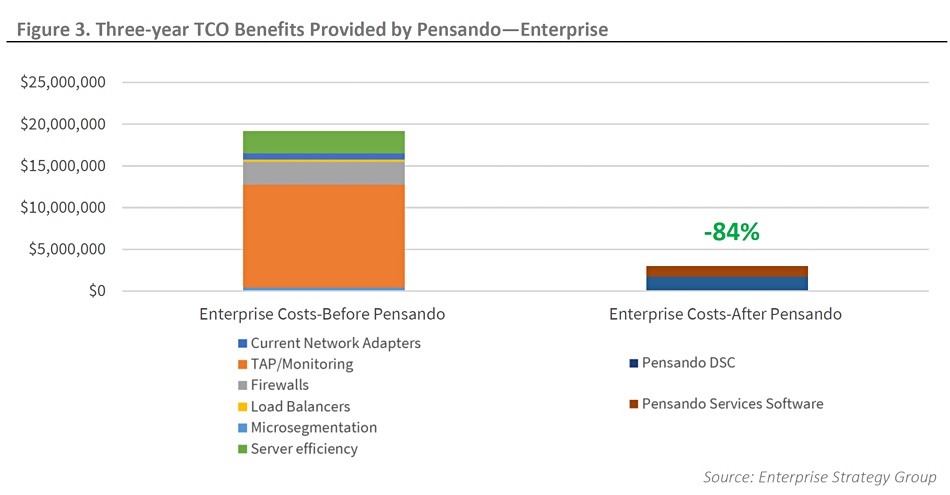
Enterprises with 2,000-plus servers could save up to 84 per cent in various network monitoring and management costs over three years by by using Pensando SmartNIC server offload chips.
This is the headline finding of an Enterprise Strategy Group Economic Validation report, published yesterday: “ESG’s analysis found that Pensando’s scale-out software-defined services approach enabled organisations to centralise management, simplify administration, and optimise performance.”
“Carriers and CSPs have embraced a ‘scale-out’ approach, which enables services to be run on homogeneous, industry-standard server hardware,” ESG adds. “The challenge is that spinning up network or security functions on the generic servers employed by carriers and CSPs burns CPU resources and is generally less efficient and performant than specialty hardware.”
Pensando, a California startup, has built the Arm-powered Naples DSC (Distributed Services Card) which connects to a host server across a PCIe interface. The card offloads and accelerates networking, storage and management tasks from its host server, freeing up the host CPU to run application workloads instead of infrastructure-focused tasks.
Pensando Naples DSC card.
Pensando’s DSC card replaces speciality hardware appliances. Infrastructure services such as security, encryption, flow-based packet telemetry, and fabric storage services are deployed on the DSC at every server. Pensando provides Policy and Services Manager (PSM) software to carry out centralised management. PSM collects events, logs, and metrics from the installed DSCs to speed troubleshooting.
Costs and savings
In its report, ESG notes: ”While at first glance it might seem expensive to implement Pensando hardware and software into each data centre server ESG’s modelled scenarios demonstrate significant savings for both traditional enterprises and cloud service providers.”
In other words the performance and related savings per server are not enough at a server level to justify the Pensando card cost. But the total cost of ownership savings across large fleets of servers, 2,000 and upwards in ESG’s scenarios, over three years make the expense of buying Pensando cards worthwhile.
The ESG researchers modelled two scenarios, an enterprise data centre with 2,000 servers each fitted with a DSC card, and a cloud services provider with 20,000 similarly equipped servers.
ESG Enterprise model.
ESG calculated the costs of network adapters and monitoring appliances, east-west firewalls, load balancers, micro-segmentation nodes, and their associated license fees and operational expenditures (Opex). These were summed over three years and compared with the same servers fitted with Pensando DSCs and services software.
In the enterprise model and over three years, ESG’s model predicts a total three-year savings of $16,180,092, or 84 per cent. In the cloud services provider model ESG’s model predicts total three-year savings of $104,456,894, or 64 per cent. These are large numbers and suggest that enterprises and CSP with a thousand-plus servers might be well-advised to look at the costs and benefits of using Pensando DSCs in their data centres.
Amazon Web Services is bringing compute closer to its RedShift cloud data warehouse storage to accelerate query processing by 10x.
The cloud giant has created a hardware-accelerated caching/CPU offload facility called AQUA – short for Avanced Query Accelerator. The technology emerged in December 2019 and it has taken nearly two years for AWS to bring it to general availability.
Rahul Pathak, AWS’VP for Analytics, said in a statement: “By bringing compute to the storage layer, AQUA helps customers eliminate unnecessary data movement to avoid these networking bandwidth limitations, delivering up to an order-of-magnitude query performance improvement over other enterprise cloud data warehouses.”
Data warehousing has relied upon data being moved from a shared storage facility to many compute nodes where it is processed in parallel, according to AWS. Redshift queries run in this way; a scale-out design. Because the volume of data has increased so much the data movement saturates the available network bandwidth and slows down processing.
There is a second problem in that the processors in the compute nodes are too slow. “CPUs are not able to keep up with the faster growth in storage capabilities (SSD storage throughput has grown 6x faster than the ability of CPUs to process data from memory),” AWS says.
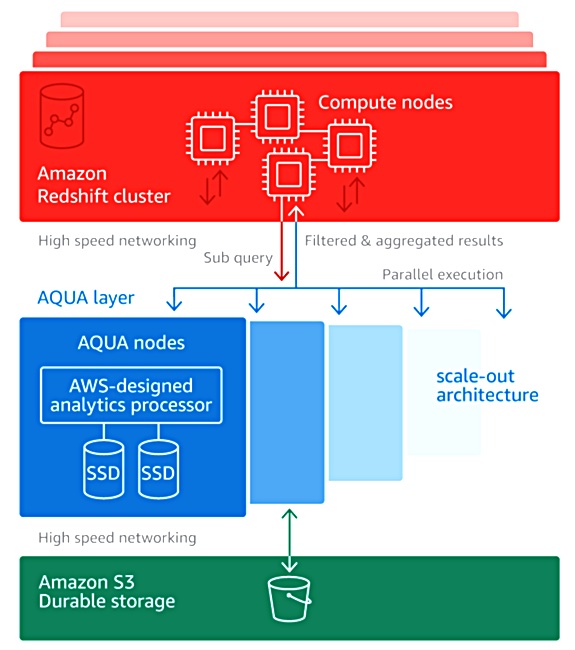
A hardware module, the AQUA Cache, has been added to each Redshift RA3 (SSD-based) node. This contains AWS-designed analytics processors which accelerate data compression, encryption, and data processing tasks like scans, aggregates, and filtering.
AQUA Diagram.
AWS Chief Evangelist Jeff Barr in a blog post explains that AQUA takes “advantage of the AWS Nitro System and custom FPGA-based acceleration.” The AQUA cache sits in front of S3 storage and AWS tiering/fetching software moves data from S3 into the AQUA Cache’s SSDs. The data is then pre-processed by the AQUA hardware before queries are handled by the Redshift RA3 node CPUs.
Barr writes: “AQUA pushes the computation needed to handle reduction and aggregation queries closer to the data. This reduces network traffic, offloads work from the CPUs in the RA3 nodes, and allows AQUA to improve the performance of those queries by up to 10x, at no extra cost.”
As a result, “the amount of data that must be sent to and processed on the compute nodes is generally far smaller (often just 5 per cent of the original).”
Shamik Ganguly, Senior Manager, Amazon Advertising, issued a statement: “We started using AQUA for Amazon Redshift recently, and it is a game changer. We have seen some of our most complex analytics queries related to attribution, personalisation, brand insights, and aggregation that scan large data sets run up to 10x faster with AQUA.
“AQUA has dramatically reduced the average wait times for some of our most demanding queries enabling us to run 50 per cent more queries on our system while keeping the cost the same resulting in faster time to value and better experience for our customers.”
AQUA is available for Redshift customers only i.e. not for other data warehouses residing in Amazon’s public cloud such as Snowflake and Yellowbrick Data. It will be interesting to see how Redshift query performance compares with its competitors.
AQUA for Amazon Redshift RA3 instances is generally available today at no additional cost, and no code changes are needed for its use. It is available to customers running Amazon Redshift RA3 instances in US East (N. Virginia), US West (Oregon), US East (Ohio), Asia Pacific (Tokyo), and Europe (Ireland), with availability in additional regions coming soon.