


GPU-powered RAID card provider Graid has developed an entry-level card: the SR-1001.
Graid until now has had two products: the SR-1000, and the SR-1010. Both support up to 32 SSDs but the SR-1000, Graid’s first card, has a PCIe gen 3 interface while the SR-1010 uses PCIe gen 4 and is therefore faster. They are for use in enterprise datacenters. Unlike traditional RAID cards that connect directly to storage drives, Graid’s SR, or SupremeRAID, products are PCIe-connected peers on the host’s motherboard and are not in the data path.
Leander Yu, President and CEO of Graid Technology, has this to say about the launch on Thursday: ”As NVMe SSDs play a crucial role in cloud, core, and edge infrastructure, the demand for enhanced data protection without compromising performance is evident. SupremeRAID SR-1001 addresses this need by delivering best-in-class performance and airtight data protection while optimizing throughput, parallelism, and latency, ensuring seamless performance at the edge.”
The SR-1001 is a limited version of the SR-1000 in that it supports just 8 SSDs and has lower performance than the other two cards, as the table below summarizes:
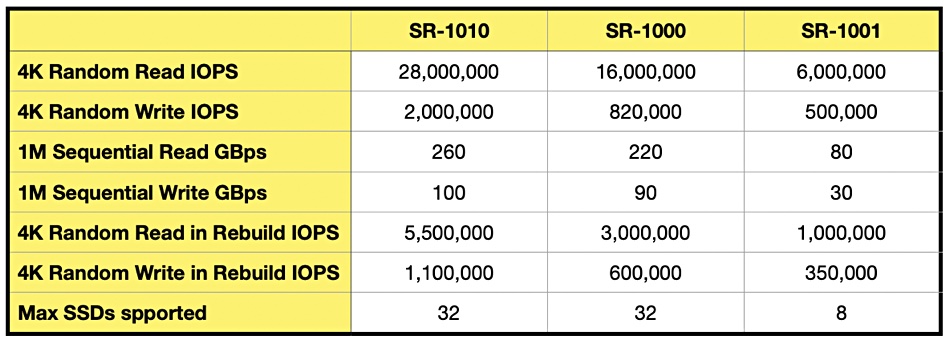
The SR-1001 has the same code base as its siblings. It is intended for use by tower and edge servers, professional workstations, and gaming desktops, running apps such as CAD, video editing, IoT workloads, and games.
Thomas Paquette, senior veep and GM at Graid, said the biz has plans to increase the number of SSDs supported by its cards later this year and will also add PCIe 5 support. That will send performance higher as well, we’re promised. He said Graid has no plans to add deduplication or compression or other data services to the hardware. Its products are intended to be NVMe SSD failure protection cards and not computational storage devices.
Graid believes its performance numbers versus legacy RAID cards, such as Broadcom’s 9600 and 9500 offerings, are superior. That said, the SR-1001 is said to be slightly less performant than Broadcom’s 9600 gear on the rebuild IOPS front but apparently convincingly better at sequential throughput.
The SupremeRAID cards also beat software RAID products, which use host server CPU cycles for RAID parity calculations and can limit overall server application performance.
The SR-1001 extends Graid’s market coverage. It has also developed a UEFI card product to protect server boot SSDs, and a fan-less product to reduce card thickness. Its market prospects look good, with Paquette telling IT journalists touring Silicon Valley this month that its AI/ML, edge computing, speed-dependent big data analytics, cloud service provider, and telecom & 5G infrastructure market segments are all growing.
He said the company had completed an A+ VC round last year, raising less than half the $15 million it pulled in from a 2022 A-round. We believe its total funding is around $20 million. It will probably run a B-round later this year to pay for business infrastructure expansion, such as hiring more sales and marketing people. Paquette said: “When we get to that point as a company, we would have additional investors and would naturally cede some control which is typical as venture backed companies progress through different phases of growth.”
Check out a datasheet-class SR-1001 brochure here.
Our view:
No competitors to Graid have emerged, meaning other GPU-powered RAID cards, since it launched its product family in 2021. The SupremeRAID series is said to have a substantial performance advantage over leading RAID card supplier Broadcom’s products, and leaves software RAID behind as well. It has a substantial performance runway ahead as PCIe gen 5 servers with a gen 5 SupremeRAID card will go even faster than PCIe gen 4 server/card combinations. Unless Broadcom and other hardware RAID card suppliers adopt the same GPU-powered technology, or an equivalent whatever that might be, they will stay in the relative low performance area.
Graid has taken in around $20 million in funding and a B-round would almost inevitably increase its valuation from the A-rounds. We here at B&F think an IPO is unlikely, the technology being quite niche, but an acquisition looks a likelier prospect. This is just our gut feeling to be clear. We have no inside knowledge. The place we get to with this is a RAID card supplier, such as Broadcom, feeling the competitive heat and buying Graid. What would it cost? We’re in string length estimation territory at this point. Suppose a 5x multiple on the VC funding was taken as a starting point; that’s $100 million. But a B-round valuation could put a higher price on the company; say $500 million or more. It’s going to be an interesting year.
Bootnote
Broadcom’s 9600 can implement over 3 million host operations per second during rebuilds on a RAID 10 or RAID 5 volume.
























{kind=link}