NetApp revenue rose 5 percent for Q3 FY24 on the back of record all-flash array sales.
It reported $1.6 billion in revenues with profits of $313 million versus $65 million a year earlier. There was a record all-flash array (AFA) annual run rate of $3.4 billion, up 21 percent year-on-year. NetApp introduced its lower cost AFF C-Series product in October last year and it says sales exceeded expectations, as did the ASA series of all-flash SAN arrays.
CEO George Kurian said on the earnings call: “I’m pleased to report that we delivered exceptional performance across the board, despite an uncertain macro environment. Revenue was above the midpoint of our guidance, driven by the momentum of our expanded all-flash product portfolio. This strength coupled with continued operational discipline yielded company all-time highs for consolidated gross margin, operating margin, and EPS for the second consecutive quarter.”
Kurian is “confident in our ability to capitalize on this momentum, as we address new market opportunities, extend our leadership position in existing markets, and deliver increasing value for all our stakeholders.”
The revenue rise reverses four successive down quarters and contrasts with competitors. Product sales of $747 million rose 9.5 percent and services went up to $859 million from $844 million.
Financial summary
- Consolidated gross margin: 72 percent
- Operating cash flow: $484 million
- Free cash flow: $448 million
- Cash, cash equivalents, and investments: $2.92 billion
Kurian said NetApp expects “a sustainable step-up in our baseline product gross margin going forward with the continued revenue shift to all-flash.” If Pure’s assertion that AFAs will replace disk and hybrid arrays by 2028 comes true, NetApp, with base conversion prospects, could be a bigger beneficiary of that than Pure.
NetApp’s all-flash revenue of $850 million was 7 percent ahead of rival Pure’s latest quarterly revenue of $789.8 million, which was down 3 percent annually.
Why did NetApp do so well this quarter? Lower cost all-flash arrays is the short answer. In contrast to Dell and HPE, it has no PC/notebook, server or networking businesses. Like Pure, it is a dedicated storage player and not exposed to these other markets that are struggling. Kurian said the hybrid cloud segment strength was ”driven by momentum from our newly introduced all-flash products and the go-to-market changes we made at the start of the year.”
He added: ”Entering FY24, we laid out a plan to drive better performance in our Storage business and build a more focused approach to our Public Cloud business, while managing the elements within our control in an uncertain macroeconomy to further improve our profitability. These actions have delivered strong results to-date [and] support our raised outlook for the year.”
The results don’t yet extend to the public cloud business, which had a minor revenue lift of just 0.666 percent. Kurian said: “As I outlined last quarter, we are taking action to sharpen our approach to our public cloud business. As a part of this plan, we exited two small services in the quarter. We also began the work of refocusing Cloud Insights and InstaClustr to complement and extend our hybrid cloud storage offerings and integrating some standalone services into the core functionality of Cloud Volumes to widen our competitive moat.”
NetApp is focusing its public cloud efforts on first-party and hyperscaler marketplace storage services. These “are growing rapidly, with the ARR of these services up more than 35 percent year-over-year.”
Kurian says NetApp is increasing its AFA market share. “As customers modernize legacy 10k hard disk drives and hybrid flash environments, we are displacing competitors’ installed bases with our all-flash solutions, driving share gains.”
GenAI hype is helping NetApp, with Kurian saying: “We saw good momentum in AI, with dozens of customer wins in the quarter, including several large Nvidia SuperPOD and BasePOD deployments. We help organizations in use cases that range from unifying their data in modern data lakes to deploying large model training environments, and to operationalize those models into production environments.”
He said NetApp’s “Keystone, our Storage-as-a-Service offering, delivered another strong quarter, with revenue growing triple-digits from Q3 a year ago.”
Guidance for next quarter’s revenues is $1.585 billion to $1.735 billion, 5 percent up on the year-ago Q4 at the midpoint. NetApp is raising its full-year revenue outlook to $6.185 billion to $6.335 billion, a 1.6 percent decrease on last year at the midpoint.
Comment
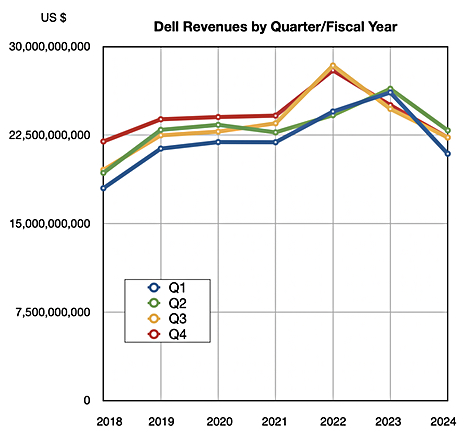
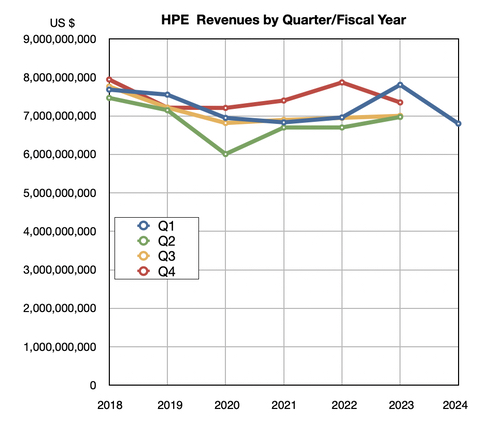
NetApp is a stable profit-making machine that has not grown its revenues for 11 years, as a chart of revenues by quarter by fiscal year illustrates:
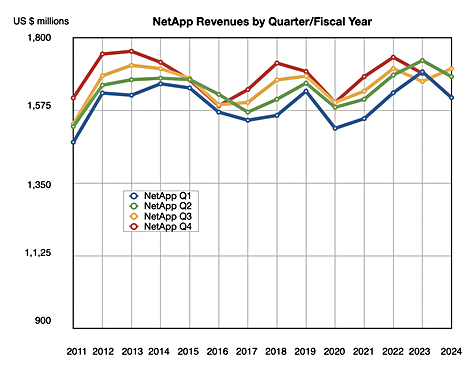
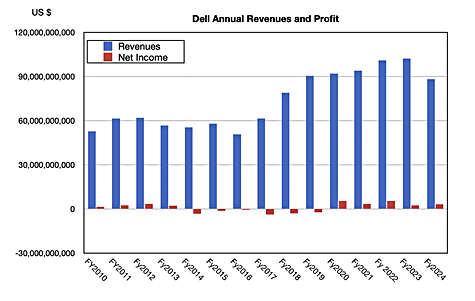
A direct chart of annual revenues shows the same thing:
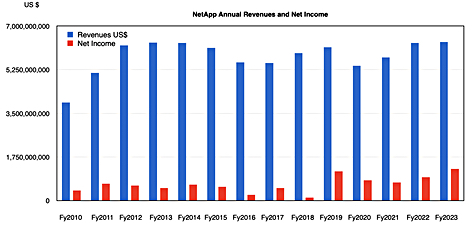
George Kurian became the CEO in 2015. Since then he’s weathered two revenue dips, in 2016-2017 and 2020, but he’s not been able to to drive NetApp’s revenues markedly higher than they were in 2013. It’s a company whose foray into the public CloudOps business has not yet proved worthwhile, despite making around $149 million of acquisitions between 2020 and 2022 . NetApp is pulling in just $151 million of public cloud revenues presently. Much of that is due to ONTAP running in the public cloud and not actually due to the acquisitions.
NetApp is generating cash and it’s not directly threatened by any competitor in the near term.