Israeli startup Polar Security officially emerges from stealth with $8.5 million seed funding to build its technology for automatically discovering and securing businesses’ managed, unmanaged and shadow data.
Polar Security’s release says “It is nearly impossible to see, follow and protect managed and unmanaged data throughout a company’s workloads. Even more problematic, in their push for speed, developers unintentionally create complex trails of “shadow data” — data that security and compliance teams don’t know exists — which presents a significant threat.” Such shadow data can include extremely sensitive business-dependent information, including IaaS databases, logs, backups, debug dumps, and data within operational cloud services.
A statement from Guy Shanny, Polar’s co-founder and CEO, said “To solve data security in the cloud, you must focus on the crown jewels — the data stores holding sensitive data — as fast as developers create new data. We built Polar to help companies automate their data security across known and unknown data stores, to continuously prevent cloud data vulnerabilities and compliance violations at any scale — what was until now an unsolvable challenge.”
The funding round was led by Glilot Capital Partners with participation from IBI Tech Fund, as well as angel investors, including:
Jim Reavis, co-founder & CEO of Cloud Security Alliance;
Tim Belcher, former RSA CTO;
Ann Johnson, former president of Qualys;
Tom Noonan, co-founder & CEO of Internet Security Systems and VP & GM of IBM Security.
Kobi Samboursky, founder and managing partner at Glilot Capital Partners, justified his firm’s investment. “As basic as it seems, many companies don’t know where their data stores are, what’s inside that data, and where that data is going. This is what excites us about Polar Security. By ensuring data stores are secured as well as in compliance with the company’s regulatory policies as soon as they are created, Polar’s technology will become a foundational piece of every CISO’s toolkit moving forward.”
Existing supplier VC-backed startup Securiti offers shadow data discovery as part of its AI-powered data privacy and security technology. It was started up in November 2018, and has pulled in $81 million in four rounds of funding, including funding from Cisco Investments in April last year. It claims its product suite is the world’s first PrivacyOps platform that helps automate all major functions needed for privacy compliance in one place.
Comment
Polar Security is building technology to discover data that an organisation doesn’t know it has — shadow data — and then secure it and ensure regulatory compliance. Its use represents another cost for its customers and will be justified by the avoidance of fines for not being compliant and, harder to cost-justify, prevention of data loss.
No business knows the extent of its shadow data and Polar will have to discover a fair chunk of it to justify its use, particularly its ongoing use, in an as-a-service deal for example. How a company can not know about backups seems a little far-fetched but, presumably, Polar has examples. And if it can bring management discipline to a data Wild West, then that will be a good thing.
Diamanti, led by CEO Chris Hickey who was appointed seven months ago, has hired 36 sales and engineering people since he took up the post.
Chris Hickey.
The firm originally supplied hyper-converged system software and pivoted to selling software on which to manage and run Kubernetes-orchestrated software, in which it claims a performance advantage. We noted eight exec departures after Hickey joined and he has been busy replenishing the exec head count as well as building up the customer-facing and engineering ranks.
According to Hickey, “Diamanti is recruiting the top sales and development talent in cloud infrastructure to power our expansion and accelerated product roadmap. … with the most experienced sales and engineering leaders in the industry, we are well positioned to innovate and make the case for the most powerful Kubernetes management platform available.”
Relatively recent exec joiners include:
Jaganathan “JJ” Jeyapaul, CTO/EVP of engineering, ex-Oracle;
Mark Glasgow, SVP of worldwide sales, Oct 2021, ex-Hammerspace and Micron;
Arnaldo Perez, CFO, June 2021.
We also know of:
Amandeep S, SVP global operations. India base, June 2021, ex-Quark like Hickey;
Vivek Gupta, VP engineering, Nov 2021;
Taha Hasan, channel sales manager, Nov 2021, ex-SUSE, Rancher Labs;
Fahem Z, sales director, Nov 2021, ex-SUSE and Rancher Labs;
Foster Nichols, sales director, Aug 2021, ex-Palo Alto Networks;
Paul (Ho) Bae, sales director, Oct 2021, ex-VMware;
Erikjan Franssen, promoted to VP international sales, Nov 2021;
Roger Laing, Kubernetes UK&I exec, Sep 2021;
Gareth Holland, business development rep, Jan 2022;
Halee Enderle, business development rep, Jan 2022.
You can see from the last two that recruitment is ongoing. Diamanti has no exec publicly identified as responsible specifically for marketing but it does have an active Twitter posting account — @Diamanticom — which posts details of new joiners and spreads good cheer. Perhaps a marketing exec hire is on the cards.
LinkedIn says Diamanti has 99 employees it knows about, meaning almost a third are new to the company in the last seven months.
The company has also opened an office at the campus of Stony Brook University, in the Charles B. Wang Center, where it says it “will recruit untapped talent and focus on mentoring the next generation of cloud leaders”.
Glassdoor has some vicious Diamanti reviews from severely disenchanted leavers, but you might expect some of that from departed employees when a new CEO comes on board to turn a troubled company around and makes waves. Then again, they may have a point. We shall have to wait and seee how the company progresses.
Funding-wise Diamanti has taken in a total of $78 million since being founded in 2014. The last round was a $35 million C-round in 2019. Presumably it is burning cash. It may be that Hickey will be able to demonstrate significant sales growth and product development this year and so persuade VCs to stump up more funding to enable accelerated growth in 2023/2024.
Enterprise storage array supplier Infinidat reported 40 per cent year-on-year bookings growth in 2021.
This included an end-of year boost, with 68 per cent growth in the final quarter, and Infinidat says it has accelerated its double-digit growth.
Phil Bullinger.
Phil Bullinger, CEO of Infinidat, who was appointed a year ago, has had a very good year and the board should be happy. He said “It has been a transformational year for the company, and our expansion demonstrates our proven growth strategy and reflects the rapidly increasing demand for Infinidat’s software-defined storage technology. The customer, partner, and product momentum we achieved in 2021 position Infinidat for continued success and growth.”
More than 25 per cent of the Fortune 50 are now Infinidat customers, and Infinidat achieved more than 130 per cent year-over-year revenue growth in the company’s Fortune 100 customer base in 2021. It also increased its channel base in 2021 from under 400 partners to more than 500 — a >25 per cent increase, and achieved close to 90 per cent channel revenue.
Infinidat also hired a slew of new execs in 2021, such as CMO Eric Herzog and EMEA and AJP sales head Richard Bradbury, as Bullinger built up its market-facing capabilities.
Dave Vellante, co-founder of SiliconAngle and chief analyst at Wikibon, provides a fitting end-of-story quote: “The company’s double-digit growth underscores its traction and ability to respond to evolving customer requirements in areas such as cyber resilience. It’s good to see management accelerating Infinidat’s original vision with an approach that has always been non-conventional. That’s what it takes to compete with established incumbents in today’s market.”
Dell Technologies is announcing storage and data protection services across the on-premises and multiple public cloud environments, along with enhanced Kubernetes support for enterprises adopting hybrid multi-cloud and cloud-native app development.
The company believes the mainstream enterprise storage, and systems, market is adopting the hybrid, multi-cloud model with a mix of on-premises and public cloud application deployments. On that basis customers want public cloud-like service deals for on-premises hardware and software, consistent application storage environments across the on-premises and multiple public cloud environments, and consistent support for cloud-native DevOps developers, app development and deployments. This positions Dell as responding to customer concerns and various multiple competitive moves by HPE, NetApp and Pure Storage as well as a group of suppliers offering SaaS backup services.
Jeff Boudreau, Dell Technologies Infrastructure Solutions Group president, was quoted in Dell’s announcement: “Today’s multi-cloud reality is complex as data becomes more distributed across on-premises and colocation datacentres, multiple public clouds and edge environments.”
Dell, he claimed, is uniquely positioned “to help customers take control of their multi-cloud strategy” because “we have the industry’s broadest technology portfolio, consistent tools, experience building open ecosystems and leading data storage capabilities, services and supply chain.”
There are futures here because not everything Dell is talking about is ready. The company is announcing APEX Multi-Cloud Data Services delivering storage and data protection as-a-service with simultaneous access to all major public clouds through a single console. This includes:
APEX Backup Services for SaaS applications, endpoints and hybrid workloads in the public cloud;
Project Alpine to offer Dell’s block and file storage software on the main public clouds;
Enhanced Kubernetes support for DevOps and developer portal.
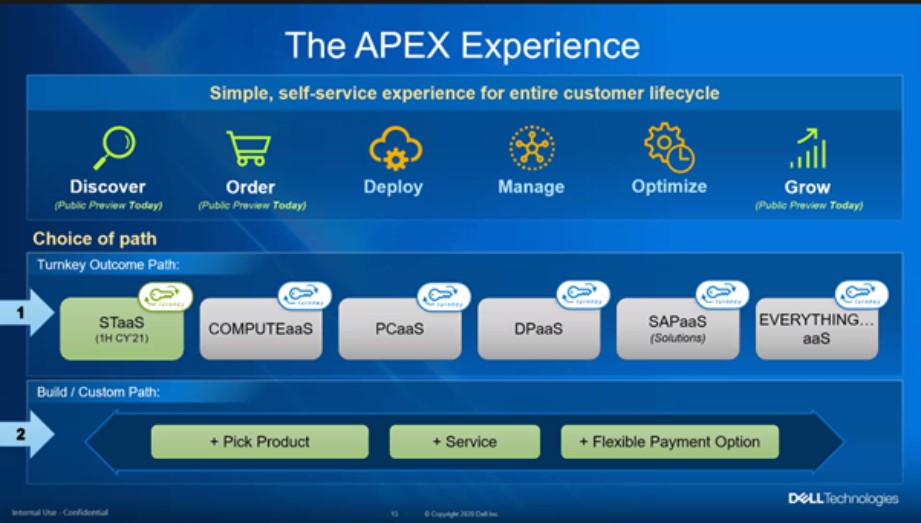
Dell APEX slide, October 2020.
Dell’s APEX initiative was first announced in October 2020 with a set of pay-as-you-go services covering hardware and software products.
The idea is to make the on-premises and public cloud IT worlds similar in terms of IT component delivery, scalability and payment. Dell says APEX Multi-Cloud Data Services, integrated with an APEX Console, will will provide file, block, object and data protection services for simultaneous access to all major public clouds from a single source of data. It will, Dell claims, help avoid public cloud vendor lock-in, excessive egress fees, and the cost and risk associated with moving data from one cloud to another.
Regarding APEX Backup Services, we wrote in April last year, “Dell EMC today officially confirmed backup-as-a-service, built on PowerProtect systems and Druva software. PowerProtect Backup Service supports SaaS applications like Microsoft 365, Google Workspace, Salesforce and other cloud-based workloads, as well as endpoints and hybrid workloads.”
Dell’s Caitlin Gordon, VP for product management, said various ecosystem partners may have roles in the APEX initiative but Dell was not sharing who was providing what technology or services.
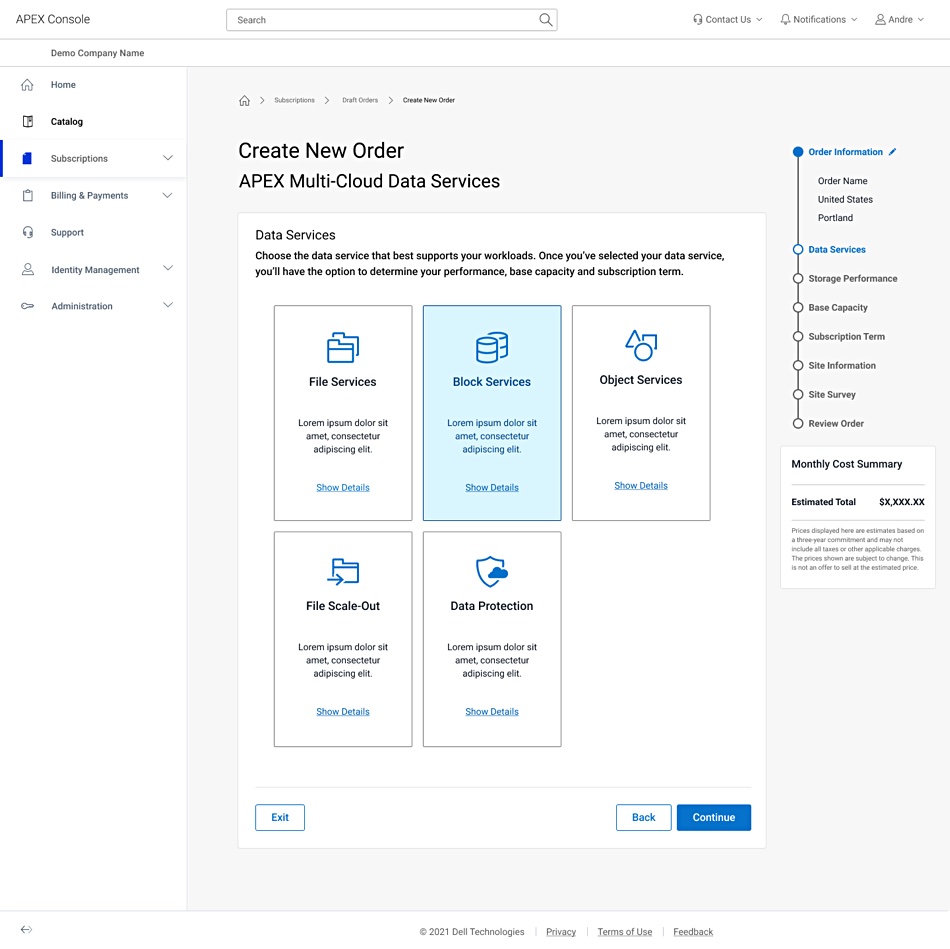
Sample Dell APEX customer order screenshot.
Dell says APEX Backup Services can be deployed in minutes, scales on demand, and protects against cyberattacks with instant detection, rapid response and accelerated recovery.
Project Alpine
This is the future bit, with Dell saying it will build on its data protection cloud offerings to bring the software IP of its block and file storage platforms to leading public clouds. Think AWS, Azure, GCP and the Oracle cloud. Supporting Oracle cloud alongside the others is, we think, unique to Dell. The actual block and file storage software will be based on Dell’s flagship products.
Gordon said “We will be bringing our flagship block and file storage software to the major public clouds. This is really huge for our customers. … Our storage portfolio today is predominantly delivered in purpose-built appliances. Technically, what we’re doing here is we’re abstracting that storage software from that underlying physical hardware. We’re enabling that to run on the general purpose instances that are in the different public clouds.”
We asked, is this PowerStore (block) and PowerScale (file) software? Gordon said “We’re not sharing the specific platforms. … What we have prioritised right now, and the roadmap that very much exists and is being developed, is focused on our two flagship [technologies or products] one in … block, and one in file.”
She added: “This is the beginning of a pretty significant investment focus for us. … We’re going to continue to add more over time.”
How will customers get this technology? Gordon said “We will deliver that based … on both hyperscaler capability as well as market demand … either as software that a customer will manage, or … as a fully-managed service. That could be a Dell service or it could be a hyperscaler service.”
Customers will be able to purchase storage software as a managed service from the various cloud marketplaces, using existing cloud credits. There will be a consistent storage experience across the on-premises block and file and public cloud environments with easy sharing of data across multiple clouds.
We should see milestone announcements from Dell over the next 12 months. However, object storage is not included. Our belief is that object services will eventually be included but there is a problem in that, as Caitlin Gordon said: “In APEX Multi-Cloud Data Services that is ECS object absolutely today [but] in APEX Data Storage Services object is actually based off of the object access in PowerScale.” For consistency one object stack, or both, or a unified object stack, needs to be used.
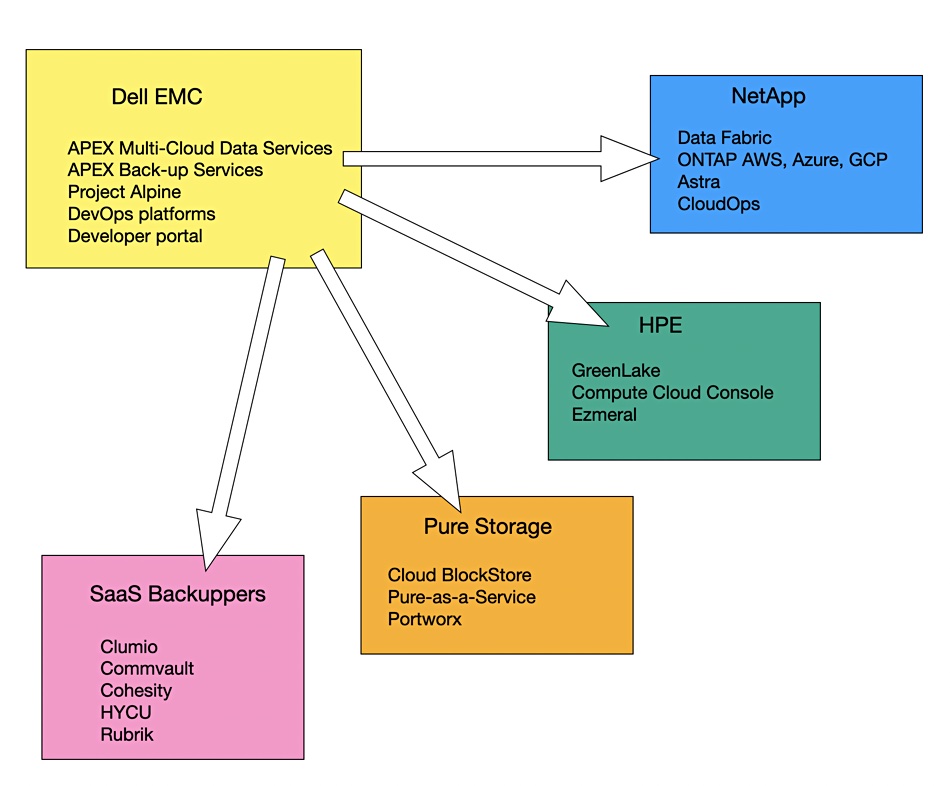
The competitive environment. Blocks and Files diagram.
The obvious competitive comparisons are with NetApp and its OEM deals with the top three public clouds. Pure also has its Cloud Block Store for AWS and Azure.
Kubernetes expansion
Dell is adding increased support for Kubernetes including:
Amazon EKS Anywhere on PowerFlex and PowerStore, enabling customers to run Kubernetes orchestration across public or on-premises clouds;
SUSE Rancher on VxRail, providing multi-cluster, multi-cloud Kubernetes management and giving customers the flexibility to choose their cloud orchestration platform.
The Dell Technologies Developer portal capabilities are being expanded, from a one-stop shop point of view both for developers and DevOps teams. The portal will provide continual access to the latest Dell APIs, SDKs, modules and plug-ins.
Availability
APEX Multi-Cloud Data Services is planned for deployment in the USA, UK, Germany and Australia later this quarter. APEX Backup Services are now globally available.
The previously announced APEX Data Storage Services, which provides Dell-managed enterprise storage as-a-service, is available with colocation services via Equinix International Business Exchange datacentres. It is now available in the United States, United Kingdom, France, Germany, Denmark, Norway, Australia, New Zealand, Spain, Italy, Sweden, Finland, Ireland and Singapore.
APEX Cloud Services with VMware Cloud, also previously announced, is now available in the USA, UK, France and Germany.
Flash fabber Kioxia is sampling a thinner and denser phone flash drive, saying it has faster read and write speeds — but with no details about that, its 3D layer count, or its thickness.
Update. Kioxia response to questions added – 21 January 2022. See end of article.
It is a a proof-of-concept (PoC) device for phones needing to work in 5G environments and handle 4K plus video and high-res photos, and uses QLC (4bits/cell) NAND.
Axel Stoermann, VP memory marketing & engineering for Kioxia Europe, issued an announcement statement, discussing “expanding our already broad lineup with new UFS Memory products for applications that demand superior interface performance. With QLC UFS we can offer another solution which will meet the increasing requirements for Flash memory devices.”
Kioxia has followed up its August 2021 phone memory card announcement, in which it promised faster phone drives built with its BiCS 5 (112-layer 3D NAND) and adhering to the UFS 3.1 standard. It then said the card improved performance by 30 per cent for random reads and 40 per cent for random writes.
Today’s news is equally light on details. Faster than what? Thinner than what? Kioxia does not say.
We guesstimated that meant around 2GB/sec sequential read bandwidth and 1GB/sec sequential write bandwidth back in August. Today’s news merely says the QLC drives use 1Tbit dies, and “For applications needing high density, such as cutting-edge smartphones, Kioxia’s QLC technology enables the capability to achieve the highest densities available in a single package” — meaning 512GB.
Let’s not get too excited at that 512GB.
Kioxia fab partner Western Digital announced a Gen 2 UFS 3.1 drive in June last year with 128, 256 and 512GB capacities.
Back in March 2020, Kioxia was sampling a UFS v3.1 card built with BiCS 3 3D NAND technology, meaning 64 layers, and, we understand TLC (3bits/cell) at 128GB, 256GB, 512GB and 1TB capacities. Here we are, 22 months later, two BiCS generations later, and with one more bit per cell, yet capacity has dropped back to 512GB — when it could, we estimate, have reached 2TB. Presumably the phone makers don’t need that much capacity.
We think that using QLC flash means Kioxia has had to overcome inherently lower QLC speeds, compared to the prior or existing TLC flash. By not releasing performance numbers it leaves the door open to doubts about the actual read and write speeds achieved.
Kioxia could say it’s using an SLC write cache, as partner WD revealed back in June, yet it does not.
Here is the table we used in August last year to try and work out what Kioxia’s UFS product technology speeds are:
For now we’ll stick at the 2GB/sec sequential read bandwidth and 1GB/sec sequential write bandwidth for the new drives, and hope more details will come through later.
Kioxia says it is sampling its 512GB QLC UFS PoC devices to select OEM customers.
Update
We asked Kioxia for performance details and why it hadn’t built a 1TB device.
A spokesperson said the answers to our spec questions are confidential, and: “This 512GB QLC UFS device is just for sampling as Proof of Concept, for customers to assess if QLC-based UFS can be a viable solution for their applications (in terms of performance/etc), and for what [use] cases…for Smartphones in particular.
“This will also help us to assess the market for QLC-based UFS parts, and what breadth of densities the market will desire. So we certainly foresee that QLC-based UFS would support higher densities than this … this is just [a] PoC.
“As for why we picked 512GB instead of some larger density as PoC samples, it’s simply that the density, at least at this level, is not so key in terms of figuring out the performance viability of QLC UFS, and therefore is more cost effective way to investigate this (i.e., the same test case, at about half the cost relative to testing with 1TB devices). Note that we do actually already have a TLC-based 1TB UFS in production.”
DataCore Software announced its DataCore Swarm object storage (from acquired Caingo) has qualified as a “Veeam Ready-Object” and “Veeam Ready – Object with Immutability” solution by Veeam. Customers can deploy Swarm as the scalable capacity tier for Veeam Backup & Replication, or Veeam Backup for Microsoft Office 365. The combined offering, DataCore says, enables more frequent backups with less effort at a lower cost, for rapid recovery.
…
According to the IDCWorldwide Quarterly Enterprise Infrastructure Tracker: Buyer and Cloud Deployment, spending on compute and storage infrastructure products for cloud infrastructure, including dedicated and shared environments, increased 6.6 per cent year over year in Q3 2021 to $18.6 billion. This increase resumes the trend of net positive quarterly year-on-year spending growth, which saw a pause in Q2 2021 when spend decreased 1.9 per cent. This follows seven quarters of year-on-year spending growth, highlighted by 38.4 per cent growth in Q2 2020 as the first global pandemic wave led to business and country closures causing a spike in investments in cloud services and infrastructure. Investments in non-cloud infrastructure increased 7.3 per cent in Q3 2021 to $14.6 billion — the third consecutive quarter to see an increase in such spend after a period of declining spending that started in 2Q19.
…
Pure Storage announced a series of updates and new benefits for its Partner Program. They include providing specific requirements and benefits for partners whether they are reselling or offering managed services, as-a-service solutions, or cloud-native architecture. This also applies to cloud-native and Kubernetes-based applications. There are differentiated benefits for Elite partners including incentives, discounts, marketing resources, and more. A new Service Specialization Program enables partner-branded professional and support services around Pure technology. Pure has a formal program to support Pure distribution partners and there is a simplification of the requirements by aligning to solutions, further enabling partners to invest in multiple routes-to-market enablement. The Pure Partner Program will adhere to Pure’s fiscal year, beginning February 7, 2022.
…
Satori, which supplies a DataSecOps platform for cloud-based data stores and infrastructure, released annual growth metrics revealing a rapidly expanding user base and soaring data store query volumes, a steady increase in brand visibility, and a new official partnership with AWS. These milestones come less than three months after the company closed a Series A funding round with $20 million in venture capital and added two execs: Gaurav Deshpande, VP of marketing, and Ediz Ertekin, VP of sales.
…
Open source software supplier SUSE has announced the NeuVector codebase is available on GitHub, saying this makes NeuVector the “first truly open source, end-to-end security solution”. It will allow Rancher users to address deep network visibility, inspection and segmentation, manage vulnerability, configuration and compliance management, do risk profiling, threat detection and incident response. A blog from SUSE’s president of engineering & innovation Sheng Liang will tell you more.
…
Open source distributed SQL database supplier Yugabyte has a strategic partnership agreement with Intuita, a UK-based lifecycle data services provider, to support the growth of enterprise-class, cloud-native, transactional database technology cloud initiatives across EMEA. Both claim that enterprise digital transformations are stalling due to the unsuitability of monolithic databases for cloud native applications, and the inadequacy of NoSQL databases to handle transactional systems of engagement and systems of record. The partners believe YugabyteDB can fix these problems.
Magneto-Resistive Random Access Memory (MRAM) has so far generally failed to replace SRAM because its Spin Transfer Torque (STT-MRAM) implementation is too slow and doesn’t last long enough. A new variant — Spin Orbit Transfer MRAM (SOT-MRAM) — promises to be faster, have a longer life and use less power.
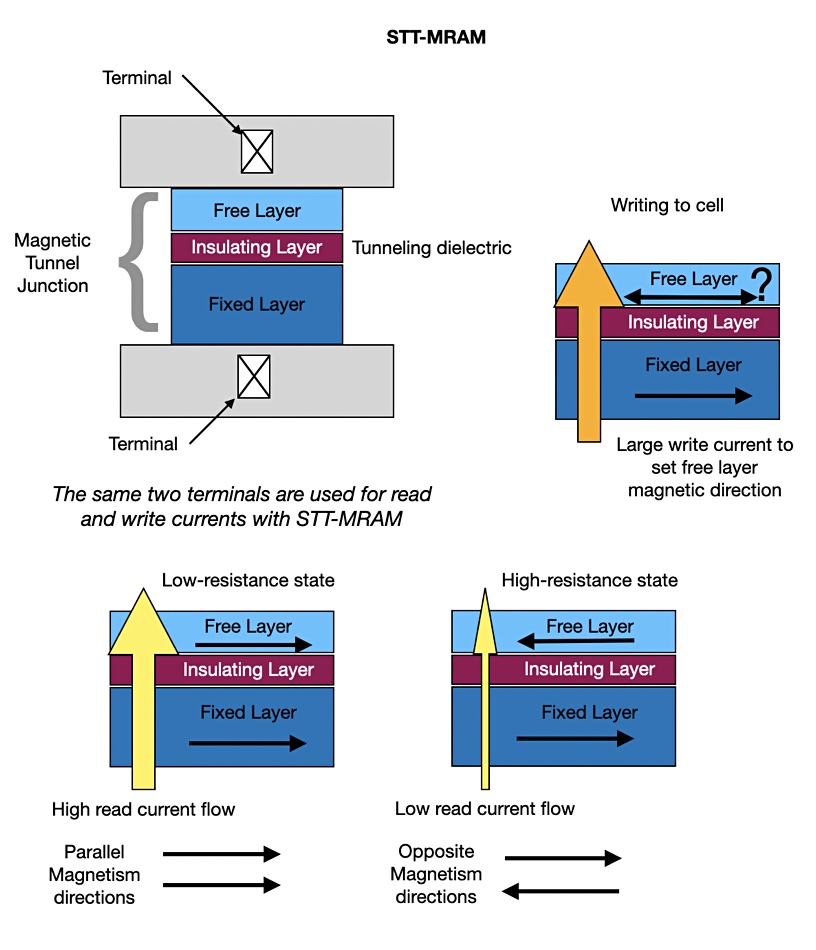
To better understand what’s going on, we have to delve into how STT-MRAM works. This is my understanding and I am neither a physicist nor a CMOS electrical engineer, so bear with me. STT-MRAM is based on a magnetic tunnel junction. This is a three-layer CMOS (Complementary Metal Oxide Semiconductor) device with a dielectric or partially insulating layer between two ferromagnetic plates or layers. The thicker layer has a fixed or pinned magnetic direction.
Blocks & Files diagrams.
The upper and thinner layer is called a free layer and its magnetic polarity can be set either way. When the magnetic polarity of both layers is in sync (parallel) then the electrical resistance of the device is lower than when the polarities are opposite, as shown in the diagram above. High or low resistance signals binary one or zero. The resistance is made high or low with a write current, stronger than the resistance-sensing read current, sent through the device.
Electrons in the magnetic layers have spins (angular momentum) which can be in an up or down direction. The current sent through the fixed layer is spin-polarised so that the bulk of its electrons spin in one direction. Some of these travel — or rather tunnel — through the dielectric layer into the free layer and can change its magnetic polarity, and thus the device’s resistance. Hence the name, magneto-resistive RAM. The change is permanent — MRAM is non-volatile, but repeated writes degrade the device’s tunnel barrier material and reduce its life.
STT-MRAM can deliver higher speed by using a larger write current, but that shortens the device’s endurance. Or it can deliver longer endurance at the cost of slower speed.
Proponents of SOT-MRAM say the problem is due to the write and read currents using the same path, from terminal to terminal, across the device. By separating the two currents you can raise both speed and endurance. But you still need to set the magnetic polarity of the free layer.
This is done by passing the write current through a so-called strap layer set adjacent to the free layer.
Blocks & Files diagram.
This means the device now has three terminals — a point to which we will return.
According to Bryon Moyer Semiconductor Engineering cited in Semiengineering.com, writing requires either a special asymmetric shaped strap layer or an externally-applied magnetic field. Research is progressing into field-free switching using using atomic-scale phenomena such as the Rashba effect, which is concerned with spin orbits and crystal asymmetry, and also the Dzyaloshinskii–Moriya effect related to magnetic vortices.
A particle can spin on its own axis or it can spin — orbit — around some other particle.
We can say that electron spin orbits represent the interaction of a particle’s spin with its motion inside an electrical field, without actually understanding what that means. A “Nanoscale physics and electronics“ scientific paper stated: “Spin orbit coupling (SOC) can be regarded as a form of effective magnetic field ‘seen’ by the spin of the electron in the rest frame. Based on the notion of effective magnetic field, it will be straightforward to conceive that spin orbit coupling can be a natural, non-magnetic means of generating spin-polarized electron current.”
It may be “straightforward” to CMOS-level electric engineers and scientists but this writer is now operating way out of any mental comfort zone.
Bryon Moyer Semiconductor Engineering says that researchers realised that with the right layering and combination of ferroelectric or ferrielectric materials, and with the right spin-index relationships, the magnetic symmetry can be broken to drive the desired [magnetic] orientation. In other words you can use spin orbits to set the free layer’s magnetic field in the desired direction.
Whatever the method, the magnetic polarity of the free layer can be set and the tunnel junction’s resistance be read as with STT-MRAM.
The three-terminal point means that an SOT-MRAM cell requires an extra select transistor — one per terminal — and this makes an SOT cell bigger than an STT cell. Unless this conundrum can be solved, SOT-MRAM may be restricted to specific niche markets within the overall SRAM market.
It is likely to be three years or more — perhaps ten years — before any SOT-MRAM products will be ready for testing by customers. In the meantime organisations like Intel, the Taiwan Semiconductor Research Institute (TSRI) and Belgium’s IMEC are researching SOT technology. We’ll keep a watch on what’s going on.
UK-based digital archiver Arkiviumhas been selected to take its petabyte-scale and SaaS-based ARCHIVER offering through to the final, pilot stage, in preparation for commercialisation on the European Open Science Cloud (EOSC) and elsewhere. It has successfully completed both the design and prototyping phase of ARCHIVER (Archiving and Preservation for Research Environments), a €4.8 million project. Arkivum has selected Google Cloud for all phases of the ARCHIVER project.
…
Dell EMC has just released AppSync v4.4, providing Integrated Copy Data Management (iCDM) with Dell EMC’s primary storage systems. A Dell EMC blog discusses PowerMax secure snapshots, application integration improvements, and deeper platform support for PowerStore arrays with, for example, NVMe-oFC support.
…
Hyve Solutions’ VP of technology Jay Shenoy told us that he believed Twitter’s Jan 2021 DriveScale acquisition was a normal acqui-hire — Twitter wanting some of DriveScale’s people and not its composable systems products. Shenoy previously worked at Twitter before joining Hyve. DriveScale was founded by CTO and then chief architect Satya Nishtala and chief scientist Tom Lyon. Shenoy said “None of the business people at DriveScale went to Twitter. … Tom and many other people from the software team are the only ones who went to Twitter.” Their remit is to build flexible infrastructure, whether it be on-premises or in the public cloud.
…
IBM’s Spectrum Fusion HCI v2.1.2 is generally available. IT includes enhanced active file management (AFM), a Container Network Interface(CNI) daemon, support for Red Hat OpenShift Container Platform, IBM Spectrum Protect Plus, Spectrum Scale Erasure Code Edition, also proxy server setup for the OpenShift Container Platform cluster.
…
We heard Veritas is going to hire Santosh Rao, currently a Gartner analyst with the title “principal product management, Amazon RDS/Aurora”. On asking, a Veritas spokesperson told us: “Veritas does not comment on rumours or speculation.”
Hyve Solutions sells storage hardware to its hyperscaler customers, but not software — because they don’t want it. What, then, do hyperscalers want?
Hyve is a TD Synnex business unit that sells, delivers and deploys IT Infrastructure — compute, networking and storage — to hyperscaler customers. That means the likes of AWS, Azure, Facebook, Twitter, etc., though it would not confirm any as customers. Typically the hardware is rackscale and complies with Open Compute Project standards. Hyve also sells into IoT and edge deployments — such as ones using 5G, where sub-rackscale systems may be typical and site numbers can be in the hundreds.
Jay Shenoy.
We were briefed by Jayarama (Jay) Shenoy, Hyve’s VP of technology and our conversation ranged from drive and rack connection protocols to SSD formats.
Shenoy said Hyve is an Original Design Manufacturer (ODM), and focusses exclusively on hyperscaler customers and hardware. It doesn’t really have separate storage products — SANs and filers for example — with their different software. Separate, that is, from servers.
Shenoy said “We make boxes, often to requirements and specifications of our hyperscale customers. And we have very little to do with the software part of it.”
Storage and storage servers
Initially hyperscalers used generic servers for everything. “A storage server was different from a compute server only in the number of either disks or SSDs. … There really was not that much different at times about the hardware, being storage. That is changing now. But the change will manifest in, I would say, two or three years. Things move much more slowly than we would like them to move.”
One of the first big changes in the storage area was a drive type change. “So the first thing that happened was hard drives gave way to SSDs. And initially, for for several years, SSDs was a test. By now that trend is really, really entrenched so that, you may just assume that the standard storage device is an SSD.”
As a consequence, there was a drive connection protocol change. “In the last three years, SATA started giving way to NVMe, to the point where now, SATA SSD would be a novelty. … We still have some legacy, things that we keep shipping. But in new designs, it’s almost all NVMe.”
Shenoy moved on to drive formats. “Three years ago, hyperscalers were sort of sort of divided between U.2 [2.5-inch] and M.2 [gumstick card format]. All the M.2 people kind of had buyer’s regret. … All three of them have confirmed that they’ve moved or are moving to the E1.S form factor.”
E1.S is the M.2 replacement design in the EDSFF (Enterprise and Datacentre SSD Form Factor) ruler set of new SSD form factors.
Shenoy said “There are primarily three, thank goodness. The whole form factor discussion settled out. That happened maybe a year and a half ago, when Samsung finally gave up on its NF1 and moved to EDSFF.”
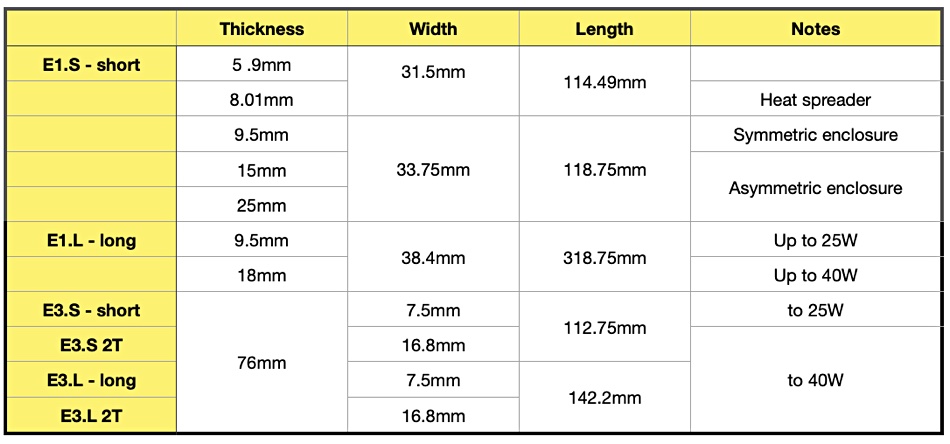
There are two basic EDSFF formats: E1 and E3. Each comes in short and long sub-formats, and also with varying thicknesses:
SNIA’s EDSFF form factor details.
The E3 form factor allows for x4, x8, or x16 PCIe host interface. Shenoy’s basic threesome are E1.S, E1.L and E3.
Shenoy told Blocks and Files “At a high enough level, what seems to me to be happening is E3 is going into … what would have been known. What is still known, as enterprise storage with features like dual porting. … E1 does not really support dual porting.”
Hyperscalers have adopted the E1 format, “but to this date, I have not come across a single one that has an E3 [drive].” He explained that “the people who picked U.2 are happy with U.2 and are going to like U.3 instead of E3.”
The difference for hyperscalers between E1.S and the E1.l format is capacity. “[With] E1.S versus E1.L the difference is exactly one capacity point, meaning the highest capacity point in the SSD line. … Only the highest capacity port will be offered in E1.L. And everything else will be offered in E1.S. So even .L is basically restricted to whoever is going to be today adopting the 30 terabyte drive capacity point.”
Edge computing
“In terms of hardware, there’s one other subtle, subtle change — well, actually, not so subtle — that’s been happening in hyperscale. When we think of hyperscale, we think of big datacentres, hundreds of thousands of nodes, and racks, and racks, and racks and racks. But edge computing … has stopped being a buzzword and started to be very much been a reality for us in the last couple of years.
“The way edge computing changes storage requirements is that hotswap of SSDs has come back. Hotswap — or at least easy field servicing — has come back as a definite requirement.” Shenoy thinks that “Edge computing driving different form factors of servers is a given.”
Another change is disaggregation. Shenoy said “The larger hyperscalers have basically embraced network storage. So it’s basically object storage or object-like storage for the petabytes or exabytes of data [and] that’s placed on hard disks. And SSD is a fast storage. It’s a combination of either — it can be object storage, or sometimes it has to be even block storage.”
PCIe matters
What about the connection protocols in Hyve’s hyperscaler world? For them, “Outside of the rack … can do anything as long as it’s Ethernet. Within the rack, there’s much more leeway in what cables people will tolerate, and what exceptions people are willing to make.” Consider hyperscale storage chassis as basically boxes of flash or disks — JBOFs or JBODs. As often as not they’ll be connected with a fat PCIe cable. In Shenoy’s view, “PCIe within a rack and Ethernet outside of a rack, I think is already a sort of a thing or reality.”
What about PCIe generation transitions — from gen 3 to 4 and from 4 to 5? Shenoy said there are very few gen 4 endpoints as yet, especially GPUs, which “were almost ready before the server CPUs. … It’s partly the success of AMD, as Rome had to do with being the first with PCIe 4.” In fact the “PCIe gen 4 transition happened rather quickly. As soon as the server CPUs were there, at least some of the endpoints were there. SSDs took a little bit of time to transition to gen 4.”
But PCIe 5 is different: “Gen 5 …. and the protocol that writes on top of gen 5, CXL, is turning out to be … very different. It’s turning out to be like the gen 2 to gen 3 transition, where the CPU showed up and nobody else does.”
According to Shenoy “The gen 5 network adapters are also lacking actually … to the point where the first CPU to carry gen 5 will probably go for, I don’t know, a good part of a year without actually attaching to gen 5 devices. That’s a long time.”
Shenoy was keen in this point. “The gen 5 transition is kind of looking a little bit like the gen 3 transition. … Gen 3 stayed around for a really, really long time.”
Chassis and racks
Hyve has standard server and storage chassis building blocks. “We have our standard building blocks. And then we have three levels of customisation. … So chassis is one of the things that we customise pretty frequently.” Edge computing systems vary from racks to sub-racks. The edge computing racks may be sparser — Shenoy’s term — than datacentre racks. Every one, without exception, will contain individual servers and may also contain routers and even long haul connection devices.
They are more like converged systems than Hyve’s normal datacentre racks.
Customer count
How has Hyve’s hyperscaler customer count changed over the years? Shenoy said “The number of hyperscalers has gone up, or the number of Hyve customers has gone up slightly, I would say, in the last three years.
“The core hyperscale market has not changed. Three years ago, or five years ago, you had the big four in the US — big five if you count Apple — and then the big three in China. And then there was a bunch of what Intel calls the next wave” — that means companies like eBay and Twitter. “These would have been known ten years ago as CDNs. Today it would be some flavour of edge computing. I am making reference to them without [saying] whether they are our customers or not.”
He said “Then the other type of customers that have come into our view … are 5G telcos.”
That means that the addressable market for Hyve in terms of customer count three to five years ago was around ten, and is now larger than that — possibly in the 15 to 20 range. It is a specialised market, but its buying power and its design influence — witness OCP — is immense.
That design influence is affecting drive formats — witness the EDSFF standards set to replace M.2 and 2.5-inch SSD form factors. Nearline high-capacity disk drives will stay on in their legacy 3.5-inch drive bays. The main point of developing EDSFF was to get more SSD capacity into server chassis while overcoming the consequent power and cooling needs.
Mainstream enterprise storage buyers will probably not come into contact with Hyve, unless they start rolling out high numbers of edge sites using 5G connectivity. Apart from that, Hyve should remain a specialised hyperscale IT infrastructure supplier.
Bootnote: Distributor Synnex became involved in this whole area when it started supplying IT infrastructure to Facebook. That prompted it to form its Hyve business ten years ago. The rise of OCP and its adoption by hyperscalers propelled Hyve’s business upwards.
The TD part of the name comes from Synnex merging with Tech Data in September last year, with combined annual revenues reaching almost $60 billion. This made it the IT industry’s largest distributor.
WAF – Write Amplification Factor – indicates the extra NAND media write operations the SSD performs in response to the host writes (WAF = total NAND media writes / total host issued writes). The additional media writes are necessitated due to the way in which NAND flash media handles writes. NAND flash pages once programmed cannot be overwritten, unless the entire flash block (1 block = N pages) is erased again. Since the erase is a costly operation, the SSD firmware avoids the unnecessary erase operations by handling the writes in a log structured manner. So any overwrites will be redirected to a new flash page and the old page is marked as invalid. Eventually many such invalid pages are generated. The Garbage Collection (GC) process of SSD will handle such pages by moving the valid pages to a new flash block. GC process also releases these flash blocks for erase and eventually for new writes. The GC causes additional writes due to the movement of valid pages, in addition to the ongoing host initiated writes. This process is the root cause of WAF problem in SSDs. The extent of the WAF problem can vary based on the active host workloads. For example, a sequential workload might not cause much of WAF since it aligns with the log structured write design of the SSD software, while a random workload with lots of overwrites can cause high WAF in SSD. [Note from Samsung Tech Blog.]
CDFP – CDFP is short for 400 (CD in Roman numerals) Form-factor Pluggable, and designed to provide a low cost, high density 400 Gigabit Ethernet connection.
OSFP MSA – Octal Small Form Factor Pluggable (OSFP) Multi Source Agreement (MSA). The OSFP (x8) and its denser OSFP-XD (x16) variants both support the latest signaling rate of 224G PAM4 per lane (for example 8 x 200G = 1.6 Tbps Ethernet). They are compatible with PCIe Gen5 / CXL 1.1, 2.0 (32G NRZ), PCIe Gen6 / CXL 3.x (64G PAM4) and PCIe Gen7 / CXL 4.x (128G PAM4). This OSFP cabling system is future-proof for 2 generations ahead in the PCIe domain. It is also ready for UALink that reuses Ethernet IO at the electrical level.