Toshiba has launched a 22TB MG10F disk drive, five months after Seagate and 14 months after Western Digital.
Basically the drive adds 10 percent capacity to its existing 3.5-inch form-factor MG10 range, which tops out at with a 20TB model announced a year ago. Like that drive it is an enterprise capacity or nearline product, spinning at 7,200rpm with up to 10 platters, and either 12Gbit/s SAS (2 to 22TB) and 6Gbit/s SATA (1 to 22 TB) interfaces.
Toshiba 22TB MG10F graphic
The drive uses different technologies as the capacities increase. From 1TB to 10TB it has conventional perpendicular magnetic recording (PMR) media in an air-filled enclosure. The 12TB to 16TB products switch to helium-filled enclosures but stay with PMR while the 18, 20 and 22TB variants have Flux Control Microwave Assisted Magnetic Recording (FC-MAMR) platters and heads inside their helium-filled enclosures. FC-MAMR uses a microwave effect to improve write signal effectiveness at high areal densities.
The cache buffer size varies between 128MiB (1 & 2TB), 256MiB (4 – 14TB) and 512MiB (16 – 22TB) and the sustained data rate varies between 204 MBps for the 1 and 2TB drives and 284MBps for the 22TB drives.
Western Digital’s Gold 22TB drive provides up to 291MBps and Seagate’s 22TB IronWolf Pro delivers up to 285MBps.
Toshiba does not provide any shingled magnetic recording (SMR) version of this drive which could provide a 15 percent or so additional capacity increase through partially overlapping write tracks. Western Digital’s 22TB drives have 26TB SMR variants. A February 2022 roadmap for Toshiba’s disk drives showed a 26TB SMR product, which has not arrived as a product.
The MG10F with a SAS interface is now sample shipping with SATA product sampling starting in the fourth quarter. No pricing information was provided. SED (Self-Encrypting Drive) and SIA (Sanitize Instant Erase) options are available. Download a datasheet here.
GPU cloud service provider CoreWeave is using VAST Data to for its customers’ storage needs.
CoreWeave rents out Nvidia A100 and H100 GPUs for use by its customers through its CoreWeave Cloud. This has been built for large-scale workloads needing GPUs, with more than 3,500 H100 Tensor Core GPUs available in one of the largest HGX clusters installed anywhere. Its GPU infrastructure is supported by x86 compute, storage and networking resources, and active in running generative AI workloads.
CEO and co-founder Michael Intrator revealed in a statement that CoreWeave is going to: “partner with VAST Data to deliver a multi-tenant and zero-trust environment purpose-built for accelerated compute use cases like machine learning, VFX and rendering, Pixel Streaming and batch processing, that’s up to 35 times faster and 80 percent less expensive than legacy cloud providers. This partnership is rooted in a deep technical collaboration that will push the boundaries of data-driven GPU computing to deliver the world’s most optimized AI cloud platform.”
Vast co-founder Jeff Denworth said: “The deep learning gold rush is on, and CoreWeave is at the epicenter of the action.”
Up until now CoreWeave Cloud Storage Volumes have been built on top of Ceph, with triple replication, and distributed across multiple servers and datacenter racks. It features disk drive and all-flash NVMe tiers, and both file and S3 object access protocol support.
This is a significantly large order for VAST, and CoreWeave will deploy the VAST arrays to store, manage and secure hundreds of petabytes of data for generative AI, high performance computing (HPC) and visual effects (VFX) workloads.
CoreWeave was funded in 2017, as an Ethereum mining company, and then pivoted in 2019 to AI. It raised $421 million in a B-round last April, another $200 million in May, plus $2.3 billion debt financing in August to expand its infrastructure. This was secured by CoreWeave using its GPUs as collateral. It reckons it will have 14 datacenters in place across the USA by the end of the year, and earn $500 million in revenue, with $2 billion contracted already for 2024.
Nvidia is an investor in CoreWeave and also in VAST, which is Nvidia SuperPOD-certified.
A statement from Renen Hallak, founder and CEO of VAST Data, was complementary to CoreWeave, saying: “Since our earliest days, VAST Data has had a single vision of building an architecture that could power the needs of the most demanding cloud-scale AI applications. We could not imagine a better cloud platform to realize this vision than what we’re creating with CoreWeave. We are humbled and honored to partner with the CoreWeave team to push the boundaries of modern AI computing and to build the infrastructure that will serve as the foundation of tomorrow’s AI-powered discoveries.”
CoreWeave said its supercomputing-class infrastructure trained the new MLPerf GPT-3 175B large language model (LLM) in under 11 minutes – more than 29x faster and 4x larger than the next best competitor. A VAST Data blog, soon to be live on its site, provides more background info.
As promised in June, the Lightbits Cloud Data Platform has been made available in the Azure Marketplace as a managed application.
Lightbits software uses public cloud ephemeral storage instances to provide block storage that is faster and more affordable than Azure’s own block storage instances. These are Azure Disk Storage ones with its Ultra Disk Storage, Premium SSD v2, Premium SSD, Standard SSD, and Standard HDD options. Lightbits creates a fast SAN in the cloud by clustering virtual machines connected by NVMe over TCP. It’s capable of delivering up to 1 million IOPS per volume and consistent latency down to 190 microseconds, and performance scales linearly as the cluster size increases.
This means tight SLAs for important apps, that otherwise could not be moved to the Azure cloud, can be met. Kam Eshghi, co-founder and chief strategy officer at Lightbits, said in a statement that customers “get the highest performance possible on Azure at a lower cost than native cloud storage, plus hands-off operations as a managed service. Now they can migrate all their workloads to the cloud and be confident that they won’t have to repatriate them back on-premises due to skyrocketing costs.”
Lightbits Cloud Data Platform software is already available in the AWS Marketplace and is now in preview in the eu-west, us-east, and us-west Azure regions. A Lightbits on Azure launch event is scheduled for September 29, 2023.
Comment
There are four suppliers providing block storage in the public cloud based on ephemeral storage instances: Dell (PowerFlex), Lightbits, Silk, and Volumez. They compete against the cloud providers’ native block storage instances and against block storage array providers, such as Pure Storage with its Cloud Block Store, which have moved their array controller software to the cloud. NeApp’s Cloud Volumes ONTAP provides block, file, and object storage in AWS, Azure, and the Google Cloud.
The advantage for NetApp and Pure customers is their customers having the same block storage environments on-premises and in the public clouds. The cloud block stores are based on the cloud providers’ native block storage and don’t use ephemeral storage instances. That should give the four suppliers above both performance and cost advantages for their products but they lack the on-premises/public cloud environment consistency that NetApp and Pure provide.
VAST Data thinks that generative AI developments will lead to an “arms race” for real data as well as the ongoing one for GPUs for AI work. That’s data coming from humans and not generated by AI chatbots.
We were briefed by Andy Pernsteiner, VAST Field CTO, who was in in London for the Big Data event. Our discussion covered lots of ground, including VAST Data arrays being used to store data for training generative AI models, and its coming DataEngine compute layer. VAST Data is building a storage and AI/analytics stack, composed of VAST’s all-flash and single tier Universal Storage at the lowest level, then its data catalog with its proprietary transactional + analytics DataBase layered on that, and, above that, DataEngine software under development to operate on the data in the DataBase. Overall this a global DataSpace will provide a single namespace spanning VAST’s systems.
Andy Pernsteiner
Pernsteiner said: “There’s going be a whole class of customers that don’t know what they’re doing in deep learning, who are going to want a solution that’s turnkey, that includes everything that they need. And so right now, obviously, we don’t have all of those things. We’re starting to think through what the next generation is. And that’s what the Data Engine is really all about; making it so that customers who don’t have the expertise of building out scalable compute infrastructures, can have it alongside their storage without having to go and layer it on themselves.”
This VAST AI and analytics system will ingest, as VAST Data CEO and founder Renen Hallak said: ”the entire data spectrum of natural data – unstructured and structured data types in the form of video, imagery, free text, instrument data,” which will be generated from all over the world and processed using real-time inference and constant, recursive AI model training.”
Hallak describes it as “natural” data, meaning generated by humans and human interactions, not created by AI chatbot-type entities.
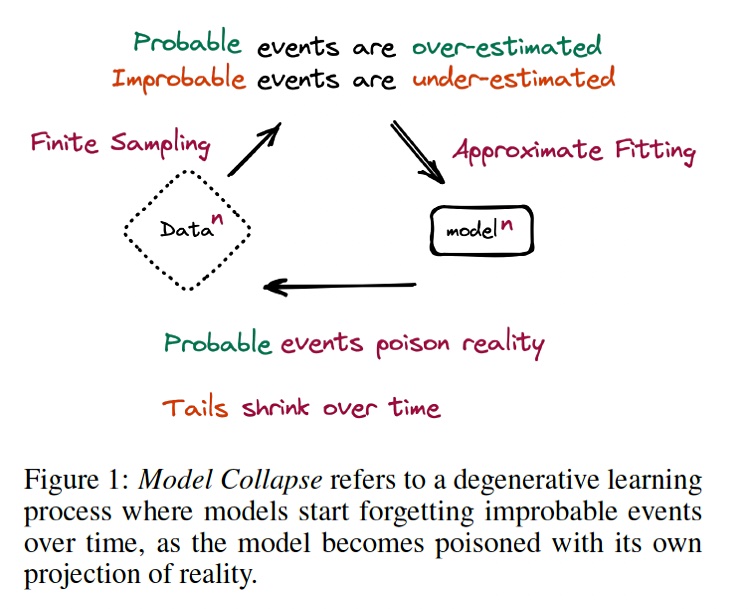
Pernsteiner said: “If the content in the future is all generated using AI, this is training itself on its own data which can lead to a downward spiral.” He referred to this as model collapse and it occurs when a generative AI model is trained on data generated by AI and not human activities. This synthetic data is limited in scope and the AI model’s generates rules (weights) are limited as well, meaning the model gives more strength to likely events and patterns in the data, and less weight to unlikely ones, becoming unrealistic.
Model collapse was explained in a research paper by Canadian and UK computer science academics called, “The Curse of Recursion: Training on Generated Data Makes Models Forget”. It found that “use of model-generated content in training causes irreversible defects in the resulting models, where tails of the original content distribution disappear.”
Large language models are trained on data scraped from the Web. Up until recently the overwhelming majority of that data has been created or generated by humans. Now increasing amounts of it are being produced by generative AI model such as ChatGPT instead. The researchers write in their paper: “If most future models’ training data is also scraped from the web, then they will inevitably come to train on data produced by their predecessors. In this paper, we investigate what happens when text produced, e.g. by a version of GPT, forms most of the training dataset of following models.”
What happens, the authors say, is that: “Models start forgetting improbable events over time, as the model becomes poisoned with its own projection of reality.”
Their paper’s abstract says: ”We demonstrate that [model collapse] has to be taken seriously if we are to sustain the benefits of training from large-scale data scraped from the web. Indeed, the value of data collected about genuine human interactions with systems will be increasingly valuable in the presence of content generated by LLMs in data crawled from the Internet.”
Pernsteiner said: “There’s a lot of debate in the community about models. Maybe it’s not necessarily a doomsday scenario. But it’s kind of a scary concept, when you can’t tell what’s real. And if a machine doesn’t know what’s real, what’s not real, how does it know to use it when it’s training a model or not? And so all the people developing models are trying to find ways to detect if the data is real or not. But how do you do that? How does a human, how do you know? How do I know that your blog post is written by you?”
The research authors write: ”the use of LLMs at scale to publish content on the internet will pollute the collection of data to train them: data about human interactions with LLMs will be increasingly valuable.”
Pernsteiner said: ”That’s why you see Meta, OpenAI, all of these forward thinking model creators, are acquiring data or having to buy it now.” They have to train their models on real data: “So real data will become more valuable to the point where any organisation that collects any data can monetize it.”
He asserts:” Any real data will become more and more valuable. … And if you’re an organization; it doesn’t really matter what kind of organisation you are, your data is valuable to somebody.”
He thinks organizations will need to build their own generative AI models because bought-in models that could have been trained on polluted data; model collapse-type data. He said: “If you’re an organization, and you want to use generative AI, you want to build a generative value practice and you want to make sure that your models are not tainted, then you have to build your own.”
This means, he reckons: “Organizations who develop their own models, who have things of value; they can start selling those as data products as well.” Also: “If you’re a big enterprise, you might be able to sell your model. And that might be where money is made in the future; selling models.”
There’s an audit angle to this as well. In regulated industries the authorities may need an AI-made decision, that led to an accident or suspect event, examined. Pernsteiner said: “Now I’ve got to understand the products a little bit more. The data products are not going to be limited to structured data. It’s going to include things like the model, the source data, the annotated data, all of the labels, any vector databases that you have that are associated with it … Show me all the lineage. Show me the model. Show me the training data you use. Show me the code you use. And it has to be immutable.”
Pernsteiner thinks that: “All these things are interesting because it makes it so that regular companies, if they want to survive; they can’t just rely on selling the products that they’ve been selling in the past. They’re going to sell data, they’re going to sell models. They want to train their own models, they need a lot of infrastructure. Maybe not exabytes of data. But they need all their data, they might need to buy data from other people. It’s not just an arms race for infrastructure, it’s an arms race for data.”
The Storj network has increased in size by a third in four months and the company is expanding into India, it says, adding that under some conditions, Storj’s decentralized storage can be faster than content distribution networks (CDNs) and standard AWS for generative AI model data distribution.
The company provides cloud storage using spare capacity in datacenters around the world, with more than 24,000 points of presence in over 100 countries. Storj treats this spare capacity as a globally distributed store, sharding incoming files and objects, typically into 80 x 64MB fragments, and spreading them plus error correcting erasure codes code around the centers. It competes with Amazon, Azure, Google, Backblaze and other CSPs as a cloud storage provider, offering, it says, lower costs and higher speed retrievals. Customers’ data is retrieved by a subset of the data centers nearest to the customer holding the file fragments, operating in parallel to have the rebuilt file delivered to the customer.
COO John Gleeson told us: “Storj’s network can be up to three times faster than a CDN for software distribution.”
He said the network is also being used to hold the data for Generative AI models, open source ones in particular. Storj says this data is needed in 100GB to 10TB amounts for model creation and file tuning, and in 1MB or smaller amounts for model execution. Data sets and models are transferred between storage and training environments. Ultimately any output of AI model workloads is delivered over a private network or the public internet.
We understand Storj has won a 6PB deal against a major object storage player.
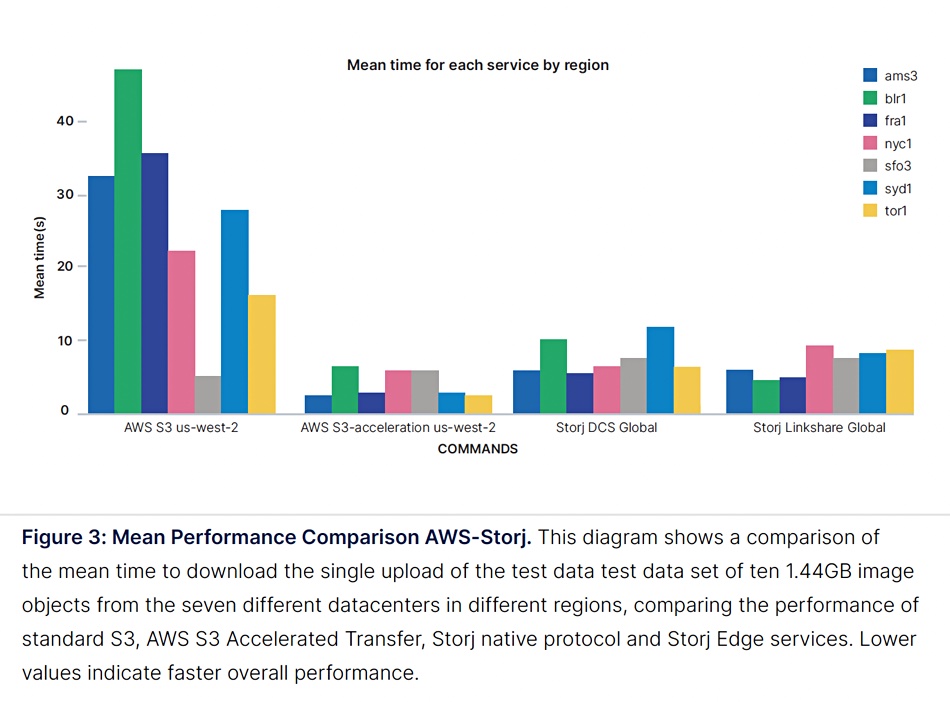
Storj says it is is a viable alternative to the hyperscaler clouds for model and training data set storage and distribution. A test performed as part of Storj’s own white paper appeared to show that Storj performance is better than standard Amazon S3, although slower than S3 Accelerated Transfer:
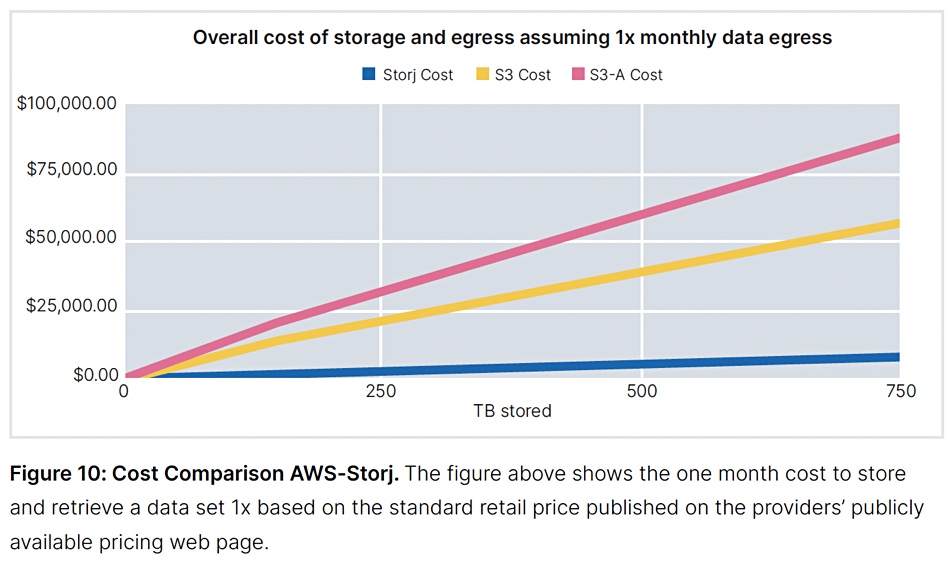
Storj storage costs less than Amazon S3, another of its own charts appears to indicate:
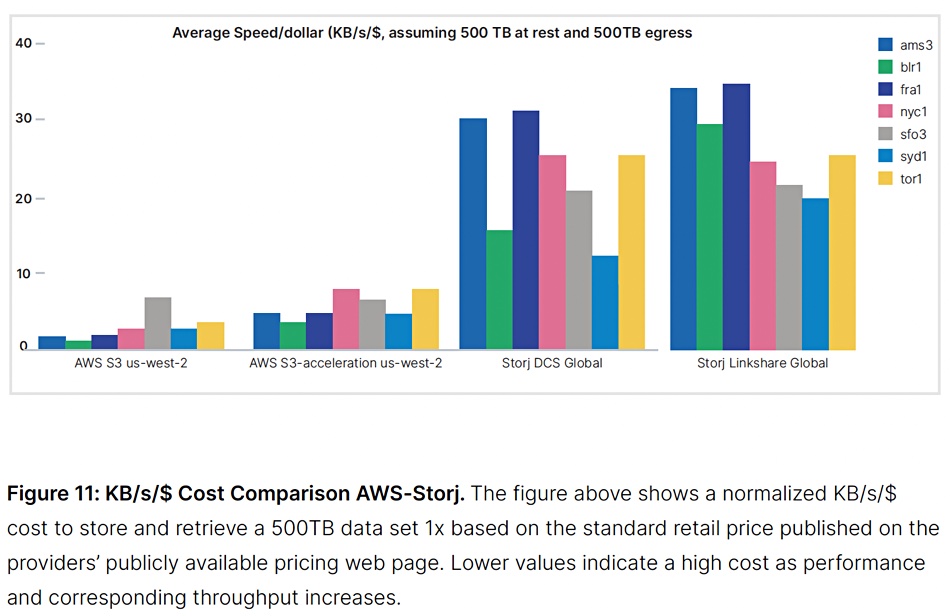
This means, it says, that when the mean download time is combined with cost to provide a download speed per dollar measure, Storj outperforms Amazon:
Its channel is an important growth driver, with one new channel partner reporting a 500 percent revenue increase from one year to the next. The firm said Storj can add capacity to its network faster than a big CSP could buy, install and deploy the same amount of capacity, according to the company.
A white paper describing Storj’s AT model training data storage capabilities is available here (registration required). The charts above were sourced from this paper.
Comment
The decentralized storage concept, shorn of its prior crypto-currency payment terms and fiat currency abolition ambitions, is becoming recognized as a realistic cloud storage technology. Suppliers like Storj, Cubbit, and Impossible Cloud are demonstrating that it is reliable, fast, and secure, and can be used without application software changes.
Their big advantage over the tier 1 and 2 CSPs is that they don’t have to build and operate datacenters. AWS, Azure, Google and others, who do bear that cost, could respond to this disruptive innovation to their business by setting up their own decentralized storage tier using spare capacity in third-party datacenters. Indeed they could use spare capacity in their own existing customer’s datacenters, offering them lower price cloud storage in return instead of a cash payment.
Hyperscalers who use SQL processing units (SPUs) to offload x86 CPUs running analytics workloads could get a 100x or more acceleration of their jobs, enabling lower costs and more efficient CPU core use, says in-memory computing chip and hardware startup NeuroBlade.
The startup has developed a specialized semiconductor chip to accelerate SQL instruction processing. It plugs into a host server’s PCIe bus and transparently takes over the SQL-related processing with no host application software changes. The device is emphatically not a DPU (data processing unit) which offloads general infrastructure processing, including security, networking and storage, from a host x86 server, nor is it a SmartNIC running networking faster.
Lior Genzel Gal, NeuroBlade chief business officer, briefed us on the company’s hyperscaler focus at the Big Data London conference event where NeuroBlade had a stand. He said that NeuroBlade was talking to all the big hyperscalers and has a contract win for several thousand SPU cards with one of them.
Big Data London event. Spot Airbyte, AWS, Confluent, Databricks, Microsoft, and VAST Data’s stands
The company has a partnership deal with Dell to distribute SPU card products in PowerEdge servers, and potential customers for these servers thronged the aisles and lecture theaters of what was a very popular event, with crowds queuing for talks and not a face mask to be seen.
Gal was CEO and co-founder of NVMe storage array startup Excelero, which was acquired by Nvidia in March last year. Gal left Excelero in September 2020 and worked on strategic business development at DPU developer arcastream, which was acquired by Kalray in 2022. He joined NeuroBlade as CBO in February 2021 and covered strategic business development for Kalray from April last year.
NeuroBlade SPU chip and card
Gal says the Excelero tech accelerated storage, but that was not enough on its own to accelerate application workloads. They needed end-to-end acceleration. DPUs can’t provide that, only working at the infrastructure level. Accelerating SQL processing by using a specifically designed processor enables end-to-end SQL analytics acceleration.
We asked about using the SPU for computational storage. It could be done, with a subset of SPU’s firmware code running in an FPGA or Arm CPU inside a drive chassis, but the return on investment would not be great. The SPU is a parallel processing design, intended to speed queries looking at data spread across many, many drives and not just one. NeuroBlade has talked to drive manufacturers, such as Samsung, but decided not to focus on this market, Gal told us.
That spurred us to ask about deploying an SPU card inside a storage array, plugged into its controllers and operating on data spread across many drives. This is relevant to NeuroBlade but the payoff from hyperscaler sales would be much higher than that from deploying SPUs inside storage arrays.
Our understanding is that a hyperscaler sale could potentially involve tens of thousands of CPUs compared to a storage array vendor shipping at the hundreds or low thousands of units a year level. NeuroBlade has talked to storage vendors such as VAST Data about SPU usage inside their arrays.
Gal said: “The path forward includes storage arrays but it is not our current focus.”
He reckons that NeuroBlade’s technology is unique and highly effective. Hyperscaler customers and others will be able to lower costs and release CPU cores for other work, saving millions of dollars a year.
Server x86 CPUs can be used for general application work. GPUs can be used for AI, while SPUs are for SQL-based analytics. “We are,” Gal said, “the Nvidia of data analytics.”
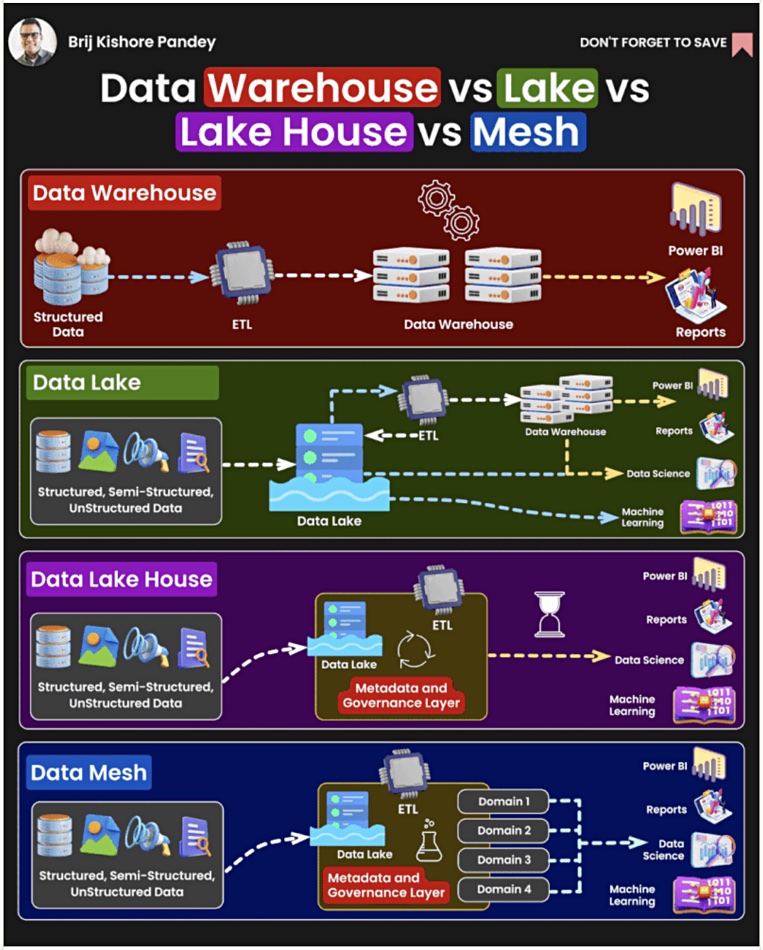
Ever get confused about the differences between a data warehouse, data lake, lakehouse, and data mesh? Bruno Rodrigues Lopes, a senior solutions architect at Bradesco, posted a handy set of definitions and differences on LinkedIn which provide a good way of viewing these different data constructs.
Let’s set an anchor with the difference between a database and a data warehouse. Real-time, current records of structured data are stored in a database. A data warehouse, such as Teradata, introduced in the late 1970s, stores older records in its structured data store with fixed schema for historical data analysis. Data is typically loaded into a data warehouse though an extract, transform and load (ETL) process applied to databases. Business intelligence users query the data, using structured query language (SQL), for example, and the warehouse code is designed for fast query processing.
Diagram by Brit Kishore Pandey
A data lake combines a large amount of structured, semi-structured, and unstructured data. Reading the data generally means filtering it through a structure defined at read time, and can involve an ETL process to get the read data into a data warehouse. An S3 or other object store can be regarded as a data lake where its contents can be used by data scientists and for machine learning.
As we might expect from its name, a data lakehouse aims to combine the attributes of a data warehouse and data lake and it is being used for both business intelligence, like a data lake, and also machine learning workloads. Databrick’s DeltaLake is an example. It has its own internal ETL functions, referencing internal metadata, to feed its data warehouse component.
A data mesh is a way of using a data lakehouse and data lake. When initiated, these two concepts typically have a centralized data team handling the questions from management and line of business (LOB) owners that need analysis routines run in the lakehouse or warehouse, as well as maintaining the warehouse/lakehouse. As the analysis workload rises, this central team can become a bottleneck, preventing timely analytic routine creation. They don’t understand LOB constraints and preferences, adding more delay.
If the LOB, domain-specific people can write their own queries, bypassing the central team, then their query routines get written and run faster. This distribution of query production to LOB teams, which operate on a decentralized self-service basis, is the essence of the data mesh approach. They design and operate their own data pipelines using the data warehouse and lakehouse as a data infrastructure platform.
The data mesh approach is supported by suppliers such as Oracle and Snowflake, Teradata, and others.
There we have it – four data container constructs parceled up, ready to be stored in your mental landscape and deployed when needed.
Cloud storage provider Backblaze has released Computer Backup 9.0 in early access, which it says eliminates stress over restoring data. The version removes the 500GB size limit on its restoring capabilities and comes with a dedicated restore app for macOS and Windows clients. Computer Backup offers free egress and is set at a fixed cost based on employee count with no limit to the amount of computers per organization.
…
New research commissioned by data management warehouse ClickHouse shows it’s speedier than Snowflake and more cost-effective when it comes to measuring real-time analytics. ClickHouse claims it improves data loading and query performance by up to 2x and compression by 38 percent even with Snowflake optimizations. ClickHouse reckons it can achieve these moves with a 15x reduction in cost. See ClickHouse’s blog (part one and part two).
…
Data protector CrashPlan has launched CrashPlan for MSPs, a dedicated program for IT Managed Service Providers and Managed Security Service Providers. They can now provide their customers with CrashPlan’s endpoint backup and recovery SaaS offering. CrashPlan for MSPs’ cloud-based SaaS deployment requires zero on-premises hardware and comes with out-of-the-box system defaults to get customers up and running. Direct billing to the MSP on a monthly, per-user basis gives the option to add or remove customers without having to commit to a cap, and perform customer chargebacks based on consumption.
…
Salesforce and Databricks have expanded a strategic partnership that delivers zero-ETL (Extract, Transform, Load) data sharing in Salesforce Data Cloud and lets customers bring their own Databricks AI models into the Salesforce platform.
…
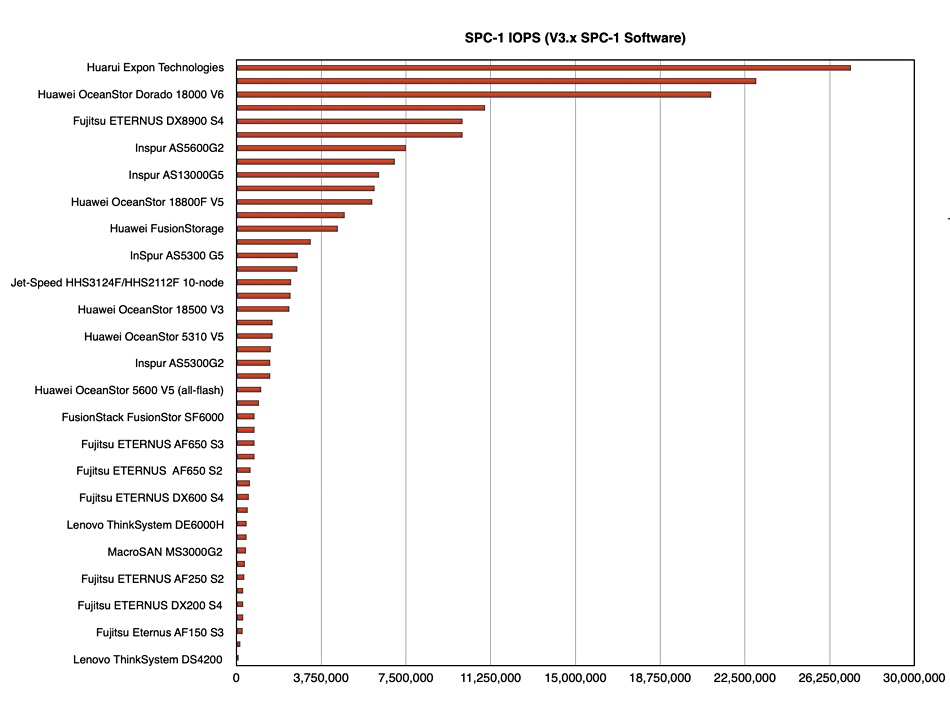
China’s Huarui Expon Technologies, the SPC’s newest member, published its first SPC-1 result and set a new performance record. A cluster of 32 ExponTech WDS V3 all-flash nodes demonstrated 27,201,325 SPC-1 IOPS with an SPC-1 IOPS Response Time of 0.217ms. ExponTech WDS V3 is a fully self-developed software-defined, high-performance distributed enterprise-level block storage platform designed for large-scale core data processing applications. ExponTech WDS V3 adopts a decentralized distributed system architecture, which it says enables smooth horizontal expansion while maintaining linear scalability of performance and capacity with the number of nodes. The platform supports NVMe SSD, SATA SSD, and SCM drives as primary storage media and is compatible with both 25G/100G RDMA RoCEv2 and traditional 10G TCP/IP networking technologies.
…
ibi, which supplies scalable data and analytics software, has announced Open Data Hub for Mainframe, directly bringing mainframe data into web-based business analytics capabilities. Business users can integrate and manipulate disparate data in real time and import rich information into preferred analytics tools. They can avoid the costs of large ETL projects and eliminate stale data by accessing the data in-place on the mainframe. Data scientists gain access to previously inaccessible mainframe data, enabling them to create custom queries without SQL and work with deeper, more complex datasets in real time for comprehensive analytics. Developers benefit from an intuitive GUI interface to generate data queries without creating custom SQL queries while providing seamless access to multiple databases, boosting productivity and software quality.
…
IBM has announced a Cyber Recovery Guarantee for its FlashSystem storage products. It guarantees to recover a user’s immutable snapshot data in 60 seconds or less, enabling businesses to persist through a ransomware attack protected by IBM FlashSystem with Safeguarded Copy. If Safeguarded Copy takes longer than 60 seconds or is unrecoverable, IBM Expert Lab will try to help the client get back on their feet. Find out more here.
…
Kioxia America has donated a command set specification to the Linux Foundation vendor-neutral Software-Enabled Flash Project. Software-Enabled Flash technology gives storage developers control over their data placement, latency outcomes, and workload isolation requirements. Through its open API and SDKs, hyperscale environments may optimize their own flash protocols, such as flexible direct placement (FDP) or zoned namespace (ZNS), while accelerating adoption of new flash technologies. Kioxia has developed working samples of hardware modules for hyperscalers, storage developers and application developers. The Linux Foundation’s Software-Enabled Flash Project offers several levels of membership and participation.
…
Lightbits Labs has announced Lightbits v3.4.1 with a transition to full userspace operation, completely eliminating Linux kernel dependencies for the first time. It has ported Lightbits kernel code to userspace and optimized it. This release extends compatibility to new distributions, including RHEL 9.2, Alma Linux 9.2, and Rocky Linux 9.2, and we’re told makes upgrades simpler and faster. The release adds various observability improvements to Lightbits and to its monitoring stack. Lightbits has now made its debut on the Azure marketplace and is offering an early preview of its new Azure Managed App Marketplace offering. To use it, click “subscribe” on the marketplace.
…
Pacific Northwest National Laboratory is collaborating with Microsoft and Micron to make computational chemistry broadly available to applied researchers and industrial users. The project, known as TEC4 (Transferring Exascale Computational Chemistry to Cloud Computing Environment and Emerging Hardware Technologies), is part of a broad effort announced by the Department of Energy to quicken the transfer of technology from fundamental research to innovation that can be scaled into products and capabilities. Instead of using a centralized supercomputer, the team will use Microsoft’s Azure Quantum Elements, which features simulation workflows augmented by artificial intelligence, and incorporate Micron’s CXL memory expansion modules.
…
The Presto Foundation has announced two new contributions to Presto, the open source SQL query engine for data analytics and data lakehouse. IBM is donating its AWS Lake Formation integration for Presto, and Uber is donating its Redis-based historical statistics provider. AWS Lake Formation is a service intended to make it easy to set up a secure data lake in a matter of days, providing the governance layer for AWS S3. With the AWS Lake Formation and Presto integration, data platform teams will be able to integrate Presto natively with AWS Glue, AWS Lake Formation, and AWS S3 while providing granular security for data.
…
Storage supplier Scality has achieved a Silver rating from EcoVadis, the world’s largest provider of business sustainability ratings. EcoVadis has become the global standard by rating more than 100,000 companies globally. Scality’s score jumped into the top 25 percent of all organizations ranked by EcoVadis for sustainability improvements, and was based on benchmarks that evaluate participating organizations on 21 sustainability criteria metrics across four core pillars: Environment, Labor and Human Rights, Ethics, and Sustainable Procurement.
…
SoftIron has been authorized by the Common Vulnerability and Exposures (CVE) Program as a CVE Numbering Authority. The CVE Program seeks to provide a common framework to identify, define, and catalog publicly disclosed vulnerabilities. As each vulnerability is detected, reported, and assessed, a CVE ID is assigned and a CVE Record is created. This ensures information technology and cybersecurity professionals can identify and coordinate efforts to prioritize and address vulnerabilities and protect systems against attack.
…
Starburst, which supplies data lake analytics software, has announced new capabilities for its data lake analytics platform including Dell storage support for ECS, ObjectScale, and Ceph in Starburst Enterprise. On-premises connectivity in Starburst Galaxy extends beyond the “cloud data source only” world and allows enterprises moving to the cloud to still access their on-prem datasets. There is integration of Starburst Galaxy and Databricks Unity Catalog to provide an additional metastore alongside AWS Glue, Hive HMS, and Galaxy Metastore so customers have access to and can blend modern data sources without migration or reconfiguration. The on-prem connectivity is probably the most significant addition here as it’s highly differentiated from other solutions on the market that are more cloud-centric. The idea is to give options to those at early stages of migration or those who must keep data on-prem for regulatory/data localization reasons so they can still use that data.
…
Synology has attained Veeam Ready – Repository certification for its enterprise-oriented storage units. These units also support Active Backup for Business.
…
Reuters reports that a $14 billion tender offer from private equity firm Japan Industrial Partners (JIP) for Toshiba has ended in success and will enable the troubled conglomerate to go private. The JIP-led consortium saw 78.65 percent of Toshiba shares tendered, giving the group a majority of more than two-thirds which would be enough to squeeze out remaining shareholders. Toshiba owns about 40 percent of SSD manufacturer Kioxia, which is involved in merger talks with its NAND foundry joint venture partner Western Digital.
Marianne Budnick
…
VAST Data has appointed its first CMO, Marianne Budnik, who will lead all marketing functions including product marketing, field marketing, customer advocacy, communications and public relations, content, creative and brand strategy. She will work closely with VAST Data co-founder Jeff Denworth, who will maintain his responsibilities leading the company’s product and commercial strategies. Budnik comes to VAST from marketing exec roles at CrowdStrike, CyberArk, and CA Technologies, along with nearly a decade in marketing leadership roles at EMC Corporation. VAST has also appointed Stacey Cast as VP of global operations, responsible for VAST’s operational processes that cover product quality and delivery. She comes to VAST from being SVP of Business Operations at H20.ai, and previously held similar roles at SentinalOne, Cohesity, Nimble Storage, and NetApp.
…
Veeam commissioned Censuswide to conduct a survey of UK business leaders to understand how the rising threat of cyber-attacks is affecting their companies. Some 43 percent indicate that ransomware is a bigger concern than all other critical macroeconomic and business challenges, including the economic crisis, skills shortages, political uncertainty, and Brexit. Of the 100 directors of UK companies surveyed, a fifth considered dissolving their business in the year after an attack and 77 percent reduced staff numbers. While turnover, customer retention, and productivity were also hit, these aren’t the only negative consequences as the survey also uncovered widespread psychological effects on respondents related to ransomware attacks.
…
Weka Data Platform’s Converged Mode is the first scale-out storage on deep learning instances available to users running workloads in the cloud. It uses ephemeral local storage and memory in cloud AI instances to yield exponential cost savings and performance improvements for large-scale generative AI resources compared to traditional data architectures. It’s done this in collaboration with its customer Stability AI, an open source generative AI company, and it is intended to enhance Stability AI’s ability to train multiple AI models in the cloud, including its popular Stable Diffusion model, and extend efficiency, cost, and sustainability benefits to its customers.
…
Zadara was placed in the “leader” position in GigaOm’s Storage-as-a-Service (STaaS) Sonar Report, beating competitors including HPE, NetApp, IBM, Pure Storage, and others. It achieved a rating of “exceptional” in categories relating to cost, expansion, ease of use, data plane and protocol support, and multi-tenancy. For more information, see the full report.
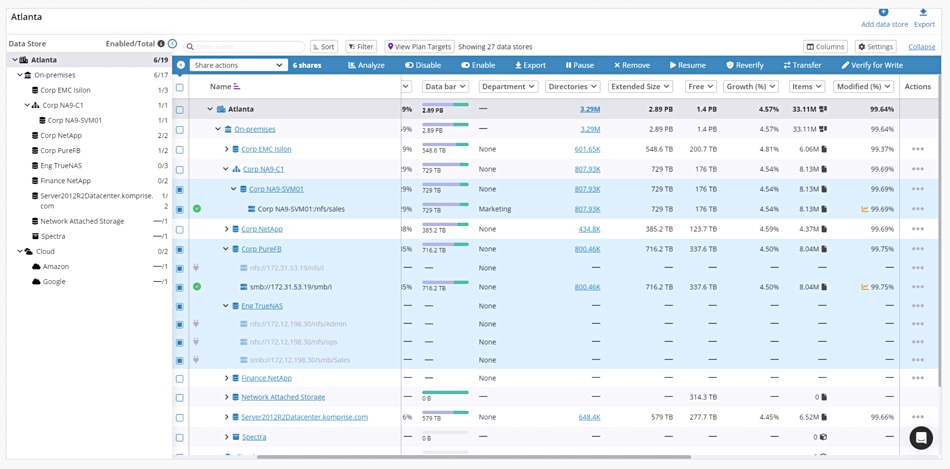
Storage Insights from Komprise provides file and object capacity and usage information across multiple suppliers, locations, and clouds.
Update: Datadobi response to Komprise’s competitive characterisations added. 3 Oct 2023.
It’s a single interface designed to let IT admins spot storage usage and consumption trends across their hybrid cloud estate, drill down, and execute plans and actions in one place to drive a better return on data storage deployments. It uses, we’re told, Komprise’s Transparent Move Technology to execute data movement plans and migrate data to users or applications, without disruption or obstructing data acess.
Storage Insights is included in the v5.0 Komprise Intelligent Data Management release.
Kumar Goswami
Kumar Goswami, co-founder and CEO of Komprise, said: “Enterprise storage is becoming more distributed across on-premises, multi-cloud and edge environments, and often across multiple vendor systems. This latest release gives customers an easier, faster way to proactively manage and deliver data services across this complex hybrid IT environment while optimizing their data storage investments.”
In March, Komprise announced an Analysis offering available as-a-service with a set of pre-built reports and interactive analysis. It could look at all file and object storage – including NetApp, Dell, HPE, Qumulo, Nutanix, Pure Storage, Windows Server, Azure, AWS, and Google – to see a unified analysis showing how data is being used, how fast it’s growing, who is using it, and what data is hot and cold. There was no ability to move files or objects with this service and a separate purchase was needed to get that functionality.
Storage Insights has that data movement capability, we’re told. Komprise bills Storage Insights is a new console that will be included in all editions of Komprise including Komprise Analysis. Komprise already provides visibility across heterogeneous storage, and Storage Insights delivers a new console that adds storage metrics to further simplify its customer’s data management. It gives admins the ability to drill down into file shares and object stores across locations and sites, and look at metrics by department, division or business unit, such as:
Which shares have the greatest amount of cold data?
Which shares have the highest recent growth in new data?
Which shares have the highest recent growth overall?
Which file servers have the least free space available?
Which shares have tiered the most data?
They can then:
Tier cold data transparently from the shares that have the highest amount of cold data to cheaper storage
Identify cloud migration opportunities such as moving least modified shares or copying project data to data lakes
Identify potential security threats and ransomware attacks on data stores with anomalous activity such as high volume of modifications
Set alert thresholds to see unusual activity or other data requiring fast actions such as storage nearing capacity
Users can customize and filter a report facility to understand the current state of storage assets across sites. They can see details on capacity, percentage of modified or new data and can filter by shares, status, data transfer roles, and more. Admins can sort file shares and view by largest, most cold data, highest recent modified data, least free space, most and least data archived or tiered by Komprise and more. They can also look into specific file servers/services, such as NetApp, Dell EMC Isilon (PowerScale), Pure Storage, AWS, Azure and Windows to check out what’s going on and keep their unstructured data estate healthy.
Storage Insights screen grab.
Krishna Subramanian, Komprise president and COO, told us: “Storage Insights is a management console to quickly understand both data usage and storage consumption as well as where you add new data stores for analysis and data management activities. We created this because several of our customers were frustrated that each storage vendor tends to report free space or storage consumption differently and they had to search across different places for this information. By adding it to our consoles, customers do not have to look in multiple places and they get one consistent definition and view of their storage metrics as well.”
Storage Insights appears similar to Datadobi’s StorageMap offering. This has an environmental dimension that Storage Insights does not. Datadobi says it helps users meet their CO2 reduction targets through carbon accounting of unstructured data storage in their hybrid clouds.
Subramanian said: “Migration vendors like DataDobi have realized the value of visibility and are now adding another product for analytics but historically this approach has lacked traction because it is a separate product, not built in as a cohesive integration, and does not address managing data at scale.” (See update note below.)
Other competitors include Data Dynamics with its StorageX file lifecycle management software, and Hammerspace with its unstructured data orchestration offering.
Komprise’s v5.0 Intelligent Data management software release also includes new pre-built reports, including Potential Duplicates, Orphaned Data, Showback, Users, and Migrations reports as well as other platform updates. Storage Insights is also available with Komprise Analysis and Komprise Elastic Data Migration. More information here.
Update. A Datadobi source said: “The premise of Subramanian’s statement is untrue. Datadobi offers one and only one solution, StorageMAP. It is, in fact, Komprise that offers multiple “products,” as can be witnessed on their website.”
“We should note that we do, however, agree with Subramanian’s statement that “this approach has lacked traction because it is a separate product, not built in as a cohesive integration, and does not address managing data at scale.” But, it is important to point out that this is true of Komprise’s multiple products, not Datadobi’s one and only StorageMAP. Only StorageMAP offers the ability to assess, organize, and act from a single platform in order to gain optimum value from data, while reducing risk, cost, and carbon footprint.”
Kioxia is looking to refinance a ¥2 trillion ($14 billion) loan arrangement pursuant to its potential merger with Western Digital’s NAND and SSD business unit, at least according to sources who spoke to Bloomberg.
Under pressure from activist investor Elliott Management, Western Digital is examining the possible split of its hard disk drive and NAND/SSD business and the latter’s subsequent merger with Kioxia. Western Digital and Kioxia have a joint venture to operate NAND fabs in Japan, with each taking approximately half the chip output to build SSDs (WD) or sell on raw chips (Kioxia).
The merger discussions have been ongoing since January. The background can be referenced here. Kioxia would own 49.5 percent of the combined business with Western Digital having 50.05 percent.
Kioxia is 56.24 percent owned by a Bain Capital-led private equity consortium and 40.64 percent owned by Toshiba, its original parent. Publicly owned Toshiba is going through a $14 billion buyout process to take it private, and Kioxia’s ability to negotiate with WD may be affected by Toshiba concerns and delayed decisions. Western Digital is also experiencing a downturn in its revenues from a severely depressed disk drive market.
The Japan Times, citing anonymous people close to the situation, reports that Kioxia’s bankers, including Sumitomo Mitsui Financial Group, Mizuho Financial Group, and Mitsubishi UFJ Financial Group, intend to file commitment letters. These banks will provide equal shares of a ¥1.3 trillion ($9.1 billion) amount. The Development Bank of Japan will provide ¥300 billion ($2 billion) and the remaining ¥400 billion ($2.8 billion) will be loan commitments, making up the ¥2 trillion total.
Some of the loan money will fund dividends payable to the existing Kioxia shareholders.
A combined Kioxia/Western Digital NAND business would have a 34 percent revenue share of the NAND market, according to TrendForce numbers from November 2022, more than current market leader Samsung’s 31 percent share. The merger makes market sense in this regard. The merged business would have its stock traded on Nasdaq and also pursue a Tokyo exchange listing.
Neither Bain, the identified banks, Kioxia nor Western Digital responded to Japan Times requests for comments. Kioxia declined to comment to Reuters as did the three named banks.
COMMISSIONED: Allocating application workloads to locations that deliver the best performance with the highest efficiency is a daunting task. Enterprise IT leaders know this all too well.
As applications become more distributed across multiple clouds and on premises systems, they generate more data, which makes them both more costly to operate and harder to move as data gravity grows.
Accordingly, applications that fuel enterprise systems must be closer to the data, which means organizations must move compute capabilities closer to where that data is generated. This helps applications such as AI, which are fueled by large quantities of data.
To make this happen, organizations are building out infrastructure that supports data needs both within and outside the organization – from datacenters and colos to public clouds and the edge. Competent IT departments cultivate such multicloud estates to run hundreds or even thousands of applications.
You know what else numbers in the hundreds to thousands of components? Jigsaw puzzles.
Workloads Placement and… Jigsaw Puzzles?
Exactly how is placing workloads akin to putting together a jigsaw puzzle? So glad you asked. Both require careful planning and execution. With a jigsaw puzzle – say, one of those 1,000-plus piece beasts – it helps to first figure out how the pieces fit together, then assemble them in the right order.
The same is true for placing application workloads in a multicloud environment. You need to carefully plan which applications will go where – internally, externally, or both – based on performance, scalability, latency, security, costs and other factors.
Putting the wrong application in the wrong place could have major performance and financial ramifications. Here are 4 workload types and considerations for locating each, according to findings from IDC research sponsored by Dell Technologies.
AI – The placement of AI workloads is one of the hottest topics du jour, given the rapid rise of generative AI technologies. AI workloads comprise two main components – inferencing and training. IT departments can run AI algorithm development and training, which are performance intensive, on premises, IDC says. And the data is trending that way, as 55 percent of IT decision makers Dell surveyed cited performance as the main reason for running GenAI workloads on premises. Conversely, less intensive inferencing tasks can be run in a distributed fashion at edge locations, in public cloud environments or on premises.
HPC – high-performance computing (HPC) applications ALSO comprise two major components – modeling and simulation. And like AI workloads, HPC model development can be performance intensive, so it may make sense to run such workloads on premises where there is lower risk of latency. Less intensive simulation can run reliably across public clouds, on premises and edge locations.
One caveat for performance-heavy workloads that IT leaders should consider: Specialized hardware such as GPUs and other accelerators is expensive. As a result, many organizations may elect to run AI and HPC workloads in resource-rich public clouds. However, running such workloads in production can cause costs to soar, especially as the data grows and the attending gravity increases. Moreover, repatriating an AI or HPC workload whose data grew 100x while running in a public cloud is harsh on your IT budget. Data egress fees may make this prohibitive.
Cyber Recovery – Organizations today prioritize data protection and recovery, thanks to threats from malicious actors and natural disasters alike. Keeping a valid copy of data outside of production systems enables organizations to recover lost or corrupted due to an adverse event. Public cloud services generally satisfy organizations’ data protection needs, but transferring data out becomes costly thanks to high data egress fees, IDC says. One option includes hosting the recovery environment adjacent to the cloud service – for example, in a colocation facility that has a dedicated private network to the public cloud service. This eliminates egress costs while ensuring speedy recovery.
Application Development – IT leaders know the public cloud has proven well suited for application development and testing, as it lends itself to the developer ethos of rapidly building and refining apps that accommodate the business. However, private clouds may prove a better option for organizations building software intended to deliver a competitive advantage, IDC argues. This affords developers greater control over their corporate intellectual property, but with the agility of a public cloud.
The Bottom Line
As an IT leader, you must assess the best place for an application based on several factors. App requirements will vary, so analyze the total expected ROI of your workloads placements before you place them.
Also consider: Workload placement is not a one-and-done activity. Repatriating workloads from various clouds or other environments to better meet the business needs is always an option.
Our Dell Technologies APEX portfolio of solutions accounts for the various workload placement requirements and challenges your organization may encounter as you build out your multicloud estate. Dell APEX’ subscription consumption model helps you procure more computing and storage as needed – so you can reduce your capital outlay.
It’s true: The stakes for assembling a jigsaw puzzle aren’t the same as allocating workloads in a complex IT environment. Yet completing both can provide a strong feeling of accomplishment. How will you build your multicloud estate?
Learn more about how Dell APEX can help you allocate workloads across your multicloud estate.
Solidigm has announced a storage-class memory (SCM) datacenter write caching SSD, taking direct aim at Micron’s XTR drive and Kioxia’s FL6 drive and putting out comparably faster random write speeds.
The D7-P5810 is a 144-layer 3D NAND drive in 1bit/cell (SLC) format with 800GB capacity in a U.2 (2.5-inch) form factor and a PCIe gen 4×4 NVMe interface. A 1.6TB version is slated to arrive in the first half of next year. Solidigm positions the drive as a fast write cache sitting in front of slower mass capacity QLC (4bits/cell) drives such as its own 61.4TB D5-P5336. The D7-P5810 can also be used in high-performance computing (HPC) applications.
Greg Matson, Solidigm VP of Strategic Planning and Marketing,said: “Solidigm has now further expanded its industry-leading endurance swim lane coverage [with] a new ultra-fast datacenter SSD with compelling specifications to serve customers’ very high write-intensive needs.”
Solidigm says the D7-P5810 can be used with QLC drives in a cloud storage acceleration layer (CSAL) deployment. CSAL is open source software that uses SCM as a write cache to shape large, small, random and sequential write workloads to large sequential writes which can then be written to QLC SSDs and improve their endurance.
Solidigm claims the D7-P5810 delivers caching, high-performance computing (HPC), metadata logging, and journaling for write-intensive workloads, with nearly 2x better 4K random write IOPS performance than Micron’s 960GB XTR NVMe SSD, also launched as an SLC caching drive.
We’ve tabulated the basic performance data for 3D NAND SLC SCM caching drives provided by Kioxia, Micron, and Solidigm to see how they stack up:
Solidigm’s D7-P5810 certainly does have better random write IOPS than Micron’s XTR in its 960GB guise, also beating its 1.92TB variant’s 350,000 IOPS, and also exceeds Kioxia’s FL6 400,000 IOPS.
Solidigm’s new drive appears – from the numbers it provided – to have the worst sequential write performance of the three, though.
It says the D7-P5810’s endurance is 50 drive writes per day (DWPD) for random writes and 65 DWPD for sequential ones. Micron’s 960GB XTR does 35 DWPD with random writes and 60 with sequential ones – both less than Solidigm’s.
The D7-P5810 provides 53µs read latency and 15µs write latency, with Micron’s 960GB XTR delivering 60µs read latency and the same 15µs write latency. Kioxia’s FL6 has 29µs read latency and 8µs write latency, being the fastest of the three in latency terms.
The Solidigm and Micron drives have the same active and idle state power draws – 12W and 5W respectively. The 800GB version of Kioxia’s FL6 is rated at 14W in the active state and 5W in what Kioxia calls its ready state, meaning idle as we understand it, making it the poorest of the three in power consumption terms.
Check out more D7-P5810 info here. The D7-P5810 will be on display at the Solidigm/SK hynix booth (A8) at the Open Compute Summit (OCP) in San Jose, CA, October 17-19, 2023.