


Amazon Web Services is bringing compute closer to its RedShift cloud data warehouse storage to accelerate query processing by 10x.
The cloud giant has created a hardware-accelerated caching/CPU offload facility called AQUA – short for Avanced Query Accelerator. The technology emerged in December 2019 and it has taken nearly two years for AWS to bring it to general availability.
Rahul Pathak, AWS’VP for Analytics, said in a statement: “By bringing compute to the storage layer, AQUA helps customers eliminate unnecessary data movement to avoid these networking bandwidth limitations, delivering up to an order-of-magnitude query performance improvement over other enterprise cloud data warehouses.”
Data warehousing has relied upon data being moved from a shared storage facility to many compute nodes where it is processed in parallel, according to AWS. Redshift queries run in this way; a scale-out design. Because the volume of data has increased so much the data movement saturates the available network bandwidth and slows down processing.
There is a second problem in that the processors in the compute nodes are too slow. “CPUs are not able to keep up with the faster growth in storage capabilities (SSD storage throughput has grown 6x faster than the ability of CPUs to process data from memory),” AWS says.
A hardware module, the AQUA Cache, has been added to each Redshift RA3 (SSD-based) node. This contains AWS-designed analytics processors which accelerate data compression, encryption, and data processing tasks like scans, aggregates, and filtering.
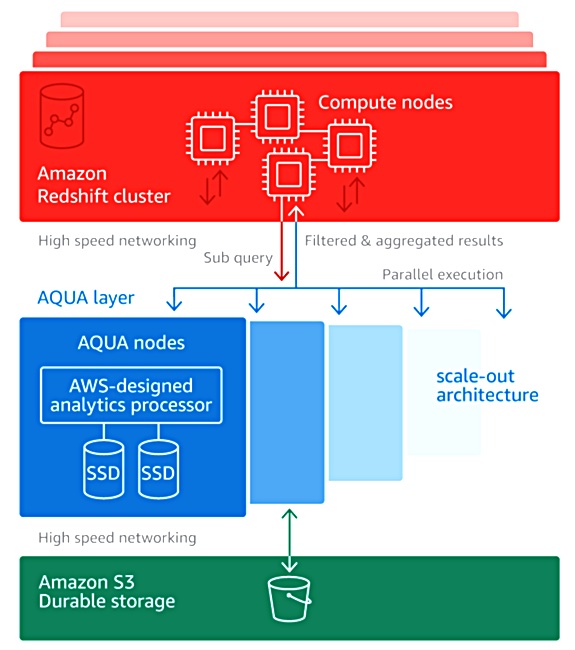
AWS Chief Evangelist Jeff Barr in a blog post explains that AQUA takes “advantage of the AWS Nitro System and custom FPGA-based acceleration.” The AQUA cache sits in front of S3 storage and AWS tiering/fetching software moves data from S3 into the AQUA Cache’s SSDs. The data is then pre-processed by the AQUA hardware before queries are handled by the Redshift RA3 node CPUs.
Barr writes: “AQUA pushes the computation needed to handle reduction and aggregation queries closer to the data. This reduces network traffic, offloads work from the CPUs in the RA3 nodes, and allows AQUA to improve the performance of those queries by up to 10x, at no extra cost.”
As a result, “the amount of data that must be sent to and processed on the compute nodes is generally far smaller (often just 5 per cent of the original).”
An AWS video introduces AQUA technology.
Shamik Ganguly, Senior Manager, Amazon Advertising, issued a statement: “We started using AQUA for Amazon Redshift recently, and it is a game changer. We have seen some of our most complex analytics queries related to attribution, personalisation, brand insights, and aggregation that scan large data sets run up to 10x faster with AQUA.
“AQUA has dramatically reduced the average wait times for some of our most demanding queries enabling us to run 50 per cent more queries on our system while keeping the cost the same resulting in faster time to value and better experience for our customers.”
AQUA is available for Redshift customers only i.e. not for other data warehouses residing in Amazon’s public cloud such as Snowflake and Yellowbrick Data. It will be interesting to see how Redshift query performance compares with its competitors.
AQUA for Amazon Redshift RA3 instances is generally available today at no additional cost, and no code changes are needed for its use. It is available to customers running Amazon Redshift RA3 instances in US East (N. Virginia), US West (Oregon), US East (Ohio), Asia Pacific (Tokyo), and Europe (Ireland), with availability in additional regions coming soon.





