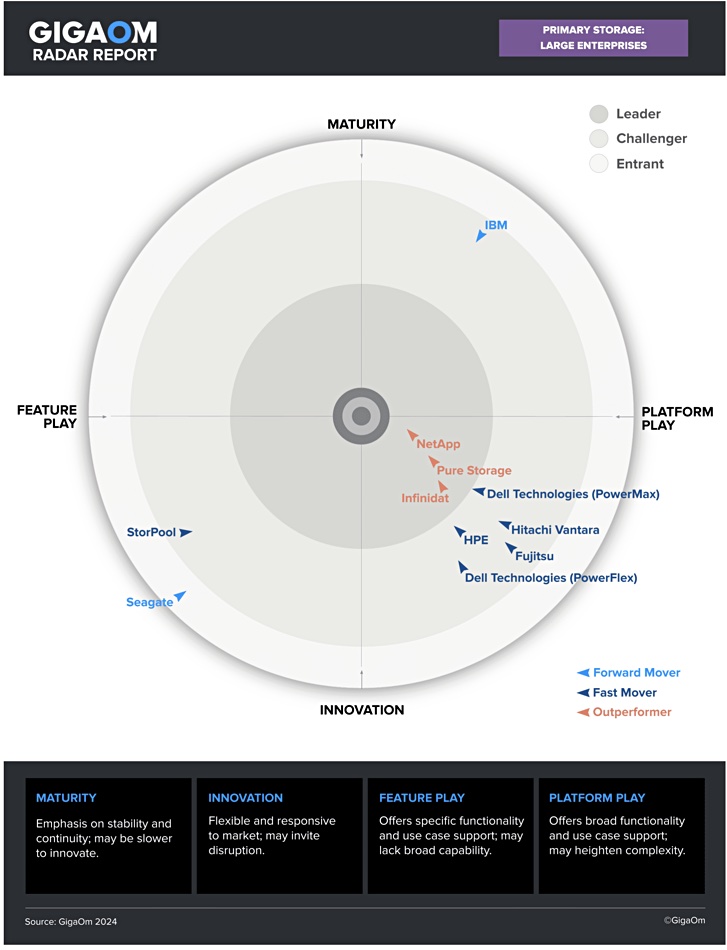
GigaOm analytical gurus have made large changes in their latest Primary Storage for Large Enterprises report, with only three leaders – NetApp, Pure and Infinidat – compared to six last year. Dell, Hitachi Vantara and IBM have been demoted to challenger status.
The GigaOm Radar for Primary Storage for Large Enterprises looks at 11 of the top primary storage products for large enterprises in the market and compares offerings against the capabilities (table stakes, key features, and emerging features) and non-functional requirements (business criteria) outlined in a companion Key Criteria report. Here is the Radar diagram:
(Its construction is described in a bootnote below.)
There were eight evaluated vendors in February 2023: Dell, Hitachi Vantara, HPE, IBM, Infinidat, NetApp, Pure Storage and Zadara. This year there are ten.
Storage-as-a-Service (STaaS) supplier Zadara has disappeared and is now evaluated by GigaOm in its Sonar for STaaS report. Fujitsu, Seagate and StorPool have entered.
Assessing the leadership circle rankings last year was complicated by the suppliers all being close to the outside edge of the leadership quadrant. Now we have NetApp clearly in front of Pure Storage, which is in front of Infinidat. All three have a nice balance between innovation and platform product plays, and are classed as outperformers.
There are three outliers. Newcomer Seagate is classed as an entrant based on its Exos X appliances. StorPool, another newcomer, is classed as a challenger with more of a feature play than a platform focus.
IBM is up on its own in the Maturity-Platform Play quadrant and, like Seagate, judged to be a relatively slow mover. GigaOm looked at its established FlashSystem 9500 all-flash array and Spectrum Virtualize architecture.
We would point out that IBM also sells its DS8000 high-end enterprise arrays to its mainframe customers, and these have not been considered by the report’s authors.
There is a group of four challenger vendors following the three leaders in the Innovation-Platform Play quadrant: Dell, newcomer Fujitsu with its ETERNUS and OEMed NetApp arrays, Hitachi Vantara (VSP 5000), and HPE (Alletra 9000). This group is led by Dell (PowerMax), with HPE close behind and then Hitachi Vantara, Dell again (PowerFlex), and finally Fujitsu.
The GigaOm analysts describe and measure each supplier’s offerings in detail in the full report, which is available to GigaOm subscribers.
Bootnote
The circular Radar diagram has four quarter-circle segments defined by a feature-vs-platform play horizontal axis and an innovation-vs-maturity vertical axis. Three concentric rings are overlaid on this with the outer one for new entrants, the middle one for challengers and the inner one for leaders. Vendor placements have direction of progress arrows indicating if they are a forward, fast or out-performing mover towards the center of the circle.
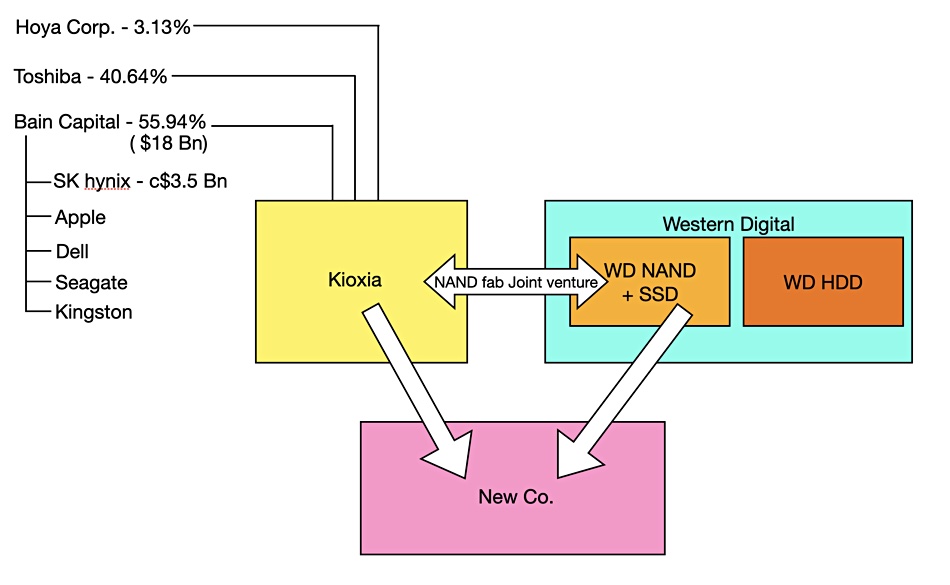
The cancelled merger talks about a combined Kioxia-Western Digital NAND/SSD business could be on again with Kioxia reportedly talking to WD and Kioxia majority shareholder Bain Capital locked in discussions with minority investor SK hynix, which previously blocked the pairing.
As reported by the Japanese outlet, 47News, Kioxia and Western Digital are reconsidering a unification of the NAND and SSD businesses. The two have a joint-venture to manufacture NAND chips in Japan and they take an approximately equal share of the produced chips to build SSDs. The on-off talks have been complicated by Kioxia having three owners: a Bain Capital consortium with around 56 percent, Toshiba with a near 41 percent, and Japan’s Hoya Corp with the remaining three percent.
This is further complicated by the Bain consortium having five participants, one of which is South Korea-based SK hynix that makes NAND chips and SSDs in competition with Kioxia and Western Digital. This dynamic caused previous merger talks to collapse due to SK’s concerns about its stake’s valuation and its competitive position in the NAND/SSD market when faced with a merged Kioxia-WD NAND+SSD business.
Kioxia ownership and merger possibility
TrendForce measured the relative market shares of the players in the NAND market in 2023’s third quarter as being:
Samsung: 31.4 percent valued at $2.9 billion
SK hynix + Solidigm subsidiary: 20.2 percent equating to $1.86 billion
WD: 16.9 percent with $1.56 billion
Kioxia: 14.5 percent with $1.34 billion
Micron: 12.5 percent with $1.15 billion
Others: 4.6 percent with $423 million
A combined Kioxia + WD business would have a 31.4 percent share of market sales, equal to Samsung’s portion, and leaving SK hynix facing two much larger players.
The situation is muddied further by Western Digital responding to activist investor Elliott Management and agreeing to separate its disk drive and NAND/SSD businesses into separate entities. That separation would be complete some time in the second half of this year.
Kioxia reportedly wants to collaborate with SK hynix in some way without violating antitrust laws. 47News also says Bain is talking with SK hynix about potential involvement in a Kioxia-WD SSD business unit merger. That suggests that SK hynix could own part of a merged Kioxia/WD SSD business.
We note that SK hynix already has two different NAND foundry operations and NAND architectures; its own and that of its acquired Solidigm business. Adding a third NAND architecture to the mix may complicate matters.
There is also the possibility of Kioxia becoming an independent public company as a way for its owners to get a more direct stake in the business. An attempt was made to do this in 2020 but it failed.
Data protector Acronis announced the integration of its Advanced Security and Endpoint Detection and Response (EDR) solutions. Its users gain access to mission-critical EDR capabilities at no additional cost. It has an MSP-centric design, enhancing technician efficiency through automation and substantially reducing false positives. Acronis recommends that MSPs deploy security to every endpoint to ensure a complete cyber-protection set up. Get more information here.
.…
Sathya Sankaran.
Sathya Sankaran, GM of CloudCasa by Catalogic, wants us to know that 2023 was a good year for CloudCasa. “2023 was the year we fully committed to the open source Velero community and made CloudCasa available to the tens of thousands of Velero users to manage and support their Velero deployments. We’ve seen continued adoption, accelerated by our joining the Azure Marketplace. Additionally, we’re so pleased to see CloudCasa named as a major player in the IDC Marketscape for Worldwide Container Data Management and a leader and outperformer in the GigaOm Radar for Kubernetes Data Protection. We appreciate that we continue to receive validation of our leading Kubernetes data protection offering from the analyst community, as well as our customers, users and partners.” CloudCasa’s spinout from Catalogic however did not happen in 2023.
…
Commvault has released research showing that while IT and security teams are talking the talk when it comes to joint operations to combat more sophisticated cyber attacks, the reality is that less than half are walking the walk. It says that traditional silos between ITOps and security teams are beginning to break down, as organizations realize the importance of increased collaboration to combat the onslaught of more sophisticated cyber attacks.
According to the Futurum-produced, Commvault-commissioned “Overcoming Data Protection Fragmentation for Cyber-Resiliency” report, nearly all (99%) respondents indicated that the relationship between ITOps and security has grown more connected over the past 12 months. For those who described the relationship between ITOps and security as “connected,” 64 percent stated they now have shared goals for maintaining the company’s security and 70 percent stated they have joint processes and procedures in place for daily operations. However, there is still work to do. For example, only 48 percent stated they have established joint processes and procedures in place to mitigate or recover from an incident.
…
Extending its coverage of archival tape library system suppliers, Hammerspace now supports QStar Archive Manager tape libraries as data sources in its Global Data Environment’s parallel file system and namespace. QStar Archive Manager provides SMB, NFS and S3 protocol options for tape library storage for data suppliers such as Cohesity, Rubrik and HYCU, and now Hammerspace. Archive Manager is gateway software running on Windows or Linux that presents one or multiple file systems or buckets for simple data management to a growing set of tape media. Learn more here.
…
IBM announced fourth quarter 2023 results, with revenues up 4% Y/Y to $17.4 billion and profits of $3.3 billion, up 14%. The Infrastructure segment of its results, which includes storage, brought in $4.6 billion, up 3%. No storage sub-segment revenues were revealed. But CFO Jim Kavanaugh said: “Distributed Infrastructure revenue was up 7%, with growth across both Power and Storage. Power performance was fueled by demand for data intensive workloads on Power 10, and Storage traction was aligned to the success of the z16 cycle.” Full year revenues were $61.9 million, up 2%, with profits of $7.5 billion, up almost fourfold on the year from $1.8 billion.
…
South Korea CXL technology startup Panmnesia is discussing CXL collaboration with HPE. The two have had one meeting so far but more are coming, with CXL’s relevance to HPC and AI acceleration being matters of interest to HPE.
…
Data protector Rubrik has celebrated its 10th birthday. A blog by co-founder amd CEO Bipul Sinha says: “Last year, we passed $500 million in subscription annual recurring revenue and currently count more than 5,500 customers.” There are more than 3,000 Rubrik employees.Sinha says: “What’s next for Rubrik? As we have from the beginning, we’ll place no limits on what we can become. We will strive for an infinite outcome as we help organizations dealing with unprecedented volume, variability, and velocity of data build a resilient future in the face of inevitable cyberattacks. We’ll continue to define new frontiers at the intersection of artificial intelligence, business data, and cybersecurity to ensure data is secure and available to the right users on any platform at the right time for the right duration.”
…
Seagate has applied its Exos 24TB technology to NAS drives with its IronWolf Pro 24 TB, upping the maximum capacity by 2 TB. This 10-platter helium-filled drive tops the existing 2 to 22 TB IronWolf capacity range and has the same 285MBps max sustained transfer rate as the 22 TB drive, 512 MB cache, 6 gig SATA interface, 7,200rpm spin speed, 2.5 million hours MTBF, 5-year warranty and 550 TB/year workload. It has Time Limited Error Recovery (TLER) and rotational vibration (RV) sensors paired with dual plane balancing to lower vibration, and is priced at $649. Get a look at the datasheet here.
…
Wells Fargo analyst Aaron Rakers calculates, based on our estimate of Toshiba’s 4Q23 HDD revenue totaling ~$665 million during 4Q23, we would estimate that total 4Q23 HDD industry revenue totaled approximately $3.37 billion, down 6.5 percent year on year and up 11 percent quarter on quarter. We now estimate that we are at a point of realizing a return of year on year growth in HDDs with our combined 1Q24 revenue estimate at ~$3.7 billion implying a 7 percent annual increase and an 11 percent jump for the quarter. This would represent the first year over year growth for the HDD industry since 1Q22.
Combined 4Q23 total HDD capacity shipped totaled approximately 215.1 exabytes, down 8 percent year on year and up 9 percent for the quarter. And total 2023 HDD exabytes shipped totalled approximately 849.3 exabytes, down 28 percent year on year and down 38 percent from the peak trailing twelve-month capacity shipped for the period ending 2Q22.
Nearline HDD capacity shipped in 4Q23 totaled ~151.4 exabytes, which was down 7 percent year on year but up 13 percent for the quarter. Seagate and Western Digital’s nearline HDD capacity shipments were up 16 percent and 23 percent respectively during 4Q23, while Toshiba’s nearline HDD capacity shipments were up only 3 percent for the quarter during this time. He estimates that Western Digital and Seagate had a ~44.5 percent and ~43.0 percent nearline HDD capacity ship share during 4Q23 – totalling 87.5 percent and leaving Toshiba with 12.5 percent.
…
GPU IaaS provider Genesis Cloud is using VAST Data’s storage to help it offer AI initiatives and Large Language Model (LLM) development. The two explain that, by providing fast, real-time access to data across public and private clouds, VAST eliminates data loading bottlenecks to ensure high GPU utilization, better efficiency and ultimately lower costs to the end customer. Germany-based Genesis Cloud has datacenters In Europe and North America with the latest AI accelerators and GPUs, network and storage facilities designed for GenAI, Machine Learning, Simulations, Rendering, and other high-performance computing workloads. This customer win is similar to previous VAST Data wins at CoreWeave and Lambda Labs.
…
Lola Visual Effects (VFX), which produces computer generated effects for feature films and television series, is using VAST Data storage to help streamline global collaboration on its data-intensive productions. It is adopting AI technologies and deep learning tools to enhance its special effects. VAST’s global namespace and metadata helped with collaboration across Lola VFX’s locations and paved the way for automated asset tracking and integration of production systems, and solved playback caching issues with its previous storage system. That meant it wouldn’t play back 4K footage in real time.
Danny Allan.
Edson Williams, Founder and Managing Partner at Lola VFX, explained: “Our operations demand infrastructure that not only supports but enhances real-time global collaboration. Our demands are extreme, but VAST actually exceeded our expectations. Initially, we anticipated a 24 to 36 month payback period, but with the remarkable efficiency gains we’ve experienced, we expect to see a significant return on our investment in as few as 15 to 18 months.” It bought its first VAST system I 2022. Read the case study here.
…
Veeam CTO Danny Allan is leaving the company. There is a next step in his career but his LinkedIn post doesn’t say much about it all.
Generative AI’s all-pervading influence has encouraged SingleStore to add new features to its Pro Max release to make AI app development faster.
SingleStore’s eponymous database combines real-time transactional and analytic database features and has hundreds of customers including Siemens, Uber, Palo Alto Networks and SiriusXM. SingleStore surpassed $100 million in ARR in 2022. In April last year it demonstrated how ChatGPT could be used to find data in SingleStoreDB. At the time it said SingleStore was the ideal database for private data search by ChatGPT, “given its abilities to store vector data, perform semantic searches and pull data from various sources without extensive ETL.” Now it’s added AI-relevant tooling to its latest database release.
Raj Verma.
CEO Raj Verma laid it on thick in a statement: “This isn’t just a product update, it’s a quantum leap … SingleStore is offering truly transformative capabilities in a single platform for customers to build all kinds of real-time applications, AI or otherwise.”
The new feature list includes:
Indexed vector search. Support for vector search using Approximate Nearest Neighbor (ANN) vector indexing algorithms, leading to 800–1,000x faster vector search performance than precise methods (kNN). This hybrid (full-text and indexed vector) search that takes advantage of SQL for queries, joins, filters and aggregations, and place SingleStore above vector-only databases that require niche query languages and are not designed to meet enterprise security and resiliency needs.
On-demand compute service for GPUs and CPUs. This works alongside SingleStore’s native Notebooks to let developers spin up GPUs and CPUs to run database-adjacent workloads including data preparation, ETL, third-party native application frameworks, etc. This capability is said to bring compute to algorithms, rather than the other way around, enabling developers to build highly performant AI applications without unnecessary data movement.
CDC: Native capabilities for real-time Change Data Capture in (CDC) for MongoDB, MySQL and ingestion from Apache Iceberg without requiring other third-party CDC tools. SingleStore will also support CDC out capabilities to ease migrations and enable the use of SingleStore as a source for other applications and databases like data warehouses and lakehouses.
SingleStore Kai. API to deliver over 100x faster analytics on MongoDB with no query changes or data transformations required. It supports BSON data format natively, has improved transactional performance, increased performance for arrays and offers industry-leading compatibility with MongoDB query language.
Projections. Allow developers to greatly speed up range filters and “group by” operations by 3x or more by introducing secondary sort and shard keys.
Free shared tier. SingleStore has announced a new cloud-based Free Shared Tier that’s designed for startups and developers to quickly bring their ideas to life – without the need to commit to a paid plan.
Nadeem Asghar, SVP, Product Management + Strategy at SingleStore, said “New features, including vector search, Projections, Apache Iceberg, Scheduled Notebooks, autoscaling, GPU compute services, SingleStore Kai, and the Free Shared Tier allow startups – as well as global enterprises – to quickly build and scale enterprise-grade real-time AI applications. We make data integration with third-party databases easy with both CDC in and CDC out support.”
SingleStore claims its Pro Max database is the industry’s first and only real-time data platform designed for all applications, analytics and AI. It supports high-throughput ingest performance, ACID transactions and low-latency analytics, and structured, semi-structured (JSON, BSON, text) and unstructured data (vector embeddings of audio, video, images, PDFs, etc.).
We are entering a period of NLQ (Natural Language Queries) with generative AI features added to databases, according to Noel Yuhanna, VP and Principal Analyst at Forrester Research. “Generative AI and LLM can help democratize data.”
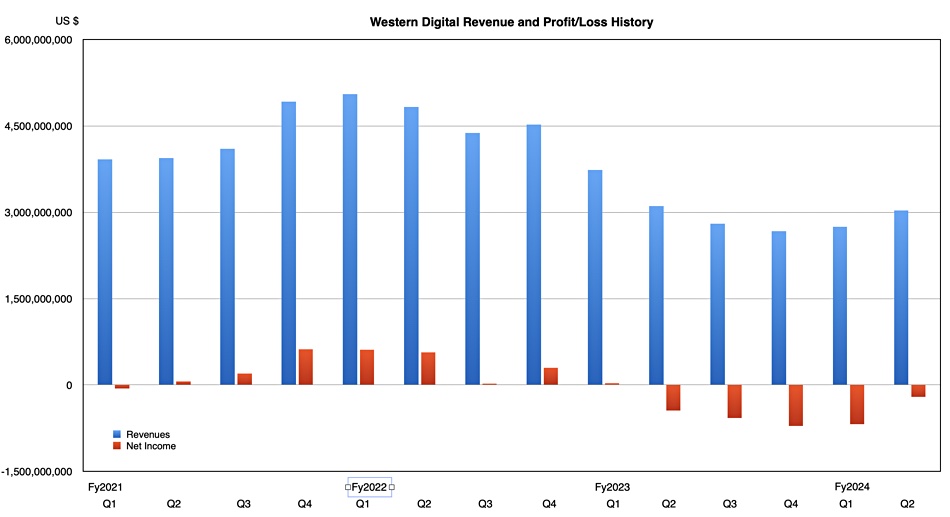
The disk/SSD downcycle low point has been reached for Western Digital with its second successive sequential revenue growth quarter.
Revenues in the second quarter of its fiscal 2024, ended December 29, were $3.03 billion, two percent down year-on-year but up 10 percent sequentially. There was a loss of $268 million, lower than the year-ago $446 million loss. The charted pattern of quarterly results clearly shows a trough has bottomed out:
WD CEO David Goeckeler said in a canned statement: “Western Digital’s second quarter results demonstrate that the structural changes we have put in place over the last few years and the strategy we have been executing are producing significant outperformance across our flash and HDD businesses.”
Overshadowing the results [PDF] are WD’s decision to split its HDD and SSD units into separate businesses and Seagate’s newly opened-up capacity and density lead with its HAMR tech – but we’ll finish with the quarter’s numbers before getting to these issues.
Financial summary
Gross margin: 16.2% vs 17% a year ago
Operating cash flow: $92 million
Cash and cash equivalents: $2.48 billion
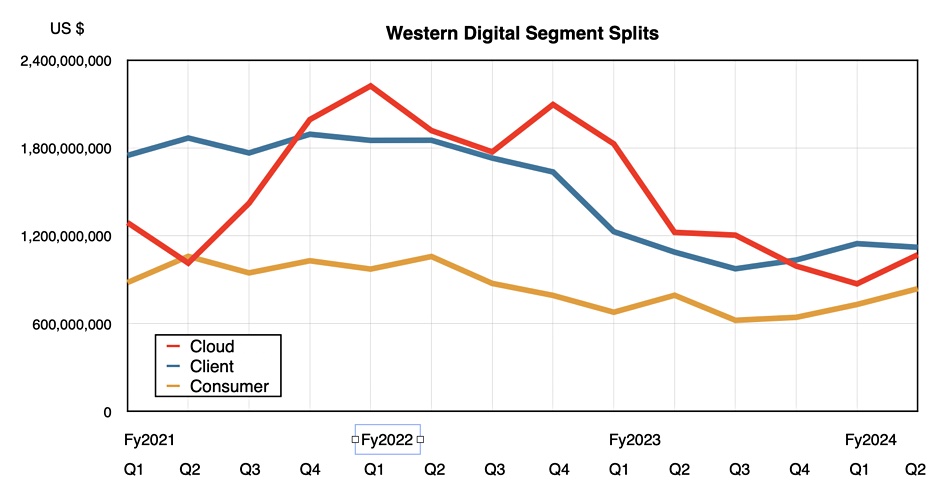
WD sells its SSDs and HDDs into three markets: cloud (enterprise and CSP), client (PC and notebook), and consumer (retail). The client ($1.1 billion, up 3% y/y) and consumer ($839 million, up 6% on seasonal buying) segments grew year-on-year while cloud ($1.1 billion, down 13%) went downhill year-on-year but rose an encouraging 23 percent sequentially;
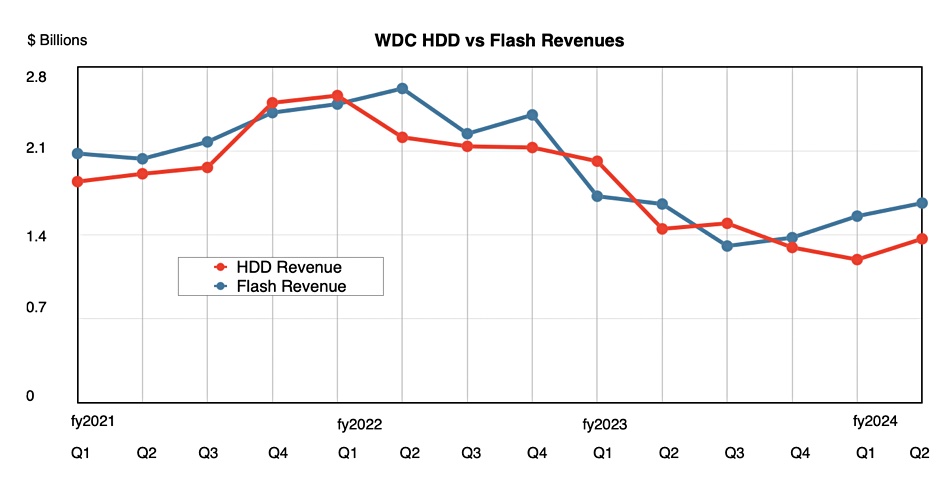
Its flash-based revenues were $1.7 billion in the quarter, flat year-on-year, while HDD revenues at $1.4 billion were down six percent, although up sequentially. Goeckeler said: “The sequential revenue increase was driven by improving nearline demand and pricing. Moreover, we are encouraged by demand in China with revenue doubling on a sequential and year-over-year basis, both of which were ahead of our expectations. We anticipate year-over-year growth in HDD throughout this calendar year.”
WD said its WD_BLACK gaming SSD products achieved record revenue with bit shipment growth of over 50% year-over-year.
SMR (shingled magnetic recording) disk drives were important as WD shipped approximately one million UltraSMR hard drives in both the first and second quarters of fiscal 2024. It expects SMR drive shipments to comprise the majority of nearline demand by calendar year 2025. Goeckeler said: “SMR drive shipments to continue to outgrow that of CMR drives going forward. Importantly, the adoption of UltraSMR is broadening to our major customers worldwide including a third cloud titan in the US this year, as well as hyperscale and smart video customers in China.”
Goeckeler added: “The sequential revenue increase was driven by improving nearline demand and pricing. Moreover, we are encouraged by demand in China with revenue doubling on a sequential and year-over-year basis, both of which were ahead of our expectations. We anticipate year-over-year growth in HDD throughout this calendar year.”
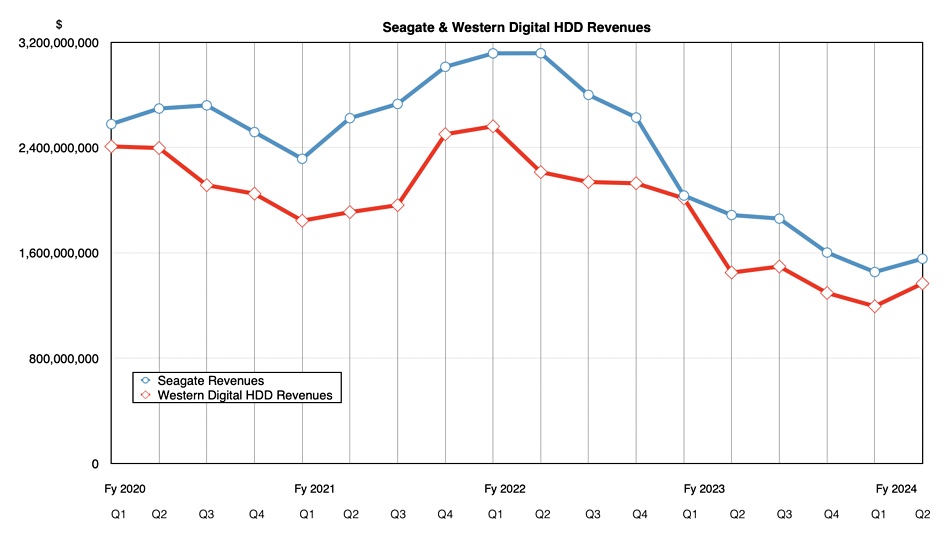
WD’s disk revenues grew a little closer to industry leader Seagate’s as a chart shows;
Earnings call
CEO David Goeckeler.
Goeckeler was optimistic about the future in an earnings call with analysts on Thursday, saying: “In addition to the recovery in both flash and HDD markets, we believe storage is entering a multiyear growth period … We believe the second wave of generative AI-driven storage deployments will spark a client and consumer device refresh cycle and re-accelerate content growth in PC, smartphone, gaming, and consumer in the coming years. Our flash portfolio is extremely well positioned to benefit from this emerging secular tailwind.”
His prepared HDD remarks seemed, we stress “seemed,” inappropriate as Seagate has just announced its 30 TB and 32 TB HAMR drives, beating WD’s 24 TB PMR and 28 TB SMR disks capacity-wise. Goeckeler said: “In HDD, Western Digital’s leading ePMR platform and enhanced UltraSMR technology allow us to provide the highest-capacity drives for mass market deployment.” Well, actually they won’t, or will they?
He continued: “We have a strong conviction that our portfolio strategy of first commercializing Western Digital’s industry-leading UltraSMR technology, which will be followed by our transition from ePMR to HAMR offers the best TCO to our customers in both the near and long term while delivering leading portfolio profitability in the industry.”
Then he said: “Over the next several years, we will be introducing a number of exciting products, including multiple generations of nearline drives, combining ePMR, OptiNAND, and UltraSMR technologies in the 30 to upper 30-terabyte capacity range, all of which will be ready for high-volume production to support the explosion of AI training data and content.”
But Seagate is talking about shipping 40+ TB drives in two years. On this basis WD is falling behind. But, in answering a question on the call, Goeckeler said he sees it differently: ”I can tell you our customers have an enormous amount of confidence in our road map, in our current products, and you’re seeing that in the performance of the business. You’re seeing accelerating growth, you’re seeing better profitability, you’re seeing share gains, that’s a clear indication that customers are very happy with our products.”
Also: “For our portfolio, given our UltraSMR technology; it’s been adopted by the market. HAMR does not make sense until you get to four terabytes per platter and because HAMR adds a lot of costs to the product … We will transition to HAMR when we get to that four terabytes per platter, that’s the economic crossover, right, that we’re looking for from a portfolio management point of view.”
Forty terabytes is in reach with WD’s existing technology, Goeckeler said: “We’ve built a technology road map that allows us to get to 40 terabytes on very well-proven, cost-controlled, high manufacturing ability technology. And we’re looking forward to delivering that to the market over the next couple of years.”
NAND and SSDs
In the flash area Goeckeler said: “We remain on track to ramp an array of QLC-based client SSDs utilizing BiCS6 technology. Our ability to combine this new high-performance node with our in-house controller development allows us to offer a portfolio of client SSDs with unmatched performance and value. We expect these products to lead the transition to QLC flash in calendar year 2024. Additionally, BiCS8 yield is progressing well, and we remain on track to productize this technology.”
But WD will not increase flash manufacturing capacity, with Goeckeler saying: “Although flash pricing has started to increase, our profitability and cash generation continue to be well below the level that justify an increase in capital investments. We anticipate wafer equipment spending will remain at historic lows in the near term and flash to be undersupplied for an extended period of time. Overall, we will continue to focus on allocating our bids to the most attractive end markets and anticipate flash ASP increases to be the primary revenue growth driver throughout this calendar year.” Price increases will drive WD flash revenues higher.
The coming split between WD’s HDD and NAND/SSD businesses was not discussed. Wells Fargo’s Aaron Rakers expects an analyst day meeting in the mid to late-summer timeframe to focus on this.
Next quarter’s outlook is for revenues of $3.3 billion +/- $0.1 billion, which will be a 17.7 percent increase on the year-ago Q3. Let the good times roll.
Nyriad, the company offering GPU-powered storage controller technology, is up for sale.
CEO Derek Dicker
A memo from CEO Derek Dicker reads: “After thoroughly considering and exploring various options, the Nyriad board has decided to actively seek to sell all or part of the company and its technology. The board believes that Nyriad technology continues to hold great promise and that this step is in the best interest of its shareholders and the long-term sustainability of its technology.”
So ends, for the time being at least, a brave attempt to rewrite X86-based storage array controller design assumptions by augmenting CPU processors with GPU accelerators.
Nyriad’s founding in 2014 was rooted in New Zealand’s involvement with the Square Kilometre Array (SKA), which at the time was still being planned and is now under construction.
Matthew Simmons and Alex St John co-founded Nyriad as CEO and CTO respectively in NZ to build a storage controller that could cope with exabyte levels of data from the SKA, which will pick up radio signals from outer space to help scientists better understand our universe.
The duo decided to use an Nvidia GPU in the controller, replacing RAID controllers and augmenting the controller’s x86 processor. The x86 CPU cores controlled the array with GPU cores responsible for computational storage functions and NVMe SSDs providing a fast storage base. This architecture would enable it to handle tremendous levels of incoming data bandwidth through parallel processing by the GPU accelerator.
They developed an Nsulate software and a high-performance storage controller platform by 2018 using $10 million to $20 million of VC funding. Nsulate presented the array as a block device to Linux hosts, doing real-time erasure coding and encryption/decryption, and with internal mirroring to protect against drive failures. However the software, and the business, was immature and things fell apart.
About 60 of its 100-plus staff were laid off by March 2019, and co-founder Alex St John left and sold his shares. New Zealand pulled out of the SKA project ending Nyriad’s reason for existing. But lead investor Guy Haddleton thought the technology still had promise. He became chairman that month, and restructured the company.
Matthew Simmons had left by late 2020 when $28 million in funding was announced, and 32-year IBM vet Herb Hunt was made CEO. He relocated the head office to San Francisco while keeping engineering in New Zealand, and appointed new execs. Sixteen months later there was another restructuring. Haddleton resigned form the chairmanship, Hunt became exec chairman, and Derek Dicker was appointed CEO.
Nyriad array in 2019.
Dicker’s resume included a stint as corporate VP and GM of Micron’s Storage Business Unit. Under his reign Nyriad released H-Series SAN arrays with CPU-GPU controllers and disk drive storage in 2022. They featured fast rebuilds and were marketed into the HPC, media and entertainment, and backup, restore, and archive areas.
It announced it was seeking funding for further development in June last year, having gained customers and channel partners.
That cash has not come to pass as, we understand, the macro-economic situation, the rise of all-flash arrays, and VC investor focus on analytics (think data warehouse, lake, and lakehouse) and AI companies meant that Nyriad was overlooked. Its market traction came to a halt, and Dicker and the board came to the conclusion that a full or partial asset sale was the best option.
His memo added: “Nyriad recently formally engaged with a firm to administer the sales process on an accelerated timeline, and that firm has begun distributing a sale memo to parties and organizations that may have a strategic interest. With this in mind, the company has taken steps to reduce expenses while it conducts this process.”
This is heart-breaking news for Nyriad’s employees and a grim outcome for its customers, channel partners, and investors. We wish them all the best.
SK hynix grew revenues in the final calendar quarter of 2023, the first growth for one and a half years, as memory buyers returned to the market.
The company recorded krw 11.3 trillion ($8.46 billion) in the quarter, 46.9 percent higher than a year ago. There was a loss of krw 1.4 trillion ($1.0 billion), much reduced from the year-ago loss of krw 3.5 trillion ($2.6 billion). SK actually reported an internally measured operating profit – krw 346 billion ($259 million), its first for four quarters. Full year revenues were krw 32.8 trillion ($24.5 billion) with a loss of krw 9.1 trillion ($6.8 billion), SK hynix’s first annual loss in at least seven years. It’s been a severe downturn.
VP and CFO Kim Woohyun stated: “We achieved a remarkable turnaround, marking the first operating profit in the fourth quarter following a protracted downturn, thanks to our technological leadership in the AI memory space.”
In his view: “We are now ready to grow into a total AI memory provider by leading changes and presenting customized solutions as we enter an era for a new leap forward.”
SK hynix said overall memory market conditions improved in the last quarter of 2023 with demand for AI server and mobile applications increasing and average selling price (ASP) rising. Sales of its main products, DDR5 and HBM3 (used in GPU servers), increased by more than four and five times, respectively, compared with a year earlier.
It will now proceed with mass production of HBM3E, a main AI memory product, and ongoing development of HBM4, while supplying high-performance, high-capacity products such as DDR5 and LPDDR5T to server and mobile markets, to meet increasing demand for high-performance DRAM.
SK hynix will also prepare high-capacity server module MCRDIMM ((Multiplexer Combined Ranks Dual In-line Memory Module) and mobile module LPCAMM2 (Low Power Compression Attached Memory Module 2) to respond to increasing memory demand due to AI server and on-device AI adoption.
Recovery in the NAND market is relatively slower and SK hynix said it would continue to improve profitability and stabilize the business by expanding sales of premium products such as eSSD. The GenAI boom is driving server, and hence memory, sales. As Seagate reported yesterday, any AI fillip for storage has still to come, although storage suppliers are confident it is coming.
LucidLink has turned to Projective Technology to supply remote workers in post-production workflow environments with what it hopes is fast file delivery.
Projective provides post-production facilities for broadcasters, creative agencies, and video production facilities worldwide. LucidLink’s FileSpaces product streams file segments directly from a central cloud vault as they are needed.
Derek Barrilleaux, Projective Technology CEO, said of the partnership this week: “For years everyone’s been trying to run post-production in the cloud. There’s been limited success moving some of the workflows, but latency for true editorial needs remained an issue. LucidLink made real-time collaboration and remote editing possible, but to run post-production at scale in the cloud you need a framework that brings structure and efficiency to your editing projects.
“This is what makes the combination of Strawberry with LucidLink so compelling. Strawberry’s project-based, intuitive workflows, together with LucidLink’s support for remote connectivity, breaks down collaboration barriers and eliminates creative silos.”
The deal involves the the integration of Projective’s post-production collaboration platform, Strawberry, with LucidLink’s remote connectivity software, to provide, they say, the best of both worlds: the structure, security, and versatility of Strawberry with the scale and global accessibility of LucidLink, enabling enterprise-level post-production and accelerating time-to-delivery.
Strawberry offers what’s said to be intelligence around project management, permissions, and sharing, with comprehensive asset and project-based search capabilities that is supposed to allow users to locate their content quickly, no matter where they are. Capabilities such as Strawberry’s review and approval framework, Avid-style bin locking, and workflow extensions for Adobe Creative Cloud are now extended to remote users through LucidLink’s Filespaces.
Scott Miller, global partners and alliances director at LucidLink, spoke of “delivering a shared space for real-time, remote collaboration. The integration enables multiple users to easily manage their projects at scale through Strawberry’s content management tools, from anywhere, at the same time, and with the flexibility, security, and performance that LucidLink delivers.”
Once again the tough demands of the entertainment and media industry provide an opening for a seemingly innovative startup in what some would consider to be a mature area – cloud-delivered file collaboration services. LucidLink is making progress because neither CTERA, Hammerspace, Nasuni, nor Panzura have the functionality and/or partnership required, in our opinion.
The Flash Memory Summit is renaming itself to the Future of Memory and Storage, conveniently keeping the FMS acronym.
FMS 2023 was held in August at the Santa Clara conference center in Silicon Valley, showcased 95 exhibitors, and drew in more than 3,000 visitors. It was the eighteenth occurrence of this annual and near-iconic conference in the memory and flash memory world, and attracts world-class technology expert presenters and panelists, and leading-edge exhibitors. In fact, the show has become the world’s largest such conference and exhibition.
Kat Pate.
Kat Pate, FMS CEO, said: “Over the past few years, we have welcomed storage and related applications to FMS and the event has grown. We are pleased to make it official by rebranding the event. We know this change will bring continued growth for FMS, and we look forward to welcoming new companies.”
The show organizers say the intention is to encompass all volatile and persistent memory and storage applications. This is because, they say, the memory and storage industry is undergoing rapid technology advancements in the artificial intelligence and machine learning, data analytics, high performance computing, cloud computing services, automotive and even outer-space application areas. FMS organizers want the event to bridge the gap between cutting-edge memory and storage solutions, and the demands of emerging use cases and applications.
FMS 2024 is set to feature dedicated sessions and discussions on the symbiotic relationship between memory-storage technologies and AI applications. Experts in their field will deliver keynote addresses and participate in panel discussions, providing insights into the evolving memory and storage technology landscape.
The conference and exhibition will put the spotlight on the latest products and systems in memory and storage, giving attendees insights into future trends and technological breakthroughs in the industry. Attendees can also expect decent networking opportunities with fellow professionals as well as analysts, media, and industry leaders from diverse storage-related fields, encouraging collaboration and innovation.
Mark your calendars; the next FMS event will take place at the Santa Clara convention center from August 6 to 8 this year. Find out more about at the FutureMemoryStorage.com website.
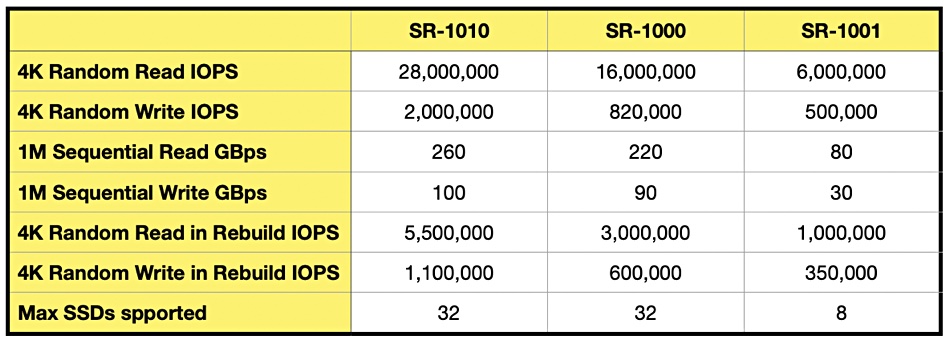
GPU-powered RAID card provider Graid has developed an entry-level card: the SR-1001.
Graid until now has had two products: the SR-1000, and the SR-1010. Both support up to 32 SSDs but the SR-1000, Graid’s first card, has a PCIe gen 3 interface while the SR-1010 uses PCIe gen 4 and is therefore faster. They are for use in enterprise datacenters. Unlike traditional RAID cards that connect directly to storage drives, Graid’s SR, or SupremeRAID, products are PCIe-connected peers on the host’s motherboard and are not in the data path.
Leander Yu, President and CEO of Graid Technology, has this to say about the launch on Thursday: ”As NVMe SSDs play a crucial role in cloud, core, and edge infrastructure, the demand for enhanced data protection without compromising performance is evident. SupremeRAID SR-1001 addresses this need by delivering best-in-class performance and airtight data protection while optimizing throughput, parallelism, and latency, ensuring seamless performance at the edge.”
The SR-1001 is a limited version of the SR-1000 in that it supports just 8 SSDs and has lower performance than the other two cards, as the table below summarizes:
The SR-1001 has the same code base as its siblings. It is intended for use by tower and edge servers, professional workstations, and gaming desktops, running apps such as CAD, video editing, IoT workloads, and games.
Thomas Paquette, senior veep and GM at Graid, said the biz has plans to increase the number of SSDs supported by its cards later this year and will also add PCIe 5 support. That will send performance higher as well, we’re promised. He said Graid has no plans to add deduplication or compression or other data services to the hardware. Its products are intended to be NVMe SSD failure protection cards and not computational storage devices.
Graid believes its performance numbers versus legacy RAID cards, such as Broadcom’s 9600 and 9500 offerings, are superior. That said, the SR-1001 is said to be slightly less performant than Broadcom’s 9600 gear on the rebuild IOPS front but apparently convincingly better at sequential throughput.
The SupremeRAID cards also beat software RAID products, which use host server CPU cycles for RAID parity calculations and can limit overall server application performance.
The SR-1001 extends Graid’s market coverage. It has also developed a UEFI card product to protect server boot SSDs, and a fan-less product to reduce card thickness. Its market prospects look good, with Paquette telling IT journalists touring Silicon Valley this month that its AI/ML, edge computing, speed-dependent big data analytics, cloud service provider, and telecom & 5G infrastructure market segments are all growing.
He said the company had completed an A+ VC round last year, raising less than half the $15 million it pulled in from a 2022 A-round. We believe its total funding is around $20 million. It will probably run a B-round later this year to pay for business infrastructure expansion, such as hiring more sales and marketing people. Paquette said: “When we get to that point as a company, we would have additional investors and would naturally cede some control which is typical as venture backed companies progress through different phases of growth.”
Check out a datasheet-class SR-1001 brochure here.
Our view:
No competitors to Graid have emerged, meaning other GPU-powered RAID cards, since it launched its product family in 2021. The SupremeRAID series is said to have a substantial performance advantage over leading RAID card supplier Broadcom’s products, and leaves software RAID behind as well. It has a substantial performance runway ahead as PCIe gen 5 servers with a gen 5 SupremeRAID card will go even faster than PCIe gen 4 server/card combinations. Unless Broadcom and other hardware RAID card suppliers adopt the same GPU-powered technology, or an equivalent whatever that might be, they will stay in the relative low performance area.
Graid has taken in around $20 million in funding and a B-round would almost inevitably increase its valuation from the A-rounds. We here at B&F think an IPO is unlikely, the technology being quite niche, but an acquisition looks a likelier prospect. This is just our gut feeling to be clear. We have no inside knowledge. The place we get to with this is a RAID card supplier, such as Broadcom, feeling the competitive heat and buying Graid. What would it cost? We’re in string length estimation territory at this point. Suppose a 5x multiple on the VC funding was taken as a starting point; that’s $100 million. But a B-round valuation could put a higher price on the company; say $500 million or more. It’s going to be an interesting year.
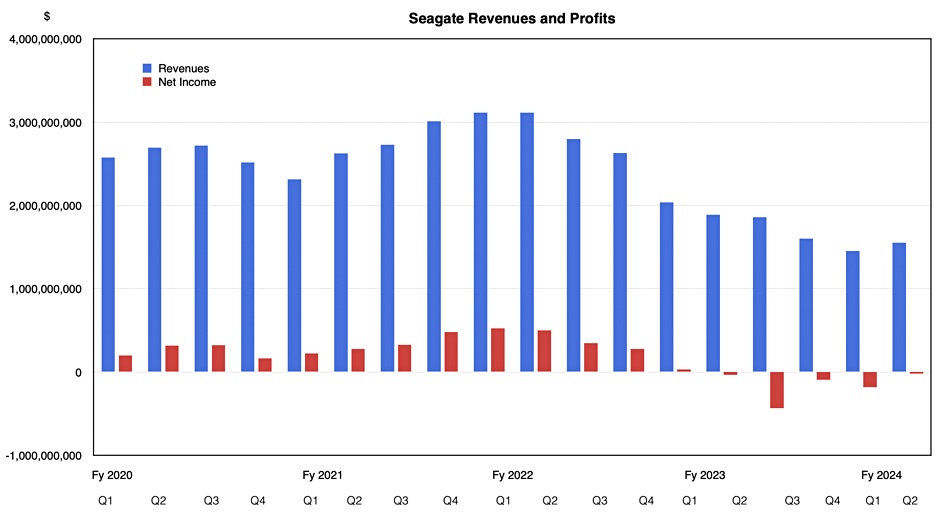
Spinning-disk slinger Seagate this week signaled its revenue recovery has begun with a sequential revenue upturn in its second fiscal 2024 quarter.
It reported [PDF] revenues of $1.56 billion, down 17 percent year-on-year but up seven percent from the previous quarter and its first such Q-to-Q upturn after seven Q-to-Q declines in a row. The biz recorded an overall loss of $19 million, much reduced from the year-ago $33 million loss and especially from last quarter’s $184 million loss.
CEO Dave Mosley on an earnings call with analysts said: “Revenue of $1.56 billion was led by sequentially improving cloud nearline demand and a seasonal uptick in consumer drives, offset partially by the decline in VIA sales that we anticipated. … These performance and demand trends affirm our expectation for the September quarter to be the bottom of this prolonged down cycle.”
VIA refers to the video surveillance market.
Financial summary:
Operating cash flow: $169 million
Free cash flow: $99 million
Gross margin: 23.3% vs 23.6% a year ago
Diluted EPS: -$0.09/share vs $10.132/share a year ago
Cash and cash equivalents: $787 million
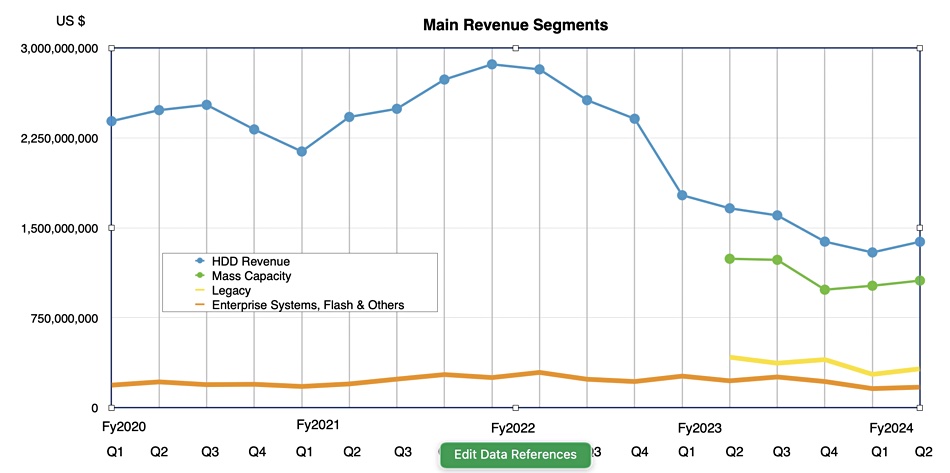
Seagate made $1.38 billion from disk drives and $171 million from enterprise systems and flash drives in the three months to December 29. It said it shipped 95 EB of capacity compared to 89.6 EB last quarter and 112.5 EB a year ago. The average capacity per drive was 8.2 TB, up from 7.3 TB a year ago and 7.5 TB last quarter.
Snapshot of Seagate’s past financial performance: Mass capacity and legacy drive numbers are only available from Q2 fiscal 2023.
Mosley talked about demand trends on the earnings call, saying: “From a demand standpoint, gradual recovery within the US cloud market has started to take shape, reflecting solid progress in consuming excess inventory, along with more stable end-market behavior.
“Enterprise OEM demand trends have also stabilized within the US markets. Customer feedback still points to macro-related concerns, although IT hardware budgets are projected to modestly improve in calendar 2024, and traditional server growth is expected to resume trends that support incremental HDD demand growth in the calendar year.”
China is lagging a bit, we’re told: “Across the broader China markets, we project a relatively slower pace of recovery given the ongoing economic challenges within the region. However, some local governments announced further steps to support the region’s economy, which our customers believe will bolster local demand across mass capacity markets in China in the second half of the calendar year.”
Seagate introduced its higher capacity HAMR drives this quarter and expects volume shipments to start ramping up. It can use HAMR tech to reduce the platter count in today’s mid-to-low capacity drives and so improve its cost structure. This should lead to increased profitability as the drive recovery gets under way and it ships more drives overall.
Mosley continued: “We are rapidly nearing qualification completion with our initial hyperscale launch partner. The qualification has gone very well, and we are working with this customer at their request to fully transition future Seagate demand to the three-plus terabyte per disk platform.”
This means that other hyperscale drive users have not yet qualified the HAMR drives.
He talked about the manufacturing ramp and getting more hyperscale wins: “Volume ramp is starting in the March quarter according to plan with a goal to ship about 1 million units in the first half of this calendar year. We then expect to continue to ramp through the balance of the calendar year, and we are currently broadening our customer engagements. Based on their planned timelines, we expect to complete qualifications with a majority of US hyperscalers and a couple of global cloud customers during calendar 2024.”
Mosley explained how HAMR will improve Seagate’s drive manufacturing costs: “As we scale areal density to four terabytes per disk, this enables extremely cost-effective product offerings in the low to midrange capacity points used by a majority of our enterprise … customers. With four terabytes per disk, we used half the number of heads and disks to produce a 20-terabyte drive. Prototypes are already working in our labs with revenue planned for the second half of calendar 2025.”
The manufacturer confirmed it expects its second generation Mozaic 3+ 4TB/platter HAMR drives, with 40TB or more capacities, to ship in the second half of next year.
Seagate has just launched a 24TB IronWolf Pro NAS drive using its perpendicular magnetic recording (PMR) technology, not HAMR. This will be one of its last PMR drives as HAMR technology will be used across the board.
The revenue outlook for the next quarter is $1.65 billion+/- $150 million which is 11.3 percent down year-on-year. Seagate’s year-on-year quarterly revenue decline is easing as its recovery gets underway. CFO Gianluca Romano said: “We expect incremental improvements in mass capacity demand from both cloud and enterprise customers to more than offset seasonal-related decline in VIA and the legacy markets.”
Jill Stelfox has departed as CEO and executive chairwoman at cloud file services collaborator Panzura, with former CRO and Chief Transformation Officer Dan Waldschmidt moving into the top spot in her stead.
Panzura started out as a file sync and share business, but didn’t grow enough. It evolved into a cloud-based file data services supplier after the company was refounded by Jill Stelfox who led a private equity buyout by Profile Capital Management in May 2020. The firm was restructured and then grew its business in competition with CTERA and Nasuni.
Dan Waldschmidt
Waldschmidt said in a statement: “I am incredibly proud of the impressive growth that this team has achieved to date. However, our ambitions are higher and the impact we plan to deliver for the enterprise is much greater. We are confident we can move even faster to provide customers with unrivaled value, security, visibility, and control of their stored data.”
Panzura chairman and Profile Capital Management president Ben Chereskin said: “Dan is well positioned to progress Panzura into a leading enterprise-grade business platform, and it is a natural transition given his deep industry experience and intimate knowledge of the company.”
Waldschmidt joined Panzura in 2020 as part of Stelfox’s team, where Panzura says he played a key role of crafting the strategy for revenue generation and moving Panzura into the enterprise market. As CRO, he led a 150 percent year-over-year increase in the customer base. Waldschmidt also guided 288 percent revenue growth over three years, 125 percent net retention, and maintained 98 percent brand loyalty. He negotiated agreements with 84 partners, and successfully developed and deployed an international revenue expansion plan.
Jill Stelfox
He became the Chief Transformation Officer in April last year. In a LinkedIn post he said: “With Panzura revenue established at record levels, I turned my focus to combining strategic foresight with effective implementation to lead significant improvements in operational efficiency and accelerated service delivery. We are successfully navigating a comprehensive digital transformation, strengthening Panzura’s standing in the market and elevating our customer experience.”
And Stelfox? A Panzura spokesperson said: “Jill has moved on from the firm and we wish her the best in her future endeavors.” Waldschmidt said: “I want to thank my co-refounder, Jill Stelfox, for her service to the company as CEO. Jill and I came into the company together and we achieved significant progress.”
Bootnote
Waldschmidt is an author and elite ultra-marathon runner, holding a record for running the equivalent elevation of Mount Everest in a single attempt.