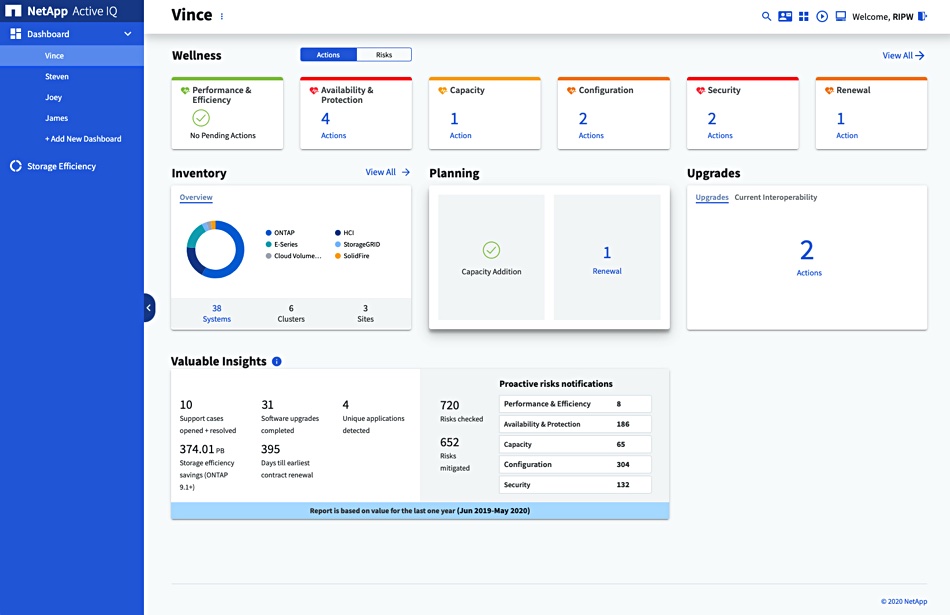
Tom’s Hardware has published a scoop-ette on an 8TB Samsung QVO 870 SSD using QLC (4bits/cell) NAND and produced in the U.2 format. The entry level starts at 1TB.

News of the 870 leaked via Amazon listing, which was pulled shortly after the Tom’s Hardware story. Samsung’s current 860 QVO uses the company’s 3D 64-layer V-NAND in QLC format and we understand the 870 QVO uses the later and denser 100+ layer 3D V-NAND generation.
The drive should have a SATA III interface like the 860, with these drives built for affordable capacity rather than high performance.
Rakers round-up
Wells Fargo senior analyst Aaron Rakers has given his subscribers a slew of company updates, following a series of virtual meetings with suppliers. Here are some of the insights he has gleaned.
Intel’s 144-layer 3D NAND is built with floating gate technology and a stack of three 48-layer components. This will be more expensive than single stack or dual-stack (2 x 72-layer) alternatives.
Optane Traction: “Over a year post launch (April 2019), Optane has now been deployed at 200 of the Fortune 500 companies, and has had 270 production deal wins, and an 85 per cent proof of concept to volume deployment conversion rate. In addition to optimization work with SAP Hana and VMware, [Intel] noted that the partner ecosystem / community has discovered new use cases for Optane, such as in AI, HPC, and open source database workloads.”
FPGA maker Xilinx: “Computational Storage. Xilinx continues to highlight computational storage as an area of FPGA opportunity in data centre. This includes the leverage of FPGAs for programmable Smart SSD functionality – Samsung representing the most visible partner; [Xilinx] noting that the company has active product engagements with several others.”
Dell EMC PowerStore: “The new Dell EMC PowerStore system also looks to compete more effectively against Pure Storage with Anytime Upgrades and Pay-per-Use consumption. The PowerStore systems can be deployed in two flexible pay-per-use consumption models with short and long-term commitments (including new one-year flexible model). This will likely be positioned against Pure Storage’s Pure-as-a-Service (PaaS) model. Anytime Upgrades allow customers to implement a data-in-place controller upgrade that will most likely be viewed as a competitive offering against Pure’s Evergreen Storage subscription (enabling a free non-disruptive controller upgrade after paying 3-years of maintenance).“
Nutanix and HPE: “Nutanix’s relationship with HPE continues to positively unfold. [Nutanix CFO Dustin] Williams noted a strong quarter for the partnership in terms of new customers. He said that Nutanix has been integrated into Greenlake but it is still in its infant stages.”
Seagate: “Seagate will be launching a proprietary 1TB flash expansion card for the upcoming (holiday season) Xbox Series X, and the company will be the exclusive manufacturer of the product. While not a high margin product, this alignment provides brand recognition as well as potential to drive higher-capacity HDD attach for additional (cheaper) storage. Regarding the move to SSDs within the next-gen game consoles, we would note that Seagate has shipped 1EB of HDD capacity to this segment over the past two quarters, and thus we would consider the move as having an immaterial impact to the company.”
SVP Business & Marketing Jeff Fochtam characterised Seagate’s SSD “strategy as being complementary to its core HDD business. He noted that Seagate has been on a strong profitable growth path with SSDs, which he credits to the company’s supply chain efforts and strategic partnerships. The company currently has >10 per cent global share in consumer portable SSDs, after rounding out the portfolio ~1 year ago.”
Nutanix Xi Clusters
Nutanix has been busy briefing tech analysts about Xi Clusters.
The company told Rakers: “Nutanix Xi Clusters (Hybrid Multi-Cloud Support): clusters give [customers] the ability to run software either in the datacenter or in the public cloud. This makes the decision non-binary. Clusters are in large scale early availability today, GA in a handful of weeks first with AWS and then with Azure. It will be cloud agnostic. The ability to run the whole software stack in the public cloud strengthens the company’s position in the core business by giving the customer the optionality to run Nutanix licenses in the public cloud at the time of their choosing.”
And we learn from Nutanix’s briefing with William Blair analyst Jason Ader: “Through its Xi Clusters product, Nutanix enables customers to run Nutanix-based workloads on bare metal instances in AWS’s cloud (soon to be extended to Azure), leveraging open APIs and AWS’s native networking constructs. This means that customers can use their existing AWS accounts (can even use AWS credits) and VPCs and seamlessly tap into the range of native AWS services. From a licensing perspective, Nutanix makes it simple to run Nutanix’s software either on-premises or in the cloud, allowing customers to move their licenses as they so choose.
Shorts
Backup biz Acronis has a signed a sponsorship deal with Atlético de Madrid, and is now the football club’s official cyber-protection partner.
Accenture has used copy data manager Actifio to automate SQL database backup for Navitaire, a travel and tourism company owned by Amadeus, the airline reservation systems company.
SSD supplier Silicon Power has launched a US70 PCIe Gen 4 SSD in M.2 format and 1TB and 2TB capacities. It uses 3D TLC NAND, has an SLC cache, and delivers read and write speeds up to 5,000MB/s and 4,400MB/s, respectively.

Some more details of the SSD in Sony’s forthcoming PlayStation 5 games console have emerged. It has 825GB capacity and is a 12-lane NVMe SSD with PCIe 4.0 interface and M.2 format. The drive has a 5GB/sec read bandwidth for raw data and up to 9GB/sec for compressed data. In comparison, Seagate’s FireCuda 520 M/2 PCIe gen 4 SSD also delivers 5GB/sec read bandwidth. It has 500GB, 1TB and 2TB capacity levels. An SK Hynix PE8010 PCIe 4.0 SSD delivers 6.5GB/sec read bandwidth. Check out this Unreal Engine video for a look at what the PS5 can do.

Stellar Data Recovery has launched v9.0 of its RAID data recovery software. The new version adds recovery of data from completely crashed and un-bootable systems, and a Drive Monitor to check hard drive health.
The Storage Performance Council has updated the SPC-1 OLTP benchmark with five extensions that cover data reduction, snapshot management, data replication, seamless encryption and non-disruptive software upgrade. They provide a realistic assessment of a storage system’s ability to support key facets of data manageability in the modern enterprise.
Automotive AI company Cerence is building AI models using WekaIO’s filesystem, which won the gig following a benchmark shoot-out with Spectrum Scale and BeeGFS.
Striim, a supplier of software to build continuous, streaming data pipelines from a range of data sources, has joined Yellowbrick Data’s partner program.
WANdisco, which supplies live data replication software, has raised $25m in a share placement. The proceeds will strengthen the balance sheet, increase working capita and fund near term opportunities with channel partners The UK company said continues to work towards run-rate breakeven by capitalising on the Microsoft Azure LiveData Platform.