InfiniteIO has added an Azure Blob backend, to make its file metadata accelerator more suited to Microsoft users.
There are now four public cloud tiering targets: Amazon Glacier, Azure Blob, Google Cloud Platform and IBM’s Cloud Object Store.
Mark Cree, InfiniteIO CEO, said in prepared remarks: “Enterprises can slash their storage spend today with InfiniteIO and Microsoft Azure technology without sacrificing speed or performance for their private and public cloud initiatives.”
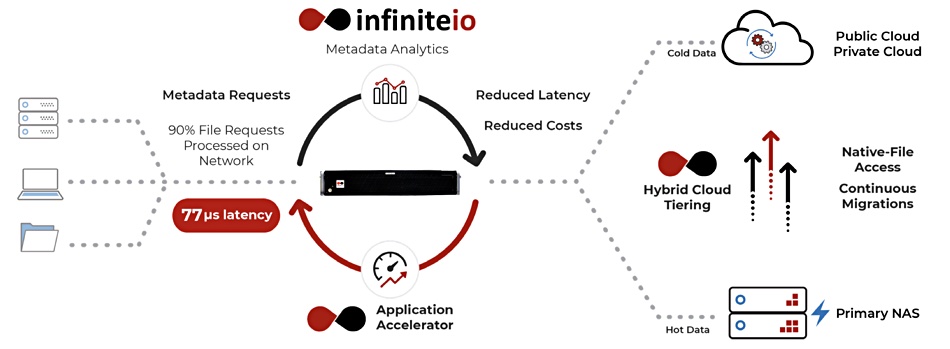
InfiniteIO processes NFS or SMB filesystem access metadata in a dedicated system. A typical NFS request could involve seven metadata requests across the NFS network with a single data transfer. InfiniteIO handles the metadata requests locally with its own Application Accelerator and so speeds up network file access.
The software moves files to cloud backend storage and remaps file requests seamlessly from on-premises file access users or applications.
On-premises S3 object storage targets are accessed via InfiniteIO’s ‘Hybrid Cloud Tiering’ .
InfiniteIO Hybrid Cloud Tiering
The Infinite Insight app scans files in on-premises NAS arrays and identifies those that have not been accessed recently. These files are shunted to object stores on-premises and in the public cloud, to release primary filer store capacity.
Read more about the InfiniteIO technology and Hybrid Cloud Tiering in a white paper (registration required).
Three startups aim to revolutionise and rescue the on-premises storage array from the twin assaults of hyperconverged infrastructure (HCI) and the public clouds.
They are Infinidat, StorONE and VAST Data and each company is gaining enterprise customers who agree that their technology supersedes all-flash arrays in marrying capacity scaling and performance.
All three claim the classic all-flash array, even when extended with NVMe-over-Fabrics speed, is a dead-end. Ground-up re-written storage software is needed to reinvigorate shared storage array technology.
Each company is a technology outlier and has responded differently to the twin needs of storing large and growing volumes of primary data cost-effectively while providing fast, flash-level access.
From left, Moshe Yanai (Infinidat), Rennen Hallek (VAST Data) and Gal Naor (StorONE)
Infinidat
According to Infinidat, all-flash arrays are prohibitively expensive at petabyte scale and its DRAM caching makes its disk-based arrays faster than all-flash arrays, even when they are boosted with Optane 3D XPoint drives.
Infinidat eschews a flash capacity store, relying instead on nearline disk drives with data prefetched into a memory cache using a Neural Cache engine with predictive algorithms. A thin SSD layer acts as an intervening store between disk and the DRAM. There are three controllers per array, which enables parallel access to the data.
Infinidat’s monolithic InfiniBox array provides block and file access to the data and there is technical background information in a Register article. The Neural Cache engine monitors which data blocks have been accessed and prefetches adjacent blocks into DRAM.
According to a Silverton Consulting report, the cache metadata uses LUN block addresses as an index and “can maintain information on billions of objects, accessing and updating that metadata in microseconds”. It enables more than 90 per cent of reads to be satisfied from memory.
Infinidat said it had deployed more than 6EB of storage to its customers in February – an exabyte greater than six months previously. It also said this 6EB was more than the top eight all-flash array (AFA) vendors had shipped in 2019.
Competitors include Dell EMC’s PowerMax, IBM with its DS8800 product, and Hitachi Vantara’s VSP. Blocks & Files expects Infinidat growth to continue.
StorONE
StorOne, Israeli startup came out of stealth in 2017, after spending six years developing its own storage software stack.
The basic idea about marrying capacity and performance is expressed through the company’s TRU (total resource utilisation) software. This can deliver the rated throughput of a storage drive, whether it is a disk drive, a SAS or SATA SSD or an NVMe SSD. StorONE said its storage software stores data as blocks which could be accessed either as blocks, files or objects in a universal store.
StorONE’s basic pitch is that its software make all types of storage hardware go faster. For example, StorONE delivered 1.7 million IOPS in a 2-node ESXi server system using 24 x 3.84TB WD SSDS in a JBOD as the data store. The company claims a typical all-flash array would need four times as much controller and storage hardware to deliver that performance.
More Optane Flash Array background can be gleaned from a video on Vimeo.
At launch, the TRU system scaled up to 18GB/sec of throughput and 15PB of capacity, making this enterprise-class in scalability. StorONE is now developing S1: Optane Flash Arrays, using Optane SSDs as a performance tier and Intel QLC flash as the capacity store. It says the combination with its own S1:Tier software “delivers over one million read IOPS, and over 1 million write IOPS”.
StorONE has not revealed much customer information, at time of writing. However, the company has made its pricing transparent and markets its technology as significantly cheaper than the competition. CEO and founder Gal Naor wrote in April 2020: “It is not unusual for us to provide a five-year total cost of ownership price to a customer that is less than what they are paying for 18 months of maintenance.”
The company is also developing an all-Optane array for extreme performance workloads. This is described in an unpublished StorONE Lab report which we have seen. In testing a three-drive system the S1 Enterprise Storage Platform delivered between 85 per cent to 100 per cent of the raw performance of the physical Optane drives:
1.15 million random read IOPS at 0.035ms latency
480,000 random read IOPS at 0.55ms
6.8GB/sec sequential read bandwidth at 0.3ms
3.1GB/sec sequential write bandwidth at 0.5ms
Our sense is that StorONE is making steady progress, while trying to demonstrate it can accelerate any storage hardware configuration without focusing on any particular market.
VAST Data
VAST Data already had some customers for its enterprise storage arrays when it came out of stealth in February 2019. Initially, the arrays used TLC (3bits/cell) flash and then transitioned to denser and lower cost QLC NAND.
VAST Data’s basic pitch revolves around extra efficient data reduction and erasure coding. The way it reduces the number of times it writes to its flash drives means the array cost and endurance are better than ordinary all-flash arrays. Customers can store all their data on flash, access it via file and object protocols, and get flash speed at disk array prices, the company claims.
Customer progress has been rapid, according to Jeff Denworth, co-founder and VP for products. He told a press briefing this week that year one sales, starting February 2019, eclipsed first year sales of Data Domain, Isilon, Pure Storage and Nutanix. The average customer spend was $1.02m and VAST claimed dozens of customers across four continents. Denworth said the company has $140m cash in the bank and sees a “clear path to breakeven”.
VAST focuses on the enterprise flash capacity market, which means it spreads less thinly across its potential customer base than StorONE. It has also produced customer references, unlike StorONE.
VAST Data customer quotes from briefing deck
Comment
Denworth told the press briefing that the NVMe-over-Fabrics array startups had failed to live up to expectations. But how will VAST, Infinidat and StorONE prosper?
Blocks & Files notes that no mainstream storage array vendor has so far made moves to extend or adapt their technology in response to Infinidat, StorONE or VAST Data. That is unsurprising, as each startup has developed its software stack from the ground up. Adding similar caching or erasure coding or data reduction technologies by the mainstreamers with their different software stacks would be difficult.
That implies that, if one or more of the three are successful enough, then an acquisition might be on the cards.
Specialist GPU servers could be overkill when crunching relatively small amounts of data for analytics purposes. So why not use ordinary servers boosted with GPU accelerator cards and deployed via HCI instead? This is what AIMES, a specialist tech provider for the UK’s National Health Service, does with its Health Cloud service.
AIMES is using GPU-enhanced hyperconverged infrastructure appliances (HCIAs) from Pivot3 to provide AI-based applications to NHS clinicians and researchers.
NHS trusts
The NHS is organised into regional NHS Trusts. These are interconnected by the closed, secure and private broadband Health and Social Care Network (HSCN) which safeguards the exchange of sensitive NHS data between trusts and their managed service providers.
An MSP can provide shared IT facilities which regional trusts can use, instead of operating their own duplicated IT department and facilities. One such MSP is AIMES (Advanced Internet Methodologies and Emerging Systems), which is based in Liverpool and originated as a spinout from Liverpool university.
Glenn Roberts, business development director at AIMES, tells us NHS trusts typically do not want to use the big US public cloud providers because of data sovereignty and security issues. They also want to expand the clinical side of their hospitals and not the admin side, which includes local IT services.
My AIMES is true
AIMES provides managed tier 3 data centre services to commercial customers over the general internet, and also to NHS trusts using the NHS HSCN networking facility. One focus area is to provide Trusted Research Environments (TREs) to its NHS customers inside a Health Cloud.
These customers such as clinicians, could provision and decommission research environments with the same speed and flexibility as the public cloud while providing researchers with secure and high-availability virtual access complying with NHS data privacy regulations.
Pivot3 precursors
AIMES is Pivot3’s customer for its GPU-enhanced systems and makes Pivot3 capabilities available through its Health Cloud infrastructure, which it set up in 2015.
Glenn Roberts
Roberts told us AIMES initially provided Health Cloud TREs using a set of servers accessing a Dell EMC EqualLogic (PS) SAN, and then a Compellent (SC) SAN but experienced problems with reliability and upgrades. (The SC SAN is still in use with general virtual servers.) AIMES also experimented with a SAN in the cloud, an Azure pod and Hyper-V, but that did not fulfil its needs either.
Pivot3
After checking out Dell EMC’s VxRail and HPE’s HCI offerings, AIMES switched to Pivot3 HCI systems, In 2018, as a way of fixing these issues. Roberts said: “Pivot3 ticked all our boxes. It’s rare that a technology does exactly what it says on the tin.”
AIMES has five clustered Pivot3 Acuity nodes, two with NVMe SSDs to provide better general performance, and two Lenovo-based systems with GPU cards to deliver faster analytics capability. The non-GPU nodes are based on Dell EMC PowerEdge servers.
Roberts is particularly pleased with Pivot3’s scalability and the quick and easy way its Acuity software recognises and adds nodes such as the two GPU systems to the cluster. That reduces AIMES’s own admin effort.
HCI AI
Roberts told us the GPU nodes help with running predictive AI applications looking at the likelihood of depressive episodes in mental health patients. The AI model code monitors clinical data and sends alerts to clinicians if certain early marker patterns are detected in a patient’s data.
He also told us: “We’re doing AI in a project with Barts [Health NHS Trust] for cardiac imaging.” A patient has a heart MRI scan and the AI code looks at a series of right ventricle contraction images from the scan. It discerns a measure of heart health from them that is up to 40 per cent more accurate than a human assessment.
This use of AI running on Pivot3 HCI systems represents a “normalisation of AI” where ordinary servers are fitted with GPU cards to run accelerated AI code. Roberts said this is big data-stye AI analytics with relatively small amounts of data and it’s not necessary to use separate GPU systems such as Nvidia’s DGX-type GPU servers.
Commvault has yielded to Starboard Value by appointing three new members to the board. The data management vendor has also set up a new operating committee.
Starboard Value announced in March that it held 9.3 per cent of Commvault stock. In April it told Commvault it wanted six proxy directors on they board. Commvault accepted one of Starboard’s picks – Todd Bradley, CEO of Mozido. Presumably, they both agreed about the other new members; Alison Pickens, formerly COO of Gainsight, and Arlen Shenken, Citrix CFO.
The new directors replace three long-standing members of the 11-strong board; co-founder Al Bunte, Frank Fanzilli and Daniel Pulver.
Jeff Smith, Starboard CEO, said in a canned statement: “We appreciate the collaborative dialogue we have had with Commvault’s Board and leadership team. Commvault is an outstanding company. We believe the expertise provided by these new directors and the focus of the Board’s Operating Committee will help improve Commvault’s profitable growth, return on investment, and enhance value creation.”
Commvault chairman Nick Adamo also issued a quote: “We are pleased to add three highly qualified directors who bring both targeted experience and diversity to the Board.”
Operating committee
Bradley, Schenkman and existing director Charles Moran sit on a new operating committee that will oversee Commvault’s budgeting process and work with management to establish margin targets and a balanced capital allocation policy no later than December 31, 2020.
Adamo said: “We … expect the new Operating Committee to build on the progress Sanjay Mirchandani has made since being appointed CEO, including important changes to our operating priorities, improvements to our go-to-market strategy and investments in Commvault’s technology differentiation.”
Commvault is migrating from its traditional on-premises soultion sales to a subscription based cloud-centric model. But progress has been slow. In response to faltering revenue growth it appointed a new CEO, Sanjay Mirchandani, in February last year. Three financial quarters later and it had not returned to growth, hence Starboard’s interest in shaking up the company.
The Electronic Visualisation Lab (EVL) at the University of Illinois is using Liqid composable systems to conduct data intensive research into computational fluid dynamics, brain imaging techniques, streaming high-resolution data visualisation to wall-sized displays and more.
EVL’s work needs GPUs to run efficiently. A normal architecture limits EVL researchers to traditional cluster topology with eight GPUs per server using a specialised GPU chassis. However, many workloads do not utilise eight GPUs efficiently or they have unbalanced resource requirements that vary at each step of a science workflow.
Liqid composable infrastructure, by contrast, enables EVL to deploy a system comprising 64 GPUs, 24 CPU nodes, NVMe storage, 100G networking and large Intel Optane memory pools.
EVL wall-size video image display
The computer’s components (traditional processor, GPU, storage and networking) are pooled so that different applications with different workflows run simultaneously, with each configuring the resources it requires almost instantaneously, at any time.
EVL engineers are working to introduce hardware composability to Kubernetes, enabling users to create containerised applications with policy-defined, reproducible hardware and software deployment. The application identifies the hardware required and directs the right amount of physical resources to handle the task.
Lance Long, EVL senior research programmer, said: “Liqid’s architecture is designed to configure bare-metal hardware on demand. Leveraging Kubernetes’s ability to detect available resources and extending the Liqid API allows us to have a container deploy only the resources – six GPUs and a 100 Gbps NIC, for example – that is required by the application.”
This week, Druva helps notebook and desktop users defeat ransomware, and WekaIO feasts on more STAC benchmarks.
Druva gets fiery-eyed
Druva, the backup service vendor, has cut a deal with security outfit FireEye to provide ransomware protection for desktop and notebook users.
FireEye Helix, a cloud-hosted security operations platform, integrates via APIs with Druva InSync to inspect endpoint restoration from backup files.
Sean Morton, customer experience VP at FireEye, said: “Traditional backup solutions can be a ‘black box’, but Druva’s unique capabilities offer greater visibility into ongoing activities.”
Druva said the combined system identifies abnormal data restoration, ensuring data being restored is within the enterprises’ network. It verifies compliance to geography-based data access and restoration policy and makes visible who is accessing the system, tracking Unauthorised Admin Login attempts, password changes and Admin attempts to download or recover data.
The joint software generates alerts, according to pre-built rules. These trigger pre-configured playbooks to help security analysts assess an event and mitigate or fix it.
WekaIO wins STACs of benchmarks
WekaIO, the fast parallel file system software startup, has topped another set of STAC benchmarks.
As we wrote 12 months ago: “The STAC-M3 Antuco and Kanaga benchmark suites are regarded as an industry standard for evaluating the performance of systems performing high-speed analytics on time series data. STAC benchmarks are widely used by banks and other financial services organisations.”
The STAC M3 tests involved a hefty setup with 32 HPE servers. The Kx kdb+ 3.6 database system was distributed across 14 HPE Proliant XL170r Gen10 servers, with data stored in a cluster of 18 HPE Proliant XL170r Gen10 servers with a total of 251TiB of SSD capacity, all accessed via WekaIO WekaFS 3.6.2 software.
WekaIO outperformed all publicly disclosed results in 11 of 24 Kanaga mean-response time (MRT) benchmarks and outperformed all publicly disclosed results in all Kanaga throughput benchmarks (STAC-M3.β1.1T.*.BPS).
When compared to a kdb+ solution involving an all-flash NAS and 4 database nodes (SUT ID KDB190430), it was faster in all 24 Kanaga MRT benchmarks and in 15 of 17 MRT Antuco benchmarks.
Fujitsu has announced PRIMEFLEX for VMware vSAN to streamline the deployment, operation, scalability and maintenance of VMware-based hyperconverged infrastructure (HCI). The system is intended for general purpose virtualization, virtual desktop infrastructures, big data and analytics, remote and branch office, edge computing and mission-critical workloads such as SAP HANA.
Kioxia has published a Manga comic designed by AI, called PHAEDO. This is the story of a homeless philosopher and Apollo, his robot bird, who try to solve crimes in Tokyo in 2030. Basically, AI software developed the character images using Nvidia GPUs and Kioxia SSDs. Kioxia says PHAEDO is the world’s first international manga created through human collaboration, high-speed and large-capacity memory and advanced AI technologies.
HPE has created vSAN ReadyNodes with VMware using ProLiant servers to add to its hyperconverged infrastructure appliance (HCIA) portfolio. The ProLiants are installed with vSphere, vSAN, and use firmware that complies with VMware Hardware Compatibility List (HCL). Customers receive HPE-based support for all Level 1 and Level 2 requests, with a handoff to VMware support for Level 3 software support requests.
IBM has joined the Active Archive Alliance. Chris Dittmer, IBM VP for high end storage, said: “Our archive storage solutions combine Exabytes of storage with geo-dispersed technology and built-in encryption for data integrity and confidentiality. We are excited to join the Active Archive Alliance and to help promote solutions that deliver rapid data search, retrieval, and analytics.” He’s talking mainly about disk-based IBM COS.
Wells Fargo senior analyst Aaron Rakers tells subscribers Micron pre- announced a solid (surprising) upside for their F3Q20 this week – revenue at $5.2-$5.4B and non-GAAP EPS of $0.75-$.80 vs. the company’s initial $4.6-$5.2B / $0.40-$0.70 guide. Rakers reckons demand for Micron’s server DRAM has shot up.
WANdisco, which supplies replication technology, has won a global reseller agreement with an un-named systems integrator. This integrator, with 240,000 people in 46 countries – think a CAP Gemini-class business – is going to build its own data migration practice for moving data at scale into the public cloud.
Veeam has published the Veeam 2020 Data Protection Trends Report, which reports that almost half of global organisations are hindered in their digital transformation (DX)journeys due to unreliable, legacy technologies. Forty-four per cent cite lack of IT skills or expertise, as one in 10 servers having unexpected outages each year — problems that last for hours and can cost hundreds of thousands of dollars. Veeam’s conclusion? This points to an urgent need to modernise data protection and focus on business continuity to enable DX. Buy Veeam products in other words. No surprise here.
People
Commvault has hired Jonathan Bowl as general manager of Commvault UK, Ireland & Nordics.
Beth Phalen, President of Dell EMC’s Data Protection Division, has resigned.
SoftIron has appointed Andrew Moloney as its VP of strategy to lead the company’s go-to-market planning and execution as it expands its product portfolio and global presence. SoftIron recently completed a $34m Series B funding round.
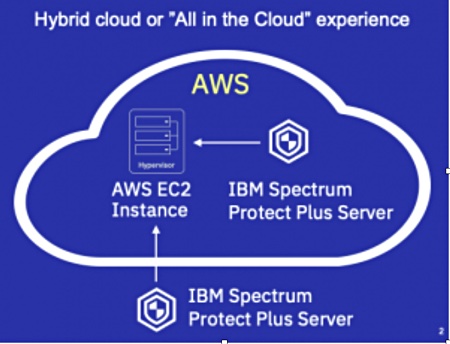
IBM has extended Spectrum Protect Plus (SPP); a data protection and availability product for virtual environments.
In hybrid clouds, enterprises can deploy IBM Spectrum Protect Plus on premises to manage AWS EC2 EBS snapshots’ Alternatively, they can deploy IBM Spectrum Protect Plus on AWS for the “all-in-the-cloud experience”. Enhanced AWS workload support includes EC2 instances, VMware virtual machines, databases, and Microsoft Exchange.
There is better protection for containers. Developers can set policies to schedule Kubernetes persistent volume snapshots, replication to secondary sites and copying data to object storage or IBM Spectrum Protect for secure long-term data retention.
Developers can back up and recover logical persistent volume groupings using Kubernetes labels. IBM said this capability is key; as applications built using containers are actually logical groups of multiple components. For example, an application may have a Mongo DB container, a web service container and middleware containers. If these application components share a common label, users can use the Kubernetes label feature to select the logical application grouping instead of picking individual volumes (persistent volumes) that make up the application.
Logical persistent volumes associated with Kubernetes namespaces can be backed up and recovered by developers.
Users can now back up, recover, reuse, and retain data in Windows file systems, with Spectrum Protect Plus agentless technology, including file-level backup and recovery of file systems on physical or virtualized servers.
Spectrum Protect
IBM continues to sell Spectrum Protect, which is a modern incarnation of the old Tivoli product,. The software backs up physical and virtual servers and in the public cloud. The latest release includes retention set to tape.
Spectrum Protect also enables users to back up the Spectrum Protect database directly to object storage including IBM Cloud Object Storage, AWS S3, Microsoft Azure, and other supported S3 targets.
There is a new licensing option for the Spectrum Protect Suite: the Committed Term License. These can be bought for a minimum of 12-months and up to a five-year term. IBM says the new pricing provides a lower-entry cost option, a flat price per TB, and increased flexibility with no vendor lock-in..
A new release of IBM’s Spectrum Copy Data Management’s lets users improve SAP HANA point in time (PIT) recovery with native log backups. Prior to this release, users could recover data using hourly snapshots. Log support enables much more gtranular recoveries.
Object storage supplier Scality says five healthcare customers each save an average $270,000 per PB over three years compared to their previous storage, and get data 52 per cent faster.
Applications include imaging, patient electronic health records, genomics sequencers, Biomedical, CCTV, EMR, radiology and accounting.
Data growth is a big issue for hospitals, Paul Speciale, Scality chief product officer, writes. “If we look at medium-to-large hospitals (those over 250 patient beds, which is common in cities with 100,000 people), in most cases there is now a petabyte scale data problem – medical image storage is becoming a much more prominent part of budgets.”
Scality has sponsored an IDC report to help persuade other healthcare customers to save money by using its RING software.
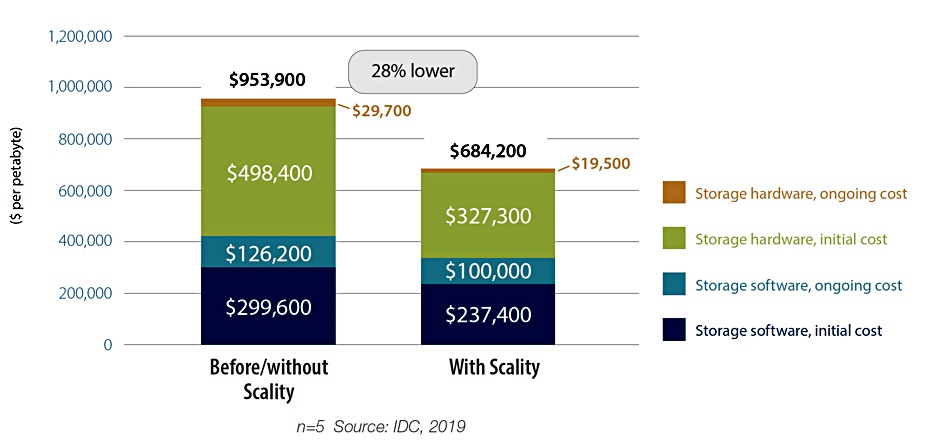
IDC interviewed five Scality customers – four hospital groups and a genomics research institution, -with an average of 2.7PB of data in their Scality RING object storage. A chart in the report shows the average costs for the Scality system and the customers’ equivalent storage systems not using Scality. Costs are split into initial and ongoing costs for storage hardware and software:
The Scality cost saving is 28 per cent, equating to $90,000 per PB per year or $90 per terabyte per year. Also, customers required 46 per cent less staff time such as scalability and ease of integration with other systems. One interviewee said: “Scality does not require a lot of management effort, unlike a SAN. Scality has allowed us to consolidate our storage arrays, which reduced the heterogeneous systems to manage a unified backup system.”
Scality numbers as customers more than 40 hospitals, hospital systems and genomics research institutions worldwide.
Update: Scality Zenko is the S3 server inside Fujifilm’s Object Archive. 24 June 2020.
Update: Cloudian and the Object Archive added. 9 June 2020.
Fujifilm is paving the way for tape cartridges and libraries to become object storage archives.
Traditionally files from backup software are stored sequentially on magnetic tape for long-term retention. The last major innovation in tape storage access was LTFS, the Linear Tape File System, in 2011. This provides a file:folder interface to tape cartridges and libraries, with a drag and drop method for adding or retrieving files.
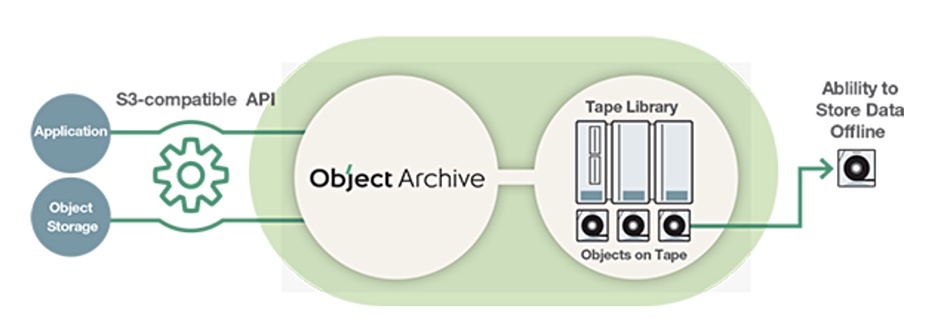
Now Fujifilm has developed a method for transferring objects and their metadata from disk or SSD drives to a tape system. This means tape can be used as an archive medium for object data.
Fujifilm’s new open source file format, OTFormat, enables objects and metadata to be written to, and read from, tape in native form.
The company’s Object Archive software uses OTFormat and an S3 API interface to provide the framework for an object storage tape tier – a software-defined tier, as Fujifilm puts it.
Update: Scality’s Zenko is the S3 server inside the Object Archive.
Fujifilm Object Archive
This tape tier can be an on-premises tape library. Fujifilm said storing petabytes of object data is much cheaper on tape drives than on drives or SSDs. It is also cheaper than the public cloud. However, tape’s slow access speed makes it suitable only for archiving low access rate objects or for object storage backup where slow restoration times are acceptable.
According to a Fujifilm White Paper, tape has a 4x data reliability superiority over disk drives. Tape also provides a literal air gap between the network and the tape cartridges when the latter are offline. This provides immunity from ransomware and other malware attacks, and a reliable means of recovering ransomeware-encrypted data.
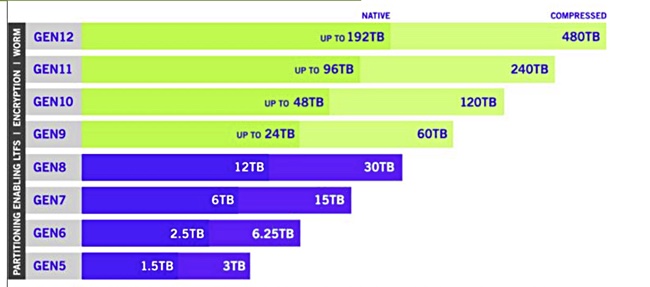
LTO roadmap. Assume 18 – 24 months between generations.
Fujifilm is a maker of LTO tape; the current generation is LTO-8 and 12TB raw capacity per cartridge, 30TB compressed. The LTO roadmap extends to LTO-12 with 192TB raw capacity, 480TB compressed. LTO-12 tapes will hold up to 16 times more data than LTO-8 cartridges. There’s lots of capacity headroom, in other words.
No UI or data mover
Fujifilm had not revealed at time of publication a user interface and data mover for its Object Archive. Such an UI/data mover is needed to select older and low-access objects from a disk or SSD-based object store, and move them to a tape system. It would also present a list of objects on the tape system and a means of retrieval.
Fujifilm perhaps needs one or more third parties to provide object backup and restore capabilities. There is a long list of potential partners. Speaking of which …. Jerome Lecat, Scality’s CEO, when asked about Fujifilm’s Object Archive, told us: “Unfortunately I cannot tell you anything more specific today, but watch our news in the coming weeks, especially around Zenko.”
Cloudian and the Object Archive
Cloudian CEO Michael Tso tells us: “We know a lot about this. About 3 years ago, Fujifilm’s Japan based product team reached out to us to partner with them for this product. They use HyperStore as their reference S3 platform for their internal development and test, we acted as their advisor on architecture and S3 API design/compatability. We also hosted them in our US office multiple times, and are engaged with Fujifilm US team as well.”
“We like Fujifilm’s team, their product, we’ve supported their journey. And yes, HyperStore can tier into it.
“I think this product is interesting in a few ways:
S3 is THE standard – they didn’t implement some multi-protocol translation gateway, or their own dialect of S3 (like some other tape vendors), they built S3 natively into the box.
Object is the present – their data layout on tape is optimized for object. That’s a really big deal because (a) it’s a lot of work and (b) it helps resiliency and efficiency. They went to all this work because object is the present, file/block are the past.
Object Stores need multi-cloud – OnPremises/Dark site cold archive is a real use case. HyperStore has native multi-cloud data management, so we simply plug in Fujifilm boxes as another “cloud target”, tier data in/out based on lifecycle policies. HyperStore’s single namespace can cover data in multiple clouds. All metadata stays in HyperStore so users can browse and search their entire namespace whether the actual data is in HyperStore, in a deep archive tape box, or in a public cloud.
This information’s means that Cloudian is ready to rock and roll with the Object Archive. We await the forthcoming news about its availability.
Snowflake has snuggled closer to its investor Salesforce with two tools that link their cloud-native systems.
The integrations enable customers to export Salesforce data to Snowflake and query it with Salesforce’s Einstein Analytics and Tableau applications. The idea is that enterprises should have a single repository for all their data.
Einstein Analytics Output Connector for Snowflake lets customers move their Salesforce data into the Snowflake data warehouse alongside data from other sources. Joint customers can consolidate all their Salesforce data in Snowflake. Automated data import keeps the Snowflake copy up to date.
Tableau dashboard
Einstein Analytics Direct Data for Snowflake enables users to run queries in their Snowflake Salesforce repository. The queries can also run data from other sources such as business applications, mobile apps, web activity, IoT devices, and datasets acquired through the Snowflake Data Marketplace and Private Data Exchange.
Einstein Analytics Output Connector for Snowflake will be available for customers later this year. Einstein Analytics Direct Data for Snowflake is in open beta and will also be generally available later this year.
Salesforce was a co-lead investor in Snowflake’s $479m funding round earlier this year, so it is literally invested in Snowflake’s success.
NetApp is buying Spot.io, an Israeli startup that specialises in cloud cost controls, for an undisclosed sum. The price is said to be $450m, according to Calcalist, an Israeli publication.
Amiram Shacher, Spot CEO and co-founder, said in a blog post about the deal: “We are going to build the next game-changing business unit at NetApp.”
Spot claimed more than 500 customers, including Intel – a backer – Sony, Ticketmaster and Verizon, in a 2017 funding round. The company was founded just two years earlier and has amassed $52.6m in venture funding in total.
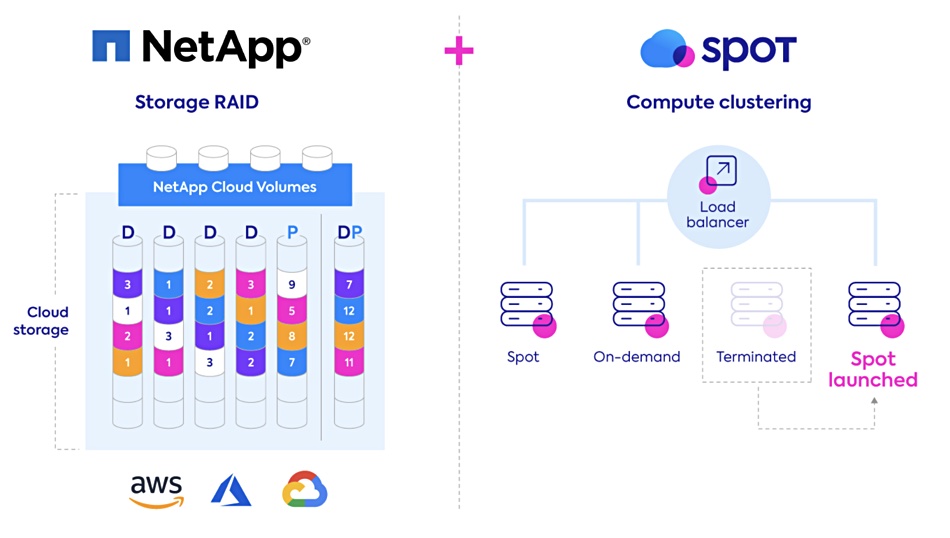
So what is NetApp buying? In effect, Spot is a cloud compute broker or virtual cloud provider that works with all three cloud giants. Spot’s Elastigroup product runs business applications on the lowest cost, discounted cloud compute instances, while maintaining service level agreements.
NetApp claims the technology can save up to 90 per cent of public cloud compute and storage cloud expenses. These typically account for up 70 per cent of total cloud spending.
Push these numbers through a mental spreadsheet and assume $1,000 per month public cloud spend and that compute and storage costs $700. By NetApp’s reckoning, Spot technology would saves $630, leaving total spend of $370 per month. If this technology works it’s a no-brainer.
NetApp will use Spot to establish an “application driven infrastructure” to enable customers to deploy more applications to public clouds. Spot’s as-a-service will provide continuous compute and storage optimisation of legacy enterprise applications, cloud-native workloads and data lakes.
Anthony Lye, head of NetApp’s public cloud services business, said in a canned quote: “Waste in the public clouds driven by idle resources and over-provisioned resources is a significant and a growing customer problem slowing down more public cloud adoption.
“The combination of NetApp’s… shared storage platform for block, file and object and Spot’s compute platform will deliver a leading solution for the continuous optimisation of cost for all workloads, both cloud-native and legacy. Optimised customers are happy customers and happy customers deploy more to the public clouds.”
NetApp and the public cloud
Here we have an on-premises storage array supplier encouraging customers to consume its storage services in the public cloud. That seems significant.
NetApp bought CloudJumper at the end of April and gained technology on which to base a NetApp Virtual Desktop Service providing virtual desktop infrastructure from the public cloud to work-from-home office staff. This will involve cloud compute and storage and Spot technology could be used to optimise the associated costs.
In its latest results (Q4 fy2020) NetApp’s public cloud business contributed 7.9 per cent of the revenue in the quarter. There was a $111m annual recurring revenue run rate in the business, up 113 per cent. This is good growth but from a small base and William Blair analyst Jason Ader thinks the “ramp has been well below management targets”.
In short, NetApp need grow its public cloud business.
“The Public Clouds have become the default platforms for all new application development,” Lye writes in a company blog. Application developers “don’t want to have to understand infrastructure details to be able to develop and deploy their code… Why shouldn’t the infrastructure be able to determine how to optimise performance, availability and cost, even as demands change and evolve?”
The deal should close by the end of October subject to the usual conditions. Spot will continue to offer and support its products as part of NetApp.
Elastigroup tech
Elastigroup creates a public cloud virtual server compute instance composed of Spot Instances, reserved instances and on-demand instances. This virtual instance is always available and dynamic, changing the actual instance type to continually find and use the lowest cost instances available.
The number of servers is scaled as demand requires and as public cloud billing periods start and terminate. Spot Instance pricing operates in a spot market and the company’s algorithms predict spot market price fluctuations and provisions on-demand instances when the spot market price goes above them.
Spot background
Spot was established in Tel Aviv in 2015 by Shachar, Liran Polak and Ahron Twizer, who has since left the company.
Shachar and Polak were members of the MAMRAM or ‘cloud infrastructure’ unit of the Israel Defense Forces and responsible for managing IDF’s data centres and virtualization systems.
They later pursued degrees in computer science and their academic research focused on addressing data centre inefficiencies by utilising Spot Instances in the Amazon cloud.
Spot Instances were excess compute capacity sold by AWS with discounts up to 90 per cent compared to normal compute instance pricing. They could be turned off with two minutes notice if AWS needed the capacity for its normal business.
Shachar and Polak designed a machine learning model to predict when AWS would want the spot instances terminated and Shachar’s employed moved to AWS Spot Instances for its IT compute needs. From there, they extended the service to Azure and Google Cloud.
IBM’s Storage for Data and AI portfolio now supports the recently announced Nvidia DGX A100, which is designed for analytics and AI workloads.
David Wolford, IBM worldwide cloud storage portfolio marketing manager, wrote last week in a company blog: “IBM brings together the infrastructure of both file and object storage with Nvidia DGX A100 to create an end-to-end solution. It is integrated with the ability to catalog and discover (in real time) all the data for the Nvidia AI solution from both IBM Cloud Object Storage and IBM Spectrum Scale storage.”
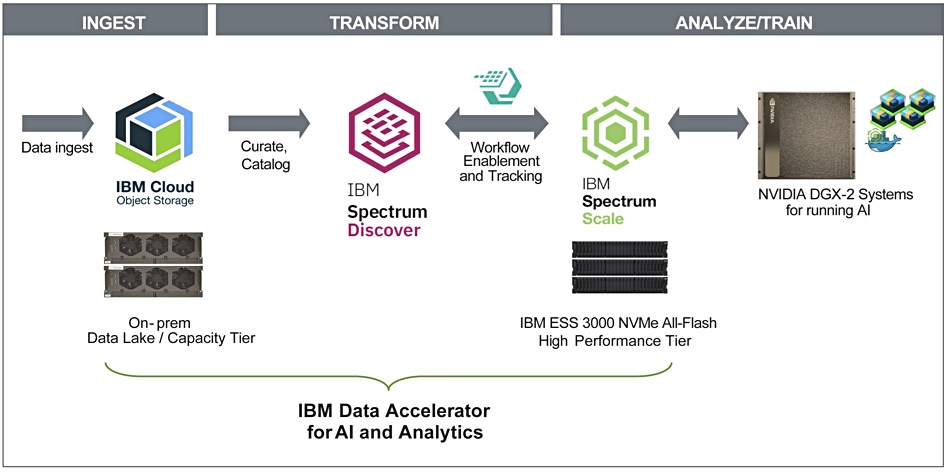
Big Blue positions IBM Storage for Data and AI as components for a three-stage AI project pipeline; Ingest, Transform, and Analyse/Train. There are five products:
ESS 3000 – an all-flash NVMe drive array, with containerised Spectrum Scale software installed on its Linux OS and with 24 SSD bays in a 2U cabinet
Spectrum LSF (load sharing facility) – a workload management and policy-driven job scheduling system for high-performance computing
IBM’s view of its storage and the AI Project pipeline
IBM is updating a Solutions Blueprint for Nvidia to include support for the DGX-A100. The new server uses Tesla A100 GPUs, which Nvidia claims is 20-times faster at AI work than the Tesla V100s used in the prior DGX-2.
Nvidia DGX-A100.
The IBM blueprint recommends COS to store ingested data, and function as a data lake. Spectrum Discover indexes this data and add metadata tags to its files. LSF manages AI project workflows and it is triggered by Spectrum Discover to move selected data from COS to the ES3000 with its Spectrum Scale software. There, it feeds the GPUs in the A100 when AI models are being developed and trained.
Other storage vendors, such as Dell, Igneous, NetApp, Pure Storage and VAST Data will also support the DGX A100. Some may try to cover the AI pipeline with a single storage array.