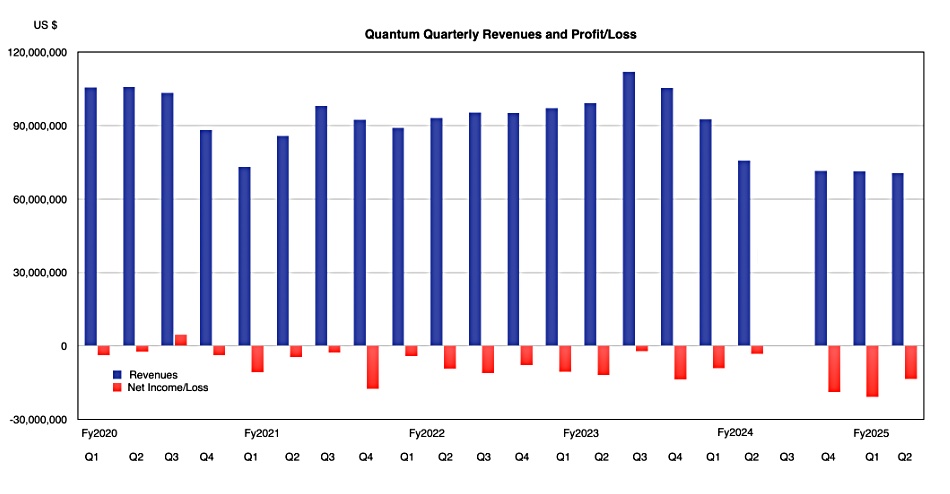
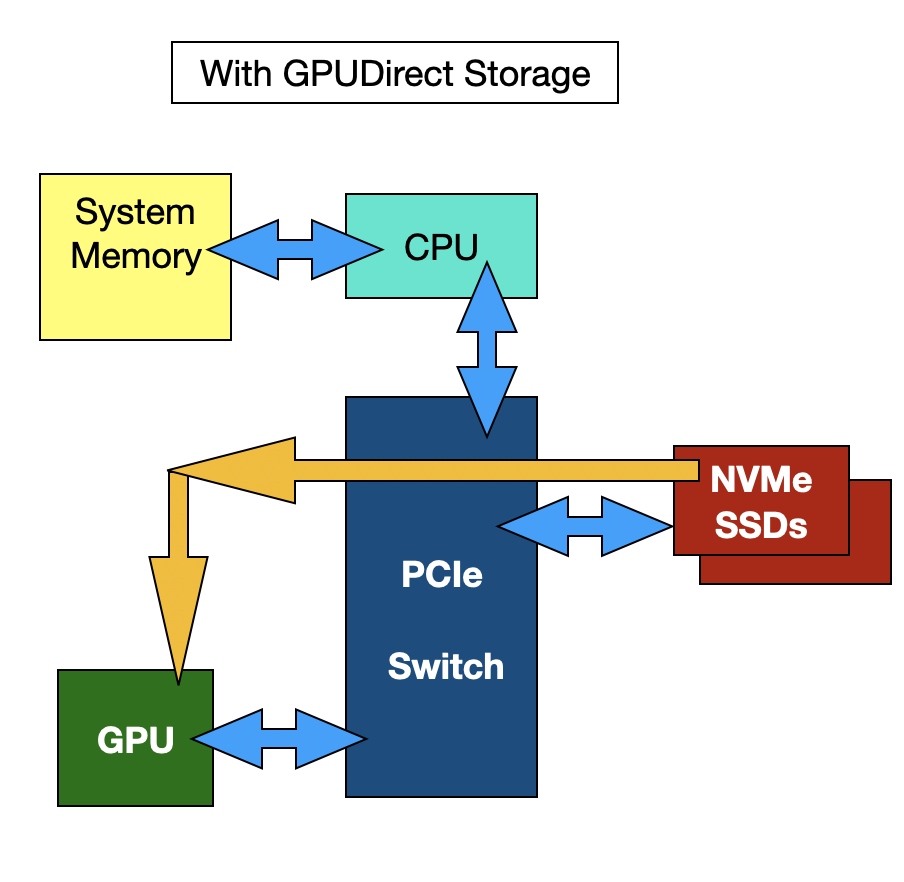
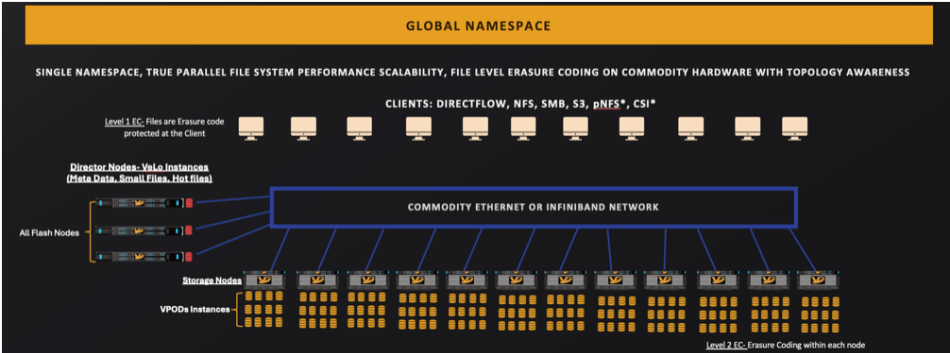
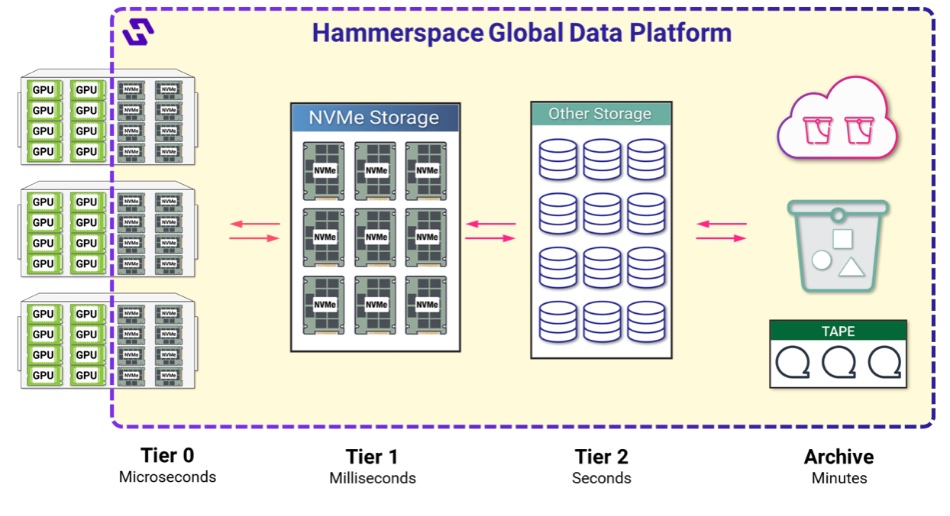
Data orchestrator Hammerspace has discovered how to add a GPU server’s local NVMe flash drives as a front end to external GPUDirect-accessed datasets, providing microsecond-level storage read and checkpoint write access to accelerate AI training workloads.
As an example, a Supermicro SYS-521GE-TNRT GPU server has up to 16 NVMe drive bays, which could be filled with 16 x 30 TB SSDs totaling 480 TB or even 16 x 61.44 TB drives amounting to 983 TB of capacity. Hammerspace says access to these is faster than to networked external storage, even if it is accessed over RDMA with GPUDirect. By incorporating these drives into its Global Data Environment as a Tier 0 in front of Tier 1 external storage, they can be used to send data to GPUs faster than from the external storage and also to write checkpoint data in less time than it takes to send that data to external storage.
We understand that checkpoints can run hourly and take five to ten minutes, during which time the GPUs are idling. Hammerspace Tier 0 drops the time from, say, 200 seconds to a couple of seconds.

David Flynn, founder and CEO of Hammerspace, stated: “Tier 0 represents a monumental leap in GPU computing, empowering organizations to harness the full potential of their existing infrastructure. By unlocking stranded NVMe storage, we are not just enhancing performance – we’re redefining the possibilities of data orchestration in high-performance computing.”
Hammerspace points out that, although NVIDA-supplied GPU servers typically include local NVMe storage, this capacity is largely unused for GPU workloads because it is siloed and doesn’t have built-in reliability and availability features. With Tier 0, Hammerspace claims it unlocks this “extremely high-performance local NVMe capacity in GPU servers.”
It is providing this Tier 0 functionality in v5.1 of its Global Data Platform software. It points out that using GPU server’s local storage in this way reduces the capacity needed in external storage, thereby reducing cost, external rack space take-up, cooling, and electricity draw. This can save “millions in storage costs.” A figure of $40 million savings was cited for a 1,000 GPU server installation.
The company has also developed a software addition to speed local storage access and contributed it to the latest Linux kernel 6.12 release. It says this Local-IO patch to standard Linux enables I/O to bypass the NFS server and network stack within the kernel, reducing latency for I/O that is local to the server.
This development “allows use of the full performance of the direct-attached NVMe which multiple devices in aggregate can scale to 100+GB/s of bandwidth and tens of millions of IOPS while maintaining mere microseconds of latency, making Tier 0 the fastest, most efficient storage solution on the market to transform GPU computing infrastructure.”
Hammerspace told us: “LocalIO is way more powerful than GPUDirect. It allows the Linux OS to auto recognize it’s connecting to itself and handle the IO request zero copy – by pointer to the memory buffer.”
Altogether, Hammerspace claims this makes it possible to “unlock the full potential of local NVMe storage by making it part of a global file system that spans all storage from any vendor. Files and objects stored on local GPU server storage can now be shared with other clients and orchestrated within the Hammerspace Global Data Platform. Data can be automatically and intelligently tiered between Tier 0, Tier 1, Tier 2, and even archival storage, while remaining visible and accessible to users.”
Hammerspace says it can work its local GPU server storage and Local-IO magic in the cloud as well as on-premises. Also, this is not just for GPU computing. It can run it in an x86 virtual machine (VM) farm to feed VMs with data faster.
v5.1 of Hammerspace’s software also includes:
- A more modern and dynamic user interface.
- A highly performant and scalable S3 object interface allowing users to consolidate, access, and orchestrate file and object data on a single data platform.
- Performance improvements for metadata, data mobility, data-in-place assimilation, and cloud-bursting.
- New Hammerspace data policies (called Objectives) and refinements to existing Objectives make it easier to automate data movement and data lifecycle management.
We understand that a second hyperscaler customer after Meta has adopted Hammerspace and prospects in the US government lab market are looking good.