


Ever get confused about the differences between a data warehouse, data lake, lakehouse, and data mesh? Bruno Rodrigues Lopes, a senior solutions architect at Bradesco, posted a handy set of definitions and differences on LinkedIn which provide a good way of viewing these different data constructs.
Let’s set an anchor with the difference between a database and a data warehouse. Real-time, current records of structured data are stored in a database. A data warehouse, such as Teradata, introduced in the late 1970s, stores older records in its structured data store with fixed schema for historical data analysis. Data is typically loaded into a data warehouse though an extract, transform and load (ETL) process applied to databases. Business intelligence users query the data, using structured query language (SQL), for example, and the warehouse code is designed for fast query processing.
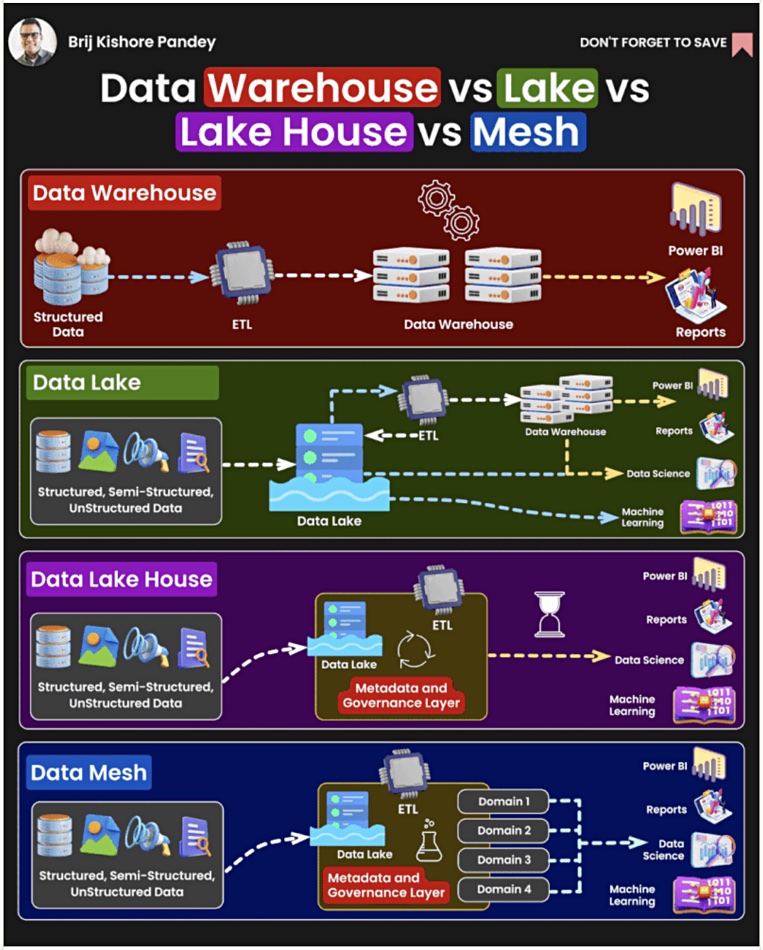
A data lake combines a large amount of structured, semi-structured, and unstructured data. Reading the data generally means filtering it through a structure defined at read time, and can involve an ETL process to get the read data into a data warehouse. An S3 or other object store can be regarded as a data lake where its contents can be used by data scientists and for machine learning.
As we might expect from its name, a data lakehouse aims to combine the attributes of a data warehouse and data lake and it is being used for both business intelligence, like a data lake, and also machine learning workloads. Databrick’s DeltaLake is an example. It has its own internal ETL functions, referencing internal metadata, to feed its data warehouse component.
A data mesh is a way of using a data lakehouse and data lake. When initiated, these two concepts typically have a centralized data team handling the questions from management and line of business (LOB) owners that need analysis routines run in the lakehouse or warehouse, as well as maintaining the warehouse/lakehouse. As the analysis workload rises, this central team can become a bottleneck, preventing timely analytic routine creation. They don’t understand LOB constraints and preferences, adding more delay.
If the LOB, domain-specific people can write their own queries, bypassing the central team, then their query routines get written and run faster. This distribution of query production to LOB teams, which operate on a decentralized self-service basis, is the essence of the data mesh approach. They design and operate their own data pipelines using the data warehouse and lakehouse as a data infrastructure platform.
The data mesh approach is supported by suppliers such as Oracle and Snowflake, Teradata, and others.
There we have it – four data container constructs parceled up, ready to be stored in your mental landscape and deployed when needed.





