


Meta has confirmed Hammerspace is its data orchestration software supplier, supporting 49,152 Nvidia H100 GPUs split into two equal clusters.
The parent of Facebook, Instgram and other social media platforms, says its “long-term vision is to create artificial general intelligence (AGI) that is open and built responsibly so that it can be widely available for everyone to benefit from.” The blog authors say: “Marking a major investment in Meta’s AI future, we are announcing two 24k GPU clusters. We are sharing details on the hardware, network, storage, design, performance, and software that help us extract high throughput and reliability for various AI workloads.”
Hammerspace has been saying for some weeks that it has a huge hyperscaler AI customer, which we suspected to be Meta, and now Meta has described the role of Hammerspace in two Llama 3 AI training systems.
Meta’s bloggers say: ”These clusters support our current and next generation AI models, including Llama 3, the successor to Llama 2, our publicly released LLM, as well as AI research and development across GenAI and other areas.”
A precursor AI Research SuperCluster, with 16,000 Nvidia A100 GPUs, was used to build Meta’s gen 1 AI models and “continues to play an important role in the development of Llama and Llama 2, as well as advanced AI models for applications ranging from computer vision, NLP, and speech recognition, to image generation, and even coding.” That cluster uses Pure Storage FlashArray and FlashBlade all-flash arrays.
Meta’s two newer and larger clusters are diagrammed in the blog:
They “support models larger and more complex than that could be supported in the RSC and pave the way for advancements in GenAI product development and AI research.” The scale here is overwhelming as they help handle “hundreds of trillions of AI model executions per day.”
The two clusters each start with 24,576 Nvidia H100 GPUs. One has an RDMA over RoCE 400 Gbps Ethernet network system, using Arista 7800 switches with Wedge400 and Minipack2 OCP rack switches, while the other has an Nvidia Quantum2 400Gbps InfiniBand setup.
Meta’s Grand Teton OCP hardware chassis houses the GPUs, which rely on Meta’s Tectonic distributed, flash-optimized and exabyte scale storage system.
This is accessed though a Meta-developed Linux Filesystem in Userspace (FUSE) API and used for AI model data needs and model checkpointing. The blog says: ”This solution enables thousands of GPUs to save and load checkpoints in a synchronized fashion (a challenge for any storage solution) while also providing a flexible and high-throughput exabyte scale storage required for data loading.”
Meta has partnered with Hammerspace “to co-develop and land a parallel network file system (NFS) deployment to meet the developer experience requirements for this AI cluster … Hammerspace enables engineers to perform interactive debugging for jobs using thousands of GPUs as code changes are immediately accessible to all nodes within the environment. When paired together, the combination of our Tectonic distributed storage solution and Hammerspace enable fast iteration velocity without compromising on scale.”
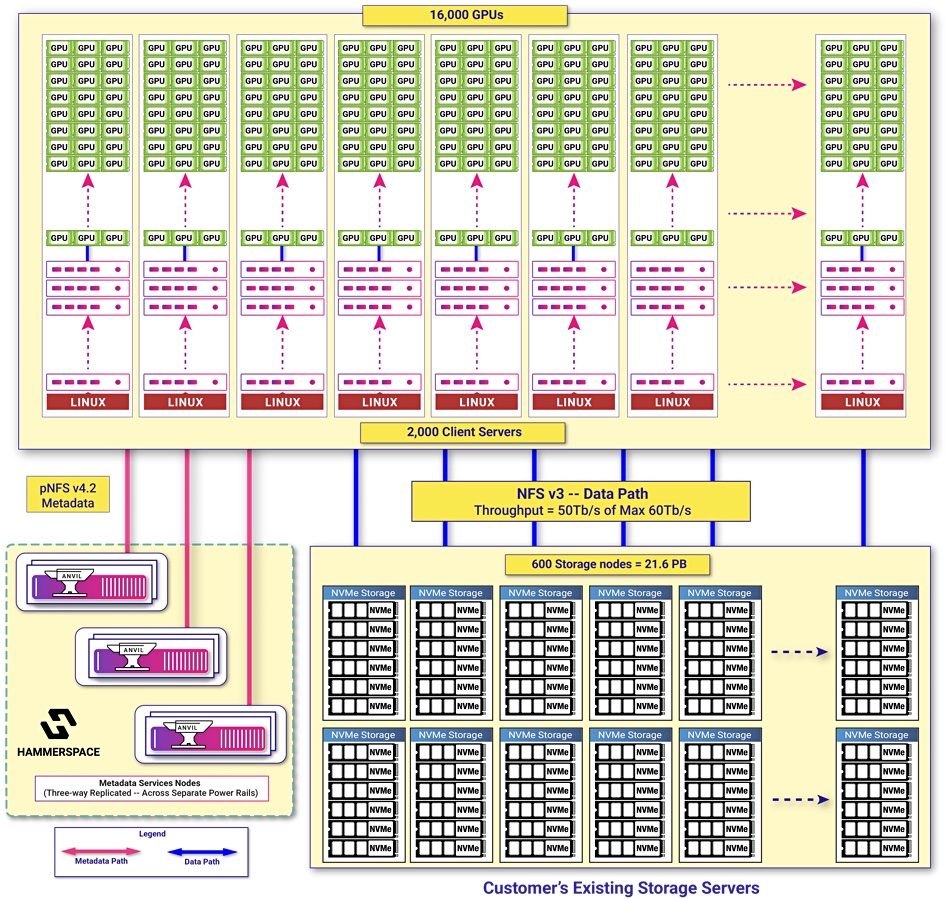
The Hammerspace diagram above provides its view of the co-developed AI cluster storage system.
Both the Tectonic and Hammerspace-backed storage deployments use Meta’s YV3 Sierra Point server fitted with the highest-capacity E1.S format SSDs available. These are OCP servers “customized to achieve the right balance of throughput capacity per server, rack count reduction, and associated power efficiency” as well as fault tolerance.
Meta is not stopping here. The blog authors say: “This announcement is one step in our ambitious infrastructure roadmap. By the end of 2024, we’re aiming to continue to grow our infrastructure build-out that will include 350,000 NVIDIA H100 GPUs as part of a portfolio that will feature compute power equivalent to nearly 600,000 H100s.”





